Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Autoskalowanie bazy danych Lakebase to najnowsza wersja bazy danych Lakebase, która umożliwia skalowanie automatyczne, skalowanie do zera, rozgałęzianie i natychmiastowe przywracanie. Aby uzyskać informacje o obsługiwanych regionach, zobacz Dostępność regionów. Jeśli jesteś użytkownikiem usługi Lakebase Provisioned, zobacz Lakebase Provisioned.
Projekt jest kontenerem najwyższego poziomu dla zasobów usługi Lakebase, w tym gałęzi, obliczeń, baz danych i ról. Na tej stronie wyjaśniono, jak tworzyć projekty, interpretować ich strukturę, konfigurować ustawienia i zarządzać cyklem życia.
Jeśli dopiero zaczynasz korzystać z usługi Lakebase, zacznij od sekcji Wprowadzenie do utworzenia pierwszego projektu.
Opis projektów
struktura projektu
Zrozumienie struktury projektu Lakebase ułatwia efektywne organizowanie zasobów i zarządzanie nimi. Projekt to kontener najwyższego poziomu dla baz danych, gałęzi, obliczeń i powiązanych zasobów. Każdy projekt zawiera ustawienia domyślnych ustawień obliczeniowych, okien przywracania i aktualizacji, które mają zastosowanie do wszystkich gałęzi w projekcie.
Na najwyższym poziomie projekt zawiera co najmniej jedną gałąz. W ramach projektu można tworzyć gałęzie dla różnych środowisk, takich jak rozwojowe, testowanie, przygotowawcze i produkcja. Każda gałąź zawiera własne obliczenia, role i bazy danych.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Oddziały
Dane znajdują się w gałęziach. Każdy projekt lakebase jest tworzony z gałęzią główną o nazwie production, której nie można usunąć. Chociaż można utworzyć dodatkowe gałęzie i wyznaczyć inną gałąź jako gałąź domyślną, nie można usunąć gałęzi głównej.
Gałęzie podrzędne można tworzyć z dowolnej gałęzi w projekcie. Podczas tworzenia gałęzi podrzędnej dziedziczy ona wszystkie bazy danych, role i dane z gałęzi nadrzędnej w momencie jej utworzenia. Kolejne zmiany w gałęzi nadrzędnej nie są automatycznie propagowane do gałęzi podrzędnej, co umożliwia izolowany rozwój, testowanie lub eksperymentowanie.
Każda gałąź może zawierać wiele baz danych i ról. Dowiedz się więcej: Zarządzanie gałęziami
Oblicza
Instancja obliczeniowa to zwirtualizowany zasób obliczeniowy, który zawiera vCPU i pamięć do uruchamiania Postgres. Podczas tworzenia projektu dla domyślnej gałęzi projektu jest tworzone podstawowe obliczenia R/W (odczyt-zapis). Każda gałąź ma jedną główną jednostkę obliczeniową R/W. Aby nawiązać połączenie z bazą danych, która znajduje się w gałęzi, musisz nawiązać połączenie za pośrednictwem obliczeń R/W skojarzonych z gałęzią.
Oprócz podstawowych obliczeń R/W można dodać jedną lub więcej replik do odczytu do dowolnej gałęzi. Repliki do odczytu umożliwiają odciążenie obciążeń związanych z odczytem z głównego serwera obliczeniowego na potrzeby takich przypadków użycia jak poziome skalowanie odczytów, analizy i zapytania raportujące oraz dostęp tylko do odczytu dla użytkowników lub aplikacji. Dowiedz się więcej: Zarządzanie obliczeniami, replikami do odczytu
Ról
Role są rolami Postgres. Do utworzenia bazy danych i uzyskania dostępu do bazy danych jest wymagana rola. Rola należy do gałęzi. Podczas tworzenia projektu rola Postgres jest automatycznie tworzona dla tożsamości Databricks (na przykład user@databricks.com), która jest właścicielem domyślnej databricks_postgres bazy danych. Każda rola utworzona w interfejsie użytkownika usługi Lakebase jest tworzona z uprawnieniami databricks_superuser . Istnieje limit 500 ról na gałąź. Dowiedz się więcej: Zarządzanie rolami
Bazy danych
Baza danych jest kontenerem dla obiektów SQL, takich jak schematy, tabele, widoki, funkcje i indeksy. W usłudze Lakebase baza danych należy do gałęzi. Domyślna gałąź projektu jest tworzona z bazą danych o nazwie databricks_postgres. Istnieje limit 500 baz danych na gałąź. Dowiedz się więcej: Zarządzanie bazami danych
Schematów
Wszystkie bazy danych w usłudze Lakebase są tworzone przy użyciu schematu, który jest domyślnym zachowaniem public dla dowolnego standardowego wystąpienia bazy danych Postgres. Obiekty SQL są domyślnie tworzone w schemacie public .
Limity projektu
Usługa Lakebase Postgres wymusza następujące limity dla projektów:
| Resource | Ograniczenie |
|---|---|
| Maksymalna liczba współbieżnych aktywnych obliczeń | 20 |
| Maksymalna liczba replik do odczytu na gałąź | 6 |
| Maksymalna liczba gałęzi na projekt | 500 |
| Maksymalna liczba ról PostgreSQL na każdą gałąź | 500 |
| Maksymalna liczba baz danych Postgres na gałąź | 500 |
| Maksymalny rozmiar danych logicznych na gałąź | 8 TB |
| Maksymalna liczba projektów na obszar roboczy | 1000 |
| Maksymalna liczba chronionych gałęzi | 1 |
| Maksymalna liczba gałęzi głównych | 3 |
| Maksymalna liczba niearchiwowanych gałęzi | 10 |
| Maksymalna liczba migawek ręcznych | 10 |
| Maksymalny okres przechowywania historii | 30 dni |
| Minimalna skala do czasu zerowego | 60 sekund |
Limit współbieżnych aktywnych zasobów obliczeniowych
Limit współbieżnych aktywnych zasobów obliczeniowych ogranicza liczbę obliczeń, które mogą być uruchamiane w tym samym czasie, aby zapobiec wyczerpaniu zasobów. Ten limit chroni przed przypadkowymi wzrostami zasobów, takimi jak uruchamianie wielu punktów końcowych obliczeniowych jednocześnie. Domyślny limit to 20 współbieżnie aktywnych obliczeń na projekt.
Ważne: Gałąź domyślna jest wyłączona z tego limitu, zapewniając, że pozostaje dostępna przez cały czas.
Po przekroczeniu limitu dodatkowe obliczenia wykraczające poza limit pozostają zawieszone i podczas próby nawiązania z nimi połączenia zostanie wyświetlony błąd. Aby rozwiązać ten problem:
- Wstrzymaj inne aktywne obliczenia i spróbuj ponownie.
- Jeśli ten błąd występuje często, skontaktuj się z pomocą techniczną usługi Databricks, aby zażądać zwiększenia limitu.
Uwaga / Notatka
Obliczenia ze skalowaniem do zera zostają automatycznie wstrzymane po okresie braku aktywności, ułatwiając pozostać w równoczesnym aktywnym limicie obliczeniowym.
Dostępność regionów
Obsługiwane regiony:
-
eastus(Wschodnie stany USA) -
eastus2(Wschodnie stany USA 2) -
centralus(Środkowe stany USA) -
southcentralus(Południowo-środkowe stany USA) -
westus(Zachodnie stany USA) -
westus2(Zachodnie stany USA 2) -
canadacentral(Kanada Środkowa) -
brazilsouth(Brazylia Południowa) -
northeurope(Europa Północna) -
uksouth(Południowe Zjednoczone Królestwo) -
westeurope(Europa Zachodnia) -
australiaeast(Australia Wschodnia) -
centralindia(Indie Środkowe) -
southeastasia(Azja Południowo-Wschodnia)
Projekt Lakebase jest tworzony w regionie obszaru roboczego Databricks.
Obsługa wersji bazy danych Postgres
Usługa autoskalowania Lakebase Postgres obsługuje bazy danych Postgres 16 i Postgres 17.
Tworzenie projektów i zarządzanie nimi
Tworzenie projektu
W usłudze Lakebase Postgres można utworzyć wiele projektów, aby zapewnić pełne odizolowanie aplikacji lub klientów, zapewniając czyste rozdzielenie danych i zasobów.
Aby utworzyć projekt:
interfejs użytkownika
- Kliknij przełącznik aplikacji w prawym górnym rogu, aby otworzyć aplikację Lakebase.
- Kliknij pozycję Nowy projekt.
- Skonfiguruj ustawienia projektu:
-
Nazwa projektu: Podaj opisową nazwę projektu. Typowe wzorce nazewnictwa obejmują nazewnictwo po aplikacji (na przykład
my-analytics-app) lub klientowi lub najemcy, którym projekt służy (na przykładacme-corp-db). - Wersja bazy danych Postgres: wybierz wersję bazy danych Postgres, której chcesz użyć.
- Zasady użycia bezserwerowego (opcjonalnie): wybierz zasady użycia bezserwerowego, aby przypisywać bezserwerowe koszty obliczeń do określonych zasad. Zobacz Zasady użycia bezserwerowe.
-
Nazwa projektu: Podaj opisową nazwę projektu. Typowe wzorce nazewnictwa obejmują nazewnictwo po aplikacji (na przykład
W oknie dialogowym Tworzenie projektu są wyświetlane opcje konfiguracji projektu.
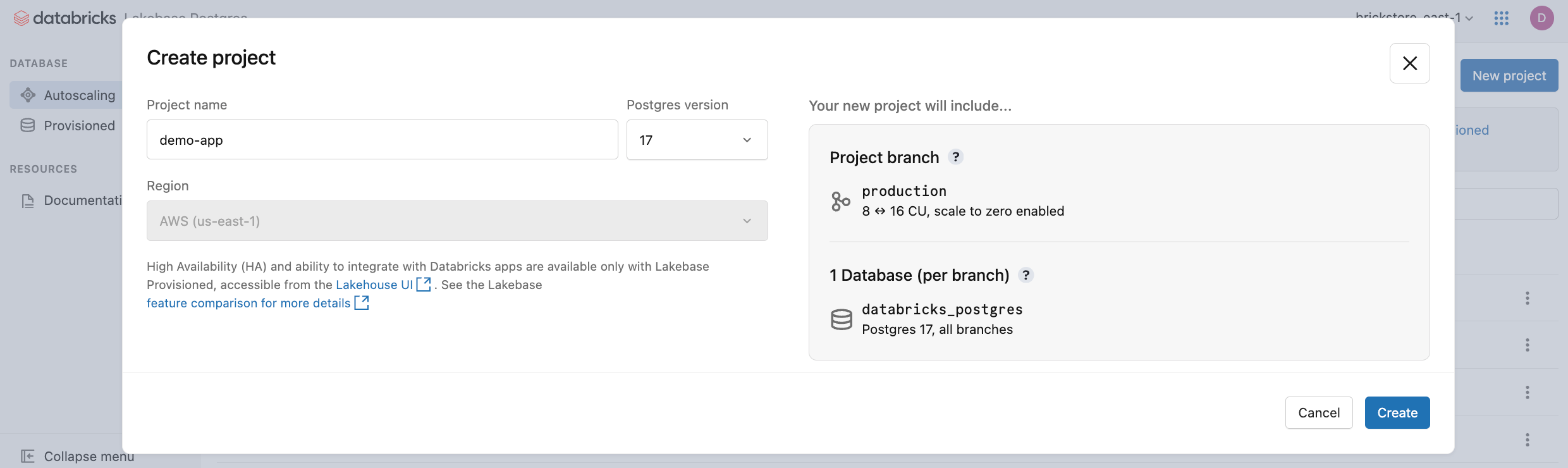
Region projektu Lakebase jest ustawiony na region obszaru roboczego usługi Databricks i nie można go modyfikować.
zestaw SDK Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version=17,
budget_policy_id="<policy-id>"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
zestaw SDK Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
CLI
# Create a project with a custom project ID
databricks postgres create-project my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}'
skręt
Utwórz projekt z niestandardowym identyfikatorem projektu. Parametr project_id jest określony jako parametr zapytania i staje się częścią nazwy zasobu projektu (na przykład projects/my-app).
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}' | jq
Jest to długotrwała operacja. Odpowiedź zawiera nazwę operacji, której można użyć do sprawdzenia stanu. Operacja zazwyczaj kończy się w ciągu kilku sekund.
Parametr project_id jest wymagany.
Nowy projekt domyślnie zawiera następujące zasoby:
Pojedyncza
productiongałąź (gałąź domyślna)Jedno podstawowe środowisko obliczeniowe odczytu i zapisu skojarzone z gałęzią z następującymi ustawieniami domyślnymi:
Branch Jednostki obliczeniowe (CU) wysoka dostępność Autoscaling Skalowanie do zera production8 – 16 CU Wyłączony Enabled Wyłączony Podczas tworzenia projektu gałąź
productionjest tworzona z zasobami obliczeniowymi, które domyślnie mają wyłączoną funkcję skalowania do zera, co oznacza, że zasoby pozostają aktywne przez cały czas. W razie potrzeby możesz włączyć skalowanie do zera dla tego środowiska obliczeniowego.Baza danych Postgres (o nazwie
databricks_postgres)Rola Postgres dla tożsamości usługi Databricks (na przykład
user@databricks.com)
Aby zmienić ustawienia obliczeniowe istniejącego projektu, zobacz Konfigurowanie ustawień projektu. Aby zmodyfikować domyślne ustawienia obliczeniowe dla nowych projektów, zobacz Compute defaults (Wartości domyślne obliczeń ) w temacie Configure project settings (Konfigurowanie ustawień projektu).
Uzyskaj szczegóły projektu
Pobierz szczegóły dla określonego projektu.
interfejs użytkownika
- Kliknij przełącznik aplikacji w prawym górnym rogu, aby otworzyć aplikację Lakebase.
- Wybierz projekt z listy projektów, aby wyświetlić jego szczegóły.
zestaw SDK Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
zestaw SDK Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
CLI
# Get project details
databricks postgres get-project projects/my-project
skręt
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Odpowiedź obejmuje:
-
name: Nazwa zasobu (projects/my-project) -
status: konfiguracja projektu i bieżący stan (display_name, pg_version, itp.)
Uwaga: pole spec nie jest wypełniane dla GET operacji. Wszystkie właściwości zasobu są zwracane w status polu.
Lista projektów
Wyświetl listę wszystkich projektów w obszarze roboczym.
interfejs użytkownika
- Kliknij przełącznik aplikacji w prawym górnym rogu, aby otworzyć aplikację Lakebase.
- Lista projektów zawiera wszystkie projekty, do których masz dostęp.
zestaw SDK Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
zestaw SDK Java
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
CLI
# List all projects
databricks postgres list-projects
skręt
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Format odpowiedzi:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": 17
}
}
]
}
Konfigurowanie ustawień projektu
Po utworzeniu projektu możesz zmodyfikować różne ustawienia na pulpicie nawigacyjnym projektu, przechodząc do pozycji Ustawienia:
Ustawienia ogólne
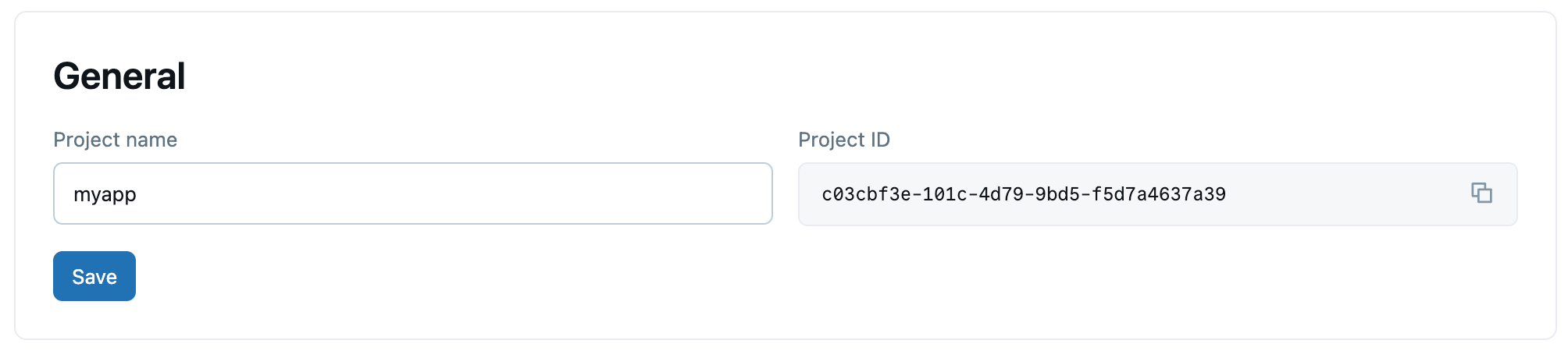
Na stronie ustawień ogólnych są wyświetlane następujące pola:
- Nazwa wyświetlana: edytowalna nazwa wyświetlana projektu.
-
Nazwa zasobu: tylko do odczytu. Pełna ścieżka zasobu dla Twojego projektu (format:
projects/{project_id}). Użyj tej wartości w wywołaniach interfejsu API i zestawu SDK, aby zidentyfikować projekt. - UID: tylko do odczytu. Unikatowy identyfikator wygenerowany przez system dla projektu.
- Zasady użycia bezserwerowego: skojarz zasady użycia bezserwerowego z projektem, aby przypisywać bezserwerowe koszty obliczeń do określonych zasad. Zobacz Zasady użycia bezserwerowe.
-
Tagi niestandardowe: dodaj tagi klucz-wartość do projektu. Tagi są rejestrowane w rozliczanych rekordach użycia konta (
system.billing.usage) i mogą służyć do śledzenia kosztów według zespołu, projektu lub centrum kosztów. Zobacz Tagi niestandardowe. Podczas aktualizowania tagów niestandardowych przy użyciu interfejsu API lub interfejsu wiersza polecenia nowa lista zastępuje wszystkie istniejące tagi.
interfejs użytkownika
zestaw SDK Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec, ProjectCustomTag, FieldMask
w = WorkspaceClient()
# Update project display name
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.display_name"]),
project=Project(spec=ProjectSpec(display_name="My Updated Project Name"))
).wait()
# Update serverless usage policy
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.budget_policy_id"]),
project=Project(spec=ProjectSpec(budget_policy_id="<policy-id>"))
).wait()
# Update custom tags (replaces all existing tags)
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.custom_tags"]),
project=Project(spec=ProjectSpec(custom_tags=[
ProjectCustomTag(key="team", value="data-eng"),
ProjectCustomTag(key="cost-center", value="1234")
]))
).wait()
CLI
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
# Update serverless usage policy
databricks postgres update-project projects/my-project spec.budget_policy_id \
--json '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}'
# Update custom tags
databricks postgres update-project projects/my-project spec.custom_tags \
--json '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}'
skręt
# Update project display name
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
# Update serverless usage policy
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.budget_policy_id" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}' | jq
# Update custom tags
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.custom_tags" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}' | jq
Są to długotrwałe operacje. Odpowiedź zawiera nazwę operacji, której można użyć do sprawdzenia stanu.
Wartości domyślne obliczeń
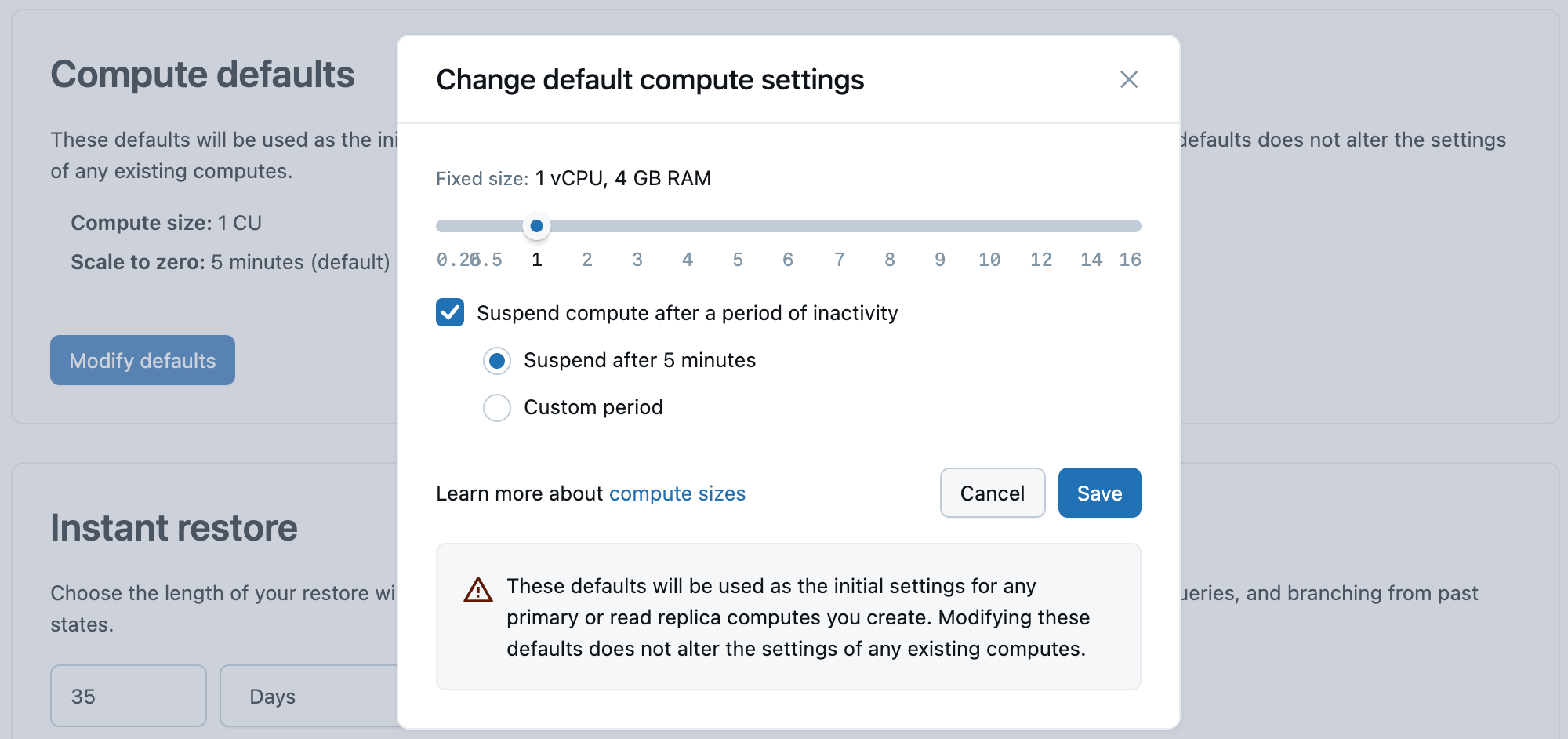
Te wartości domyślne są używane jako ustawienia początkowe dla wszystkich tworzonych zasobów obliczeniowych podstawowej lub repliki do odczytu. Modyfikowanie tych wartości domyślnych nie zmienia ustawień żadnych istniejących obliczeń.
Wartości domyślne:
- Rozmiar obliczeniowy: 2 ↔ 4 CU (zakres skalowania automatycznego; ~4–8 GB pamięci RAM)
- Skalowanie do zera: Włączone domyślnie — wstrzymaj obliczenia po zaznaczeniu okresu braku aktywności z wybraną pozycją Wstrzymaj po 5 minutach
Kliknij pozycję Modyfikuj wartości domyślne , aby otworzyć okno dialogowe i zmienić te wartości.
Uwaga / Notatka
Aby zmodyfikować ustawienia dla istniejącego środowiska obliczeniowego, zobacz Zarządzanie obliczeniami.
Usługa Lakebase Postgres obsługuje rozmiary obliczeń z 0,5 CU do 112 CU. Skalowanie automatyczne jest dostępne dla obliczeń do 32 CU (0,5, a następnie liczby całkowite przyrostowe: 1, 2, 3... 16, a następnie 24, 28, 32). Większe jednostki obliczeniowe o stałym rozmiarze są dostępne od 36 CU do 112 CU (36, 40, 44, 48, 52, 56, 60, 64, 72, 80, 88, 96, 104, 112). Każda jednostka obliczeniowa (CU) zapewnia 2 GB pamięci RAM.
Uwaga / Notatka
Lakebase Provisioned vs Autoscaling: W trybie Lakebase Provisioned każda jednostka obliczeniowa przydziela około 16 GB pamięci RAM. W usłudze Lakebase Autoscaling każdy CU przydziela 2 GB pamięci RAM. Ta zmiana zapewnia bardziej szczegółowe opcje skalowania i kontrolę kosztów.
Rozmiary reprezentatywne:
| Jednostki obliczeniowe | RAM |
|---|---|
| 0,5 CU | 1 GB |
| 1 CU | 2 GB |
| 4 jednostki obliczeniowe (CU) | 8 GB |
| 8 Jednostki Obliczeniowe (CU) | 16 GB |
| 16 jednostek obliczeniowych | 32 GB |
| 32 jednostki obliczeniowe (CU) | 64 GB |
| 64 Jednostek Obliczeniowych (CU) | 128 GB |
| 112 CU | 224 GB |
- Aby włączyć skalowanie automatyczne, ustaw zakres rozmiarów obliczeniowych za pomocą suwaka. Skalowanie automatyczne dynamicznie dostosowuje zasoby obliczeniowe na podstawie zapotrzebowania na obciążenia. Dowiedz się więcej: Skalowanie automatyczne
- Dostosuj ustawienie skalowania do zera, aby zwiększyć lub zmniejszyć ilość nieaktywnego czasu obliczeniowego przed wstrzymaniem obliczeń. Możesz również wyłączyć skalowanie do zera, aby zasoby obliczeniowe były zawsze aktywne. Dowiedz się więcej: Skalowanie do zera
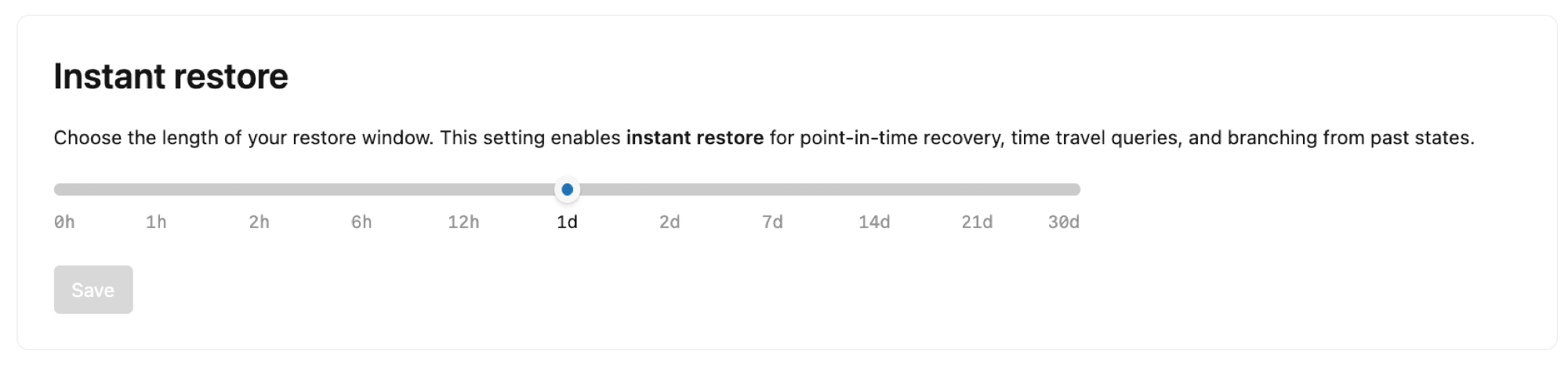
Natychmiastowe przywracanie
Skonfiguruj długość okna przywracania dla projektu. Domyślnie usługa Lakebase zachowuje historię zmian gałęzi głównych w projekcie, umożliwiając przywracanie do punktu w czasie na potrzeby odzyskiwania utraconych danych, wykonywanie zapytań dotyczących danych w danym momencie na potrzeby badania problemów z danymi i rozgałęzianie z poprzednich stanów dla przepływów pracy programowania.
Możesz ustawić okno przywracania z 2 dni do 30 dni. Należy pamiętać, że:
- Wydłużenie czasu okna przywracania zwiększa przestrzeń przechowywania
- Ustawienie okna przywracania ma wpływ na wszystkie gałęzie w projekcie
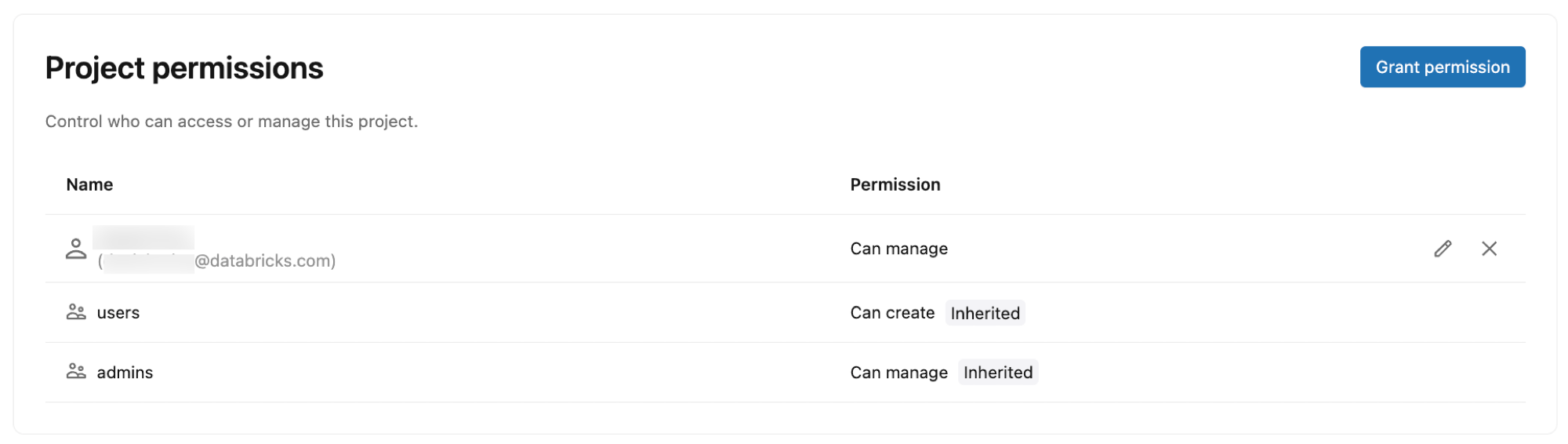
Uprawnienia projektu
Kontroluj dostęp do projektu Lakebase i zarządzaj nim, udzielając uprawnień tożsamościom, grupom i głównym usługom Azure Databricks. Uprawnienia projektowe określają, jakie działania użytkownicy mogą wykonywać w ramach projektu, takie jak tworzenie gałęzi, zarządzanie obliczeniami i wyświetlanie szczegółów połączenia.
Typy uprawnień:
- CAN CREATE: Wyświetlanie i tworzenie zasobów projektu
- MOŻE UŻYWAĆ: Wyświetlanie i używanie zasobów projektu (lista, wyświetlanie, łączenie i wykonywanie określonych operacji gałęzi) bez tworzenia lub usuwania projektów lub gałęzi
- MOŻE ZARZĄDZAĆ: Pełna kontrola nad konfiguracją i zasobami projektu
Uprawnienia domyślne:
Podczas tworzenia projektu są automatycznie przypisywane następujące uprawnienia:
- Właściciel projektu (użytkownik, który utworzył projekt): ZARZĄDZA (pełna kontrola)
- Użytkownicy obszaru roboczego: CAN CREATE (może wyświetlać i tworzyć projekty)
- Administratorzy obszaru roboczego: MOŻE ZARZĄDZAĆ (pełna kontrola)
Aby udzielić dostępu innym użytkownikom, zobacz Zarządzanie uprawnieniami projektu.
Uwaga / Notatka
uprawnienia Project i dostęp do bazy danych są oddzielne
Uprawnienia projektowe kontrolują akcje platformy Lakebase, podczas gdy dostęp do bazy danych jest kontrolowany przez role Postgres i skojarzone z nimi uprawnienia. Zobacz Tworzenie ról bazy danych Postgres i Zarządzanie uprawnieniami bazy danych.
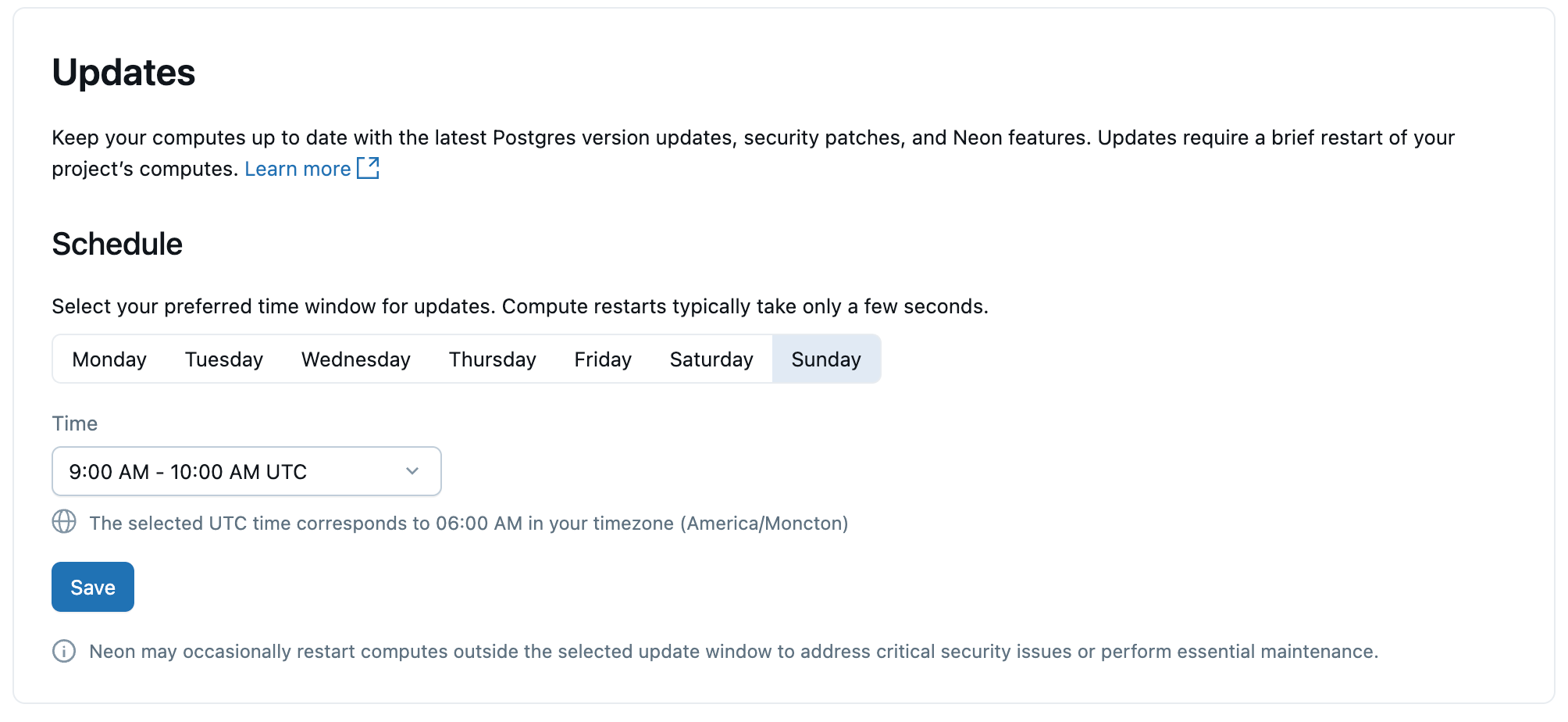
Aktualizacje
Aby Twoje wystąpienia obliczeniowe i bazy danych Postgres w usłudze Lakebase były zawsze aktualne, Lakebase automatycznie stosuje zaplanowane aktualizacje, które obejmują uaktualnienia wersji podrzędnych Postgres, poprawki zabezpieczeń i funkcje platformy. Aktualizacje są stosowane do obliczeń w projekcie i wymagają krótkiego ponownego uruchomienia obliczeniowego, które trwa kilka sekund.
Aktualizacje są stosowane automatycznie, ale można ustawić preferowany dzień i godzinę aktualizacji. Ponowne uruchomienia są wykonywane w wybranym przedziale czasu.
Aby uzyskać szczegółowe informacje o aktualizacjach, zobacz Zarządzanie aktualizacjami.
Usuwanie projektu
Usunięcie projektu to stała akcja, która usuwa również wszystkie obliczenia, gałęzie, bazy danych, role i dane należące do projektu.
Ważne
Tej akcji nie można cofnąć. Należy zachować ostrożność podczas usuwania projektu, ponieważ powoduje to usunięcie wszystkich skojarzonych gałęzi i danych.
Przed usunięciem
Usługa Databricks zaleca usunięcie wszystkich skojarzonych katalogów Unity Catalog i zsynchronizowanych tabel przed usunięciem projektu. W przeciwnym razie próba wyświetlenia wykazów lub uruchomienia zapytań SQL odwołujących się do nich powoduje błędy.
Jeśli nie jesteś właścicielem tabel lub katalogów, przed usunięciem musisz ponownie przypisać własność do siebie.
Uwaga / Notatka
Tylko użytkownicy z uprawnieniami CAN MANAGE w projekcie Lakebase mogą go usunąć. Aby uzyskać szczegółowe informacje, zobacz Project ACL i Zarządzaj uprawnieniami project.
Usuwanie projektu
Aby usunąć projekt:
interfejs użytkownika
- Przejdź do obszaru Ustawienia projektu w aplikacji Lakebase.
- W sekcji Usuwanie projektu kliknij pozycję Usuń i wprowadź nazwę projektu, aby potwierdzić usunięcie.
zestaw SDK Python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name}")
Jest to długotrwała operacja. Projekt i wszystkie jego zasoby (gałęzie, punkty końcowe, bazy danych, role, dane) zostaną usunięte.
zestaw SDK Java
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
Jest to długotrwała operacja. Projekt i wszystkie jego zasoby (gałęzie, punkty końcowe, bazy danych, role, dane) zostaną usunięte.
CLI
# Delete a project
databricks postgres delete-project projects/my-project
To polecenie zwraca wynik natychmiast. Projekt i wszystkie jego zasoby zostaną usunięte.
skręt
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Jest to długotrwała operacja. Odpowiedź zawiera nazwę operacji, której można użyć do sprawdzenia stanu usunięcia.