Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na końcu tego przewodnika będziesz mieć uruchomioną bazę danych Postgres z przykładowymi danymi gotowymi do nawiązania połączenia z aplikacją lub zintegrować ją z usługą Databricks Lakehouse.
Kroki: (1) Tworzenie → projektu (2) Łączenie → (3) Tworzenie tabeli
Krok 1. Tworzenie pierwszego projektu
Otwórz aplikację Lakebase z przełącznika aplikacji.
Wybierz pozycję Autoskalowanie , aby uzyskać dostęp do interfejsu użytkownika skalowania automatycznego usługi Lakebase.
Kliknij pozycję Nowy projekt. Nadaj projektowi nazwę i wybierz wersję bazy danych Postgres. Projekt jest tworzony przy użyciu jednej production gałęzi, domyślnej databricks_postgres bazy danych i zasobów obliczeniowych skonfigurowanych dla gałęzi.
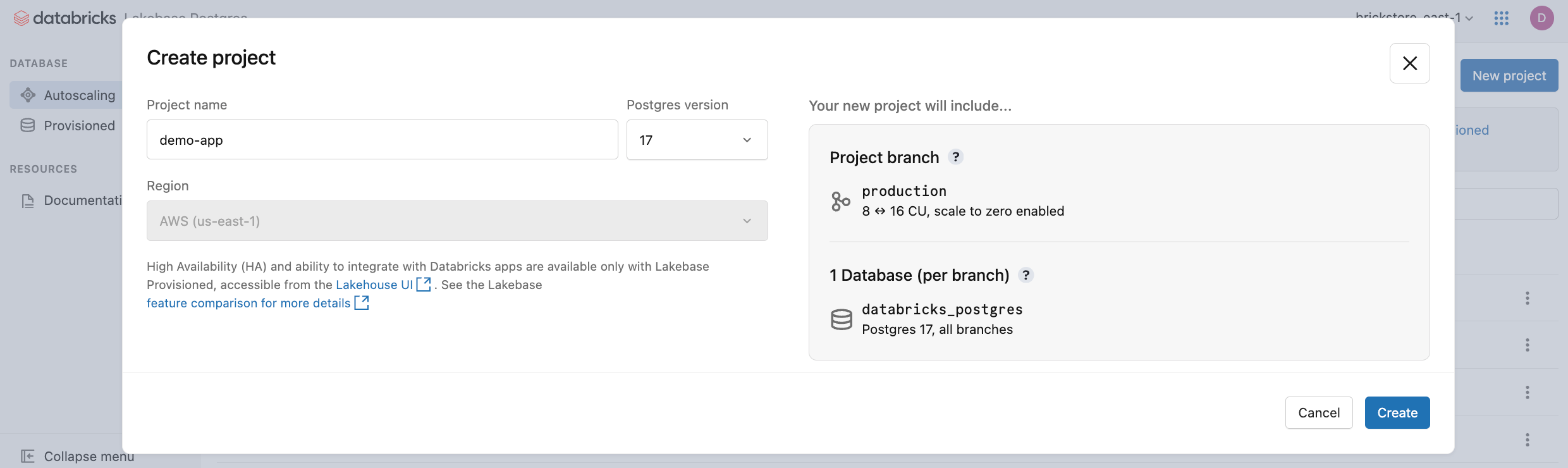
Aktywacja zasobów obliczeniowych może potrwać kilka minut. Obliczenia dla production gałęzi mają domyślnie włączone skalowanie do zera z 24-godzinnym limitem czasu braku aktywności, ale w razie potrzeby można skonfigurować to ustawienie.
Region projektu jest automatycznie ustawiany na region obszaru roboczego. Zobacz Dostępność regionów.
Dowiedz się więcej: Tworzenie projektu | Automatyczne skalowanie | Skalowanie do zera
Krok 2. Nawiązywanie połączenia z bazą danych
W projekcie wybierz gałąź produkcyjną , a następnie kliknij pozycję Połącz. Parametry połączenia działają z dowolnym standardowym klientem Postgres (psql, pgAdmin, DBeaver lub frameworkami aplikacji).
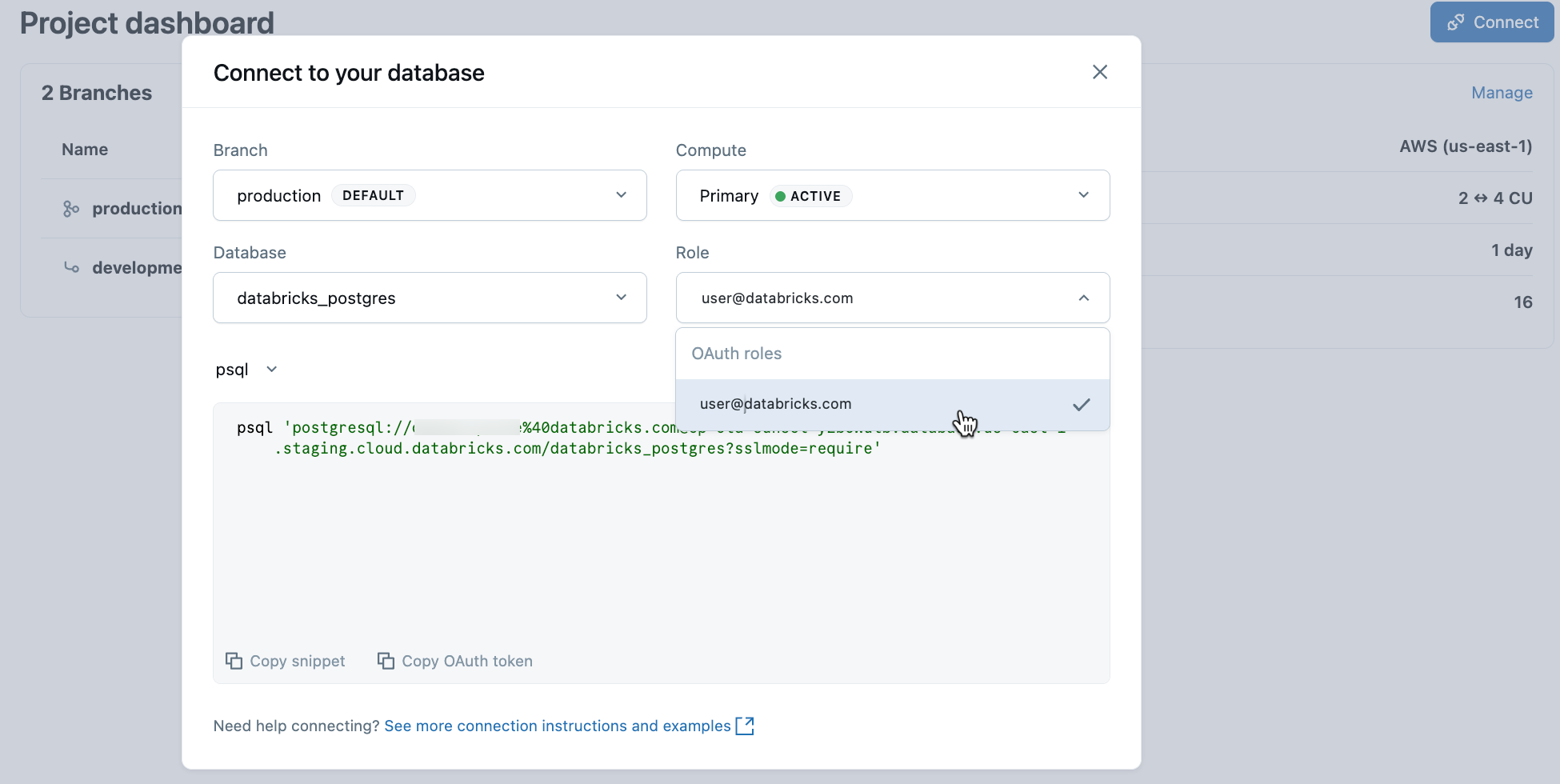
Aby nawiązać połączenie z tożsamością usługi Databricks, skopiuj psql fragment kodu z okna dialogowego połączenia i wklej token OAuth po wyświetleniu monitu:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Dowiedz się więcej: Szybki Start połączenia | psql | , pgAdmin | , klienci Postgres
Krok 3. Tworzenie pierwszej tabeli
Edytor SQL Lakebase zawiera przykładowy kod SQL. W projekcie wybierz gałąź produkcyjną , otwórz edytor SQL i uruchom podane instrukcje, aby utworzyć tabelę playing_with_lakebase i wstawić przykładowe dane.
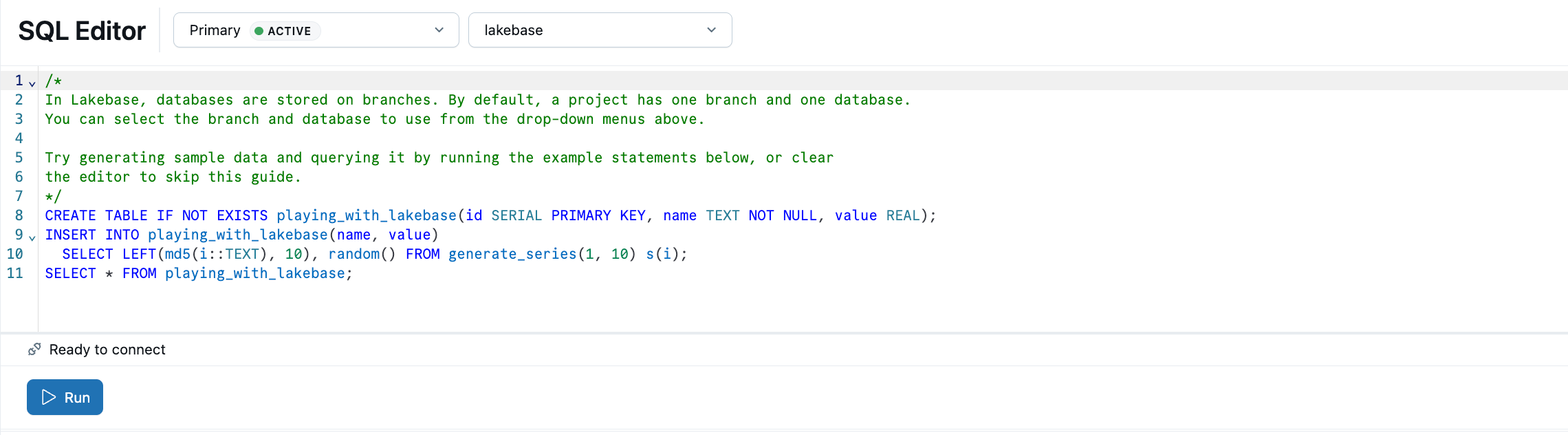
Dowiedz się więcej:Edytor SQL | Edytor tabel | Klienci Postgres
Dalsze kroki
| Następny krok | Opis |
|---|---|
| Udostępnianie danych lakehouse | Synchronizować tabele Unity Catalog do Postgres na potrzeby aplikacji wymagających odczytów z małymi opóźnieniami. |
Learn more
| Resource | Opis |
|---|---|
| Budowanie aplikacji | Wdróż aplikację Databricks z automatycznym połączeniem z usługą Lakebase. |
| Rejestrowanie w Unity Catalog | Ujednolicone zarządzanie, śledzenie pochodzenia danych i zapytania obejmujące wiele źródeł. |
| Podstawowe pojęcia | Skalowanie automatyczne, skalowanie do zera, rozgałęzianie i sposób ich działania. |
| Projekty | Omówienie architektury, modelu rozgałęziania i produktu. |