Migrowanie danych z usługi Data Lake lub data warehouse na platformę Azure przy użyciu usługi Azure Data Factory
DOTYCZY:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Jeśli chcesz przeprowadzić migrację magazynu danych data lake lub przedsiębiorstwa (EDW) na platformę Microsoft Azure, rozważ użycie usługi Azure Data Factory. Usługa Azure Data Factory jest odpowiednia do następujących scenariuszy:
- Migracja obciążeń danych big data z usługi Amazon Simple Storage Service (Amazon S3) lub lokalnego rozproszonego systemu plików Hadoop (HDFS) na platformę Azure
- Migracja EDW z programu Oracle Exadata, Netezza, Teradata lub Amazon Redshift na platformę Azure
Usługa Azure Data Factory może przenosić petabajty (PB) danych na potrzeby migracji typu data lake oraz dziesiątki terabajtów (TB) danych na potrzeby migracji magazynu danych.
Dlaczego usługa Azure Data Factory może służyć do migracji danych
- Usługa Azure Data Factory umożliwia łatwe skalowanie w górę mocy obliczeniowej w celu przenoszenia danych w sposób bezserwerowy z wysoką wydajnością, odpornością i skalowalnością. Płacisz tylko za to, czego używasz. Zwróć również uwagę na następujące kwestie:
- Usługa Azure Data Factory nie ma ograniczeń dotyczących woluminu danych ani liczby plików.
- Usługa Azure Data Factory może w pełni wykorzystać przepustowość sieci i magazynu w celu osiągnięcia największej przepływności przenoszenia danych w środowisku.
- Usługa Azure Data Factory używa metody płatności zgodnie z rzeczywistym użyciem, dzięki czemu płacisz tylko za czas, którego faktycznie używasz do uruchamiania migracji danych na platformę Azure.
- Usługa Azure Data Factory może wykonywać zarówno jednorazowe obciążenie historyczne, jak i zaplanowane obciążenia przyrostowe.
- Usługa Azure Data Factory używa środowiska Azure Integration Runtime (IR) do przenoszenia danych między publicznie dostępnymi punktami końcowymi usługi Data Lake i magazynem. Może również używać własnego środowiska IR do przenoszenia danych dla punktów końcowych magazynu i typu data lake w sieci wirtualnej platformy Azure lub za zaporą.
- Usługa Azure Data Factory ma zabezpieczenia klasy korporacyjnej: do zarządzania poświadczeniami można użyć Instalatora Windows (MSI) lub tożsamości usługi na potrzeby integracji zabezpieczonej usługi z usługą lub użyć usługi Azure Key Vault.
- Usługa Azure Data Factory udostępnia środowisko tworzenia bez kodu i rozbudowany, wbudowany pulpit nawigacyjny monitorowania.
Migracja danych w trybie online a offline
Azure Data Factory to standardowe narzędzie do migracji danych online do przesyłania danych za pośrednictwem sieci (Internet, ER lub VPN). Podczas migracji danych w trybie offline użytkownicy fizycznie wysyłają urządzenia transferu danych z organizacji do centrum danych platformy Azure.
Podczas wybierania podejścia do migracji w trybie online i offline istnieją trzy kluczowe zagadnienia:
- Rozmiar danych do zmigrowania
- Przepustowość sieci
- Okno migracji
Załóżmy na przykład, że planujesz użyć usługi Azure Data Factory do ukończenia migracji danych w ciągu dwóch tygodni ( okno migracji). Zwróć uwagę na różową/niebieską linię cięcia w poniższej tabeli. Najniższa różowa komórka dla każdej kolumny pokazuje rozmiar danych/parowanie przepustowości sieci, których okno migracji jest najbliższe, ale mniej niż dwa tygodnie. (Dowolny rozmiar/przepustowość parowania w niebieskiej komórce ma okno migracji online ponad dwa tygodnie).
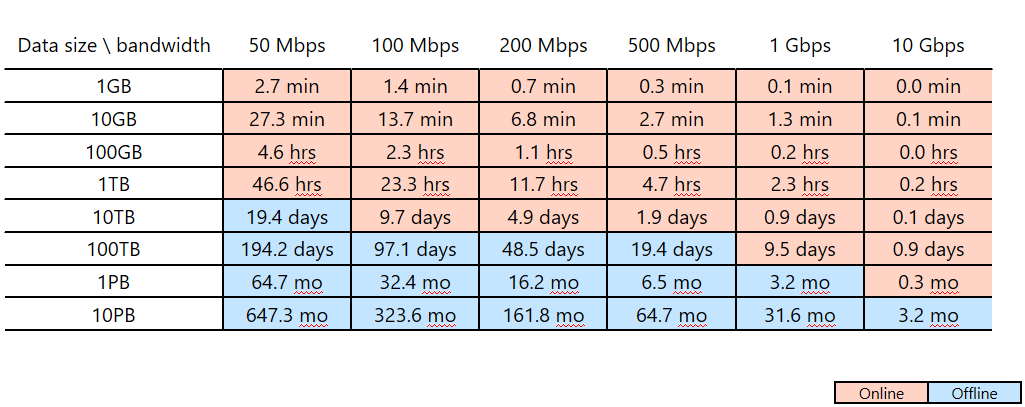 Ta tabela ułatwia określenie, czy można spełnić zamierzone okno migracji za pośrednictwem migracji online (Azure Data Factory) na podstawie rozmiaru danych i dostępnej przepustowości sieci. Jeśli okno migracji online trwa dłużej niż dwa tygodnie, należy użyć migracji w trybie offline.
Ta tabela ułatwia określenie, czy można spełnić zamierzone okno migracji za pośrednictwem migracji online (Azure Data Factory) na podstawie rozmiaru danych i dostępnej przepustowości sieci. Jeśli okno migracji online trwa dłużej niż dwa tygodnie, należy użyć migracji w trybie offline.
Uwaga
Korzystając z migracji online, można osiągnąć zarówno ładowanie danych historycznych, jak i przyrostowe źródła danych za pomocą jednego narzędzia. Dzięki temu podejściu dane mogą być synchronizowane między istniejącym magazynem a nowym magazynem w całym oknie migracji. Oznacza to, że można ponownie skompilować logikę ETL w nowym magazynie przy użyciu odświeżonych danych.