Migrowanie danych z usługi Amazon S3 do usługi Azure Storage przy użyciu usługi Azure Data Factory
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Usługa Azure Data Factory zapewnia wydajny, niezawodny i ekonomiczny mechanizm migracji danych na dużą skalę z usługi Amazon S3 do usługi Azure Blob Storage lub Azure Data Lake Storage Gen2. Ten artykuł zawiera następujące informacje dla inżynierów danych i deweloperów:
- Wydajności
- Odporność kopiowania
- Bezpieczeństwo sieci
- Architektura rozwiązania wysokiego poziomu
- Najlepsze rozwiązania dotyczące implementacji
Wydajność
Usługa ADF oferuje architekturę bezserwerową, która umożliwia równoległość na różnych poziomach, co umożliwia deweloperom tworzenie potoków w celu pełnego wykorzystania przepustowości sieci i liczby operacji we/wy na sekundę magazynu oraz przepustowości w celu zmaksymalizowania przepływności przenoszenia danych dla środowiska.
Klienci pomyślnie zmigrowali petabajty danych składających się z setek milionów plików z usługi Amazon S3 do usługi Azure Blob Storage, przy stałej przepływności 2 GB/s i wyższych.
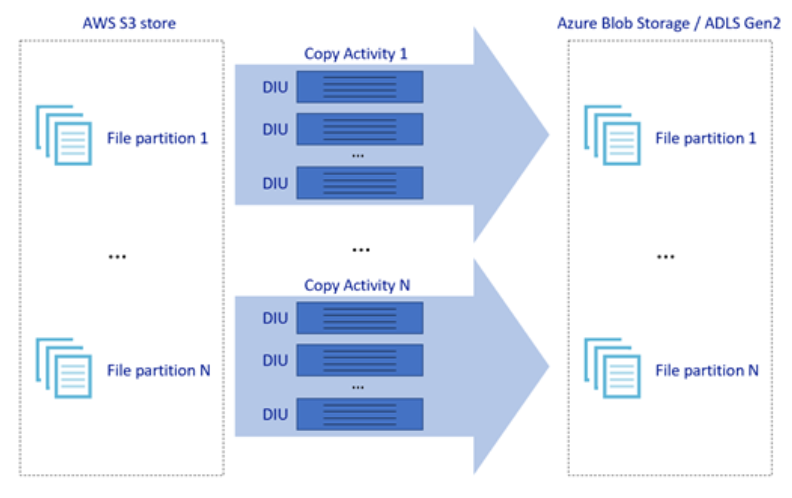
Na powyższym obrazie pokazano, jak można osiągnąć dużą szybkość przenoszenia danych przez różne poziomy równoległości:
- Jedno działanie kopiowania może korzystać ze skalowalnych zasobów obliczeniowych: w przypadku korzystania z środowiska Azure Integration Runtime można określić maksymalnie 256 jednostek DIU dla każdego działania kopiowania w sposób bezserwerowy. W przypadku korzystania z własnego środowiska Integration Runtime można ręcznie skalować maszynę w górę lub skalować w poziomie do wielu maszyn (do czterech węzłów), a jedno działanie kopiowania będzie partycjonować zestaw plików we wszystkich węzłach.
- Jedno działanie kopiowania odczytuje dane i zapisuje je w magazynie danych przy użyciu wielu wątków.
- Przepływ sterowania usługi ADF może uruchamiać wiele działań kopiowania równolegle, na przykład za pomocą pętli For Each.
Odporność
W ramach jednego uruchomienia działania kopiowania usługa ADF ma wbudowany mechanizm ponawiania prób, dzięki czemu może obsługiwać określony poziom przejściowych błędów w magazynach danych lub w sieci bazowej.
Podczas kopiowania binarnego z S3 do obiektu blob i z S3 do usługi ADLS Gen2 usługa ADF automatycznie wykonuje tworzenie punktów kontrolnych. Jeśli uruchomienie działania kopiowania nie powiodło się lub upłynął limit czasu, po kolejnym ponowieniu próby kopia zostanie wznowiona z ostatniego punktu awarii zamiast rozpoczynać się od początku.
Bezpieczeństwo sieci
Domyślnie usługa ADF przesyła dane z usługi Amazon S3 do usługi Azure Blob Storage lub Azure Data Lake Storage Gen2 przy użyciu szyfrowanego połączenia za pośrednictwem protokołu HTTPS. Protokół HTTPS zapewnia szyfrowanie danych podczas przesyłania i uniemożliwia podsłuchiwanie i ataki typu man-in-the-middle.
Alternatywnie, jeśli nie chcesz, aby dane zostały przesłane za pośrednictwem publicznego Internetu, możesz uzyskać większe bezpieczeństwo, przesyłając dane za pośrednictwem prywatnego połączenia komunikacji równorzędnej między usługami AWS Direct Połączenie i Azure Express Route. Zapoznaj się z architekturą rozwiązania w następnej sekcji, aby dowiedzieć się, jak można to osiągnąć.
Architektura rozwiązania
Migrowanie danych za pośrednictwem publicznego Internetu:
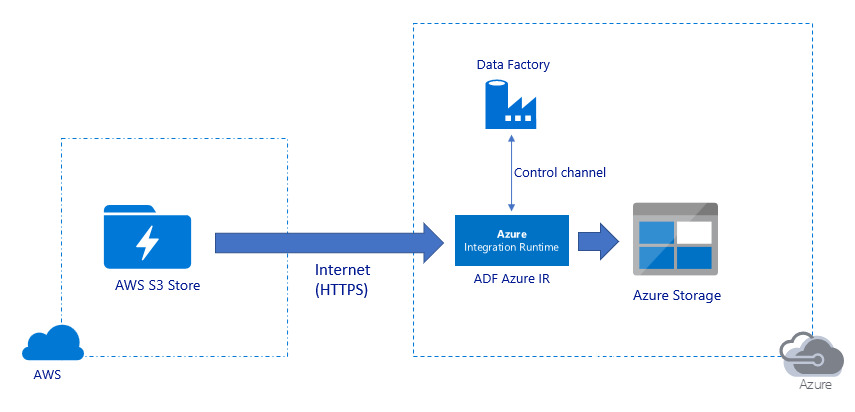
- W tej architekturze dane są bezpiecznie przesyłane przy użyciu protokołu HTTPS za pośrednictwem publicznego Internetu.
- Zarówno źródłowa usługa Amazon S3, jak i docelowa usługa Azure Blob Storage lub Azure Data Lake Storage Gen2 są skonfigurowane tak, aby zezwalać na ruch ze wszystkich adresów IP sieci. Zapoznaj się z drugą architekturą, do której odwołujesz się w dalszej części tej strony, aby dowiedzieć się, jak ograniczyć dostęp sieciowy do określonego zakresu adresów IP.
- Możesz łatwo skalować w górę ilość koni mechanicznych w sposób bezserwerowy, aby w pełni wykorzystać sieć i przepustowość magazynu, dzięki czemu można uzyskać najlepszą przepływność dla środowiska.
- Przy użyciu tej architektury można osiągnąć zarówno początkową migrację migawek, jak i migrację danych różnicowych.
Migrowanie danych za pośrednictwem łącza prywatnego:
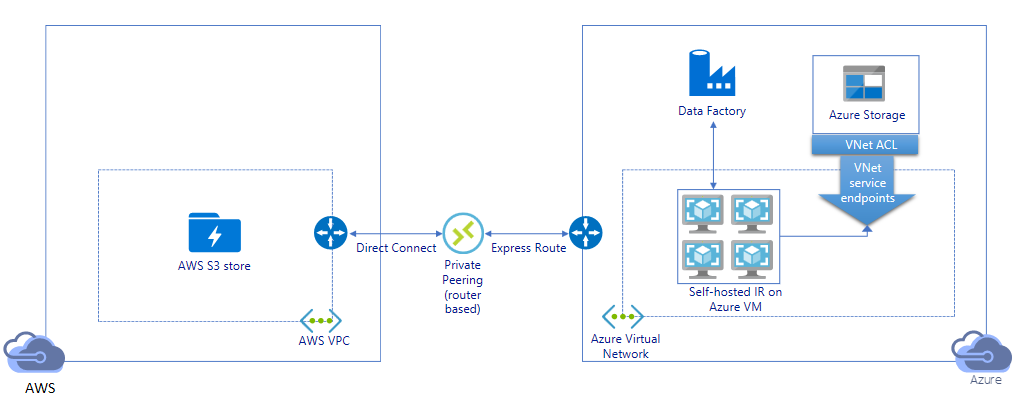
- W tej architekturze migracja danych odbywa się za pośrednictwem prywatnego połączenia komunikacji równorzędnej między usługami AWS Direct Połączenie i Azure Express Route, tak aby dane nigdy nie przechodziły przez publiczny Internet. Wymaga ona użycia usługi AWS VPC i sieci wirtualnej platformy Azure.
- Aby osiągnąć tę architekturę, musisz zainstalować własne środowisko Integration Runtime usługi ADF na maszynie wirtualnej z systemem Windows w sieci wirtualnej platformy Azure. Możesz ręcznie skalować w górę własne maszyny wirtualne IR lub skalować w poziomie do wielu maszyn wirtualnych (do czterech węzłów), aby w pełni wykorzystać operacje we/wy na sekundę/przepustowość sieci i magazynu.
- Migracja danych migawek początkowych i migracja danych różnicowych można osiągnąć przy użyciu tej architektury.
Najlepsze rozwiązania dotyczące implementacji
Uwierzytelnianie i zarządzanie poświadczeniami
- Aby uwierzytelnić się na koncie usługi Amazon S3, musisz użyć klucza dostępu dla konta IAM.
- Wiele typów uwierzytelniania jest obsługiwanych w celu nawiązania połączenia z usługą Azure Blob Storage. Korzystanie z tożsamości zarządzanych dla zasobów platformy Azure jest zdecydowanie zalecane: oparte na automatycznie zarządzanej tożsamości usługi ADF w identyfikatorze Entra firmy Microsoft umożliwia konfigurowanie potoków bez podawania poświadczeń w definicji połączonej usługi. Alternatywnie możesz uwierzytelnić się w usłudze Azure Blob Storage przy użyciu jednostki usługi, sygnatury dostępu współdzielonego lub klucza konta magazynu.
- Wiele typów uwierzytelniania jest również obsługiwanych w celu nawiązania połączenia z usługą Azure Data Lake Storage Gen2. Korzystanie z tożsamości zarządzanych dla zasobów platformy Azure jest zdecydowanie zalecane, chociaż można również użyć klucza jednostki usługi lub konta magazynu.
- Jeśli nie używasz tożsamości zarządzanych dla zasobów platformy Azure, przechowywanie poświadczeń w usłudze Azure Key Vault jest zdecydowanie zalecane, aby ułatwić centralne zarządzanie kluczami i obracanie ich bez modyfikowania połączonych usług ADF. Jest to również jedno z najlepszych rozwiązań dotyczących ciągłej integracji/ciągłego wdrażania.
Początkowa migracja danych migawek
Partycja danych jest zalecana szczególnie w przypadku migrowania ponad 100 TB danych. Aby podzielić dane na partycje, użyj ustawienia "prefiks", aby filtrować foldery i pliki w usłudze Amazon S3 według nazwy, a następnie każde zadanie kopiowania usługi ADF może skopiować jedną partycję naraz. W celu uzyskania lepszej przepływności można jednocześnie uruchamiać wiele zadań kopiowania usługi ADF.
Jeśli którekolwiek z zadań kopiowania nie powiedzie się z powodu przejściowego problemu z siecią lub magazynem danych, możesz ponownie uruchomić zadanie kopiowania, aby ponownie załadować tę konkretną partycję z usługi AWS S3. Nie będzie to miało wpływu na wszystkie inne zadania kopiowania ładując inne partycje.
Migracja danych różnicowych
Najbardziej wydajnym sposobem identyfikowania nowych lub zmienionych plików z usługi AWS S3 jest użycie konwencji nazewnictwa partycjonowanego czasowo — gdy dane w usłudze AWS S3 zostały podzielone na partycje z informacjami o wycinkach czasu w nazwie pliku lub folderu (na przykład /rrrr/mm/dd/file.csv), potok może łatwo zidentyfikować pliki/foldery, które mają być kopiowane przyrostowo.
Alternatywnie, jeśli dane w usłudze AWS S3 nie są partycjonowane, usługa ADF może identyfikować nowe lub zmienione pliki według ich daty ostatniej modyfikacji. W ten sposób usługa ADF skanuje wszystkie pliki z usługi AWS S3 i kopiuje tylko nowy i zaktualizowany plik, którego znacznik czasu ostatniej modyfikacji jest większy niż określona wartość. Jeśli masz dużą liczbę plików w usłudze S3, początkowe skanowanie plików może zająć dużo czasu niezależnie od tego, ile plików jest zgodnych z warunkiem filtru. W takim przypadku zaleca się najpierw partycjonowanie danych przy użyciu tego samego ustawienia "prefiksu" na potrzeby migracji początkowej migawki, aby skanowanie plików mogło nastąpić równolegle.
W przypadku scenariuszy wymagających własnego środowiska Integration Runtime na maszynie wirtualnej platformy Azure
Niezależnie od tego, czy migrujesz dane za pośrednictwem łącza prywatnego, czy chcesz zezwolić na określony zakres adresów IP w zaporze amazon S3, musisz zainstalować własne środowisko Integration Runtime na maszynie wirtualnej z systemem Windows platformy Azure.
- Zalecana konfiguracja do rozpoczęcia od dla każdej maszyny wirtualnej platformy Azure jest Standard_D32s_v3 z 32 procesorami wirtualnymi i 128 GB pamięci. W trakcie migracji danych można monitorować użycie procesora CPU i pamięci maszyny wirtualnej ir, aby sprawdzić, czy konieczne jest dalsze skalowanie maszyny wirtualnej w górę w celu uzyskania lepszej wydajności lub skalowania maszyny wirtualnej w dół, aby zmniejszyć koszty.
- Można również skalować w poziomie, kojarząc maksymalnie cztery węzły maszyn wirtualnych z jednym własnym środowiskiem IR. Jedno zadanie kopiowania uruchomione względem własnego środowiska IR automatycznie partycjonuje zestaw plików i użyje wszystkich węzłów maszyny wirtualnej do równoległego kopiowania plików. W celu zapewnienia wysokiej dostępności zaleca się rozpoczęcie pracy z dwoma węzłami maszyny wirtualnej, aby uniknąć pojedynczego punktu awarii podczas migracji danych.
Rate limiting (Ograniczanie szybkości)
Najlepszym rozwiązaniem jest przeprowadzenie weryfikacji koncepcji wydajności przy użyciu reprezentatywnego przykładowego zestawu danych, dzięki czemu można określić odpowiedni rozmiar partycji.
Zacznij od pojedynczej partycji i pojedynczego działania kopiowania z domyślnym ustawieniem jednostki DIU. Stopniowo zwiększaj ustawienie jednostek DIU do momentu osiągnięcia limitu przepustowości sieci lub limitu liczby operacji we/wy na sekundę/przepustowości magazynów danych lub osiągnięto maksymalną liczbę 256 jednostek DIU dozwolonych w ramach pojedynczego działania kopiowania.
Następnie stopniowo zwiększa liczbę współbieżnych działań kopiowania do momentu osiągnięcia limitów środowiska.
W przypadku wystąpienia błędów ograniczania przepustowości zgłoszonych przez działanie kopiowania usługi ADF zmniejsz ustawienie współbieżności lub jednostek DIU w usłudze ADF lub rozważ zwiększenie limitów przepustowości/liczby operacji we/wy na sekundę sieci i magazynów danych.
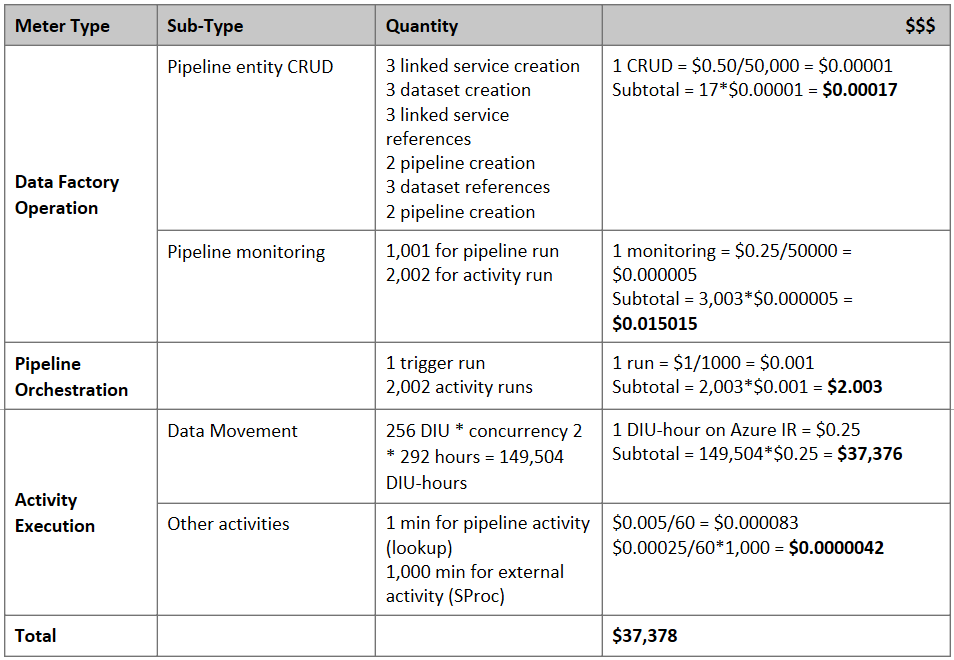
Szacowanie ceny
Uwaga
Jest to hipotetyczny przykład cen. Rzeczywiste ceny zależą od rzeczywistej przepływności w danym środowisku.
Rozważmy następujący potok skonstruowany do migrowania danych z usługi S3 do usługi Azure Blob Storage:
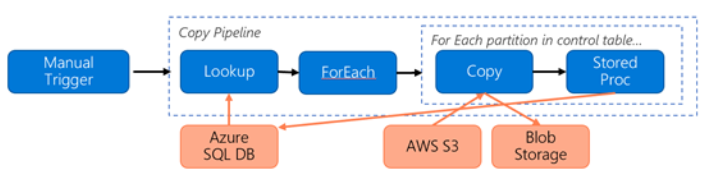
Załóżmy, że:
- Łączna ilość danych to 2 PB
- Migrowanie danych za pośrednictwem protokołu HTTPS przy użyciu pierwszej architektury rozwiązania
- 2 PB jest podzielony na 1 KB partycji, a każda kopia przenosi jedną partycję
- Każda kopia jest skonfigurowana przy użyciu jednostki DIU=256 i osiąga przepływność 1 GB/s
- Współbieżność forEach jest ustawiona na 2, a zagregowana przepływność wynosi 2 GB/s
- W sumie ukończenie migracji trwa 292 godziny
Poniżej przedstawiono szacowaną cenę opartą na powyższych założeniach:
Dodatkowa dokumentacja
- Łącznik usługi Amazon Simple Storage Service
- Łącznik usługi Azure Blob Storage
- Łącznik usługi Azure Data Lake Storage Gen2
- Przewodnik dostosowywania wydajności działanie Kopiuj
- Tworzenie i konfigurowanie własnego środowiska Integration Runtime
- Wysoka dostępność i skalowalność własnego środowiska Integration Runtime
- Zagadnienia dotyczące zabezpieczeń przenoszenia danych
- Przechowywanie poświadczeń w usłudze Azure Key Vault
- Kopiowanie pliku przyrostowo na podstawie nazwy pliku partycjonowanego czasowo
- Kopiowanie nowych i zmienionych plików na podstawie daty ostatniej modyfikacji
- Strona cennika usługi ADF
Szablon
Oto szablon, z który należy zacząć od migracji petabajtów danych składających się z setek milionów plików z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2.