Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano, jak stworzyć punkty końcowe i indeksy wyszukiwania wektorów przy użyciu Mosaic AI Vector Search.
Możesz tworzyć składniki wyszukiwania wektorowego, takie jak punkt końcowy wyszukiwania wektorów i indeksy wyszukiwania wektorów, przy użyciu interfejsu użytkownika, zestawu SDK
Na przykład notesy ilustrujące sposób tworzenia i wykonywania zapytań punktów końcowych wyszukiwania wektorowego, zobacz Przykładowe notesy wyszukiwania wektorowego. Aby uzyskać informacje referencyjne, zobacz dokumentację zestawu SDK Python.
Requirements
- Obszar roboczy z włączonym Unity Catalog.
- Włączono bezserwerowe obliczenia. Aby uzyskać instrukcje, zobacz Połącz się z obliczeniami bezserwerowymi.
- W przypadku standardowych punktów końcowych tabela źródłowa musi mieć włączony Strumień danych zmian. Zobacz Korzystanie z przepływu danych zmian w Delta Lake na platformie Azure Databricks.
- Aby utworzyć indeks wyszukiwania wektorowego, musisz mieć uprawnienia CREATE TABLE w schemacie wykazu, w którym zostanie utworzony indeks.
- Aby wykonać zapytanie dotyczące indeksu należącego do innego użytkownika, musisz mieć dodatkowe uprawnienia. Zobacz Jak wykonywać zapytania względem indeksu wyszukiwania wektorowego.
Uprawnienia do tworzenia punktów końcowych wyszukiwania wektorów i zarządzania nimi są konfigurowane przy użyciu list kontroli dostępu. Zobacz kontrole dostępu (ACL) punktu końcowego wyszukiwania wektorów
Instalacja
Aby użyć zestawu SDK wyszukiwania wektorowego, należy zainstalować go w notesie. Użyj następującego kodu, aby zainstalować pakiet:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Następnie użyj następującego polecenia, aby zaimportować VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Aby uzyskać informacje na temat uwierzytelniania, zobacz Ochrona danych i uwierzytelnianie.
Tworzenie punktu końcowego wyszukiwania wektorów
Punkt końcowy wyszukiwania wektorów można utworzyć przy użyciu interfejsu użytkownika usługi Databricks, zestawu SDK Python lub interfejsu API.
Tworzenie punktu końcowego wyszukiwania wektorów przy użyciu interfejsu użytkownika
Wykonaj następujące kroki, aby utworzyć punkt końcowy wyszukiwania wektorów przy użyciu interfejsu użytkownika.
Na lewym pasku bocznym kliknij pozycję Compute.
Kliknij kartę Wyszukiwanie wektorowe i kliknij pozycję Utwórz punkt końcowy.

Otwiera się formularz tworzenia punktu końcowego . Wprowadź nazwę tego punktu końcowego.
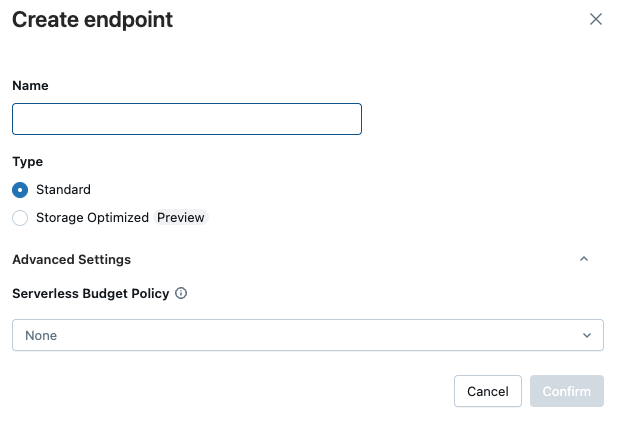
W polu Typ wybierz pozycję Standardowa lub Zoptymalizowana pod kątem magazynu. Zobacz Opcje punktu końcowego.
(Opcjonalnie) W obszarze Ustawienia zaawansowane wybierz zasady budżetu. Zobacz Zasady budżetu wyszukiwania wektorowego.
Kliknij przycisk Potwierdź.
Tworzenie punktu końcowego wyszukiwania wektorów przy użyciu zestawu SDK Python
W poniższym przykładzie użyto funkcji zestawu SDK create_endpoint() w celu utworzenia punktu końcowego wyszukiwania wektorów.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
Tworzenie punktu końcowego wyszukiwania wektorów przy użyciu interfejsu API REST
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/endpoints.
Utwórz punkt końcowy z minimalnym docelowym QPS dla obciążeń o wysokiej przepustowości
Ważne
Ta funkcja jest dostępna w wersji beta. Administratorzy obszaru roboczego mogą kontrolować dostęp do tej funkcji ze strony Podglądy . Zobacz Zarządzanie podglądami Azure Databricks.
W przypadku obciążeń o wysokiej wydajności można utworzyć punkt końcowy z minimalnym docelowym QPS. Ta funkcja jest dostępna tylko dla standardowych punktów końcowych.
Aby ustawić minimalną wartość docelową QPS, użyj parametru min_qps . Zobacz Zwiększanie przepustowości punktu końcowego przy wysokim QPS (beta).
Ważne
Włączenie min_qps zwiększa dodatkową pojemność, co zwiększa koszt punktu końcowego. Opłaty są naliczane za tę dodatkową pojemność niezależnie od rzeczywistego ruchu zapytań. Aby zatrzymać naliczanie tych opłat, zresetuj punkt końcowy przy użyciu polecenia min_qps=-1. Skalowanie przepływności jest realizowane w miarę możliwości (best-effort) i nie jest gwarantowane w wersji beta.
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
min_qps=500, # Beta: minimum QPS target for high-throughput workloads
)
Aby zmienić minimalną liczbę QPS w istniejącym punkcie końcowym, użyj polecenia update_endpoint().
from databricks.vector_search.client import VectorSearchClient, MIN_QPS_RESET_TO_DEFAULT
client = VectorSearchClient()
# Set or update minimum QPS
response = client.update_endpoint(name="vector_search_endpoint_name", min_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
# Remove high QPS configuration and return to default
client.update_endpoint(name="vector_search_endpoint_name", min_qps=MIN_QPS_RESET_TO_DEFAULT)
Po zaktualizowaniu minimalnej liczby QPS zsynchronizuj indeksy, aby zastosować nową konfigurację.
(Opcjonalnie) Tworzenie i konfigurowanie punktu końcowego w celu obsługi modelu osadzania
Jeśli zdecydujesz się, aby usługa Databricks obliczała wektory, możesz użyć wstępnie skonfigurowanego punktu końcowego interfejsów API modelu bazowego lub utworzyć punkt końcowy obsługujący wybrany model osadzania. Aby uzyskać instrukcje, zobacz interfejsy API modelu z płatnością na podstawie tokena lub Utwórz punkty końcowe obsługujące model podstawowy. Aby zobaczyć przykładowe notesy, zobacz przykładowe notesy wyszukiwania wektorów.
Podczas konfigurowania punktu końcowego osadzania usługa Databricks zaleca usunięcie domyślnego wyboru Skalowanie do zera. Obsługa punktów końcowych może potrwać kilka minut, a początkowe zapytanie dotyczące indeksu ze skalowanym w dół punktem końcowym może spowodować przekroczenie limitu czasu.
Uwaga / Notatka
Inicjowanie indeksu wyszukiwania wektorowego może dojść do przekroczenia limitu czasu, gdy punkt końcowy osadzania nie został odpowiednio skonfigurowany dla zestawu danych. W przypadku małych zestawów danych i testów należy używać tylko punktów końcowych procesora CPU. W przypadku większych zestawów danych użyj punktu końcowego procesora GPU w celu uzyskania optymalnej wydajności.
Tworzenie indeksu wyszukiwania wektorów
Indeks wyszukiwania wektorowego można utworzyć przy użyciu interfejsu użytkownika, zestawu SDK Python lub interfejsu API REST. Interfejs użytkownika jest najprostszym podejściem.
Istnieją dwa typy indeksów:
- Indeks Delta Sync automatycznie synchronizuje się ze źródłową tabelą Delta, automatycznie i przyrostowo aktualizując indeks w miarę zmian danych w tabeli Delta.
- Bezpośredni Indeks Dostępu do Wektorów umożliwia bezpośrednie odczytywanie i zapisywanie wektorów oraz metadanych. Użytkownik jest odpowiedzialny za aktualizowanie tej tabeli przy użyciu interfejsu API REST lub zestawu SDK Python. Nie można utworzyć tego typu indeksu przy użyciu interfejsu użytkownika. Musisz użyć interfejsu API REST lub zestawu SDK.
Indeksy usługi Delta Sync obsługują następujące tryby wyszukiwania:
-
Wyszukiwanie wektorowe (ANN lub hybrydowa): wymaga osadzania kolumn. Obsługuje zarówno standardowe, jak i zoptymalizowane pod kątem magazynu punkty końcowe. Można również użyć
query_type="FULL_TEXT"funkcji wyszukiwania słów kluczowych dla tych indeksów. - Dedykowany indeks wyszukiwania pełnotekstowego (beta): Indeks Delta Sync utworzony bez żadnych kolumn osadzania, dla wyszukiwania wyłącznie po słowach kluczowych. Dostępne tylko w punktach końcowych zoptymalizowanych pod kątem przechowywania z wyzwalanym trybem synchronizacji. Zobacz Tworzenie indeksu wyszukiwania pełnotekstowego.
Uwaga / Notatka
Nazwa _id kolumny jest zarezerwowana. Jeśli tabela źródłowa ma kolumnę o nazwie _id, zmień jej nazwę przed utworzeniem indeksu wyszukiwania wektorowego.
Tworzenie indeksu przy użyciu interfejsu użytkownika
Na pasku bocznym po lewej stronie kliknij pozycję Katalog, aby otworzyć interfejs użytkownika Eksploratora katalogu.
Przejdź do tabeli delty, której chcesz użyć.
Kliknij przycisk Utwórz w prawym górnym rogu i wybierz indeks wyszukiwania wektorów z menu rozwijanego.
Użyj selektorów w oknie dialogowym, aby skonfigurować indeks.
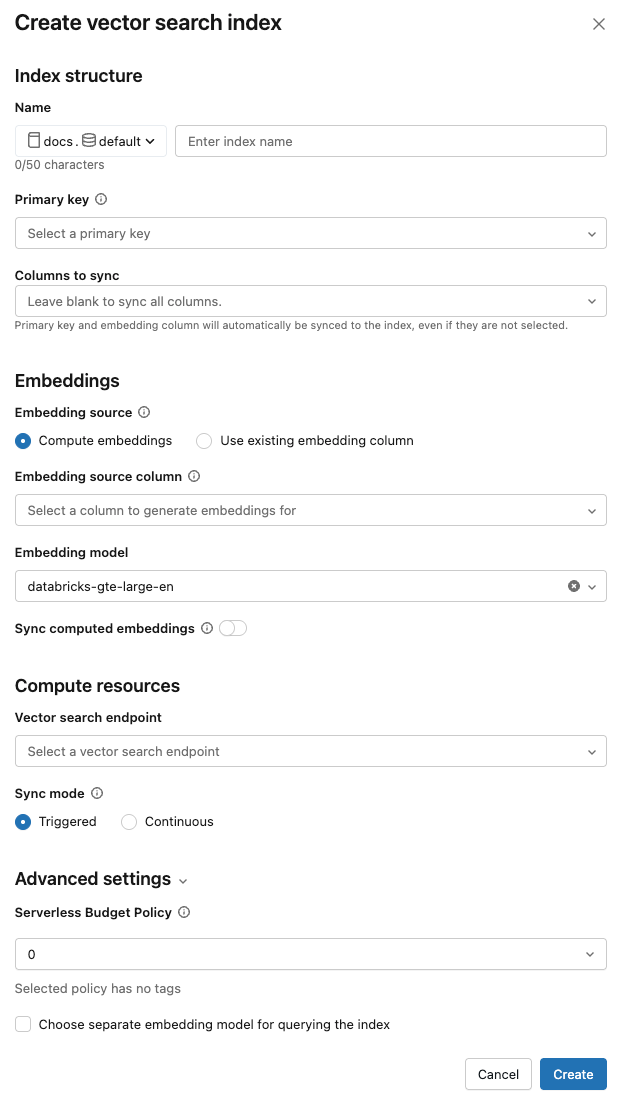
Nazwa: Nazwa używana dla tabeli online w Unity Catalog. Nazwa wymaga trzypoziomowej przestrzeni nazw,
<catalog>.<schema>.<name>. Dozwolone są tylko znaki alfanumeryczne i podkreślenia.klucz podstawowy: kolumna do użycia jako klucz podstawowy.
Kolumny do synchronizacji: wybierz kolumny do synchronizacji z indeksem wektorowym. Jeśli to pole pozostanie puste, wszystkie kolumny z tabeli źródłowej zostaną zsynchronizowane z indeksem. Kolumna klucza podstawowego oraz kolumna źródłowa osadzania lub kolumna wektora osadzania są zawsze synchronizowane.
osadzanie źródła: Wskaż, czy chcesz, aby usługa Databricks obliczała reprezentacje dla kolumny tekstowej w tabeli Delta (Oblicz reprezentacje), lub jeśli tabela Delta zawiera wstępnie obliczone reprezentacje (Użyj istniejącej kolumny reprezentacji).
Jeśli wybrano Oblicz osadzenia, wybierz kolumnę, dla której mają zostać obliczone osadzenia, oraz model osadzania do użycia w obliczeniach. Obsługiwane są tylko kolumny tekstowe.
W przypadku aplikacji produkcyjnych korzystających ze standardowych punktów końcowych usługa Databricks zaleca używanie modelu
databricks-gte-large-enpodstawowego z aprowizowaną przepływnością obsługującego punkt końcowy.W przypadku aplikacji produkcyjnych korzystających z punktów końcowych zoptymalizowanych pod kątem przechowywania danych, z modelami hostowanymi w usłudze Databricks, użyj nazwy modelu bezpośrednio (na przykład
databricks-gte-large-en) jako punktu końcowego modelu kodowania. Zoptymalizowane pod kątem przechowywania punkty końcowe wykorzystująai_queryz wnioskowaniem wsadowym podczas przetwarzania danych wejściowych, zapewniając wysoką przepływność dla procesu osadzania. Jeśli preferujesz używać dedykowanego punktu końcowego o przepustowości do wykonywania zapytań, określ to w polumodel_endpoint_name_for_querypodczas tworzenia indeksu.
W przypadku wybrania Użyj istniejącej kolumny osadzania danych, wybierz kolumnę zawierającą wstępnie obliczone osadzanie oraz wymiar osadzania. Format wstępnie skompilowanej kolumny osadzania powinien być
array[float]. W przypadku punktów końcowych zoptymalizowanych pod kątem magazynu wymiar osadzania musi być równomiernie podzielny przez 16.
Synchronizacja obliczonych osadzeń: Przełącz to ustawienie, aby zapisać wygenerowane osadzenia w tabeli katalogu Unity. Aby uzyskać więcej informacji, zobacz Zapisz wygenerowaną tabelę osadzania.
Punkt końcowy wyszukiwania wektorowego: wybierz punkt końcowy wyszukiwania wektorów do przechowywania indeksu.
tryb synchronizacji: ciągły utrzymuje indeks w synchronizacji z sekundami opóźnienia. Jednak wiąże się z nim wyższy koszt, ponieważ klaster obliczeniowy jest przydzielany w celu uruchomienia potoku strumieniowego ciągłej synchronizacji.
- W przypadku standardowych punktów końcowych zarówno ciągłe , jak i wyzwalane wykonują aktualizacje przyrostowe, więc przetwarzane są tylko dane, które uległy zmianie od ostatniej synchronizacji.
- W przypadku punktów końcowych zoptymalizowanych pod kątem magazynowania każda synchronizacja częściowo odbudowuje indeks. W przypadku indeksów zarządzanych podczas kolejnych synchronizacji wszystkie wygenerowane osadzanie, w przypadku których wiersz źródłowy nie uległ zmianie, są ponownie używane i nie muszą być ponownie skompilowane. Zobacz Ograniczenia dotyczące punktów końcowych zoptymalizowanych pod kątem magazynu.
W trybie synchronizacji Triggered możesz użyć zestawu SDK Pythona lub interfejsu API REST, aby rozpocząć synchronizację. Zobacz Update a Delta Sync Index.
W przypadku punktów końcowych zoptymalizowanych pod kątem przechowywania obsługuje wyłącznie tryb synchronizacji wyzwalanej.
Ustawienia zaawansowane: (opcjonalnie)
Do indeksu można zastosować zasady budżetu. Zobacz Zasady budżetu wyszukiwania wektorowego.
W przypadku wybrania opcji Osadzanie obliczeniowe można określić oddzielny model osadzania w celu wykonywania zapytań względem indeksu wyszukiwania wektorowego. Może to być przydatne, jeśli potrzebujesz punktu końcowego o wysokiej przepustowości do przetwarzania danych, ale punktu końcowego o niższym opóźnieniu do wykonywania zapytań dotyczących indeksu. Model określony w polu Model osadzania jest zawsze używany do pozyskiwania i jest również używany do wykonywania zapytań, chyba że w tym miejscu określono inny model. Aby określić inny model, kliknij pozycję Wybierz oddzielny model osadzania na potrzeby wykonywania zapytań względem indeksu i wybierz model z menu rozwijanego.
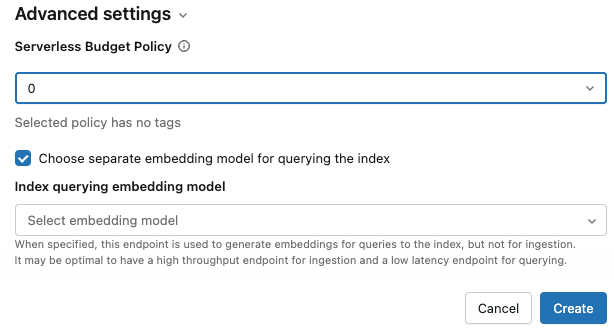
Po zakończeniu konfigurowania indeksu kliknij pozycję Utwórz.
Tworzenie indeksu przy użyciu zestawu SDK Python
W poniższym przykładzie tworzony jest indeks synchronizacji Delta z embeddingami obliczonymi przez Databricks. Aby uzyskać szczegółowe informacje, zobacz dokumentację zestawu SDK Python.
W tym przykładzie przedstawiono również opcjonalny parametr model_endpoint_name_for_query, który określa oddzielny model osadzania obsługujący punkt końcowy, który ma być używany do wykonywania zapytań względem indeksu.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
W poniższym przykładzie tworzony jest Delta Sync Index z własnymi embeddingami.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Domyślnie wszystkie kolumny z tabeli źródłowej są synchronizowane z indeksem. Aby wybrać podzbiór kolumn do synchronizacji, użyj polecenia columns_to_sync. Klucz podstawowy i kolumny wbudowane są zawsze uwzględniane w indeksie.
Aby zsynchronizować tylko klucz podstawowy i kolumnę osadzania, należy określić je w columns_to_sync, jak pokazano poniżej:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Aby zsynchronizować dodatkowe kolumny, określ je w sposób pokazany. Nie trzeba dołączać klucza podstawowego i kolumny osadzania, ponieważ są one zawsze synchronizowane.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Tworzenie indeksu wyszukiwania pełnotekstowego (beta)
Ważne
Tworzenie indeksu wyszukiwania pełnotekstowego jest dostępne jako funkcja beta tylko w punktach końcowych zoptymalizowanych dla potrzeb przechowywania. Aby go używać, należy włączyć wersję zapoznawczą obszaru roboczego vs_full_text. Skontaktuj się z zespołem ds. kont lub zobacz Zarządzaj podglądami Azure Databricks aby włączyć podglądy.
Indeks wyszukiwania pełnotekstowego umożliwia wyszukiwanie oparte na słowach kluczowych na kolumnach tekstowych bez konieczności osadzania wektorów. Jest to przydatne, gdy chcesz wyszukać dokładne terminy, identyfikatory lub słowa kluczowe, a nie semantyczne podobieństwo.
Indeksy wyszukiwania pełnotekstowego mają następujące wymagania:
- Musi używać punktu końcowego zoptymalizowanego pod kątem przechowywania. Standardowe punkty końcowe nie są obsługiwane.
- Musi używać trybu wyzwolonego synchronizacji. Ciągła synchronizacja nie jest obsługiwana.
- Parametry
embedding_source_column,embedding_vector_columniembedding_dimensionnie są obsługiwane.
Poniższy przykład tworzy indeks wyszukiwania pełnotekstowego przy użyciu zestawu SDK Python.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
Po utworzeniu indeksu wyzwól synchronizację, aby ją wypełnić:
index.sync()
Aby wysłać zapytanie do indeksu pełnotekstowego, użyj polecenia query_type="FULL_TEXT". Aby uzyskać szczegółowe informacje, zobacz Query a vector search index (Wykonywanie zapytań względem indeksu wyszukiwania wektorów ).
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
Poniższy przykład tworzy indeks bezpośredniego dostępu do wektora.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Tworzenie indeksu przy użyciu interfejsu API REST
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/indexes.
Zapisz wygenerowaną tabelę osadzania
Jeśli Databricks generuje embeddings, możesz zapisać wygenerowane embeddings w tabeli w Unity Catalog. Ta tabela jest tworzona w tym samym schemacie co indeks wektorowy i jest połączona ze strony indeksu wektorowego.
Nazwa tabeli to nazwa indeksu wyszukiwania wektorów, dołączana przez _writeback_table. Nazwa nie jest edytowalna.
Możesz uzyskiwać dostęp do tabeli i wykonywać do niej zapytania, tak jak do każdej innej tabeli w katalogu Unity. Nie należy jednak usuwać ani modyfikować tabeli, ponieważ nie jest ona przeznaczona do ręcznej aktualizacji. Tabela zostanie usunięta automatycznie, jeśli indeks zostanie usunięty.
Aktualizowanie indeksu wyszukiwania wektorowego
Aktualizacja indeksu synchronizacji różnicowej
Indeksy utworzone w trybie synchronizacji ciągłej są automatycznie aktualizowane, gdy zmienia się źródłowa tabela Delta. Jeśli używasz trybu synchronizacji Triggered, możesz rozpocząć synchronizację przy użyciu interfejsu użytkownika, zestawu SDK Python lub interfejsu API REST.
Interfejs użytkownika usługi Databricks
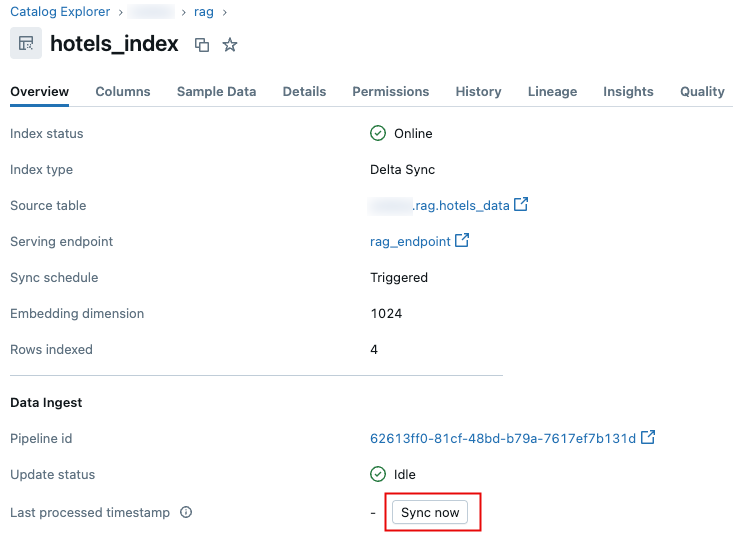
W Eksploratorze wykazu przejdź do indeksu wyszukiwania wektorowego.
Na karcie Przegląd w sekcji Pozyskiwanie danych kliknij pozycję Synchronizuj teraz.
zestaw SDK Python
Aby uzyskać szczegółowe informacje, zobacz dokumentację zestawu SDK Python.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
interfejs API REST
Zapoznaj się z dokumentacją interfejsu API REST: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Aktualizacja indeksu dostępu wektora bezpośredniego
Za pomocą zestawu SDK Python lub interfejsu API REST można wstawić, zaktualizować lub usunąć dane z indeksu dostępu bezpośredniego wektora.
zestaw SDK Python
Aby uzyskać szczegółowe informacje, zobacz dokumentację zestawu SDK Python.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
interfejs API REST
Zobacz dokumentację referencyjną interfejsu API REST: POST /api/2.0/vector-search/indexes.
W przypadku aplikacji produkcyjnych Databricks zaleca używanie pryncypałów serwisowych zamiast osobistych tokenów dostępu. Wydajność można poprawić o maksymalnie 100 ms na zapytanie.
Poniższy przykład kodu ilustruje sposób aktualizowania indeksu przy użyciu zasady usługi.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Poniższy przykład kodu ilustruje sposób aktualizowania indeksu przy użyciu osobistego tokenu dostępu (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Jak wprowadzać zmiany schematu bez przestoju
Zmiany schematu w tabeli źródłowej nie są obsługiwane, chyba że ponownie skompilujesz indeks. Obejmuje to modyfikowanie istniejących kolumn i dodawanie nowych kolumn. Schemat indeksu jest stały w czasie tworzenia, więc wszelkie zmiany schematu wymagają utworzenia nowego indeksu, aby zaczęły obowiązywać.
Wykonaj następujące kroki, aby ponownie skompilować i wdrożyć indeks bez przestoju:
- Przeprowadź zmianę schematu w tabeli źródłowej.
- Utwórz nowy indeks przy użyciu zaktualizowanego schematu.
- Gdy nowy indeks będzie gotowy, przełącz ruch do nowego indeksu.
- Usuń oryginalny indeks.