Ciągła integracja i ciągłe dostarczanie w usłudze Azure Databricks przy użyciu usługi Azure DevOps
Uwaga
W tym artykule opisano usługę Azure DevOps, która nie jest dostarczana ani obsługiwana przez usługę Databricks. Aby skontaktować się z dostawcą, zobacz Pomoc techniczna usługi Azure DevOps Services.
Ten artykuł przeprowadzi Cię przez proces konfigurowania automatyzacji usługi Azure DevOps dla kodu i artefaktów, które współpracują z usługą Azure Databricks. W szczególności skonfigurujesz przepływ pracy ciągłej integracji i dostarczania (CI/CD) w celu nawiązania połączenia z repozytorium Git, uruchomisz zadania przy użyciu usługi Azure Pipelines w celu skompilowania i przetestowania jednostkowego koła języka Python (*.whl) i wdrożysz go do użycia w notesach usługi Databricks.
Przepływ pracy programowania ciągłej integracji/ciągłego wdrażania
Usługa Databricks sugeruje następujący przepływ pracy na potrzeby programowania ciągłej integracji/ciągłego wdrażania za pomocą usługi Azure DevOps:
- Utwórz repozytorium lub użyj istniejącego repozytorium z dostawcą git innej firmy.
- Połącz lokalną maszynę programową z tym samym repozytorium innej firmy. Aby uzyskać instrukcje, zobacz dokumentację dostawcy git innej firmy.
- Pobierz wszystkie istniejące zaktualizowane artefakty (takie jak notesy, pliki kodu i skrypty kompilacji) w dół do lokalnej maszyny deweloperów z repozytorium innej firmy.
- W razie potrzeby utwórz, zaktualizuj i przetestuj artefakty na lokalnej maszynie dewelopera. Następnie wypchnij wszystkie nowe i zmienione artefakty z lokalnej maszyny deweloperów do repozytorium innej firmy. Aby uzyskać instrukcje, zobacz dokumentację dostawcy git innej firmy.
- Powtórz kroki 3 i 4 zgodnie z potrzebami.
- Użyj usługi Azure DevOps okresowo jako zintegrowanego podejścia do automatycznego ściągania artefaktów z repozytorium innej firmy, tworzenia, testowania i uruchamiania kodu w obszarze roboczym usługi Azure Databricks oraz raportowania wyników testu i uruchamiania. Chociaż można uruchomić usługę Azure DevOps ręcznie, w rzeczywistych implementacjach należy poinstruować dostawcę usługi Git innej firmy, aby uruchamiał usługę Azure DevOps za każdym razem, gdy wystąpi określone zdarzenie, takie jak żądanie ściągnięcia repozytorium.
Istnieje wiele narzędzi ciągłej integracji/ciągłego wdrażania, których można użyć do zarządzania potokiem i wykonywania go. W tym artykule pokazano, jak używać usługi Azure DevOps. Ciągła integracja/ciągłe wdrażanie jest wzorcem projektowym, więc kroki i etapy opisane w tym artykule powinny zostać przeniesione z kilkoma zmianami w języku definicji potoku w każdym narzędziu. Ponadto większość kodu w tym przykładowym potoku to standardowy kod języka Python, który można wywołać w innych narzędziach.
Napiwek
Aby uzyskać informacje na temat korzystania z serwera Jenkins z usługą Azure Databricks zamiast usługi Azure DevOps, zobacz Ciągła integracja/ciągłe wdrażanie za pomocą narzędzia Jenkins w usłudze Azure Databricks.
W pozostałej części tego artykułu opisano parę przykładowych potoków w usłudze Azure DevOps, które można dostosować do własnych potrzeb usługi Azure Databricks.
Informacje o przykładzie
W tym artykule użyto dwóch potoków do zbierania, wdrażania i uruchamiania przykładowego kodu języka Python oraz notesów języka Python przechowywanych w zdalnym repozytorium Git.
Pierwszy potok, znany jako potok kompilacji, przygotowuje artefakty kompilacji dla drugiego potoku , znanego jako potok wydania . Oddzielenie potoku kompilacji z potoku wydania umożliwia utworzenie artefaktu kompilacji bez wdrażania go lub jednoczesnego wdrażania artefaktów z wielu kompilacji. Aby utworzyć potoki kompilacji i wydania:
- Utwórz maszynę wirtualną platformy Azure dla potoku kompilacji.
- Skopiuj pliki z repozytorium Git do maszyny wirtualnej.
- Utwórz plik tar gzip'ed zawierający kod języka Python, notesy języka Python oraz powiązane pliki kompilacji, wdrażania i uruchamiania ustawień.
- Skopiuj plik tar gzip'ed jako plik zip do lokalizacji potoku wydania, aby uzyskać dostęp.
- Utwórz inną maszynę wirtualną platformy Azure dla potoku wydania.
- Pobierz plik zip z lokalizacji potoku kompilacji, a następnie rozpakuj plik zip, aby pobrać kod języka Python, notesy języka Python i powiązane pliki kompilacji, wdrożenia i uruchamiania ustawień.
- Wdróż kod języka Python, notesy języka Python oraz powiązane pliki kompilacji, wdrażania i uruchamiania ustawień w zdalnym obszarze roboczym usługi Azure Databricks.
- Skompiluj pliki kodu składników biblioteki wheel języka Python w pliku wheel języka Python.
- Uruchom testy jednostkowe w kodzie składnika, aby sprawdzić logikę w pliku wheel języka Python.
- Uruchom notesy języka Python, z których jeden wywołuje funkcje pliku wheel języka Python.
Informacje o interfejsie wiersza polecenia usługi Databricks
W tym artykule pokazano, jak używać interfejsu wiersza polecenia usługi Databricks w trybie nieinterakcyjnym w potoku. Przykładowy potok tego artykułu wdraża kod, kompiluje bibliotekę i uruchamia notesy w obszarze roboczym usługi Azure Databricks.
Jeśli używasz interfejsu wiersza polecenia usługi Databricks w potoku bez implementowania przykładowego kodu, biblioteki i notesów z tego artykułu, wykonaj następujące kroki:
Przygotuj obszar roboczy usługi Azure Databricks do używania uwierzytelniania maszyny do maszyny OAuth (M2M) na potrzeby uwierzytelniania jednostki usługi. Przed rozpoczęciem upewnij się, że masz jednostkę usługi Microsoft Entra ID (dawniej Azure Active Directory) z wpisem tajnym OAuth usługi Azure Databricks. Zobacz Używanie jednostki usługi do uwierzytelniania w usłudze Azure Databricks.
Zainstaluj interfejs wiersza polecenia usługi Databricks w potoku. W tym celu dodaj zadanie skryptu powłoki Bash do potoku, które uruchamia następujący skrypt:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shAby dodać zadanie skryptu powłoki Bash do potoku, zobacz Krok 3.6. Zainstaluj interfejs wiersza polecenia usługi Databricks i narzędzia kompilacji koła języka Python.
Skonfiguruj potok, aby umożliwić zainstalowanemu interfejsowi wiersza polecenia usługi Databricks uwierzytelnianie jednostki usługi w obszarze roboczym. Aby to zrobić, zobacz Krok 3.1: Definiowanie zmiennych środowiskowych dla potoku wydania.
Dodaj więcej zadań skryptu powłoki Bash do potoku zgodnie z potrzebami, aby uruchomić polecenia interfejsu wiersza polecenia usługi Databricks. Zobacz Polecenia interfejsu wiersza polecenia usługi Databricks.
Zanim rozpoczniesz
Aby użyć przykładu tego artykułu, musisz mieć następujące elementy:
- Istniejący projekt usługi Azure DevOps . Jeśli nie masz jeszcze projektu, utwórz projekt w usłudze Azure DevOps.
- Istniejące repozytorium z dostawcą Usługi Git obsługiwanego przez usługę Azure DevOps. Do tego repozytorium dodasz przykładowy kod języka Python, przykładowy notes języka Python i powiązane pliki ustawień wydania. Jeśli nie masz jeszcze repozytorium, utwórz je, postępując zgodnie z instrukcjami dostawcy usługi Git. Następnie połącz projekt usługi Azure DevOps z tym repozytorium, jeśli jeszcze tego nie zrobiono. Aby uzyskać instrukcje, postępuj zgodnie z linkami w temacie Obsługiwane repozytoria źródłowe.
- W tym artykule użyto uwierzytelniania OAuth machine-to-machine (M2M) w celu uwierzytelnienia jednostki usługi Microsoft Entra ID (dawniej Azure Active Directory) w obszarze roboczym usługi Azure Databricks. Musisz mieć jednostkę usługi Microsoft Entra ID z wpisem tajnym OAuth usługi Azure Databricks dla tej jednostki usługi. Zobacz Używanie jednostki usługi do uwierzytelniania w usłudze Azure Databricks.
Krok 1. Dodawanie plików przykładu do repozytorium
W tym kroku w repozytorium z dostawcą git innej firmy dodasz wszystkie przykładowe pliki tego artykułu, które potoki usługi Azure DevOps kompilują, wdrażają i uruchamiają w zdalnym obszarze roboczym usługi Azure Databricks.
Krok 1.1. Dodawanie plików składników wheel języka Python
W tym przykładzie potoki usługi Azure DevOps kompilują i testują jednostkowy plik koła języka Python. Następnie notes usługi Azure Databricks wywołuje funkcję skompilowanych plików wheel języka Python.
Aby zdefiniować logikę i testy jednostkowe dla pliku wheel języka Python, względem którego działają notesy, w katalogu głównym repozytorium utwórz dwa pliki o nazwie i test_addcol.py, a następnie dodaj je do struktury folderów o nazwie addcol.py python/dabdemo/dabdemo w folderzeLibraries, zwizualizowane w następujący sposób:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
Plik addcol.py zawiera funkcję biblioteki wbudowaną później w plik wheel języka Python, a następnie zainstalowaną w klastrach usługi Azure Databricks. Jest to prosta funkcja, która dodaje nową kolumnę wypełniną literałem do ramki danych platformy Apache Spark:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Plik test_addcol.py zawiera testy, aby przekazać pozorny obiekt ramki danych do with_status funkcji zdefiniowanej w addcol.pypliku . Wynik jest następnie porównywany z obiektem DataFrame zawierającym oczekiwane wartości. Jeśli wartości są zgodne, test zakończy się pomyślnie:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Aby umożliwić interfejsowi wiersza polecenia usługi Databricks poprawne spakowanie tego kodu biblioteki do pliku koła języka Python, utwórz dwa pliki o nazwie __init__.py i __main__.py w tym samym folderze co poprzednie dwa pliki. Ponadto utwórz plik o nazwie setup.py w folderze zwizualizowany python/dabdemo w następujący sposób:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
Plik __init__.py zawiera numer wersji biblioteki i jego autora. Zastąp <my-author-name> ciąg nazwą:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Plik __main__.py zawiera punkt wejścia biblioteki:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Plik setup.py zawiera dodatkowe ustawienia tworzenia biblioteki w pliku wheel języka Python. Zastąp <my-url>wartości , <my-author-name>@<my-organization>i <my-package-description> prawidłowymi wartościami:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Krok 1.2. Dodawanie notesu testowania jednostkowego dla pliku wheel języka Python
Później interfejs wiersza polecenia usługi Databricks uruchamia zadanie notesu. To zadanie uruchamia notes języka Python z nazwą pliku run_unit_tests.py. Ten notes działa pytest w odniesieniu do logiki biblioteki wheel języka Python.
Aby uruchomić testy jednostkowe dla przykładu tego artykułu, dodaj do katalogu głównego repozytorium plik notesu o nazwie o następującej run_unit_tests.py zawartości:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Krok 1.3. Dodawanie notesu, który wywołuje plik wheel języka Python
Później interfejs wiersza polecenia usługi Databricks uruchamia inne zadanie notesu. Ten notes tworzy obiekt ramki danych, przekazuje go do funkcji biblioteki with_status kół języka Python, wyświetla wynik i raportuje wyniki uruchomienia zadania. Utwórz katalog główny repozytorium pliku notesu o nazwie o dabdemo_notebook.py następującej zawartości:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Krok 1.4. Tworzenie konfiguracji pakietu
W tym przykładzie użyto pakietów zasobów usługi Databricks do zdefiniowania ustawień i zachowań związanych z kompilowaniem, wdrażaniem i uruchamianiem pliku wheel języka Python, dwoma notesami i plikiem kodu języka Python. Pakiety zasobów usługi Databricks, znane po prostu jako pakiety, umożliwiają wyrażanie pełnych danych, analiz i projektów uczenia maszynowego jako kolekcji plików źródłowych. Zobacz Co to są pakiety zasobów usługi Databricks?.
Aby skonfigurować pakiet dla przykładu tego artykułu, utwórz w katalogu głównym repozytorium plik o nazwie databricks.yml. W tym przykładowym databricks.yml pliku zastąp następujące symbole zastępcze:
- Zastąp
<bundle-name>element unikatową nazwą programową pakietu. Na przykładazure-devops-demo. - Zastąp
<job-prefix-name>ciąg ciągiem, aby ułatwić unikatowe zidentyfikowanie zadań utworzonych w obszarze roboczym usługi Azure Databricks w tym przykładzie. Na przykładazure-devops-demo. - Zastąp element
<spark-version-id>identyfikatorem wersji środowiska Databricks Runtime dla klastrów zadań, na przykład13.3.x-scala2.12. - Zastąp
<cluster-node-type-id>ciąg identyfikatorem typu węzła klastra dla klastrów zadań, na przykładStandard_DS3_v2. - Zwróć uwagę, że
devwtargetsmapowaniu określa hosta i powiązane zachowania wdrażania. W rzeczywistych implementacjach możesz nadać temu celowi inną nazwę we własnych pakietach.
Oto zawartość pliku tego przykładu databricks.yml :
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
Aby uzyskać więcej informacji na temat databricks.yml składni pliku, zobacz Konfiguracje pakietu zasobów usługi Databricks.
Krok 2. Definiowanie potoku kompilacji
Usługa Azure DevOps udostępnia interfejs użytkownika hostowany w chmurze do definiowania etapów potoku ciągłej integracji/ciągłego wdrażania przy użyciu języka YAML. Aby uzyskać więcej informacji na temat usługi Azure DevOps i potoków, zobacz dokumentację usługi Azure DevOps.
W tym kroku użyjesz znaczników YAML do zdefiniowania potoku kompilacji, który tworzy artefakt wdrożenia. Aby wdrożyć kod w obszarze roboczym usługi Azure Databricks, należy określić artefakt kompilacji tego potoku jako dane wejściowe w potoku wydania. Ten potok wydania definiuje się później.
Aby uruchamiać potoki kompilacji, usługa Azure DevOps udostępnia agentów wykonywania hostowanych w chmurze na żądanie, które obsługują wdrożenia na platformie Kubernetes, maszynach wirtualnych, usłudze Azure Functions, usłudze Azure Web Apps i wielu innych miejscach docelowych. W tym przykładzie użyjesz agenta na żądanie, aby zautomatyzować tworzenie artefaktu wdrożenia.
Zdefiniuj przykładowy potok kompilacji tego artykułu w następujący sposób:
Zaloguj się do usługi Azure DevOps , a następnie kliknij link Zaloguj, aby otworzyć projekt usługi Azure DevOps.
Uwaga
Jeśli witryna Azure Portal wyświetli zamiast projektu usługi Azure DevOps, kliknij pozycję Więcej usług > w organizacjach > usługi Azure DevOps Moja organizacja usługi Azure DevOps, a następnie otwórz projekt usługi Azure DevOps.
Kliknij pozycję Potoki na pasku bocznym, a następnie kliknij pozycję Potoki w menu Potoki .
Kliknij przycisk Nowy potok i postępuj zgodnie z instrukcjami wyświetlanymi na ekranie. (Jeśli masz już potoki, kliknij przycisk Zamiast tego utwórz potok ). Na końcu tych instrukcji zostanie otwarty edytor potoku. W tym miejscu zdefiniujesz skrypt potoku kompilacji w wyświetlonym
azure-pipelines.ymlpliku. Jeśli edytor potoku nie jest widoczny na końcu instrukcji, wybierz nazwę potoku kompilacji, a następnie kliknij przycisk Edytuj.Selektor
 gałęzi Git umożliwia dostosowanie procesu kompilacji dla każdej gałęzi w repozytorium Git. Najlepszym rozwiązaniem jest brak możliwości wykonywania pracy produkcyjnej
gałęzi Git umożliwia dostosowanie procesu kompilacji dla każdej gałęzi w repozytorium Git. Najlepszym rozwiązaniem jest brak możliwości wykonywania pracy produkcyjnej mainbezpośrednio w gałęzi repozytorium. W tym przykładzie założono, że gałąź o nazwiereleaseistnieje w repozytorium, które ma być używane zamiastmain.
Skrypt
azure-pipelines.ymlpotoku kompilacji jest domyślnie przechowywany w katalogu głównym zdalnego repozytorium Git skojarzonego z potokiem.Zastąp zawartość początkową pliku potoku
azure-pipelines.ymlnastępującą definicją, a następnie kliknij przycisk Zapisz.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Krok 3. Definiowanie potoku wydania
Potok wydania wdraża artefakty kompilacji z potoku kompilacji do środowiska usługi Azure Databricks. Oddzielenie potoku wydania w tym kroku od potoku kompilacji w poprzednich krokach umożliwia utworzenie kompilacji bez jej wdrożenia lub wdrożenie artefaktów z wielu kompilacji jednocześnie.
W projekcie usługi Azure DevOps w menu Potoki na pasku bocznym kliknij pozycję Wydania.
Kliknij pozycję Nowy > potok wydania. (Jeśli masz już potoki, kliknij przycisk Zamiast tego nowy potok ).
Po stronie ekranu znajduje się lista polecanych szablonów dla typowych wzorców wdrażania. Na potrzeby tego przykładowego potoku wydania kliknij pozycję
 .
.
W polu Artefakty po stronie ekranu kliknij pozycję
 . W okienku Dodawanie artefaktu w polu Źródło (potok kompilacji) wybierz utworzony wcześniej potok kompilacji. Następnie kliknij pozycję Dodaj.
. W okienku Dodawanie artefaktu w polu Źródło (potok kompilacji) wybierz utworzony wcześniej potok kompilacji. Następnie kliknij pozycję Dodaj.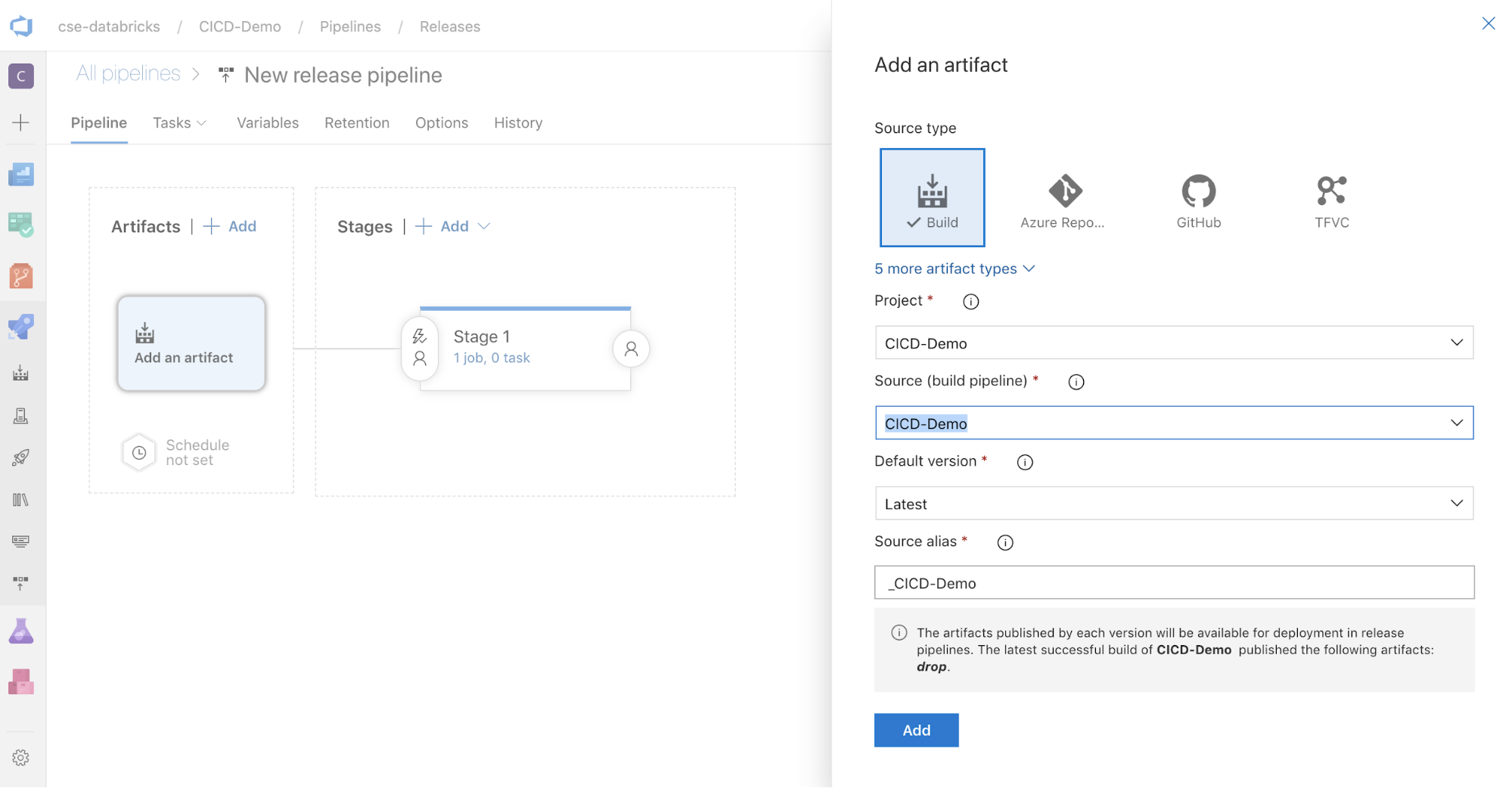
Możesz skonfigurować sposób wyzwalania potoku, klikając
 , aby wyświetlić opcje wyzwalania po stronie ekranu. Jeśli chcesz, aby wydanie zostało zainicjowane automatycznie na podstawie dostępności artefaktu kompilacji lub po przepływie pracy żądania ściągnięcia, włącz odpowiedni wyzwalacz. Na razie w tym przykładzie w ostatnim kroku tego artykułu ręcznie wyzwolisz potok kompilacji, a następnie potok wydania.
, aby wyświetlić opcje wyzwalania po stronie ekranu. Jeśli chcesz, aby wydanie zostało zainicjowane automatycznie na podstawie dostępności artefaktu kompilacji lub po przepływie pracy żądania ściągnięcia, włącz odpowiedni wyzwalacz. Na razie w tym przykładzie w ostatnim kroku tego artykułu ręcznie wyzwolisz potok kompilacji, a następnie potok wydania.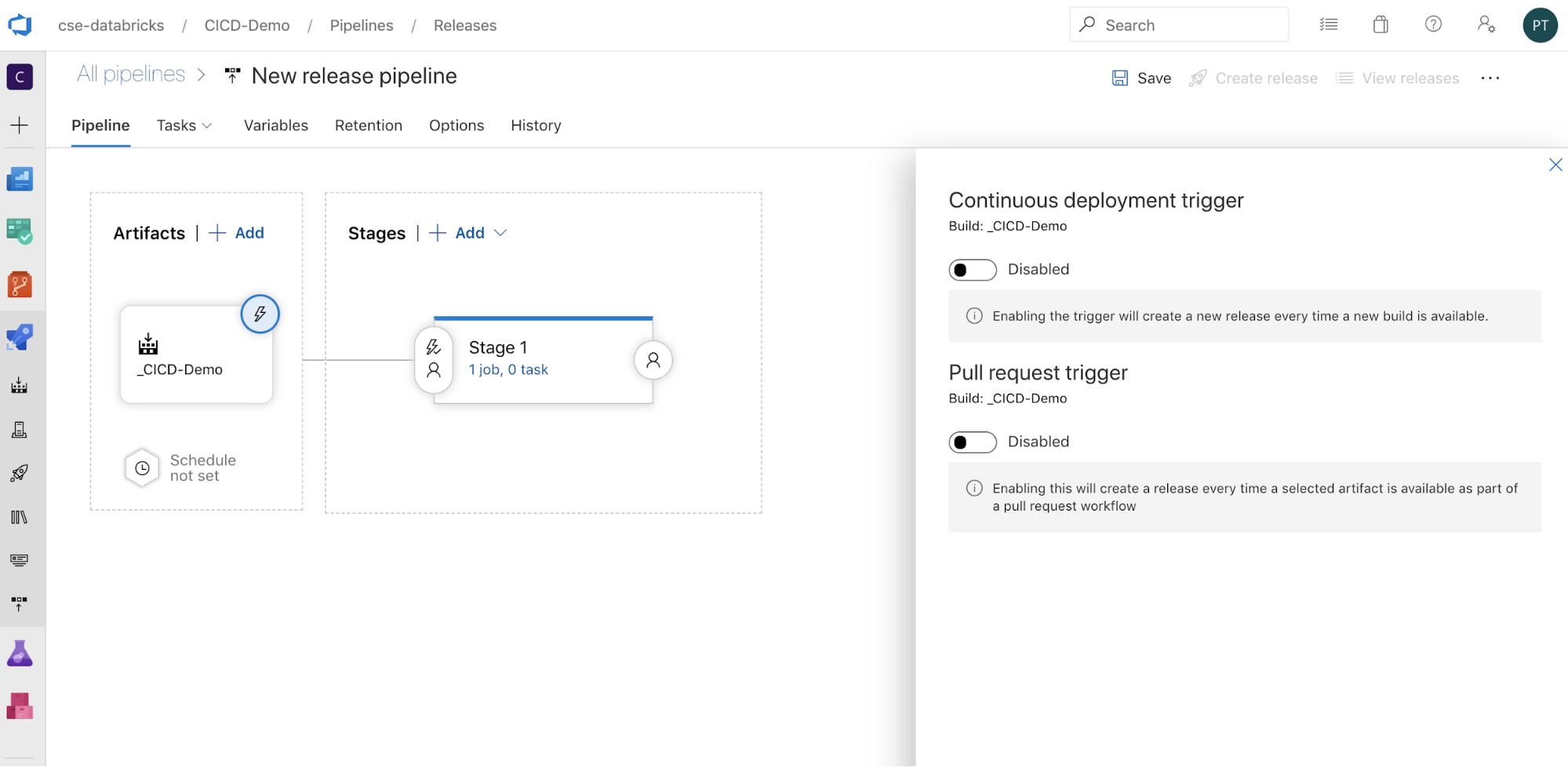
Kliknij przycisk Zapisz > OK.
Krok 3.1. Definiowanie zmiennych środowiskowych dla potoku wydania
Potok wydania tego przykładu opiera się na następujących zmiennych środowiskowych, które można dodać, klikając pozycję Dodaj w sekcji Zmienne potoku na karcie Zmienne z zakresem etapu 1:
BUNDLE_TARGET, który powinien być zgodny ztargetnazwą wdatabricks.ymlpliku. W tym przykładzie tego artykułu jest todev.DATABRICKS_HOST, który reprezentuje adres URL dla poszczególnych obszarów roboczych obszaru roboczego usługi Azure Databricks, zaczynając odhttps://, na przykładhttps://adb-<workspace-id>.<random-number>.azuredatabricks.net. Nie dołączaj końcowego/ciągu po.net.DATABRICKS_CLIENT_ID, który reprezentuje identyfikator aplikacji dla jednostki usługi Microsoft Entra ID.DATABRICKS_CLIENT_SECRET, który reprezentuje wpis tajny OAuth usługi Azure Databricks dla jednostki usługi Microsoft Entra ID.
Krok 3.2. Konfigurowanie agenta wydania dla potoku wydania
Kliknij łącze 1 zadanie, 0 zadania w obiekcie Etap 1.
Na karcie Zadania kliknij pozycję Zadanie agenta.
W sekcji Wybór agenta w polu Pula agentów wybierz pozycję Azure Pipelines.
W obszarze Specyfikacja agenta wybierz tego samego agenta, który został wcześniej określony dla agenta kompilacji, w tym przykładzie ubuntu-22.04.
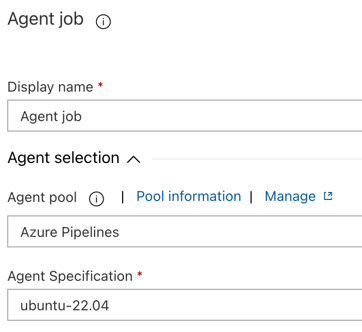
Kliknij przycisk Zapisz > OK.
Krok 3.3. Ustawianie wersji języka Python dla agenta wydania
Kliknij znak plus w sekcji Zadanie agenta wskazywane przez czerwoną strzałkę na poniższej ilustracji. Zostanie wyświetlona lista dostępnych zadań z możliwością wyszukiwania. Istnieje również karta Marketplace dla wtyczek innych firm, które mogą służyć do uzupełnienia standardowych zadań usługi Azure DevOps. W kolejnych kilku krokach dodasz kilka zadań do agenta wydania.
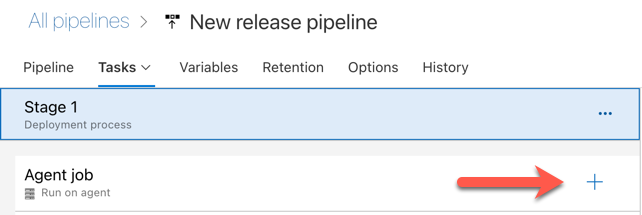
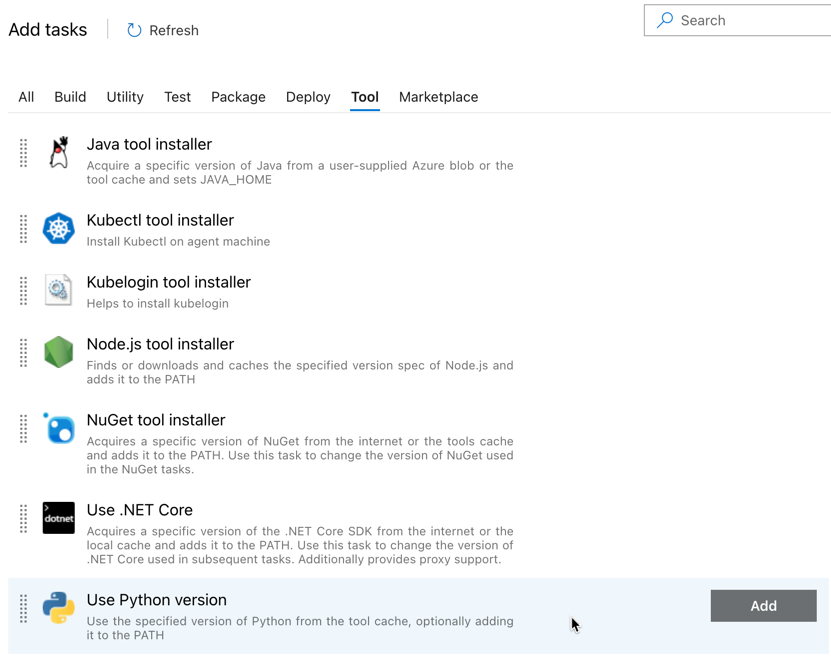
Pierwszym dodanym zadaniem jest użycie wersji języka Python znajdującej się na karcie Narzędzie . Jeśli nie możesz odnaleźć tego zadania, użyj pola Wyszukiwania , aby go wyszukać. Po znalezieniu wybierz go, a następnie kliknij przycisk Dodaj obok zadania Użyj wersji języka Python.
Podobnie jak w przypadku potoku kompilacji, chcesz upewnić się, że wersja języka Python jest zgodna ze skryptami wywoływanymi w kolejnych zadaniach. W takim przypadku kliknij zadanie Użyj języka Python 3.x obok pozycji Zadanie agenta, a następnie ustaw opcję Specyfikacja wersji na
3.10. Ustaw również wartość Nazwa wyświetlana naUse Python 3.10. W tym potoku założono, że używasz środowiska Databricks Runtime 13.3 LTS w klastrach z zainstalowanym językiem Python 3.10.12.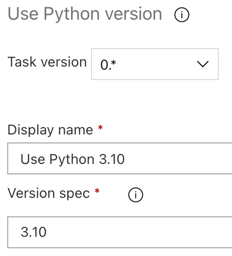
Kliknij przycisk Zapisz > OK.
Krok 3.4. Rozpakowywanie artefaktu kompilacji z potoku kompilacji
Następnie agent wydania wyodrębnia plik wheel języka Python, powiązane pliki ustawień wydania, notesy i plik kodu języka Python z pliku zip przy użyciu zadania Wyodrębnij pliki : kliknij przycisk plus w sekcji Zadanie agenta, wybierz zadanie Wyodrębnij pliki na karcie Narzędzie , a następnie kliknij przycisk Dodaj.
Kliknij zadanie Wyodrębnij pliki obok pozycji Zadanie agenta, ustaw opcję Zarchiwizuj wzorce plików na
**/*.zip, a następnie ustaw folder Destination na zmienną systemową$(Release.PrimaryArtifactSourceAlias)/Databricks. Ustaw również wartość Nazwa wyświetlana naExtract build pipeline artifact.Uwaga
$(Release.PrimaryArtifactSourceAlias)reprezentuje alias wygenerowany przez usługę Azure DevOps, aby zidentyfikować podstawową lokalizację źródła artefaktu na agencie wydania, na przykład_<your-github-alias>.<your-github-repo-name>. Potok wydania ustawia tę wartość jako zmienną środowiskowąRELEASE_PRIMARYARTIFACTSOURCEALIASw fazie inicjowania zadania agenta wydania. Zobacz Zmienne wersji klasycznej i artefaktów.Ustaw wartość Nazwa wyświetlana na
Extract build pipeline artifact.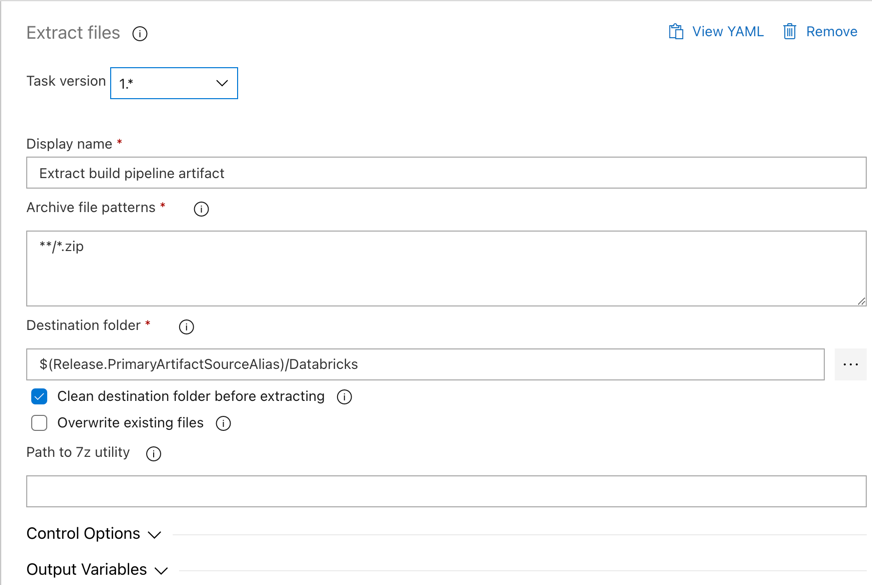
Kliknij przycisk Zapisz > OK.
Krok 3.5. Ustawianie zmiennej środowiskowej BUNDLE_ROOT
Aby przykład tego artykułu działał zgodnie z oczekiwaniami, należy ustawić zmienną środowiskową o nazwie BUNDLE_ROOT w potoku wydania. Pakiety zasobów usługi Databricks używają tej zmiennej środowiskowej do określenia lokalizacji databricks.yml pliku. Aby ustawić tę zmienną środowiskową:
Użyj zadania Zmienne środowiskowe: kliknij ponownie znak plus w sekcji Zadanie agenta, wybierz zadanie Zmienne środowiskowe na karcie Narzędzie, a następnie kliknij przycisk Dodaj.
Uwaga
Jeśli zadanie Zmienne środowiskowe nie jest widoczne na karcie Narzędzie, wprowadź w
Environment Variablespolu Wyszukiwania i postępuj zgodnie z instrukcjami wyświetlanymi na ekranie, aby dodać zadanie do karty Narzędzie. Może to wymagać opuszczenia usługi Azure DevOps, a następnie powrotu do tej lokalizacji, w której została przerwana.W polu Zmienne środowiskowe (rozdzielone przecinkami) wprowadź następującą definicję:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Uwaga
$(Agent.ReleaseDirectory)reprezentuje alias wygenerowany przez usługę Azure DevOps w celu zidentyfikowania lokalizacji katalogu wydania na agencie wydania, na przykład/home/vsts/work/r1/a. Potok wydania ustawia tę wartość jako zmienną środowiskowąAGENT_RELEASEDIRECTORYw fazie inicjowania zadania agenta wydania. Zobacz Zmienne wersji klasycznej i artefaktów. Aby uzyskać informacje o$(Release.PrimaryArtifactSourceAlias)programie , zobacz notatkę w poprzednim kroku.Ustaw wartość Nazwa wyświetlana na
Set BUNDLE_ROOT environment variable.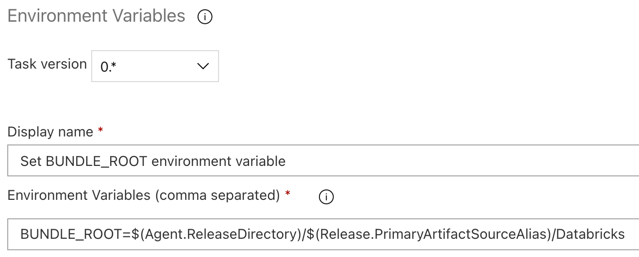
Kliknij przycisk Zapisz > OK.
Krok 3.6. Instalowanie interfejsu wiersza polecenia usługi Databricks i narzędzi kompilacji koła języka Python
Następnie zainstaluj interfejs wiersza polecenia usługi Databricks i narzędzia kompilacji wheel języka Python na agencie wydania. Agent wydania wywoła interfejs wiersza polecenia usługi Databricks i narzędzia kompilacji koła języka Python w kilku następnych zadaniach. W tym celu użyj zadania powłoki Bash : kliknij ponownie znak plus w sekcji Zadanie agenta , wybierz zadanie powłoki Bash na karcie Narzędzie , a następnie kliknij przycisk Dodaj.
Kliknij zadanie skryptu powłoki Bash obok pozycji Zadanie agenta.
W polu Typ wybierz pozycję Wbudowany.
Zastąp zawartość skryptu następującym poleceniem, które instaluje interfejs wiersza polecenia usługi Databricks i narzędzia kompilacji koła języka Python:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelUstaw wartość Nazwa wyświetlana na
Install Databricks CLI and Python wheel build tools.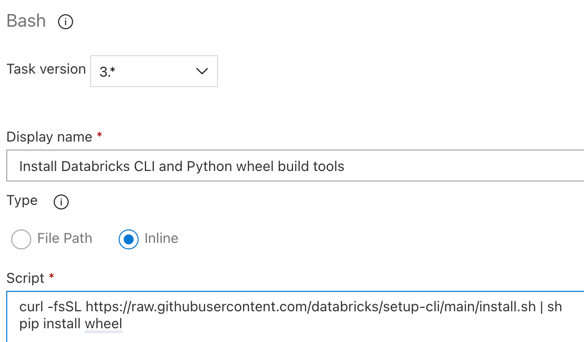
Kliknij przycisk Zapisz > OK.
Krok 3.7. Weryfikowanie pakietu zasobów usługi Databricks
W tym kroku upewnij się, że databricks.yml plik jest syntaktycznie poprawny.
Użyj zadania powłoki Bash : kliknij ponownie znak plus w sekcji Zadanie agenta, wybierz zadanie powłoki Bash na karcie Narzędzie , a następnie kliknij przycisk Dodaj.
Kliknij zadanie skryptu powłoki Bash obok pozycji Zadanie agenta.
W polu Typ wybierz pozycję Wbudowany.
Zastąp zawartość skryptu następującym poleceniem, które używa interfejsu wiersza polecenia usługi Databricks, aby sprawdzić, czy
databricks.ymlplik jest składniowo poprawny:databricks bundle validate -t $(BUNDLE_TARGET)Ustaw wartość Nazwa wyświetlana na
Validate bundle.Kliknij przycisk Zapisz > OK.
Krok 3.8. Wdrażanie pakietu
W tym kroku skompilujesz plik wheel języka Python i wdrożysz skompilowany plik wheel języka Python, dwa notesy języka Python i plik języka Python z potoku wydania do obszaru roboczego usługi Azure Databricks.
Użyj zadania powłoki Bash : kliknij ponownie znak plus w sekcji Zadanie agenta, wybierz zadanie powłoki Bash na karcie Narzędzie , a następnie kliknij przycisk Dodaj.
Kliknij zadanie skryptu powłoki Bash obok pozycji Zadanie agenta.
W polu Typ wybierz pozycję Wbudowany.
Zastąp zawartość skryptu następującym poleceniem, które używa interfejsu wiersza polecenia usługi Databricks do skompilowania pliku wheel języka Python i wdrożenia przykładowych plików tego artykułu z potoku wydania do obszaru roboczego usługi Azure Databricks:
databricks bundle deploy -t $(BUNDLE_TARGET)Ustaw wartość Nazwa wyświetlana na
Deploy bundle.Kliknij przycisk Zapisz > OK.
Krok 3.9. Uruchamianie notesu testów jednostkowych dla koła języka Python
W tym kroku uruchomisz zadanie uruchamiające notes testu jednostkowego w obszarze roboczym usługi Azure Databricks. Ten notes uruchamia testy jednostkowe względem logiki biblioteki wheel języka Python.
Użyj zadania powłoki Bash : kliknij ponownie znak plus w sekcji Zadanie agenta, wybierz zadanie powłoki Bash na karcie Narzędzie , a następnie kliknij przycisk Dodaj.
Kliknij zadanie skryptu powłoki Bash obok pozycji Zadanie agenta.
W polu Typ wybierz pozycję Wbudowany.
Zastąp zawartość skryptu następującym poleceniem, które używa interfejsu wiersza polecenia usługi Databricks do uruchomienia zadania w obszarze roboczym usługi Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsUstaw wartość Nazwa wyświetlana na
Run unit tests.Kliknij przycisk Zapisz > OK.
Krok 3.10. Uruchamianie notesu wywołującego koło języka Python
W tym kroku uruchomisz zadanie, które uruchamia inny notes w obszarze roboczym usługi Azure Databricks. Ten notes wywołuje bibliotekę wheel języka Python.
Użyj zadania powłoki Bash : kliknij ponownie znak plus w sekcji Zadanie agenta, wybierz zadanie powłoki Bash na karcie Narzędzie , a następnie kliknij przycisk Dodaj.
Kliknij zadanie skryptu powłoki Bash obok pozycji Zadanie agenta.
W polu Typ wybierz pozycję Wbudowany.
Zastąp zawartość skryptu następującym poleceniem, które używa interfejsu wiersza polecenia usługi Databricks do uruchomienia zadania w obszarze roboczym usługi Azure Databricks:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookUstaw wartość Nazwa wyświetlana na
Run notebook.Kliknij przycisk Zapisz > OK.
Ukończono konfigurowanie potoku wydania. Powinna wyglądać następująco:
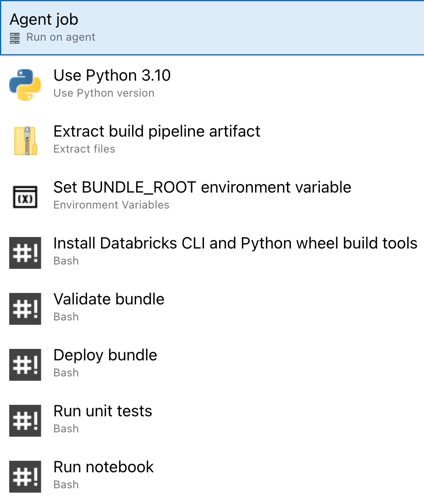
Krok 4. Uruchamianie potoków kompilacji i wydania
W tym kroku uruchomisz potoki ręcznie. Aby dowiedzieć się, jak uruchamiać potoki automatycznie, zobacz Określanie zdarzeń wyzwalających potoki i wyzwalaczy wydania.
Aby ręcznie uruchomić potok kompilacji:
- W menu Potoki na pasku bocznym kliknij pozycję Potoki.
- Kliknij nazwę potoku kompilacji, a następnie kliknij pozycję Uruchom potok.
- W polu Gałąź/tag wybierz nazwę gałęzi w repozytorium Git, która zawiera cały dodany kod źródłowy. W tym przykładzie przyjęto założenie, że znajduje się on w
releasegałęzi . - Kliknij Uruchom. Zostanie wyświetlona strona uruchamiania potoku kompilacji.
- Aby wyświetlić postęp potoku kompilacji i wyświetlić powiązane dzienniki, kliknij ikonę wirowania obok pozycji Zadanie.
- Gdy ikona Zadania zmieni się na zielony znacznik wyboru, przejdź do uruchomienia potoku wydania.
Aby ręcznie uruchomić potok wydania:
- Po pomyślnym uruchomieniu potoku kompilacji na pasku bocznym w menu Potoki kliknij pozycję Wydania.
- Kliknij nazwę potoku wydania, a następnie kliknij pozycję Utwórz wydanie.
- Kliknij pozycję Utwórz.
- Aby wyświetlić postęp potoku wydania, na liście wydań kliknij nazwę najnowszej wersji.
- W polu Etapy kliknij pozycję Etap 1, a następnie kliknij pozycję Dzienniki.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla