Regionalne odzyskiwanie po awarii dla klastrów usługi Azure Databricks
W tym artykule opisano architekturę odzyskiwania po awarii przydatną dla klastrów usługi Azure Databricks oraz kroki do wykonania tego projektu.
Architektura usługi Azure Databricks
Podczas tworzenia obszaru roboczego usługi Azure Databricks z witryny Azure Portal zarządzana aplikacja jest wdrażana jako zasób platformy Azure w ramach subskrypcji w wybranym regionie świadczenia usługi Azure (na przykład Zachodnie stany USA). To urządzenie jest wdrażane w sieci wirtualnej platformy Azure z siecią zabezpieczeń i kontem usługi Azure Storage dostępnym w ramach subskrypcji. Sieć wirtualna zapewnia zabezpieczenia na poziomie obwodu obszaru roboczego usługi Databricks i jest chroniona za pośrednictwem sieciowej grupy zabezpieczeń. W obszarze roboczym utworzysz klastry usługi Databricks, udostępniając typ maszyny wirtualnej procesu roboczego i sterowników oraz wersję środowiska uruchomieniowego usługi Databricks. Utrwalone dane są dostępne na koncie magazynu. Po utworzeniu klastra można uruchamiać zadania za pośrednictwem notesów, interfejsów API REST lub punktów końcowych ODBC/JDBC, dołączając je do określonego klastra.
Płaszczyzna sterowania usługi Databricks zarządza środowiskiem obszaru roboczego usługi Databricks i monitoruje je. Każda operacja zarządzania, taka jak tworzenie klastra, zostanie zainicjowana z płaszczyzny sterowania. Wszystkie metadane, takie jak zaplanowane zadania, są przechowywane w usłudze Azure Database, a kopie zapasowe bazy danych są automatycznie replikowane geograficznie do sparowanych regionów , w których są implementowane.
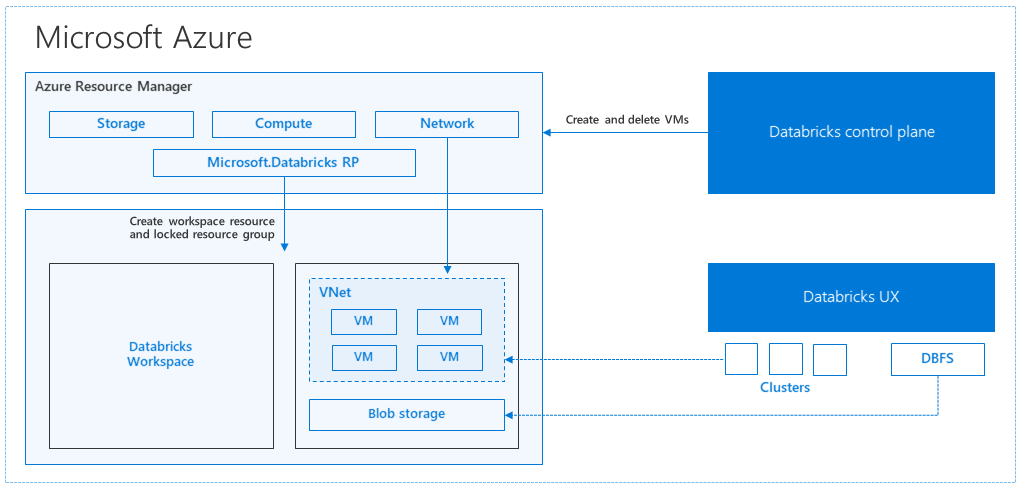
Jedną z zalet tej architektury jest to, że użytkownicy mogą łączyć usługę Azure Databricks z dowolnym zasobem magazynu na swoim koncie. Kluczową korzyścią jest to, że zarówno zasoby obliczeniowe (Azure Databricks) jak i magazyn mogą być skalowane niezależnie od siebie.
Jak utworzyć regionalną topologię odzyskiwania po awarii
W powyższym opisie architektury istnieje wiele składników używanych do potoku danych big data za pomocą usługi Azure Databricks: Azure Storage, Azure Database i innych źródeł danych. Usługa Azure Databricks to obliczenia dla potoku danych big data. Jest to charakter efemeryczny , co oznacza, że chociaż dane są nadal dostępne w usłudze Azure Storage, obliczenia (klaster usługi Azure Databricks) można zakończyć, aby uniknąć płacenia za obliczenia, gdy nie są potrzebne. Źródła zasobów obliczeniowych (Azure Databricks) i magazynu muszą znajdować się w tym samym regionie, aby zadania nie doświadczały dużego opóźnienia.
Aby utworzyć własną regionalną topologię odzyskiwania po awarii, wykonaj następujące wymagania:
Aprowizuj wiele obszarów roboczych usługi Azure Databricks w oddzielnych regionach świadczenia usługi Azure. Na przykład utwórz podstawowy obszar roboczy usługi Azure Databricks w regionie Wschodnie stany USA. Utwórz pomocniczy obszar roboczy odzyskiwania po awarii usługi Azure Databricks w osobnym regionie, takim jak Zachodnie stany USA. Aby uzyskać listę sparowanych regionów świadczenia usługi Azure, zobacz Replikacja między regionami. Aby uzyskać szczegółowe informacje na temat regionów usługi Azure Databricks, zobacz Obsługiwane regiony.
Użyj magazynu geograficznie nadmiarowego. Domyślnie dane skojarzone z usługą Azure Databricks są przechowywane w usłudze Azure Storage, a wyniki zadań usługi Databricks są przechowywane w usłudze Azure Blob Storage, dzięki czemu przetworzone dane są trwałe i pozostają wysoce dostępne po zakończeniu działania klastra. Magazyn klastra i magazyn zadań znajdują się w tej samej strefie dostępności. Aby chronić się przed niedostępnością regionalną, obszary robocze usługi Azure Databricks domyślnie używają magazynu geograficznie nadmiarowego. W przypadku magazynu geograficznie nadmiarowego dane są replikowane do sparowanego regionu platformy Azure. Usługa Databricks zaleca zachowanie domyślnego magazynu geograficznie nadmiarowego, ale jeśli zamiast tego musisz użyć magazynu lokalnie nadmiarowego, możesz ustawić
storageAccountSkuNamewartość naStandard_LRSw szablonie usługi ARM dla obszaru roboczego.Po utworzeniu regionu pomocniczego należy przeprowadzić migrację użytkowników, folderów użytkowników, notesów, konfiguracji klastra, konfiguracji zadań, bibliotek, magazynu, skryptów inicjowania i ponownej konfiguracji kontroli dostępu. Dodatkowe szczegóły opisano w poniższej sekcji.
Katastrofa regionalna
Aby przygotować się do regionalnych awarii, należy jawnie zachować inny zestaw obszarów roboczych usługi Azure Databricks w regionie pomocniczym. Zobacz Odzyskiwanie po awarii.
Naszymi zalecanymi narzędziami do odzyskiwania po awarii są głównie narzędzia Terraform (w przypadku replikacji infrastruktury) i delta Deep Clone (na potrzeby replikacji danych).
Szczegółowe kroki migracji
Konfigurowanie interfejsu wiersza polecenia usługi Databricks na komputerze
W tym artykule przedstawiono wiele przykładów kodu, które używają interfejsu wiersza polecenia w większości zautomatyzowanych kroków, ponieważ jest to łatwa otoka interfejsu API REST usługi Azure Databricks.
Przed wykonaniem jakichkolwiek kroków migracji zainstaluj interfejs wiersza polecenia usługi databricks na komputerze stacjonarnym lub maszynie wirtualnej, na której planujesz wykonać pracę. Aby uzyskać więcej informacji, zobacz Instalowanie interfejsu wiersza polecenia usługi Databricks
pip install databricks-cliUwaga
Wszystkie skrypty języka Python podane w tym artykule powinny współdziałać z językiem Python 2.7+ < 3.x.
Skonfiguruj dwa profile.
Skonfiguruj jeden dla podstawowego obszaru roboczego, a drugi dla pomocniczego obszaru roboczego:
databricks configure --profile primary --token databricks configure --profile secondary --tokenBloki kodu w tym artykule przełączają się między profilami w każdym kolejnym kroku przy użyciu odpowiedniego polecenia obszaru roboczego. Upewnij się, że nazwy utworzonych profilów są zastępowane do każdego bloku kodu.
EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary"W razie potrzeby możesz ręcznie przełączać się w wierszu polecenia:
databricks workspace ls --profile primary databricks workspace ls --profile secondaryMigrowanie użytkowników usługi Microsoft Entra ID (dawniej Azure Active Directory)
Ręcznie dodaj tych samych użytkowników microsoft Entra ID (dawniej Azure Active Directory) do pomocniczego obszaru roboczego, który istnieje w podstawowym obszarze roboczym.
Migrowanie folderów użytkowników i notesów
Użyj następującego kodu w języku Python, aby przeprowadzić migrację środowisk użytkownika w trybie piaskownicy, w tym struktury zagnieżdżonych folderów i notesów dla poszczególnych użytkowników.
Uwaga
Biblioteki nie są kopiowane w tym kroku, ponieważ podstawowy interfejs API nie obsługuje tych bibliotek.
Skopiuj i zapisz następujący skrypt języka Python do pliku i uruchom go w wierszu polecenia usługi Databricks. Na przykład
python scriptname.py.import sys import os import subprocess from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get a list of all users user_list_out = check_output(["databricks", "workspace", "ls", "/Users", "--profile", EXPORT_PROFILE]) user_list = (user_list_out.decode(encoding="utf-8")).splitlines() print (user_list) # Export sandboxed environment(folders, notebooks) for each user and import into new workspace. #Libraries are not included with these APIs / commands. for user in user_list: #print("Trying to migrate workspace for user ".decode() + user) print (("Trying to migrate workspace for user ") + user) subprocess.call(str("mkdir -p ") + str(user), shell = True) export_exit_status = call("databricks workspace export_dir /Users/" + str(user) + " ./" + str(user) + " --profile " + EXPORT_PROFILE, shell = True) if export_exit_status==0: print ("Export Success") import_exit_status = call("databricks workspace import_dir ./" + str(user) + " /Users/" + str(user) + " --profile " + IMPORT_PROFILE, shell=True) if import_exit_status==0: print ("Import Success") else: print ("Import Failure") else: print ("Export Failure") print ("All done")Migrowanie konfiguracji klastra
Po przeprowadzeniu migracji notesów możesz opcjonalnie przeprowadzić migrację konfiguracji klastra do nowego obszaru roboczego. Jest to prawie w pełni zautomatyzowany krok przy użyciu interfejsu wiersza polecenia usługi Databricks, chyba że chcesz przeprowadzić selektywną migrację konfiguracji klastra, a nie dla wszystkich.
Uwaga
Niestety nie ma punktu końcowego konfiguracji klastra, a ten skrypt próbuje utworzyć każdy klaster od razu. Jeśli w subskrypcji nie ma wystarczającej liczby rdzeni, tworzenie klastra może zakończyć się niepowodzeniem. Awarię można zignorować, o ile konfiguracja zostanie pomyślnie przeniesiona.
Poniższy skrypt wyświetla mapowanie ze starego na nowe identyfikatory klastra, które mogą być później używane do migracji zadań (w przypadku zadań skonfigurowanych do korzystania z istniejących klastrów).
Skopiuj i zapisz następujący skrypt języka Python do pliku i uruchom go w wierszu polecenia usługi Databricks. Na przykład
python scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Get all clusters info from old workspace clusters_out = check_output(["databricks", "clusters", "list", "--profile", EXPORT_PROFILE]) clusters_info_list = str(clusters_out.decode(encoding="utf-8")). splitlines() print("Printting Cluster info List") print(clusters_info_list) # Create a list of all cluster ids clusters_list = [] ##for cluster_info in clusters_info_list: clusters_list.append (cluster_info.split(None, 1)[0]) for cluster_info in clusters_info_list: if cluster_info != '': clusters_list.append(cluster_info.split(None, 1)[0]) # Optionally filter cluster ids out manually, so as to create only required ones in new workspace # Create a list of mandatory / optional create request elements cluster_req_elems = ["num_workers","autoscale","cluster_name","spark_version","spark_conf","node_type_id","driver_node_type_id","custom_tags","cluster_log_conf","spark_env_vars","autotermination_minutes","enable_elastic_disk"] print("Printing Cluster element List") print (cluster_req_elems) print(str(len(clusters_list)) + " clusters found in the primary site" ) print ("---------------------------------------------------------") # Try creating all / selected clusters in new workspace with same config as in old one. cluster_old_new_mappings = {} i = 0 for cluster in clusters_list: i += 1 print("Checking cluster " + str(i) + "/" + str(len(clusters_list)) + " : " +str(cluster)) cluster_get_out_f = check_output(["databricks", "clusters", "get", "--cluster-id", str(cluster), "--profile", EXPORT_PROFILE]) cluster_get_out=str(cluster_get_out_f.decode(encoding="utf-8")) print ("Got cluster config from old workspace") print (cluster_get_out) # Remove extra content from the config, as we need to build create request with allowed elements only cluster_req_json = json.loads(cluster_get_out) cluster_json_keys = cluster_req_json.keys() #Don't migrate Job clusters if cluster_req_json['cluster_source'] == u'JOB' : print ("Skipping this cluster as it is a Job cluster : " + cluster_req_json['cluster_id'] ) print ("---------------------------------------------------------") continue #cluster_req_json.pop(key, None) for key in cluster_json_keys: if key not in cluster_req_elems: print (cluster_req_json) #cluster_del_item=cluster_json_keys .keys() cluster_req_json.popitem(key, None) # Create the cluster, and store the mapping from old to new cluster ids #Create a temp file to store the current cluster info as JSON strCurrentClusterFile = "tmp_cluster_info.json" #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) fClusterJSONtmp = open(strCurrentClusterFile,"w+") fClusterJSONtmp.write(json.dumps(cluster_req_json)) fClusterJSONtmp.close() #cluster_create_out = check_output(["databricks", "clusters", "create", "--json", json.dumps(cluster_req_json), "--profile", IMPORT_PROFILE]) cluster_create_out = check_output(["databricks", "clusters", "create", "--json-file", strCurrentClusterFile , "--profile", IMPORT_PROFILE]) cluster_create_out_json = json.loads(cluster_create_out) cluster_old_new_mappings[cluster] = cluster_create_out_json['cluster_id'] print ("Cluster create request sent to secondary site workspace successfully") print ("---------------------------------------------------------") #delete the temp file if exists if os.path.exists(strCurrentClusterFile) : os.remove(strCurrentClusterFile) print ("Cluster mappings: " + json.dumps(cluster_old_new_mappings)) print ("All done") print ("P.S. : Please note that all the new clusters in your secondary site are being started now!") print (" If you won't use those new clusters at the moment, please don't forget terminating your new clusters to avoid charges")Migrowanie konfiguracji zadań
W przypadku migracji konfiguracji klastra w poprzednim kroku możesz zdecydować się na migrację konfiguracji zadań do nowego obszaru roboczego. Jest to w pełni zautomatyzowany krok przy użyciu interfejsu wiersza polecenia usługi Databricks, chyba że chcesz przeprowadzić selektywną migrację konfiguracji zadań zamiast wykonywać je dla wszystkich zadań.
Uwaga
Konfiguracja zaplanowanego zadania zawiera również informacje o harmonogramie, więc domyślnie rozpocznie ono pracę zgodnie ze skonfigurowanym czasem, gdy tylko zostanie zmigrowany. W związku z tym poniższy blok kodu usuwa wszelkie informacje o harmonogramie podczas migracji (aby uniknąć zduplikowanych przebiegów w starych i nowych obszarach roboczych). Skonfiguruj harmonogramy takich zadań po dokonaniu migracji jednorazowej.
Konfiguracja zadania wymaga ustawień dla nowego lub istniejącego klastra. Jeśli używasz istniejącego klastra, skrypt /code poniżej podejmie próbę zastąpienia starego identyfikatora klastra nowym identyfikatorem klastra.
Skopiuj i zapisz następujący skrypt języka Python do pliku. Zastąp wartość parametru
old_cluster_idinew_cluster_idwartością , a dane wyjściowe z migracji klastra zostały wykonane w poprzednim kroku. Uruchom go w wierszu polecenia usługi databricks-cli, na przykładpython scriptname.py.import sys import os import subprocess import json from subprocess import call, check_output EXPORT_PROFILE = "primary" IMPORT_PROFILE = "secondary" # Please replace the old to new cluster id mappings from cluster migration output cluster_old_new_mappings = {"0227-120427-tryst214": "0229-032632-paper88"} # Get all jobs info from old workspace try: jobs_out = check_output(["databricks", "jobs", "list", "--profile", EXPORT_PROFILE]) jobs_info_list = jobs_out.splitlines() except: print("No jobs to migrate") sys.exit(0) # Create a list of all job ids jobs_list = [] for jobs_info in jobs_info_list: jobs_list.append(jobs_info.split(None, 1)[0]) # Optionally filter job ids out manually, so as to create only required ones in new workspace # Create each job in the new workspace based on corresponding settings in the old workspace for job in jobs_list: print("Trying to migrate ") + job job_get_out = check_output(["databricks", "jobs", "get", "--job-id", job, "--profile", EXPORT_PROFILE]) print("Got job config from old workspace") job_req_json = json.loads(job_get_out) job_req_settings_json = job_req_json['settings'] # Remove schedule information so job doesn't start before proper cutover job_req_settings_json.pop('schedule', None) # Replace old cluster id with new cluster id, if job configured to run against an existing cluster if 'existing_cluster_id' in job_req_settings_json: if job_req_settings_json['existing_cluster_id'] in cluster_old_new_mappings: job_req_settings_json['existing_cluster_id'] = cluster_old_new_mappings[job_req_settings_json['existing_cluster_id']] else: print("Mapping not available for old cluster id ") + job_req_settings_json['existing_cluster_id'] continue call(["databricks", "jobs", "create", "--json", json.dumps(job_req_settings_json), "--profile", IMPORT_PROFILE]) print("Sent job create request to new workspace successfully") print("All done")Migrowanie bibliotek
Obecnie nie ma prostego sposobu migrowania bibliotek z jednego obszaru roboczego do innego. Zamiast tego ponownie zainstaluj te biblioteki w nowym obszarze roboczym ręcznie. Istnieje możliwość zautomatyzowania korzystania z kombinacji interfejsu wiersza polecenia systemu plików DBFS w celu przekazania bibliotek niestandardowych do obszaru roboczego i interfejsu wiersza polecenia bibliotek.
Migrowanie usługi Azure Blob Storage i instalacji usługi Azure Data Lake Storage
Ręcznie zainstaluj ponownie wszystkie punkty instalacji usługi Azure Blob Storage i Azure Data Lake Storage (Gen 2) przy użyciu rozwiązania opartego na notesach. Zasoby magazynu zostałyby zainstalowane w podstawowym obszarze roboczym i muszą być powtarzane w pomocniczym obszarze roboczym. Nie ma zewnętrznego interfejsu API dla instalacji.
Migrowanie skryptów inicjowania klastra
Wszystkie skrypty inicjowania klastra można migrować ze starego do nowego obszaru roboczego przy użyciu interfejsu wiersza polecenia systemu plików DBFS. Najpierw skopiuj wymagane skrypty z
dbfs:/dat abricks/init/..komputera lokalnego lub maszyny wirtualnej. Następnie skopiuj te skrypty do nowego obszaru roboczego w tej samej ścieżce.// Primary to local dbfs cp -r dbfs:/databricks/init ./old-ws-init-scripts --profile primary // Local to Secondary workspace dbfs cp -r old-ws-init-scripts dbfs:/databricks/init --profile secondaryRęcznie skonfiguruj ponownie i ponownie zastosuj kontrolę dostępu.
Jeśli istniejący podstawowy obszar roboczy jest skonfigurowany do korzystania z warstwy Premium lub Enterprise (SKU), prawdopodobnie używasz również funkcji Kontroli dostępu.
Jeśli używasz funkcji Kontrola dostępu, ręcznie ponownie zastosuj kontrolę dostępu do zasobów (notesy, klastry, zadania, tabele).
Odzyskiwanie po awarii dla ekosystemu platformy Azure
Jeśli używasz innych usług platformy Azure, pamiętaj również o zaimplementowaniu najlepszych rozwiązań dotyczących odzyskiwania po awarii dla tych usług. Jeśli na przykład zdecydujesz się użyć zewnętrznego wystąpienia magazynu metadanych Hive, rozważ odzyskanie po awarii dla usługi Azure SQL Database, azure HDInsight i/lub usługi Azure Database for MySQL. Aby uzyskać ogólne informacje na temat odzyskiwania po awarii, zobacz Odzyskiwanie po awarii dla aplikacji platformy Azure.
Następne kroki
Aby uzyskać więcej informacji, zobacz dokumentację usługi Azure Databricks.