Jak pozyskiwać dane historyczne do usługi Azure Data Explorer
Typowym scenariuszem podczas dołączania do usługi Azure Data Explorer jest pozyskiwanie danych historycznych, czasami nazywane wypełnieniem. Proces obejmuje pozyskiwanie danych z istniejącego systemu magazynu do tabeli, która jest kolekcją zakresów.
Zalecamy pozyskiwanie danych historycznych przy użyciu właściwości pozyskiwania creationTime , aby ustawić czas tworzenia zakresów do momentu utworzenia danych. Użycie czasu tworzenia jako kryterium partycjonowania pozyskiwania może starzeć dane zgodnie z zasadami pamięci podręcznej i przechowywania oraz zwiększyć wydajność filtrów czasu.
Domyślnie czas tworzenia zakresów jest ustawiany na czas pozyskiwania danych, co może nie spowodować oczekiwanego zachowania. Załóżmy na przykład, że masz tabelę z okresem pamięci podręcznej 30 dni i okresem przechowywania w ciągu dwóch lat. W normalnym przepływie dane pozyskane w miarę ich produkcji są buforowane przez 30 dni, a następnie przenoszone do magazynu zimnego. Po dwóch latach, na podstawie czasu tworzenia, starsze dane są usuwane jeden dzień naraz. Jednak w przypadku pozyskiwania dwóch lat danych historycznych, w których domyślnie dane są oznaczone czasem tworzenia, gdy dane są pozyskiwane. Może to nie wygenerować żądanego wyniku, ponieważ:
- Wszystkie dane ląduje w pamięci podręcznej i pozostają tam przez 30 dni, korzystając z większej ilości pamięci podręcznej niż oczekiwano.
- Starsze dane nie są usuwane jeden dzień naraz; w związku z tym dane są przechowywane w klastrze dłużej niż jest to konieczne, a po dwóch latach wszystkie są usuwane jednocześnie.
- Dane, wcześniej pogrupowane według daty w systemie źródłowym, mogą być teraz wsadowe w tym samym zakresie, co prowadzi do nieefektywnych zapytań.

Z tego artykułu dowiesz się, jak partycjonować dane historyczne:
Używanie właściwości pozyskiwania podczas pozyskiwania
creationTime(zalecane)Jeśli to możliwe, pozyskiwanie danych historycznych przy użyciu
creationTimewłaściwości pozyskiwania, która umożliwia ustawienie czasu tworzenia zakresów przez wyodrębnienie ich ze ścieżki pliku lub obiektu blob. Jeśli struktura folderów nie używa wzorca daty utworzenia, zalecamy przeprowadzenie restrukturyzacji pliku lub ścieżki obiektu blob w celu odzwierciedlenia czasu utworzenia. Za pomocą tej metody dane są pozyskiwane do tabeli z poprawnym czasem tworzenia, a okresy przechowywania i pamięci podręcznej są stosowane poprawnie.Uwaga
Domyślnie zakresy są partycjonowane według czasu tworzenia (pozyskiwania) i w większości przypadków nie ma potrzeby ustawiania zasad partycjonowania danych.
Używanie zasad partycjonowania po pozyskiwaniu
Jeśli nie możesz użyć
creationTimewłaściwości pozyskiwania, na przykład w przypadku pozyskiwania danych przy użyciu łącznika usługi Azure Cosmos DB , w którym nie możesz kontrolować czasu tworzenia lub jeśli nie możesz ponownie restrukturyzacji struktury folderów, możesz ponownie podzielić tabelę po pozyskiwaniu, aby osiągnąć ten sam efekt przy użyciu zasad partycjonowania. Jednak ta metoda może wymagać pewnej próby i błędu w celu zoptymalizowania właściwości zasad i jest mniej wydajna niż użycie właściwości pozyskiwaniacreationTime. Ta metoda jest zalecana tylko wtedy, gdy użycie właściwości pozyskiwaniacreationTimenie jest możliwe.
Wymagania wstępne
- Konto Microsoft lub tożsamość użytkownika Microsoft Entra. Subskrypcja platformy Azure nie jest wymagana.
- Baza danych i klaster usługi Azure Data Explorer. Utwórz klaster i bazę danych.
- Konto magazynu.
- Aby uzyskać zalecaną metodę używania właściwości pozyskiwania podczas pozyskiwania
creationTime, zainstaluj program LightIngest.
Pozyskiwanie danych historycznych
Zdecydowanie zalecamy partycjonowanie danych historycznych przy użyciu właściwości pozyskiwania creationTime podczas pozyskiwania. Jeśli jednak nie możesz użyć tej metody, możesz ponownie podzielić tabelę po pozyskiwaniu przy użyciu zasad partycjonowania.
LightIngest może być przydatne do ładowania danych historycznych z istniejącego systemu magazynu do usługi Azure Data Explorer. Chociaż możesz utworzyć własne polecenie przy użyciu listy argumentów wiersza polecenia, w tym artykule pokazano, jak automatycznie wygenerować to polecenie za pomocą kreatora pozyskiwania. Oprócz tworzenia polecenia można użyć tego procesu, aby utworzyć nową tabelę i utworzyć mapowanie schematu. To narzędzie wywnioskuje mapowanie schematu z zestawu danych.
Element docelowy
W internetowym interfejsie użytkownika usługi Azure Data Explorer z menu po lewej stronie wybierz pozycję Zapytanie.
Kliknij prawym przyciskiem myszy bazę danych, w której chcesz pozyskać dane, a następnie wybierz pozycję LightIngest.
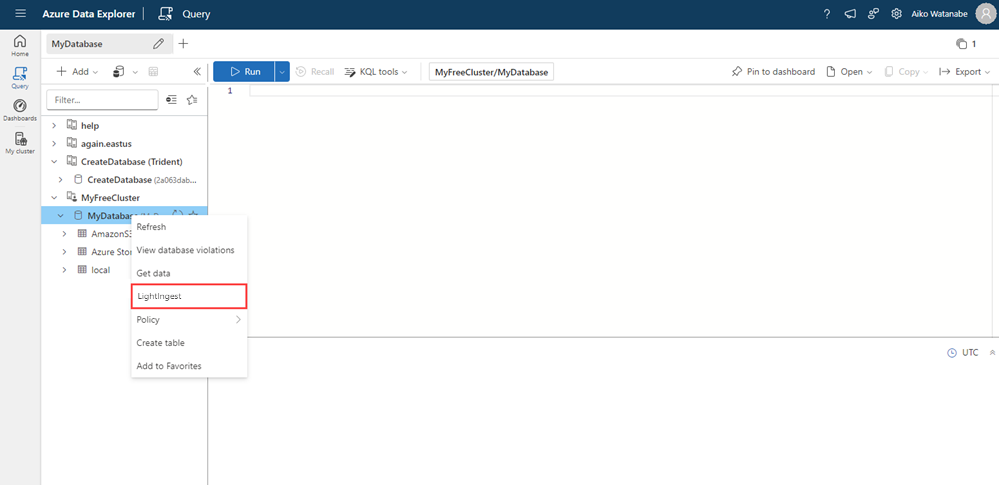
Zostanie otwarte okno Pozyskiwanie danych z wybraną kartą Miejsce docelowe . Pola Klaster i Baza danych są wypełniane automatycznie.
Wybierz tabelę docelową. Jeśli chcesz pozyskać dane do nowej tabeli, wybierz pozycję Nowa tabela, a następnie wprowadź nazwę tabeli.
Uwaga
Nazwy tabel mogą zawierać maksymalnie 1024 znaki, w tym spacje, alfanumeryczne, łączniki i podkreślenia. Znaki specjalne nie są obsługiwane.
Wybierz pozycję Dalej: Źródło.

Source
W obszarze Wybierz źródło wybierz pozycję Dodaj adres URL lub Wybierz kontener.
Podczas dodawania adresu URL w obszarze Link do źródła określ klucz konta lub adres URL sygnatury dostępu współdzielonego do kontenera. Adres URL sygnatury dostępu współdzielonego można utworzyć ręcznie lub automatycznie.
Podczas wybierania kontenera z konta magazynu wybierz subskrypcję magazynu, konto magazynu i kontener z menu rozwijanych.

Uwaga
Maksymalny rozmiar pliku obsługiwany w pozyskiwaniu wynosi 6 GB. Zaleceniem jest pozyskiwanie plików z zakresu od 100 MB do 1 GB.
Wybierz pozycję Ustawienia zaawansowane , aby zdefiniować dodatkowe ustawienia procesu pozyskiwania przy użyciu funkcji LightIngest.

W okienku Konfiguracja zaawansowana zdefiniuj ustawienia LightIngest zgodnie z poniższą tabelą.
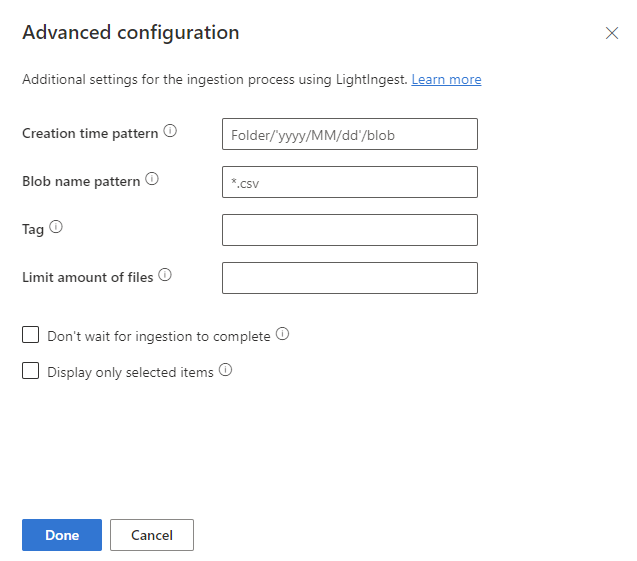
Właściwość Opis Wzorzec czasu tworzenia Określ, aby zastąpić właściwość czasu pozyskiwania utworzonego zakresu wzorcem, na przykład, aby zastosować datę na podstawie struktury folderów kontenera. Zobacz również Wzorzec czasu tworzenia. Wzorzec nazwy obiektu blob Określ wzorzec używany do identyfikowania plików do pozyskiwania. Pozyskiwanie wszystkich plików pasujących do wzorca nazwy obiektu blob w danym kontenerze. Obsługuje symbole wieloznaczne. Zalecamy ujęcie w cudzysłów podwójnych. Tag Tag przypisany do pozyskanych danych. Tag może być dowolnym ciągiem. Ogranicz ilość plików Określ liczbę plików, które można pozyskać. Pozyskiwanie pierwszych nplików pasujących do wzorca nazwy obiektu blob do określonej liczby.Nie czekaj na zakończenie pozyskiwania Jeśli jest ustawiona, kolejkuje obiekty blob na potrzeby pozyskiwania bez monitorowania procesu pozyskiwania. Jeśli nie zostanie ustawiona, lightIngest będzie nadal sondować stan pozyskiwania do momentu zakończenia pozyskiwania. Wyświetlanie tylko wybranych elementów Wyświetl listę plików w kontenerze, ale nie pozyskuje ich. Wybierz pozycję Gotowe , aby powrócić do karty Źródło .
Opcjonalnie wybierz pozycję Filtry plików , aby filtrować dane w celu pozyskiwania tylko plików w określonej ścieżce folderu lub za pomocą określonego rozszerzenia pliku.

Domyślnie jeden z plików w kontenerze jest losowo wybierany i używany do generowania schematu dla tabeli.
Opcjonalnie w obszarze Plik definiujący schemat można określić plik do użycia.
Wybierz pozycję Dalej: Schemat , aby wyświetlić i edytować konfigurację kolumny tabeli.
Schemat
Karta schematu zawiera podgląd danych.
Aby wygenerować polecenie LightIngest, wybierz pozycję Dalej: Rozpocznij pozyskiwanie.
Opcjonalnie:
- Zmień automatycznie wnioskowany format danych , wybierając żądany format z menu rozwijanego.
- Zmień automatycznie wnioskowaną nazwę mapowania. Można użyć znaków alfanumerycznych i podkreśleń. Spacje, znaki specjalne i łączniki nie są obsługiwane.
- W przypadku korzystania z istniejącej tabeli można zachować bieżący schemat tabeli , jeśli schemat tabeli jest zgodny z wybranym formatem.
- Wybierz pozycję Przeglądarka poleceń , aby wyświetlić i skopiować automatyczne polecenia wygenerowane na podstawie danych wejściowych.
- Edytuj kolumny. W obszarze Podgląd częściowych danych wybierz menu rozwijane kolumn, aby zmienić różne aspekty tabeli.
Zmiany, które można wprowadzić w tabeli, zależą od następujących parametrów:
- Typ tabeli jest nowy lub istniejący
- Typ mapowania jest nowy lub istniejący
| Typ tabeli | Typ mapowania | Dostępne korekty |
|---|---|---|
| Nowa tabela | Nowe mapowanie | Zmień typ danych, Zmień nazwę kolumny, Nowa kolumna, Usuń kolumnę, Aktualizuj kolumnę, Sortuj rosnąco, Sortuj malejąco |
| Istniejąca tabela | Nowe mapowanie | Nowa kolumna (na której można zmienić typ danych, zmienić nazwę i zaktualizować) Aktualizuj kolumnę, Sortuj rosnąco, Sortuj malejąco |
| Istniejące mapowanie | Sortuj rosnąco, Sortuj malejąco |
Uwaga
Podczas dodawania nowej kolumny lub aktualizowania kolumny można zmienić przekształcenia mapowania. Aby uzyskać więcej informacji, zobacz Przekształcenia mapowania
Pozyskiwanie
Gdy tabela, mapowanie i polecenie LightIngest zostaną oznaczone zielonymi znacznikami wyboru, wybierz ikonę kopiowania w prawym górnym rogu pola polecenia Wygenerowane , aby skopiować wygenerowane polecenie LightIngest.
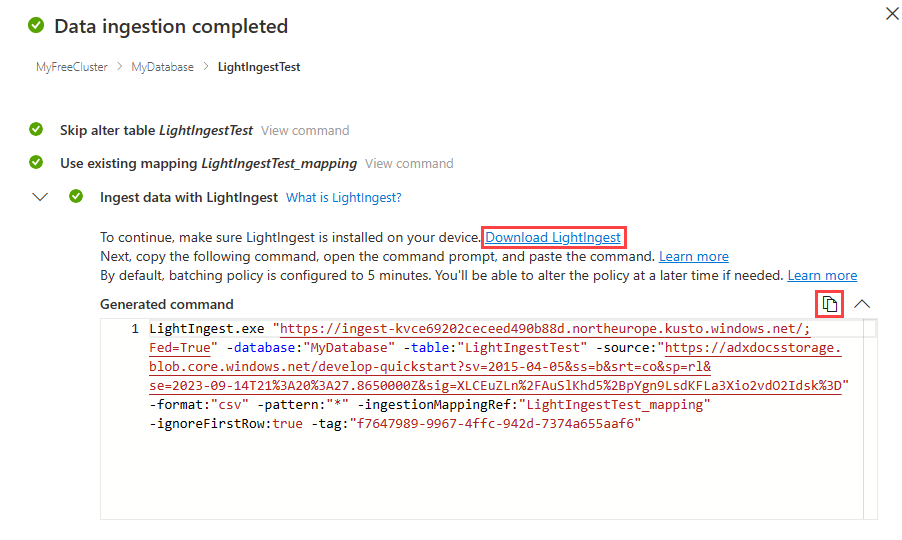
Uwaga
W razie potrzeby możesz pobrać narzędzie LightIngest, wybierając pozycję Pobierz lightingest.
Aby ukończyć proces pozyskiwania, należy uruchomić polecenie LightIngest przy użyciu skopiowanego polecenia.
