Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano używanie Edytora potoków Lakeflow do opracowywania i debugowania potoków ETL (wyodrębnianie, przekształcanie i ładowanie) w Lakeflow Spark Declarative Pipelines (SDP).
Co to jest Edytor Lakeflow Pipelines?
Edytor Lakeflow Pipelines jest środowiskiem IDE przeznaczonym do rozwijania potoków. Łączy wszystkie zadania programistyczne potoków na jednej powierzchni, obsługując przepływy pracy oparte na kodzie, organizację kodu opartą na folderach, selektywne wykonywanie, podglądy danych i grafy potoków. Zintegrowana z platformą Azure Databricks umożliwia również kontrolę wersji, przeglądy kodu i zaplanowane uruchomienia.
Omówienie interfejsu użytkownika edytora potoków Lakeflow
Na poniższej ilustracji przedstawiono Edytor Potoków Lakeflow.
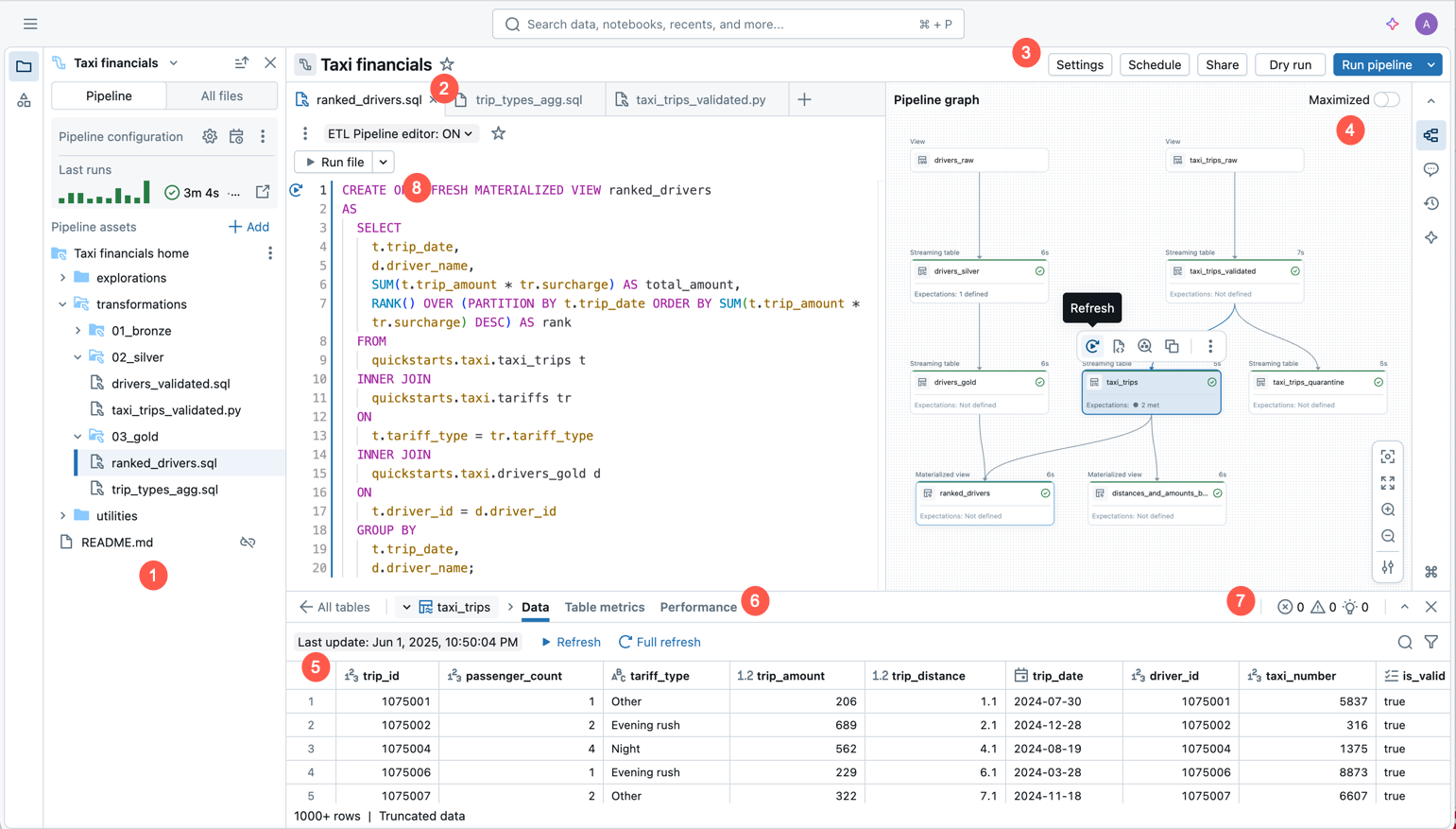
Obraz przedstawia następujące funkcje:
- Przeglądarka zasobów pipeline'u: tworzyć, usuwać, zmieniać nazwy i organizować zasoby pipeline'u. Zawiera również skróty do konfiguracji potoku.
- Edytor kodu z kartami dla wielu plików: Praca z wieloma plikami kodu powiązanymi z pipeline.
- Pasek narzędzi specyficzny dla potoku: zawiera opcje konfiguracji potoku i zawiera akcje uruchamiania na poziomie potoku.
- Interaktywny wykres potoku: Uzyskaj przegląd tabel, otwórz dolny pasek podglądu danych i wykonaj inne akcje związane z tabelami.
- Szczegółowe informacje o wykonywaniu na poziomie tabel: Uzyskaj szczegółowe informacje o wykonywaniu dla wszystkich tabel lub jednej tabeli w potoku. Szczegółowe informacje dotyczą najnowszego uruchomienia potoku.
- Panel Problemy: ta funkcja podsumowuje błędy, ostrzeżenia i szczegółowe informacje we wszystkich plikach w potoku, a następnie możesz przejść do lokalizacji, w której wystąpił błąd wewnątrz określonego pliku. Uzupełnia on wskaźniki błędów umieszczonych w kodzie.
- Wykonywanie selektywne: Edytor kodu ma funkcje programowania krok po kroku, takie jak możliwość odświeżania tylko tabel w bieżącym pliku przy użyciu akcji Uruchom plik lub odświeżania pojedynczej tabeli.
-
 Genie Code: Twórz, aktualizuj i debuguj swoje potoki za pomocą Genie Code — funkcji opartej na agencie AI, która automatyzuje wieloetapowe przepływy pracy, od odnajdywania danych i generowania kodu po uruchamianie potoków oraz rozwiązywanie problemów z jakością danych.
Genie Code: Twórz, aktualizuj i debuguj swoje potoki za pomocą Genie Code — funkcji opartej na agencie AI, która automatyzuje wieloetapowe przepływy pracy, od odnajdywania danych i generowania kodu po uruchamianie potoków oraz rozwiązywanie problemów z jakością danych.
Inne ważne funkcje:
- Podgląd danych: sprawdź dane tabel przesyłania strumieniowego i zmaterializowane widoki.
- Domyślna struktura folderów potoku: nowe potoki zawierają wstępnie zdefiniowaną strukturę folderów i przykładowy kod, którego można użyć jako punktu wyjścia dla potoku.
Utwórz nowy potok ETL
Aby utworzyć nowy potok ETL przy użyciu Edytora Potoków Lakeflow, postępuj zgodnie z tymi krokami:
W górnej części paska bocznego kliknij
 Nowy, następnie wybierz
Nowy, następnie wybierz  Potok ETL.
Potok ETL.Potok jest tworzony automatycznie z następującymi ustawieniami domyślnymi:
Możesz dostosować te ustawienia na pasku narzędzi rurociągu.
U góry nadaj potokowi unikatową nazwę.
Obok nazwy wyświetlane są domyślny katalog i schemat wybrane dla Ciebie.
Domyślny wykaz i domyślny schemat to miejsce, w którym zestawy danych są odczytywane lub zapisywane, gdy nie kwalifikujesz zestawów danych z wykazem lub schematem w kodzie. Aby uzyskać więcej informacji, zobacz Obiekty bazy danych w usłudze Azure Databricks .
Kliknij katalog i schemat, aby zmienić domyślne ustawienia potoku.
Potok domyślnie ma pusty plik
my_transformation. Przełącz ten plik między Python a bazą danych SQL, wybierając z listy rozwijanej język. Napisz kod bezpośrednio w tym pliku lub wybierz jedną z następujących opcji, aby szybko rozpocząć pracę:-
Tworzenie za pomocą kodu Genie: opisz potok przy użyciu języka naturalnego i pozwól aplikacji Genie Code skompilować go za Ciebie.
- Użyj przykładowego kodu: utwórz domyślną strukturę folderów i przykładowy kod w języku bieżącego pliku.
Aby uzyskać bardziej zaawansowane opcje, rozwiń menu
 (po prawej stronie przycisku
(po prawej stronie przycisku  Użyj przykładowego kodu), aby:
Użyj przykładowego kodu), aby:- Dodaj istniejący kod źródłowy: Skojarz potok z plikami kodu źródłowego już dostępnymi w obszarze roboczym, w tym z folderami Git.
- Skonfiguruj pod kontrolą wersji: użyj projektu Declarative Automation Bundles, aby uzyskać obsługę kontroli wersji i CI/CD.
- Użyj magazynu metadanych Hive: utwórz potok ze starszymi ustawieniami.
-
Alternatywnie możesz utworzyć potok ETL w przeglądarce obszaru roboczego:
- Kliknij pozycję Obszar roboczy w panelu po lewej stronie.
- Wybierz dowolny folder, w tym foldery Git.
- Kliknij pozycję Utwórz w prawym górnym rogu, a następnie kliknij pozycję Potok ETL.
Potok ETL można również utworzyć na stronie z zadaniami i potokami.
- W obszarze roboczym kliknij
 Zadania i rury na pasku bocznym.
Zadania i rury na pasku bocznym. - W obszarze Nowy kliknij ETL Pipeline.
Wskazówka
Interfejs wiersza polecenia (CLI) usługi Databricks udostępnia polecenia umożliwiające tworzenie, modyfikowanie i zarządzanie potokami deklaratywnymi Lakeflow Spark bezpośrednio w terminalu. Zobacz pipelines grupę poleceń.
Otwórz istniejący potok ETL
Istnieje wiele sposobów otworzenia istniejącego potoku ETL w edytorze potoków Lakeflow:
Otwórz dowolny plik źródłowy skojarzony z potokiem:
- Kliknij pozycję Obszar roboczy w panelu bocznym.
- Przejdź do folderu z plikami kodu źródłowego dla potoku.
- Kliknij plik kodu źródłowego, aby otworzyć pipeline w edytorze.
Otwórz niedawno edytowany rurociąg:
- W edytorze możesz przejść do innych ostatnio edytowanych potoków, klikając nazwę potoku u góry przeglądarki zasobów i wybierając inny potok z wyświetlonej listy ostatnio edytowanych.
- Spoza edytora na stronie Ostatnie na lewym pasku bocznym otwórz potok lub plik skonfigurowany jako kod źródłowy potoku.
Podczas przeglądania potoku w całym produkcie możesz edytować potok:
- Na stronie monitorowania potoku kliknij
 Edytuj potok.
Edytuj potok. - Na stronie Zadania i potoki na lewym pasku bocznym kliknij Aby edytować potok.
- Podczas edytowania zadania i dodawania zadania potoku, możesz kliknąć przycisk
 , kiedy wybierzesz potok w obszarze Potok.
, kiedy wybierzesz potok w obszarze Potok.
- Na stronie monitorowania potoku kliknij
Jeśli przeglądasz Wszystkie pliki w przeglądarce zasobów, a gdy otworzysz plik kodu źródłowego z innego potoku, w górnej części edytora zostanie wyświetlony baner z monitem o otwarcie skojarzonego potoku.
Przeglądarka zasobów potoku
Podczas edytowania potoku lewy pasek boczny obszaru roboczego używa trybu specjalnego nazywanego przeglądarką zasobów potoku. Domyślnie przeglądarka zasobów potoku jest skupiona na katalogu głównym potoku oraz folderach i plikach w jego obrębie. Możesz również wybrać opcję wyświetlenia wszystkich plików, aby zobaczyć pliki poza główną strukturą potoku. Karty otwarte w edytorze potoków podczas edytowania konkretnego potoku są zapamiętywane, a przy przełączaniu na inny potok przywracane są te same karty, które były otwarte podczas ostatniej edycji tego potoku.
Uwaga / Notatka
Edytor zawiera również konteksty do edytowania plików SQL (nazywanych Edytorem SQL usługi Databricks) oraz ogólny kontekst edytowania plików w obszarach roboczych, które nie są plikami SQL ani potokowymi. Każdy z tych kontekstów zapamiętuje i przywraca karty, które były otwierane podczas ostatniego użycia tego kontekstu. Kontekst można przełączać z góry lewego paska bocznego. Kliknij nagłówek, aby wybrać między Workspace, Edytorem SQL a ostatnio edytowaną potoką.
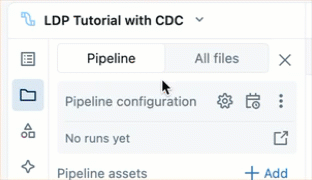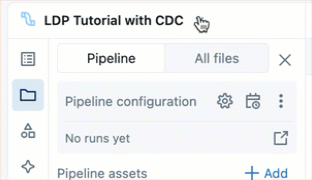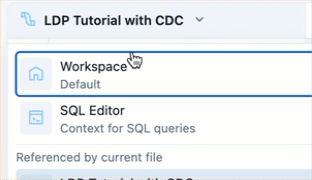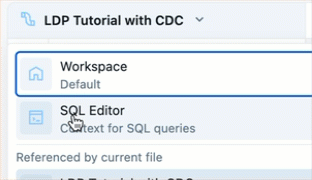
Po otwarciu pliku z przeglądarki Obszaru roboczego, zostanie on otwarty w odpowiadającym mu edytorze. Jeśli plik jest skojarzony z potokiem, to jest to Edytor Potoków Lakeflow.
Aby otworzyć plik, który nie jest częścią procesu, ale zachować jego kontekst, otwórz plik z zakładki Wszystkie pliki w przeglądarce zasobów.
Przeglądarka zasobów pipeline’u ma dwie karty.
- Pipeline: W tym miejscu można znaleźć wszystkie pliki związane z tym procesem. Można tworzyć, usuwać, zmieniać nazwy i organizować je w folderach. Ta karta zawiera również skróty klawiszowe do konfiguracji potoku oraz graficzny widok ostatnich przebiegów.
- Wszystkie pliki: wszystkie inne zasoby obszaru roboczego są dostępne tutaj. Może to być przydatne w przypadku znajdowania plików do dodania do potoku lub wyświetlania innych plików związanych z potokiem, takich jak plik YAML, który definiuje deklaratywne pakiety automatyzacji.
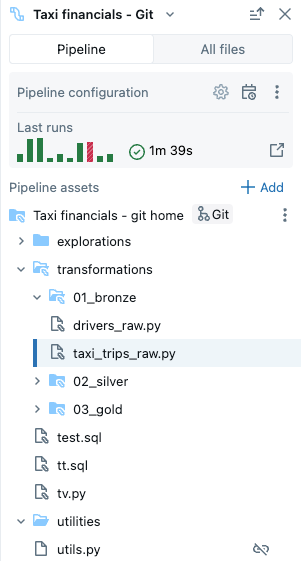
Możesz mieć następujące typy plików w swoim potoku.
- Pliki kodu źródłowego: Pliki te są częścią definicji kodu źródłowego strumienia, którą można zobaczyć w Ustawieniach. Usługa Databricks zaleca zawsze przechowywanie plików kodu źródłowego w folderze głównym potoku; w przeciwnym razie są one wyświetlane w sekcji plików zewnętrznych w dolnej części interfejsu przeglądarki Databricks i mają mniej bogaty zestaw funkcji.
- pl-PL: Pliki niebędące kodem źródłowym: Te pliki są przechowywane w folderze głównym potoku, ale nie są częścią definicji kodu źródłowego potoku.
Ważne
Aby zarządzać plikami i folderami w swoim potoku, musisz użyć przeglądarki zasobów potoku na karcie Pipeline. To poprawnie zaktualizuje ustawienia pipeline. Przenoszenie lub zmienianie nazw plików i folderów z przeglądarki obszaru roboczego lub na karcie Wszystkie pliki powoduje przerwanie konfiguracji potoku, a następnie należy rozwiązać ten problem ręcznie w obszarze Ustawienia.
Folder główny
Przeglądarka zasobów potoku jest zakotwiczona w folderze głównym potoku. Podczas tworzenia nowego potoku folder główny potoku jest tworzony w folderze głównym użytkownika.
Folder główny można zmienić w przeglądarce zasobów potoku. Jest to przydatne, jeśli utworzyłeś potok w folderze, a później chcesz przenieść wszystko do innego folderu. Na przykład pipeline został utworzony w zwykłym folderze i chcesz przenieść kod źródłowy do folderu Git w celu kontroli wersji.
- Kliknij Menu przepełnienia dla folderu głównego.
- Kliknij Konfiguruj nowy folder główny.
- W obszarze Folder główny potoku kliknij
 i wybierz inny folder jako folder główny potoku.
i wybierz inny folder jako folder główny potoku. - Kliknij przycisk Zapisz.
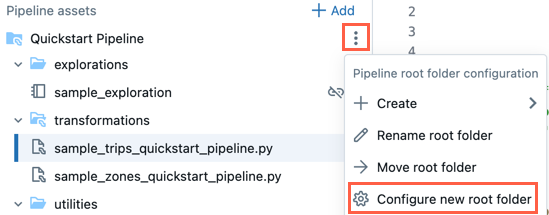
W ![]() w folderze głównym możesz również kliknąć pozycję Zmień nazwę folderu głównego , aby zmienić nazwę folderu. W tym miejscu możesz również kliknąć pozycję Przenieś folder główny , aby przenieść folder główny, na przykład do folderu Git.
w folderze głównym możesz również kliknąć pozycję Zmień nazwę folderu głównego , aby zmienić nazwę folderu. W tym miejscu możesz również kliknąć pozycję Przenieś folder główny , aby przenieść folder główny, na przykład do folderu Git.
Możesz również zmienić folder główny potoku w ustawieniach:
- Kliknij przycisk Ustawienia.
- W obszarze Zasoby kodu kliknij pozycję Konfiguruj ścieżki.
- Kliknij , aby zmienić folder w folderze głównym potoku.
- Kliknij przycisk Zapisz.
Uwaga / Notatka
Jeśli zmienisz folder główny potoku, lista plików wyświetlana przez przeglądarkę zasobów potoku zmieni się, ponieważ pliki z poprzedniego folderu głównego będą wyświetlane jako pliki zewnętrzne.
Istniejący potok bez folderu głównego
Istniejący potok utworzony przy użyciu starszego środowiska edytowania notatnika nie będzie miał skonfigurowanego folderu głównego. Po otwarciu potoku, który nie ma skonfigurowanego folderu głównego, jeśli chcesz skonfigurować folder główny dla potoku, wykonaj następujące kroki:
- W przeglądarce zasobów pipeline’u kliknij Konfiguruj.
- Kliknij , aby wybrać folder główny u dołu Folder główny potoku.
- Kliknij przycisk Zapisz.
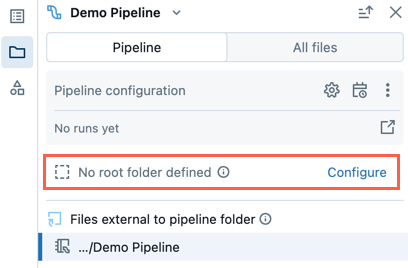
Domyślna struktura folderów
Podczas tworzenia nowego potoku zostanie utworzona domyślna struktura folderów. Jest to zalecana struktura organizowania plików źródłowych potoku i plików kodu innego niż źródłowy, zgodnie z poniższym opisem.
W tej strukturze folderów jest tworzona niewielka liczba przykładowych plików kodu.
| Nazwa folderu | Zalecana lokalizacja dla tych typów plików |
|---|---|
<pipeline_root_folder> |
Folder główny zawierający wszystkie foldery i pliki dla ciągu technologicznego. |
transformations |
Pliki kodu źródłowego, takie jak pliki kodu Python lub SQL z definicjami tabeli. |
explorations |
Pliki kodu inne niż źródłowe, takie jak notesy, zapytania i pliki kodu używane do eksploratywnej analizy danych. |
utilities |
Pliki kodu inne niż źródłowe z modułami języka Python, które można zaimportować z innych plików kodu. Jeśli wybierzesz język SQL jako język przykładowego kodu, ten folder nie zostanie utworzony. |
Możesz zmienić nazwy folderów lub zmienić strukturę tak, aby pasowała do przepływu pracy. Aby dodać nowy folder kodu źródłowego, wykonaj następujące kroki:
- Kliknij pozycję Dodaj w przeglądarce zasobów potoku.
- Kliknij pozycję Utwórz folder kodu źródłowego potoku.
- Wprowadź nazwę folderu i kliknij przycisk Utwórz.
Pliki kodu źródłowego
Pliki kodu źródłowego są częścią definicji kodu źródłowego potoku. Po uruchomieniu potoku te pliki są oceniane. Pliki i foldery, część definicji kodu źródłowego, mają specjalną ikonę z nałożoną ikoną mini potoku.
Aby dodać nowy plik kodu źródłowego:
- Kliknij obok folderu głównego.
- Kliknij Przekształcenie.
- Wprowadź nazwę pliku i wybierz pozycję Python lub SQL jako język.
- Kliknij pozycję Utwórz.
Użyj pomocników w tekście, aby rozpocząć pisanie kodu, korzystając z ![]() Genie Code, lub generować krótkie fragmenty kodu dla wybranego typu zbioru danych (na przykład widoku zmaterializowanego lub tabeli strumieniowej).
Genie Code, lub generować krótkie fragmenty kodu dla wybranego typu zbioru danych (na przykład widoku zmaterializowanego lub tabeli strumieniowej).
transformations Folder kodu źródłowego jest tworzony domyślnie podczas tworzenia nowego potoku. Ten folder jest zalecaną lokalizacją dla kodu źródłowego potoku, takiego jak pliki języka Python lub kodu SQL z definicjami tabeli potoku.
Pliki kodu innego niż źródłowy
Pliki inne niż kod źródłowy są przechowywane w folderze głównym potoku, ale nie są częścią definicji kodu źródłowego potoku. Te pliki nie są oceniane podczas uruchamiania potoku. Pliki kodu innego niż źródłowy nie mogą być plikami zewnętrznymi.
Możesz użyć tego w przypadku plików związanych z pracą nad pipeline, które chciałbyś przechowywać razem z kodem źródłowym. Przykład:
- Notatniki używane do eksploracji ad hoc wykonywanych na poza cyklem życia tych potoków w obliczeniach innych niż Deklaratywne Potoki Lakeflow Spark.
- Moduły języka Python, które nie mają być oceniane przy użyciu kodu źródłowego, chyba że jawnie zaimportujesz te moduły do plików kodu źródłowego.
Aby dodać nowy plik kodu innego niż źródłowy:
- Kliknij obok folderu głównego.
- Kliknij pozycję Eksploracja lub Narzędzie.
- Wprowadź nazwę pliku.
- Kliknij pozycję Utwórz.
Podczas tworzenia nowego potoku domyślnie tworzone są następujące foldery dla plików kodu innego niż źródłowy:
| Nazwa folderu | Description |
|---|---|
explorations |
Ten folder jest zalecaną lokalizacją dla notesów, zapytań, pulpitów nawigacyjnych i innych plików, do uruchamiania ich na zewnętrznych zasobach obliczeniowych Spark spoza cyklu życia potoków deklaratywnych Lakeflow. |
utilities |
Ten folder jest zalecaną lokalizacją modułów języka Python, które można zaimportować z innych plików za pośrednictwem bezpośrednich importów wyrażonych jako from <filename> import, o ile ich folder nadrzędny jest hierarchicznie w folderze głównym. |
Możesz również zaimportować moduły języka Python znajdujące się poza folderem głównym, ale w takim przypadku należy dołączyć ścieżkę folderu do sys.path w kodzie języka Python:
import sys, os
sys.path.append(os.path.abspath('<alternate_path_for_utilities>/utilities'))
from utils import \*
Pliki zewnętrzne
Sekcja Pliki zewnętrzne przeglądarki potoku pokazuje pliki kodu źródłowego znajdujące się poza folderem głównym.
Aby przenieść plik zewnętrzny do folderu głównego, takiego jak transformations folder, wykonaj następujące kroki:
- Kliknij dla pliku w przeglądarce zasobów i kliknij przycisk Przenieś.
- Wybierz folder, do którego chcesz przenieść plik, a następnie kliknij przycisk Przenieś.
Pliki skojarzone z wieloma rurami
Wskaźnik jest wyświetlany w nagłówku pliku, jeśli plik jest skojarzony z więcej niż jednym potokiem. Ma liczbę powiązanych potoków i umożliwia przełączanie się na inne potoki.
Sekcja Wszystkie pliki
Oprócz sekcji Potok znajduje się sekcja Wszystkie pliki , w której można otworzyć dowolny plik w obszarze roboczym. W tym miejscu możesz:
- Otwórz pliki poza folderem głównym na karcie bez opuszczania edytora potoków lakeflow.
- Przejdź do kodu źródłowego innego pipeline'u i otwórz go. Spowoduje to otwarcie pliku w edytorze i wyświetli pasek z opcją przełączenia fokusu w edytorze na ten drugi potok.
- Przenieś pliki do folderu głównego potoku.
- Uwzględnij pliki znajdujące się poza katalogiem głównym w definicji kodu źródłowego potoku.
Edytuj pliki źródłowe pipeline
Po otwarciu pliku źródłowego potoku z przeglądarki obszaru roboczego lub z przeglądarki zasobów potoku plik otwiera się na karcie edytora w Edytorze potoków Lakeflow. Otwieranie większej liczby plików otwiera oddzielne karty, co pozwala na edycję wielu plików jednocześnie.
Uwaga / Notatka
Otwarcie pliku, który nie jest skojarzony z potokiem z przeglądarki obszaru roboczego, spowoduje otwarcie edytora w innym kontekście (ogólny edytor obszaru roboczego lub, w przypadku plików SQL, Edytor SQL).
Po otwarciu pliku, który nie jest powiązany z potokiem, z karty Wszystkie pliki w przeglądarce zasobów potoku, plik zostanie otwarty na nowej karcie w kontekście potoku.
Kod źródłowy potoku zawiera wiele plików. Domyślnie pliki źródłowe znajdują się w folderze transformations w przeglądarce zasobów pipeline’u. Pliki kodu źródłowego mogą być plikami języka Python (*.py) lub SQL (*.sql). Źródło może zawierać kombinację zarówno plików Python, jak i SQL w jednym potoku, a kod w jednym pliku może odwoływać się do tabeli lub widoku zdefiniowanego w innym pliku.
Pliki markdown (*.md) można również uwzględnić w folderze transformations . Pliki Markdown mogą być używane do dokumentacji lub notatek, ale są ignorowane przy aktualizacji potoku.
Następujące funkcje są specyficzne dla edytora potoków Lakeflow:
Połącz: Połącz się z obliczeniami bezserwerowymi lub klasycznymi, aby uruchomić potok przetwarzania. Wszystkie pliki skojarzone z potokiem używają tego samego połączenia obliczeniowego, więc po nawiązaniu połączenia nie trzeba łączyć się z innymi plikami w tym samym potoku. Aby uzyskać więcej informacji na temat opcji obliczeniowych, zobacz Opcje konfiguracji obliczeniowej.
W przypadku plików innych niż potoki, takich jak notes eksploracyjny, opcja łączenia jest dostępna, ale dotyczy tylko tego pojedynczego pliku.
Uruchom plik: uruchom kod, aby zaktualizować tabele zdefiniowane w tym pliku źródłowym. W następnej sekcji opisano różne sposoby uruchamiania kodu potoku.
Edytuj: Użyj funkcji
Genie Code, aby edytować lub dodawać kod w pliku.Szybka poprawka: użyj
Genie Code, aby naprawić błędy lub wykorzystać sugestie w swoim kodzie.
Dolny panel jest również dostosowywany na podstawie bieżącej karty. Możliwość wyświetlania informacji o pipeline'u w dolnym panelu jest zawsze dostępna. Nieskojarzone z potokiem pliki, takie jak pliki edytora SQL, również wyświetlają swoje dane wyjściowe w dolnym panelu na osobnej karcie. Poniższa ilustracja przedstawia pionowy selektor kartowy do przełączania dolnego panelu między wyświetlaniem informacji o potoku a informacjami dla wybranego notatnika.
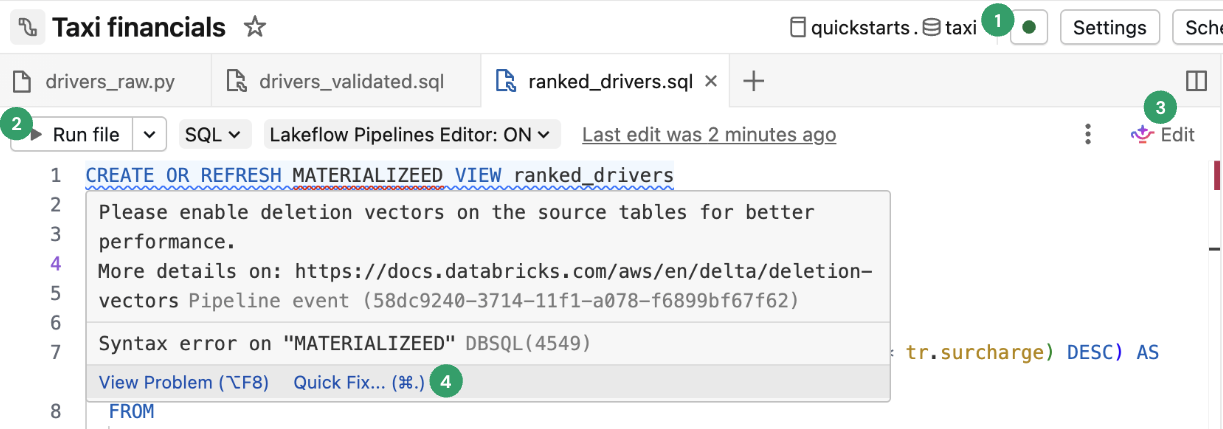
Uruchom kod potoku
Istnieją cztery opcje uruchamiania kodu potoku:
Uruchom wszystkie pliki kodu źródłowego w ramach potoku
Kliknij pozycję Uruchom potok lub Uruchom potok z pełnym odświeżaniem tabeli , aby uruchomić wszystkie definicje tabeli we wszystkich plikach zdefiniowanych jako kod źródłowy potoku. Aby uzyskać szczegółowe informacje na temat typów odświeżania, zobacz Semantyka odświeżania przepływu.
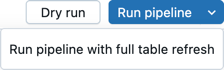
Możesz również kliknąć Próba na sucho, aby zweryfikować potok bez aktualizowania żadnych danych.
Uruchamianie kodu w jednym pliku
Kliknij pozycję Uruchom plik lub Uruchom plik z pełnym odświeżaniem tabeli , aby uruchomić wszystkie definicje tabeli w bieżącym pliku. Inne pliki w pipeline nie są oceniane.
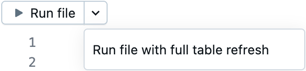
Ta opcja jest przydatna do debugowania podczas szybkiego edytowania i iteracji w pliku. Występują skutki uboczne tylko w przypadku uruchamiania kodu w jednym pliku.
- Jeśli inne pliki nie są oceniane, nie można odnaleźć błędów w tych plikach.
- Tabele zmaterializowane w innych plikach używają najnowszej materializacji tabeli, nawet jeśli istnieją nowsze dane źródłowe.
- Błędy mogą wystąpić, jeśli tabela, do której się odnosi, nie została jeszcze zmaterializowana.
- Wykres potoku może być niepoprawny lub niespójny w przypadku tabel z innych plików, które nie zostały zmaterializowane. Usługa Azure Databricks najlepiej stara się zachować poprawność grafu, ale nie ocenia innych plików, aby to zrobić.
Po zakończeniu debugowania i edytowania pliku usługa Databricks zaleca uruchomienie wszystkich plików kodu źródłowego w potoku, aby sprawdzić, czy potok działa kompleksowo przed umieszczeniem potoku w środowisku produkcyjnym.
Uruchamianie kodu dla pojedynczej tabeli
Obok definicji tabeli w pliku kodu źródłowego kliknij ikonę Uruchom tabelę
 , a następnie wybierz pozycję Odśwież tabelę lub Pełne odświeżenie tabeli z listy rozwijanej. Uruchomienie kodu dla pojedynczej tabeli ma podobne skutki uboczne jak uruchomienie kodu w jednym pliku.
, a następnie wybierz pozycję Odśwież tabelę lub Pełne odświeżenie tabeli z listy rozwijanej. Uruchomienie kodu dla pojedynczej tabeli ma podobne skutki uboczne jak uruchomienie kodu w jednym pliku.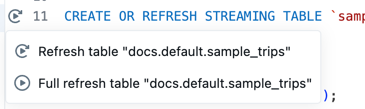
Uwaga / Notatka
Uruchamianie kodu dla pojedynczej tabeli jest dostępne dla tabel przesyłania strumieniowego i zmaterializowanych widoków. Ujścia i widoki nie są obsługiwane.
Uruchamianie kodu dla zestawu tabel
Możesz wybrać tabele na wykresie potoku, aby utworzyć listę tabel do uruchomienia. Najedź kursorem na tabelę na grafie potoku, kliknij
, a następnie wybierz Wybierz tabelę do odświeżenia. Po wybraniu tabel do odświeżenia wybierz opcję Uruchom lub Uruchom z pełnym odświeżaniem w dolnej części wykresu potoku.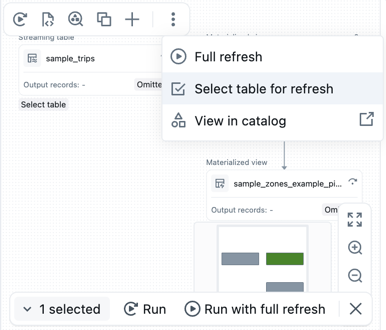
Uruchamianie wybranego kodu
Wyróżnij kod SQL i kliknij pozycję Uruchom wybrany kod , aby szybko sprawdzić dane wyjściowe bez materializowania danych. Dane wyjściowe są wyświetlane na karcie Wyniki zapytania w dolnym panelu.
Wykres potoku
Po uruchomieniu lub zweryfikowaniu wszystkich plików kodu źródłowego w potoku zobaczysz graf potoku, nazywany również skierowanym grafem acyklicznym (DAG). Wykres przedstawia wykres zależności tabeli. Każdy węzeł ma różne stany wzdłuż cyklu życia potoku, takie jak zweryfikowane, uruchomione lub błąd.
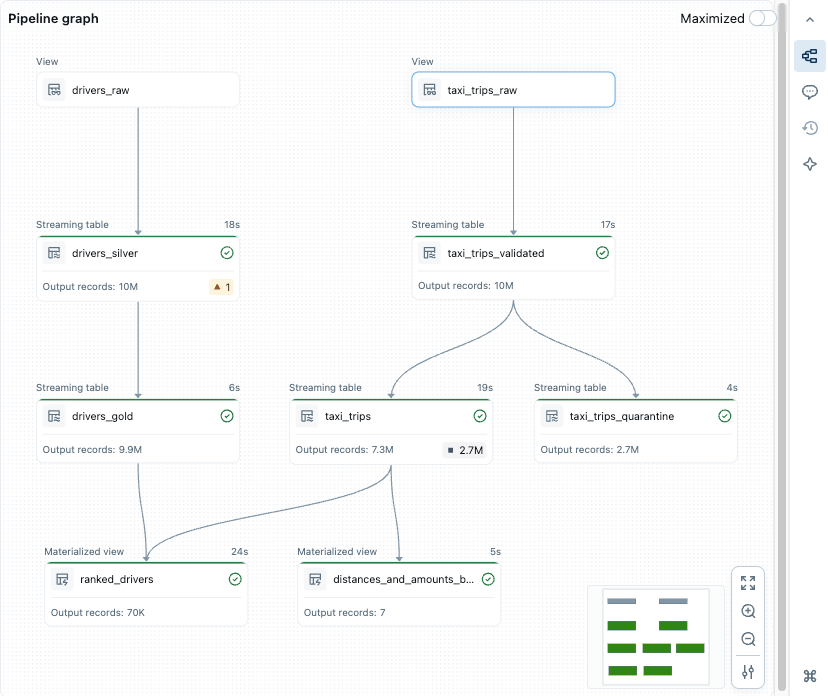
- Wykres potoku: otwórz graf, klikając kartę Wykres potoku w dolnym panelu.
- Węzły: Wyświetla zależności tabel, które są częścią potoku przetwarzania, a także wszystkie metryki z nimi powiązane. Węzły będące częścią aktualnie otwartych plików są wyróżnione na wykresie potoku. Umieszczenie kursora na węźle powoduje wyświetlenie paska narzędzi z opcjami, w tym odświeżenie zapytania. Kliknięcie prawym przyciskiem myszy węzła daje te same opcje w menu kontekstowym. Kliknięcie węzła spowoduje wyświetlenie podglądu danych i definicji tabeli. Podczas edytowania pliku tabele zdefiniowane w tym pliku są wyróżnione na grafie.
- Otwórz na karcie: Aby zmaksymalizować wykres, wybierz ikonę w prawym górnym rogu panelu dolnego, aby otworzyć go na osobnej karcie.
- Więcej opcji: Dodatkowe opcje znajdują się w prawym dolnym rogu, w tym opcje powiększenia i Więcej opcji wyświetlania wykresu w układzie pionowym lub poziomym.
Podglądy danych
Sekcja podglądu danych zawiera przykładowe dane dla wybranej tabeli.
Po kliknięciu węzła na wykresie potoku zobaczysz podgląd danych tej tabeli. Aby przejść do podglądu danych innej tabeli bezpośrednio w dolnym panelu, wybierz pozycję Wstecz do grafu lub kliknij inny węzeł, jeśli wykres potoku jest otwarty na osobnej karcie.
Alternatywnie przejdź do sekcji Tabele i kliknij pozycję Wyświetl podgląd danych![]() . Jeśli wybrano tabelę, kliknij pozycję Wszystkie tabele , aby powrócić do wszystkich tabel.
. Jeśli wybrano tabelę, kliknij pozycję Wszystkie tabele , aby powrócić do wszystkich tabel.
Można filtrować lub sortować dane tabeli bezpośrednio podczas podglądu. Jeśli chcesz wykonać bardziej złożoną analizę, możesz użyć lub utworzyć notes w folderze Explorations (przy założeniu, że zachowana jest domyślna struktura folderów). Domyślnie kod źródłowy w tym folderze nie jest uruchamiany podczas aktualizowania potoku, więc można tworzyć zapytania bez wpływu na dane wyjściowe potoku.
Analizy wykonania
Szczegółowe informacje dotyczące wykonywania tabeli dotyczące najnowszej aktualizacji potoku można wyświetlić w panelach u dołu edytora.
| Panel | Description |
|---|---|
| Tables | Wyświetla listę wszystkich tabel ze stanami i metrykami. Jeśli wybierzesz jedną tabelę, zobaczysz metryki i wydajność dla tej tabeli oraz kartę podglądu danych. |
| Performance | Historia zapytań i profile dla wszystkich przepływów w tym potoku. Możesz uzyskać dostęp do metryk wykonywania i szczegółowych planów zapytań podczas wykonywania i po jego wykonaniu. Aby uzyskać więcej informacji , zobacz Access query history for pipelines (Historia zapytań programu Access dla potoków ). |
| Panel problemów | Kliknij panel, aby wyświetlić uproszczony widok błędów, ostrzeżeń i informacji diagnostycznych dotyczących potoku. Kliknij wpis, aby wyświetlić więcej szczegółów, a następnie przejdź do miejsca w kodzie, w którym wystąpił błąd. Jeśli błąd znajduje się w pliku innym niż aktualnie wyświetlany, spowoduje to przekierowanie do pliku, w którym występuje błąd. Kliknij pozycję Wyświetl szczegóły , aby wyświetlić odpowiedni wpis dziennika zdarzeń, aby uzyskać szczegółowe informacje. Kliknij pozycję Wyświetl dzienniki , aby wyświetlić pełny dziennik zdarzeń. Kliknij pozycję Diagnozuj błąd, aby zdiagnozować problem za pomocą Wskaźniki błędu umieszczone w kodzie są wyświetlane w przypadku błędów skojarzonych z określoną częścią kodu. Aby uzyskać więcej szczegółów, kliknij ikonę błędu lub umieść kursor nad czerwoną linią. Zostanie wyświetlone wyskakujące okienko z większą ilością informacji. Następnie możesz kliknąć pozycję Szybka poprawka , aby wyświetlić zestaw akcji, aby rozwiązać problem z błędem. |
| Dziennik zdarzeń | Wszystkie zdarzenia wyzwalane podczas ostatniego uruchomienia potoku. Kliknij pozycję Wyświetl dzienniki lub dowolny wpis na pasku problemów. |
Konfiguracja rurociągu
Potok można skonfigurować z poziomu edytora potoków. Możesz wprowadzić zmiany w ustawieniach potoku, harmonogramie lub uprawnieniach.
Do każdego z nich można uzyskać dostęp za pomocą przycisku w nagłówku edytora lub ikon w przeglądarce elementów zawartości (lewym pasku bocznym).
Ustawienia (lub wybierz
 w przeglądarce zasobów):
w przeglądarce zasobów):Ustawienia potoku można edytować na panelu ustawień, w tym ogólne informacje, folder główny i konfigurację kodu źródłowego, konfigurację obliczeniową, powiadomienia, ustawienia zaawansowane i inne.
Zaplanuj (lub wybierz
 w przeglądarce elementów zawartości):
w przeglądarce elementów zawartości):W oknie dialogowym harmonogramu można utworzyć jeden lub więcej harmonogramów dla procesu przetwarzania. Jeśli na przykład chcesz uruchomić go codziennie, możesz ustawić to tutaj. Tworzy zadanie do uruchomienia potoku zgodnie z wybranym harmonogramem. Możesz dodać nowy harmonogram lub usunąć istniejący harmonogram z okna dialogowego harmonogramu.
Udostępnij (lub z
w przeglądarce zasobów wybierz  ):
):Można zarządzać uprawnieniami w potoku dla użytkowników i grup w oknie dialogowym uprawnień potoku.
Dziennik zdarzeń
Możesz opublikować dziennik zdarzeń dla potoku danych w wykazie Unity Catalog. Domyślnie dziennik zdarzeń potoku danych jest wyświetlany w interfejsie użytkownika i dostępny dla właściciela do wykonywania zapytań.
- Otwórz Ustawienia.
- Kliknij
 obok pozycji Ustawienia zaawansowane.
obok pozycji Ustawienia zaawansowane. - Kliknij pozycję Edytuj ustawienia zaawansowane.
- W obszarze Dzienniki zdarzeń kliknij pozycję Publikuj w katalogu.
- Podaj nazwę, wykaz i schemat dziennika zdarzeń.
- Kliknij przycisk Zapisz.
Zdarzenia twojego potoku są publikowane do tabeli, którą określiłeś.
Aby dowiedzieć się więcej informacji na temat korzystania z dziennika zdarzeń, zobacz Zapytania w dzienniku zdarzeń.
Środowisko potoku
Środowisko dla kodu źródłowego można utworzyć, dodając zależności w obszarze Ustawienia.
- Otwórz Ustawienia.
- W obszarze Środowisko potoku kliknij pozycję Edytuj środowisko.
- Kliknij pozycję Dodaj zależność , aby dodać zależność, tak jak w przypadku dodawania jej do
requirements.txtpliku. Aby uzyskać więcej informacji na temat zależności, zobacz Dodawanie zależności do notesu.
Databricks zaleca przypięcie wersji za pomocą ==. Zobacz pakiet PyPI.
Środowisko ma zastosowanie do wszystkich plików kodu źródłowego w potoku.
Powiadomienia
Powiadomienia można dodawać za pomocą ustawień potoku.
- Otwórz Ustawienia.
- W sekcji Powiadomienia kliknij pozycję Dodaj powiadomienie.
- Dodaj co najmniej jeden adres e-mail i wskaż zdarzenia, na które chcesz je wysyłać.
- Kliknij pozycję Dodaj powiadomienie.
Uwaga / Notatka
Utwórz niestandardowe odpowiedzi na zdarzenia, w tym powiadomienia lub obsługę niestandardową, przy użyciu hooków zdarzeń w języku Python.
Monitorowanie potoków
Usługa Azure Databricks udostępnia również funkcje do monitorowania działających pipeline'ów. W edytorze są wyświetlane wyniki i informacje o wykonaniu dotyczące ostatniego przebiegu. Jest zoptymalizowany pod kątem ułatwiania wydajnego iterowania podczas interaktywnego opracowywania potoku.
Strona monitorowania potoku danych umożliwia wyświetlanie przebiegów historycznych, co jest przydatne, gdy potok danych jest uruchamiany zgodnie z harmonogramem przy użyciu zadania typu Job.
Uwaga / Notatka
Istnieje domyślne środowisko monitorowania i zaktualizowane środowisko monitorowania w wersji zapoznawczej. W poniższej sekcji opisano sposób włączania lub wyłączania środowiska monitorowania w wersji zapoznawczej. Aby uzyskać informacje o obu środowiskach, zobacz Monitorowanie potoków w interfejsie użytkownika.
Funkcja monitorowania jest dostępna za pomocą przycisku Zadania i potoki po lewej stronie obszaru roboczego. Możesz również przejść bezpośrednio do strony monitorowania z poziomu edytora, klikając wyniki uruchomienia w przeglądarce zasobów potoku.
Aby uzyskać więcej informacji na temat strony monitorowania, zobacz Monitorowanie potoków w interfejsie użytkownika. Interfejs użytkownika monitorowania zawiera możliwość powrotu do edytora potoków Lakeflow, wybierając pozycję Edytuj potoki z nagłówka interfejsu użytkownika.
Agent inżynierii danych
Ważne
Ta funkcja jest dostępna w publicznej wersji testowej.
Edytor Potoków Lakeflow integruje się z agentem inżynierii danych Genie Code, który może generować, modyfikować i debugować całe Deklaratywne Potoki Spark Lakeflow bezpośrednio z języka naturalnego. Aby uzyskać więcej informacji, zobacz Use Genie Code for pipeline development (Używanie kodu Genie na potrzeby opracowywania potoków).
Ograniczenia i znane problemy
Zapoznaj się z następującymi ograniczeniami i znanymi problemami dotyczącymi edytora potoków ETL w usłudze Lakeflow Spark Deklaratywne potoki:
Pasek boczny przeglądarki obszaru roboczego nie koncentruje się na potoku, jeśli rozpoczynasz od otwarcia pliku w
explorationsfolderze lub notesie, ponieważ te pliki lub notesy nie są częścią definicji kodu źródłowego potoku.Aby wprowadzić tryb koncentracji przepływu danych w oknie obszaru roboczego, otwórz plik skojarzony z przepływem danych.
Podglądy danych nie są obsługiwane w przypadku standardowych widoków.
Modułów języka Python nie można odnaleźć w ramach UDF, nawet jeśli znajdują się w folderze głównym lub na
sys.path. Dostęp do tych modułów można uzyskać, dołączając ścieżkę dosys.pathobiektu z poziomu funkcji zdefiniowanej przez użytkownika, na przykład:sys.path.append(os.path.abspath(“/Workspace/Users/path/to/modules”))%pip installnie jest obsługiwany jako źródło plików (domyślny typ elementu w nowym edytorze). Zależności można dodawać w ustawieniach. Zobacz Środowisko potoku.Alternatywnie możesz nadal używać
%pip installz notesu skojarzonego z potokiem w definicji kodu źródłowego.
Często zadawane pytania
Dlaczego warto używać plików, a nie notesów dla kodu źródłowego?
Wykonywanie notatników opartych na komórkach nie jest zgodne z pipeline'ami. Standardowe funkcje notebooków są wyłączane lub zmieniane podczas pracy z potokami, co powoduje zamieszanie wśród użytkowników zaznajomionych z zachowaniem notebooków.
W Edytorze potoków Lakeflow edytor plików jest używany jako podstawa dla edytora wysokiej klasy do potoków. Funkcje są przeznaczone wyraźnie do potoków, takich jak Run Table Iconikona tabeli uruchamiania, zamiast przeciążać znane funkcje różnymi zachowaniami.
Czy nadal mogę używać notesów jako kodu źródłowego?
Tak, możesz. Jednak niektóre funkcje, takie jak Uruchom tabelę
lub Uruchom plik, nie są obecne.Jeśli masz istniejący pipeline z użyciem notesów, nadal będzie działać w nowym edytorze. Jednak usługa Databricks zaleca przejście na użycie plików w nowych potokach danych.
Jak mogę dodać istniejący kod do nowo utworzonego pipeline'u?
Istniejące pliki kodu źródłowego można dodać do nowego potoku. Aby dodać folder z istniejącymi plikami, wykonaj następujące kroki:
- Kliknij przycisk Ustawienia.
- W obszarze Kod źródłowy kliknij pozycję Konfiguruj ścieżki.
- Kliknij pozycję Dodaj ścieżkę i wybierz folder dla istniejących plików.
- Kliknij przycisk Zapisz.
Można również dodać poszczególne pliki:
- Kliknij Wszystkie pliki w przeglądarce zasobów pipeline’u.
- Przejdź do pliku, kliknij , a następnie kliknij Uwzględnij w potoku.
Rozważ przeniesienie tych plików do folderu głównego potoku. Jeśli są pozostawione poza folderem głównym potoku danych, zostaną one wyświetlone w sekcji Pliki zewnętrzne.
Czy mogę zarządzać kodem źródłowym Pipeline w systemie kontroli wersji Git?
Źródło potoku można zarządzać w usłudze Git, wybierając folder Git podczas początkowego tworzenia potoku.
Uwaga / Notatka
Zarządzanie źródłem w folderze Git dodaje kontrolę wersji dla kodu źródłowego. Jednak aby kontrolować wersję konfiguracji, firma Databricks zaleca używanie Deklaratywnych Pakietów Automatyzacji w celu zdefiniowania konfiguracji potoku w plikach konfiguracji pakietu, które mogą być przechowywane w Git (lub innym systemie kontroli wersji). Aby uzyskać więcej informacji, zobacz Co to są pakiety deklaratywne automatyzacji?.
Jeśli nie utworzyłeś pipeline'u początkowo w środowisku Git, możesz przenieść swoje źródło do folderu Git. Usługa Databricks zaleca użycie akcji edytora w celu przeniesienia całego folderu głównego do folderu Git. Spowoduje to odpowiednie zaktualizowanie wszystkich ustawień. Zobacz Folder główny.
Aby przenieść folder główny do folderu Git w przeglądarce zasobów potoku:
- Kliknij w folderze głównym.
- Kliknij pozycję Przenieś folder główny.
- Wybierz nową lokalizację folderu głównego i kliknij przycisk Przenieś.
Aby uzyskać więcej informacji, zobacz sekcję Folder główny .
Po przeniesieniu obok nazwy folderu głównego zostanie wyświetlona znana ikona git.
Ważne
Aby przenieść folder główny potoku, użyj przeglądarki zasobów potoku i wykonaj powyższe kroki. Przeniesienie go w inny sposób zakłóca konfiguracje potoku i należy ręcznie skonfigurować poprawną ścieżkę folderu w Settings.
- Kliknij
Czy mogę mieć wiele pipeline'ów w tym samym folderze głównym?
Możesz, ale usługa Databricks zaleca używanie tylko jednego potoku na folder główny.
Kiedy należy przeprowadzić próbę testową?
Kliknij pozycję Suche uruchomienie , aby sprawdzić kod bez aktualizowania tabel.
Kiedy należy używać widoków tymczasowych i kiedy należy używać zmaterializowanych widoków w kodzie?
Użyj widoków tymczasowych, gdy nie chcesz materializować danych. Na przykład jest to krok w sekwencji kroków przygotowywania danych przed przygotowaniem ich do zmaterializowania przy użyciu tabeli przesyłania strumieniowego lub zmaterializowanego widoku zarejestrowanego w wykazie.