Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Przepływy danych są dostępne zarówno w potokach usługi Azure Data Factory, jak i w potokach usługi Azure Synapse Analytics. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz przekształcanie danych, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływów danych mapowania.
Po zakończeniu przekształcania danych zapisz je w magazynie docelowym przy użyciu transformacji typu 'sink'. Każdy przepływ danych wymaga co najmniej jednej transformacji do ujścia, ale można zapisywać do tylu ujść, ile potrzeba, aby ukończyć przepływ transformacji. Aby zapisywać do dodatkowych ujść, utwórz nowe strumienie przez nowe gałęzie i rozdziały warunkowe.
Każda transformacja ujściowa jest skojarzona z dokładnie jednym obiektem zestawu danych lub połączoną usługą. Transformacja zlewu określa kształt i lokalizację danych, które chcesz zapisać.
Wbudowane zestawy danych
Podczas tworzenia przekształcenia ujścia wybierz, czy informacje ujścia są zdefiniowane wewnątrz obiektu zestawu danych, czy w ramach przekształcenia ujścia. Większość formatów jest dostępna tylko w jednym lub drugim. Aby dowiedzieć się, jak używać określonego łącznika, zobacz odpowiedni dokument łącznika.
Jeśli format jest obsługiwany zarówno w tekście, jak i w obiekcie zestawu danych, istnieją korzyści dla obu tych elementów. Obiekty zestawu danych to jednostki wielokrotnego użytku, które mogą być używane w innych przepływach danych i działaniach, takich jak Kopiowanie. Te jednostki wielokrotnego użytku są szczególnie przydatne przy korzystaniu ze schematu o wzmocnionej strukturze. Zestawy danych nie są oparte na platformie Spark. Czasami może być konieczne nadpisanie niektórych ustawień lub projekcji schematu w transformacji wyjściowej.
Zaleca się używanie zestawów danych wbudowanych, gdy korzystamy z elastycznych schematów, jednorazowych instancji odbiorników lub parametryzowanych odbiorników. Jeśli ujście jest silnie sparametryzowane, wbudowane zestawy danych umożliwiają nie tworzenie obiektu "fikcyjnego". Wbudowane zestawy danych są oparte na platformie Spark, a ich właściwości są natywne dla przepływu danych.
Aby użyć wbudowanego zestawu danych, wybierz odpowiedni format w selektorze typu ujścia. Zamiast wybierać zestaw danych ujścia, należy wybrać połączoną usługę, z którą chcesz nawiązać połączenie.
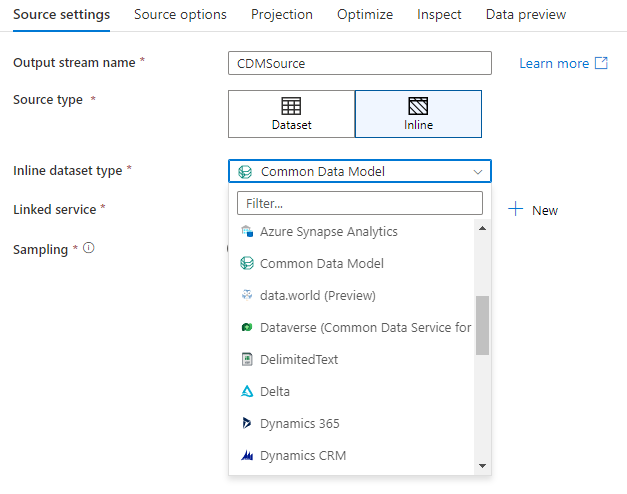
Baza danych obszaru roboczego (tylko obszary robocze Synapse)
W przypadku korzystania z przepływów danych w obszarach roboczych usługi Azure Synapse będziesz mieć dodatkową opcję ujścia danych bezpośrednio do typu bazy danych, który znajduje się w obszarze roboczym usługi Synapse. Spowoduje to złagodzenie potrzeby dodawania połączonych usług lub zestawów danych dla tych baz danych. Bazy danych utworzone za pośrednictwem szablonów baz danych usługi Azure Synapse są również dostępne po wybraniu pozycji Baza danych obszaru roboczego.
Uwaga
Łącznik usługi Azure Synapse Workspace DB jest obecnie w publicznej wersji zapoznawczej i może obecnie pracować tylko z bazami danych Spark Lake
Obsługiwane typy ujścia
Przepływ danych mapowania jest zgodny z podejściem wyodrębniania, ładowania i przekształcania (ELT) i współpracuje z przejściowymi zestawami danych, które znajdują się na platformie Azure. Obecnie następujące zestawy danych mogą być używane w transformacji danych wyjściowych.
Napiwek
Odbiornik może mieć inny format niż źródło. Jest to jeden z kroków przekształcenia jednego formatu na inny. Na przykład z formatu CSV do formatu Parquet. Może być konieczne wprowadzenie pewnych przekształceń w przepływie danych między źródłem i ujściem, aby działało poprawnie. (Na przykład Parquet ma bardziej szczegółowe wymagania nagłówka niż CSV).
| Łącznik | Formatuj | Zestaw danych/wbudowany |
|---|---|---|
| Azure Blob Storage |
Avro Tekst rozdzielany znakami Delta JSON ORK Parkiet |
✓/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Cosmos DB for NoSQL | ✓/- | |
| Usługa Azure Data Lake Storage 1. generacji |
Avro Tekst rozdzielany znakami JSON ORK Parkiet |
✓/- ✓/- ✓/- ✓/✓ ✓/- |
| Azure Data Lake Storage Gen2 |
Avro Wspólny Model Danych Tekst rozdzielany znakami Delta JSON ORK Parkiet |
✓/✓ -/✓ ✓/✓ -/✓ ✓/✓ ✓/✓ ✓/✓ |
| Azure Database for MySQL | ✓/✓ | |
| Azure Database for PostgreSQL | ✓/✓ | |
| Azure Data Explorer | ✓/✓ | |
| Azure SQL Database | ✓/✓ | |
| Wystąpienie zarządzane Azure SQL | ✓/- | |
| Azure Synapse Analytics | ✓/- | |
| Usługa Dataverse | ✓/✓ | |
| Dynamics 365 | ✓/✓ | |
| Dynamics CRM | ✓/✓ | |
| Platforma Lakehouse | ✓/✓ | |
| Protokół SFTP |
Avro Tekst rozdzielany znakami JSON ORK Parkiet |
✓/✓ ✓/✓ ✓/✓ ✓/✓ ✓/✓ |
| Płatek śniegu | ✓/✓ | |
| SQL Server | ✓/✓ |
Ustawienia specyficzne dla tych łączników znajdują się na karcie Ustawienia . Przykłady skryptów przepływu informacji i danych znajdują się w dokumentacji łącznika.
Usługa ma dostęp do ponad 90 łączników natywnych. Aby zapisać dane w innych źródłach z przepływu danych, użyj działania kopiowania, aby załadować te dane z obsługiwanego ujścia.
Ustawienia ujścia
Po dodaniu ujścia skonfiguruj za pomocą karty Ujście . W tym miejscu możesz wybrać lub utworzyć zestaw danych, do którego zapisuje ujście. Wartości programistyczne parametrów zestawu danych można skonfigurować w ustawieniach debugowania. (Tryb debugowania musi być włączony).
W poniższym filmie wideo wyjaśniono wiele różnych opcji ujścia dla typów plików rozdzielanych tekstem.
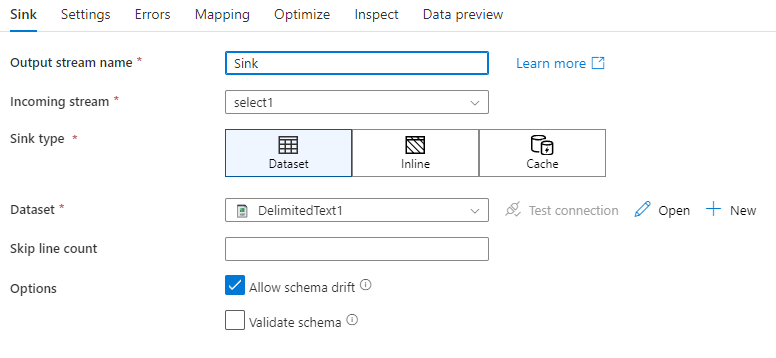
Dryf schematu: Dryf schematu to zdolność usługi do natywnego obsługiwania elastycznych schematów w przepływach danych bez konieczności jawnego definiowania zmian kolumn. Włącz opcję Zezwalaj na dryfowanie schematu, aby zapisywać dodatkowe kolumny poza tym, co jest zdefiniowane w schemacie danych docelowych.
Zweryfikuj schemat: Jeśli wybrano weryfikację schematu, przepływ danych zakończy się niepowodzeniem, jeśli którakolwiek kolumna w projekcji miejsca docelowego nie zostanie znaleziona w magazynie docelowym lub jeśli typy danych nie będą zgodne. Użyj tego ustawienia, aby wymusić, że schemat ujścia spełnia kontrakt zdefiniowanej projekcji. Jest to przydatne w scenariuszach ujścia bazy danych, aby zasygnalizować, że nazwy kolumn lub typy uległy zmianie.
Odbiornik pamięci podręcznej
Cache sink to sytuacja, gdy przepływ danych zapisuje informacje w pamięci podręcznej Spark zamiast w magazynie danych. Podczas mapowania przepływów danych można odwoływać się do tych danych w tym samym przepływie wiele razy przy użyciu wyszukiwania w pamięci podręcznej. Jest to przydatne, gdy chcesz odwoływać się do danych w ramach wyrażenia, ale nie chcesz jawnie łączyć do niej kolumn. Typowe przykłady, gdzie bufor pamięci podręcznej może pomóc, to wyszukiwanie maksymalnej wartości w bazie danych oraz dopasowywanie kodów błędów do bazy danych komunikatów o błędach.
Aby zapisać w wyjściu pamięci podręcznej, dodaj przekształcenie wyjścia i wybierz opcję Pamięć podręczna jako typ wyjścia. W przeciwieństwie do innych typów zlewów nie trzeba wybierać zestawu danych ani połączonej usługi, ponieważ nie zapisujesz danych w zewnętrznym magazynie.
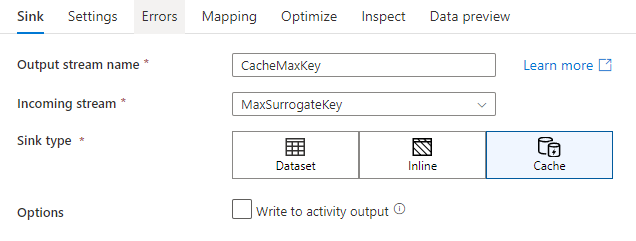
W ustawieniach ujścia można opcjonalnie określić kolumny kluczy ujścia pamięci podręcznej. Są one używane jako warunki dopasowania podczas korzystania z funkcji lookup() w wyszukiwaniu w pamięci podręcznej. Jeśli określisz kolumny kluczowe, nie możesz użyć funkcji outputs() w wyszukiwaniu pamięci podręcznej. Aby dowiedzieć się więcej na temat składni wyszukiwań w pamięci podręcznej, zobacz wyszukiwania w pamięci podręcznej.
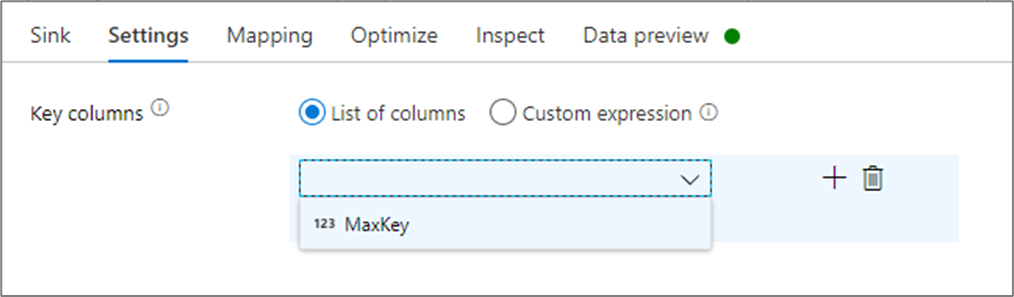
Na przykład, jeśli określę pojedynczą kolumnę klucza column1 w ujściu pamięci podręcznej o nazwie cacheExample, wywołanie cacheExample#lookup() zawierałoby jeden parametr określający, który wiersz w ujściu pamięci podręcznej ma być dopasowany. Funkcja generuje pojedynczą złożoną kolumnę z podkolumnami dla każdej zmapowanych kolumn.
Uwaga
Zasobnik pamięci podręcznej musi znajdować się w całkowicie niezależnym strumieniu danych od dowolnego przekształcenia odwołującego się do niego za pośrednictwem wyszukiwania w pamięci podręcznej. Ujście pamięci podręcznej musi być także pierwszym ujściem, które zostanie zapisane.
Zapisz w danych wyjściowych działania
Moduł pamięci podręcznej może opcjonalnie zapisywać swoje dane w danych wyjściowych działania Przepływu danych, które można następnie używać jako dane wejściowe innego działania w ramach potoku. Umożliwi to szybkie i łatwe przekazywanie danych w ramach działania przepływu danych bez konieczności utrwalania danych w bazie danych.
Należy pamiętać, że dane wyjściowe z Data Flow, które są wstrzykiwane bezpośrednio do potoku są ograniczone do 2 MB. W związku z tym Przepływ danych podejmie próbę dodania do danych wyjściowych tak wielu wierszy, jak to możliwe, pozostając w limicie 2 MB, dlatego czasami w danych wyjściowych czynności może się zdarzyć, że nie wszystkie wiersze będą widoczne. Ustawienie wartości "Tylko pierwszy wiersz" na poziomie działania Przepływ danych pomaga również ograniczyć dane wyjściowe z Przepływ danych w razie potrzeby.
Metoda aktualizacji
W przypadku typów ujścia bazy danych karta Ustawienia będzie zawierać właściwość "Metoda aktualizacji". Wartość domyślna to wstawianie, ale także opcje pola wyboru dla aktualizacji, operacji upsert i usuwania. Aby użyć tych dodatkowych opcji, należy dodać przekształcenie Alter Row przed mocowaniem. Alter Row umożliwia zdefiniowanie warunków dla każdej akcji bazy danych. Jeśli źródło jest natywnym źródłem obsługującym funkcję CDC, możesz ustawić metody aktualizacji bez zmiany wiersza, ponieważ Azure Data Factory (ADF) już zna znaczniki wierszy dla operacji wstawiania, aktualizacji, scalania i usuwania.
Mapowanie pól
Podobnie jak w przypadku przekształcenia wybierającego, na karcie Mapowanie miejsca docelowego możesz zdecydować, które kolumny przychodzące zostaną zapisane. Domyślnie wszystkie kolumny wejściowe, w tym kolumny dryfujące, są mapowane. To zachowanie jest nazywane automapowaniem.
Po wyłączeniu automatycznego mapowania można dodać stałe mapowania oparte na kolumnach lub mapowania oparte na regułach. Dzięki mapowaniom opartym na regułach można pisać wyrażenia z dopasowaniem wzorca. Naprawiono mapowanie, który łączy logiczne i fizyczne nazwy kolumn. Aby uzyskać więcej informacji na temat mapowania opartego na regułach, zobacz Wzorce kolumn w przepływie mapowania danych.
Zamawianie niestandardowych zlewów
Domyślnie dane są zapisywane w wielu odbiornikach w nieokreślonej kolejności. Silnik wykonawczy zapisuje dane równolegle w miarę ukończenia logiki przekształcania, a kolejność zapisu w ujściu może się różnić przy każdym uruchomieniu. Aby określić dokładną kolejność ujścia, włącz niestandardową kolejność ujścia na karcie Ogólne w przepływie danych. Po włączeniu ujścia są zapisywane sekwencyjnie w kolejności rosnącej.
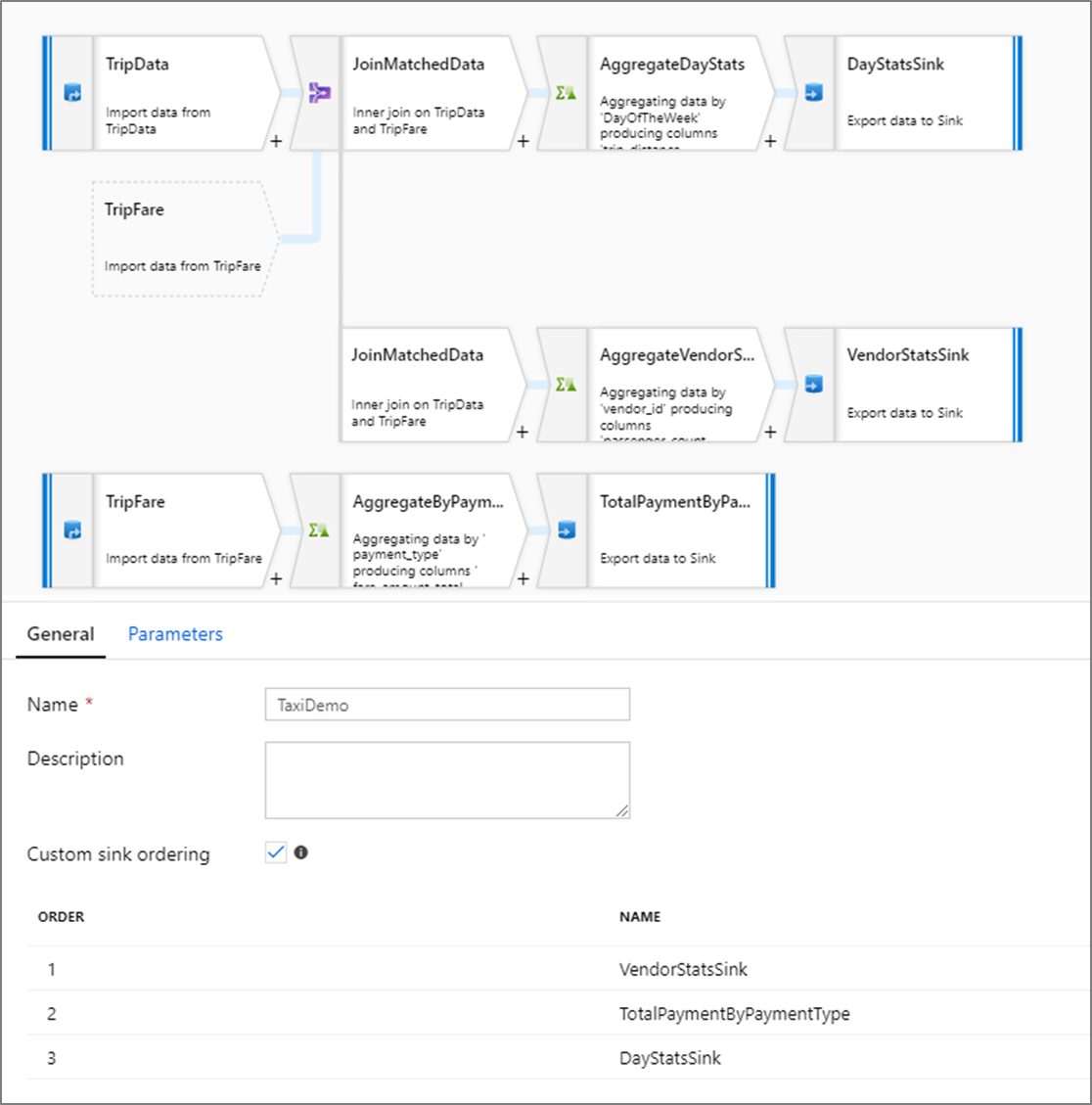
Uwaga
Podczas korzystania z buforowanych wyszukiwań upewnij się, że kolejność zlewów ma buforowane zlewy ustawione na 1, czyli najniższą (lub pierwszą) w kolejności.
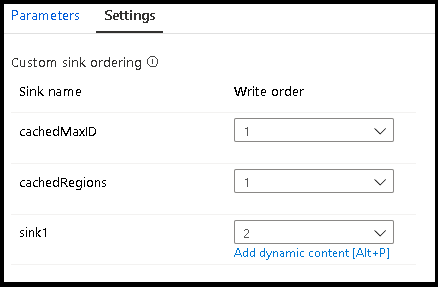
Grupy ujścia
Ujścia można grupować razem, stosując ten sam numer zamówienia dla serii ujść. Usługa będzie traktować te ujścia jako grupy, które mogą być wykonywane równolegle. Opcje wykonywania równoległego będą dostępne w działaniu przepływu danych potoku.
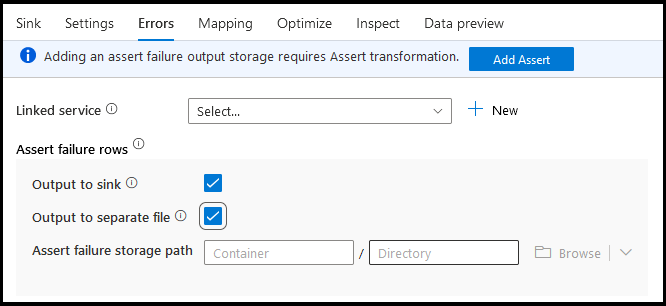
Błędy
Na karcie Błędy ujścia można skonfigurować obsługę wierszy błędów w celu przechwytywania i przekierowywania danych wyjściowych błędów sterowników bazy danych oraz nieudanych asercji.
Podczas zapisywania w bazach danych niektóre wiersze danych mogą zakończyć się niepowodzeniem z powodu ograniczeń ustawionych przez miejsce docelowe. Domyślnie uruchomienie przepływu danych zakończy się niepowodzeniem przy pierwszym napotkanym błędzie. W niektórych łącznikach możesz wybrać opcję Kontynuuj po błędzie , który umożliwia ukończenie przepływu danych, nawet jeśli poszczególne wiersze mają błędy. Obecnie ta funkcja jest dostępna tylko w usługach Azure SQL Database i Azure Synapse. Aby uzyskać więcej informacji, zobacz obsługa wierszy błędów w usłudze Azure SQL DB.
Poniżej przedstawiono samouczek wideo dotyczący automatycznego używania obsługi wierszy błędów bazy danych w transformacji ujścia.
W przypadku wierszy niepowodzeń asercji można użyć przekształcenia Assert w przepływie danych, a następnie przekierować nieudane asercje do pliku wyjściowego tutaj na karcie Błędy ujścia. Istnieje również możliwość ignorowania wierszy z błędami asercji, nie wyprowadzając tych wierszy w ogóle do miejsca docelowego ujścia danych.
Podgląd danych w ujściu
Podczas pobierania podglądu danych w trybie debugowania żadne dane nie zostaną zapisane w ujściu. Migawka tego, jak wyglądają dane, zostanie zwrócona, ale nic nie zostanie zapisane w miejscu docelowym. Aby przetestować zapisywanie danych w ujściu, uruchom debugowanie potoku z kanwy potoku.
Skrypt przepływu danych
Przykład
Poniżej przedstawiono przykład przekształcenia ujścia i skryptu przepływu danych:
sink(input(
movie as integer,
title as string,
genres as string,
year as integer,
Rating as integer
),
allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:false,
updateable:true,
upsertable:false,
keys:['movie'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
saveOrder: 1,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Powiązana zawartość
Skoro już utworzyłeś przepływ danych, dodaj działanie przepływu danych do swojego potoku.