Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Szukasz łatwego sposobu przenoszenia danych? Zadanie kopiowania w usłudze Microsoft Fabric zapewnia prosty, skalowalny sposób ładowania danych bez tworzenia potoku. Dowiedz się, jak go utworzyć.
W tym samouczku pokazano kopiowanie wielu tabel z usługi Azure SQL Database do usługi Azure Synapse Analytics. Tego samego wzorca można użyć także w innych scenariuszach kopiowania. Na przykład kopiowanie tabel z programu SQL Server/Oracle do usługi Azure SQL Database/Azure Synapse Analytics /Azure Blob, kopiowanie różnych ścieżek z obiektu blob do tabel usługi Azure SQL Database.
Uwaga
Jeśli dopiero zaczynasz korzystać z usługi Azure Data Factory, zobacz Wprowadzenie do usługi Azure Data Factory.
Na poziomie ogólnym ten samouczek obejmuje następujące kroki:
- Tworzenie fabryki danych.
- Tworzenie połączonych usług Azure SQL Database, Azure Synapse Analytics i Azure Storage.
- Tworzenie zestawów danych usługi Azure SQL Database i Azure Synapse Analytics.
- Utwórz potok do wyszukiwania tabel do skopiowania i inny potok do wykonania operacji kopiowania.
- Uruchom potok.
- Monitoruj potok i uruchomienia działań.
W tym samouczku używany jest Azure portal. Aby dowiedzieć się więcej na temat tworzenia fabryki danych używając innych narzędzi lub zestawów SDK, zobacz Szybki start.
Kompletny przepływ pracy
W tym scenariuszu istnieje wiele tabel w usłudze Azure SQL Database, które chcesz skopiować do usługi Azure Synapse Analytics. Oto sekwencja logiczna kroków przepływu pracy, który następuje w potokach:

- Pierwszy potok danych wyszukuje listę tabel danych, które należy skopiować do docelowych magazynów danych. Alternatywnie można utrzymywać tabelę metadanych, która zawiera listę wszystkich tabel do skopiowania do magazynu danych ujścia. Następnie potok wywołuje inny potok, który iteruje przez każdą tabelę w bazie danych i wykonuje operację kopiowania danych.
- Drugi pipeline wykonuje rzeczywiste kopiowanie. Pobiera listę tabel jako parametr. Dla każdej tabeli na liście skopiuj określoną tabelę w usłudze Azure SQL Database do odpowiedniej tabeli w usłudze Azure Synapse Analytics przy użyciu kopii etapowej za pośrednictwem usługi Blob Storage i technologii PolyBase , aby uzyskać najlepszą wydajność. W tym przykładzie pierwszy pipeline przekazuje listę tabel jako wartość parametru.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto .
Wymagania wstępne
- Konto usługi Azure Storage. Konto usługi Azure Storage jest używane jako przejściowy magazyn obiektów blob w operacji kopiowania zbiorczego.
- Azure SQL Database. Ta baza danych zawiera dane źródłowe. Tworzenie bazy danych w usłudze SQL Database przy użyciu przykładowych danych Adventure Works LT poniżej artykułu Tworzenie bazy danych w usłudze Azure SQL Database . Ten samouczek kopiuje wszystkie tabele z tej przykładowej bazy danych do usługi Azure Synapse Analytics.
- Azure Synapse Analytics. Ten magazyn danych służy do przechowywania danych skopiowanych z bazy SQL Database. Jeśli nie masz obszaru roboczego usługi Azure Synapse Analytics, zobacz artykuł Rozpoczynanie pracy z usługą Azure Synapse Analytics , aby uzyskać instrukcje tworzenia.
Usługi platformy Azure umożliwiające dostęp do serwera SQL
W przypadku usług SQL Database i Azure Synapse Analytics zezwól usługom platformy Azure na dostęp do serwera SQL. Upewnij się, że ustawienie Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwerajest włączone. To ustawienie umożliwia usłudze Data Factory odczytywanie danych z usługi Azure SQL Database i zapisywanie danych w usłudze Azure Synapse Analytics.
Aby sprawdzić i włączyć to ustawienie, przejdź do pozycji > Zapory i wirtualne sieci > serwera >, ustaw Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera na WŁĄCZONE.
Tworzenie fabryki danych
Uruchom przeglądarkę internetową Microsoft Edge lub Google Chrome . Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko przez przeglądarki internetowe Microsoft Edge i Google Chrome.
Przejdź do witryny Azure Portal.
W górnym menu wybierz pozycję Utwórz zasób>Analityka>Fabryka Danych :
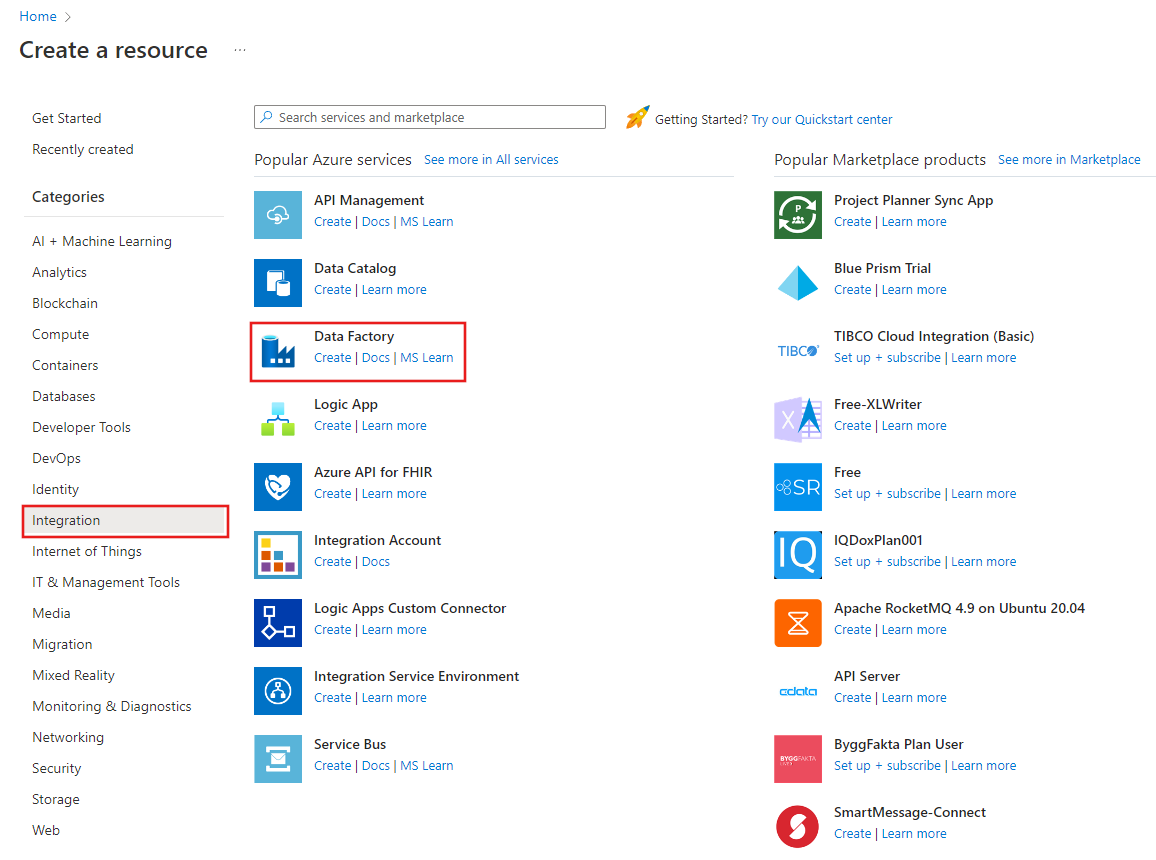
Na stronie Nowa fabryka danych wprowadź nazwę ADFTutorialBulkCopyDF.
Nazwa fabryki danych Azure musi być globalnie unikatowa. Jeśli dla pola nazwy wystąpi poniższy błąd, zmień nazwę fabryki danych (np. twojanazwaADFTutorialBulkCopyDF). Zobacz artykuł Data Factory — Reguły nazewnictwa , aby zapoznać się z regułami nazewnictwa artefaktów usługi Data Factory.
Data factory name "ADFTutorialBulkCopyDF" is not availableWybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W przypadku grupy zasobów wykonaj jedną z następujących czynności:
Wybierz pozycję Użyj istniejącej i wybierz istniejącą grupę zasobów z listy rozwijanej.
Wybierz pozycję Utwórz nową i wprowadź nazwę grupy zasobów.
Aby dowiedzieć się więcej o grupach zasobów, zobacz Używanie grup zasobów do zarządzania zasobami platformy Azure.
Wybierz wersjęV2.
Wybierz lokalizację fabryki danych. Aby uzyskać listę regionów świadczenia usługi Azure, w których usługa Data Factory jest obecnie dostępna, wybierz interesujące Cię regiony na poniższej stronie, a następnie rozwiń węzeł Analiza , aby zlokalizować usługę Data Factory: produkty dostępne według regionów. Magazyny danych (Azure Storage, Azure SQL Database itp.) i jednostki obliczeniowe (HDInsight itp.) używane przez fabrykę danych mogą mieścić się w innych regionach.
Kliknij pozycję Utwórz.
Po zakończeniu tworzenia wybierz pozycję Przejdź do zasobu , aby przejść do strony Fabryka danych .
Wybierz Otwórz na kafelku Open Azure Data Factory Studio, aby uruchomić aplikację Data Factory UI na osobnej karcie.
Tworzenie połączonych usług
Połączone usługi są tworzone w celu połączenia magazynów danych i obliczeń z fabryką danych. Usługa połączona zawiera informacje o połączeniu, które usługa Data Factory wykorzystuje do łączenia się z magazynem danych podczas działania.
W tym samouczku połączysz magazyny danych usługi Azure SQL Database, Azure Synapse Analytics i Azure Blob Storage z fabryką danych. Azure SQL Database to źródłowy magazyn danych. Usługa Azure Synapse Analytics to magazyn danych będący ujściem/docelowym. Usługa Azure Blob Storage umożliwia przygotowanie danych przed załadowaniem danych do usługi Azure Synapse Analytics przy użyciu technologii PolyBase.
Tworzenie źródłowej połączonej usługi Azure SQL Database
W tym kroku utworzysz połączoną usługę, aby połączyć bazę danych w usłudze Azure SQL Database z fabryką danych.
Otwórz kartę Zarządzaj w okienku po lewej stronie.
Na stronie Połączone usługi wybierz pozycję +Nowy , aby utworzyć nową połączoną usługę.
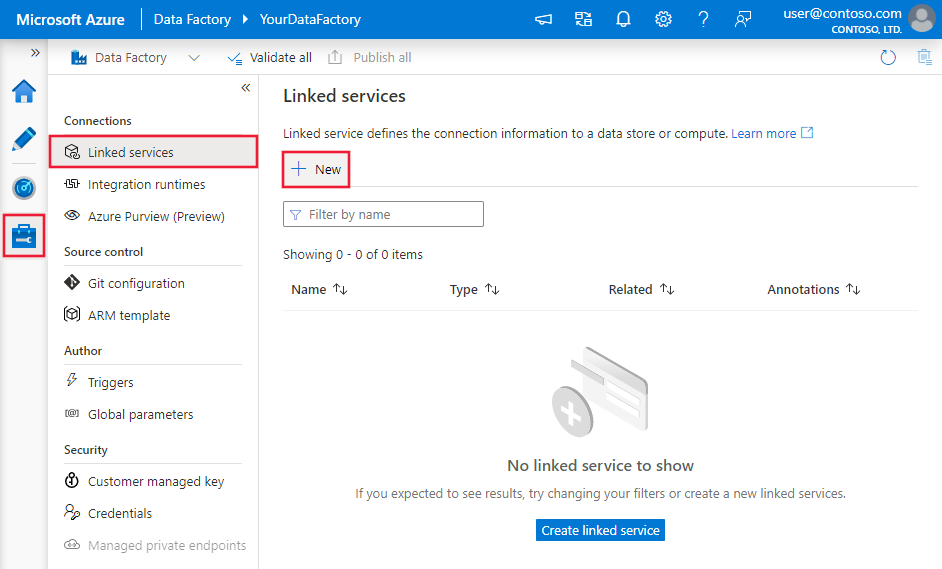
W oknie Nowa połączona usługa wybierz pozycję Azure SQL Database, a następnie kliknij przycisk Kontynuuj.
W oknie Nowa połączona usługa (Azure SQL Database) wykonaj następujące czynności:
a. Wprowadź AzureSqlDatabaseLinkedService jako Nazwa.
b. Wybierz swój serwer dla nazwa serwera
c. Wybierz swoją bazę danych dla nazwy bazy danych.
d. Wprowadź nazwę użytkownika, aby nawiązać połączenie z bazą danych.
e. Wprowadź hasło użytkownika.
f. Aby przetestować połączenie z bazą danych przy użyciu określonych informacji, kliknij pozycję Testuj połączenie.
g. Kliknij przycisk Utwórz , aby zapisać połączoną usługę.
Tworzenie połączonej usługi Azure Synapse Analytics ujścia
Na karcie Połączenia ponownie kliknij pozycję + Nowy na pasku narzędzi.
W oknie Nowa połączona usługa wybierz pozycję Azure Synapse Analytics, a następnie kliknij przycisk Kontynuuj.
W oknie Nowa połączona usługa (Azure Synapse Analytics) wykonaj następujące czynności:
a. Wprowadź AzureSqlDWLinkedService dla Nazwa.
b. Wybierz swój serwer dla nazwa serwera
c. Wybierz swoją bazę danych dla nazwy bazy danych.
d. Wprowadź nazwę użytkownika , aby nawiązać połączenie z bazą danych.
e. Wprowadź hasło dla użytkownika.
f. Aby przetestować połączenie z bazą danych przy użyciu określonych informacji, kliknij pozycję Testuj połączenie.
g. Kliknij pozycję Utwórz.
Tworzenie przejściowej połączonej usługi Azure Storage
W tym samouczku magazyn obiektów blob platformy Azure służy jako obszar przejściowy, pozwalający na włączenie programu PolyBase w celu podniesienia wydajności kopiowania.
Na karcie Połączenia ponownie kliknij pozycję + Nowy na pasku narzędzi.
W oknie Nowa połączona usługa wybierz pozycję Azure Blob Storage, a następnie kliknij przycisk Kontynuuj.
W oknie Nowa połączona usługa (Azure Blob Storage) wykonaj następujące czynności:
a. Wpisz AzureStorageLinkedService dla Nazwa.
b. Wybierz konto usługi Azure Storage jako nazwę konta usługi Storage.c. Kliknij pozycję Utwórz.
Tworzenie zestawów danych
W tym samouczku utworzysz zestawy danych źródłowych i docelowych, które określają lokalizację przechowywania danych.
Wejściowy zestaw danych AzureSqlDatabaseDataset odnosi się do elementu AzureSqlDatabaseLinkedService. Połączona usługa określa parametry połączenia w celu nawiązania połączenia z bazą danych. Zestaw danych określa nazwę bazy danych i tabelę, która zawiera dane źródłowe.
Wyjściowy zestaw danych AzureSqlDWDataset odnosi się do elementu AzureSqlDWLinkedService. Połączona usługa określa parametry połączenia, aby nawiązać połączenie z usługą Azure Synapse Analytics. Zestaw danych określa bazę danych i tabelę, do którego dane są kopiowane.
W tym samouczku źródłowe i docelowe tabele SQL nie są ustalone w definicjach zestawów danych. Zamiast tego działanie ForEach przekazuje w czasie wykonywania nazwę tabeli do działania kopiowania.
Tworzenie zestawu danych źródłowej bazy danych SQL Database
Wybierz kartę Autor w okienku po lewej stronie.
Wybierz ikonę + (plus) w okienku po lewej stronie, a następnie wybierz pozycję Zestaw danych.
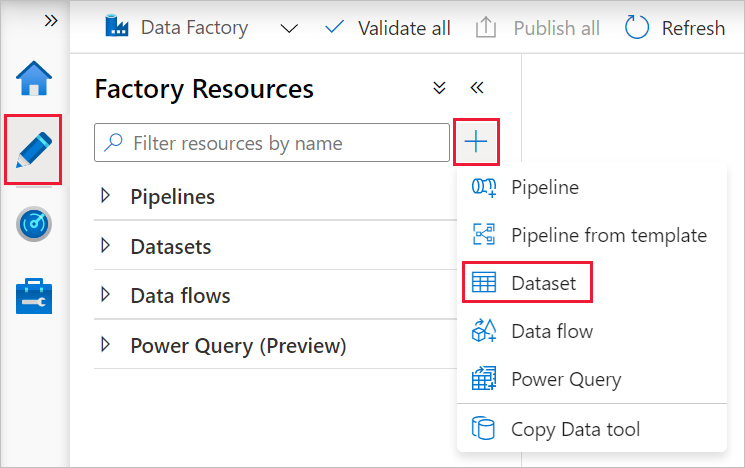
W oknie Nowy zestaw danych wybierz pozycję Azure SQL Database, a następnie kliknij przycisk Kontynuuj.
W oknie Właściwości w obszarze Nazwa wprowadź AzureSqlDatabaseDataset. W obszarze Połączona usługa wybierz pozycję AzureSqlDatabaseLinkedService. Następnie kliknij przycisk OK.
Przejdź do karty Połączenie, wybierz dowolną tabelę jako Table. Jest to tabela przykładowa. Określasz zapytanie dotyczące źródłowego zestawu danych podczas tworzenia potoku. Zapytanie służy do wyodrębniania danych z bazy danych. Alternatywnie możesz kliknąć pole wyboru Edytuj i wprowadzić dbo.dummyName jako nazwę tabeli.
Tworzenie zestawu danych dla docelowego systemu Azure Synapse Analytics
Kliknij pozycję + (plus) w okienku po lewej stronie, a następnie kliknij pozycję Zestaw danych.
W oknie Nowy zestaw danych wybierz pozycję Azure Synapse Analytics, a następnie kliknij przycisk Kontynuuj.
W oknie Ustawianie właściwości w obszarze Nazwa wprowadź AzureSqlDWDataset. W obszarze Połączona usługa wybierz pozycję AzureSqlDWLinkedService. Następnie kliknij przycisk OK.
Przejdź do karty Parametry, kliknij + Nowy, a następnie wprowadź DWTableName jako nazwę parametru. Kliknij ponownie pozycję + Nowy i wprowadź ciąg DWSchema jako nazwę parametru. Kopiując/wklejając tę nazwę ze strony, upewnij się, że na końcu DWTableName i DWSchema nie ma znaku spacji końcowej.
Przejdź do karty Połączenie
W obszarze Tabela zaznacz opcję Edytuj . Wybierz pierwsze pole wejściowe i kliknij link Dodaj zawartość dynamiczną poniżej. Na stronie Dodawanie zawartości dynamicznej kliknij pozycję DWSchema w obszarze Parametry, co spowoduje automatyczne wypełnienie górnego pola tekstowego wyrażenia
@dataset().DWSchema, a następnie kliknij przycisk Zakończ.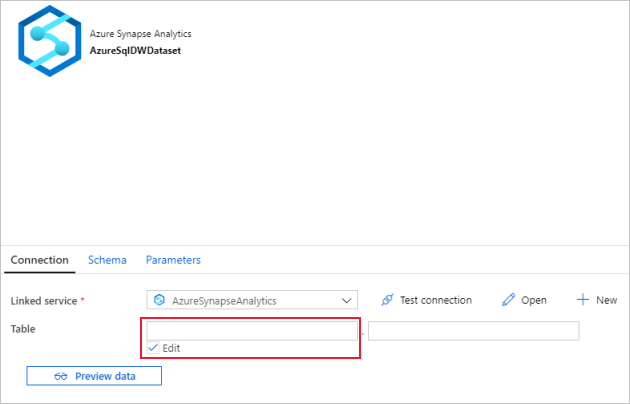
Wybierz drugie pole wejściowe i kliknij link Dodaj zawartość dynamiczną poniżej. Na stronie Dodawanie zawartości dynamicznej kliknij pozycję DWTAbleName w obszarze Parametry, co spowoduje automatyczne wypełnienie górnego pola
@dataset().DWTableNametekstowego wyrażenia , a następnie kliknij przycisk Zakończ.Właściwość tableName zestawu danych jest ustawiona na wartości, które są przekazywane jako argumenty dla parametrów DWSchema i DWTableName . Działanie ForEach iteruje w obrębie listy tabel i przekazuje je po jednej do działania Copy.
Tworzenie potoków
W tym samouczku utworzysz dwa potoki: IterateAndCopySQLTables oraz GetTableListAndTriggerCopyData.
Potok GetTableListAndTriggerCopyData wykonuje dwie akcje:
- Wyszukuje tabelę systemową bazy Azure SQL Database w celu pobrania listy tabel do skopiowania.
- Wyzwala potok IterateAndCopySQLTables w celu faktycznego kopiowania danych.
Potok IterateAndCopySQLTables przyjmuje listę tabel jako parametr. Dla każdej tabeli na liście kopiuje dane z tabeli w usłudze Azure SQL Database do usługi Azure Synapse Analytics przy użyciu kopiowania etapowego i technologii PolyBase.
Utwórz potok IterateAndCopySQLTables
W okienku po lewej stronie kliknij + (plus), a następnie kliknij Rurociąg.
W panelu Ogólne w obszarze Właściwości określ wartość IterateAndCopySQLTables w polu Nazwa. Następnie zwiń panel, klikając ikonę Właściwości w prawym górnym rogu.
Przejdź do karty Parametry i wykonaj następujące czynności:
a. Kliknij pozycję + Nowy.
b. Wprowadź tableList jako nazwę parametru.
c. Wybierz Tablica dla Typ.
W przyborniku Działania rozwiń kategorię Iteracja i warunki, a następnie przeciągnij i upuść działanie ForEach na obszar projektowania potoku. Możesz również wyszukać działania w przyborniku Działania .
a. Na karcie Ogólne w dolnej części wprowadź IterateSQLTables w polu Nazwa.
b. Przejdź do karty Ustawienia , kliknij pole wejściowe dla pozycji Elementy, a następnie kliknij link Dodaj zawartość dynamiczną poniżej.
c. Na stronie Dodawanie zawartości dynamicznej zwiń sekcje Zmienne systemowe i Funkcje kliknij tabelęLista w obszarze Parametry, co spowoduje automatyczne wypełnienie pola tekstowego wyrażenia górnego jako
@pipeline().parameter.tableList. Następnie kliknij przycisk Zakończ.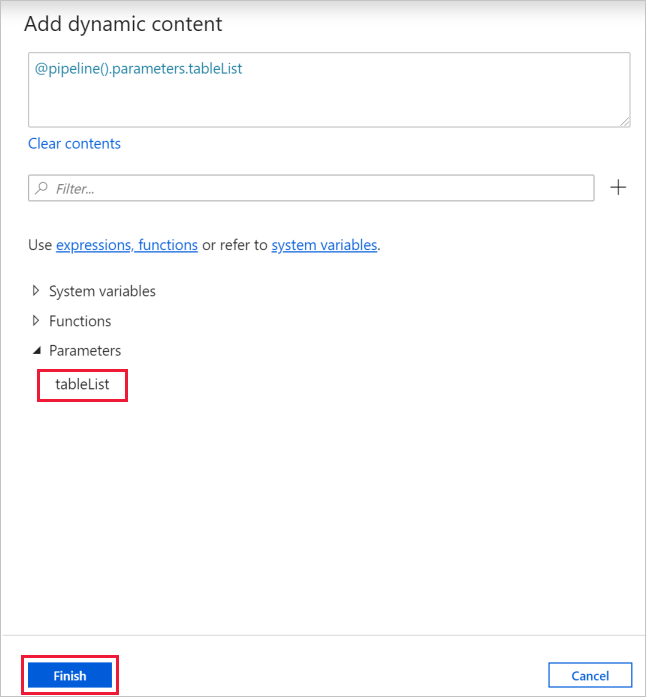
d. Przejdź do karty Działania, a następnie kliknij ikonę ołówka, aby dodać działanie podrzędne do działania ForEach.
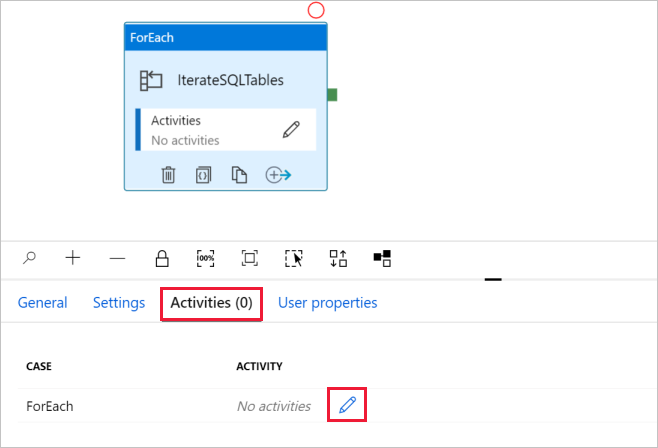
W przyborniku Działania, rozwiń pozycję Przesuń i przenieś i przeciągnij oraz upuść akcję Kopiuj dane na obszarze projektanta potoku. Zwróć uwagę na menu linków do stron nadrzędnych w górnej części. IterateAndCopySQLTable jest nazwą potoku, a IterateSQLTables to nazwa działania ForEach. Projektant należy do zakresu działania. Aby wrócić do edytora potoków z edytora ForEach, możesz kliknąć link w nawigacji ścieżkowej.
Przejdź do karty Źródło i wykonaj następujące czynności:
Wybierz AzureSqlDatabaseDataset dla Źródłowego zestawu danych.
Wybierz opcję Zapytanie dla opcji Użyj zapytania.
Kliknij pole Wprowadzanie zapytania —> wybierz pozycję Dodaj zawartość dynamiczną poniżej —> wprowadź następujące wyrażenie dla pozycji Zapytanie —> wybierz pozycję Zakończ.
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
Przejdź do karty Ujście i wykonaj następujące czynności:
Wybierz AzureSqlDWDataset dla zestawu danych Sink.
Kliknij pole wejściowe dla parametru VALUE DWTableName, wybierz opcję > poniżej, wprowadź wyrażenie jako skrypt, wybierz Zakończ.
Kliknij pole wejściowe dla wartości parametru DWSchema —> wybierz pozycję Dodaj zawartość dynamiczną poniżej, wprowadź
@item().TABLE_SCHEMAwyrażenie jako skrypt—> wybierz pozycję Zakończ.W polu Metoda kopiowania wybierz pozycję PolyBase.
Wyczyść opcję Użyj typu domyślnego .
Domyślne ustawienie dla opcji Tabela to "Brak". Jeśli nie masz wstępnie utworzonych tabel w ujściu usługi Azure Synapse Analytics, włącz opcję Automatyczne tworzenie tabeli , a następnie działanie kopiowania automatycznie utworzy tabele na podstawie danych źródłowych. Aby uzyskać szczegółowe informacje, zobacz Automatyczne tworzenie tabel ujścia.
Kliknij pole wprowadzania skryptu wstępnego —> wybierz pozycję Dodaj zawartość dynamiczną poniżej — wprowadź następujące wyrażenie jako skrypt —>> wybierz pozycję Zakończ.
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]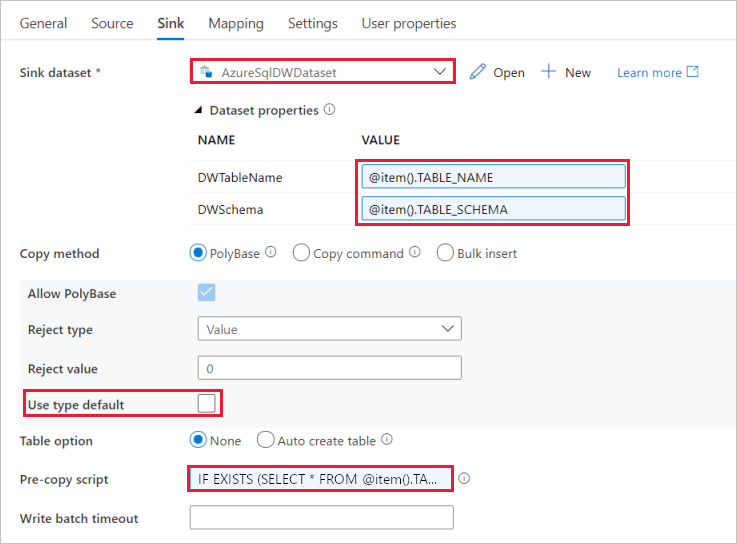
Przejdź do karty Ustawienia i wykonaj następujące czynności:
- Zaznacz pole wyboru włącz etapowanie.
- Wybierz pozycję AzureStorageLinkedService dla połączonej usługi konta sklepu.
Aby zweryfikować ustawienia potoku, kliknij pozycję Weryfikuj na górnym pasku narzędzi potoku. Upewnij się, że nie ma błędu walidacji. Aby zamknąć raport weryfikacji potoku, kliknij podwójne nawiasy kątowe >>.
Utwórz potok GetTableListAndTriggerCopyData
Ten potok przetwarzania wykonuje dwa działania:
- Wyszukuje tabelę systemową bazy Azure SQL Database w celu pobrania listy tabel do skopiowania.
- Wyzwala potok „IterateAndCopySQLTables”, aby faktycznie wykonać kopiowanie danych.
Oto kroki tworzenia przepływu danych:
W okienku po lewej stronie kliknij + (plus), a następnie kliknij Rurociąg.
W panelu Ogólne w obszarze Właściwości zmień nazwę potoku na GetTableListAndTriggerCopyData.
W narzędziowniku Aktywności rozwiń pozycję Ogólne, a następnie przeciągnij i upuść akcję Lookup na powierzchnię projektanta potoku i wykonaj następujące czynności:
- Wprowadź LookupTableList dla Nazwa.
- Wprowadź Pobierz listę tabel z mojej bazy danych w polu Opis.
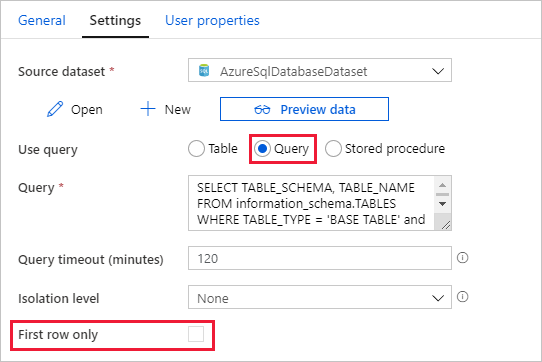
Przejdź do karty Ustawienia i wykonaj następujące czynności:
Wybierz AzureSqlDatabaseDataset dla Źródłowego zestawu danych.
Wybierz pozycję Zapytanie , aby użyć zapytania.
Wprowadź następujące zapytanie SQL dla zapytania.
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'Wyczyść pole wyboru Tylko pierwszy wiersz.
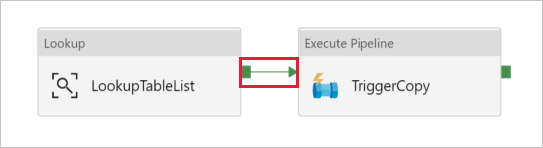
Przeciągnij i upuść działanie Wykonaj potok z przybornika Działania na obszar projektanta potoku i ustaw jego nazwę na TriggerCopy.
Aby połączyć działanie Lookup z działaniem Execute Pipeline, przeciągnij zielone pole dołączone do działania Lookup na lewo od działania Execute Pipeline.
Przejdź do karty Ustawienia działania Wykonaj potok i wykonaj następujące czynności:
Wybierz IterateAndCopySQLTables dla Wywoływany potok.
Wyczyść pole wyboru Wait on completion (Oczekiwanie po zakończeniu).
W sekcji Parametry kliknij pole wejściowe w obszarze WARTOŚĆ —> wybierz pozycję Dodaj zawartość dynamiczną poniżej — wprowadź > jako wartość nazwy tabeli —
@activity('LookupTableList').output.value> wybierz pozycję Zakończ. Ustawiasz listę wyników z działania Lookup jako dane wejściowe do drugiego potoku. Lista wyników zawiera listę tabel, których dane trzeba skopiować do miejsca docelowego.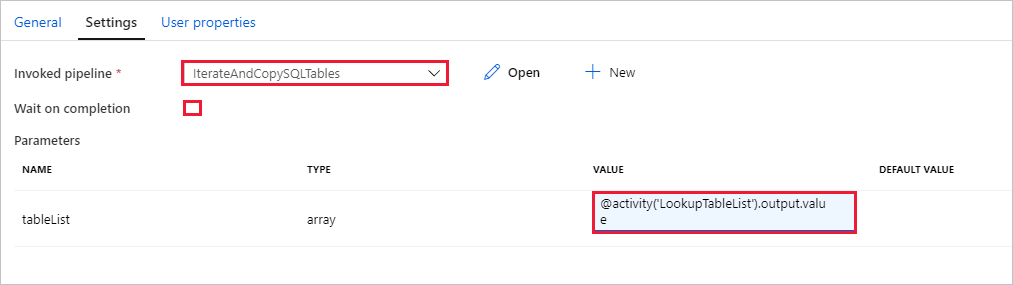
Aby zweryfikować potok, kliknij Weryfikuj na pasku narzędzi. Potwierdź, że nie ma błędów walidacji. Aby zamknąć Raport Weryfikacji Pipeline, kliknij >>.
Aby opublikować jednostki (zestawy danych, potoki itp.) w usłudze Data Factory, kliknij przycisk Opublikuj wszystko w górnej części okna. Poczekaj na pomyślne zakończenie publikowania.
Wyzwól uruchomienie potoku
Przejdź do potoku GetTableListAndTriggerCopyData, kliknij pozycję Dodaj wyzwalacz na górnym pasku narzędzi potoku, a następnie kliknij pozycję Wyzwól teraz.
Potwierdź uruchomienie na stronie Uruchamianie potoku, a następnie wybierz pozycję Zakończ.
Monitoruj działanie potoku
Przejdź do karty Monitorowanie . Kliknij przycisk Odśwież , dopóki nie zobaczysz uruchomień dla obu potoków w rozwiązaniu. Kontynuuj odświeżanie listy do momentu wyświetlenia stanu Powodzenie .
Aby wyświetlić uruchomienia działań skojarzone z potokiem GetTableListAndTriggerCopyData, kliknij link z nazwą potoku. Powinny zostać wyświetlone dwa uruchomienia działania dla tego uruchomienia potoku.
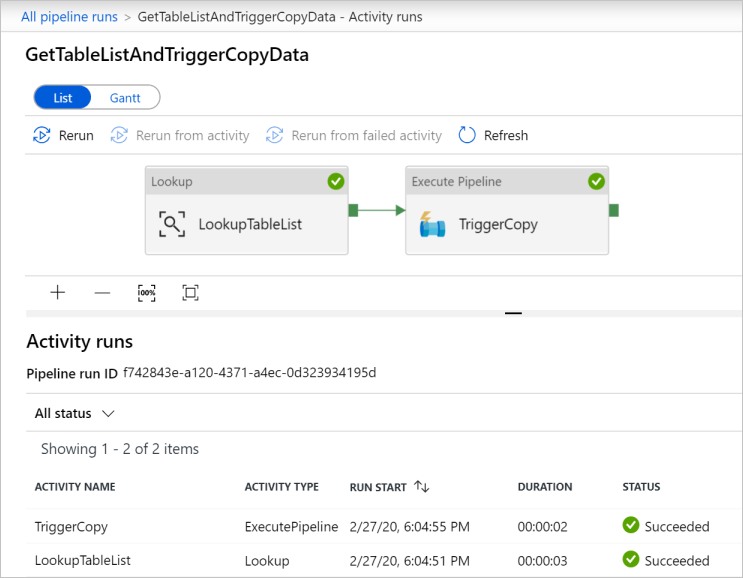
Aby wyświetlić dane wyjściowe działania Lookup , kliknij link Dane wyjściowe obok działania w kolumnie NAZWA DZIAŁANIA . Możesz zmaksymalizować i przywrócić okno Dane wyjściowe. Po przejrzeniu kliknij przycisk X , aby zamknąć okno Dane wyjściowe .
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }Aby wrócić do widoku Uruchomienia Potoku, kliknij link Wszystkie Uruchomienia Potoku w górnej części okruszkowego menu. Kliknij link IterateAndCopySQLTables (w kolumnie NAZWA POTOKU), aby wyświetlić uruchomienia działań potoku. Zwróć uwagę, że istnieje jedno uruchomienie działania Kopiowania dla każdej tabeli w danych wyjściowych działania Lookup .
Upewnij się, że dane zostały skopiowane do usługi Azure Synapse Analytics, której użyłeś w tym samouczku jako docelowej.
Powiązana zawartość
W ramach tego samouczka wykonano następujące procedury:
- Tworzenie fabryki danych.
- Tworzenie połączonych usług Azure SQL Database, Azure Synapse Analytics i Azure Storage.
- Tworzenie zestawów danych usługi Azure SQL Database i Azure Synapse Analytics.
- Utwórz potok do wyszukiwania tabel do skopiowania i inny potok do wykonania operacji kopiowania.
- Uruchom potok.
- Monitoruj potok i uruchomienia działań.
Przejdź do poniższego samouczka, aby dowiedzieć się, jak przyrostowo kopiować dane z lokalizacji źródłowej do docelowej: