Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Przepływy danych są dostępne zarówno w potokach Azure Data Factory, jak i w potokach Azure Synapse Analytics. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz z przekształceń danych, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływów mapowania danych.
Wskazówka
Przekształcenie Alter Row nie jest obecnie obsługiwane w usłudze Dataflow Gen2. Aby uzyskać listę obsługiwanych przekształceń i ich odpowiedników, zobacz Przewodnik po przepływie danych Gen2 dla użytkowników przepływu danych mapowania.
Użyj przekształcenia Alter Row, aby ustawić zasady wstawiania, usuwania, aktualizowania i upsert w wierszach. Możesz dodawać wyrażenia jako warunki typu jeden-do-wielu. Te warunki należy określić w kolejności priorytetu, ponieważ każdy wiersz jest oznaczony zasadami odpowiadającymi wyrażeniu pierwszego dopasowania. Każdy z tych warunków może spowodować wstawienie, zaktualizowanie, usunięcie lub wstawienie lub aktualizację wiersza. Funkcja Alter Row umożliwia tworzenie akcji DDL i DML względem bazy danych.
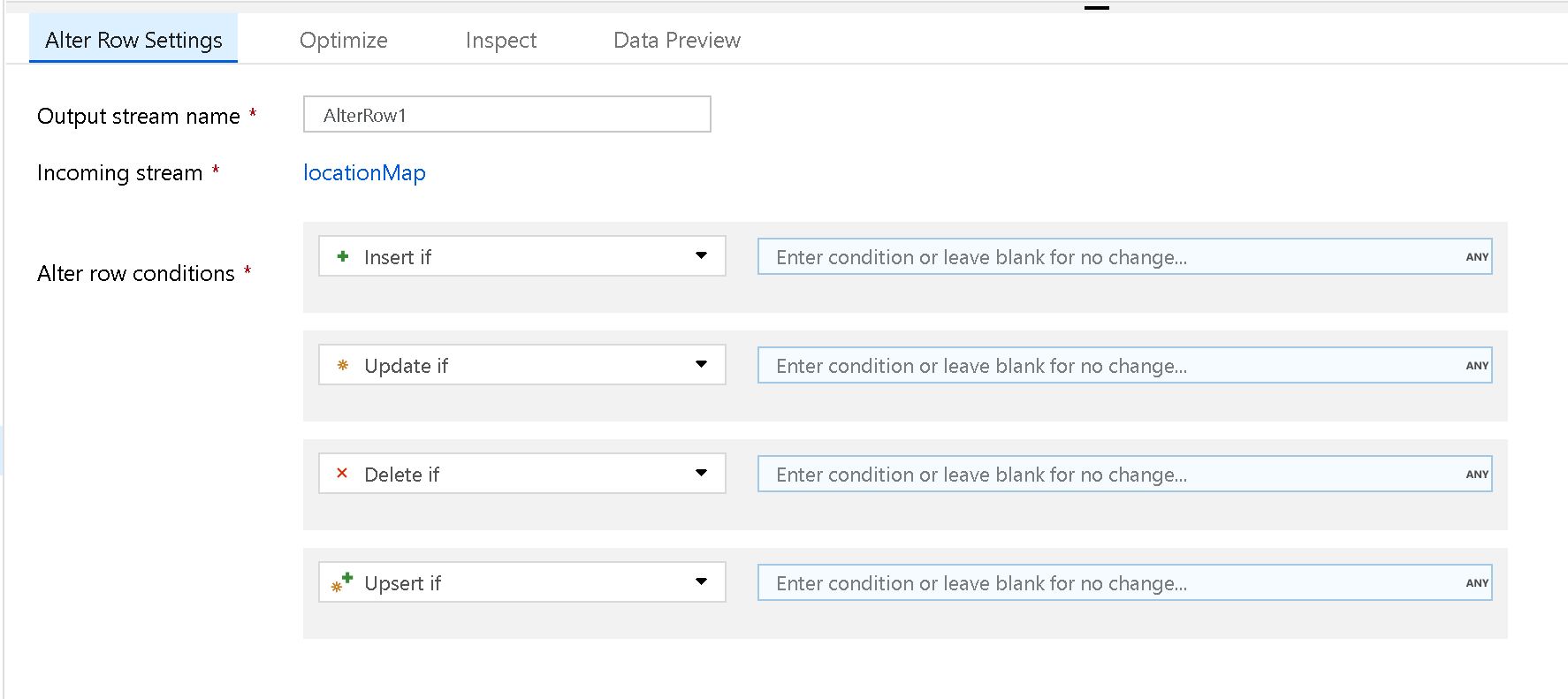
Przekształcenia typu alter Row działają tylko na bazach danych, REST lub Azure Cosmos DB jako miejscach docelowych w procesie przepływu danych. Akcje przypisywane do wierszy (wstawianie, aktualizowanie, usuwanie, upsert) nie są wykonywane podczas sesji debugowania. Aby wprowadzić zasady zmiany wierszy w tabelach bazy danych, uruchom działanie Execute Przepływ danych w potoku.
Uwaga
Przekształcenie alter row nie jest wymagane w przypadku przepływów danych przechwytywania zmiany danych, które używają natywnych źródeł CDC, takich jak SQL Server lub SAP. W takich przypadkach usługa ADF automatycznie wykryje znacznik wiersza, dzięki czemu zasady Alter Row stają się zbędne.
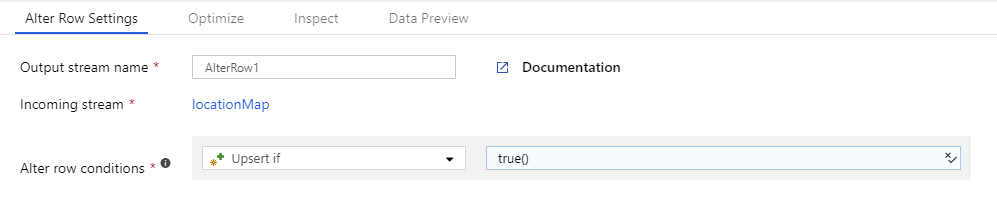
Określ domyślną zasadę wiersza
Utwórz przekształcenie Alter Row i określ politykę wierszy z warunkiem true(). Każdy wiersz, który nie pasuje do żadnego z wcześniej zdefiniowanych wyrażeń, jest oznaczony dla określonej polityki wiersza. Domyślnie każdy wiersz, który nie pasuje do żadnego wyrażenia warunkowego, jest oznaczony jako Insert.
Uwaga
Aby oznaczyć wszystkie wiersze za pomocą jednej zasady, możesz utworzyć warunek dla tych zasad i określić warunek jako true().
Wyświetlanie zasad w wersji zapoznawczej danych
Użyj trybu debugowania, aby wyświetlić wyniki zasad zmiany wiersza w okienku podglądu danych. Podgląd danych przekształcenia alter row nie generuje akcji DDL ani DML względem obiektu docelowego.
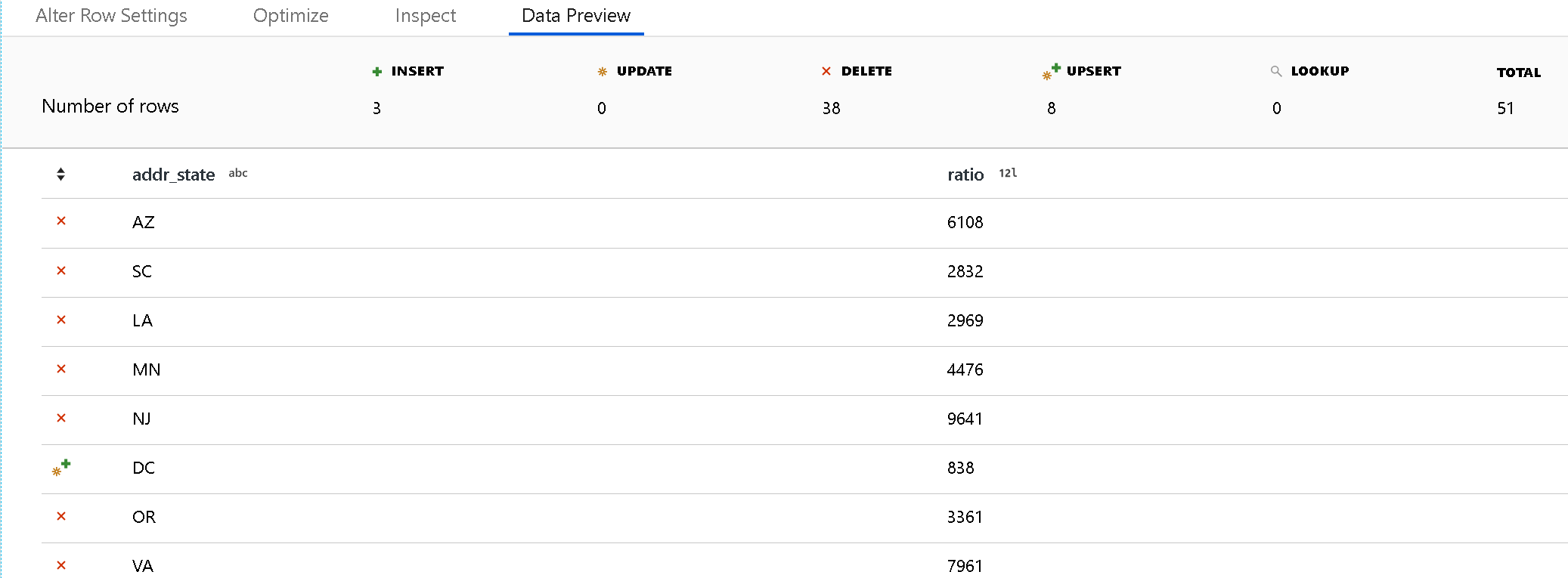
Ikona każdej zasady zmiany wiersza wskazuje, czy występuje akcja wstawiania, aktualizowania, upsert lub usuwania. Górny nagłówek pokazuje, ile wierszy ma wpływ na poszczególne zasady w wersji zapoznawczej.
Zezwalaj na zasady zmiany wierszy w miejscu docelowym
Aby zasady zmiany wierszy działały, strumień danych musi być zapisywany w bazie danych lub ujściu Azure Cosmos DB. Na karcie Ustawienia ujścia włącz dozwolone zasady zmiany wierszy dla tego ujścia.
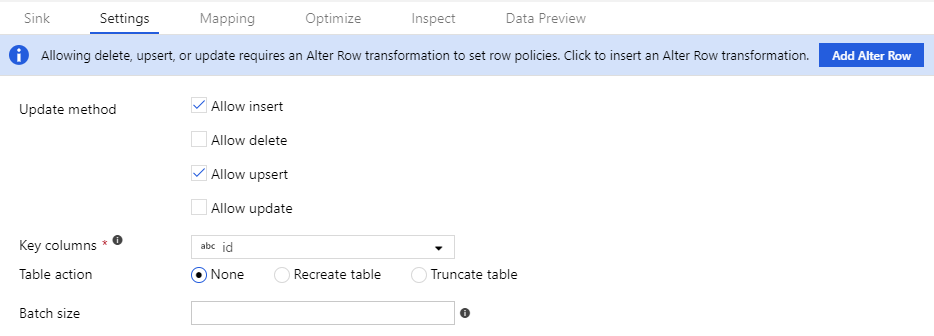
Domyślne zachowanie polega na zezwalaniu tylko na wstawianie. Aby zezwolić na aktualizacje, upserts lub deletes, zaznacz pole wyboru w ujściu odpowiadającym temu warunku. W przypadku włączenia aktualizacji, operacji upsert lub usunięcia należy określić kolumny kluczy w ujściu, które mają być zgodne.
Uwaga
Jeśli wstawienia, aktualizacje lub upserty modyfikują schemat tabeli docelowej w wyniku, przepływ danych nie powiedzie się. Aby zmodyfikować schemat docelowy w bazie danych, wybierz pozycję Utwórz ponownie tabelę jako akcję tabeli. Spowoduje to usunięcie i ponowne utworzenie tabeli przy użyciu nowej definicji schematu.
Transformacja sink wymaga pojedynczego klucza lub zestawu kluczy do unikatowej identyfikacji wierszy w docelowej bazie danych. W przypadku ujścia SQL ustaw klucze na karcie ustawienia ujścia. W przypadku Azure Cosmos DB ustaw klucz partycji w ustawieniach, a także ustaw pole systemowe Azure Cosmos DB "ID" w mapowaniu ujścia. W przypadku Azure Cosmos DB obowiązkowe jest dołączenie kolumny systemowej "ID" dla aktualizacji, operacji upsert i usuwania.
Scalanie i upsery z Azure SQL Database i Azure Synapse
Przepływy danych obsługują scalanie z Azure SQL Database i Azure Synapse pulą baz danych (magazyn danych) z opcją upsert.
Można jednak napotkać scenariusze, w których docelowy schemat bazy danych wykorzystał właściwość tożsamości kolumn kluczy. Aby skorzystać z usługi, musisz zidentyfikować klucze, które używasz do dopasowywania wartości wierszy dla aktualizacji i operacji upsert. Jeśli jednak kolumna docelowa ma ustawioną właściwość tożsamości i używasz zasad upsert, docelowa baza danych nie zezwala na zapisywanie w kolumnie. Przy próbie wykonania operacji upsert na kolumnie dystrybucji tabeli rozproszonej mogą również wystąpić błędy.
Oto sposoby rozwiązania tego problemu:
Przejdź do opcji transformacji "Sink" i ustaw "Pomiń zapisywanie kolumn kluczy". Informuje to, że usługa nie zapisuje kolumny wybranej jako wartość klucza dla mapowania.
Jeśli ta kolumna klucza nie jest kolumną, która powoduje problem z kolumnami tożsamości, możesz użyć opcji Przetwarzanie Wstępne SQL w przekształceniu sink:
SET IDENTITY_INSERT tbl_content ON. Następnie wyłącz tę funkcję za pomocą właściwości SQL dotyczącej post-processingu:SET IDENTITY_INSERT tbl_content OFF.W przypadku zarówno przypadku tożsamości, jak i przypadku kolumny dystrybucji można przełączyć logikę z upsert na użycie oddzielnego warunku aktualizacji i oddzielnego warunku wstawiania przy użyciu przekształcenia podziału warunkowego. W ten sposób można ustawić mapowanie na ścieżce aktualizacji tak, aby zignorować mapowanie kolumny kluczowej.
Skrypt przepływu danych
Składnia
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
Przykład
W poniższym przykładzie przedstawiono przekształcenie alter row o nazwie CleanData, które pobiera strumień SpecifyUpsertConditions przychodzący i tworzy trzy warunki modyfikacji wiersza. W poprzedniej transformacji kolumna o nazwie alterRowCondition jest obliczana, która określa, czy wiersz jest wstawiany, aktualizowany lub usuwany w bazie danych. Jeśli wartość kolumny ma wartość ciągu zgodną z regułą zmiany wiersza, przypisywana jest ta zasada.
W interfejsie użytkownika ta transformacja wygląda jak na poniższej ilustracji:
Skrypt przepływu danych dla tej transformacji znajduje się w poniższym fragmencie kodu:
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
Powiązana zawartość
Po przekształceniu transformaty Alter Row możesz chcieć zapisać dane do docelowego magazynu danych.