Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia związane z ADF można uaktualnić do Fabric, aby uzyskać dostęp do nowych funkcji w dziedzinie nauki o danych, analizach w czasie rzeczywistym i raportowaniu.
Przepływy danych są dostępne zarówno w potokach Azure Data Factory, jak i w potokach Azure Synapse Analytics. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz z przekształceń danych, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływów mapowania danych.
Wskazówka
Przekształcanie asertywne nie jest obecnie obsługiwane w usłudze Dataflow Gen2. Aby uzyskać listę obsługiwanych przekształceń i ich odpowiedników, zobacz Przewodnik po przepływie danych Gen2 dla użytkowników przepływu danych mapowania.
Przekształcenie Assert umożliwia tworzenie niestandardowych reguł wewnątrz przepływów mapowania danych dla jakości i walidacji danych. Możesz tworzyć reguły określające, czy wartości spełniają oczekiwaną domenę wartości. Ponadto można tworzyć reguły sprawdzające unikatowość wierszy. Przekształcenie asertywne pomaga określić, czy każdy wiersz w danych spełnia zestaw kryteriów. Przekształcenie asertywne umożliwia również ustawianie niestandardowych komunikatów o błędach, gdy reguły sprawdzania poprawności danych nie są spełnione.
Konfigurowanie
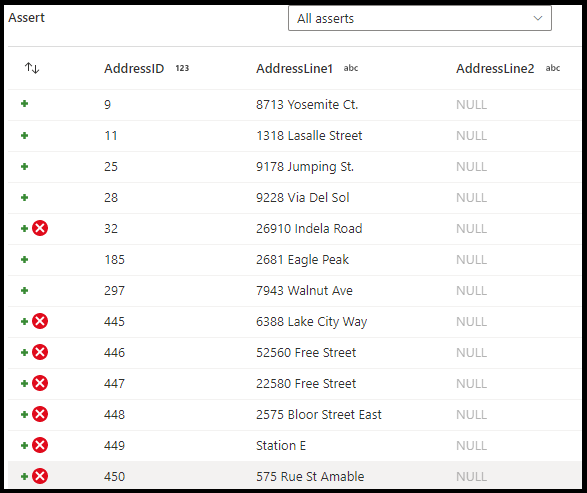
W panelu konfiguracji przekształcania asercji wybierz typ asercji, podaj unikatową nazwę asercji, opcjonalny opis i zdefiniuj wyrażenie i opcjonalny filtr. Okienko podglądu danych wskazuje, które wiersze nie spełniły asercji. Ponadto można przetestować każdy tag wiersza podrzędny przy użyciu poleceń isError() i hasError() dla wierszy, które zakończyły się niepowodzeniem.
Typ assert
- Oczekiwano wartości logicznej true: wynik wyrażenia musi zostać obliczony jako wartość logiczna true. Użyj tego ustawienia, aby zweryfikować zakresy wartości domeny w danych.
- Ustaw unikalność: określ kolumnę lub wyrażenie jako zasadę unikalności w swoich danych. To ustawienie służy do tagowania zduplikowanych wierszy.
- Opcja 'Istnienie oczekiwane': Ta opcja jest dostępna tylko po wybraniu dodatkowego strumienia przychodzącego. Funkcja EXISTS przegląda oba strumienie i określa, czy wiersze istnieją w obu strumieniach na podstawie określonych przez ciebie kolumn lub wyrażeń. Aby dodać drugi strumień dla istniejącego elementu, wybierz pozycję
Additional streams.
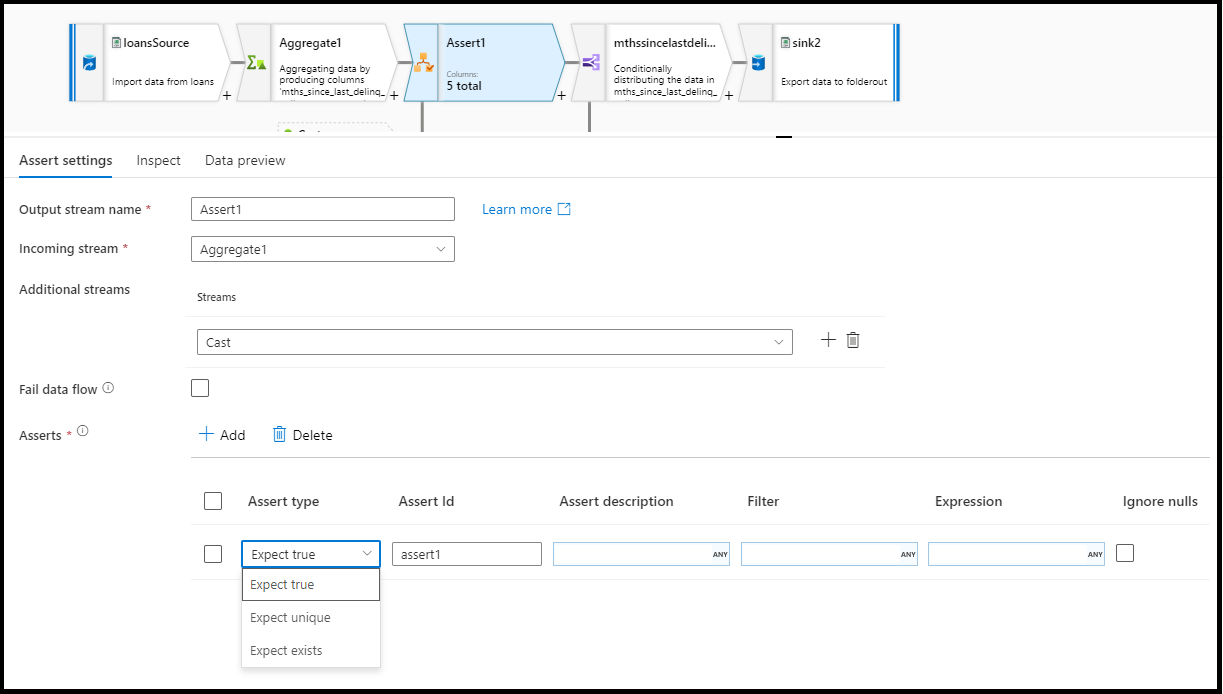
Niepowodzenie przepływu danych
Wybierz fail data flow, jeśli chcesz, aby działanie przepływu danych zakończyło się niepowodzeniem natychmiast po niepowodzeniu reguły asercji.
Identyfikator potwierdzenia
Identyfikator asercji to właściwość, w której wprowadzasz nazwę (ciąg) dla asercji. Możesz użyć identyfikatora później w dalszej części przepływu danych za pomocą hasError(), lub w celu wyprowadzenia kodu błędu asercji. Identyfikatory asertów muszą być unikatowe w każdym przepływie danych.
Opis stwierdzenia
Wprowadź tutaj opis ciągu znaków dla warunku. W tym miejscu możesz również użyć wyrażeń i wartości kolumn kontekstu wiersza.
Filtr
Filter to opcjonalna właściwość, dzięki której można filtrować asercje do podzbioru wierszy, opierając się na określonej wartości wyrażenia.
Wyrażenie
Wprowadź wyrażenie do oceny dla każdej asercji. Dla każdej transformacji asercji można mieć wiele asercji. Każdy typ asercji wymaga wyrażenia, które usługa ADF musi ocenić, aby sprawdzić, czy asercja jest prawdziwa.
Ignoruj wartości NULL
Domyślnie transformacja asercji obejmuje wartości NULL w ocenie asercji wierszy. Możesz wybrać, aby zignorować wartości NULL z tą właściwością.
Bezpośrednie błędy asercji w wierszach
W przypadku niepowodzenia asercji można opcjonalnie skierować te wiersze błędów do pliku w Azure, używając karty "Błędy" na transformacji wyjściowej. Istnieje również opcja przekształcenia ujścia, aby nie wyprowadzać wierszy z błędami asercji w ogóle, ignorując wiersze błędów.
Przykłady
source(output(
AddressID as integer,
AddressLine1 as string,
AddressLine2 as string,
City as string,
StateProvince as string,
CountryRegion as string,
PostalCode as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source(output(
CustomerID as integer,
AddressID as integer,
AddressType as string,
rowguid as string,
ModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source2
source1, source2 assert(expectExists(AddressLine1 == AddressLine1, false, 'nonUS', true(), 'only valid for U.S. addresses')) ~> Assert1
Skrypt przepływu danych
Przykłady
source1, source2 assert(expectTrue(CountryRegion == 'United States', false, 'nonUS', null, 'only valid for U.S. addresses'),
expectExists(source1@AddressID == source2@AddressID, false, 'assertExist', StateProvince == 'Washington', toString(source1@AddressID) + ' already exists in Washington'),
expectUnique(source1@AddressID, false, 'uniqueness', null, toString(source1@AddressID) + ' is not unique')) ~> Assert1
Powiązana zawartość
- Użyj przekształcenia „Wybierz”, aby wybrać i zweryfikować kolumny.
- Użyj przekształcenia kolumny pochodnej, aby zmienić wartości kolumn.