Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W usłudze Azure Databricks możesz kontrolować potok i cały skojarzony z nim kod. Dzięki kontroli wersji wszystkich plików związanych z pipeline, zmiany w kodzie przekształcania, kodzie eksploracji i konfiguracji pipeline są wersjonowane w Git i mogą być testowane w środowisku deweloperskim oraz z powodzeniem wdrażane w środowisku produkcyjnym.
Potok kontrolowany przez źródło oferuje następujące korzyści:
- Możliwość śledzenia: przechwyć każdą zmianę w historii Git.
- Testowanie: zweryfikuj zmiany potoku w obszarze roboczym deweloperskim przed przeniesieniem do udostępnionego produkcyjnego obszaru roboczego. Każdy deweloper ma własny potok programowania we własnej gałęzi kodu w folderze Git i we własnym schemacie.
- Współpraca: po zakończeniu tworzenia i testowania zmiany kodu są przesyłane do głównego ciągu produkcyjnego.
- Zarządzanie: Dostosowanie do standardów ciągłej integracji, ciągłego wdrażania i wdrażania w przedsiębiorstwie.
Usługa Azure Databricks umożliwia sterowanie potokami i ich plikami źródłowymi razem przy użyciu pakietów deklaratywnych automatyzacji. W przypadku pakietów konfiguracja potoku jest kontrolowana przez źródło w postaci plików konfiguracji YAML wraz z plikami źródłowymi języka Python lub SQL potoku. Jeden pakiet danych może mieć jeden lub wiele potoków, a także inne rodzaje zasobów, takie jak zadania.
Na tej stronie przedstawiono sposób konfigurowania potoku kontrolowanego przez źródło przy użyciu pakietów deklaratywnej automatyzacji (wcześniej nazywanych pakietami zasobów usługi Databricks). Aby uzyskać więcej informacji na temat pakietów, zobacz Co to są pakiety deklaratywne automatyzacji?.
Requirements
Aby utworzyć potok kontrolowany przez źródło, musisz mieć już następujące elementy:
- Folder Git utworzony w obszarze roboczym i skonfigurowany. Folder Git umożliwia poszczególnym użytkownikom tworzenie i testowanie zmian przed zatwierdzeniem ich w repozytorium Git. Zobacz Foldery git usługi Azure Databricks.
- Edytor potoków Lakeflow. Więcej informacji znajdziesz w sekcji Tworzenie i debugowanie potoków ETL w edytorze Lakeflow Pipelines.
- Aby uzyskać pełny zestaw uprawnień wymaganych do tworzenia, uruchamiania, odświeżania i wyświetlania potoków oraz ich danych wyjściowych, zobacz Zarządzanie tożsamościami, uprawnieniami i uprawnieniami dla potoków.
Utwórz nowy pipeline w pakiecie
Uwaga / Notatka
Usługa Databricks zaleca utworzenie potoku kontrolowanego przez źródło od samego początku. Alternatywnie możesz dodać istniejący potok do pakietu, który jest już kontrolowany przez źródło. Zobacz Migrowanie istniejących zasobów do pakietu.
Aby utworzyć nowy potok kontrolowany przez źródło:
W górnej części paska bocznego kliknij
 Nowy, następnie wybierz
Nowy, następnie wybierz  Potok ETL.
Potok ETL.Wprowadź dowolne zmiany w nazwie potoku lub schemacie. Zobacz Tworzenie nowego potoku ETL.
Kliknij menu
 (po prawej stronie przycisku
(po prawej stronie przycisku  Użyj przykładowego kodu) i wybierz
Użyj przykładowego kodu) i wybierz  Skonfiguruj jako kontrolowane przez system kontroli źródła.
Skonfiguruj jako kontrolowane przez system kontroli źródła.Kliknij pozycję Utwórz nowy projekt, a następnie wybierz folder Git, w którym chcesz umieścić kod i konfigurację:
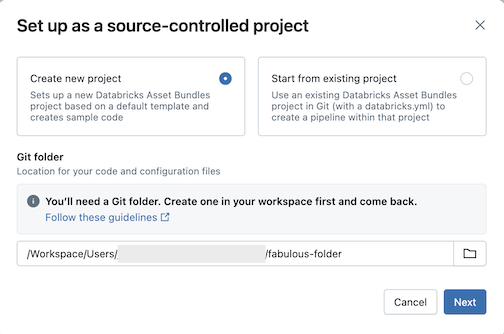
Kliknij przycisk Dalej.
Wprowadź następujące informacje w oknie dialogowym Tworzenie pakietu zasobów :
- Nazwa pakietu: nazwa pakietu.
- Katalog początkowy: nazwa wykazu, który zawiera schemat do użycia.
- Użyj schematu osobistego: Zostaw to pole zaznaczone, jeśli chcesz izolować zmiany do osobistego schematu, aby użytkownicy w Twojej organizacji mogli współpracować nad tym samym projektem bez nadpisywania nawzajem swoich zmian w środowisku deweloperskim.
- Język początkowy: język stosowany do przykładowych plików potoku projektu, Python lub SQL.
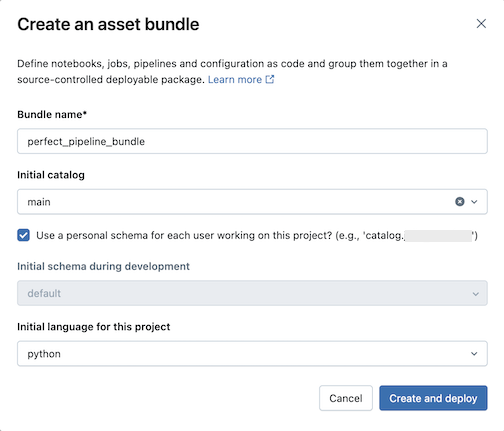
Kliknij pozycję Utwórz i wdróż. Tworzony jest pakiet z pipeline w folderze repozytorium Git.
Eksplorowanie pakietu potoku
Następnie zapoznaj się z utworzonym pakietem potoku danych.
Pakiet, który znajduje się w folderze Git, zawiera pliki systemowe pakietu i databricks.yml plik, który definiuje zmienne, docelowe adresy URL obszaru roboczego i uprawnienia oraz inne ustawienia pakietu. Ponieważ databricks.yml znajduje się w katalogu głównym pakietu (nadrzędnym katalogu głównego potoku), przejdź do karty Wszystkie pliki w przeglądarce elementów zawartości potoku, aby go wyświetlić. Folder resources w pakiecie zawiera definicje zasobów, takich jak potoki i zadania.
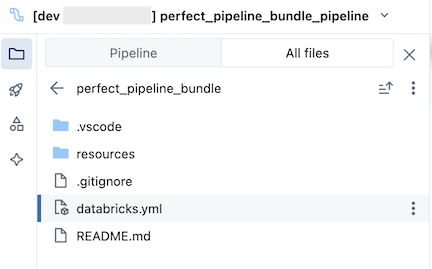
resources Otwórz folder, a następnie kliknij przycisk edytora potoków, aby wyświetlić potok kontrolowany przez źródło:
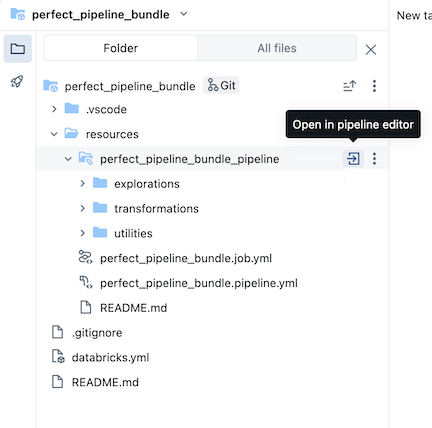
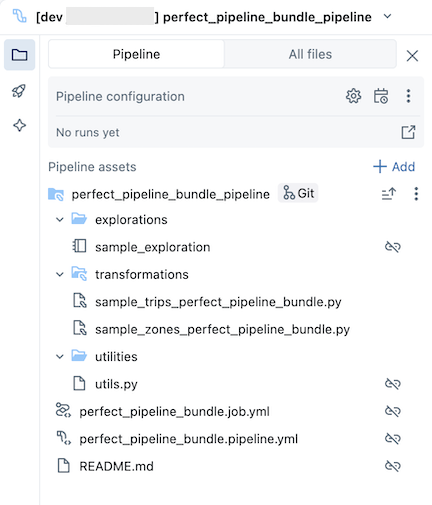
Przykładowy pakiet potoku zawiera następujące pliki:
Przykładowy notatnik eksploracyjny
Dwa przykładowe pliki kodu, które wykonują przekształcenia w tabelach
Przykładowy plik kodu zawierający funkcję narzędzia
Plik YAML konfiguracji zadania, który definiuje zadanie w pakiecie, w ramach którego jest uruchamiany potok
Plik YAML konfiguracji potoku opisujący działanie potoku
Ważne
Należy edytować ten plik, aby trwale zapisać wszelkie zmiany konfiguracji potoku, w tym zmiany wprowadzone w interfejsie użytkownika, w przeciwnym razie zmiany interfejsu użytkownika są nadpisywane po ponownym wdrożeniu pakietu. Aby na przykład ustawić inny domyślny katalog dla rurociągu, zmodyfikuj
catalogpole w tym pliku konfiguracyjnym.Plik README z dodatkowymi szczegółami dotyczącymi przykładowego pakietu potoku i instrukcjami dotyczącymi uruchamiania potoku
Informacje o plikach potoków przetwarzania znajdziesz w Przeglądarce zasobów potoków przetwarzania.
Aby uzyskać więcej informacji na temat tworzenia i wdrażania zmian w pakiecie rurociągu, zobacz Tworzenie pakietów w obszarze roboczym oraz Wdrażanie pakietów i uruchamianie przepływów z obszaru roboczego.
Uruchamianie potoku
Można uruchomić pojedyncze przekształcenia lub cały potok kontrolowany przez źródło:
- Aby uruchomić i wyświetlić podgląd pojedynczej transformacji w potoku, wybierz plik przekształcenia w drzewie przeglądarki obszaru roboczego, aby otworzyć go w edytorze plików. W górnej części pliku w edytorze kliknij przycisk Uruchom odtwarzanie pliku .
- Aby uruchomić wszystkie przekształcenia w potoku, kliknij na przycisk Uruchom potok w prawym górnym rogu obszaru roboczego usługi Databricks.
Aby uzyskać więcej informacji na temat uruchamiania potoków, zobacz Run pipeline code (Uruchamianie kodu potoku).
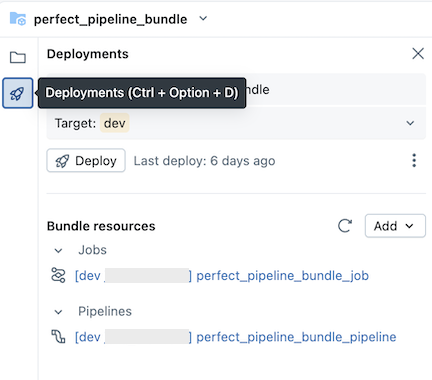
Zaktualizuj potok
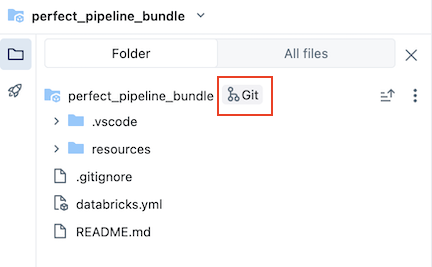
Możesz zaktualizować artefakty w pipeline lub dodać dodatkowe eksploracje i przekształcenia, ale następnie będziesz chciał opublikować te zmiany na GitHub. Kliknij ![]() Ikona git skojarzona z pakietem potoku lub kliknij kebab dla folderu, a następnie git... , aby wybrać zmiany do wypchnięcia. Zobacz Zatwierdzanie i wypychanie zmian.
Ikona git skojarzona z pakietem potoku lub kliknij kebab dla folderu, a następnie git... , aby wybrać zmiany do wypchnięcia. Zobacz Zatwierdzanie i wypychanie zmian.
Ponadto podczas aktualizowania plików konfiguracji potoku lub dodawania lub usuwania plików z pakietu te zmiany nie są propagowane do docelowego obszaru roboczego do momentu jawnego wdrożenia pakietu. Zobacz Wdrażanie pakietów i uruchamianie przepływów pracy z obszaru roboczego.
Uwaga / Notatka
Usługa Databricks zaleca zachowanie domyślnej konfiguracji dla potoków kontrolowanych przez źródło. Domyślna konfiguracja jest ustawiona tak, że nie trzeba edytować konfiguracji YAML pakietu procesów po dodaniu dodatkowych plików za pośrednictwem interfejsu użytkownika.
Dodaj istniejący potok do pakietu
Aby dodać istniejący potok do pakietu, najpierw utwórz pakiet w obszarze roboczym, a następnie dodaj definicję YAML potoku do pakietu zgodnie z opisem na następujących stronach:
- Samouczek: tworzenie i wdrażanie pakietu w obszarze roboczym
- Dodawanie istniejącego zasobu do pakietu
Aby uzyskać informacje na temat migrowania zasobów do pakietu przy użyciu interfejsu wiersza polecenia usługi Databricks, zobacz Migrowanie istniejących zasobów do pakietu.
Dodatkowe zasoby
Aby uzyskać dodatkowe samouczki i materiały referencyjne dotyczące potoków, zobacz Spark Declarative Pipelines (Potoki deklaratywne platformy Spark).