Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Note
Funkcja strumienia danych o zmianach w Lakebase jest dostępna w publicznej wersji zapoznawczej.
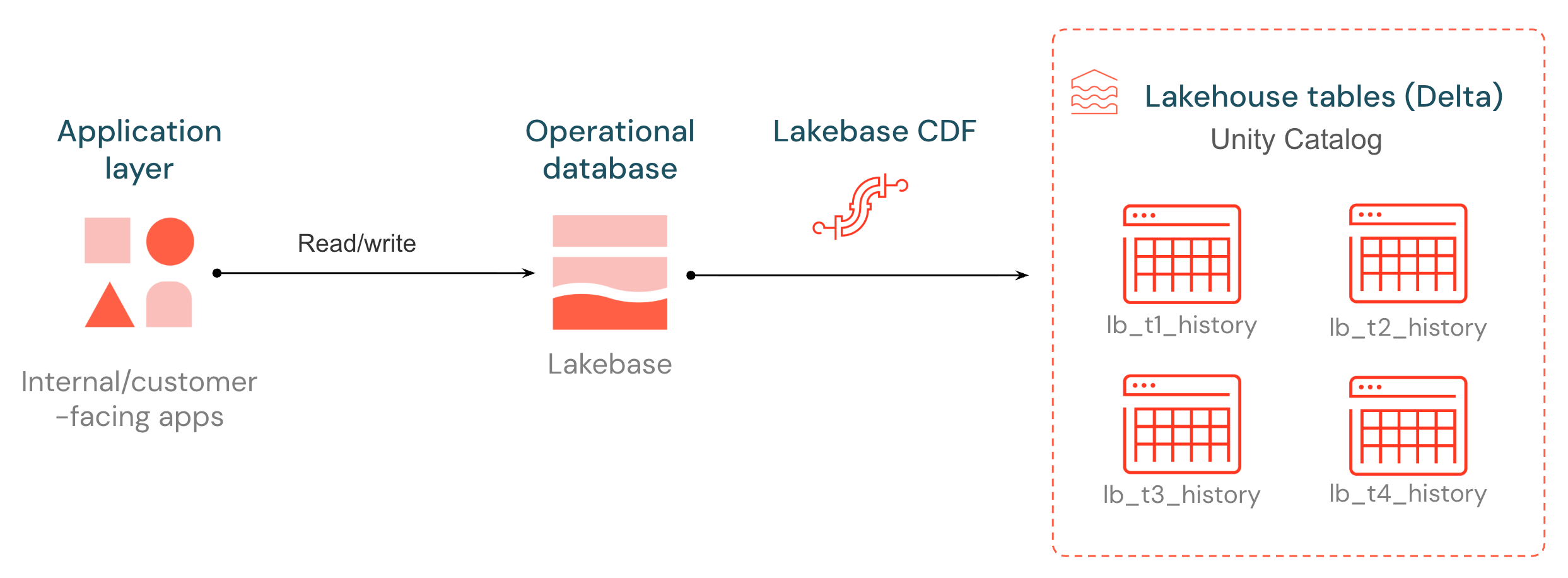
Czym jest strumień zmian danych w usłudze Lakebase?
Lakebase wprowadza natywny strumień danych o zmianach (CDF), udostępniając dane operacyjne dla dalszych potoków przetwarzania danych, modeli i aplikacji. Każda operacja wstawienia, aktualizacji i usunięcia w tabeli PostgreSQL w Lakebase jest przechwytywana z dziennika wyprzedzającego zapis i przechowywana jako nowy wiersz w tabeli Delta zarządzanej przez Unity Catalog, grupowana w partie i zapisywana co ok. 15 sekund. Historia zmian jest przechowywana w otwartym formacie, który może odczytywać każdy aparat obliczeniowy.
Tabele docelowe mają taką samą strukturę jak Delta Change Data Feed: każdy wiersz zawiera _pg_change_type, numer LSN, identyfikator transakcji i znacznik czasu. Zmiany operacyjne stają się pełnoprawnym źródłem dla procesów ETL, audytu i odbiorców systemów podrzędnych — bez konieczności wdrażania zewnętrznego stosu CDC.
Przypadki użycia
Usługa Lakebase CDF przenosi dane operacyjne do usługi Lakehouse, dzięki czemu potoki podrzędne i aplikacje mogą reagować na zmiany w miarę ich trwania.
| Przypadek użycia | Description |
|---|---|
| Potoki ETL | Użyj lakebase jako brązowego źródła dla potoków medalionu. Twórz przyrostowe zadania SDP lub Spark Structured Streaming względem zestawienia zmian i aktualizuj podrzędne tabele srebra i złota. |
| Dzienniki inspekcji | Zachowaj kompletną historię każdego wstawienia, zaktualizowania i usunięcia w tabeli Lakebase, którą można przeszukiwać za pomocą zapytań, na potrzeby zgodności i analizy śledczej. Historia jest niezmienna Delta. |
| Systemy zewnętrzne | Przechowuj dane zmian usługi Lakebase Store w otwartym formacie, z którego może korzystać dowolny silnik. Ponieważ miejscem docelowym jest tabela Delta w Unity Catalog, systemy zewnętrzne i odbiorcy spoza Databricks mogą uzyskiwać bezpośredni dostęp do strumienia danych. |
Włącz tę wersję zapoznawczą
Administrator przestrzeni roboczej musi włączyć wersję zapoznawczą Lakebase Change Data Feed na stronie Wersje zapoznawcze przestrzeni roboczej.
Requirements
- Automatyczne skalowanie Lakebase: Projekt automatycznego skalowania Lakebase działający w oparciu o Postgres 17.
-
Źródłowa baza danych: Tabele muszą znajdować się w bazie danych w usłudze
databricks_postgresLakebase. Każdy projekt jest tworzony przy użyciu tej domyślnej bazy danych. Jest to znane ograniczenie. - Unity Catalog: Tożsamość konfigurująca CDF musi mieć USE CATALOG, USE SCHEMA i CREATE TABLE w docelowym katalogu i schemacie. Zobacz Udzielanie uprawnień do obiektu.
- Magazyn domyślny: Katalogi docelowe skonfigurowane z magazynem domyślnym nie są obsługiwane.
- Projekt Lakebase: Rola Postgres wymaga uprawnień CAN MANAGE w projekcie Lakebase. Właściciele projektu domyślnie mają CAN MANAGE. Zobacz Zarządzanie uprawnieniami projektu.
- Typy danych: Zobacz Mapowanie typów danych. Typy, które nie mają bezpośredniego odpowiednika w Delta, są przechowywane jako STRING.
Konfigurowanie usługi Lakebase CDF
Aby rozpocząć, ustaw pełną tożsamość repliki w żądanych tabelach (krok 1), a następnie uruchom usługę CDF w aplikacji Lakebase (krok 2). Twoje dane są wyświetlane jako tabele lb_<table_name>_history Delta w wybranym przez Ciebie katalogu i schemacie usługi Unity Catalog.
Krok 1. Ustawianie pełnej tożsamości repliki
Aby tabela Lakebase uczestniczyła w CDF, musi mieć ustawienie REPLICA IDENTITY FULL. Domyślnie usługa Postgres rejestruje tylko klucz podstawowy po zaktualizowaniu lub usunięciu wiersza. Ustawienie pełnej tożsamości nakazuje usłudze Postgres rejestrowanie stanu przed i po wierszu w dzienniku z wyprzedzeniem zapisu, który musi utworzyć pełną historię zmian.
Te polecenia można uruchomić w edytorze SQL lakebase lub dowolnym kliencie Postgres.
Pojedyncza tabela
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Wszystkie istniejące tabele w schemacie
Aby ustawić tożsamość repliki dla każdej istniejącej tabeli w schemacie (public w tym przykładzie), uruchom polecenie:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
Automatyczne stosowanie do przyszłych tabel
Aby automatycznie otrzymywać REPLICA IDENTITY FULLkażdą nowo utworzoną tabelę, zainstaluj wyzwalacz zdarzeń Postgres. Jest uruchamiany po każdym CREATE TABLE i ustawia tożsamość w nowej tabeli:
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
Połącz wyzwalacz zdarzenia z pętlą z poprzedniej karty, aby objąć zarówno istniejące, jak i przyszłe tabele w ramach jednej konfiguracji.
Sprawdź, które tabele mają ustawioną tożsamość repliki
Aby sprawdzić, które tabele w schemacie mają skonfigurowaną tożsamość repliki, uruchom polecenie:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Tylko wiersze z funkcją replica_identity = 'full' są gotowe do użycia w usłudze CDF.
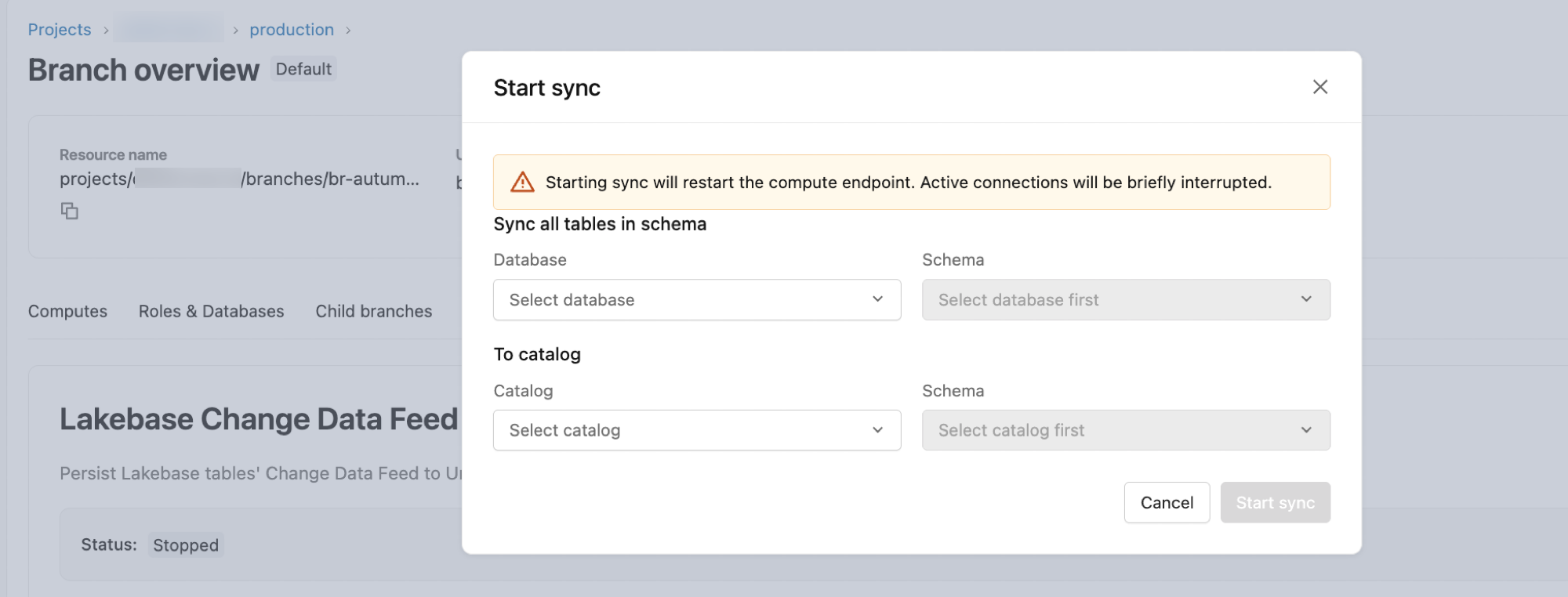
Krok 2. Uruchom strumień danych zmian
Lakebase CDF jest konfigurowane na poziomie schematu. Po uruchomieniu wszystkie obecne i przyszłe tabele w schemacie źródłowym są uwzględniane w strumieniu.
- W obszarze roboczym Azure Databricks otwórz Lakebase Postgres z przełącznika aplikacji (w prawym górnym rogu).
- Wybierz projekt Lakebase i gałąź, której chcesz użyć (na przykład produkcyjnej lub głównej).
- Otwórz przegląd gałęzi i kliknij kartę Zmień źródło danych .
- Kliknij przycisk Start.
- W oknie dialogowym konfiguracji:
-
Baza danych: Domyślną wartością jest
databricks_postgres. - Schemat: Wybierz schemat źródłowy bazy danych Postgres.
- Do katalogu: Wybierz docelowy katalog usługi Unity Catalog.
- Schemat: Wybierz docelowy schemat usługi Unity Catalog.
-
Baza danych: Domyślną wartością jest
- Kliknij przycisk Start , aby rozpocząć kanał informacyjny.
Tabele są wyświetlane w miejscu docelowym jako lb_<table_name>_history. Aby je znaleźć, otwórz pozycję Wykaz na pasku bocznym, przejdź do katalogu docelowego i schematu, a następnie otwórz kartę Tabele .
Karta Zestawienie danych zmian w usłudze Lakebase ma dwie karty podrzędne:
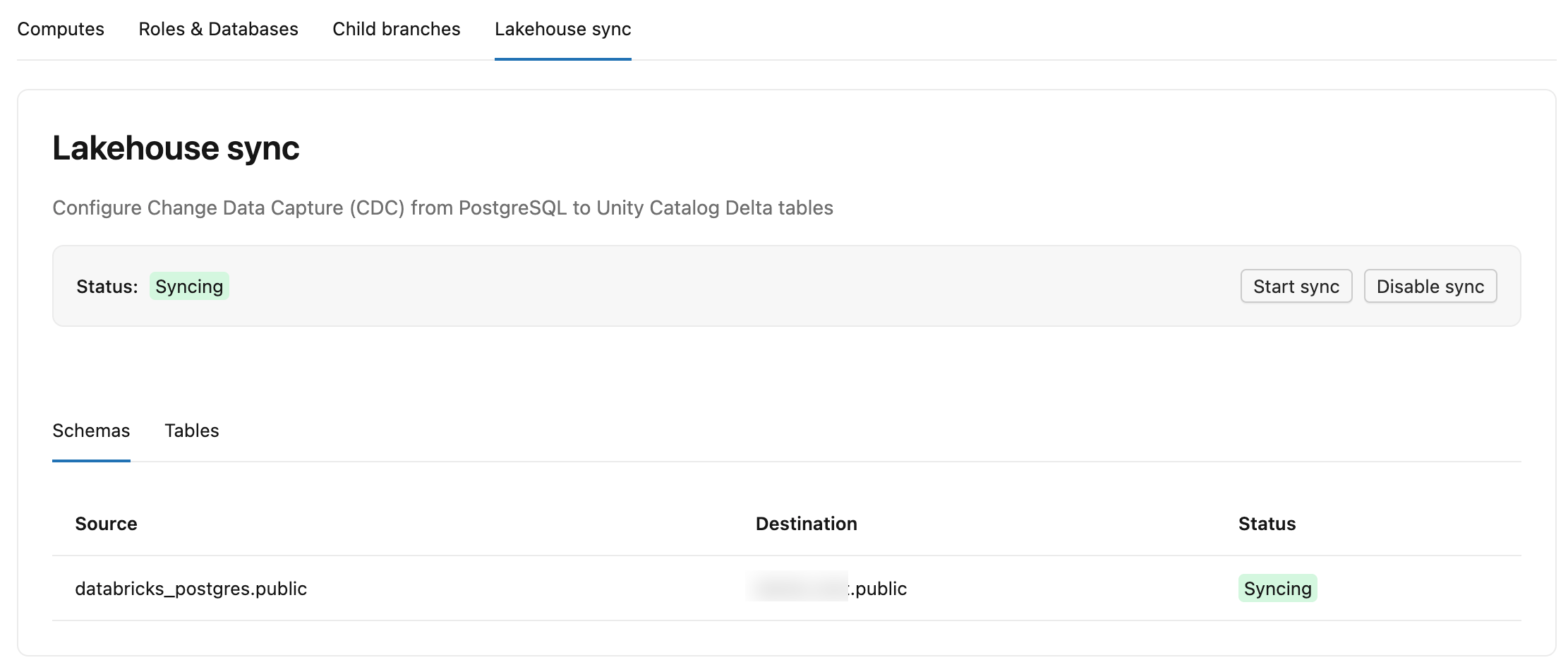
- Schematy: Zawiera listę wszystkich schematów źródłowych, ich katalogów docelowych i schematów w Unity Catalog oraz ich statusów.
-
Tabele: Wyświetla każdą tabelę źródłową, odpowiadającą jej tabelę docelową
lb_<table_name>_history, stan (StreaminglubSnapshotting), zatwierdzony numer LSN (jak daleko strumień zapisał dane do Delta, wyświetlane jako-, gdy nadal trwa początkowa migawka) oraz Ostatnia aktualizacja (czas ostatniego otrzymania zmian przez tabelę).
Możesz również sprawdzić stan feedu w Postgresie, uruchamiając to w Lakebase SQL Editor:
SELECT * FROM wal2delta.tables;
Wynik obejmuje table_oid, status (STREAMING lub SNAPSHOTTING), committed_lsni last_write_time dla tabeli.
Ważna
Co to jest wal2delta? Usługa Lakebase CDF jest obsługiwana przez rozszerzenie wal2delta Postgres, które działa wewnątrz obliczeń Lakebase. Narzędzie używa dekodowania logicznego do rejestrowania zmian w dzienniku WAL i zapisuje je w tabelach Delta w Unity Catalog.
Schemat tabeli docelowej
CDF zapisuje jedną tabelę Delta dla każdej tabeli źródłowej o nazwie lb_<table_name>_history w docelowym katalogu i schemacie. Oprócz kolumn źródłowych każdy wiersz zawiera następujące kolumny systemowe:
| Column | Typ | Description |
|---|---|---|
_pg_change_type |
TEKST | Typ operacji: insert, , deleteupdate_preimagelub update_postimage. |
_pg_lsn |
BIGINT | Numer sekwencyjny dziennika PostgreSQL. |
_pg_xid |
INTEGER | Identyfikator transakcji postgres. |
_timestamp |
TIMESTAMP | Sygnatura czasowa przetwarzania zmiany (bez strefy czasowej). |
_sort_by |
BIGINT | Monotoniczny klucz sortowania używany do zamawiania wszystkich zmian. |
Typowe wzorce zmian
-
Początkowa migawka: Przy pierwszym uruchomieniu usługi CDF w istniejącej tabeli Lakebase każdy istniejący wiersz jest zapisywany przy użyciu polecenia
_pg_change_type = 'insert'. -
Aktualizacje: Aktualizacja tworzy dwa wiersze: jeden z
_pg_change_type = 'update_preimage'(stary wiersz) i jeden z_pg_change_type = 'update_postimage'(nowy wiersz). -
Usuwa: Usunięcie tworzy jeden wiersz z elementem
_pg_change_type = 'delete'.
Są to te same zdarzenia zmian co w Delta Change Data Feed, więc obowiązują te same wzorce przetwarzania podrzędnego.
Zachowanie operacyjne
-
Kolizje nazw: Jeśli dwie tabele źródłowe zostałyby odwzorowane na tę samą nazwę docelową (na przykład, jeśli
sales.usersimarketing.usersbyłyby odwzorowywane nalb_users_history), usługa CDF zapisuje pierwszą pod nazwąlb_users_history, a do drugiej automatycznie dodaje sufiks, tworząclb_users_history_1. Możesz zmienić nazwę dowolnej z tabel docelowych w Unity Catalog, a strumień nadal będzie działać. - Zakres na poziomie schematu: Po włączeniu funkcji CDF dla schematu Lakebase uwzględniane są wszystkie obecne i przyszłe tabele w tym schemacie. Puste tabele są pomijane — tabela musi zawierać co najmniej jeden wiersz do wyświetlenia w miejscu docelowym.
- Usunięte tabele źródłowe: Jeśli usuniesz tabelę w usłudze Lakebase, docelowa tabela Delta w Unity Catalog zostanie zachowana.
Tworzenie potoków podrzędnych
Usługa CDF usługi Lakebase jest przeznaczona dla potoków podrzędnych, które reagują na zmiany operacyjne. Poniższe wzorce pokazują trzy sposoby korzystania z kanału informacyjnego uporządkowane od najprostszego do najbardziej elastycznego.
Przykładowy scenariusz. Aplikacja e-commerce rejestruje zamówienia w tabeli Postgres orders, a każdy wiersz zawiera item_id i quantity. Zespół logistyczny potrzebuje stanów magazynowych w czasie rzeczywistym. Dzięki funkcji CDF każda zmiana w elemencie orders jest przechowywana w tabeli Delta lb_orders_history w Unity Catalog. Potoki podrzędne odczytują ten strumień zmian i aktualizują tabelę inventory_levels zawsze, gdy zamówienie zostanie złożone, zmodyfikowane lub anulowane.
Obliczanie bieżącego spisu za pomocą zmaterializowanego widoku
Najprostszym wzorcem jest widok SQL zmaterializowany oparty na tabeli historii. Mv odświeża się przyrostowo w miarę nadejścia nowych zdarzeń zmiany, a odbiorcy podrzędni wysyłają do niej zapytania w taki sposób, jak każda inna tabela.
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
Dwa wiersze utworzone dla każdej aktualizacji anulują się z wyjątkiem zmiany netto, więc suma bieżąca pozostaje poprawna, ponieważ zamówienia są edytowane.
Przesyłanie strumieniowe zmian za pomocą potoków deklaratywnych platformy Spark
W przypadku ustrukturyzowanej architektury medalionowej użyj Spark Declarative Pipelines (SDP) do zdefiniowania tabel brązowych, srebrnych i złotych. SDP uruchamia je jako spójny potok, a punkty kontrolne i zarządzanie zależnościami są obsługiwane za Ciebie.
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments odczytuje lb_orders_history przyrostowo z użyciem readStream i generuje przyrost dla każdego zdarzenia.
inventory_levels agreguje według item_id, aby obliczyć bieżący stan magazynowy. Asercja odrzuca wiersze, które powodowałyby ujemny stan magazynowy, sygnalizując błąd we wcześniejszym etapie przetwarzania.
Aby zapoznać się z kompleksowym przewodnikiem krok po kroku, zobacz Samouczek: Tworzenie potoku ETL przy użyciu mechanizmu Change Data Capture.
Niestandardowe przetwarzanie przy użyciu Spark Structured Streaming
Jeśli potrzebujesz pełnej kontroli — na przykład niestandardowych operacji scalania, efektów ubocznych lub wielu miejsc docelowych — odczytuj tabelę historii bezpośrednio za pomocą Spark Structured Streaming i użyj foreachBatch, aby zapisać dane w miejscu docelowym.
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
Każda mikropaczka agreguje zdarzenia zmian według item_id i scala delty netto do inventory_levels.
Przyrostowe z założenia. Każda tabela lb_<table_name>_history jest tabelą Delta typu append-only. Każda zmiana źródła jest rejestrowana jako nowy wiersz z _pg_change_type oznaczeniem operacji. Widoki zmaterializowane Databricks SQL, przepływy Lakeflow Spark Declarative Pipelines oraz zadania Spark Structured Streaming przetwarzają nowe wiersze przyrostowo na podstawie dziennika transakcji Delta, więc potoki podrzędne wykonują pracę tylko w zakresie proporcjonalnym do wprowadzonych zmian. Nie trzeba włączać Delta Change Data Feed dla tabeli historii, ponieważ informacje o zmianach są już zapisane w danych wierszy.
Mapowanie typu danych
Usługa CDF obsługuje większość standardowych typów pierwotnych PostgreSQL. Typy, które nie mają bezpośredniego odpowiednika w Delta, są przechowywane jako STRING.
| Typ bazy danych PostgreSQL | typ Delta usługi Azure Databricks | Notatki |
|---|---|---|
| BOOLEAN | BOOLEAN | |
| INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
| TEKST, VARCHAR, CHAR | STRING | |
| JSONB | STRING | Przechowywane jako ciąg JSON. |
| ENUM | STRING | Przechowywane jako etykieta enum. |
| NUMERYCZNY / DZIESIĘTNY | DECIMAL lub STRING | Używa dokładności/skali źródła, jeśli jest to możliwe. Wykonuje bezstratne przeskalowanie w przypadku niezgodnych wartości precyzji/skali. Przechodzi na typ STRING, gdy precyzja przekracza 38 lub gdy precyzja/skala nie są określone (nieograniczony typ NUMERIC). Wszystkie kolumny NUMERIC/DECIMAL są dopuszczane do wartości null, ponieważ wartości NaN są mapowane na wartość NULL. Zobacz Typy liczbowe PostgreSQL. |
| DATE | DATE | |
| TIMESTAMP | TIMESTAMP_NTZ | |
| TIMESTAMPTZ | TIMESTAMP | |
| FLOAT, DOUBLE | FLOAT, DOUBLE |
Typy przechowywane jako CIĄG:
-
Geography/Geometry (PostGIS): Typy z rozszerzenia PostGIS (na przykład
geometry,geography). -
Wektor (pgvector):
vectorTyp z rozszerzenia pgvector. -
Typy złożone/typy struct: Typy niestandardowe zdefiniowane przy użyciu
CREATE TYPE ... AS (field_name type, ...). Są to typy wierszopodobne z nazwanymi polami. -
Mapa: Typy klucz-wartość, takie jak hstore (z rozszerzenia
hstore). Baza danych Postgres nie ma wbudowanego typu mapy.hstoreto typowy sposób przechowywania par klucz-wartość w kolumnie.
Zarządzanie zmianami schematu
-
Zmiana nazwy tabeli w PostgreSQL (na przykład
ALTER TABLE users RENAME TO customers) umożliwia dalsze działanie strumienia danych. Docelowa nazwa tabeli Delta nie zmienia się — pozostajelb_users_history. - Zmiany schematu (dodawanie kolumny, upuszczanie kolumny lub zmiana typu danych kolumny) powodują ponowne utworzenie migawki tabeli, której dotyczy problem. Usługa CDF ponownie odczytuje całą tabelę z bazy danych Postgres i ponownie zapisuje ją w docelowej tabeli delty.
Wyłączanie usługi Lakebase CDF
Wyłączenie CDF zatrzymuje strumień danych dla wszystkich schematów Lakebase w projekcie.
- W obszarze roboczym Azure Databricks otwórz Lakebase Postgres z przełącznika aplikacji (w prawym górnym rogu).
- Wybierz projekt Lakebase i gałąź, w której skonfigurowano usługę CDF.
- Otwórz przegląd gałęzi i kliknij kartę Zmień źródło danych .
- Kliknij pozycję Wyłącz. W oknie dialogowym potwierdzenia przejrzyj ostrzeżenie, że zmiany przestaną przepływać do tabel delty, a następnie kliknij przycisk Wyłącz ponownie, aby potwierdzić.
Wyłączenie usługi CDF nie powoduje ponownego uruchomienia obliczeń.
Ostrzeżenie
Jeśli włączysz ponownie usługę CDF później, system nie wykonuje pełnej ponownej migawki. Wszelkie zmiany, które zaszły, gdy CDF było wyłączone, zostały trwale utracone w docelowych tabelach Delta.
Ograniczenia i rozwiązywanie problemów
Stan poszczególnych tabel (tworzenie migawek, pominięto lub strumieniowanie) można sprawdzić na karcie Change Data Feed lub wykonując to polecenie w usłudze Lakebase:
SELECT * FROM wal2delta.tables;
Typowe przyczyny, dla których tabela nie jest wyświetlana w kanale informacyjnym:
-
REPLICA IDENTITY FULLnie ustawiono: UruchomALTER TABLE <table_name> REPLICA IDENTITY FULL;dla tej tabeli. Zobacz Krok 1. Ustawianie pełnej tożsamości repliki. - Tabele podzielone na partycje: Tabele partycjonowane w usłudze Lakebase nie są obsługiwane. Schemat zawierający tabele partycjonowane powoduje niepowodzenie tych tabel.
- Puste tabele: Tabela z zerowymi wierszami jest pomijana, dopóki nie istnieje co najmniej jeden wiersz.
Następne kroki
- Twórz przyrostowe ETL za pomocą Spark Declarative Pipelines. Zobacz Samouczek: jak utworzyć potok ETL przy użyciu przechwytywania zmian danych, aby zapoznać się ze szczegółowym omówieniem.
- Wykonuj zapytania do warstwy bronze za pomocą Databricks SQL. Zobacz Wprowadzenie do magazynowania danych przy użyciu usługi Databricks SQL.
- Historia audytu przy użyciu zapytań podróży w czasie w docelowych tabelach Delta.