Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga
Usługa Databricks Connect zaleca użycie programu Databricks Connect dla środowiska Databricks Runtime w wersji 13.0 lub nowszej .
Usługa Databricks nie planuje żadnych nowych funkcji dla usługi Databricks Connect dla środowiska Databricks Runtime 12.2 LTS i poniżej.
Usługa Databricks Connect umożliwia łączenie popularnych środowisk IDE, takich jak Visual Studio Code i PyCharm, serwery notesów i inne aplikacje niestandardowe z klastrami usługi Azure Databricks.
W tym artykule wyjaśniono, jak działa program Databricks Connect, przedstawiono procedurę rozpoczynania pracy z usługą Databricks Connect, wyjaśniono, jak rozwiązywać problemy występujące podczas korzystania z usługi Databricks Connect oraz różnice między uruchamianiem przy użyciu programu Databricks Connect a uruchamianiem w notesie usługi Azure Databricks.
Omówienie
Databricks Connect to biblioteka klienta środowiska Databricks Runtime. Umożliwia ona pisanie zadań przy użyciu interfejsów API platformy Spark i uruchamianie ich zdalnie w klastrze usługi Azure Databricks zamiast w lokalnej sesji platformy Spark.
Na przykład po uruchomieniu polecenia spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame przy użyciu narzędzia Databricks Connect logiczna reprezentacja polecenia jest wysyłana do serwera Spark uruchomionego w usłudze Azure Databricks w celu wykonania w klastrze zdalnym.
Za pomocą usługi Databricks Connect można wykonywać następujące czynności:
- Uruchamianie zadań platformy Spark na dużą skalę z dowolnej aplikacji python, R, Scala lub Java. W dowolnym miejscu, w którym można uruchamiać
import pysparkrequire(SparkR)import org.apache.sparkzadania platformy Spark bezpośrednio z poziomu aplikacji, bez konieczności instalowania wtyczek IDE ani używania skryptów przesyłania platformy Spark. - Wykonaj kroki i debuguj kod w środowisku IDE nawet podczas pracy z klastrem zdalnym.
- Szybkie iterowanie podczas tworzenia bibliotek. Nie trzeba ponownie uruchamiać klastra po zmianie zależności bibliotek języka Python lub Java w programie Databricks Connect, ponieważ każda sesja klienta jest odizolowana od siebie w klastrze.
- Zamknij bezczynne klastry bez utraty pracy. Ponieważ aplikacja kliencka jest oddzielona od klastra, nie ma to wpływu na ponowne uruchomienia klastra lub uaktualnienia, co zwykle spowodowałoby utratę wszystkich zmiennych, RDD i obiektów ramki danych zdefiniowanych w notesie.
Uwaga
W przypadku programowania w języku Python za pomocą zapytań SQL usługa Databricks zaleca użycie łącznika SQL usługi Databricks dla języka Python zamiast usługi Databricks Connect. Łącznik SQL usługi Databricks dla języka Python jest łatwiejszy do skonfigurowania niż usługa Databricks Connect. Ponadto usługa Databricks Connect analizuje i planuje zadania są uruchamiane na komputerze lokalnym, podczas gdy zadania są uruchamiane na zdalnych zasobach obliczeniowych. Może to utrudnić szczególnie debugowanie błędów środowiska uruchomieniowego. Łącznik SQL usługi Databricks dla języka Python przesyła zapytania SQL bezpośrednio do zdalnych zasobów obliczeniowych i pobiera wyniki.
Wymagania
W tej sekcji wymieniono wymagania dotyczące usługi Databricks Connect.
Obsługiwane są tylko następujące wersje środowiska Databricks Runtime:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
Musisz zainstalować język Python 3 na komputerze deweloperskim, a wersja pomocnicza instalacji klienta języka Python musi być taka sama jak wersja pomocniczego języka Python klastra usługi Azure Databricks. W poniższej tabeli przedstawiono wersję języka Python zainstalowaną z każdym środowiskiem Databricks Runtime.
Wersja środowiska Databricks Runtime Wersja języka Python 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3,8 9.1 LTS ML, 9.1 LTS 3,8 7.3 LTS 3.7 Usługa Databricks zdecydowanie zaleca aktywowanie środowiska wirtualnego języka Python dla każdej wersji języka Python używanej z usługą Databricks Connect. Środowiska wirtualne języka Python pomagają upewnić się, że używasz poprawnych wersji języka Python i usługi Databricks Connect razem. Może to pomóc skrócić czas spędzony na rozwiązywaniu powiązanych problemów technicznych.
Jeśli na przykład używasz venv na swojej maszynie deweloperskiej, a twój klaster działa na Pythonie 3.9, musisz utworzyć
venvśrodowisko z tą wersją. Następujące przykładowe polecenie generuje skrypty, aby aktywowaćvenvśrodowisko przy użyciu języka Python 3.9, a następnie umieszcza te skrypty w ukrytym folderze o nazwie.venvw bieżącym katalogu roboczym:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvAby użyć tych skryptów do aktywowania tego
venvśrodowiska, zobacz Jak działają venvs.W innym przykładzie, jeśli używasz środowiska Conda na maszynie deweloperów, a klaster korzysta z języka Python 3.9, musisz utworzyć środowisko Conda w tej wersji, na przykład:
conda create --name dbconnect python=3.9Aby aktywować środowisko Conda o tej nazwie środowiska, uruchom polecenie
conda activate dbconnect.Wersja główna i wersja podrzędna pakietu usługi Databricks Connect musi zawsze odpowiadać wersji środowiska Databricks Runtime. Usługa Databricks zaleca, aby zawsze używać najnowszego pakietu usługi Databricks Connect zgodnego z wersją środowiska Databricks Runtime. Na przykład w przypadku korzystania z klastra Databricks Runtime 12.2 LTS należy również użyć
databricks-connect==12.2.*pakietu.Uwaga
Zapoznaj się z informacjami o wersji programu Databricks Connect, aby uzyskać listę dostępnych wersji programu Databricks Connect i aktualizacji konserwacji.
Środowisko uruchomieniowe Java (JRE) 8. Klient został przetestowany przy użyciu środowiska JRE OpenJDK 8. Klient nie obsługuje środowiska Java 11.
Uwaga
Jeśli w systemie Windows pojawi się błąd informujący, że Databricks Connect nie może odnaleźć winutils.exe, zobacz Nie można odnaleźć winutils.exe w systemie Windows.
Konfigurowanie klienta
Wykonaj poniższe kroki, aby skonfigurować klienta lokalnego dla usługi Databricks Connect.
Uwaga
Przed rozpoczęciem konfigurowania lokalnego klienta usługi Databricks Connect należy spełnić wymagania programu Databricks Connect.
Krok 1. Instalowanie klienta programu Databricks Connect
Po aktywowaniu środowiska wirtualnego odinstaluj narzędzie PySpark, jeśli jest już zainstalowane, uruchamiając
uninstallpolecenie . Jest to wymagane, ponieważdatabricks-connectpakiet powoduje konflikt z narzędziem PySpark. Aby uzyskać szczegółowe informacje, zobacz Konflikt instalacji PySpark. Aby sprawdzić, czy program PySpark jest już zainstalowany, uruchomshowpolecenie .# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkPo aktywowaniu środowiska wirtualnego zainstaluj klienta programu Databricks Connect, uruchamiając
installpolecenie .--upgradeUżyj opcji , aby uaktualnić dowolną istniejącą instalację klienta do określonej wersji.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Uwaga
Usługa Databricks zaleca dołączenie notacji "kropka-gwiazdka", aby określić
databricks-connect==X.Y.*zamiastdatabricks-connect=X.Y, aby upewnić się, że zainstalowano najnowszy pakiet.
Krok 2. Konfigurowanie właściwości połączenia
Zbierz następujące właściwości konfiguracji.
Adres URL usługi Azure Databricks dla obszaru roboczego. Jest to również takie samo, jak
https://po wartości Nazwa hosta serwera dla klastra. Zobacz Pobieranie szczegółów połączenia dla zasobu obliczeniowego usługi Azure Databricks.Osobisty token dostępu usługi Azure Databricks lub token microsoft Entra ID (dawniej Azure Active Directory).
- W przypadku przekazywania poświadczeń usługi Azure Data Lake Storage (ADLS) należy użyć tokenu identyfikatora entra firmy Microsoft. Przekazywanie poświadczeń identyfikatora entra firmy Microsoft jest obsługiwane tylko w klastrach w warstwie Standardowa z uruchomionym środowiskiem Databricks Runtime 7.3 LTS lub nowszym i nie jest zgodny z uwierzytelnianiem jednostki usługi.
- Aby uzyskać więcej informacji na temat uwierzytelniania za pomocą tokenów identyfikatora Entra firmy Microsoft, zobacz Uwierzytelnianie przy użyciu tokenów identyfikatora Entra firmy Microsoft.
Identyfikator klastra. Identyfikator klastra można uzyskać z adresu URL. W tym miejscu identyfikator klastra to
1108-201635-xxxxxxxx. Zobacz również Adres URL i identyfikator klastra.
Unikatowy identyfikator organizacji dla obszaru roboczego. Zobacz Pobieranie identyfikatorów dla obiektów obszaru roboczego.
Port, z który łączy się usługa Databricks Connect w klastrze. Domyślnym portem jest
15001. Jeśli klaster jest skonfigurowany do używania innego portu, takiego jak8787podany w poprzednich instrukcjach dotyczących usługi Azure Databricks, użyj skonfigurowanego numeru portu.
Skonfiguruj połączenie w następujący sposób.
Możesz użyć interfejsu wiersza polecenia, konfiguracji SQL lub zmiennych środowiskowych. Pierwszeństwo metod konfiguracji od najwyższego do najniższego to: klucze konfiguracji SQL, interfejs wiersza polecenia i zmienne środowiskowe.
Interfejs Linii Komend (CLI)
Uruchom program
databricks-connect.databricks-connect configureZostanie wyświetlona licencja:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Zaakceptuj licencję i podaj wartości konfiguracji. W przypadku hosta usługi Databricks i tokenu usługi Databricks wprowadź adres URL obszaru roboczego i osobisty token dostępu zanotowany w kroku 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Jeśli zostanie wyświetlony komunikat informujący, że token identyfikatora entra firmy Microsoft jest za długi, możesz pozostawić pole Token usługi Databricks puste i ręcznie wprowadzić token w
~/.databricks-connectpliku .
Konfiguracje SQL lub zmienne środowiskowe. W poniższej tabeli przedstawiono klucze konfiguracji SQL i zmienne środowiskowe, które odpowiadają właściwościom konfiguracji zanotowany w kroku 1. Aby ustawić klucz konfiguracji SQL, użyj polecenia
sql("set config=value"). Na przykład:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Parametr Klucz konfiguracji SQL Nazwa zmiennej środowiskowej Databricks Host spark.databricks.service.address DATABRICKS_ADDRESS Databricks Token spark.databricks.service.token DATABRICKS_API_TOKEN Identyfikator klastra spark.databricks.service.clusterId Identyfikator klastra DATABRICKS Identyfikator organizacji spark.databricks.service.orgId DATABRICKS_ORG_ID Port spark.databricks.service.port DATABRICKS_PORT
Po aktywowaniu środowiska wirtualnego przetestuj łączność z usługą Azure Databricks w następujący sposób.
databricks-connect testJeśli skonfigurowany klaster nie jest uruchomiony, test uruchomi klaster, który pozostanie uruchomiony do czasu skonfigurowania autoterminacji. Dane wyjściowe powinny wyglądać mniej więcej tak:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiJeśli nie są wyświetlane żadne błędy związane z połączeniem (
WARNkomunikaty są w porządku), połączenie zostało pomyślnie nawiązane.
Korzystanie z usługi Databricks Connect
W sekcji opisano sposób konfigurowania preferowanego serwera IDE lub serwera notesu w celu korzystania z klienta dla usługi Databricks Connect.
W tej sekcji:
- JupyterLab
- Klasyczny notes Jupyter Notebook
- PyCharm
- SparkR i RStudio Desktop
- sparklyr i RStudio Desktop
- IntelliJ (Scala lub Java)
- PyDev z programem Eclipse
- Zaćmienie
- SBT
- Powłoka platformy Spark
JupyterLab
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby używać usługi Databricks Connect z oprogramowaniem JupyterLab i językiem Python, postępuj zgodnie z tymi instrukcjami.
Aby zainstalować narzędzie JupyterLab z aktywowanym środowiskiem wirtualnym języka Python, uruchom następujące polecenie w terminalu lub wierszu polecenia:
pip3 install jupyterlabAby uruchomić aplikację JupyterLab w przeglądarce internetowej, uruchom następujące polecenie w aktywowanym środowisku wirtualnym języka Python:
jupyter labJeśli aplikacja JupyterLab nie jest wyświetlana w przeglądarce internetowej, skopiuj adres URL rozpoczynający się od
localhostlub127.0.0.1ze środowiska wirtualnego i wprowadź go na pasku adresu przeglądarki internetowej.Utwórz nowy notes: w programie JupyterLab kliknij pozycję Plik > nowy > notes w menu głównym, wybierz pozycję Python 3 (ipykernel), a następnie kliknij pozycję Wybierz.
W pierwszej komórce notesu wprowadź przykładowy kod lub własny kod. Jeśli używasz własnego kodu, co najmniej musisz utworzyć wystąpienie wystąpienia
SparkSession.builder.getOrCreate()klasy , jak pokazano w przykładowym kodzie.Aby uruchomić notes, kliknij pozycję Uruchom > wszystkie komórki.
Aby debugować notatnik, kliknij ikonę błędu (Włącz debuger) obok Python 3 (ipykernel) na pasku narzędzi notatnika. Ustaw co najmniej jeden punkt przerwania, a następnie kliknij przycisk Uruchom > wszystkie komórki.
Aby zamknąć aplikację JupyterLab, kliknij pozycję > plik. Jeśli proces JupyterLab nadal działa w terminalu lub wierszu polecenia, zatrzymaj ten proces, naciskając
Ctrl + c, a następnie wprowadzając poleceniey, aby potwierdzić.
Aby uzyskać bardziej szczegółowe instrukcje debugowania, zobacz Debuger.
Klasyczny notes Jupyter Notebook
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Skrypt konfiguracji programu Databricks Connect automatycznie dodaje pakiet do konfiguracji projektu. Aby rozpocząć pracę w jądrze języka Python, uruchom polecenie:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Aby włączyć skrót uruchamiania %sql i wizualizowania zapytań SQL, użyj następującego fragmentu kodu:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby użyć programu Databricks Connect z programem Visual Studio Code, wykonaj następujące czynności:
Sprawdź, czy rozszerzenie języka Python jest zainstalowane.
Otwórz paletę poleceń (Command+Shift+P w systemie macOS i Ctrl+Shift+P w systemie Windows/Linux).
Wybierz interpreter języka Python. Przejdź do > preferencji > kodu i wybierz pozycję Ustawienia języka Python.
Uruchom program
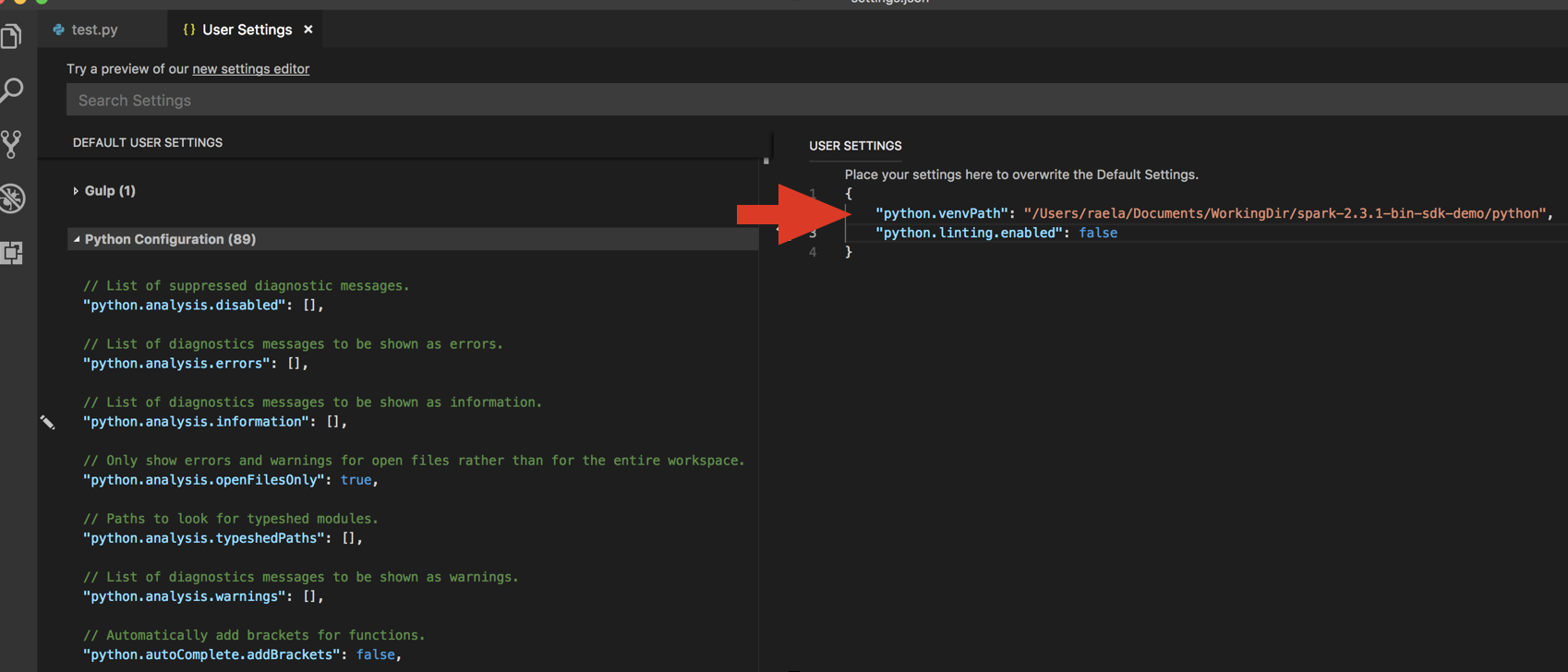
databricks-connect get-jar-dir.Dodaj katalog zwrócony z polecenia do pliku JSON ustawień użytkownika w obszarze
python.venvPath. Należy go dodać do konfiguracji języka Python.Wyłącz linter. Kliknij ikonę ... po prawej stronie i edytuj ustawienia json. Zmodyfikowane ustawienia są następujące:
Jeśli korzystasz ze środowiska wirtualnego, co jest zalecanym sposobem tworzenia dla języka Python w programie VS Code, w typie
select python interpreterpalety poleceń i wskaż środowisko zgodnez wersją języka Python klastra.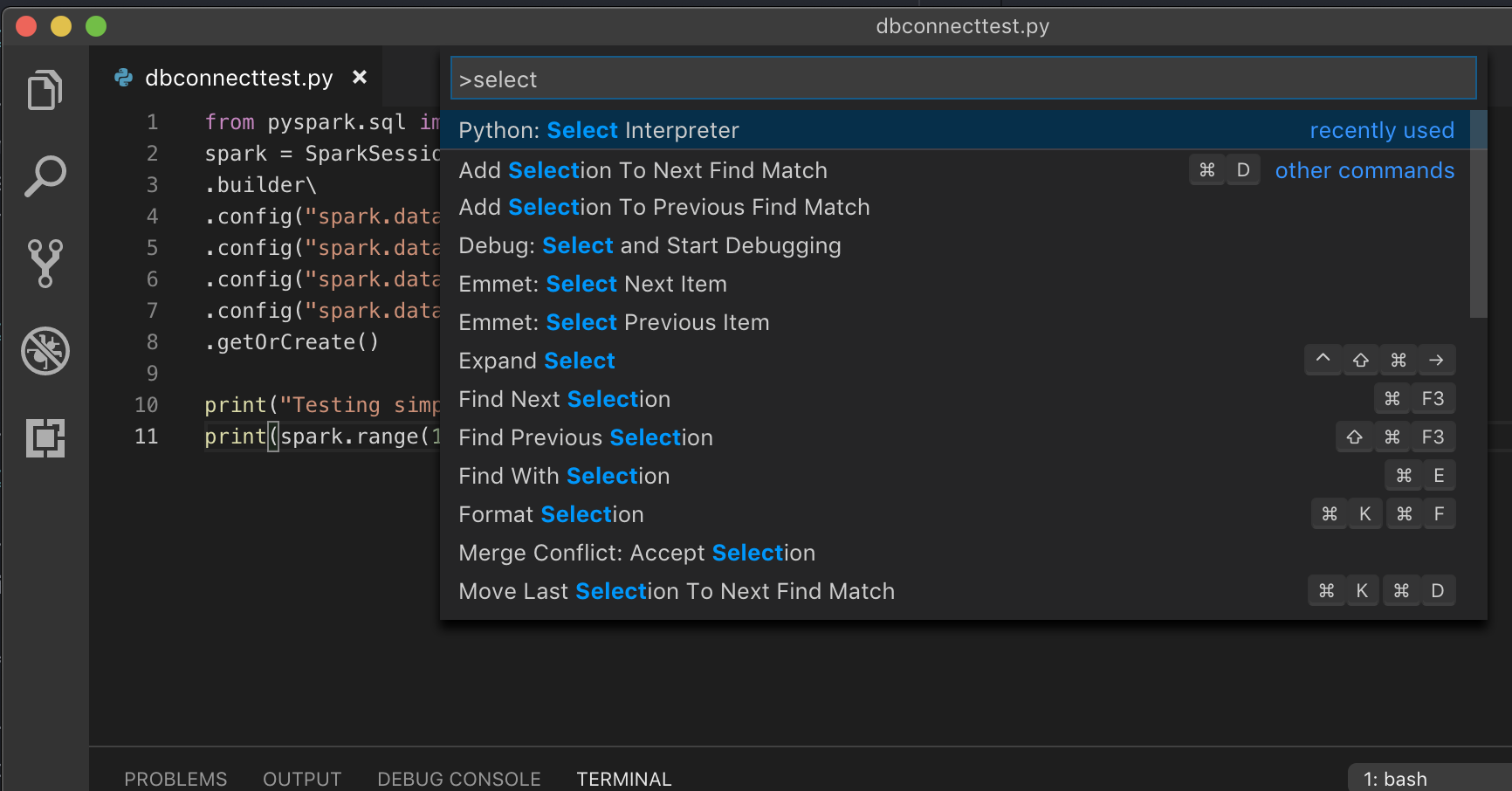
Jeśli na przykład klaster to Python 3.9, środowisko programistyczne powinno mieć wartość Python 3.9.
PyCharm
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Skrypt konfiguracji programu Databricks Connect automatycznie dodaje pakiet do konfiguracji projektu.
Klastry języka Python 3
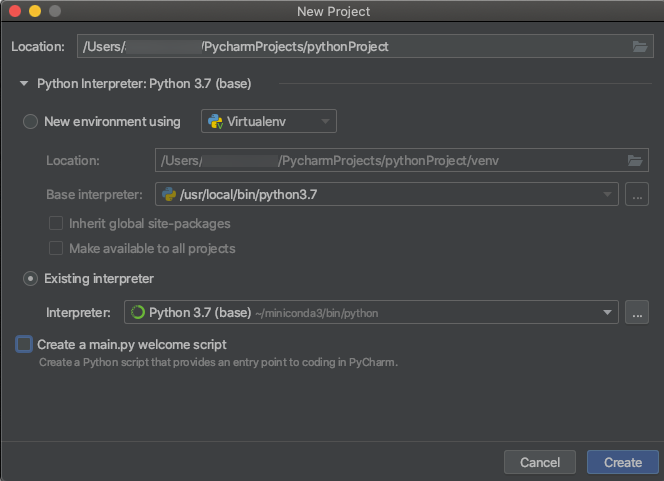
Podczas tworzenia projektu PyCharm wybierz pozycję Istniejący interpreter. Z menu rozwijanego wybierz utworzone środowisko Conda (zobacz Wymagania).
Przejdź do pozycji Uruchom > konfiguracje edycji.
Dodaj
PYSPARK_PYTHON=python3jako zmienną środowiskową.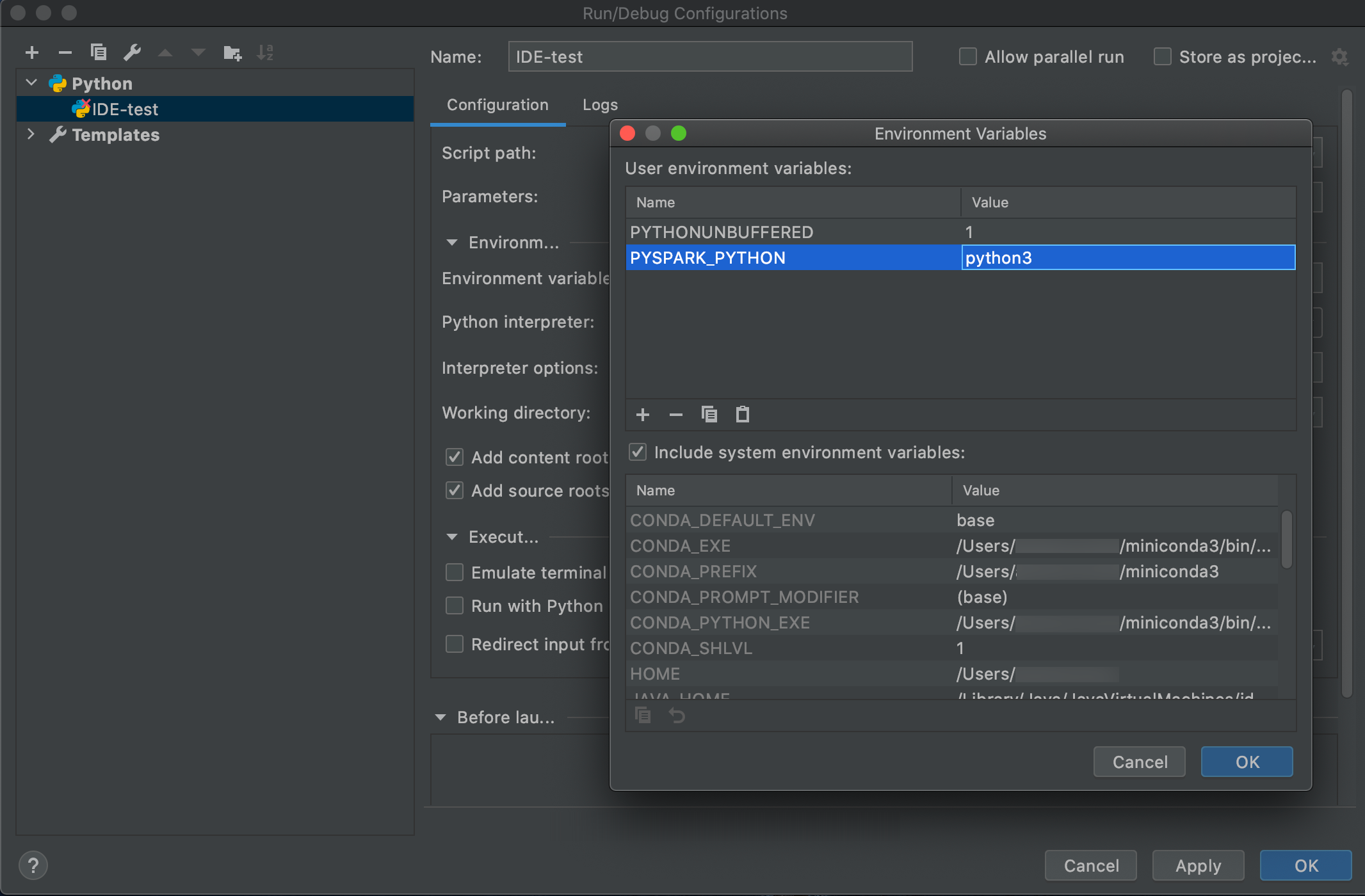
SparkR i RStudio Desktop
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby użyć usługi Databricks Connect z usługami SparkR i RStudio Desktop, wykonaj następujące czynności:
Pobierz i rozpakuj dystrybucję platformy Spark typu open source na maszynie dewelopera. Wybierz tę samą wersję co w klastrze usługi Azure Databricks (Hadoop 2.7).
Uruchom program
databricks-connect get-jar-dir. To polecenie zwraca ścieżkę, taką jak/usr/local/lib/python3.5/dist-packages/pyspark/jars. Skopiuj ścieżkę pliku jednego katalogu powyżej ścieżki pliku katalogu JAR, na przykład/usr/local/lib/python3.5/dist-packages/pyspark, czyliSPARK_HOMEkatalogu.Skonfiguruj ścieżkę lib platformy Spark i główną platformę Spark, dodając je do góry skryptu języka R. Ustaw
<spark-lib-path>katalog, w którym rozpakujesz pakiet Spark typu open source w kroku 1. Ustaw<spark-home-path>katalog Databricks Connect z kroku 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Zainicjuj sesję platformy Spark i uruchom polecenia sparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr i RStudio Desktop
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Kod zależny od interfejsu sparklyr można skopiować lokalnie przy użyciu programu Databricks Connect i uruchomić go w notesie usługi Azure Databricks lub hostowanym serwerze RStudio Server w obszarze roboczym usługi Azure Databricks z minimalnymi zmianami lub bez zmian w kodzie.
W tej sekcji:
- Wymagania
- Instalowanie, konfigurowanie i używanie narzędzia sparklyr
- Zasoby
- Ograniczenia aplikacji sparklyr i RStudio Desktop
Wymagania
- sparklyr 1.2 lub nowszy.
- Databricks Runtime 7.3 LTS lub nowsza z zgodną wersją usługi Databricks Connect.
Instalowanie, konfigurowanie i używanie narzędzia sparklyr
W programie RStudio Desktop zainstaluj aplikację sparklyr 1.2 lub nowszą z poziomu sieci CRAN lub zainstaluj najnowszą wersję master z usługi GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Aktywuj środowisko języka Python z zainstalowaną poprawną wersją programu Databricks Connect i uruchom następujące polecenie w terminalu, aby pobrać polecenie
<spark-home-path>:databricks-connect get-spark-homeZainicjuj sesję platformy Spark i rozpocznij uruchamianie poleceń sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countZamknij połączenie.
spark_disconnect(sc)
Zasoby
Aby uzyskać więcej informacji, zobacz sparklyr GitHub README.
Aby zapoznać się z przykładami kodu, zobacz sparklyr.
Ograniczenia aplikacji sparklyr i RStudio Desktop
Nieobsługiwane są następujące funkcje:
- Interfejsy API przesyłania strumieniowego sparklyr
- Interfejsy API uczenia maszynowego sparklyr
- interfejsy API miotły
- tryb serializacji csv_file
- przesyłanie platformy Spark
IntelliJ (Scala lub Java)
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby użyć usługi Databricks Connect z funkcją IntelliJ (Scala lub Java), wykonaj następujące czynności:
Uruchom program
databricks-connect get-jar-dir.Wskaż zależności do katalogu zwróconego z polecenia . Przejdź do obszaru Zależności modułów >> struktury > projektu plików > "+" podpisz pliki > JAR lub katalogi.
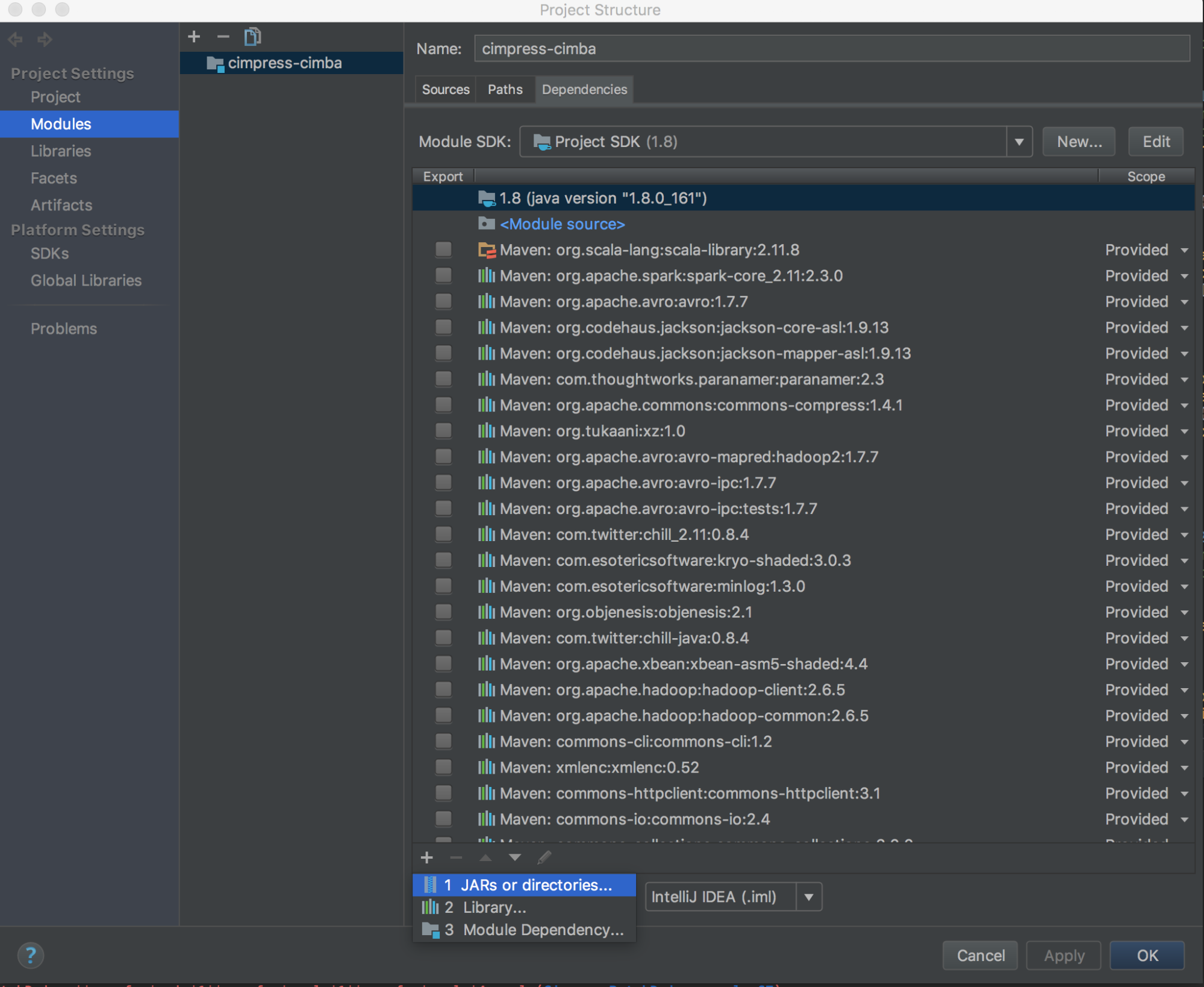
Aby uniknąć konfliktów, zdecydowanie zalecamy usunięcie wszelkich innych instalacji platformy Spark ze ścieżki klasy. Jeśli nie jest to możliwe, upewnij się, że dodane elementy JAR znajdują się na początku ścieżki klasy. W szczególności muszą one być przed dowolną inną zainstalowaną wersją platformy Spark (w przeciwnym razie użyjesz jednej z tych innych wersji platformy Spark i uruchomisz ją lokalnie lub zgłosisz wartość
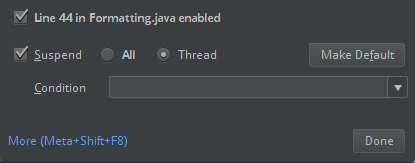
ClassDefNotFoundError).Sprawdź ustawienie opcji breakout w środowisku IntelliJ. Wartość domyślna to Wszystkie i spowoduje przekroczenie limitu czasu sieci w przypadku ustawienia punktów przerwania na potrzeby debugowania. Ustaw ją na wątek , aby uniknąć zatrzymywania wątków sieciowych w tle.
PyDev z programem Eclipse
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby użyć narzędzi Databricks Connect i PyDev z programem Eclipse, postępuj zgodnie z tymi instrukcjami.
- Uruchom środowisko Eclipse.
- Utwórz projekt: kliknij pozycję Plik > nowy > projekt > PyDev PyDev > PyDev Project, a następnie kliknij przycisk Dalej.
- Określ nazwę projektu.
- W polu Zawartość projektu określ ścieżkę do środowiska wirtualnego języka Python.
- Kliknij przycisk Skonfiguruj interpreter przed kontynuowaniem.
- Kliknij pozycję Konfiguracja ręczna.
- Kliknij pozycję Nowe > przeglądaj dla pliku exe python/pypy.
- Przejdź do i wybierz pełną ścieżkę do interpretera języka Python, do którego odwołuje się środowisko wirtualne, a następnie kliknij przycisk Otwórz.
- W oknie dialogowym Wybieranie interpretera kliknij przycisk OK.
- W oknie dialogowym Wybór potrzebny kliknij przycisk OK.
- W oknie dialogowym Preferencje kliknij przycisk Zastosuj i zamknij.
- W oknie dialogowym Projekt PyDev kliknij przycisk Zakończ.
- Kliknij pozycję Otwórz perspektywę.
- Dodaj do projektu plik kodu języka Python (
.py), który zawiera przykładowy kod lub własny kod. Jeśli używasz własnego kodu, co najmniej musisz utworzyć wystąpienie wystąpieniaSparkSession.builder.getOrCreate()klasy , jak pokazano w przykładowym kodzie. - Po otwarciu pliku kodu języka Python ustaw wszystkie punkty przerwania, w których kod ma zostać wstrzymany podczas działania.
- Kliknij pozycję Uruchom uruchom > lub Uruchom > debugowanie.
Aby uzyskać bardziej szczegółowe instrukcje dotyczące uruchamiania i debugowania, zobacz Running a Program (Uruchamianie programu).
Zaćmienie
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby użyć programu Databricks Connect i środowiska Eclipse, wykonaj następujące czynności:
Uruchom program
databricks-connect get-jar-dir.Wskaż zewnętrzną konfigurację jardów do katalogu zwróconego z polecenia . Przejdź do menu > Projekt Właściwości > Biblioteki > ścieżek > kompilacji Java Dodaj zewnętrzne pliki JAR.
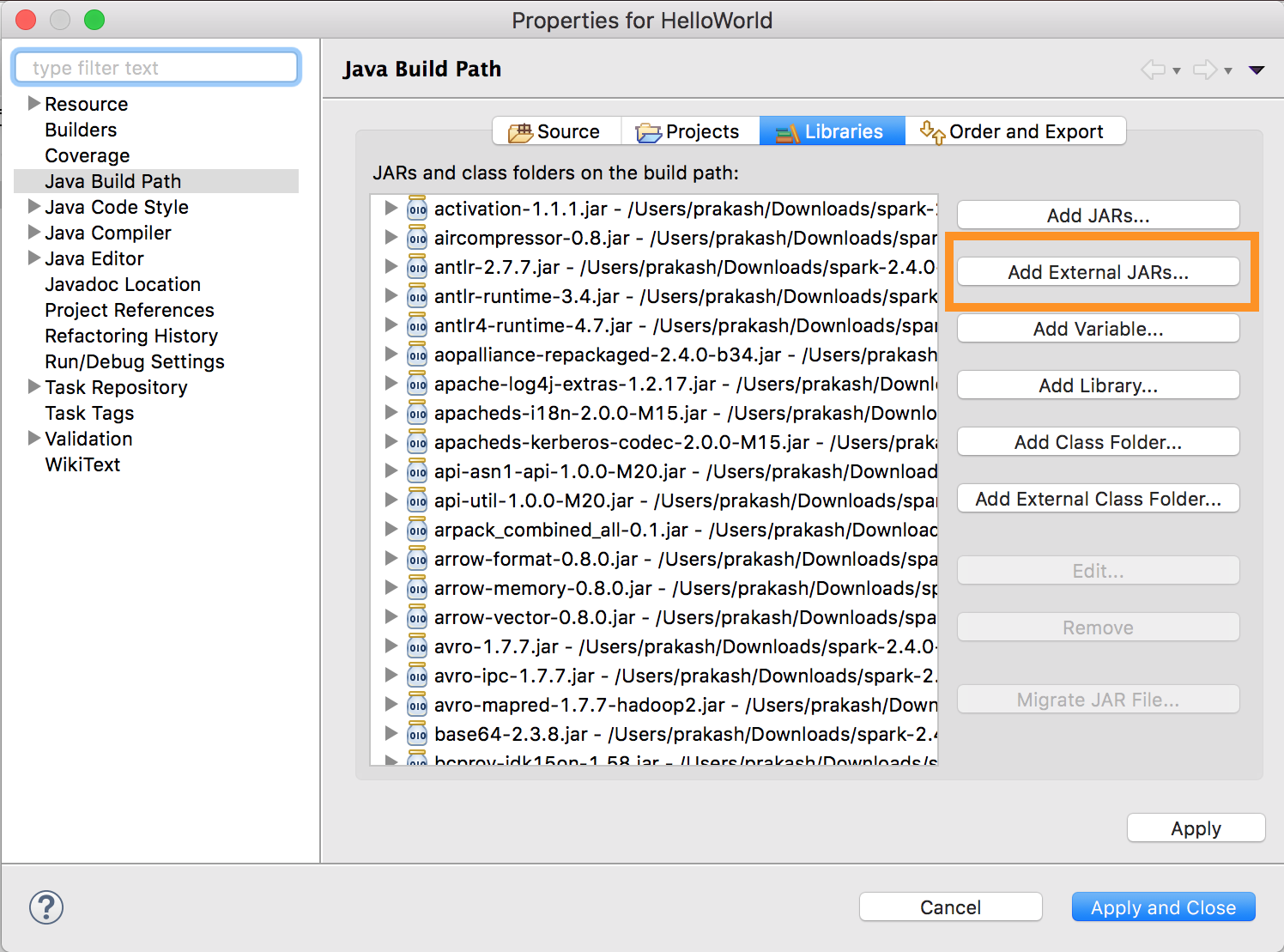
Aby uniknąć konfliktów, zdecydowanie zalecamy usunięcie wszelkich innych instalacji platformy Spark ze ścieżki klasy. Jeśli nie jest to możliwe, upewnij się, że dodane elementy JAR znajdują się na początku ścieżki klasy. W szczególności muszą one być przed dowolną inną zainstalowaną wersją platformy Spark (w przeciwnym razie użyjesz jednej z tych innych wersji platformy Spark i uruchomisz ją lokalnie lub zgłosisz wartość
ClassDefNotFoundError).
SBT (jeśli kontekst wymaga rozwinięcia, należy podać pełne znaczenie)
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby używać usługi Databricks Connect z usługą SBT, należy skonfigurować build.sbt plik tak, aby łączył się z regułami JARs programu Databricks Connect, a nie zwykłą zależnością biblioteki platformy Spark. Należy to zrobić za unmanagedBase pomocą dyrektywy w poniższym przykładowym pliku kompilacji, który zakłada aplikację Scala, która ma com.example.Test główny obiekt:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Powłoka platformy Spark
Uwaga
Przed rozpoczęciem korzystania z usługi Databricks Connect należy spełnić wymagania i skonfigurować klienta dla usługi Databricks Connect.
Aby użyć usługi Databricks Connect z powłoką Spark i językiem Python lub Scala, postępuj zgodnie z tymi instrukcjami.
Po aktywowaniu środowiska wirtualnego upewnij się, że
databricks-connect testpolecenie zostało pomyślnie uruchomione w obszarze Konfigurowanie klienta.Po aktywowaniu środowiska wirtualnego uruchom powłokę spark. W przypadku języka Python uruchom
pysparkpolecenie . W przypadku języka Scala uruchomspark-shellpolecenie .# For Python: pyspark# For Scala: spark-shellZostanie wyświetlona powłoka Spark, na przykład dla języka Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Dla języka Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>Zapoznaj się z tematem Interactive Analysis with the Spark Shell (Interaktywna analiza za pomocą powłoki Spark w powłoce Spark przy użyciu języka Python lub języka Scala), aby uruchomić polecenia w klastrze.
Użyj wbudowanej
sparkzmiennej, aby reprezentowaćSparkSessionklaster uruchomiony, na przykład dla języka Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsDla języka Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsAby zatrzymać powłokę Spark, naciśnij lub
Ctrl + dCtrl + zuruchom poleceniequit()alboexit()w języku Python lub:q:quitw języku Scala.
Przykłady kodu
Ten prosty przykład kodu wysyła zapytanie do określonej tabeli, a następnie pokazuje pierwsze 5 wierszy określonej tabeli. Aby użyć innej tabeli, dostosuj wywołanie do spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Ten dłuższy przykład kodu wykonuje następujące czynności:
- Tworzy ramkę danych w pamięci.
- Tworzy tabelę o nazwie
zzz_demo_temps_tablew schemaciedefault. Jeśli tabela o tej nazwie już istnieje, tabela zostanie usunięta jako pierwsza. Aby użyć innego schematu lub tabeli, dostosuj wywołania dospark.sql,temps.write.saveAsTablelub obu. - Zapisuje zawartość DataFrame w tabeli.
-
SELECTUruchamia zapytanie dotyczące zawartości tabeli. - Pokazuje wynik zapytania.
- Usuwa tabelę.
Pyton
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Skala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Jawa
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Praca z zależnościami
Zazwyczaj główna klasa lub plik w języku Python będą miały inne zależności JAR i pliki. Możesz dodać takie zależności JAR i pliki, wywołując polecenie sparkContext.addJar("path-to-the-jar") lub sparkContext.addPyFile("path-to-the-file"). Możesz również dodać pliki Egg i pliki zip za pomocą interfejsu addPyFile() . Za każdym razem, gdy uruchamiasz kod w środowisku IDE, na klastrze są instalowane pliki i żądania JAR zależności.
Pyton
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Funkcje zdefiniowane przez użytkownika w języku Python i Java
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Skala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Uzyskiwanie dostępu do narzędzi usługi Databricks
W tej sekcji opisano sposób uzyskiwania dostępu do narzędzi usługi Databricks Connect za pomocą usługi Databricks Connect.
Możesz używać narzędzi dbutils.fs i dbutils.secrets w module referencyjnym Databricks Utilities (dbutils).
Obsługiwane polecenia to dbutils.fs.cp, dbutils.fs.headdbutils.fs.lsdbutils.fs.mkdirsdbutils.fs.mvdbutils.fs.putdbutils.fs.rmdbutils.secrets.getdbutils.secrets.getBytes, . dbutils.secrets.listdbutils.secrets.listScopes
Zobacz Narzędzie systemu plików (dbutils.fs) lub uruchom dbutils.fs.help() narzędzie Secrets (dbutils.secrets) lub uruchom polecenie dbutils.secrets.help().
Pyton
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
W przypadku korzystania z środowiska Databricks Runtime 7.3 LTS lub nowszego, aby uzyskać dostęp do modułu DBUtils w sposób, który działa lokalnie i w klastrach usługi Azure Databricks, użyj następującego get_dbutils()polecenia:
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
W przeciwnym razie użyj następującego get_dbutils()polecenia:
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Skala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Kopiowanie plików między lokalnymi i zdalnymi systemami plików
Służy dbutils.fs do kopiowania plików między klientem a zdalnymi systemami plików. Schemat file:/ odwołuje się do lokalnego systemu plików na kliencie.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
Maksymalny rozmiar pliku, który można przenieść w ten sposób, wynosi 250 MB.
Włącz funkcję dbutils.secrets.get
Ze względu na ograniczenia zabezpieczeń możliwość wywoływania dbutils.secrets.get jest domyślnie wyłączona. Skontaktuj się z pomocą techniczną usługi Azure Databricks, aby włączyć tę funkcję dla obszaru roboczego.
Ustawianie konfiguracji usługi Hadoop
Na kliencie można ustawić konfiguracje usługi Hadoop przy użyciu interfejsu spark.conf.set API, który ma zastosowanie do operacji SQL i DataFrame. Konfiguracje usługi Hadoop ustawione na sparkContext serwerze muszą być ustawione w konfiguracji klastra lub przy użyciu notesu. Dzieje się tak, ponieważ konfiguracje ustawione na sparkContext serwerze nie są powiązane z sesjami użytkownika, ale mają zastosowanie do całego klastra.
Rozwiązywanie problemów
Uruchom polecenie databricks-connect test , aby sprawdzić, czy występują problemy z łącznością. W tej sekcji opisano niektóre typowe problemy, które mogą wystąpić w usłudze Databricks Connect i sposób ich rozwiązywania.
W tej sekcji:
- Niezgodność wersji języka Python
- Serwer nie jest włączony
- Instalacje środowiska PySpark powodują konflikt
-
Sprzeczne
SPARK_HOME -
Konflikt lub brak
PATHwpisu dla plików binarnych - Ustawienia serializacji powodujące konflikt w klastrze
-
Nie można odnaleźć
winutils.exew systemie Windows - Nazwa pliku, nazwa katalogu lub składnia etykiety woluminu jest niepoprawna w systemie Windows
Niezgodność wersji języka Python
Sprawdź używaną lokalnie wersję języka Python ma co najmniej tę samą wersję pomocniczą co wersja klastra (na przykład 3.9.16 w porównaniu z 3.9.15 wersją jest OK, 3.9 a 3.8 nie).
Jeśli masz zainstalowane lokalnie wiele wersji języka Python, upewnij się, że program Databricks Connect używa odpowiedniej wersji, ustawiając zmienną PYSPARK_PYTHON środowiskową (na przykład PYSPARK_PYTHON=python3).
Serwer nie jest włączony
Upewnij się, że klaster ma włączony serwer Spark z spark.databricks.service.server.enabled truesystemem . W dzienniku sterowników powinny zostać wyświetlone następujące wiersze:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Sprzeczne instalacje PySpark
Pakiet databricks-connect powoduje konflikt z narzędziem PySpark. Zainstalowanie obu tych elementów spowoduje błędy podczas inicjowania kontekstu platformy Spark w języku Python. Może to manifestować się na kilka sposobów, w tym błędy "stream uszkodzone" lub "nie znaleziono klasy". Jeśli masz zainstalowany program PySpark w środowisku języka Python, upewnij się, że został on odinstalowany przed zainstalowaniem usługi databricks-connect. Po odinstalowaniu programu PySpark upewnij się, że w pełni zainstaluj pakiet Databricks Connect:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Sprzeczne SPARK_HOME
Jeśli wcześniej używano platformy Spark na maszynie, środowisko IDE może być skonfigurowane do używania jednej z innych wersji platformy Spark, a nie platformy Databricks Connect Spark. Może to manifestować się na kilka sposobów, w tym błędy "stream uszkodzone" lub "nie znaleziono klasy". Zobaczysz, która wersja platformy Spark jest używana, sprawdzając wartość zmiennej środowiskowej SPARK_HOME :
Pyton
import os
print(os.environ['SPARK_HOME'])
Skala
println(sys.env.get("SPARK_HOME"))
Jawa
System.out.println(System.getenv("SPARK_HOME"));
Rozwiązanie
Jeśli SPARK_HOME ustawiono wersję platformy Spark inną niż ta w kliencie, usuń ustawienie zmiennej SPARK_HOME i spróbuj ponownie.
Sprawdź ustawienia zmiennej środowiskowej ŚRODOWISKA IDE, plik .bashrc, .zshrclub .bash_profile i w dowolnym innym miejscu mogą być ustawione zmienne środowiskowe. Najprawdopodobniej konieczne będzie zamknięcie i ponowne uruchomienie środowiska IDE w celu przeczyszczenia starego stanu, a nawet utworzenie nowego projektu może być konieczne, jeśli problem będzie się powtarzać.
Nie należy ustawiać SPARK_HOME nowej wartości, a jej zresetowanie powinno być wystarczające.
Konflikt lub brak PATH wpisu dla plików binarnych
Istnieje możliwość, że ścieżka jest skonfigurowana tak, aby polecenia, takie jak spark-shell , były uruchamiane inne wcześniej zainstalowane pliki binarne zamiast tej dostarczonej z usługą Databricks Connect. Może to spowodować databricks-connect test niepowodzenie. Upewnij się, że pliki binarne usługi Databricks Connect mają pierwszeństwo lub usuń zainstalowane wcześniej pliki binarne.
Jeśli nie możesz uruchamiać poleceń, takich jak spark-shell, możliwe, że zmienna środowiskowa PATH nie została automatycznie skonfigurowana przez pip3 install i musisz ręcznie dodać katalog instalacji bin do swojej ścieżki PATH. Możesz użyć usługi Databricks Connect z środowiskami IDE, nawet jeśli nie jest to skonfigurowane. Jednak databricks-connect test polecenie nie będzie działać.
Ustawienia serializacji powodujące konflikt w klastrze
Jeśli podczas uruchamiania databricks-connect testjest wyświetlany komunikat o błędach "stream corrupted" (strumień jest uszkodzony), może to być spowodowane niezgodnymi konfiguracjami serializacji klastra. Na przykład ustawienie spark.io.compression.codec konfiguracji może spowodować ten problem. Aby rozwiązać ten problem, rozważ usunięcie tych konfiguracji z ustawień klastra lub ustawienie konfiguracji w kliencie Usługi Databricks Connect.
Nie można odnaleźć winutils.exe w systemie Windows
Jeśli używasz usługi Databricks Connect w systemie Windows i zobacz:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Postępuj zgodnie z instrukcjami, aby skonfigurować ścieżkę usługi Hadoop w systemie Windows.
Nazwa pliku, nazwa katalogu lub składnia etykiety woluminu jest niepoprawna w systemie Windows
Jeśli używasz systemów Windows i Databricks Connect i zobacz:
The filename, directory name, or volume label syntax is incorrect.
Program Java lub Databricks Connect został zainstalowany w katalogu ze spacją w ścieżce. Można to obejść, instalując ścieżkę katalogu bez spacji lub konfigurując ścieżkę przy użyciu krótkiego formularza nazwy.
Uwierzytelnianie przy użyciu tokenów identyfikatora Entra firmy Microsoft
Uwaga
Poniższe informacje dotyczą tylko programu Databricks Connect w wersji 7.3.5 do 12.2.x.
Program Databricks Connect dla środowiska Databricks Runtime 13.3 LTS i nowszych obecnie nie obsługuje tokenów identyfikatora Entra firmy Microsoft.
Jeśli używasz programu Databricks Connect w wersji 7.3.5 do 12.2.x, możesz uwierzytelnić się przy użyciu tokenu identyfikatora Entra firmy Microsoft zamiast osobistego tokenu dostępu. Tokeny identyfikatora Entra firmy Microsoft mają ograniczony okres istnienia. Po wygaśnięciu tokenu identyfikatora entra firmy Microsoft program Databricks Connect kończy się niepowodzeniem Invalid Token z powodu błędu.
W przypadku programu Databricks Connect w wersji 7.3.5 do 12.2.x możesz podać token identyfikatora Entra firmy Microsoft w uruchomionej aplikacji Databricks Connect. Aplikacja musi uzyskać nowy token dostępu i ustawić go na spark.databricks.service.token klucz konfiguracji SQL.
Pyton
spark.conf.set("spark.databricks.service.token", new_aad_token)
Skala
spark.conf.set("spark.databricks.service.token", newAADToken)
Po zaktualizowaniu tokenu aplikacja może nadal używać tych samych SparkSession obiektów i wszystkich obiektów i stanu, które są tworzone w kontekście sesji. Aby uniknąć sporadycznych błędów, usługa Databricks zaleca podanie nowego tokenu przed wygaśnięciem starego tokenu.
Możesz przedłużyć okres istnienia tokenu identyfikatora Entra firmy Microsoft, aby utrwał się podczas wykonywania aplikacji. W tym celu dołącz tokenLifetimePolicy z odpowiednio długim okresem istnienia do aplikacji autoryzacji Microsoft Entra ID, która była używana do uzyskiwania tokenu dostępu.
Uwaga
Przekazywanie identyfikatora entra firmy Microsoft używa dwóch tokenów: token dostępu Microsoft Entra ID, który został wcześniej opisany w usłudze Databricks Connect w wersji 7.3.5 do 12.2.x, oraz token przekazywania usługi ADLS dla określonego zasobu generowanego przez usługę Databricks, podczas gdy usługa Databricks przetwarza żądanie. Nie można przedłużyć okresu istnienia tokenów przekazywania usługi ADLS przy użyciu zasad okresu istnienia tokenu identyfikatora entra firmy Microsoft. Jeśli wysyłasz polecenie do klastra, który trwa dłużej niż godzinę, polecenie zakończy się niepowodzeniem, jeśli polecenie uzyska dostęp do zasobu usługi ADLS po godzinie.
Ograniczenia
- Wykaz aparatu Unity.
- Przesyłanie strumieniowe ze strukturą.
- Uruchamianie dowolnego kodu, który nie jest częścią zadania Spark w klastrze zdalnym.
- Natywne interfejsy API scala, Python i R dla operacji tabeli delty (na przykład
DeltaTable.forPath) nie są obsługiwane. Jednak interfejs API SQL (spark.sql(...)) z operacjami usługi Delta Lake i interfejsem API platformy Spark (na przykładspark.read.load) w tabelach delta są obsługiwane. - Skopiuj do.
- Korzystanie z funkcji SQL, języka Python lub funkcji UDF języka Scala, które są częścią katalogu serwera. Jednak lokalnie wprowadzono funkcje UDF języka Scala i Python.
- Apache Zeppelin 0.7.x i poniżej.
- Nawiązywanie połączenia z klastrami za pomocą kontroli dostępu do tabel.
- Nawiązywanie połączenia z klastrami z włączoną izolacją procesów (innymi słowy, gdzie
spark.databricks.pyspark.enableProcessIsolationjest ustawiona wartośćtrue). - Polecenie delta
CLONESQL. - Globalne widoki tymczasowe.
-
Koalas i
pyspark.pandas. -
CREATE TABLE table AS SELECT ...Polecenia SQL nie zawsze działają. Zamiast tego użyj poleceniaspark.sql("SELECT ...").write.saveAsTable("table").
- Przekazywanie poświadczeń identyfikatora entra firmy Microsoft jest obsługiwane tylko w standardowych klastrach z uruchomionym środowiskiem Databricks Runtime 7.3 LTS lub nowszym i nie jest zgodny z uwierzytelnianiem jednostki usługi.
- Następujące odwołanie do narzędzi Databricks (
dbutils):