Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Pozyskiwanie danych to proces ładowania danych z co najmniej jednego źródła do tabeli w usłudze Azure Data Explorer. Po pozyskaniu dane są dostępne dla zapytań. Z tego artykułu dowiesz się, jak pobrać dane z pliku lokalnego do nowej lub istniejącej tabeli.
Aby uzyskać ogólne informacje na temat pozyskiwania danych, zobacz Omówienie pozyskiwania danych w usłudze Azure Data Explorer.
Wymagania wstępne
- Konto Microsoft lub tożsamość użytkownika Microsoft Entra. Subskrypcja platformy Azure nie jest wymagana.
- Zaloguj się do internetowego interfejsu użytkownika usługi Azure Data Explorer.
- Baza danych i klaster usługi Azure Data Explorer. Utwórz klaster i bazę danych.
Pobierz dane
W okienku nawigacji po lewej stronie wybierz pozycję Zapytanie.
Kliknij prawym przyciskiem myszy bazę danych, w której chcesz pozyskać dane. Wybierz Pobierz dane.


Wybieranie źródła danych
W oknie Pobieranie danych zostanie wybrana karta Źródło.
Wybierz źródło danych z listy dostępnych. W tym przykładzie dane są pozyskiwane z pliku lokalnego.

Uwaga
Maksymalny rozmiar pliku obsługiwany w pozyskiwaniu wynosi 6 GB. Zaleceniem jest pozyskiwanie plików z zakresu od 100 MB do 1 GB.
Konfigurowanie pozyskiwania danych
Wybierz docelową bazę danych i tabelę. Aby pozyskać dane do nowej tabeli, wybierz pozycję + Nowa tabela i wprowadź nazwę tabeli.
Uwaga
Nazwy tabel mogą zawierać maksymalnie 1024 znaki, w tym spacje, znaki alfanumeryczne, łączniki i podkreślenia. Znaki specjalne nie są obsługiwane.
Przeciągnij pliki do okna lub wybierz pozycję Przeglądaj w poszukiwaniu plików.
Uwaga
Można dodać maksymalnie 1000 plików. Każdy plik może być maksymalnie 1 GB nieskompresowany.
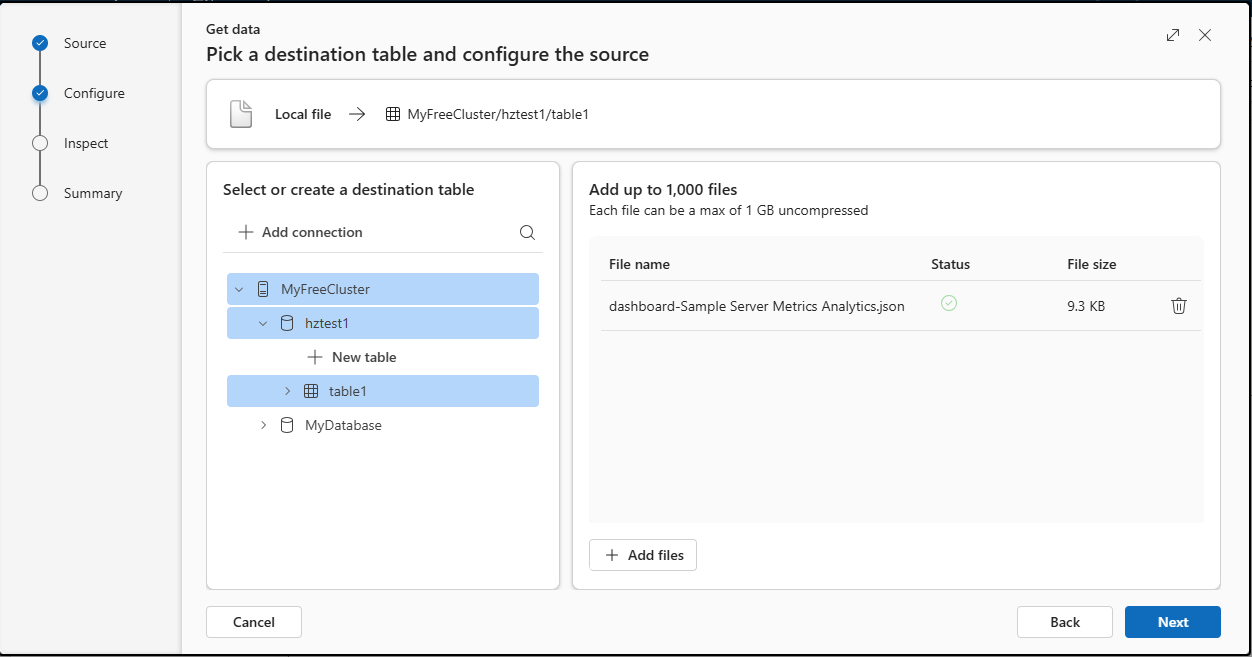
Wybierz Dalej.

Kontrola
Karta Inspekcja zostanie otwarta z podglądem danych.
Aby ukończyć proces pozyskiwania, wybierz pozycję Zakończ.

Opcjonalnie:
- Zmień automatycznie wnioskowany format danych, wybierając żądany format z listy rozwijanej. Aby uzyskać informacje na temat pozyskiwania, zobacz Formaty danych obsługiwane przez usługę Azure Data Explorer.
- Edytuj kolumny.
- Zapoznaj się z opcjami zaawansowanymi na podstawie typu danych.
Edytuj kolumny
Uwaga
- W przypadku formatów tabelarycznych (CSV, TSV, PSV) nie można dwukrotnie mapować kolumny. Aby zamapować na istniejącą kolumnę, najpierw usuń nową kolumnę.
- Nie można zmienić istniejącego typu kolumny. Jeśli spróbujesz mapować kolumnę na inny format, może się okazać, że kolumny będą puste.
Zmiany, które można wprowadzić w tabeli, zależą od następujących parametrów:
- Typ tabeli jest nowy lub istniejący
- Typ mapowania to nowy lub istniejący
| Typ tabeli | Typ mapowania | Dostępne korekty |
|---|---|---|
| Nowa tabela | Nowe mapowanie | Zmienianie nazwy kolumny, zmienianie typu danych, zmienianie źródła danych, przekształcanie mapowania, dodawanie kolumny, usuwanie kolumny |
| Istniejąca tabela | Nowe mapowanie | Dodaj kolumnę (na której można następnie zmienić typ danych, zmienić nazwę i zaktualizować) |
| Istniejąca tabela | Istniejące mapowanie | Brak |

Przekształcenia mapowania
Niektóre mapowania formatów danych (Parquet, JSON i Avro) obsługują proste przekształcenia czasu pozyskiwania. Aby zastosować przekształcenia mapowania, utwórz lub zaktualizuj kolumnę w oknie Edytowanie kolumn .
Przekształcenia mapowania można wykonać na kolumnie typu ciąg lub data/godzina, a źródło ma typ danych int lub long. Obsługiwane przekształcenia mapowania to:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opcje zaawansowane oparte na typie danych
Tabelaryczny (CSV, TSV, PSV):
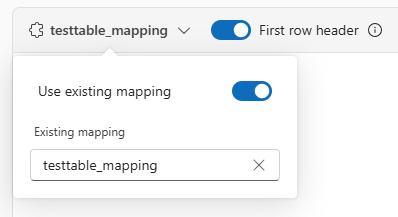
Jeśli pozyskujesz formaty tabelaryczne w istniejącej tabeli, możesz wybrać z listy rozwijanej mapowanie tabeli i wybrać pozycję Użyj istniejącego mapowania. Dane tabelaryczne nie muszą zawierać nazw kolumn używanych do mapowania danych źródłowych na istniejące kolumny. Po zaznaczeniu tej opcji mapowanie odbywa się według kolejności, a schemat tabeli pozostaje taki sam.
W przeciwnym razie utwórz nowe mapowanie.
Aby użyć pierwszego wiersza jako nazw kolumn, wybierz pozycję Nagłówek pierwszego wiersza.
JSON:
- Aby określić podział kolumn danych JSON, wybierz Poziomy zagnieżdżenia, które mogą być w zakresie od 1 do 100.
Podsumowanie
W oknie Przygotowywanie danych wszystkie trzy kroki pokazują zielone znaczniki wyboru po pomyślnym zakończeniu pozyskiwania danych. Możesz wyświetlić polecenia używane przez każdy krok lub wybrać kartę do wykonywania zapytań, wizualizowania lub porzucania pozyskanych danych.
