Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Jeśli dopiero zaczynasz pracę z Azure Data Factory, zobacz Wprowadzenie do Azure Data Factory.
W tym samouczku użyjesz interfejsu użytkownika usługi Data Factory, aby utworzyć potok, który kopiuje i przekształca dane ze źródła Azure Data Lake Storage Gen2 do ujścia Data Lake Storage Gen2 (zezwalając na dostęp tylko do wybranych sieci) przy użyciu przepływu mapowania danych w usłudze Zarządzana usługaData Factory Virtual Network. Możesz rozwinąć schemat konfiguracji w tym samouczku podczas przekształcania danych przy użyciu mapowania przepływu danych.
W tym samouczku wykonasz następujące czynności:
- Tworzenie fabryki danych.
- Utwórz potok z działaniem przepływu danych.
- Utwórz przepływ danych do mapowania z czterema przekształceniami.
- Testowo uruchom potok.
- Monitorowanie działania przepływu danych.
Wymagania wstępne
- Subskrypcja Azure. Jeśli nie masz subskrypcji Azure, przed rozpoczęciem utwórz konto free Azure.
- Azure konto magazynowe Używasz Data Lake Storage jako źródło danych i ujście danych magazynów danych. Jeśli nie masz konta magazynu, zobacz Utwórz konto magazynu Azure aby uzyskać instrukcje tworzenia konta. Zapewnij, że konto magazynowe zezwala na dostęp tylko z wybranych sieci.
Plik, który przekształcimy w tym samouczku, to moviesDB.csv, który można znaleźć na tej stronie GitHub z zawartością. Aby pobrać plik z GitHub, skopiuj zawartość do wybranego edytora tekstów, aby zapisać go lokalnie jako plik .csv. Aby przesłać plik na konto magazynu, zobacz Przesyłanie blobów w portalu Azure. Przykłady będą odwoływać się do kontenera o nazwie sample-data.
Tworzenie fabryki danych
W tym kroku utworzysz fabrykę danych i otworzysz interfejs użytkownika usługi Data Factory, aby utworzyć potok w fabryce danych.
Otwórz Microsoft Edge lub Google Chrome. Obecnie tylko przeglądarki internetowe Microsoft Edge i Google Chrome obsługują interfejs użytkownika usługi Data Factory.
W menu po lewej stronie wybierz pozycję Utwórz zasób>Analiza>Data Factory.
Na stronie Nowa fabryka danych w polu Nazwa wprowadź wartość ADFTutorialDataFactory.
Nazwa fabryki danych musi być globalnie unikatowa. Jeśli zostanie wyświetlony komunikat o błędzie dotyczący wartości nazwy, wprowadź inną nazwę fabryki danych (na przykład yournameADFTutorialDataFactory). Reguły nazewnictwa dla artefaktów usługi Data Factory można znaleźć w artykule Data Factory — reguły nazewnictwa.
Wybierz Azure subskrypcję w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
- Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
- Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Aby dowiedzieć się więcej o grupach zasobów, zobacz Użyj grupy zasobów do zarządzania zasobami Azure.
W obszarze Wersja wybierz pozycję V2.
W obszarze Lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (na przykład Azure Storage i Azure SQL Database) i obliczenia (na przykład Azure HDInsight) używane przez fabrykę danych mogą znajdować się w innych regionach.
Wybierz pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlone powiadomienie w Centrum powiadomień. Wybierz pozycję Przejdź do zasobu, aby przejść do strony Data Factory.
Wybierz pozycję Otwórz Azure Data Factory Studio aby uruchomić interfejs użytkownika usługi Data Factory na osobnej karcie.
Tworzenie środowiska Azure IR w usłudze Data Factory Managed Virtual Network
W tym kroku utworzysz środowisko AZURE IR i włączysz usługę Data Factory Managed Virtual Network.
W portalu usługi Data Factory przejdź do Zarządzanie i wybierz pozycję Nowy aby utworzyć nowe środowisko IR Azure.
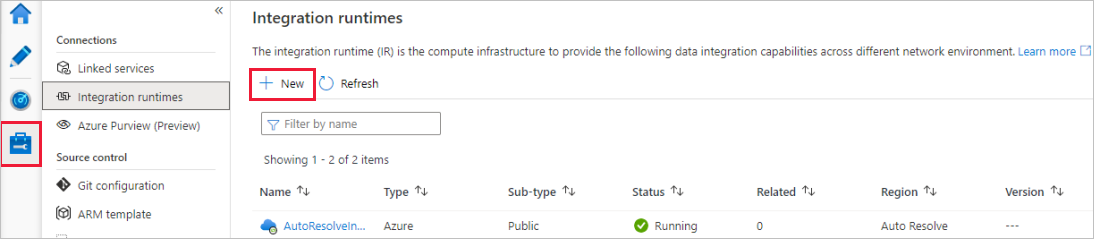
Na stronie Konfiguracja środowiska Integration Runtime wybierz środowisko Integration Runtime, które ma zostać utworzone na podstawie wymaganych możliwości. W tym samouczku wybierz pozycję Azure, Self-Hosted a następnie kliknij pozycję Continue.
Wybierz Azure a następnie kliknij pozycję Continue aby utworzyć środowisko Integration Runtime Azure.
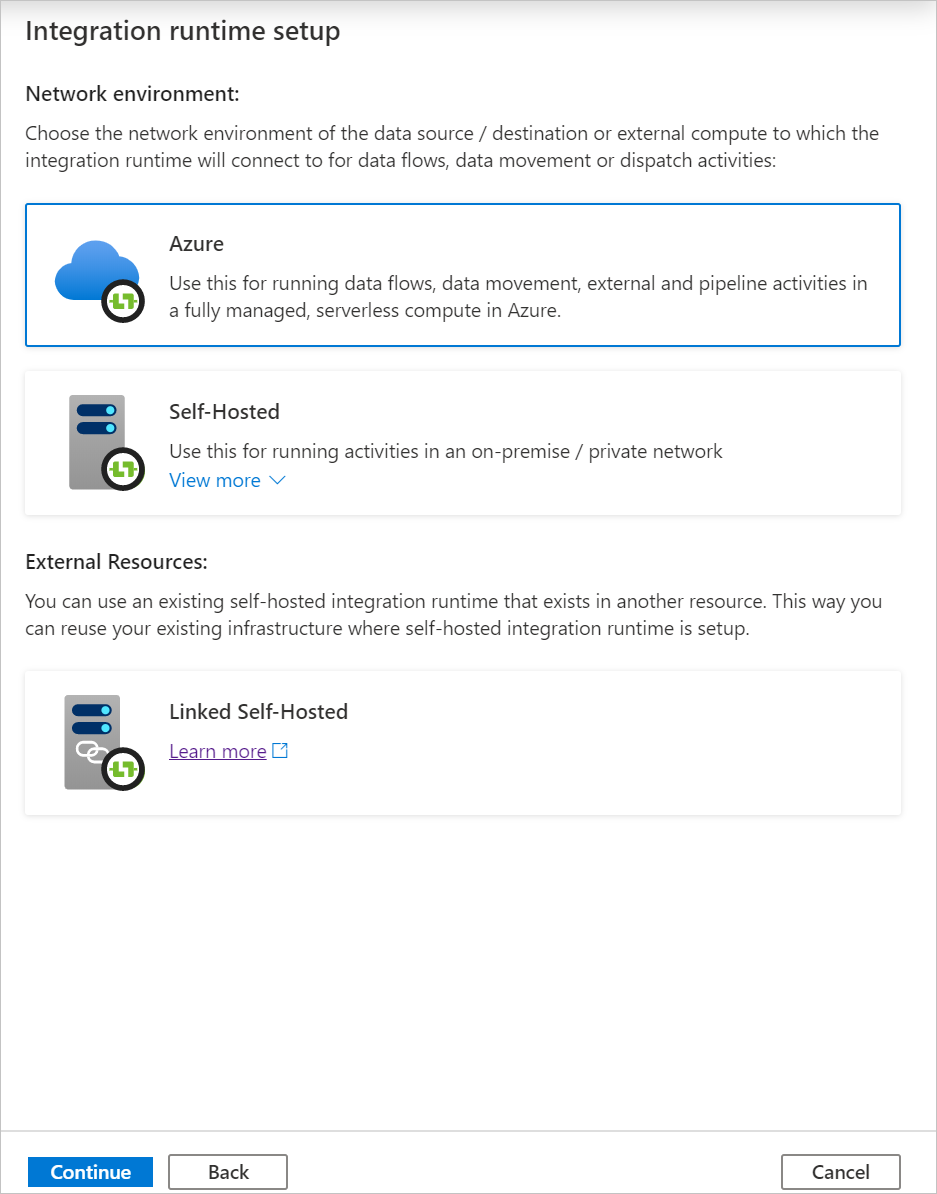
W obszarze Konfiguracja sieci wirtualnej (wersja zapoznawcza) wybierz pozycję Włącz.
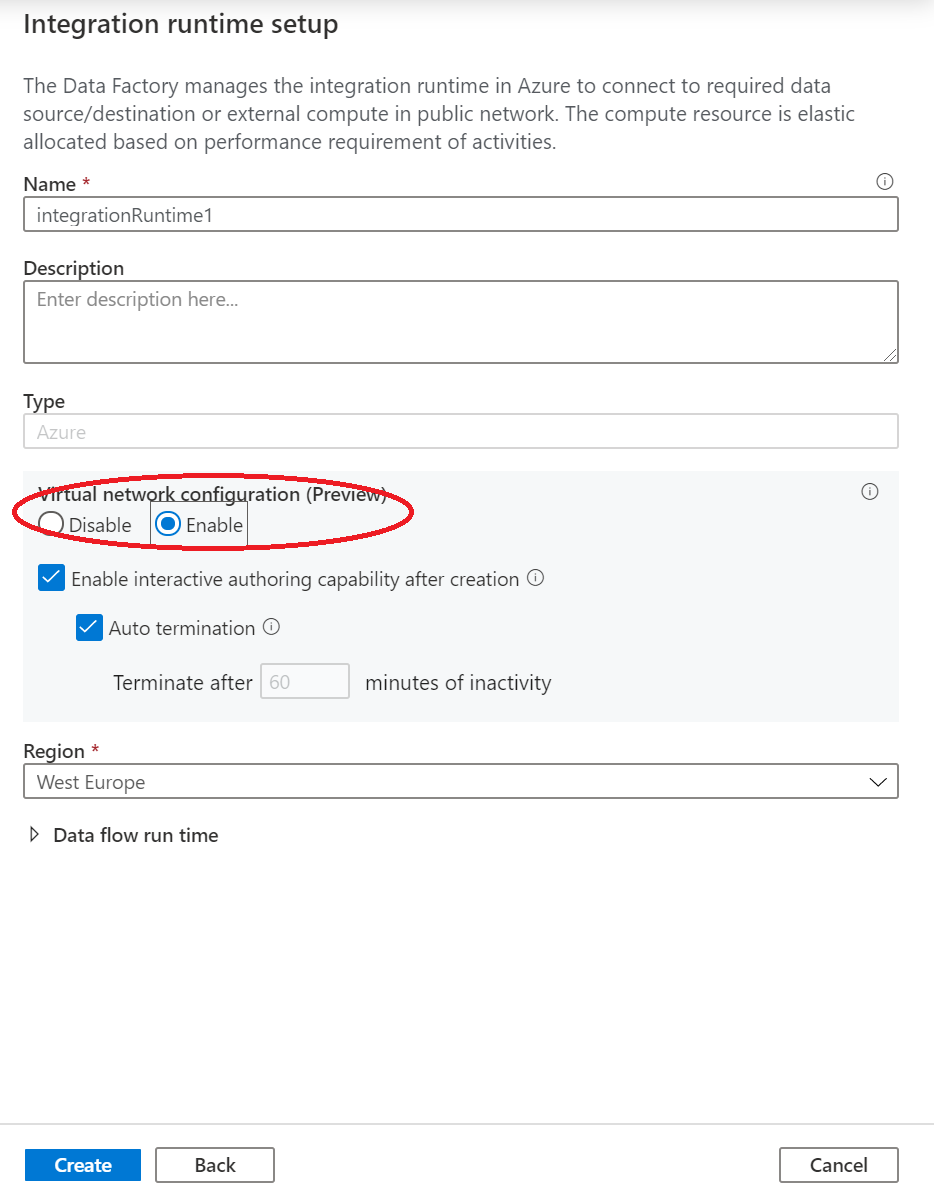
Wybierz pozycję Utwórz.
Utwórz potok z procesem przepływu danych
W tym kroku utworzysz pipeline zawierający aktywność przepływu danych.
Na stronie głównej Azure Data Factory wybierz pozycję Orchestrate.
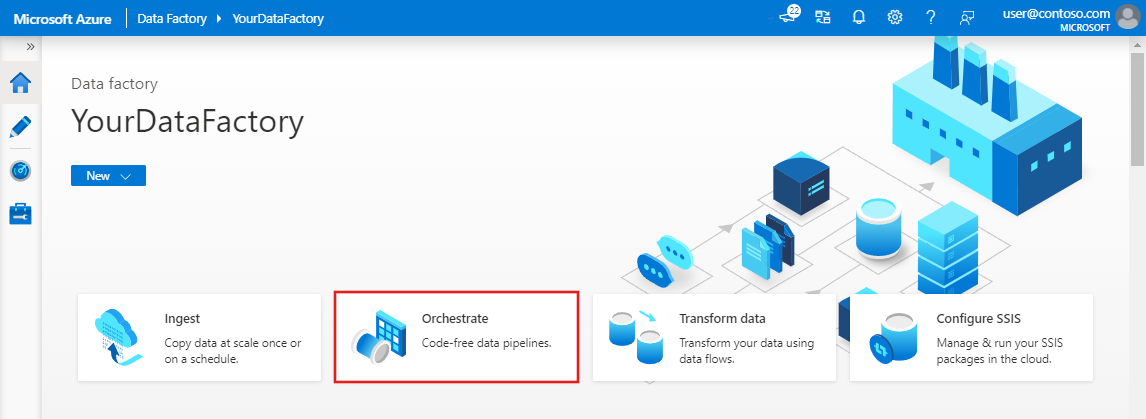
W okienku właściwości potoku wprowadź TransformFilmy jako nazwę potoku.
W okienku Działania rozwiń Przenieś i Przekształć. Przeciągnij działanie Data Flow z okienka do kanwy potoku.
W oknie Dodawanie przepływu danych wybierz Utwórz nowy przepływ danych, a następnie wybierz pozycję Mapowanie przepływu danych. Po zakończeniu wybierz przycisk OK .
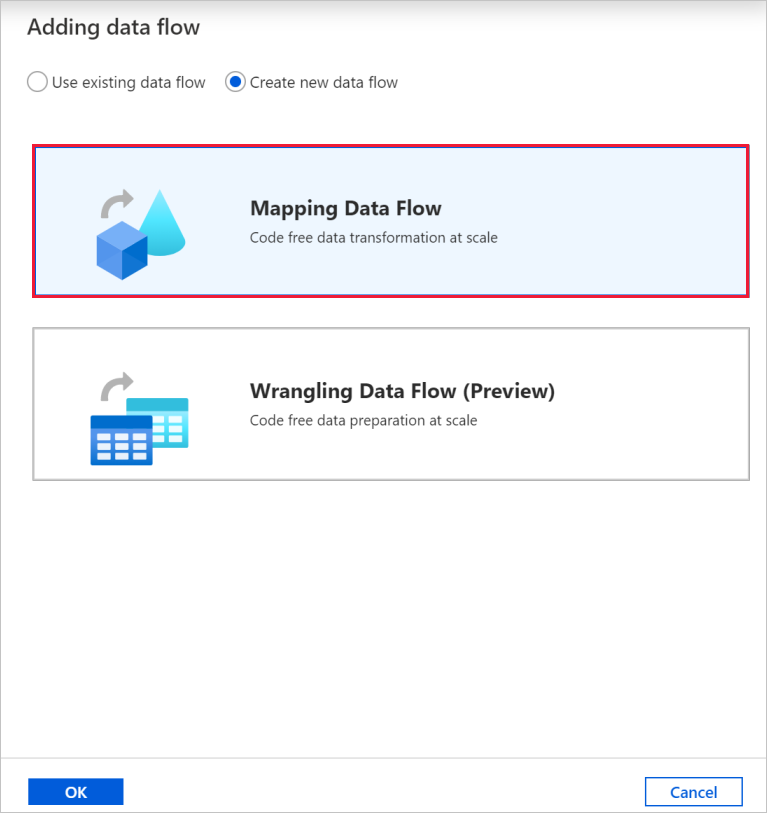
Nadaj przepływowi danych nazwę TransformFilms w okienku właściwości.
Na górnym pasku kanwy potoku przesuń suwak debugowania Data Flow. Tryb debugowania umożliwia interaktywne testowanie logiki transformacji względem dynamicznego klastra Spark. Klastry Data Flow potrzebują od 5 do 7 minut na rozgrzanie, a użytkownikom zaleca się włączyć debugowanie przed rozpoczęciem pracy nad rozwojem aplikacji Data Flow. Aby uzyskać więcej informacji, zobacz Tryb debugowania.

Tworzenie logiki przekształcania na kanwie przepływu danych
Po utworzeniu przepływu danych zostaniesz automatycznie przeniesiony na obszar roboczy przepływu danych. W tym kroku utworzysz przepływ danych, który pobiera plik moviesDB.csv w Data Lake Storage i agreguje średnią ocenę komedii z 1910 do 2000 roku. Następnie zapiszesz ten plik z powrotem do Data Lake Storage.
Dodaj przekształcenie źródłowe
W tym kroku skonfigurujesz Data Lake Storage Gen2 jako źródło.
Na kanwie przepływu danych dodaj źródło, wybierając pole Dodaj źródło .
Nazwij źródłową bazę danych MoviesDB. Wybierz pozycję Nowy , aby utworzyć nowy źródłowy zestaw danych.
Wybierz Azure Data Lake Storage Gen2, a następnie wybierz Continue.
Wybierz pozycję RozdzielanyTekst, a następnie wybierz pozycję Kontynuuj.
Nadaj zestawowi danych nazwę MoviesDB. Z listy rozwijanej połączonej usługi wybierz pozycję Nowy.
Na ekranie tworzenia połączonej usługi nazwij połączoną usługę Data Lake Storage Gen2 ADLSGen2 i określ metodę uwierzytelniania. Następnie wprowadź poświadczenia połączenia. W tym samouczku używamy klucza konta do nawiązywania połączenia z naszym kontem magazynu.
Upewnij się, że włączono interakcyjne tworzenie. Włączenie tej opcji może potrwać minutę.
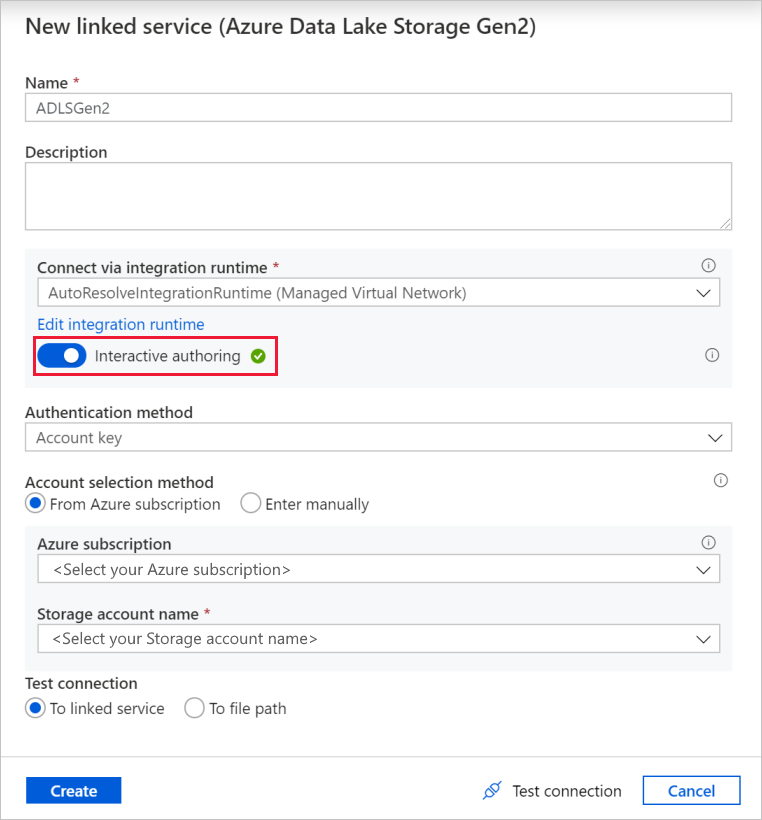
Wybierz pozycję Testuj połączenie. Powinno się zakończyć niepowodzeniem, ponieważ do konta magazynu nie można uzyskać dostępu bez utworzenia i zatwierdzenia prywatnego punktu końcowego. W komunikacie o błędzie powinien pojawić się link do utworzenia prywatnego punktu końcowego, który można śledzić w celu utworzenia zarządzanego prywatnego punktu końcowego. Alternatywą jest przejście bezpośrednio do karty Zarządzanie i wykonanie instrukcji w tej sekcji w celu utworzenia zarządzanego prywatnego punktu końcowego.
Pozostaw otwarte okno dialogowe, a następnie przejdź do twojego konta magazynowego.
Postępuj zgodnie z instrukcjami w tej sekcji , aby zatwierdzić link prywatny.
Wróć do okna dialogowego. Wybierz ponownie pozycję Testuj połączenie i wybierz pozycję Utwórz , aby wdrożyć połączoną usługę.
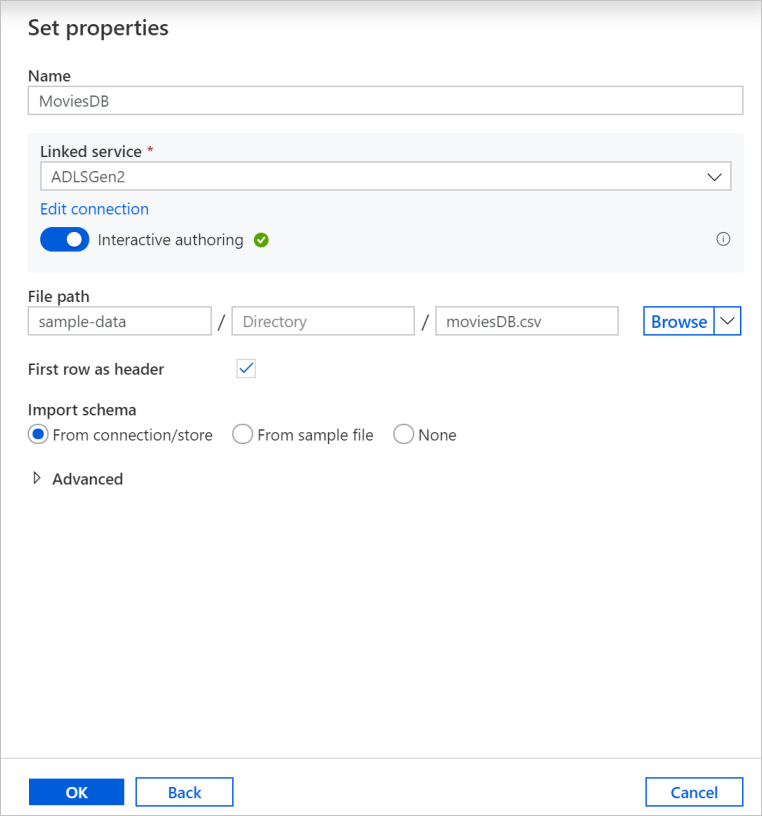
Na ekranie tworzenia zestawu danych określ, gdzie znajduje się twój plik w polu Ścieżka pliku. W tym samouczku plik moviesDB.csv znajduje się w kontenerze sample-data. Ponieważ plik ma nagłówki, zaznacz pole wyboru Pierwszy wiersz jako nagłówek . Wybierz Z połączenia/przechowywania, aby zaimportować schemat nagłówka bezpośrednio z pliku w przechowywaniu. Po zakończeniu wybierz przycisk OK .
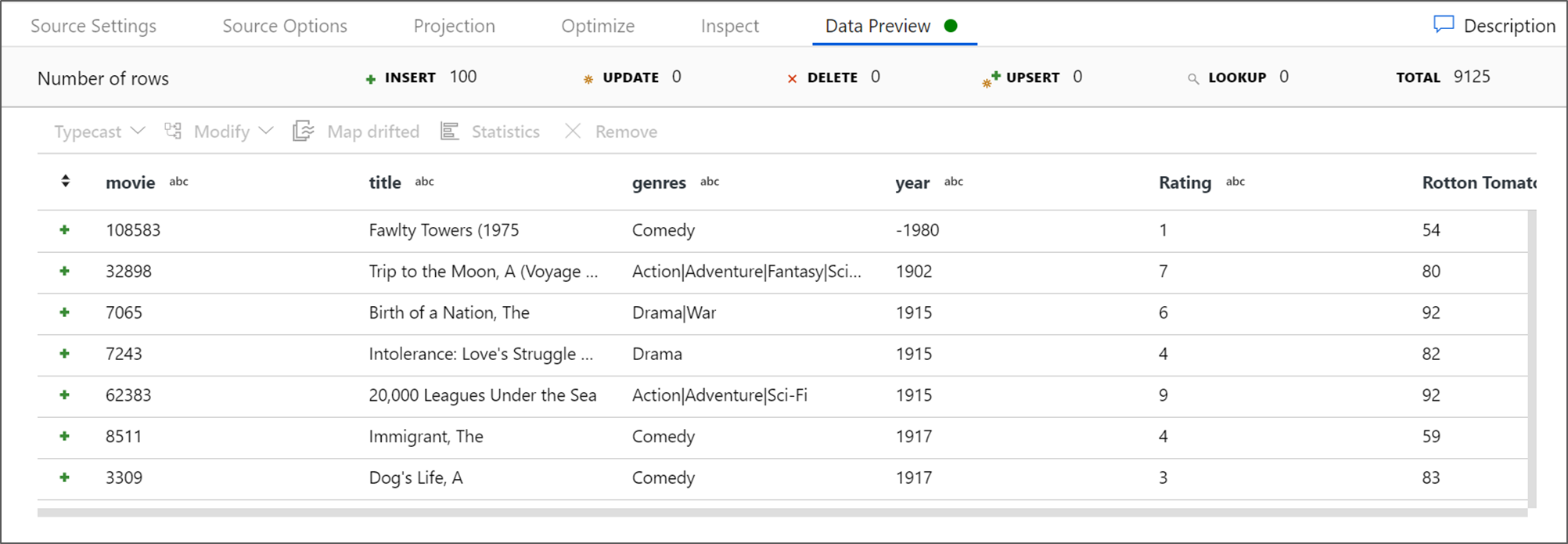
Jeśli klaster debugowania został uruchomiony, przejdź do karty Podgląd danych przekształcenia źródłowego i wybierz Odśwież, aby uzyskać zrzut danych. Możesz użyć podglądu danych, aby sprawdzić, czy transformacja jest poprawnie skonfigurowana.
Tworzenie zarządzanego prywatnego punktu końcowego
Jeśli nie użyto hiperlinku podczas testowania poprzedniego połączenia, postępuj zgodnie ze ścieżką. Teraz musisz utworzyć zarządzany prywatny punkt końcowy, który połączysz z usługą połączoną, którą utworzyłeś.
Przejdź do karty Zarządzanie .
Uwaga
Karta Zarządzanie może nie być dostępna dla wszystkich wystąpień usługi Data Factory. Jeśli tego nie widzisz, możesz uzyskać dostęp do prywatnych punktów końcowych, wybierając Author>Połączenia>Prywatny punkt końcowy.
Przejdź do sekcji Zarządzane prywatne punkty końcowe .
Wybierz + Nowy w sekcji Zarządzane prywatne punkty końcowe.
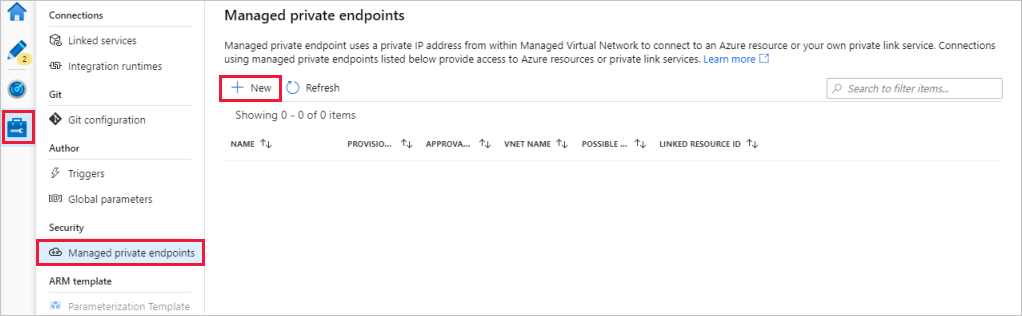
Wybierz kafelek Azure Data Lake Storage Gen2 z listy i wybierz Continue.
Wprowadź nazwę utworzonego konta magazynowego.
Wybierz pozycję Utwórz.
Po kilku sekundach powinno zostać wyświetlone, że utworzony link prywatny wymaga zatwierdzenia.
Wybierz utworzony prywatny punkt końcowy. Możesz zobaczyć hiperlink, który przeniesie Cię do miejsca, gdzie możesz zatwierdzić prywatny punkt końcowy na poziomie konta przechowywania.
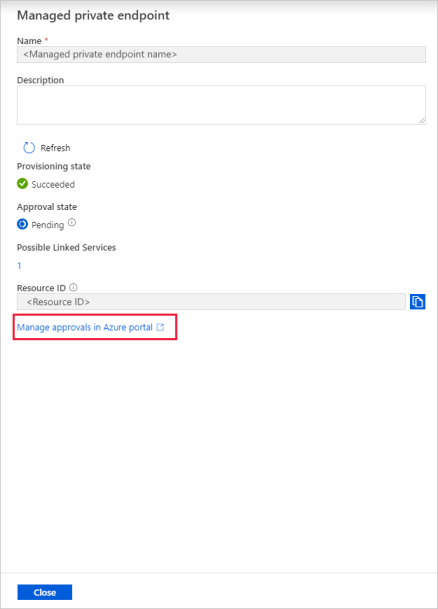
Zatwierdzanie łącza prywatnego w koncie magazynowym
Na koncie magazynu przejdź do Prywatne połączenia końcowe w sekcji Ustawienia.
Zaznacz pole wyboru utworzonego prywatnego punktu końcowego, a następnie wybierz pozycję Zatwierdź.
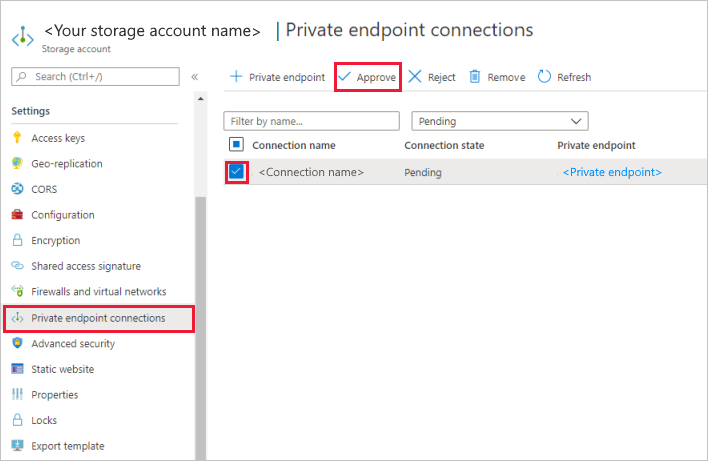
Dodaj opis i wybierz pozycję Tak.
Wróć do sekcji Zarządzane prywatne punkty końcowe na karcie Zarządzanie w usłudze Data Factory.
Po około minucie powinno zostać wyświetlone zatwierdzenie dla prywatnego punktu końcowego.
Dodaj przekształcenie filtru
Obok węzła źródłowego na kanwie przepływu danych wybierz ikonę plusa, aby dodać nową transformację. Pierwszą dodaną transformacją jest filtr.
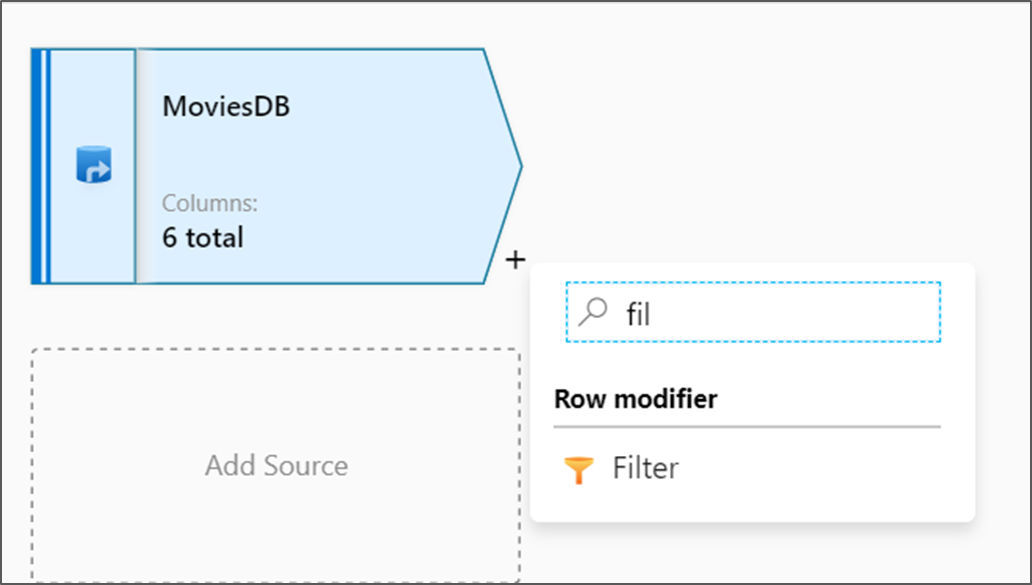
Nadaj transformacji filtrowi nazwę FilterYears. Wybierz pole wyrażenia obok pozycji Filtruj , aby otworzyć konstruktora wyrażeń. W tym miejscu określisz warunek filtrowania.
Konstruktor wyrażeń przepływu danych umożliwia interaktywne tworzenie wyrażeń używanych w różnych przekształceniach. Wyrażenia mogą zawierać wbudowane funkcje, kolumny ze schematu wejściowego i parametry zdefiniowane przez użytkownika. Aby uzyskać więcej informacji na temat tworzenia wyrażeń, zobacz Konstruktor wyrażeń przepływu danych.
W tym samouczku chcesz filtrować filmy w gatunku komediowym, który wyszedł między latami 1910 i 2000. Ponieważ rok jest obecnie ciągiem, należy przekonwertować go na liczbę całkowitą przy użyciu
toInteger()funkcji . Użyj operatorów większe lub równe (>=) i mniejsze lub równe (<=), aby porównać z literałami reprezentującymi lata 1910 i 2000. Połącz te wyrażenia razem z operatorem i (&&). Wyrażenie jest przedstawiane jako:toInteger(year) >= 1910 && toInteger(year) <= 2000Aby dowiedzieć się, które filmy są komediami, możesz użyć
rlike()funkcji , aby znaleźć wzorzec "Comedy" w gatunkach kolumn. Połącz wyrażenierlikez porównaniem roku, aby uzyskać:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Jeśli masz aktywny klaster debugowania, możesz zweryfikować logikę, wybierając pozycję Odśwież , aby wyświetlić dane wyjściowe wyrażenia w porównaniu z użytymi danymi wejściowymi. Istnieje więcej niż jedna właściwa odpowiedź na temat tego, jak można osiągnąć tę logikę przy użyciu języka wyrażeń przepływu danych.
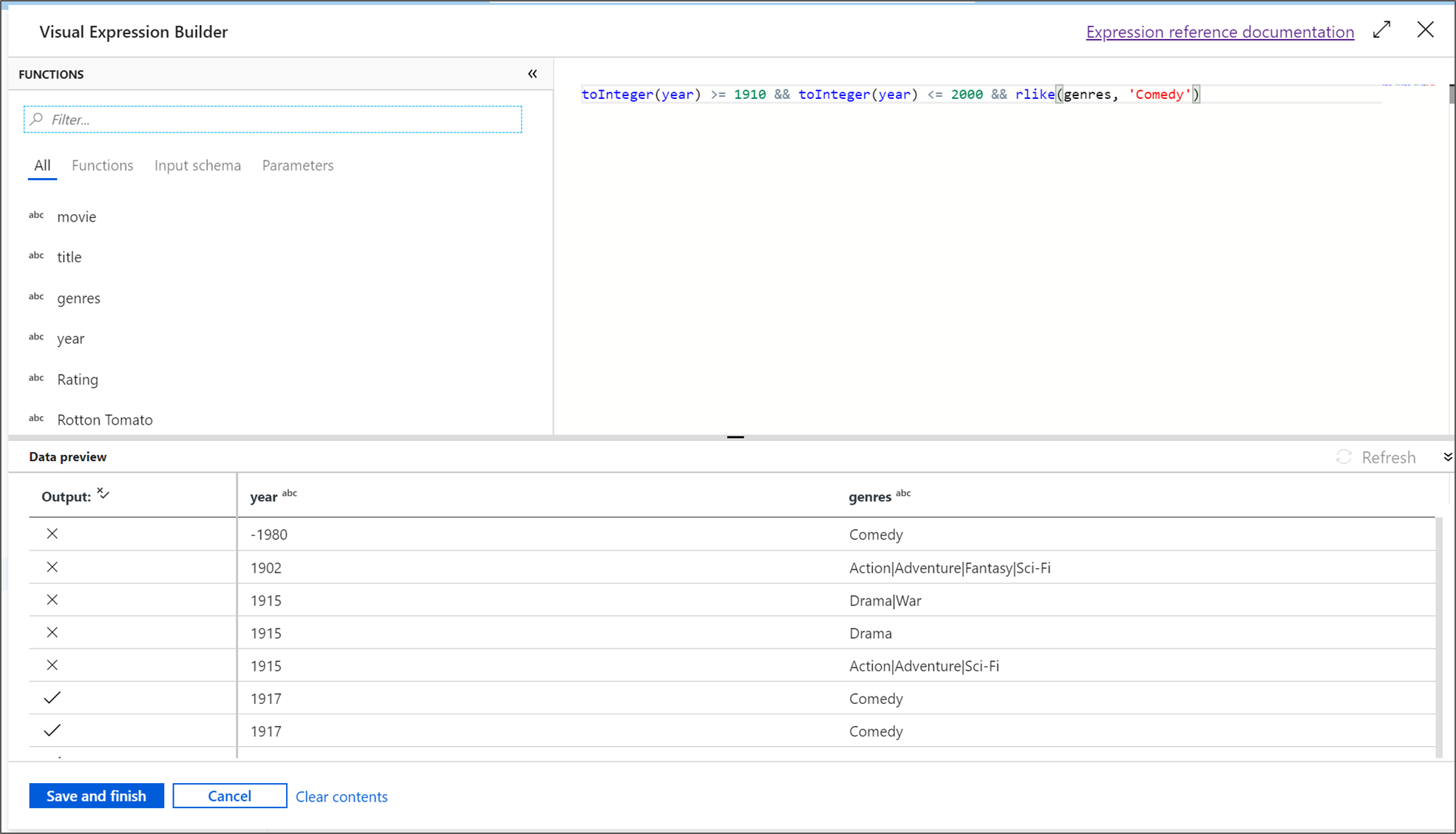
Po zakończeniu pracy z wyrażeniem wybierz pozycję Zapisz i zakończ .
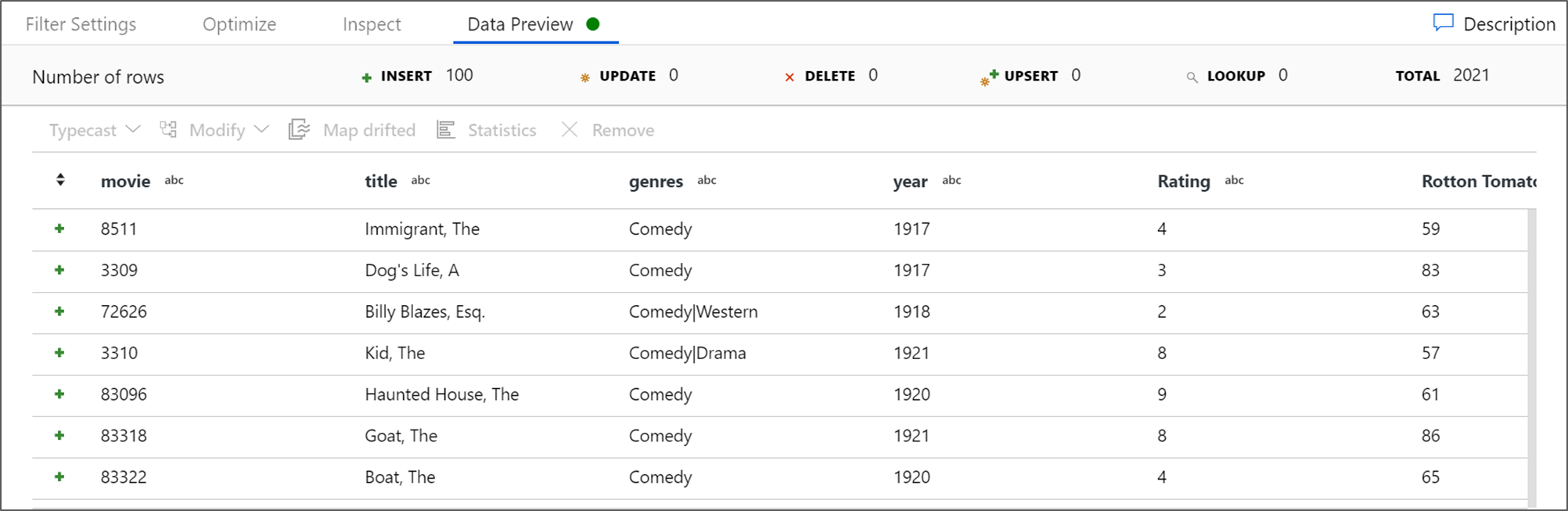
Pobierz podgląd danych, aby sprawdzić, czy filtr działa poprawnie.
Dodaj transformację agregującą
Kolejną transformacją, którą dodasz, jest transformacja typu Agregacja w kategorii Modyfikator schematu.
Nadaj agregacji nazwę AggregateComedyRating. Na karcie Grupuj według wybierz rok z listy rozwijanej, aby pogrupować agregacje według roku, w którym film się ukazał.
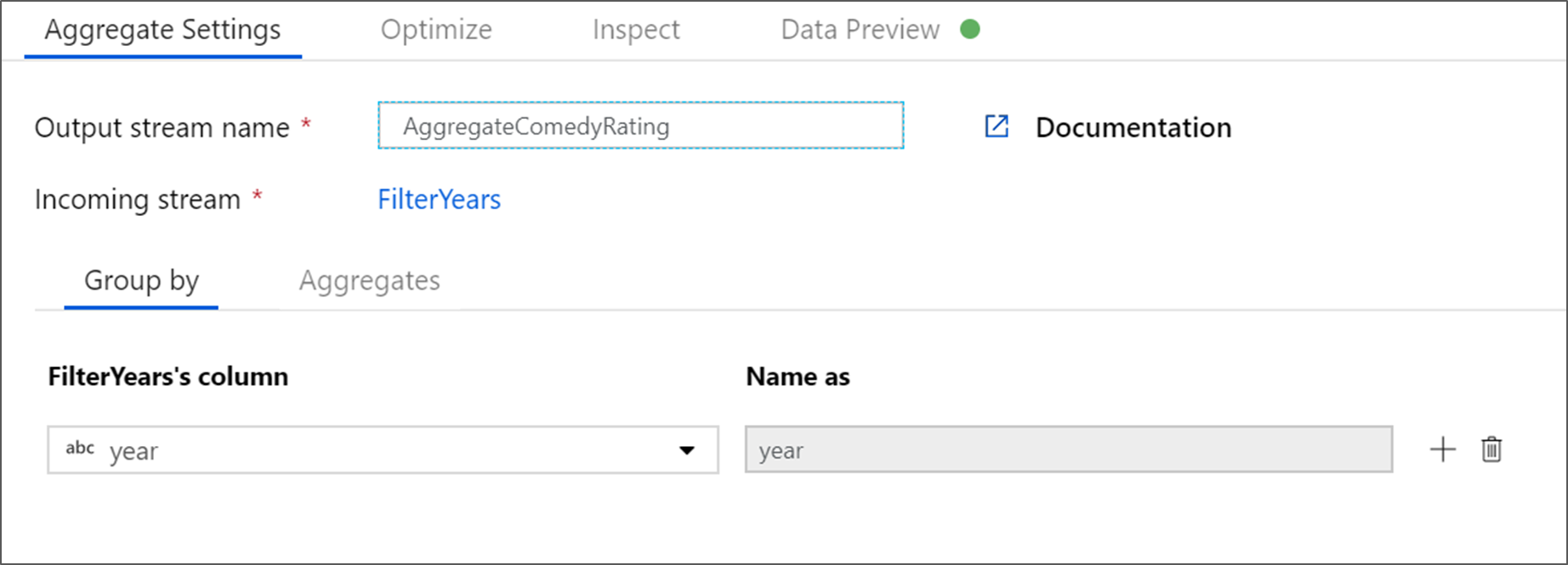
Przejdź do karty Agregacje . W polu tekstowym po lewej stronie nadaj kolumnie agregacji nazwę AverageComedyRating. Wybierz odpowiednie pole wyrażenia, aby wprowadzić wyrażenie zbiorcze korzystając z konstruktora wyrażeń.
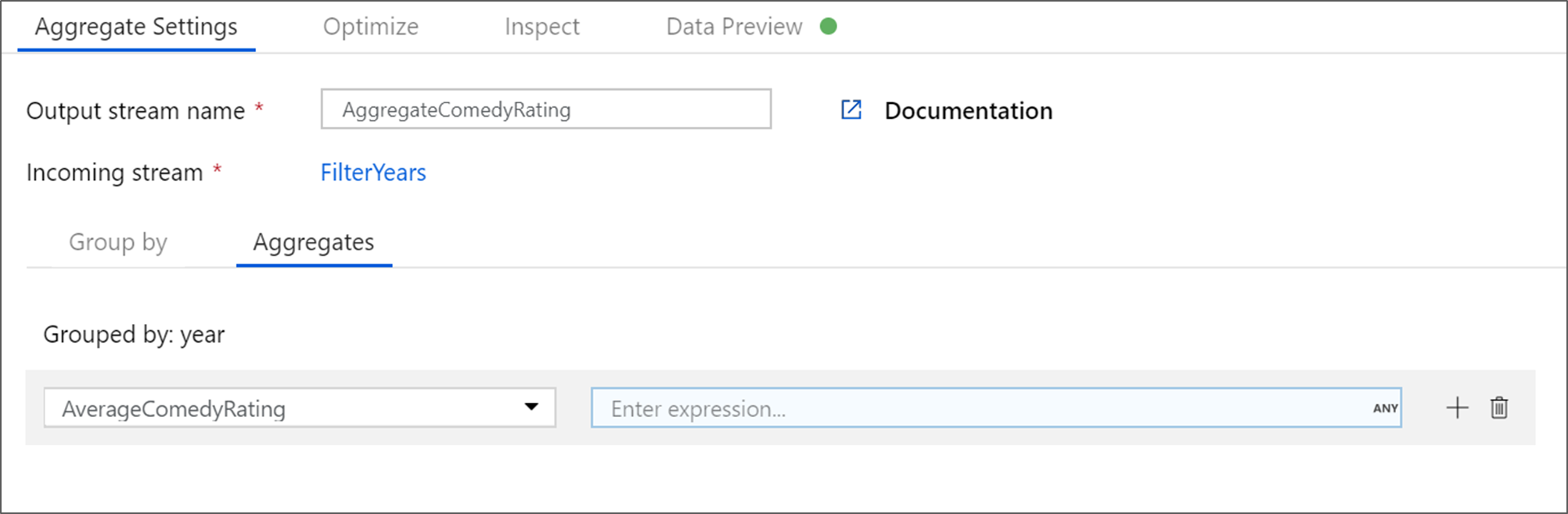
Aby uzyskać średnią kolumny Ocena, użyj
avg()funkcji agregującej. Ponieważ ocena jest ciągiem iavg()przyjmuje dane wejściowe liczbowe, musimy przekonwertować wartość na liczbę za pośrednictwemtoInteger()funkcji. To wyrażenie wygląda następująco:avg(toInteger(Rating))Po zakończeniu wybierz pozycję Zapisz i zakończ .

Przejdź do karty Podgląd danych, aby wyświetlić dane wyjściowe przekształcenia. Zwróć uwagę, że istnieją tylko dwie kolumny: rok i AverageComedyRating.
Dodawanie przekształcenia ujścia
Następnie chcesz dodać przekształcenie ujścia w obszarze Miejsce docelowe.
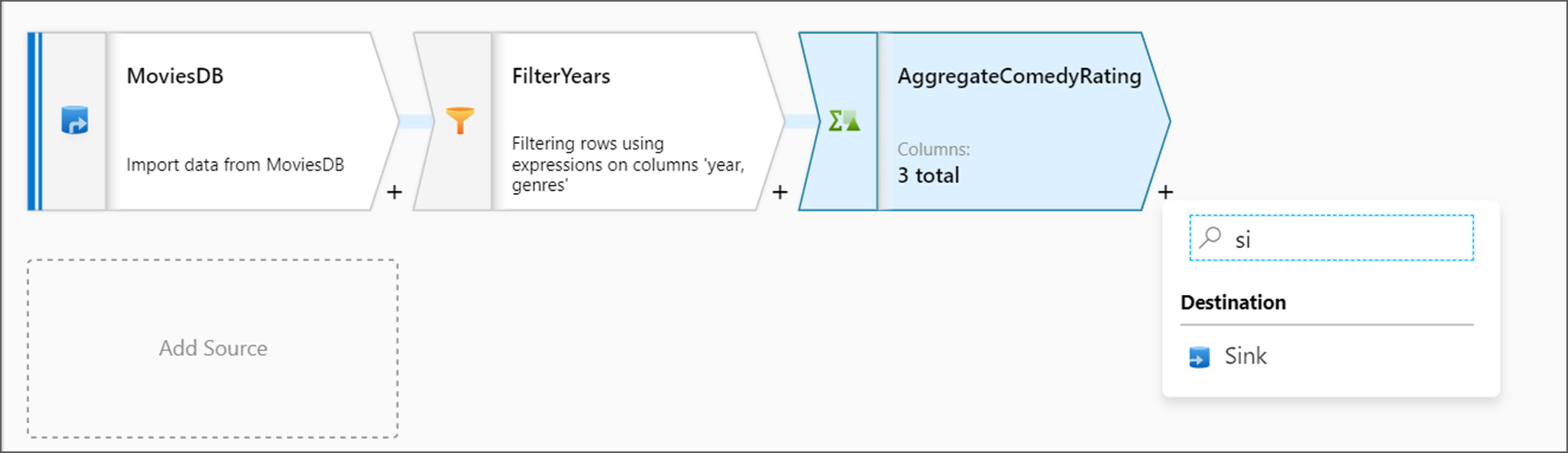
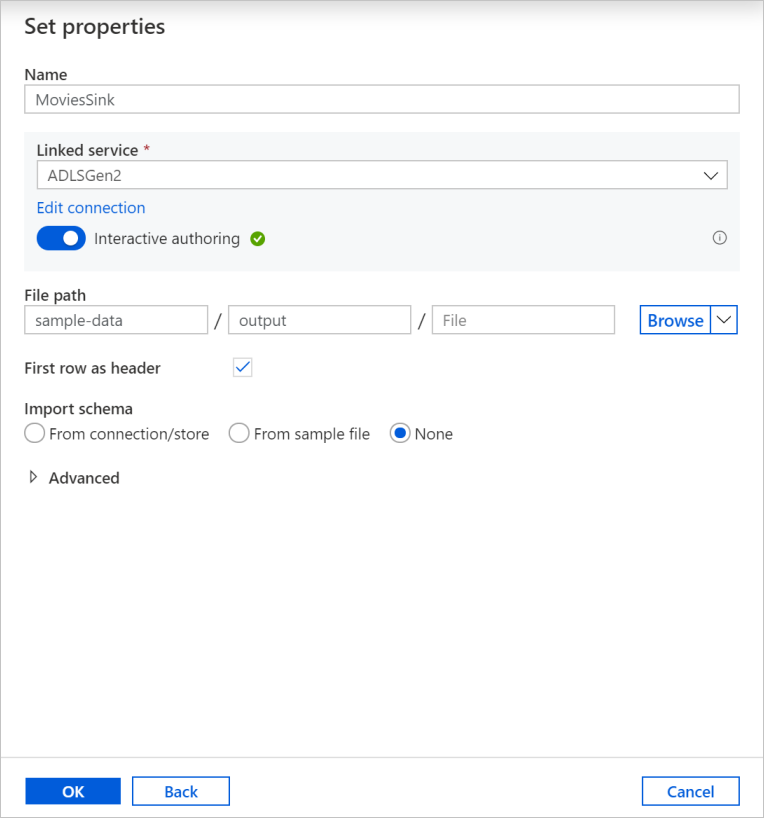
Nazwij swój zlew Sink. Wybierz pozycję Nowy , aby utworzyć zestaw danych ujścia.
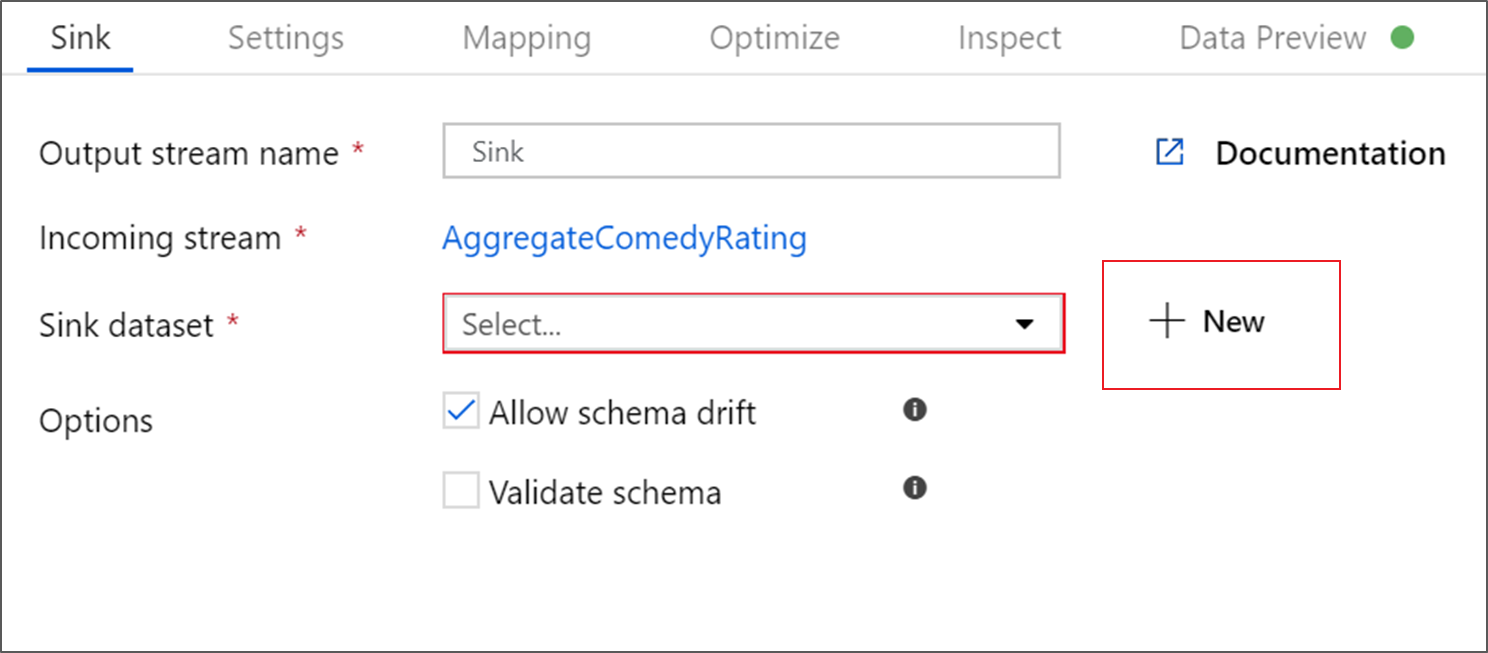
Na stronie Nowy zestaw danych wybierz Azure Data Lake Storage Gen2 a następnie wybierz pozycję Continue.
Na stronie Wybierz format wybierz pozycję RozdzielanyTekst , a następnie wybierz pozycję Kontynuuj.
Nadaj nazwę zestawowi danych ujściowemu MoviesSink. W przypadku połączonej usługi wybierz tę samą połączoną usługę ADLSGen2 utworzoną do przekształcania źródła. Wprowadź folder wyjściowy do zapisania danych. W tym samouczku zapisujemy do folderu output w kontenerze sample-data. Folder nie musi istnieć wcześniej i można go dynamicznie tworzyć. Zaznacz pole wyboru Pierwszy wiersz jako nagłówek i wybierz pozycję Brak w polu Importuj schemat. Wybierz przycisk OK.
Teraz zakończyłeś tworzenie przepływu danych. Możesz go uruchomić w pipelinie.
Uruchamianie i monitorowanie przepływu danych
Można debugować potok danych przed jego opublikowaniem. W tym kroku wyzwalasz uruchomienie debugowania potoku danych. Chociaż podgląd danych nie zapisuje danych, uruchomienie debugowania spowoduje zapisanie danych w miejscu docelowym ujścia.
Przejdź do kanwy potoku. Wybierz pozycję Debuguj , aby wyzwolić przebieg debugowania.
Debugowanie pipeline'u działań związanych z przepływem danych używa aktywnego klastra debugowania, aczkolwiek inicjowanie nadal trwa co najmniej minutę. Postęp można śledzić za pomocą karty Wyjście. Po pomyślnym zakończeniu procesu wybierz ikonę okularów, aby uzyskać szczegółowe informacje o przebiegu.
Na stronie szczegółów można zobaczyć liczbę wierszy i czas spędzony na każdym kroku transformacji.
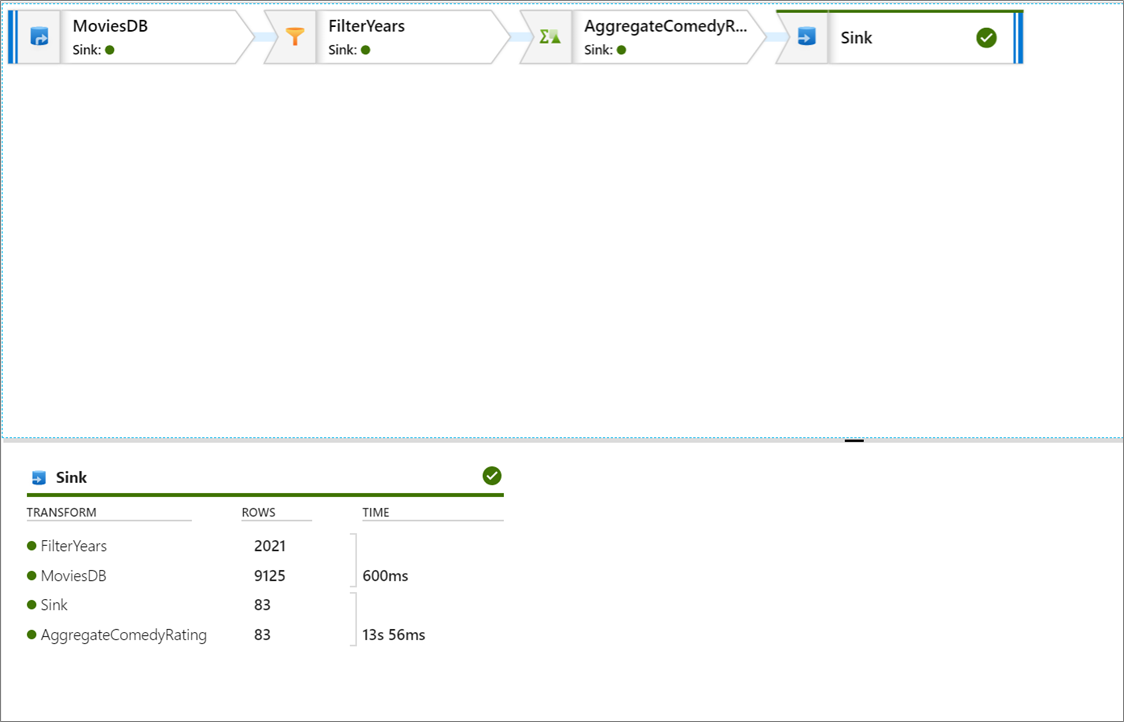
Wybierz przekształcenie, aby uzyskać szczegółowe informacje o kolumnach i partycjonowaniu danych.
Jeśli wykonano czynności opisane w tym samouczku poprawnie, należy zapisać 83 wiersze i 2 kolumny w folderze docelowym. Możesz sprawdzić, czy dane są poprawne, sprawdzając przechowywanie obiektów blob.
Podsumowanie
W tym samouczku użyto interfejsu użytkownika usługi Data Factory do utworzenia potoku, który kopiuje i przekształca dane ze źródła Data Lake Storage Gen2 do ujścia Data Lake Storage Gen2 (zarówno zezwalając na dostęp do wybranych sieci) przy użyciu przepływu danych mapowania w usłudze Data Factory Managed Virtual Network.