Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Autoskalowanie bazy danych Lakebase to najnowsza wersja bazy danych Lakebase, która umożliwia skalowanie automatyczne, skalowanie do zera, rozgałęzianie i natychmiastowe przywracanie. Aby uzyskać informacje o obsługiwanych regionach, zobacz Dostępność regionów. Jeśli jesteś użytkownikiem usługi Lakebase Provisioned, zobacz Lakebase Provisioned.
W tym przewodniku pokazano, jak połączyć aplikacje zewnętrzne z rozwiązaniem Lakebase Autoscaling przy użyciu standardowych sterowników Postgres (psycopg, pgx, JDBC) z rotacją tokenów OAuth. Zestaw SDK usługi Azure Databricks jest używany z jednostką usługi i pulą połączeń, która wywołuje generate_database_credential() podczas otwierania każdego nowego połączenia, dzięki czemu uzyskujesz nowy token (okres istnienia 60 minut) za każdym razem, gdy nawiązujesz połączenie. Przykłady są dostępne dla języków Python, Java i Go. Aby ułatwić konfigurację za pomocą automatycznego zarządzania poświadczeniami, rozważ zamiast tego usługę Azure Databricks Apps .
Co utworzysz: Wzorzec połączenia, który używa rotacji tokenów OAuth do nawiązywania połączenia z usługą Lakebase Autoscaling z aplikacji zewnętrznej, a następnie sprawdź, czy połączenie działa.
Potrzebny jest zestaw SDK usługi Databricks (Python v0.89.0+, Java v0.73.0+lub Go v0.109.0+). Wykonaj następujące kroki w następującej kolejności:
:::wskazówka Inne języki Dla języków bez wsparcia SDK Databricks (Node.js, Ruby, PHP, Elixir, Rust), zobacz Connect external app to Lakebase using API. :::
Jak to działa
Zestaw SDK usługi Databricks upraszcza uwierzytelnianie OAuth, automatycznie obsługując zarządzanie tokenami obszaru roboczego:
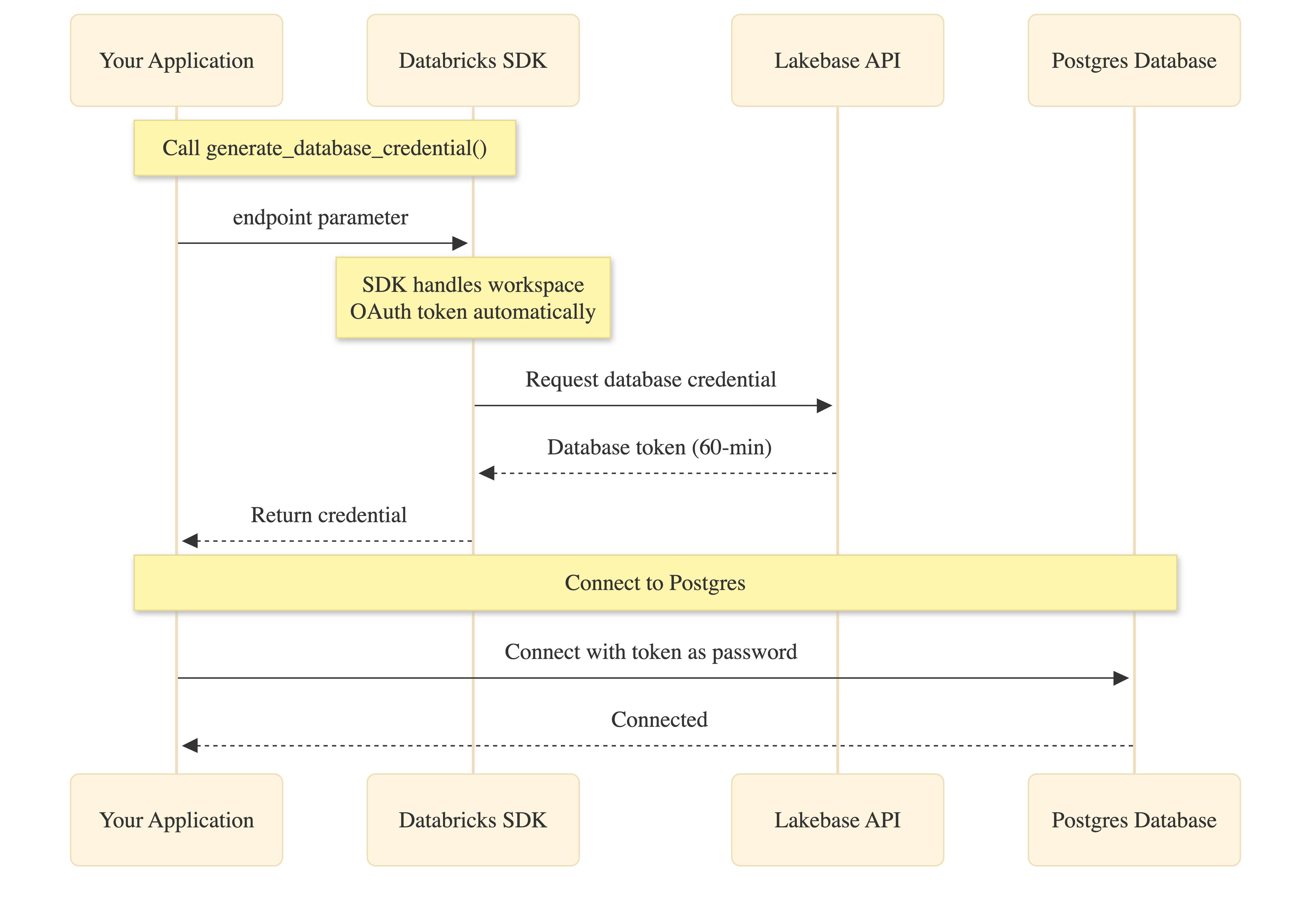
Twoja aplikacja wywołuje generate_database_credential() z parametrem punktu końcowego. SDK uzyskuje wewnętrznie token OAuth przestrzeni roboczej (bez wymaganego kodu), żąda poświadczeń bazy danych z interfejsu API Lakebase i zwraca je do twojej aplikacji. Następnie użyjesz tego poświadczenia jako hasła podczas nawiązywania połączenia z usługą Postgres.
Zarówno token OAuth obszaru roboczego, jak i poświadczenia bazy danych wygasają po 60 minutach. Pule połączeń obsługują automatyczne odświeżanie przez wywołanie generate_database_credential() podczas tworzenia nowych połączeń.
1. Stwórz service principal przy użyciu wpisu tajnego OAuth
Utwórz obiekt zasad dostępu Azure Databricks z sekretem OAuth. Pełne szczegóły znajdują się w temacie Autoryzowanie dostępu jednostki usługi. W przypadku tworzenia aplikacji zewnętrznej należy pamiętać o:
- Ustaw swój sekret na preferowany czas życia, maksymalnie 730 dni. Określa to, jak często należy odświeżyć tajny klucz, który jest używany do generowania tych poświadczeń bazy danych za pomocą rotacji.
-
Włącz opcję "Dostęp do obszaru roboczego" dla jednostki usługi (Ustawienia → Tożsamość i dostęp → Jednostki usługi →
{name}→ karta Konfiguracji). Jest to wymagane do generowania nowych poświadczeń bazy danych. -
Zanotuj identyfikator klienta (UUID). Używasz go podczas tworzenia pasującej roli Postgres w konfiguracji aplikacji oraz dla
PGUSER.
2. Tworzenie roli Postgres dla jednostki usługi
Interfejs użytkownika usługi Lakebase obsługuje tylko role oparte na hasłach. Utwórz rolę OAuth w edytorze SQL Lakebase przy użyciu identyfikatora klienta z kroku 1 (nie używaj nazwy wyświetlanej; nazwa roli rozróżnia wielkość liter):
-- Enable the auth extension (if not already enabled)
CREATE EXTENSION IF NOT EXISTS databricks_auth;
-- Create OAuth role using the service principal client ID
SELECT databricks_create_role('{client-id}', 'SERVICE_PRINCIPAL');
-- Grant database permissions
GRANT CONNECT ON DATABASE databricks_postgres TO "{client-id}";
GRANT USAGE ON SCHEMA public TO "{client-id}";
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO "{client-id}";
ALTER DEFAULT PRIVILEGES IN SCHEMA public
GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO "{client-id}";
Zastąp {client-id} identyfikatorem klienta głównego użytkownika usługi. Zobacz Tworzenie ról OAuth.
3. Uzyskiwanie szczegółów połączenia
W projekcie w konsoli lakebase kliknij pozycję Połącz, wybierz gałąź i punkt końcowy, a następnie zanotuj host, bazę danych (zazwyczaj databricks_postgres) i nazwę punktu końcowego (format: projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>).
Użyj CLI:
databricks postgres list-endpoints projects/<project-id>/branches/<branch-id>
Aby uzyskać szczegółowe informacje, zobacz Parametry połączenia .
4. Ustawianie zmiennych środowiskowych
Przed uruchomieniem aplikacji ustaw następujące zmienne środowiskowe:
# Databricks workspace authentication
export DATABRICKS_HOST="https://your-workspace.databricks.com"
export DATABRICKS_CLIENT_ID="<service-principal-client-id>"
export DATABRICKS_CLIENT_SECRET="<your-oauth-secret>"
# Lakebase connection details (from step 3)
export ENDPOINT_NAME="projects/<project-id>/branches/<branch-id>/endpoints/<endpoint-id>"
export PGHOST="<endpoint-id>.database.<region>.cloud.databricks.com"
export PGDATABASE="databricks_postgres"
export PGUSER="<service-principal-client-id>" # Same UUID as step 1
export PGPORT="5432"
export PGSSLMODE="require" # Python only
5. Dodawanie kodu połączenia
Python
W tym przykładzie użyto narzędzia psycopg3 z niestandardową klasą połączenia, która generuje nowy token, gdy pula tworzy każde nowe połączenie.
import os
from databricks.sdk import WorkspaceClient
import psycopg
from psycopg_pool import ConnectionPool
# Initialize Databricks SDK
workspace_client = None
def _get_workspace_client():
"""Get or create the workspace client for OAuth."""
global workspace_client
if workspace_client is None:
workspace_client = WorkspaceClient(
host=os.environ["DATABRICKS_HOST"],
client_id=os.environ["DATABRICKS_CLIENT_ID"],
client_secret=os.environ["DATABRICKS_CLIENT_SECRET"],
)
return workspace_client
def _get_endpoint_name():
"""Get endpoint name from environment."""
name = os.environ.get("ENDPOINT_NAME")
if not name:
raise ValueError(
"ENDPOINT_NAME must be set (format: projects/<id>/branches/<id>/endpoints/<id>)"
)
return name
class OAuthConnection(psycopg.Connection):
"""Custom connection class that generates a fresh OAuth token per connection."""
@classmethod
def connect(cls, conninfo="", **kwargs):
endpoint_name = _get_endpoint_name()
client = _get_workspace_client()
# Generate database credential (tokens are workspace-scoped)
credential = client.postgres.generate_database_credential(
endpoint=endpoint_name
)
kwargs["password"] = credential.token
return super().connect(conninfo, **kwargs)
# Create connection pool with OAuth token rotation
def get_connection_pool():
"""Get or create the connection pool."""
database = os.environ["PGDATABASE"]
user = os.environ["PGUSER"]
host = os.environ["PGHOST"]
port = os.environ.get("PGPORT", "5432")
sslmode = os.environ.get("PGSSLMODE", "require")
conninfo = f"dbname={database} user={user} host={host} port={port} sslmode={sslmode}"
return ConnectionPool(
conninfo=conninfo,
connection_class=OAuthConnection,
min_size=1,
max_size=10,
open=True,
)
# Use the pool in your application
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Zależności:databricks-sdk>=0.89.0, psycopg[binary,pool]>=3.1.0
Go
W tym przykładzie użyto pgxpool z funkcją wywołania zwrotnego BeforeConnect, która generuje nowy token dla każdego połączenia.
package main
import (
"context"
"fmt"
"log"
"os"
"time"
"github.com/databricks/databricks-sdk-go"
"github.com/databricks/databricks-sdk-go/service/postgres"
"github.com/jackc/pgx/v5"
"github.com/jackc/pgx/v5/pgxpool"
)
func createConnectionPool(ctx context.Context) (*pgxpool.Pool, error) {
// Initialize Databricks workspace client
w, err := databricks.NewWorkspaceClient(&databricks.Config{
Host: os.Getenv("DATABRICKS_HOST"),
ClientID: os.Getenv("DATABRICKS_CLIENT_ID"),
ClientSecret: os.Getenv("DATABRICKS_CLIENT_SECRET"),
})
if err != nil {
return nil, err
}
// Build connection string
connStr := fmt.Sprintf("host=%s port=%s dbname=%s user=%s sslmode=require",
os.Getenv("PGHOST"),
os.Getenv("PGPORT"),
os.Getenv("PGDATABASE"),
os.Getenv("PGUSER"))
config, err := pgxpool.ParseConfig(connStr)
if err != nil {
return nil, err
}
// Configure pool
config.MaxConns = 10
config.MinConns = 1
config.MaxConnLifetime = 45 * time.Minute
config.MaxConnIdleTime = 15 * time.Minute
// Generate fresh token for each new connection
config.BeforeConnect = func(ctx context.Context, connConfig *pgx.ConnConfig) error {
credential, err := w.Postgres.GenerateDatabaseCredential(ctx,
postgres.GenerateDatabaseCredentialRequest{
Endpoint: os.Getenv("ENDPOINT_NAME"),
})
if err != nil {
return err
}
connConfig.Password = credential.Token
return nil
}
return pgxpool.NewWithConfig(ctx, config)
}
func main() {
ctx := context.Background()
pool, err := createConnectionPool(ctx)
if err != nil {
log.Fatal(err)
}
defer pool.Close()
var user, database string
err = pool.QueryRow(ctx, "SELECT current_user, current_database()").Scan(&user, &database)
if err != nil {
log.Fatal(err)
}
fmt.Printf("Connected as: %s to database: %s\n", user, database)
}
Zależności: Zestaw SDK usługi Databricks dla języka Go w wersji 0.109.0+ (github.com/databricks/databricks-sdk-go), sterownik pgx (github.com/jackc/pgx/v5)
Uwaga: Wywołanie BeforeConnect zwrotne zapewnia świeże tokeny OAuth dla każdego nowego połączenia, umożliwiając automatyczną rotację tokenów w przypadku długotrwałych aplikacji.
Java
W tym przykładzie użyto narzędzia JDBC z oprogramowaniem HikariCP i niestandardowego źródła danych, które generuje nowy token podczas tworzenia każdego nowego połączenia przez pulę.
import java.sql.*;
import javax.sql.DataSource;
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.core.DatabricksConfig;
import com.databricks.sdk.service.postgres.*;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
public class LakebaseConnection {
private static WorkspaceClient workspaceClient() {
String host = System.getenv("DATABRICKS_HOST");
String clientId = System.getenv("DATABRICKS_CLIENT_ID");
String clientSecret = System.getenv("DATABRICKS_CLIENT_SECRET");
return new WorkspaceClient(new DatabricksConfig()
.setHost(host)
.setClientId(clientId)
.setClientSecret(clientSecret));
}
private static DataSource createDataSource() {
WorkspaceClient w = workspaceClient();
String endpointName = System.getenv("ENDPOINT_NAME");
String host = System.getenv("PGHOST");
String database = System.getenv("PGDATABASE");
String user = System.getenv("PGUSER");
String port = System.getenv().getOrDefault("PGPORT", "5432");
String jdbcUrl = "jdbc:postgresql://" + host + ":" + port +
"/" + database + "?sslmode=require";
// DataSource that returns a new connection with a fresh token (tokens are workspace-scoped)
DataSource tokenDataSource = new DataSource() {
@Override
public Connection getConnection() throws SQLException {
DatabaseCredential cred = w.postgres().generateDatabaseCredential(
new GenerateDatabaseCredentialRequest().setEndpoint(endpointName)
);
return DriverManager.getConnection(jdbcUrl, user, cred.getToken());
}
@Override
public Connection getConnection(String u, String p) {
throw new UnsupportedOperationException();
}
// ... other DataSource methods (getLogWriter, etc.)
};
// Wrap in HikariCP for connection pooling
HikariConfig config = new HikariConfig();
config.setDataSource(tokenDataSource);
config.setMaximumPoolSize(10);
config.setMinimumIdle(1);
// Recycle connections before 60-min token expiry
config.setMaxLifetime(45 * 60 * 1000L);
return new HikariDataSource(config);
}
public static void main(String[] args) throws SQLException {
DataSource pool = createDataSource();
try (Connection conn = pool.getConnection();
Statement st = conn.createStatement();
ResultSet rs = st.executeQuery("SELECT current_user, current_database()")) {
if (rs.next()) {
System.out.println("User: " + rs.getString(1));
System.out.println("Database: " + rs.getString(2));
}
}
}
}
Zależności: SDK Databricks dla Java w wersji 0.73.0+ (com.databricks:databricks-sdk-java), sterownik JDBC PostgreSQL (org.postgresql:postgresql), HikariCP (com.zaxxer:HikariCP)
6. Uruchom i sprawdź połączenie
Python
Zainstaluj zależności:
pip install databricks-sdk psycopg[binary,pool]
Uruchomić:
# Save all the code from step 5 (above) as db.py, then run:
from db import get_connection_pool
pool = get_connection_pool()
with pool.connection() as conn:
with conn.cursor() as cur:
cur.execute("SELECT current_user, current_database()")
print(cur.fetchone())
Oczekiwane dane wyjściowe:
('c00f575e-d706-4f6b-b62c-e7a14850571b', 'databricks_postgres')
Jeśli current_user jest zgodny z identyfikatorem klienta głównego z kroku 1, działa rotacja tokenu OAuth.
Java
Uwaga: Przyjęto założenie, że masz projekt Maven z zależnościami z powyższego przykładu języka Java w pliku pom.xml.
Zainstaluj zależności:
mvn install
Uruchomić:
mvn exec:java -Dexec.mainClass="com.example.LakebaseConnection"
Oczekiwane dane wyjściowe:
User: c00f575e-d706-4f6b-b62c-e7a14850571b
Database: databricks_postgres
Jeśli użytkownik pasuje do identyfikatora klienta usługi z kroku 1, działa rotacja tokenu OAuth.
Go
Zainstaluj zależności:
go mod init myapp
go get github.com/databricks/databricks-sdk-go
go get github.com/jackc/pgx/v5
Uruchomić:
go run main.go
Oczekiwane dane wyjściowe:
Connected as: c00f575e-d706-4f6b-b62c-e7a14850571b to database: databricks_postgres
Jeśli użytkownik pasuje do identyfikatora klienta usługi z kroku 1, działa rotacja tokenu OAuth.
Uwaga: Pierwsze połączenie po bezczynności może trwać dłużej, ponieważ autoskalowanie usługi Lakebase uruchamia obliczenia od zera.
Rozwiązywanie problemów
| Error | Napraw. |
|---|---|
| "Interfejs API jest wyłączony dla użytkowników bez uprawnień dostępu do obszaru roboczego" | Włącz opcję "Dostęp do obszaru roboczego" dla jednostki usługi (krok 1). |
| "Rola nie istnieje" lub uwierzytelnianie kończy się niepowodzeniem | Utwórz rolę OAuth za pomocą języka SQL (krok 2), a nie interfejsu użytkownika. |
| "Odmowa połączenia" lub "Nie znaleziono punktu końcowego" | Użyj ENDPOINT_NAME formatu projects/<id>/branches/<id>/endpoints/<id>; identyfikator punktu końcowego znajduje się na hoście. |
| "Nieprawidłowy użytkownik" lub "Nie znaleziono użytkownika" | Ustaw PGUSER na ID klienta jednostki usługi (UUID), a nie nazwę wyświetlaną. |