Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Apache Spark to ujednolicony aparat analityczny do przetwarzania danych na dużą skalę. Usługa Azure Data Explorer to szybka, w pełni zarządzana usługa do analizy danych, która pozwala w czasie rzeczywistym analizować duże woluminy danych.
Łącznik Kusto dla platformy Spark to projekt typu open source, który można uruchomić w dowolnym klastrze Spark. Implementuje źródło danych i odpływ danych do przenoszenia danych pomiędzy klastrami Azure Data Explorer i Spark. Korzystając z usług Azure Data Explorer i Apache Spark, można tworzyć szybkie i skalowalne aplikacje przeznaczone dla scenariuszy opartych na danych. Na przykład uczenie maszynowe (ML), wyodrębnianie i przekształcanie obciążenia (ETL) i usługa Log Analytics. Dzięki łącznikowi usługa Azure Data Explorer staje się prawidłowym magazynem danych dla standardowych operacji źródła i ujścia platformy Spark, takich jak write, readi writeStream.
Możesz zapisywać w usłudze Azure Data Explorer za pomocą ingestii kolejnej lub ingestii strumieniowej. Odczyt z usługi Azure Data Explorer obsługuje przycinanie kolumn i przesunięcie predykatu, które filtrują dane w Azure Data Explorer, redukując ilość przesyłanych danych.
Uwaga
Aby uzyskać informacje na temat pracy z łącznikiem usługi Synapse Spark dla usługi Azure Data Explorer, zobacz Nawiązywanie połączenia z usługą Azure Data Explorer przy użyciu platformy Apache Spark dla usługi Azure Synapse Analytics.
W tym artykule opisano sposób instalowania i konfigurowania łącznika Spark usługi Azure Data Explorer oraz przenoszenia danych między usługami Azure Data Explorer i Apache Spark.
Uwaga
Chociaż niektóre przykłady w tym artykule odnoszą się do klastra Spark Azure Databricks, łącznik Spark dla usługi Azure Data Explorer nie jest bezpośrednio zależny od Databricks ani żadnej innej dystrybucji Spark.
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz bezpłatne konto platformy Azure.
- Baza danych i klaster usługi Azure Data Explorer. Utwórz klaster i bazę danych.
- Klaster Spark
- Zainstaluj bibliotekę łącznika:
- Wstępnie utworzone biblioteki dla platformy Spark 2.4+Scala 2.11 lub Spark 3+scala 2.12
- Repozytorium Maven
- Zainstalowano program Maven 3.x
Napiwek
Obsługiwane są również wersje platformy Spark 2.3.x, ale może być konieczne zmianę niektórych zależności w pom.xml.
Jak utworzyć łącznik spark
Począwszy od wersji 2.3.0 wprowadzamy nowe identyfikatory artefaktów zastępujące łącznik spark-kusto-connector: kusto-spark_3.0_2.12 przeznaczone dla platform Spark 3.x i Scala 2.12.
Uwaga
Wersje wcześniejsze niż 2.5.1 przestały działać w przypadku przetwarzania do istniejącej tabeli, prosimy zaktualizować do nowszej wersji. To krok jest opcjonalny. Jeśli używasz wstępnie utworzonych bibliotek, na przykład narzędzia Maven, zobacz Konfigurowanie klastra Spark.
Wymagania wstępne procesu budowania
Zapoznaj się z tym źródłem w celu utworzenia łącznika Spark.
W przypadku aplikacji Scala/Java korzystających z definicji projektu Maven połącz aplikację z najnowszym artefaktem. Znajdź najnowszy artefakt w usłudze Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Jeśli nie korzystasz z gotowych bibliotek, musisz zainstalować biblioteki wymienione w zależnościach, w tym następujące biblioteki Kusto Java SDK. Aby znaleźć odpowiednią wersję do zainstalowania, zapoznaj się z odpowiednią wersją:
Aby skompilować plik jar i uruchomić wszystkie testy:
mvn clean package -DskipTestsAby skompilować plik jar, uruchom wszystkie testy i zainstaluj plik jar w lokalnym repozytorium Maven:
mvn clean install -DskipTests
Aby uzyskać więcej informacji, zobacz użycie łącznika.
Konfiguracja klastra Spark
Uwaga
Zaleca się użycie najnowszej wersji łącznika Kusto Spark podczas wykonywania poniższych kroków.
Skonfiguruj następujące ustawienia klastra Spark na podstawie klastra usługi Azure Databricks Spark 3.0.1 i Scala 2.12:
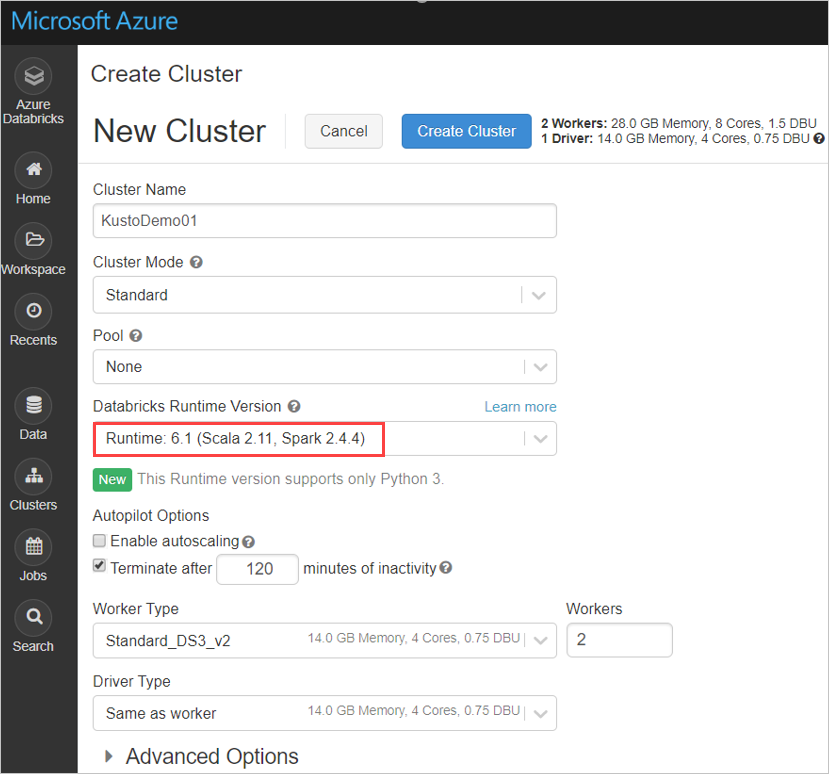
Zainstaluj najnowszą bibliotekę spark-kusto-connector z narzędzia Maven:
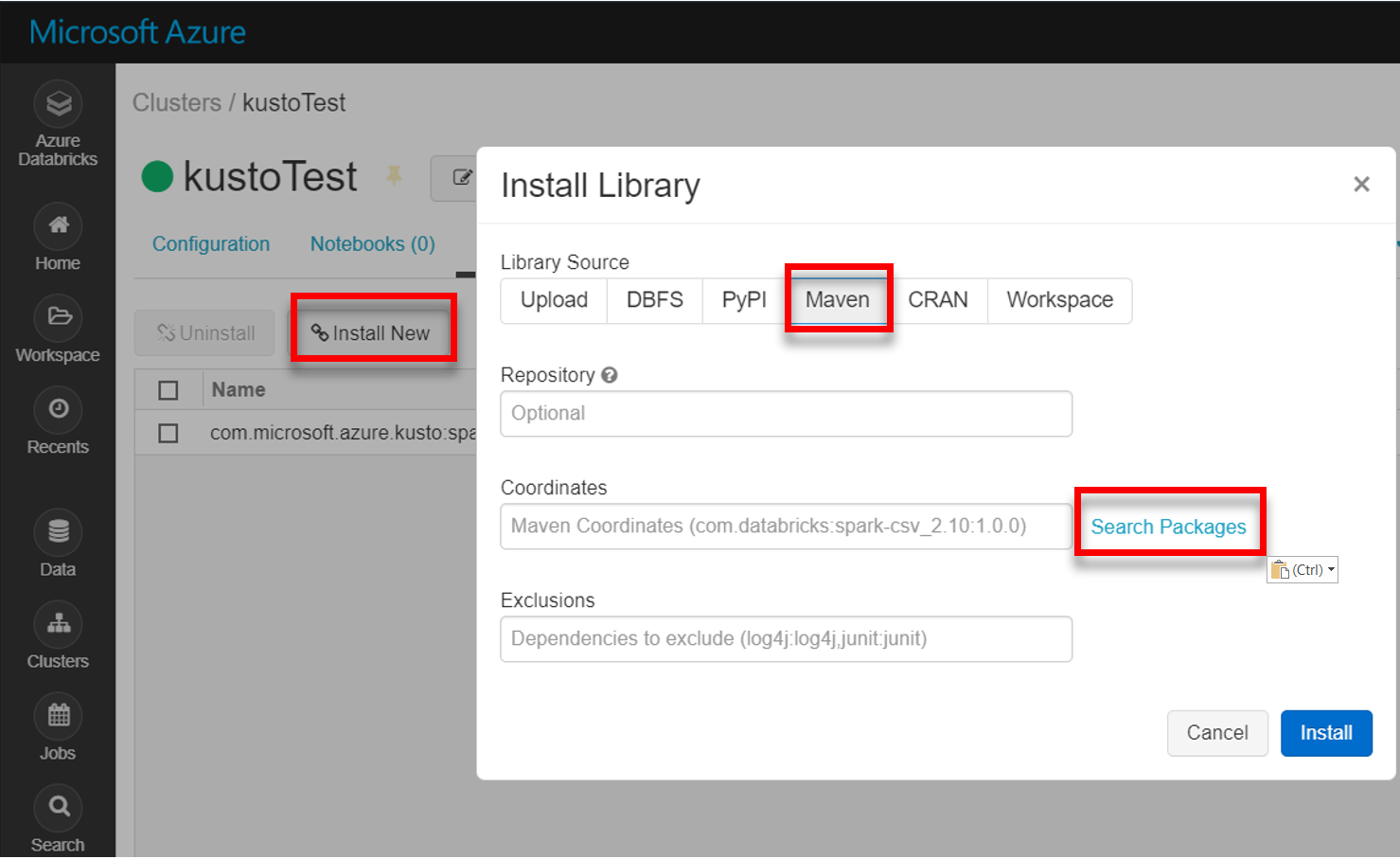
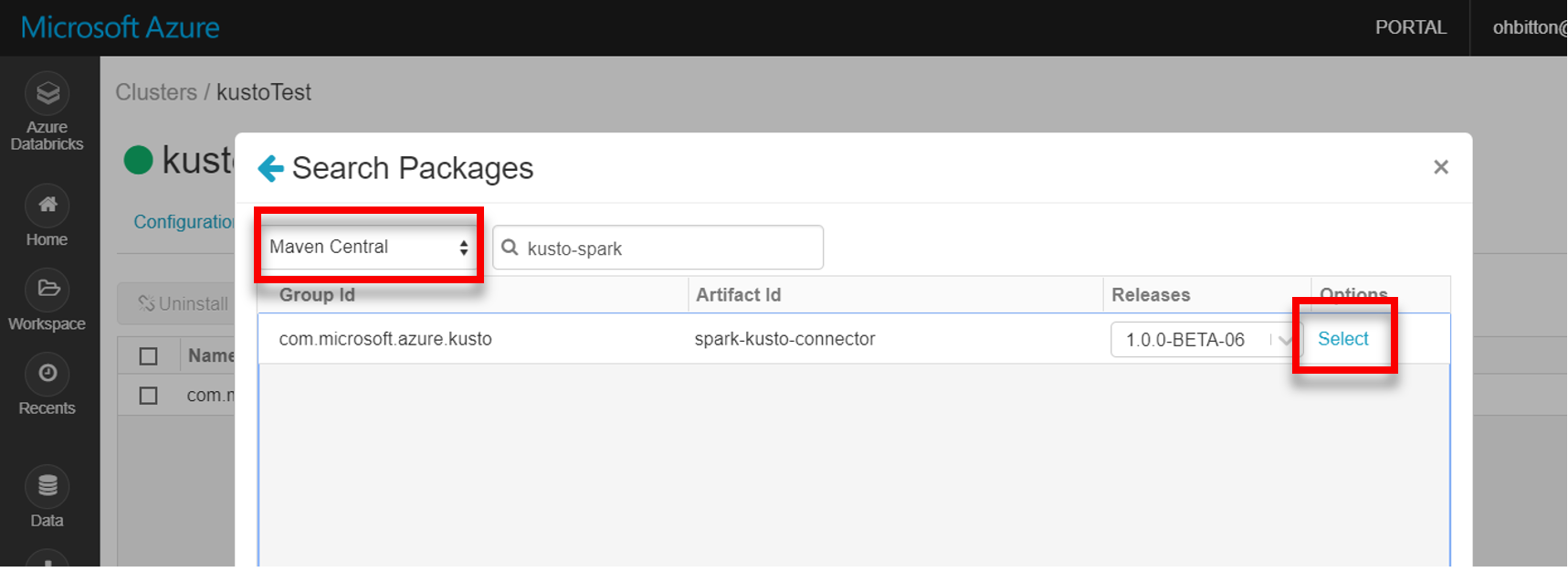
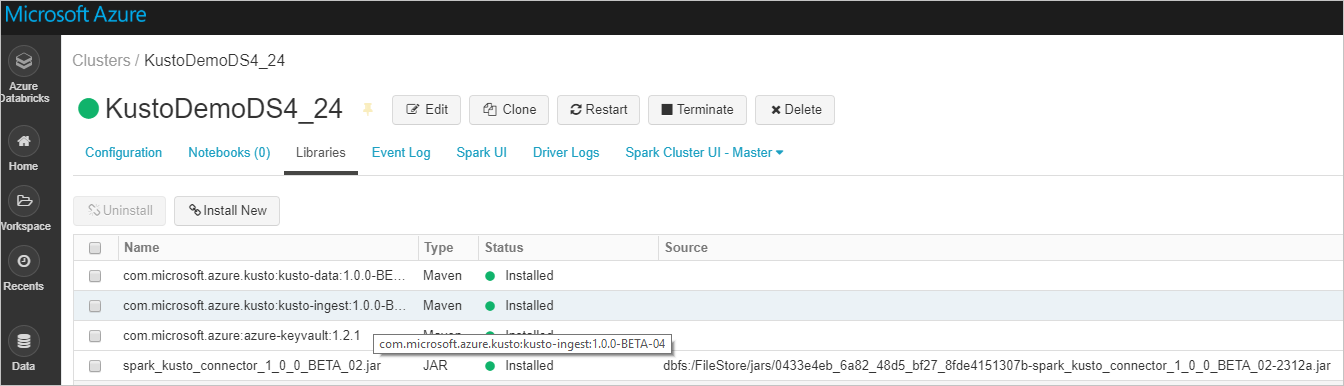
Sprawdź, czy wszystkie wymagane biblioteki są zainstalowane:
W przypadku instalacji przy użyciu pliku JAR sprawdź, czy zainstalowano inne zależności:
Uwierzytelnianie
Łącznik Kusto Spark umożliwia uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft przy użyciu jednej z następujących metod:
- Aplikacja Firmy Microsoft Entra
- Token dostępu Microsoft Entra
- Uwierzytelnianie urządzenia (w scenariuszach nieprodukcyjnych)
- Usługa Azure Key Vault Aby uzyskać dostęp do zasobu usługi Key Vault , zainstaluj pakiet azure-keyvault i podaj poświadczenia aplikacji.
Uwierzytelnianie aplikacji Microsoft Entra
Uwierzytelnianie aplikacji Microsoft Entra jest najprostszą i najbardziej typową metodą uwierzytelniania i jest zalecane dla łącznika Kusto Spark.
Zaloguj się do swojej subskrypcji platformy Azure za pomocą Azure CLI. Następnie uwierzytelnij się w przeglądarce.
az loginWybierz subskrypcję do hostowania głównego elementu. Ten krok jest wymagany, gdy masz wiele subskrypcji.
az account set --subscription YOUR_SUBSCRIPTION_GUIDUtwórz jednostkę usługi. W tym przykładzie zasadnicza usługa nosi nazwę
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Z zwróconych danych JSON skopiuj wartości
appId,passworditenantdo użycia w przyszłości.{ "appId": "00001111-aaaa-2222-bbbb-3333cccc4444", "displayName": "my-service-principal", "name": "my-service-principal", "password": "00001111-aaaa-2222-bbbb-3333cccc4444", "tenant": "00001111-aaaa-2222-bbbb-3333cccc4444" }
Utworzono aplikację Microsoft Entra i jednostkę usługi.
Łącznik platformy Spark używa następujących właściwości aplikacji Entra do uwierzytelniania:
| Właściwości | Opcjonalny ciąg znaków | opis |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Identyfikator aplikacji Microsoft Entra (klienta). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Urząd uwierzytelniania Firmy Microsoft Entra. Identyfikator katalogu Microsoft Entra (dzierżawa). Opcjonalne — domyślnie microsoft.com. Aby uzyskać więcej informacji, zobacz Microsoft Entra Authority. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Klucz aplikacji Entra firmy Microsoft dla klienta. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Jeśli masz już token accessToken, który został utworzony z dostępem do usługi Kusto, możesz go przekazać do łącznika w celu uwierzytelnienia. |
Uwaga
Starsze wersje interfejsu API (mniejsze niż 2.0.0) mają następujące nazwy: "kustoAADClientID", "kustoClientADClientPassword", "kustoAADAuthorityID"
Uprawnienia usługi Kusto
Przyznaj następujące uprawnienia po stronie Kusto w zależności od operacji Spark, którą chcesz wykonać.
| Operacja platformy Spark | Uprawnienia |
|---|---|
| Odczyt — tryb pojedynczy | Czytelnik |
| Odczyt — wymuś tryb rozproszony | Czytelnik |
| Zapis — tryb w kolejce z opcją utworzenia tabeli CreateTableIfNotExist | Administracja |
| Write – tryb kolejkowany z opcją tworzenia tabeli FailIfNotExist | Ingestor |
| Zapis — TransactionalMode | Administracja |
Aby uzyskać więcej informacji na temat ról głównych, zobacz Kontrola dostępu oparta na rolach. Aby zarządzać rolami zabezpieczeń, zobacz Zarządzanie rolami zabezpieczeń.
Docelowe miejsce dla danych Spark: zapisywanie w usłudze Kusto
Konfigurowanie parametrów ujścia:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Zapisz DataFrame platformy Spark w klastrze Kusto w trybie wsadowym.
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Możesz też użyć uproszczonej składni:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ // Optional, for any extra options: val conf: Map[String, String] = Map() val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Zapisywanie danych przesyłanych strumieniowo:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // As an alternative to adding .option by .option, you can provide a map: val conf: Map[String, String] = Map( KustoSinkOptions.KUSTO_CLUSTER -> cluster, KustoSinkOptions.KUSTO_TABLE -> table, KustoSinkOptions.KUSTO_DATABASE -> database, KustoSourceOptions.KUSTO_ACCESS_TOKEN -> accessToken) // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Źródło platformy Spark: odczytywanie z usługi Kusto
Podczas odczytywania małych ilości danych zdefiniuj zapytanie dotyczące danych:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Opcjonalnie: Jeśli podasz przejściowy magazyn obiektów blob (a nie Kusto), obiekty blob są tworzone na odpowiedzialność osoby wywołującej. Obejmuje to aprowizowanie magazynu, rotację kluczy dostępu i usuwanie przejściowych artefaktów. Moduł KustoBlobStorageUtils zawiera funkcje pomocnicze do usuwania obiektów blob na podstawie współrzędnych konta i kontenera oraz poświadczeń konta lub pełnego adresu URL sygnatury dostępu współdzielonego z uprawnieniami do zapisu, odczytu i listy. Gdy odpowiedni RDD nie jest już potrzebny, każda transakcja przechowuje tymczasowe artefakty blobów w osobnym katalogu. Ten katalog jest rejestrowany w postaci dzienników transakcji odczytu zapisywanych w węźle Sterownik platformy Spark.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")W powyższym przykładzie usługa Key Vault nie jest dostępna za pomocą interfejsu łącznika; używana jest prostsza metoda korzystania z sekretów usługi Databricks.
Przeczytaj z Kusto.
Jeśli podasz przejściowy magazyn obiektów blob, odczytuj dane z Kusto w następujący sposób:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Jeśli Kusto udostępnia przejściowy magazyn obiektów blob, odczytaj dane z Kusto w następujący sposób:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)