Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej. Aby uzyskać informacje na temat uprawnień i włączania, zobacz Włączanie bezserwerowych obliczeń.
W tym artykule wyjaśniono, jak używać bezserwerowych obliczeń dla notesów. Aby uzyskać informacje na temat używania bezserwerowych zasobów obliczeniowych dla przepływów pracy, zobacz Uruchamianie zadania usługi Azure Databricks z bezserwerowymi obliczeniami dla przepływów pracy.
Aby uzyskać informacje o cenach, zobacz Cennik usługi Databricks.
Wymagania
Obszar roboczy musi być włączony dla wykazu aparatu Unity.
Obszar roboczy musi znajdować się w obsługiwanym regionie. Zobacz Regiony usługi Azure Databricks.
Twoje konto musi być włączone dla obliczeń bezserwerowych. Zobacz Włączanie przetwarzania bezserwerowego.
Dołączanie notesu do obliczeń bezserwerowych
Jeśli obszar roboczy jest włączony dla bezserwerowych interaktywnych obliczeń, wszyscy użytkownicy w obszarze roboczym mają dostęp do bezserwerowych obliczeń dla notesów. Nie są wymagane żadne dodatkowe uprawnienia.
Aby dołączyć do bezserwerowych zasobów obliczeniowych, kliknij menu rozwijane Połącz w notesie i wybierz pozycję Bezserwerowe. W przypadku nowych notesów dołączone zasoby obliczeniowe są automatycznie domyślnie domyślnie bezserwerowe po wykonaniu kodu, jeśli nie wybrano żadnego innego zasobu.
Instalowanie zależności notesu
Zależności języka Python można zainstalować dla notesów bezserwerowych przy użyciu panelu bocznego Środowisko , który udostępnia jedno miejsce do edycji, wyświetlania i eksportowania wymagań dotyczących biblioteki dla notesu. Te zależności można dodawać przy użyciu środowiska podstawowego lub indywidualnie.
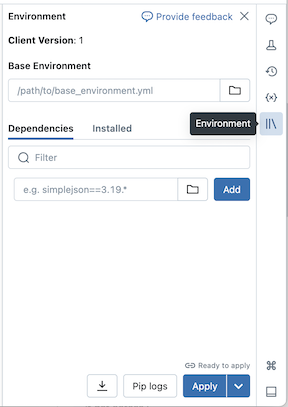
Konfigurowanie środowiska podstawowego
Środowisko podstawowe to plik YAML przechowywany jako plik obszaru roboczego lub wolumin wykazu aparatu Unity, który określa dodatkowe zależności środowiska. Środowiska podstawowe mogą być współużytkowane przez notesy. Aby skonfigurować środowisko podstawowe:
Utwórz plik YAML, który definiuje ustawienia dla środowiska wirtualnego języka Python. Poniższy przykład YAML oparty na specyfikacji środowiska projektów MLflow definiuje środowisko podstawowe z kilkoma zależnościami biblioteki:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Przekaż plik YAML jako plik obszaru roboczego lub do woluminu wykazu aparatu Unity. Zobacz Importowanie pliku lub Przekazywanie plików do woluminu wykazu aparatu Unity.
Po prawej stronie notesu kliknij
 przycisk , aby rozwinąć panel Środowisko . Ten przycisk jest wyświetlany tylko wtedy, gdy notes jest połączony z obliczeniami bezserwerowymi.
przycisk , aby rozwinąć panel Środowisko . Ten przycisk jest wyświetlany tylko wtedy, gdy notes jest połączony z obliczeniami bezserwerowymi.W polu Środowisko podstawowe wprowadź ścieżkę przekazanego pliku YAML lub przejdź do niego i wybierz go.
Kliknij Zastosuj. Spowoduje to zainstalowanie zależności w środowisku wirtualnym notesu i ponowne uruchomienie procesu języka Python.
Użytkownicy mogą zastąpić zależności określone w środowisku podstawowym, instalując zależności indywidualnie.
Dodawanie zależności pojedynczo
Zależności można również zainstalować w notesie połączonym z obliczeniami bezserwerowym przy użyciu karty Zależności panelu Środowisko:
- Po prawej stronie notesu kliknij przycisk , aby rozwinąć panel Środowisko . Ten przycisk jest wyświetlany tylko wtedy, gdy notes jest połączony z obliczeniami bezserwerowymi.
- W sekcji Zależności kliknij pozycję Dodaj zależność i wprowadź ścieżkę zależności biblioteki w polu. Zależność można określić w dowolnym formacie prawidłowym w pliku requirements.txt .
- Kliknij Zastosuj. Spowoduje to zainstalowanie zależności w środowisku wirtualnym notesu i ponowne uruchomienie procesu języka Python.
Uwaga
Zadanie korzystające z obliczeń bezserwerowych spowoduje zainstalowanie specyfikacji środowiska notesu przed wykonaniem kodu notesu. Oznacza to, że nie ma potrzeby dodawania zależności podczas planowania notesów jako zadań. Zobacz Konfigurowanie środowisk i zależności notesu.
Wyświetlanie zainstalowanych zależności i dzienników
Aby wyświetlić zainstalowane zależności, kliknij pozycję Zainstalowane w panelu bocznym Środowiska dla notesu. Dzienniki instalacji dla środowiska notesu są również dostępne, klikając pozycję Dzienniki w dolnej części panelu.
Resetowanie środowiska
Jeśli notes jest połączony z obliczeniami bezserwerowymi, usługa Databricks automatycznie buforuje zawartość środowiska wirtualnego notesu. Oznacza to, że zwykle nie trzeba ponownie instalować zależności języka Python określonych w panelu Środowisko po otwarciu istniejącego notesu, nawet jeśli został odłączony z powodu braku aktywności.
Buforowanie środowiska wirtualnego języka Python dotyczy również zadań. Oznacza to, że kolejne uruchomienia zadań są szybsze, ponieważ wymagane zależności są już dostępne.
Uwaga
Jeśli zmienisz implementację niestandardowego pakietu języka Python używanego w zadaniu bezserwerowym, musisz również zaktualizować jego numer wersji dla zadań, aby pobrać najnowszą implementację.
Aby wyczyścić pamięć podręczną środowiska i przeprowadzić nową instalację zależności określonych w panelu Środowisko notesu dołączonego do obliczeń bezserwerowych, kliknij strzałkę obok pozycji Zastosuj , a następnie kliknij pozycję Resetuj środowisko.
Uwaga
Zresetuj środowisko wirtualne, jeśli zainstalujesz pakiety powodujące przerwanie lub zmianę podstawowego notesu lub środowiska platformy Apache Spark. Odłączanie notesu od bezserwerowych obliczeń i ponowne dołączanie go niekoniecznie powoduje wyczyszczenie całej pamięci podręcznej środowiska.
Wyświetlanie szczegółowych informacji o zapytaniach
Bezserwerowe obliczenia dla notesów i przepływów pracy używają szczegółowych informacji o zapytaniach do oceny wydajności wykonywania platformy Spark. Po uruchomieniu komórki w notesie możesz wyświetlić szczegółowe informacje związane z zapytaniami SQL i Python, klikając link Zobacz wydajność .
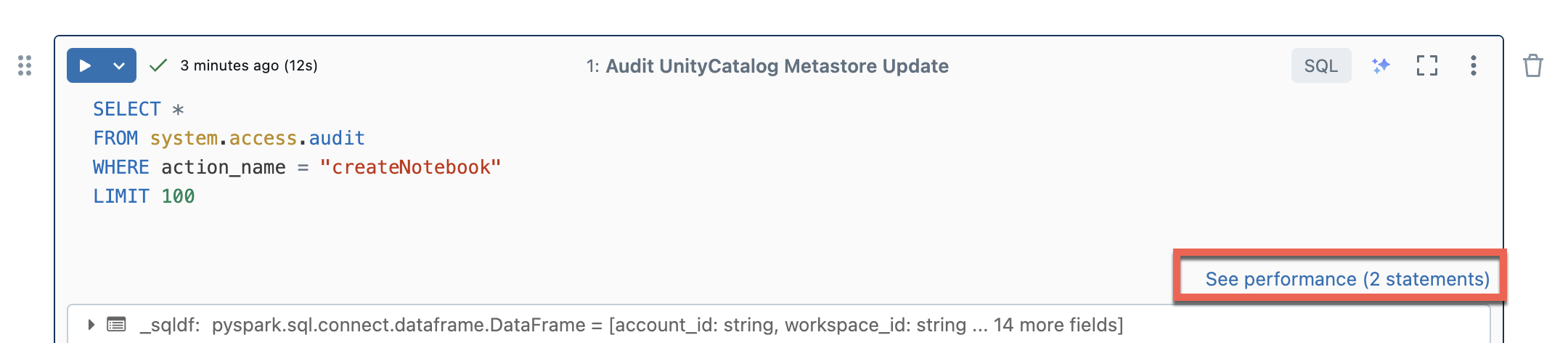
Możesz kliknąć dowolną instrukcję platformy Spark, aby wyświetlić metryki zapytania. W tym miejscu możesz kliknąć pozycję Zobacz profil zapytania, aby wyświetlić wizualizację wykonywania zapytania. Aby uzyskać więcej informacji na temat profilów zapytań, zobacz Profil zapytania.
Uwaga
Aby wyświetlić szczegółowe informacje o wydajności przebiegów zadań, zobacz Wyświetlanie szczegółowych informacji o zapytaniach uruchamiania zadania.
Historia zapytań
Wszystkie zapytania uruchamiane na bezserwerowych obliczeniach będą również rejestrowane na stronie historii zapytań obszaru roboczego. Aby uzyskać informacje na temat historii zapytań, zobacz Historia zapytań.
Ograniczenia szczegółowych informacji o zapytaniach
- Profil zapytania jest dostępny tylko po zakończeniu wykonywania zapytania.
- Metryki są aktualizowane na żywo, chociaż profil zapytania nie jest wyświetlany podczas wykonywania.
- Omówiono tylko następujące stany zapytania: URUCHOMIONE, ANULOWANE, ZAKOŃCZONE, ZAKOŃCZONE.
- Nie można anulować uruchamiania zapytań ze strony historii zapytań. Można je anulować w notesach lub zadaniach.
- Pełne metryki nie są dostępne.
- Pobieranie profilu zapytania jest niedostępne.
- Dostęp do interfejsu użytkownika platformy Spark jest niedostępny.
- Tekst instrukcji zawiera tylko ostatni wiersz, który został uruchomiony. Może jednak istnieć kilka wierszy poprzedzających ten wiersz, które zostały uruchomione w ramach tej samej instrukcji.
Ograniczenia
Aby uzyskać listę ograniczeń, zobacz Ograniczenia obliczeniowe bezserwerowe.