Ciągła integracja/ciągłe wdrażanie za pomocą usługi Jenkins w usłudze Azure Databricks
Uwaga
W tym artykule opisano usługę Jenkins, która nie jest ani udostępniana ani obsługiwana przez usługę Databricks. Aby skontaktować się z dostawcą, zobacz Pomoc usługi Jenkins.
Istnieje wiele narzędzi ciągłej integracji/ciągłego wdrażania, których można użyć do zarządzania potokami ciągłej integracji/ciągłego wdrażania i uruchamiania ich. W tym artykule pokazano, jak używać serwera automatyzacji Jenkins . Ciągła integracja/ciągłe wdrażanie jest wzorcem projektowym, dlatego kroki i etapy opisane w tym artykule powinny zostać przeniesione z kilkoma zmianami w języku definicji potoku w każdym narzędziu. Ponadto większość kodu w tym przykładowym potoku uruchamia standardowy kod języka Python, który można wywołać w innych narzędziach. Aby zapoznać się z omówieniem ciągłej integracji/ciągłego wdrażania w usłudze Azure Databricks, zobacz Co to jest ciągła integracja/ciągłe wdrażanie w usłudze Azure Databricks?.
Aby uzyskać informacje na temat korzystania z usługi Azure DevOps z usługą Azure Databricks, zobacz Ciągła integracja i ciągłe dostarczanie w usłudze Azure Databricks przy użyciu usługi Azure DevOps.
Przepływ pracy programowania ciągłej integracji/ciągłego wdrażania
Usługa Databricks sugeruje następujący przepływ pracy na potrzeby programowania ciągłej integracji/ciągłego wdrażania za pomocą usługi Jenkins:
- Utwórz repozytorium lub użyj istniejącego repozytorium z dostawcą git innej firmy.
- Połącz lokalną maszynę programową z tym samym repozytorium innej firmy. Aby uzyskać instrukcje, zobacz dokumentację dostawcy git innej firmy.
- Pobierz wszystkie istniejące zaktualizowane artefakty (takie jak notesy, pliki kodu i skrypty kompilacji) z repozytorium innej firmy w dół na lokalną maszynę deweloperzą.
- Zgodnie z potrzebami utwórz, zaktualizuj i przetestuj artefakty na lokalnej maszynie dewelopera. Następnie wypchnij wszystkie nowe i zmienione artefakty z lokalnej maszyny deweloperów do repozytorium innej firmy. Aby uzyskać instrukcje, zobacz dokumentację dostawcy git innej firmy.
- Powtórz kroki 3 i 4 zgodnie z potrzebami.
- Użyj narzędzia Jenkins okresowo jako zintegrowanego podejścia do automatycznego ściągania artefaktów z repozytorium innej firmy na lokalną maszynę deweloperzą lub obszar roboczy usługi Azure Databricks; kompilowanie, testowanie i uruchamianie kodu na lokalnym komputerze deweloperskim lub w obszarze roboczym usługi Azure Databricks; oraz raportowanie wyników testów i przebiegów. Chociaż można uruchomić narzędzie Jenkins ręcznie, w rzeczywistych implementacjach należy poinstruować dostawcę usługi Git innej firmy, aby uruchamiał narzędzie Jenkins za każdym razem, gdy wystąpi określone zdarzenie, takie jak żądanie ściągnięcia repozytorium.
W pozostałej części tego artykułu użyto przykładowego projektu do opisania jednego ze sposobów użycia narzędzia Jenkins do zaimplementowania poprzedniego przepływu pracy tworzenia ciągłej integracji/ciągłego wdrażania.
Aby uzyskać informacje na temat korzystania z usługi Azure DevOps zamiast serwera Jenkins, zobacz Ciągła integracja i dostarczanie w usłudze Azure Databricks przy użyciu usługi Azure DevOps.
Konfiguracja lokalnej maszyny dewelopera
W tym przykładzie użyto narzędzia Jenkins w celu poinstruowania interfejsu wiersza polecenia usługi Databricks i pakietów zasobów usługi Databricks w celu wykonania następujących czynności:
- Skompiluj plik wheel języka Python na lokalnej maszynie dewelopera.
- Wdróż skompilowany plik wheel języka Python wraz z dodatkowymi plikami języka Python i notesami języka Python z lokalnej maszyny deweloperów do obszaru roboczego usługi Azure Databricks.
- Przetestuj i uruchom przekazany plik koła języka Python i notesy w tym obszarze roboczym.
Aby skonfigurować lokalną maszynę dewelopera w celu poinstruowania obszaru roboczego usługi Azure Databricks w celu wykonania etapów kompilacji i przekazywania na potrzeby tego przykładu, wykonaj następujące czynności na lokalnej maszynie dewelopera:
Krok 1. Instalowanie wymaganych narzędzi
W tym kroku zainstalujesz interfejs wiersza polecenia usługi Databricks, usługę Jenkins i jqnarzędzia kompilacji koła języka Python na lokalnej maszynie deweloperów. Te narzędzia są wymagane do uruchomienia tego przykładu.
Zainstaluj interfejs wiersza polecenia usługi Databricks w wersji 0.205 lub nowszej, jeśli jeszcze tego nie zrobiono. Usługa Jenkins używa interfejsu wiersza polecenia usługi Databricks do przekazania tych przykładowych testów i uruchamiania instrukcji do obszaru roboczego. Zobacz Instalowanie lub aktualizowanie interfejsu wiersza polecenia usługi Databricks.
Zainstaluj i uruchom narzędzie Jenkins, jeśli jeszcze tego nie zrobiono. Zobacz Instalowanie serwera Jenkins dla systemów Linux, macOS lub Windows.
Zainstaluj pakiet jq. W tym przykładzie użyto
jqmetody , aby przeanalizować niektóre dane wyjściowe polecenia w formacie JSON.Użyj
pippolecenia , aby zainstalować narzędzia kompilacji wheel języka Python za pomocą następującego polecenia (niektóre systemy mogą wymagać użyciapip3zamiastpippolecenia ):pip install --upgrade wheel
Krok 2. Tworzenie potoku serwera Jenkins
W tym kroku użyjesz narzędzia Jenkins do utworzenia potoku serwera Jenkins dla przykładu tego artykułu. Usługa Jenkins udostępnia kilka różnych typów projektów do tworzenia potoków ciągłej integracji/ciągłego wdrażania. Usługa Jenkins Pipelines udostępnia interfejs do definiowania etapów w potoku serwera Jenkins przy użyciu kodu Groovy w celu wywoływania i konfigurowania wtyczek serwera Jenkins.
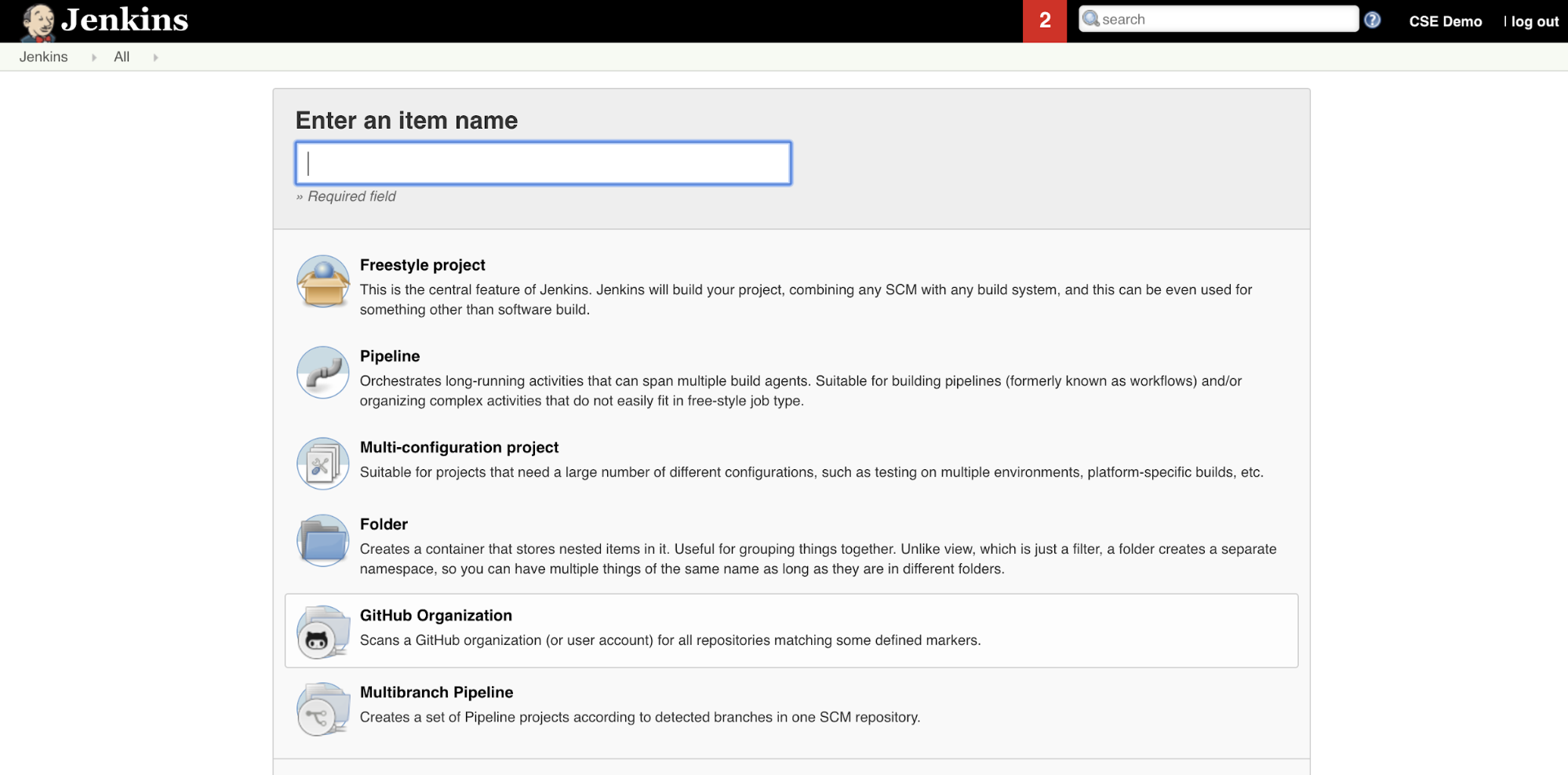
Aby utworzyć potok serwera Jenkins w usłudze Jenkins:
- Po uruchomieniu narzędzia Jenkins na pulpicie nawigacyjnym usługi Jenkins kliknij pozycję Nowy element.
- W polu Wprowadź nazwę elementu wpisz nazwę potoku serwera Jenkins, na przykład
jenkins-demo. - Kliknij ikonę Typ projektu potoku .
- Kliknij przycisk OK. Zostanie wyświetlona strona Konfigurowanie potoku narzędzia Jenkins.
- W obszarze Potok na liście rozwijanej Defintion (Defintion) wybierz pozycję Pipeline script from SCM (Skrypt potoku z programu SCM).
- Z listy rozwijanej SCM wybierz pozycję Git.
- W polu Adres URL repozytorium wpisz adres URL repozytorium hostowanego przez dostawcę usługi Git innej części.
- W polu Specyfikator gałęzi wpisz
*/<branch-name>, gdzie<branch-name>jest nazwą gałęzi w repozytorium, którego chcesz użyć, na przykład*/main. - W polu Ścieżka skryptu wpisz
Jenkinsfile, jeśli nie został jeszcze ustawiony. W dalszej części tego artykułu utworzyszJenkinsfile. - Usuń zaznaczenie pola o nazwie Uproszczone wyewidencjonowywanie, jeśli zostało już zaznaczone.
- Kliknij przycisk Zapisz.
Krok 3. Dodawanie globalnych zmiennych środowiskowych do usługi Jenkins
W tym kroku do serwera Jenkins zostaną dodane trzy globalne zmienne środowiskowe. Usługa Jenkins przekazuje te zmienne środowiskowe do interfejsu wiersza polecenia usługi Databricks. Interfejs wiersza polecenia usługi Databricks wymaga wartości tych zmiennych środowiskowych do uwierzytelniania w obszarze roboczym usługi Azure Databricks. W tym przykładzie użyto uwierzytelniania maszyny do maszyny OAuth (M2M) dla jednostki usługi (chociaż dostępne są również inne typy uwierzytelniania). Aby skonfigurować uwierzytelnianie OAuth M2M dla obszaru roboczego usługi Azure Databricks, zobacz Używanie jednostki usługi do uwierzytelniania w usłudze Azure Databricks.
Trzy globalne zmienne środowiskowe dla tego przykładu to:
DATABRICKS_HOST, ustaw adres URL obszaru roboczego usługi Azure Databricks, zaczynając odhttps://. Zobacz Nazwy, adresy URL i identyfikatory wystąpień obszaru roboczego.DATABRICKS_CLIENT_ID, ustaw na identyfikator klienta jednostki usługi, który jest również znany jako jego identyfikator aplikacji.DATABRICKS_CLIENT_SECRET, ustaw wartość na wpis tajny OAuth jednostki usługi Azure Databricks.
Aby ustawić globalne zmienne środowiskowe w usłudze Jenkins, na pulpicie nawigacyjnym usługi Jenkins:
- Na pasku bocznym kliknij pozycję Zarządzaj serwerem Jenkins.
- W sekcji Konfiguracja systemu kliknij pozycję System.
- W sekcji Właściwości globalne zaznacz pole z kafelkiem Zmienne środowiskowe.
- Kliknij przycisk Dodaj, a następnie wprowadź nazwę i wartość zmiennej środowiskowej. Powtórz to dla każdej dodatkowej zmiennej środowiskowej.
- Po zakończeniu dodawania zmiennych środowiskowych kliknij przycisk Zapisz, aby powrócić do pulpitu nawigacyjnego usługi Jenkins.
Projektowanie potoku narzędzia Jenkins
Usługa Jenkins udostępnia kilka różnych typów projektów do tworzenia potoków ciągłej integracji/ciągłego wdrażania. W tym przykładzie zaimplementowany jest potok serwera Jenkins. Usługa Jenkins Pipelines udostępnia interfejs do definiowania etapów w potoku serwera Jenkins przy użyciu kodu Groovy w celu wywoływania i konfigurowania wtyczek serwera Jenkins.
Definicję potoku narzędzia Jenkins można napisać w pliku tekstowym o nazwie Jenkinsfile, który z kolei jest sprawdzany w repozytorium kontroli źródła projektu. Aby uzyskać więcej informacji, zobacz Potok serwera Jenkins. Oto przykład potoku serwera Jenkins dla tego artykułu. W tym przykładzie Jenkinsfilezastąp następujące symbole zastępcze:
- Zastąp
<user-name>wartości i<repo-name>nazwą nazwy użytkownika i repozytorium hostowanej przez dostawcę usługi Git innej części. W tym artykule jako przykład jest używany adres URL usługi GitHub. - Zastąp
<release-branch-name>ciąg nazwą gałęzi wydania w repozytorium. Na przykład może to byćmain. - Zastąp
<databricks-cli-installation-path>ciąg ścieżką na lokalnej maszynie dewelopera, na której zainstalowano interfejs wiersza polecenia usługi Databricks. Na przykład w systemie macOS może to być/usr/local/bin. - Zastąp
<jq-installation-path>ciąg ścieżką na lokalnej maszynie dewelopera, na którejjqjest zainstalowana. Na przykład w systemie macOS może to być/usr/local/bin. - Zastąp
<job-prefix-name>ciąg ciągiem, aby ułatwić unikatowe zidentyfikowanie zadań usługi Azure Databricks utworzonych w obszarze roboczym w tym przykładzie. Na przykład może to byćjenkins-demo. - Zwróć uwagę, że
BUNDLETARGETustawiono wartośćdev, która jest nazwą docelowego pakietu zasobów usługi Databricks, który jest zdefiniowany w dalszej części tego artykułu. W rzeczywistych implementacjach można to zmienić na nazwę docelowego pakietu. Więcej szczegółów na temat elementów docelowych pakietu znajduje się w dalszej części tego artykułu.
Oto element Jenkinsfile, który należy dodać do katalogu głównego repozytorium:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
W pozostałej części tego artykułu opisano każdy etap w tym potoku serwera Jenkins oraz sposób konfigurowania artefaktów i poleceń serwera Jenkins do uruchamiania na tym etapie.
Ściąganie najnowszych artefaktów z repozytorium innej firmy
Pierwszy etap w tym potoku Checkout serwera Jenkins , etap, jest definiowany w następujący sposób:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Ten etap zapewnia, że katalog roboczy używany przez narzędzie Jenkins na lokalnej maszynie dewelopera zawiera najnowsze artefakty z repozytorium Git innej firmy. Zazwyczaj narzędzie Jenkins ustawia ten katalog roboczy na <your-user-home-directory>/.jenkins/workspace/<pipeline-name>wartość . Dzięki temu na tej samej lokalnej maszynie programistycznej możesz zachować własną kopię artefaktów w środowisku deweloperskim niezależnie od artefaktów używanych przez usługę Jenkins z repozytorium Git innej firmy.
Weryfikowanie pakietu zasobów usługi Databricks
Drugi etap w tym potoku serwera Jenkins , etap, jest definiowany Validate Bundle w następujący sposób:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Ten etap zapewnia, że pakiet zasobów usługi Databricks, który definiuje przepływy pracy na potrzeby testowania i uruchamiania artefaktów, jest poprawny składniowo. Pakiety zasobów usługi Databricks, znane po prostu jako pakiety, umożliwiają wyrażanie pełnych danych, analiz i projektów uczenia maszynowego jako kolekcji plików źródłowych. Zobacz Co to są pakiety zasobów usługi Databricks?.
Aby zdefiniować pakiet dla tego artykułu, utwórz plik o nazwie databricks.yml w katalogu głównym sklonowanego repozytorium na komputerze lokalnym. W tym przykładowym databricks.yml pliku zastąp następujące symbole zastępcze:
- Zastąp
<bundle-name>element unikatową nazwą programową pakietu. Na przykład może to byćjenkins-demo. - Zastąp
<job-prefix-name>ciąg ciągiem, aby ułatwić unikatowe zidentyfikowanie zadań usługi Azure Databricks utworzonych w obszarze roboczym w tym przykładzie. Na przykład może to byćjenkins-demo. Powinna być zgodna z wartościąJOBPREFIXw pliku Jenkinsfile. - Zastąp element
<spark-version-id>identyfikatorem wersji środowiska Databricks Runtime dla klastrów zadań, na przykład13.3.x-scala2.12. - Zastąp
<cluster-node-type-id>ciąg identyfikatorem typu węzła dla klastrów zadań, na przykładStandard_DS3_v2. - Zwróć uwagę, że
devw mapowaniu jest to samo coBUNDLETARGETwtargetspliku Jenkinsfile. Element docelowy pakietu określa hosta i powiązane zachowania wdrażania.
databricks.yml Oto plik, który należy dodać do katalogu głównego repozytorium, aby ten przykład działał poprawnie:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Aby uzyskać więcej informacji na temat databricks.yml pliku, zobacz Konfiguracje pakietu zasobów usługi Databricks.
Wdrażanie pakietu w obszarze roboczym
Trzeci etap potoku narzędzia Jenkins o nazwie , jest definiowany Deploy Bundlew następujący sposób:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Ten etap obejmuje dwie rzeczy:
artifactPonieważ mapowanie wdatabricks.ymlpliku jest ustawione nawhlwartość , powoduje to, że interfejs wiersza polecenia usługi Databricks skompiluje plik wheel języka Python przy użyciusetup.pypliku w określonej lokalizacji.- Po zbudowaniu pliku wheel języka Python na lokalnej maszynie deweloperów interfejs wiersza polecenia usługi Databricks wdraża skompilowany plik wheel języka Python wraz z określonymi plikami i notesami języka Python w obszarze roboczym usługi Azure Databricks. Domyślnie pakiety zasobów usługi Databricks wdrażają plik wheel języka Python i inne pliki w usłudze
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Aby umożliwić skompilowanie pliku wheel języka Python zgodnie z opisem databricks.yml w pliku, utwórz następujące foldery i pliki w katalogu głównym sklonowanego repozytorium na komputerze lokalnym.
Aby zdefiniować logikę i testy jednostkowe dla pliku wheel języka Python, względem którego zostanie uruchomiony notes, utwórz dwa pliki o nazwie i test_addcol.py, a następnie dodaj je do struktury folderów o nazwie addcol.py w python/dabdemo/dabdemo folderze repozytoriumLibraries, zwizualizowane w następujący sposób (wielokropek wskazuje pominięte foldery w repozytorium, aby uzyskać zwięzłość):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Plik addcol.py zawiera funkcję biblioteki wbudowaną później w plik wheel języka Python, a następnie zainstalowaną w klastrze usługi Azure Databricks. Jest to prosta funkcja, która dodaje nową kolumnę wypełniną literałem do ramki danych platformy Apache Spark:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Plik test_addcol.py zawiera testy, aby przekazać pozorny obiekt ramki danych do with_status funkcji zdefiniowanej w addcol.pypliku . Wynik jest następnie porównywany z obiektem DataFrame zawierającym oczekiwane wartości. Jeśli wartości są zgodne, co w takim przypadku wykonuje, test zakończy się pomyślnie:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Aby umożliwić interfejsowi wiersza polecenia usługi Databricks poprawne spakowanie tego kodu biblioteki do pliku koła języka Python, utwórz dwa pliki o nazwie __init__.py i __main__.py w tym samym folderze co poprzednie dwa pliki. Ponadto utwórz plik o nazwie setup.py w folderze zwizualizowany python/dabdemo w następujący sposób (wielokropek wskazuje pominięte foldery w celu zwięzłości):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Plik __init__.py zawiera numer wersji biblioteki i jego autora. Zastąp <my-author-name> ciąg nazwą:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Plik __main__.py zawiera punkt wejścia biblioteki:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Plik setup.py zawiera dodatkowe ustawienia tworzenia biblioteki w pliku wheel języka Python. Zastąp <my-url>wartości , <my-author-name>@<my-organization>i <my-package-description> znaczącymi wartościami:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Testowanie logiki składników koła języka Python
Etap Run Unit Tests , czwarty etap tego potoku serwera Jenkins, służy pytest do testowania logiki biblioteki, aby upewnić się, że działa ona zgodnie z kompilacją. Ten etap jest definiowany w następujący sposób:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Ten etap używa interfejsu wiersza polecenia usługi Databricks do uruchamiania zadania notesu. To zadanie uruchamia notes języka Python z nazwą pliku run-unit-test.py. Ten notes jest uruchamiany pytest względem logiki biblioteki.
Aby uruchomić testy jednostkowe dla tego przykładu, dodaj plik notesu języka Python o nazwie z run_unit_tests.py następującą zawartością do katalogu głównego sklonowanego repozytorium na komputerze lokalnym:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Korzystanie z wbudowanego koła języka Python
Piąty etap tego potoku narzędzia Jenkins o nazwie Run Notebook, uruchamia notes języka Python, który wywołuje logikę w skompilowanym pliku wheel języka Python w następujący sposób:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Ten etap uruchamia interfejs wiersza polecenia usługi Databricks, który z kolei instruuje obszar roboczy, aby uruchamiał zadanie notesu. Ten notes tworzy obiekt ramki danych, przekazuje go do funkcji biblioteki with_status , wyświetla wynik i zgłasza wyniki uruchomienia zadania. Utwórz notes, dodając plik notesu języka Python o nazwie z dabdaddemo_notebook.py następującą zawartością w katalogu głównym sklonowanego repozytorium na lokalnym komputerze deweloperskim:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Ocena wyników uruchomienia zadania notesu
Etap Evaluate Notebook Runs , szósty etap tego potoku serwera Jenkins, ocenia wyniki poprzedniego uruchomienia zadania notesu. Ten etap jest definiowany w następujący sposób:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Ten etap uruchamia interfejs wiersza polecenia usługi Databricks, który z kolei instruuje obszar roboczy, aby uruchamiał zadanie pliku języka Python. Ten plik w języku Python określa kryteria niepowodzenia i powodzenia uruchomienia zadania notesu i zgłasza ten błąd lub wynik powodzenia. Utwórz plik o nazwie o następującej evaluate_notebook_runs.py zawartości w katalogu głównym sklonowanego repozytorium na lokalnym komputerze deweloperskim:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importowanie i raportowanie wyników testów
Siódmy etap w tym potoku narzędzia Jenkins zatytułowanym Import Test Resultsużywa interfejsu wiersza polecenia usługi Databricks do wysyłania wyników testów z obszaru roboczego do lokalnej maszyny deweloperów. Ósmy i ostatni etap, zatytułowany Publish Test Results, publikuje wyniki testów dla serwera Jenkins przy użyciu junit wtyczki Jenkins. Dzięki temu można wizualizować raporty i pulpity nawigacyjne związane ze stanem wyników testu. Te etapy są definiowane w następujący sposób:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Wypychanie wszystkich zmian kodu do repozytorium innej firmy
Teraz należy wypchnąć zawartość sklonowanego repozytorium na lokalnym komputerze deweloperskim do repozytorium innej firmy. Przed wypchnięciem należy najpierw dodać następujące wpisy do .gitignore pliku w sklonowanym repozytorium, ponieważ prawdopodobnie nie należy wypychać wewnętrznych plików roboczych pakietu zasobów usługi Databricks, raportów weryfikacji, plików kompilacji języka Python i pamięci podręcznych języka Python do repozytorium innej firmy. Zazwyczaj należy ponownie wygenerować nowe raporty weryfikacji i najnowsze kompilacje koła języka Python w obszarze roboczym usługi Azure Databricks, zamiast używać potencjalnie nieaktualnych raportów weryfikacji i kompilacji koła języka Python:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Uruchamianie potoku narzędzia Jenkins
Teraz możesz przystąpić do ręcznego uruchamiania potoku serwera Jenkins. W tym celu z poziomu pulpitu nawigacyjnego narzędzia Jenkins:
- Kliknij nazwę potoku serwera Jenkins.
- Na pasku bocznym kliknij pozycję Skompiluj teraz.
- Aby wyświetlić wyniki, kliknij najnowsze uruchomienie potoku (na przykład
#1), a następnie kliknij pozycję Dane wyjściowe konsoli.
W tym momencie potok ciągłej integracji/ciągłego wdrażania zakończył cykl integracji i wdrażania. Automatyzując ten proces, możesz upewnić się, że kod został przetestowany i wdrożony przez wydajny, spójny i powtarzalny proces. Aby poinstruować dostawcę git innej firmy, aby uruchamiał narzędzie Jenkins za każdym razem, gdy wystąpi określone zdarzenie, takie jak żądanie ściągnięcia repozytorium, zapoznaj się z dokumentacją dostawcy git innej firmy.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla