Migrowanie danych z lokalnego serwera Netezza na platformę Azure przy użyciu usługi Azure Data Factory
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Usługa Azure Data Factory zapewnia wydajny, niezawodny i ekonomiczny mechanizm migracji danych na dużą skalę z lokalnego serwera Netezza do konta usługi Azure Storage lub bazy danych usługi Azure Synapse Analytics.
Ten artykuł zawiera następujące informacje dla inżynierów danych i deweloperów:
- Wydajności
- Odporność kopiowania
- Bezpieczeństwo sieci
- Architektura rozwiązania wysokiego poziomu
- Najlepsze rozwiązania dotyczące implementacji
Wydajność
Usługa Azure Data Factory oferuje architekturę bezserwerową, która umożliwia równoległość na różnych poziomach. Jeśli jesteś deweloperem, oznacza to, że możesz tworzyć potoki, aby w pełni korzystać zarówno z przepustowości sieci, jak i bazy danych, aby zmaksymalizować przepływność przenoszenia danych dla środowiska.
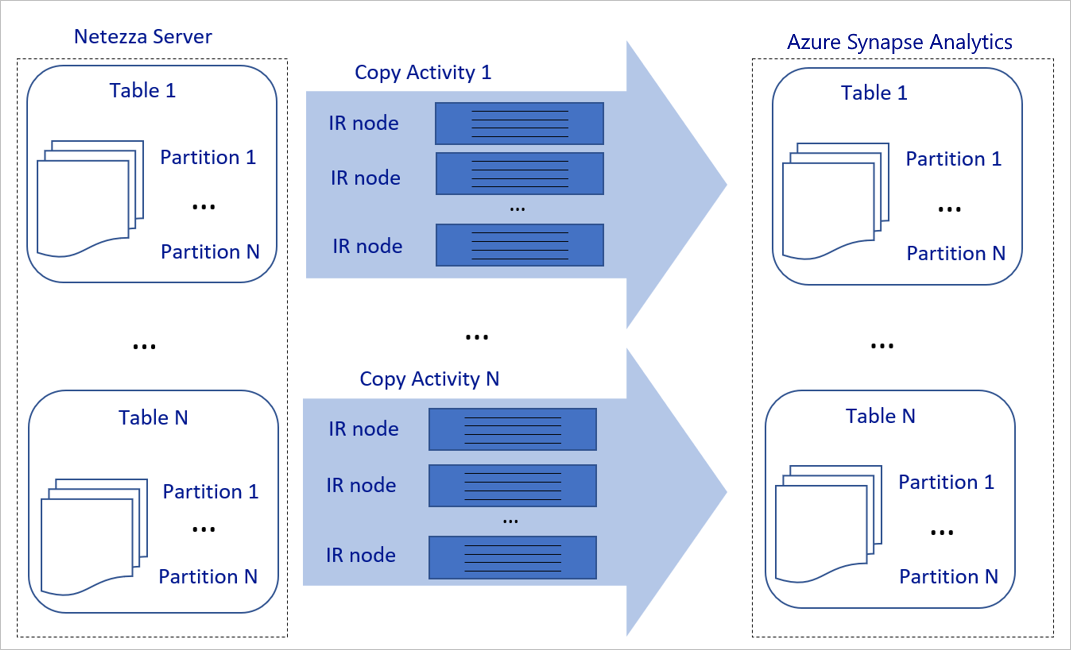
Powyższy diagram można interpretować w następujący sposób:
Jedno działanie kopiowania może korzystać ze skalowalnych zasobów obliczeniowych. W przypadku korzystania z środowiska Azure Integration Runtime można określić maksymalnie 256 jednostek DIU dla każdego działania kopiowania w sposób bezserwerowy. Za pomocą własnego środowiska Integration Runtime (własnego środowiska IR) można ręcznie skalować maszynę w górę lub skalować w poziomie do wielu maszyn (do czterech węzłów), a jedno działanie kopiowania dystrybuuje swoją partycję we wszystkich węzłach.
Jedno działanie kopiowania odczytuje dane i zapisuje je w magazynie danych przy użyciu wielu wątków.
Przepływ sterowania usługi Azure Data Factory może równolegle uruchamiać wiele działań kopiowania. Można na przykład uruchomić je za pomocą pętli For Each.
Aby uzyskać więcej informacji, zobacz działanie Kopiuj przewodnik dotyczący wydajności i skalowalności.
Odporność
W ramach jednego uruchomienia działania kopiowania usługa Azure Data Factory ma wbudowany mechanizm ponawiania, który umożliwia obsługę określonego poziomu przejściowych błędów w magazynach danych lub w sieci bazowej.
W przypadku działania kopiowania usługi Azure Data Factory podczas kopiowania danych między magazynami danych źródłowych i ujścia istnieją dwa sposoby obsługi niezgodnych wierszy. Możesz przerwać działanie kopiowania i zakończyć się niepowodzeniem lub kontynuować kopiowanie reszty danych, pomijając niezgodne wiersze danych. Ponadto, aby poznać przyczynę awarii, możesz zarejestrować niezgodne wiersze w usłudze Azure Blob Storage lub Azure Data Lake Store, naprawić dane w źródle danych i ponowić próbę działania kopiowania.
Bezpieczeństwo sieci
Domyślnie usługa Azure Data Factory przesyła dane z lokalnego serwera Netezza do konta usługi Azure Storage lub bazy danych usługi Azure Synapse Analytics przy użyciu szyfrowanego połączenia za pośrednictwem protokołu Secure (HTTPS). Protokół HTTPS zapewnia szyfrowanie danych podczas przesyłania i uniemożliwia podsłuchiwanie i ataki typu man-in-the-middle.
Alternatywnie, jeśli nie chcesz przesyłać danych za pośrednictwem publicznego Internetu, możesz pomóc w osiągnięciu wyższego poziomu bezpieczeństwa, przesyłając dane za pośrednictwem łącza prywatnej komunikacji równorzędnej za pośrednictwem usługi Azure Express Route.
W następnej sekcji omówiono sposób osiągania wyższych zabezpieczeń.
Architektura rozwiązania
W tej sekcji omówiono dwa sposoby migracji danych.
Migrowanie danych za pośrednictwem publicznego Internetu
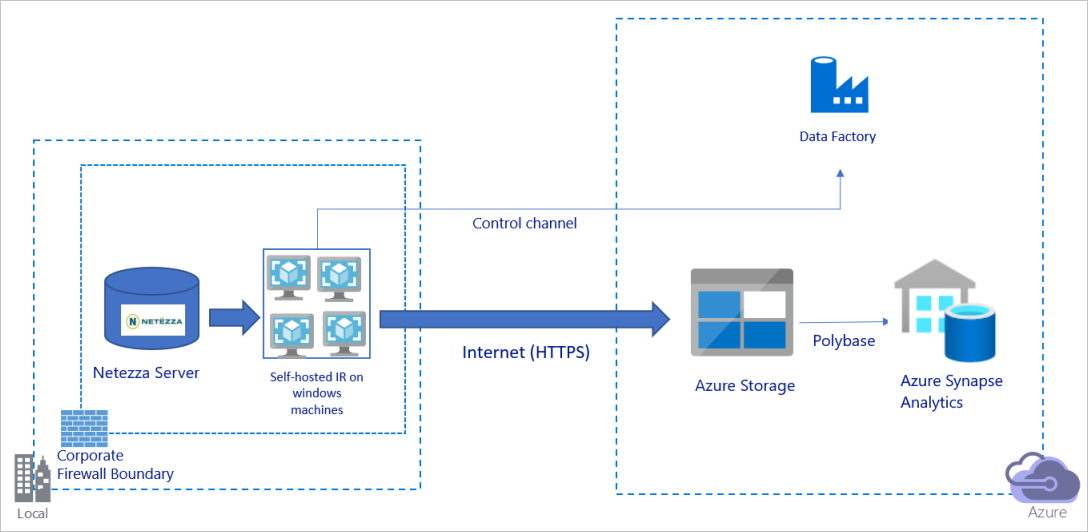
Powyższy diagram można interpretować w następujący sposób:
W tej architekturze dane są bezpiecznie transferowane przy użyciu protokołu HTTPS za pośrednictwem publicznego Internetu.
Aby osiągnąć tę architekturę, musisz zainstalować środowisko Azure Data Factory Integration Runtime (self-hosted) na maszynie z systemem Windows za zaporą firmową. Upewnij się, że to środowisko Integration Runtime może uzyskać bezpośredni dostęp do serwera Netezza. Aby w pełni wykorzystać przepustowość sieci i magazynu danych do kopiowania danych, możesz ręcznie skalować maszynę w górę lub skalować w poziomie do wielu maszyn.
Korzystając z tej architektury, można migrować zarówno początkowe dane migawki, jak i dane różnicowe.
Migrowanie danych za pośrednictwem sieci prywatnej
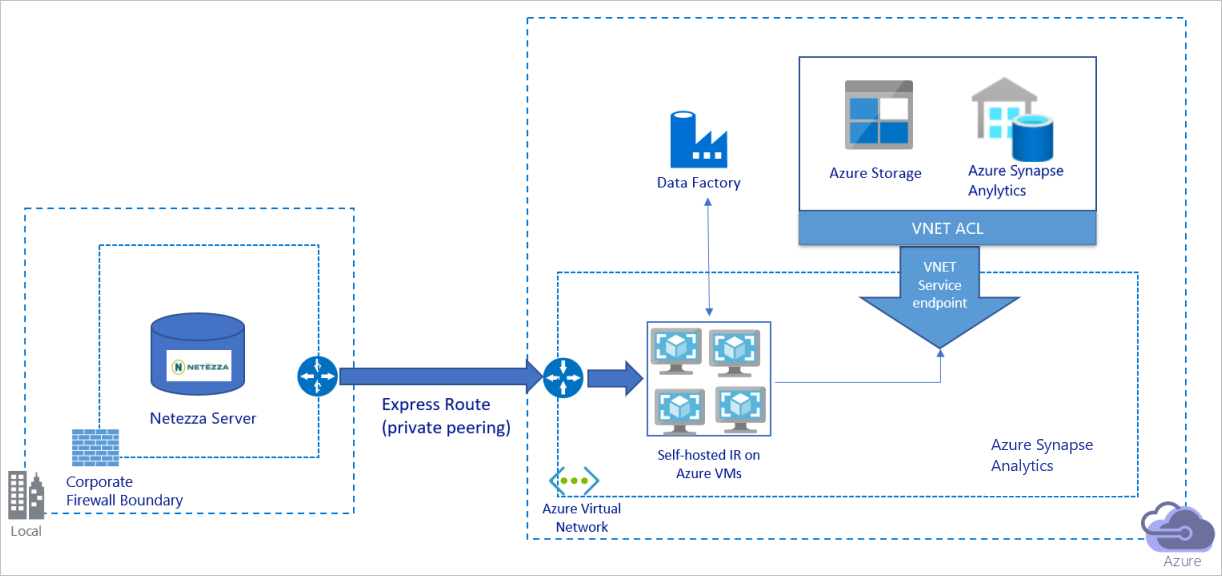
Powyższy diagram można interpretować w następujący sposób:
W tej architekturze dane są migrowane za pośrednictwem łącza prywatnej komunikacji równorzędnej za pośrednictwem usługi Azure Express Route, a dane nigdy nie przechodzą przez publiczny Internet.
Aby osiągnąć tę architekturę, musisz zainstalować środowisko Azure Data Factory Integration Runtime (self-hosted) na maszynie wirtualnej z systemem Windows w sieci wirtualnej platformy Azure. Aby w pełni wykorzystać przepustowość sieci i magazynów danych do kopiowania danych, możesz ręcznie skalować maszynę wirtualną w górę lub skalować w poziomie do wielu maszyn wirtualnych.
Korzystając z tej architektury, można migrować zarówno początkowe dane migawki, jak i dane różnicowe.
Implementowanie najlepszych rozwiązań
Zarządzanie uwierzytelnianiem i poświadczeniami
Aby uwierzytelnić się w usłudze Netezza, możesz użyć uwierzytelniania ODBC za pośrednictwem parametry połączenia.
Aby uwierzytelnić się w usłudze Azure Blob Storage:
Zdecydowanie zalecamy używanie tożsamości zarządzanych dla zasobów platformy Azure. Oparte na automatycznie zarządzanej tożsamości usługi Azure Data Factory w usłudze Microsoft Entra ID tożsamości zarządzane umożliwiają konfigurowanie potoków bez konieczności podawania poświadczeń w definicji połączonej usługi.
Alternatywnie możesz uwierzytelnić się w usłudze Azure Blob Storage przy użyciu jednostki usługi, sygnatury dostępu współdzielonego lub klucza konta magazynu.
Aby uwierzytelnić się w usłudze Azure Data Lake Storage Gen2:
Zdecydowanie zalecamy używanie tożsamości zarządzanych dla zasobów platformy Azure.
Możesz również użyć jednostki usługi lub klucza konta magazynu.
Aby uwierzytelnić się w usłudze Azure Synapse Analytics:
Zdecydowanie zalecamy używanie tożsamości zarządzanych dla zasobów platformy Azure.
Możesz również użyć jednostki usługi lub uwierzytelniania SQL.
Jeśli nie używasz tożsamości zarządzanych dla zasobów platformy Azure, zdecydowanie zalecamy przechowywanie poświadczeń w usłudze Azure Key Vault , aby ułatwić centralne zarządzanie kluczami i obracanie ich bez konieczności modyfikowania połączonych usług Azure Data Factory. Jest to również jedno z najlepszych rozwiązań dotyczących ciągłej integracji/ciągłego wdrażania.
Migrowanie początkowych danych migawki
W przypadku małych tabel (czyli tabel z woluminem mniejszym niż 100 GB lub zmigrowanych na platformę Azure w ciągu dwóch godzin) każde zadanie kopiowania może ładować dane na tabelę. Aby uzyskać większą przepływność, można uruchomić wiele zadań kopiowania usługi Azure Data Factory w celu równoczesnego ładowania oddzielnych tabel.
W każdym zadaniu kopiowania, aby uruchamiać zapytania równoległe i kopiować dane według partycji, można również osiągnąć pewien poziom równoległości przy użyciu parallelCopies ustawienia właściwości z jedną z następujących opcji partycji danych:
Aby uzyskać lepszą wydajność, zachęcamy do rozpoczęcia od wycinka danych. Upewnij się, że wartość w
parallelCopiesustawieniu jest mniejsza niż całkowita liczba partycji fragmentowania danych w tabeli na serwerze Netezza.Jeśli wolumin każdej partycji fragmentatora danych jest nadal duży (na przykład 10 GB lub większy), zachęcamy do przełączenia się na partycję zakresu dynamicznego. Ta opcja zapewnia większą elastyczność definiowania liczby partycji i woluminu każdej partycji według kolumny partycji, górnej granicy i dolnej granicy.
W przypadku większych tabel (czyli tabel z woluminem o rozmiarze 100 GB lub większym lub nie można ich zmigrować na platformę Azure w ciągu dwóch godzin), zalecamy podzielenie danych za pomocą zapytania niestandardowego, a następnie skopiowanie jednej partycji zadania kopiowania naraz. Aby uzyskać lepszą przepływność, można jednocześnie uruchamiać wiele zadań kopiowania w usłudze Azure Data Factory. Dla każdego miejsca docelowego zadania kopiowania ładowania jednej partycji według zapytania niestandardowego można zwiększyć przepływność, włączając równoległość za pośrednictwem fragmentatora danych lub zakresu dynamicznego.
Jeśli jakiekolwiek zadanie kopiowania nie powiedzie się z powodu przejściowego problemu z siecią lub magazynem danych, możesz ponownie uruchomić zadanie kopiowania, które zakończyło się niepowodzeniem, aby ponownie załadować tę konkretną partycję z tabeli. Nie ma to wpływu na inne zadania kopiowania, które ładują inne partycje.
Podczas ładowania danych do bazy danych usługi Azure Synapse Analytics zalecamy włączenie programu PolyBase w ramach zadania kopiowania za pomocą usługi Azure Blob Storage jako przejściowego.
Migrowanie danych różnicowych
Aby zidentyfikować nowe lub zaktualizowane wiersze z tabeli, użyj kolumny sygnatury czasowej lub klucza przyrostowego w schemacie. Następnie możesz zapisać najnowszą wartość jako wysoki limit wodny w tabeli zewnętrznej, a następnie użyć jej do filtrowania danych różnicowych przy następnym załadowaniu danych.
Każda tabela może użyć innej kolumny limitu, aby zidentyfikować nowe lub zaktualizowane wiersze. Zalecamy utworzenie tabeli kontroli zewnętrznej. W tabeli każdy wiersz reprezentuje jedną tabelę na serwerze Netezza z jej określoną nazwą kolumny limitu i wysoką wartością limitu.
Konfigurowanie własnego środowiska Integration Runtime
Jeśli migrujesz dane z serwera Netezza na platformę Azure, niezależnie od tego, czy serwer znajduje się lokalnie za zaporą korporacji, czy w środowisku sieci wirtualnej, musisz zainstalować własne środowisko IR na maszynie lub maszynie wirtualnej z systemem Windows, który jest aparatem używanym do przenoszenia danych. Podczas instalowania własnego środowiska IR zalecamy następujące podejście:
Dla każdej maszyny lub maszyny wirtualnej z systemem Windows zacznij od konfiguracji 32 procesorów wirtualnych i 128 GB pamięci. Możesz nadal monitorować użycie procesora CPU i pamięci maszyny IR podczas migracji danych, aby sprawdzić, czy konieczne jest dalsze skalowanie maszyny w górę, aby uzyskać lepszą wydajność, czy skalować maszynę w dół, aby zaoszczędzić koszty.
Można również skalować w poziomie, kojarząc maksymalnie cztery węzły z jednym własnym środowiskiem IR. Jedno zadanie kopiowania, które jest uruchomione względem własnego środowiska IR, automatycznie stosuje wszystkie węzły maszyn wirtualnych do równoległego kopiowania danych. Aby uzyskać wysoką dostępność, zacznij od czterech węzłów maszyn wirtualnych, aby uniknąć pojedynczego punktu awarii podczas migracji danych.
Ogranicz partycje
Najlepszym rozwiązaniem jest przeprowadzenie weryfikacji wydajności koncepcji przy użyciu reprezentatywnego przykładowego zestawu danych, dzięki czemu można określić odpowiedni rozmiar partycji dla każdego działania kopiowania. Zalecamy załadowanie każdej partycji na platformę Azure w ciągu dwóch godzin.
Aby skopiować tabelę, zacznij od pojedynczego działania kopiowania przy użyciu pojedynczej maszyny własnego środowiska IR. Stopniowo zwiększaj parallelCopies ustawienie na podstawie liczby partycji fragmentowania danych w tabeli. Sprawdź, czy cała tabela może zostać załadowana na platformę Azure w ciągu dwóch godzin, zgodnie z przepływnością wynikającą z zadania kopiowania.
Jeśli nie można go załadować na platformę Azure w ciągu dwóch godzin, a pojemność węzła własnego środowiska IR i magazynu danych nie są w pełni używane, stopniowo zwiększaj liczbę współbieżnych działań kopiowania, dopóki nie osiągniesz limitu sieci lub limitu przepustowości magazynów danych.
Zachowaj monitorowanie użycia procesora CPU i pamięci na maszynie własnego środowiska IR i przygotuj się do skalowania maszyny w górę lub skalowania w poziomie do wielu maszyn, gdy zobaczysz, że procesor i pamięć są w pełni używane.
Jeśli wystąpią błędy ograniczania przepustowości, zgłoszone przez działanie kopiowania usługi Azure Data Factory, zmniejsz współbieżność lub parallelCopies ustawienie w usłudze Azure Data Factory lub rozważ zwiększenie przepustowości lub operacji we/wy na sekundę (IOPS) limitów sieci i magazynów danych.
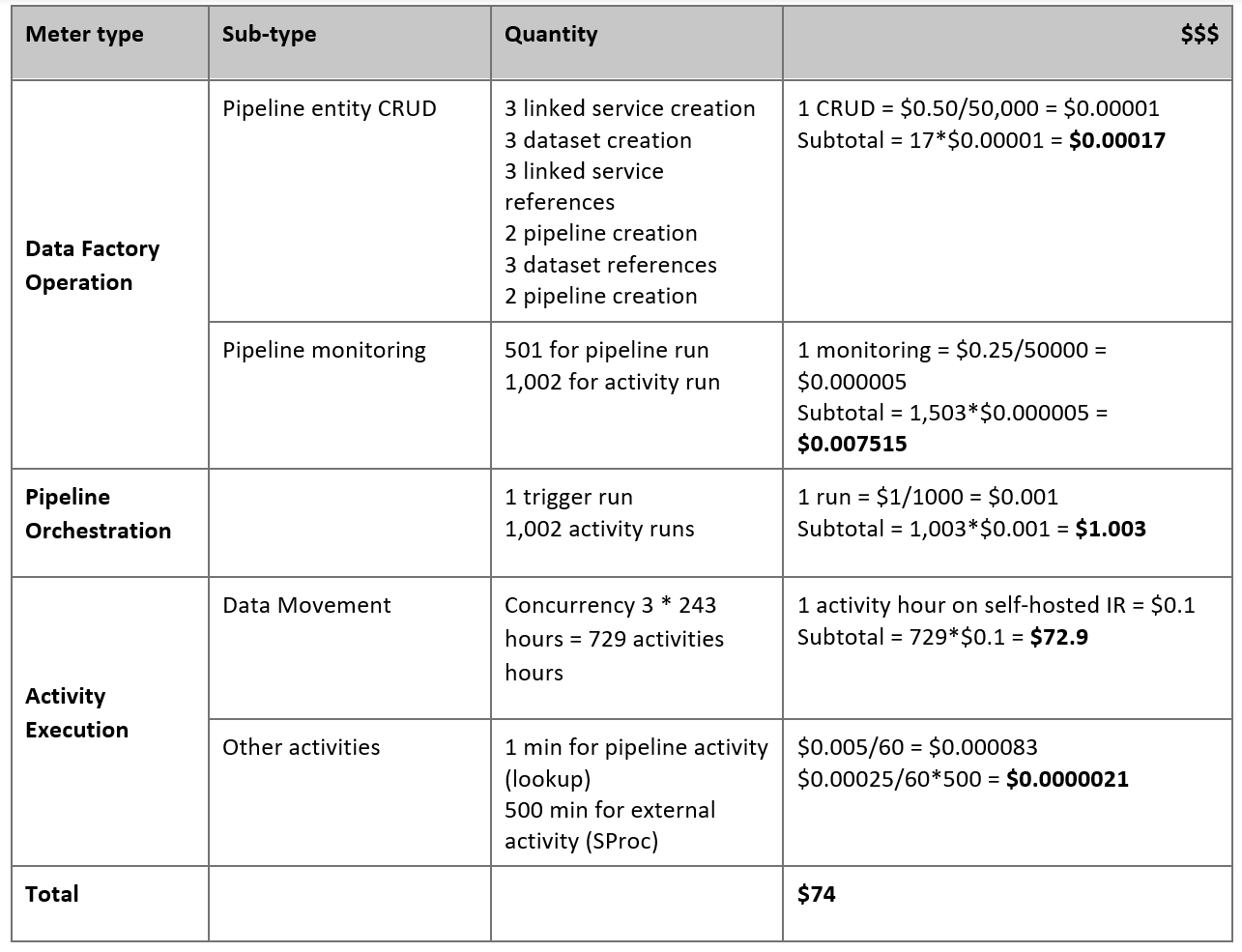
Szacowanie cen
Rozważ następujący potok, który jest skonstruowany w celu migracji danych z lokalnego serwera Netezza do bazy danych usługi Azure Synapse Analytics:
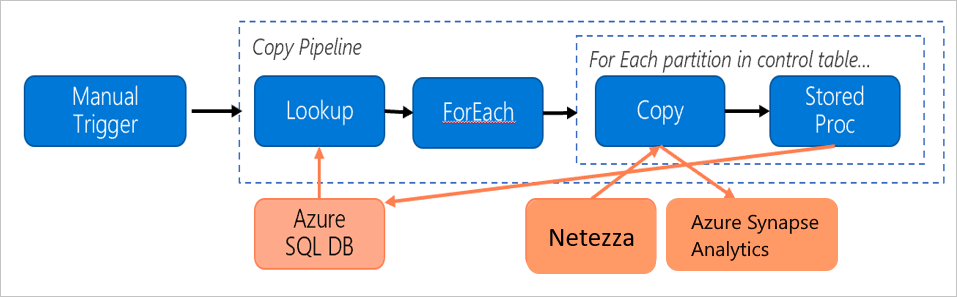
Załóżmy, że następujące instrukcje są prawdziwe:
Łączny wolumin danych to 50 terabajtów (TB).
Migrujemy dane przy użyciu architektury pierwszego rozwiązania (serwer Netezza znajduje się lokalnie za zaporą).
Wolumin 50 TB jest podzielony na 500 partycji, a każde działanie kopiowania przenosi jedną partycję.
Każde działanie kopiowania jest skonfigurowane przy użyciu jednego własnego środowiska IR na czterech maszynach i osiąga przepływność 20 megabajtów na sekundę (MB/s). (W ramach działania
parallelCopieskopiowania jest ustawiona wartość 4, a każdy wątek do ładowania danych z tabeli osiąga przepływność 5 MB/s).Współbieżność forEach jest ustawiona na 3, a zagregowana przepływność wynosi 60 MB/s.
W sumie ukończenie migracji trwa 243 godziny.
Na podstawie powyższych założeń przedstawiono szacowaną cenę:
Uwaga
Ceny pokazane w poprzedniej tabeli są hipotetyczne. Rzeczywiste ceny zależą od rzeczywistej przepływności w danym środowisku. Cena maszyny z systemem Windows (z zainstalowanym własnym środowiskiem IR) nie jest uwzględniana.
Dodatkowa dokumentacja
Aby uzyskać więcej informacji, zobacz następujące artykuły i przewodniki:
- Łącznik Netezza
- Łącznik ODBC
- Łącznik usługi Azure Blob Storage
- Łącznik usługi Azure Data Lake Storage Gen2
- Łącznik usługi Azure Synapse Analytics
- Przewodnik dostosowywania wydajności działanie Kopiuj
- Tworzenie i konfigurowanie własnego środowiska Integration Runtime
- Wysoka dostępność i skalowalność własnego środowiska Integration Runtime
- Zagadnienia dotyczące zabezpieczeń przenoszenia danych
- Przechowywanie poświadczeń w usłudze Azure Key Vault
- Przyrostowe kopiowanie danych z jednej tabeli
- Przyrostowe kopiowanie danych z wielu tabel
- Strona cennika usługi Azure Data Factory