Łączenie transformacji w przepływie danych mapowania
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Przepływy danych są dostępne zarówno w usłudze Azure Data Factory, jak i w potokach usługi Azure Synapse. Ten artykuł dotyczy przepływów danych mapowania. Jeśli dopiero zaczynasz transformacje, zapoznaj się z artykułem wprowadzającym Przekształcanie danych przy użyciu przepływu danych mapowania.
Użyj przekształcenia sprzężenia, aby połączyć dane z dwóch źródeł lub strumieni w przepływie danych mapowania. Strumień wyjściowy będzie zawierać wszystkie kolumny z obu źródeł dopasowane na podstawie warunku sprzężenia.
Typy sprzężenia
Przepływy danych mapowania obsługują obecnie pięć różnych typów sprzężenia.
Sprzężenie wewnętrzne
Sprzężenie wewnętrzne generuje tylko wiersze, które mają pasujące wartości w obu tabelach.
Lewa zewnętrzna
Lewe sprzężenie zewnętrzne zwraca wszystkie wiersze ze strumienia po lewej stronie i dopasowane rekordy z prawego strumienia. Jeśli wiersz ze strumienia po lewej stronie nie jest zgodny, kolumny wyjściowe z prawego strumienia są ustawione na wartość NULL. Dane wyjściowe będą wierszami zwracanym przez sprzężenie wewnętrzne oraz niedopasowane wiersze ze strumienia po lewej stronie.
Uwaga
Aparat Spark używany przez przepływy danych od czasu do czasu zakończy się niepowodzeniem ze względu na możliwe produkty kartezjańskie w warunkach sprzężenia. W takim przypadku możesz przełączyć się na niestandardowe sprzężenie krzyżowe i ręcznie wprowadzić warunek sprzężenia. Może to spowodować niższą wydajność przepływów danych, ponieważ aparat wykonywania może wymagać obliczenia wszystkich wierszy z obu stron relacji, a następnie filtrowania wierszy.
Prawa zewnętrzna
Prawe sprzężenie zewnętrzne zwraca wszystkie wiersze z prawego strumienia i dopasowane rekordy ze strumienia po lewej stronie. Jeśli wiersz z prawego strumienia nie jest zgodny, kolumny wyjściowe z lewego strumienia są ustawione na wartość NULL. Dane wyjściowe będą wierszami zwracanym przez sprzężenie wewnętrzne oraz niedopasowane wiersze z prawego strumienia.
Pełne zewnętrzne
Pełne sprzężenia zewnętrzne zwraca wszystkie kolumny i wiersze z obu stron z wartościami NULL dla kolumn, które nie są zgodne.
Niestandardowe sprzężenia krzyżowe
Sprzężenia krzyżowe wyprowadza krzyżowy produkt dwóch strumieni na podstawie warunku. Jeśli używasz warunku, który nie jest równości, określ wyrażenie niestandardowe jako warunek sprzężenia krzyżowego. Strumień wyjściowy będzie mieć wszystkie wiersze spełniające warunek sprzężenia.
Tego typu sprzężenia można użyć dla sprzężeń i OR warunków innych niż równocze.
Jeśli chcesz jawnie utworzyć pełny produkt kartezjański, użyj przekształcenia kolumny pochodnej w każdym z dwóch niezależnych strumieni przed sprzężenie, aby utworzyć syntetyczny klucz do dopasowania. Na przykład utwórz nową kolumnę w kolumnie pochodnej w każdym strumieniu o nazwie SyntheticKey i ustaw ją na wartość 1. Następnie użyj a.SyntheticKey == b.SyntheticKey polecenia jako niestandardowego wyrażenia sprzężenia.
Uwaga
Pamiętaj, aby uwzględnić co najmniej jedną kolumnę z każdej strony lewej i prawej relacji w niestandardowym sprzężenia krzyżowym. Wykonywanie sprzężeń krzyżowych przy użyciu wartości statycznych zamiast kolumn z każdej strony powoduje pełne skanowanie całego zestawu danych, co powoduje, że przepływ danych działa nieprawidłowo.
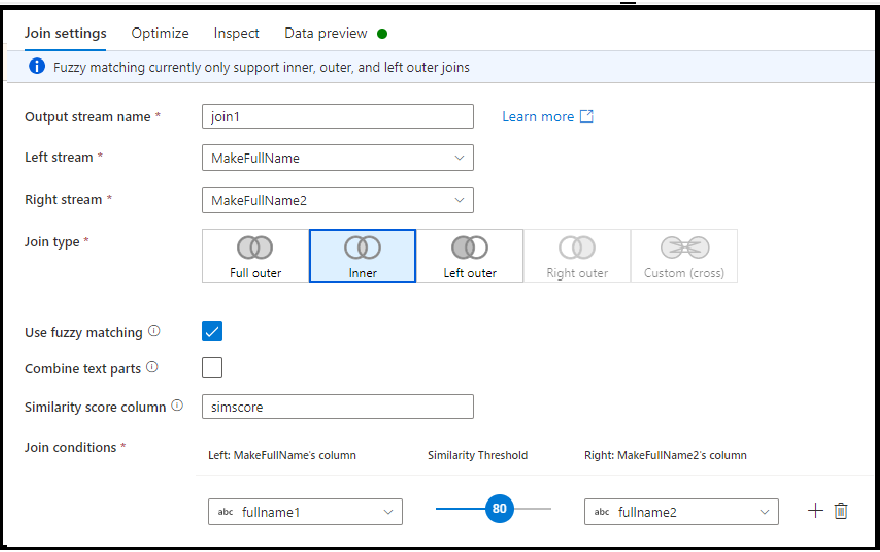
Przyłączanie rozmyte
Możesz wybrać sprzężenie na podstawie logiki sprzężenia rozmytego zamiast dokładnego dopasowania wartości kolumny, włączając opcję pola wyboru "Użyj dopasowywania rozmytego".
- Połącz części tekstowe: użyj tej opcji, aby znaleźć dopasowania przez usunięcie odstępu między wyrazami. Na przykład usługa Data Factory jest zgodna z usługą DataFactory, jeśli ta opcja jest włączona.
- Kolumna wyników podobieństwa: opcjonalnie możesz wybrać przechowywanie pasującego wyniku dla każdego wiersza w kolumnie, wprowadzając w tym miejscu nową nazwę kolumny w celu przechowywania tej wartości.
- Próg podobieństwa: wybierz wartość z zakresu od 60 do 100 jako procentową dopasowanie między wartościami w wybranych kolumnach.
Uwaga
Dopasowywanie rozmyte działa obecnie tylko z typami kolumn ciągów i wewnętrznymi, lewymi zewnętrznymi i pełnymi typami sprzężenia zewnętrznego. Optymalizację emisji należy wyłączyć podczas używania sprzężeń dopasowywania rozmytego.
Konfigurowanie
- Wybierz strumień danych, z którym łączysz się, na liście rozwijanej Prawy strumień .
- Wybierz typ sprzężenia
- Wybierz kolumny kluczy, dla których chcesz dopasować warunek sprzężenia. Domyślnie przepływ danych szuka równości między jedną kolumną w każdym strumieniu. Aby porównać wartość obliczoną, umieść kursor nad listą rozwijaną kolumny i wybierz pozycję Obliczona kolumna.
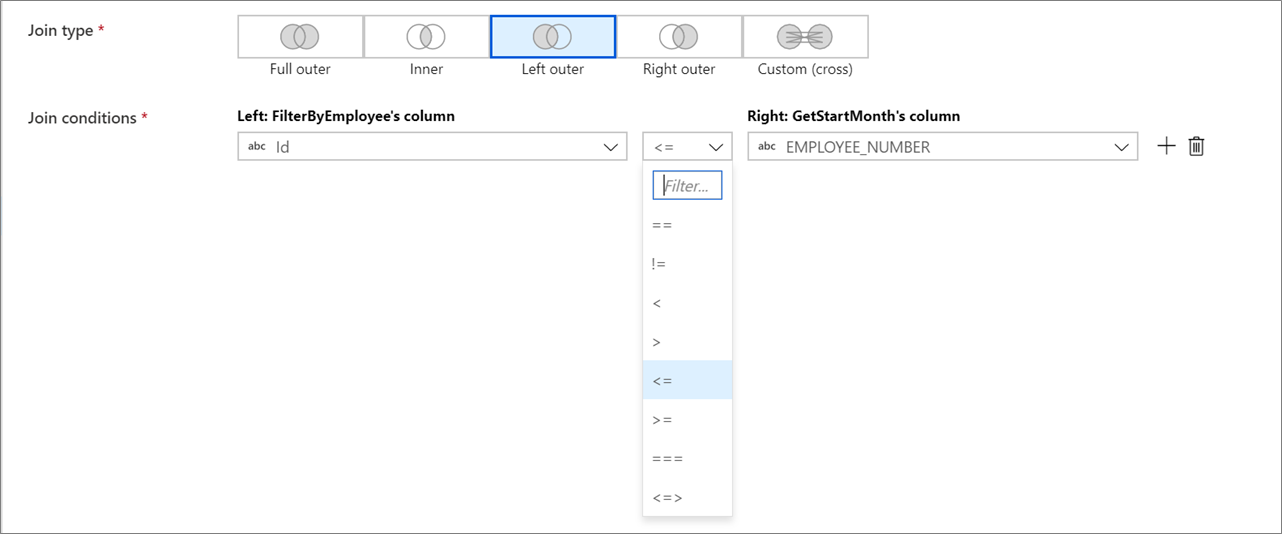
Sprzężenia inne niż równocze
Aby użyć operatora warunkowego, takiego jak nie równe (!=) lub większe niż (>) w warunkach sprzężenia, zmień listę rozwijaną operatora między dwiema kolumnami. Sprzężenia inne niż równoważne wymagają emisji co najmniej jednego z dwóch strumieni przy użyciu emisji stałej na karcie Optymalizacja .
Optymalizowanie wydajności sprzężenia
W przeciwieństwie do łączenia scalania w narzędziach, takich jak SSIS, transformacja sprzężenia nie jest obowiązkową operacją scalania. Klucze sprzężenia nie wymagają sortowania. Operacja sprzężenia odbywa się na podstawie optymalnej operacji sprzężenia na platformie Spark, emisji lub sprzężenia po stronie mapy.
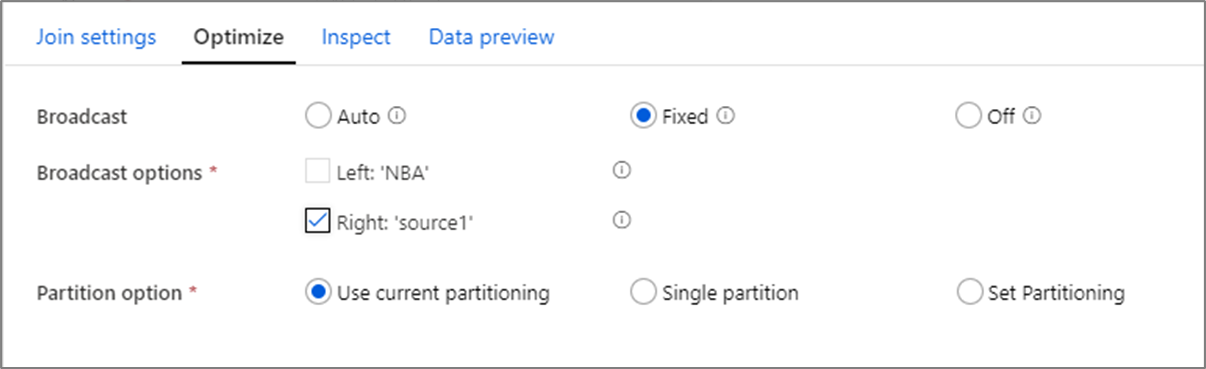
W sprzężeniach wyszukiwanie i istnieje transformacja, jeśli jeden lub oba strumienie danych mieszczą się w pamięci węzła procesu roboczego, możesz zoptymalizować wydajność, włączając funkcję Emisja. Domyślnie aparat spark automatycznie zdecyduje, czy emitować jedną stronę. Aby ręcznie wybrać stronę do emisji, wybierz pozycję Naprawiono.
Nie zaleca się wyłączania emisji za pośrednictwem opcji Wyłącz , chyba że sprzężenia występują błędy przekroczenia limitu czasu.
Samosprzężenia
Aby samodzielnie połączyć strumień danych z samym sobą, alias istniejącego strumienia z wybranym przekształceniem. Utwórz nową gałąź, klikając ikonę znaku plus obok przekształcenia i wybierając pozycję Nowa gałąź. Dodaj przekształcenie wyboru, aby utworzyć alias oryginalnego strumienia. Dodaj przekształcenie sprzężenia i wybierz oryginalny strumień jako strumień po lewej stronie, a następnie wybierz przekształcenie jako strumień prawy.
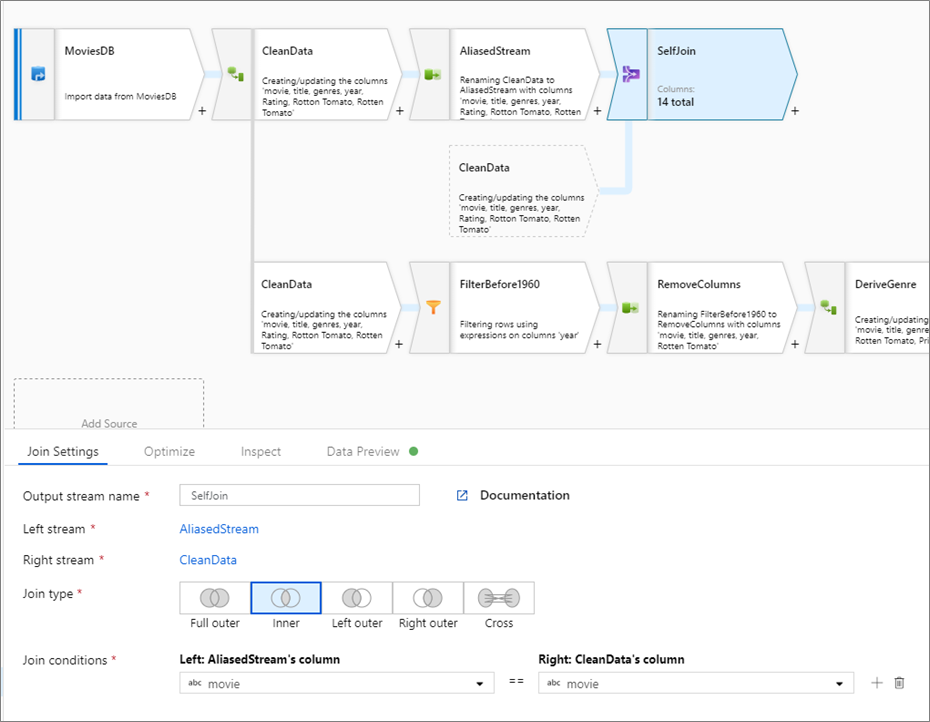
Testowanie warunków sprzężenia
Podczas testowania przekształceń sprzężenia za pomocą podglądu danych w trybie debugowania użyj małego zestawu znanych danych. Podczas próbkowania wierszy z dużego zestawu danych nie można przewidzieć, które wiersze i klucze będą odczytywane do testowania. Wynik nie jest deterministyczny, co oznacza, że warunki sprzężenia mogą nie zwracać żadnych dopasowań.
Skrypt przepływu danych
Składnia
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
Przykład sprzężenia wewnętrznego
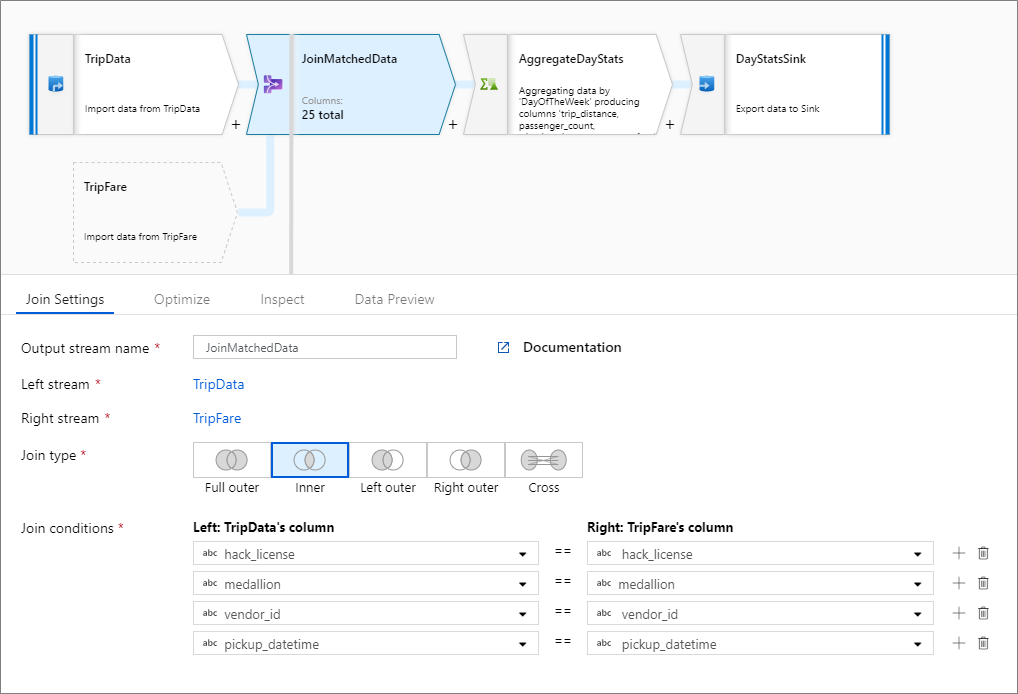
Poniższy przykład to przekształcenie sprzężenia o nazwie JoinMatchedData , które pobiera strumień TripData po lewej stronie i prawy strumień TripFare. Warunek sprzężenia jest wyrażeniem hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} , które zwraca wartość true, jeśli hack_licensekolumny , medallion, vendor_idi pickup_datetime w każdym strumieniu są zgodne. Wartość joinType to 'inner'. Włączamy emisję tylko w lewym strumieniu, więc broadcast ma wartość 'left'.
W interfejsie użytkownika ta transformacja wygląda jak na poniższej ilustracji:
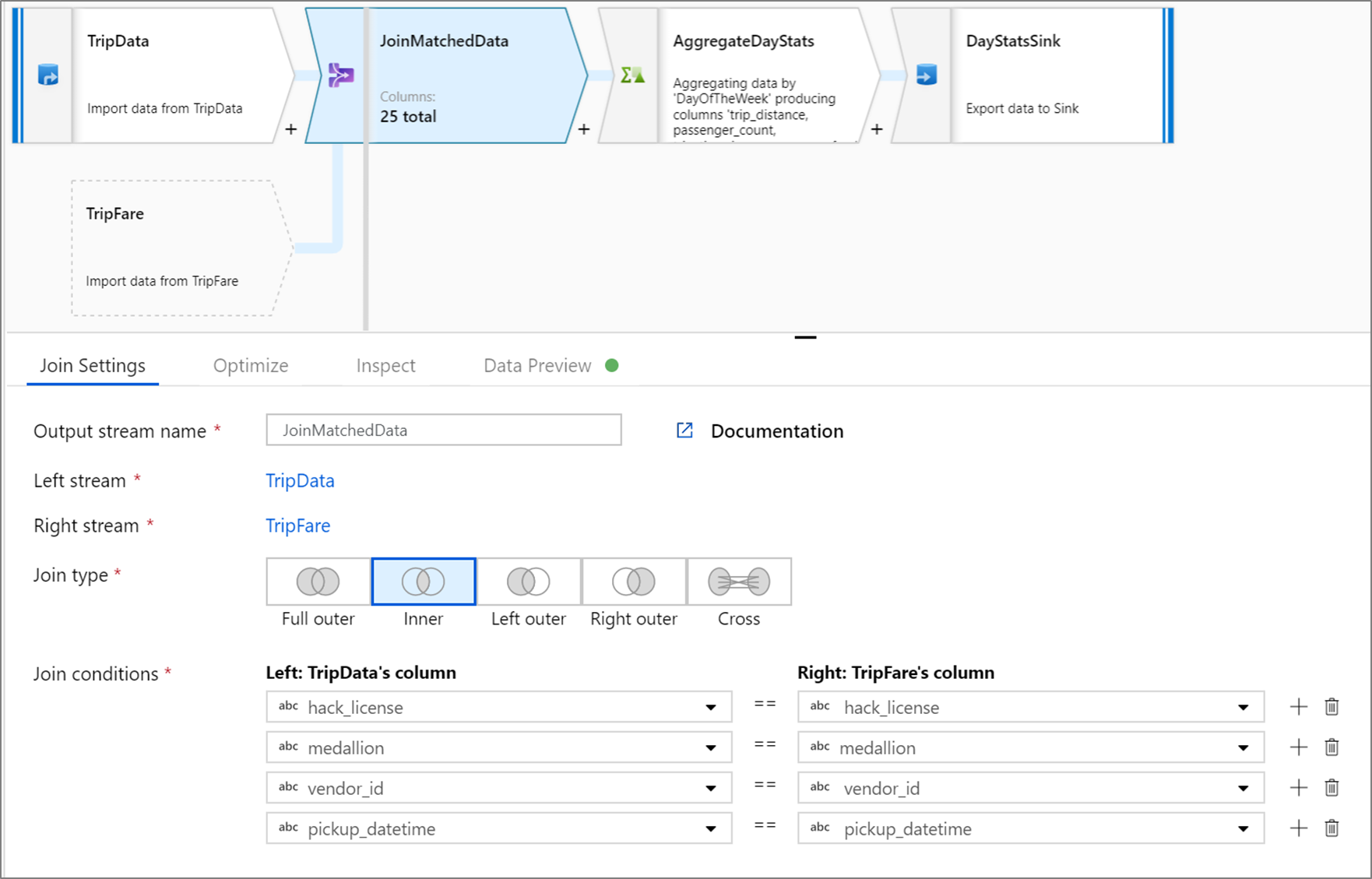
Skrypt przepływu danych dla tej transformacji znajduje się w poniższym fragmencie kodu:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Przykład niestandardowego sprzężenia krzyżowego
Poniższy przykład to przekształcenie sprzężenia o nazwie JoiningColumns , które pobiera strumień LeftStream po lewej stronie i prawy strumień RightStream. Ta transformacja przyjmuje dwa strumienie i łączy ze sobą wszystkie wiersze, w których kolumna leftstreamcolumn jest większa niż kolumna rightstreamcolumn. Wartość joinType to cross. Emisja nie jest włączona broadcast , ma wartość 'none'.
W interfejsie użytkownika ta transformacja wygląda jak na poniższej ilustracji:
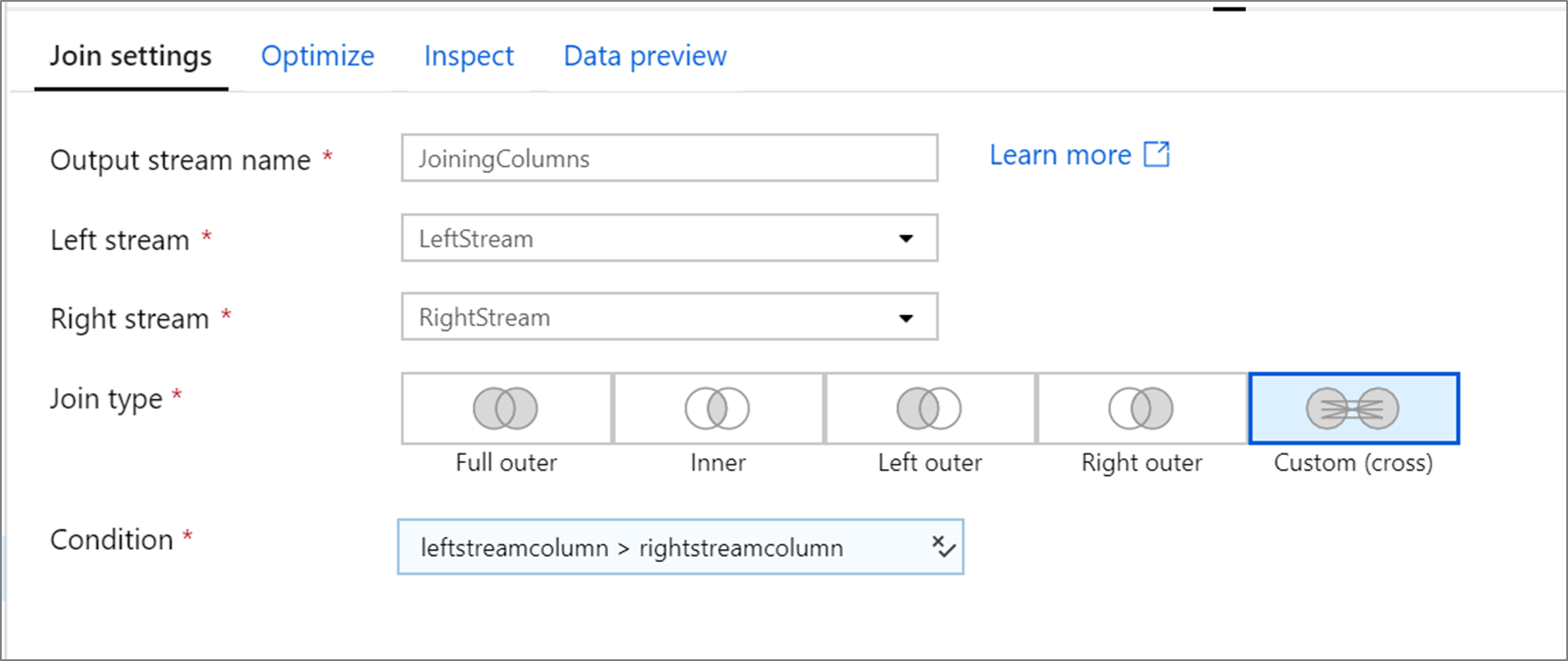
Skrypt przepływu danych dla tej transformacji znajduje się w poniższym fragmencie kodu:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Powiązana zawartość
Po dołączeniu danych utwórz pochodną kolumnęi ujmij dane do docelowego magazynu danych.