Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule pokazano, jak wdrożyć aplikację Red Hat JBoss Enterprise Application Platform (EAP) w klastrze usługi Azure Red Hat OpenShift. Przykład jest aplikacją Java wspieraną przez bazę danych SQL. Aplikacja jest wdrażana przy użyciu pakietów Helm JBoss EAP.
Z tego przewodnika dowiesz się, jak wykonywać następujące działania:
- Przygotuj aplikację JBoss EAP dla platformy OpenShift.
- Utwórz pojedyncze wystąpienie bazy danych Azure SQL.
- Ponieważ tożsamość obciążenia platformy Azure nie jest jeszcze obsługiwana przez usługę Azure OpenShift, w tym artykule nadal jest używana nazwa użytkownika i hasło do uwierzytelniania bazy danych zamiast używania połączeń z bazą danych bez hasła.
- Wdrażanie aplikacji w klastrze usługi Azure Red Hat OpenShift przy użyciu pakietów Helm JBoss i konsoli internetowej OpenShift
Przykładowa aplikacja to stanowa aplikacja, która przechowuje informacje w sesji HTTP. Korzysta z funkcji klastrowania JBoss EAP i korzysta z następujących technologii Jakarta EE i MicroProfile:
- Twarze serwera Dżakarta
- Fasola dżakarta Enterprise
- Trwałość Dżakarta
- Kondycja mikroprofile
Ten artykuł zawiera szczegółowe wskazówki dotyczące uruchamiania aplikacji JBoss EAP w klastrze Usługi Azure Red Hat OpenShift. Aby uzyskać bardziej zautomatyzowane rozwiązanie, które przyspiesza podróż do klastra usługi Azure Red Hat OpenShift, zobacz Szybki start: wdrażanie protokołu EAP JBoss w usłudze Azure Red Hat OpenShift przy użyciu witryny Azure Portal.
Jeśli chcesz przekazać opinię lub ściśle pracować nad scenariuszem migracji z zespołem inżynierów opracowującym rozwiązanie JBoss EAP na platformie Azure, wypełnij tę krótką ankietę dotyczącą migracji JBoss EAP i dołącz swoje informacje kontaktowe. Zespół menedżerów programów, architektów i inżynierów natychmiast skontaktuje się z Tobą w celu zainicjowania ścisłej współpracy.
Ważne
W tym artykule wdrożono aplikację przy użyciu pakietów Helm JBoss EAP. W momencie pisania tego artykułu ta funkcja jest nadal oferowana jako wersja Zapoznawcza Technologii. Przed podjęciem decyzji o wdrażaniu aplikacji za pomocą pakietów Helm JBoss EAP w środowiskach produkcyjnych upewnij się, że ta funkcja jest obsługiwaną funkcją dla wersji produktu JBoss EAP/XP.
Ważne
Podczas gdy firmy Red Hat i Microsoft Azure wspólnie projektują, zarządzają i obsługują usługę Azure Red Hat OpenShift, aby zapewnić zintegrowane wsparcie techniczne, oprogramowanie uruchamiane na platformie Azure Red Hat OpenShift, w tym opisane w tym artykule, podlega własnym warunkom wsparcia technicznego i licencji. Aby uzyskać szczegółowe informacje o obsłudze usługi Azure Red Hat OpenShift, zobacz Cykl życia pomocy technicznej dla usługi Azure Red Hat OpenShift 4. Aby uzyskać szczegółowe informacje o obsłudze oprogramowania opisanego w tym artykule, zobacz strony główne dotyczące tego oprogramowania zgodnie z opisem w artykule.
Wymagania wstępne
Uwaga
Usługa Azure Red Hat OpenShift wymaga co najmniej 40 rdzeni do utworzenia i uruchomienia klastra OpenShift. Domyślny limit przydziału zasobów platformy Azure dla nowej subskrypcji platformy Azure nie spełnia tego wymagania. Aby zażądać zwiększenia limitu zasobów, zobacz Limit przydziału w warstwie Standardowa: Zwiększanie limitów według serii maszyn wirtualnych. Subskrypcja bezpłatnej wersji próbnej nie kwalifikuje się do zwiększenia limitu przydziału, uaktualnij do subskrypcji typu 'Pay-As-You-Go'You-Go przed zażądaniem zwiększenia limitu przydziału.
Przygotuj maszynę lokalną z systemem operacyjnym przypominającym system Unix obsługiwanym przez różne zainstalowane produkty — takie jak Ubuntu, macOS lub Podsystem Windows dla systemu Linux.
Zainstaluj implementację języka Java Standard Edition (SE). Lokalne kroki programistyczne w tym artykule zostały przetestowane przy użyciu zestawu Java Development Kit (JDK) 17 z kompilacji microsoft OpenJDK.
Zainstaluj program Maven 3.8.6 lub nowszy.
Zainstaluj interfejs wiersza polecenia platformy Azure w wersji 2.40 lub nowszej.
Sklonuj kod tej aplikacji demonstracyjnej (lista zadań do wykonania) do systemu lokalnego. Aplikacja demonstracyjna znajduje się w witrynie GitHub.
Postępuj zgodnie z instrukcjami w artykule Create an Azure Red Hat OpenShift 4 cluster (Tworzenie klastra usługi Azure Red Hat OpenShift 4).
Chociaż krok "Uzyskaj tajny klucz dostępu Red Hat" jest oznaczony jako opcjonalny, w tym artykule jest on wymagany. Wpis tajny ściągania umożliwia klastrowi usługi Azure Red Hat OpenShift znajdowanie obrazów aplikacji JBoss EAP.
Jeśli planujesz uruchamianie aplikacji intensywnie korzystających z pamięci w klastrze, określ odpowiedni rozmiar maszyny wirtualnej dla węzłów procesu roboczego przy użyciu parametru
--worker-vm-size. Aby uzyskać więcej informacji, zobacz:Połącz się z klastrem, wykonując kroki opisane w artykule Nawiązywanie połączenia z klastrem usługi Azure Red Hat OpenShift 4.
- Wykonaj kroki opisane w temacie "Instalowanie interfejsu wiersza polecenia platformy OpenShift"
- Nawiązywanie połączenia z klastrem usługi Azure Red Hat OpenShift przy użyciu interfejsu wiersza polecenia openShift z użytkownikiem
kubeadmin
Wykonaj następujące polecenie, aby utworzyć projekt OpenShift dla tej aplikacji demonstracyjnej:
oc new-project eap-demoWykonaj następujące polecenie, aby dodać rolę widoku do domyślnego konta usługi. Ta rola jest potrzebna, aby aplikacja mogła odnaleźć inne zasobniki i skonfigurować klaster przy użyciu nich:
oc policy add-role-to-user view system:serviceaccount:$(oc project -q):default -n $(oc project -q)
Przygotowywanie aplikacji
Sklonuj przykładową aplikację przy użyciu następującego polecenia:
git clone https://github.com/Azure-Samples/jboss-on-aro-jakartaee
Sklonowałeś aplikację demonstracyjną listy zadań do wykonania, a twoje lokalne repozytorium znajduje się na gałęzi main. Aplikacja demonstracyjna to prosta aplikacja Java, która tworzy, odczytuje, aktualizuje i usuwa rekordy w usłudze Azure SQL. Tę aplikację można wdrożyć na serwerze JBoss EAP zainstalowanym na komputerze lokalnym. Wystarczy skonfigurować serwer przy użyciu wymaganego sterownika bazy danych i źródła danych. Potrzebny jest również serwer bazy danych dostępny ze środowiska lokalnego.
Jednak jeśli używasz platformy OpenShift, możesz przyciąć możliwości serwera JBoss EAP. Na przykład możesz zmniejszyć narażenie na zabezpieczenia aprowizowanego serwera i zmniejszyć całkowity rozmiar. Możesz również uwzględnić niektóre specyfikacje microProfile, aby aplikacja bardziej odpowiednia do działania w środowisku OpenShift. W przypadku korzystania z protokołu JBoss EAP jednym ze sposobów wykonania tego zadania jest pakowanie aplikacji i serwera w jednej jednostce wdrażania znanej jako rozruchowy plik JAR. Zróbmy to, dodając wymagane zmiany do naszej aplikacji demonstracyjnej.
Przejdź do lokalnego repozytorium aplikacji demonstracyjnej i zmień gałąź na bootable-jar:
## cd jboss-on-aro-jakartaee
git checkout bootable-jar
Przyjrzyjmy się temu, co zmieniliśmy w tej gałęzi:
- Dodaliśmy wtyczkę
wildfly-jar-maven, aby aprowizować serwer i aplikację w jednym wykonywalnym pliku JAR. Jednostka wdrażania platformy OpenShift to nasz serwer z naszą aplikacją. - W wtyczki Maven określono zestaw warstw Galleon. Ta konfiguracja umożliwia przycinanie możliwości serwera tylko do tego, czego potrzebujemy. Pełną dokumentację dotyczącą Galleon można znaleźć w dokumentacji platformy WildFly.
- Nasza aplikacja używa twarzy Dżakarta z żądaniami Ajax, co oznacza, że w sesji HTTP są przechowywane informacje. Nie chcemy tracić takich informacji, jeśli zasobnik zostanie usunięty. Możemy zapisać te informacje na kliencie i wysłać je z powrotem na każde żądanie. Istnieją jednak przypadki, w których można zrezygnować z dystrybucji niektórych informacji do klientów. W tym pokazie wybraliśmy replikację sesji we wszystkich replikach zasobników. W tym celu dodaliśmy
<distributable />do web.xml. To, wraz z możliwościami klastrowania serwerów, sprawia, że sesja HTTP jest dystrybuowana we wszystkich zasobnikach. - Dodaliśmy dwie testy kondycji mikroprofile, które umożliwiają identyfikację, kiedy aplikacja jest aktywna i gotowa do odbierania żądań.
Lokalne uruchamianie aplikacji
Przed wdrożeniem aplikacji w usłudze OpenShift uruchomimy ją lokalnie, aby sprawdzić, jak działa. W poniższych krokach założono, że usługa Azure SQL jest uruchomiona i dostępna w środowisku lokalnym.
Aby utworzyć bazę danych, wykonaj kroki opisane w przewodniku Szybki start: tworzenie pojedynczej bazy danych usługi Azure SQL Database, ale użyj następujących podstawień.
- W przypadku grupy zasobów użyj utworzonej wcześniej grupy zasobów.
- W polu Nazwa bazy danych użyj .
todos_db - W przypadku logowania administratora serwera użyj polecenia
azureuser. - W przypadku hasła użyj polecenia
Passw0rd!. - W sekcji Reguły zapory przełącz opcję Zezwalaj usługom i zasobom platformy Azure na dostęp do tego serwera na wartość Tak.
Wszystkie inne ustawienia można bezpiecznie używać z połączonego artykułu.
Na stronie Dodatkowe ustawienia nie trzeba wybierać opcji wstępnego wypełniania bazy danych z przykładowymi danymi, ale nie ma żadnych szkód.
Po utworzeniu bazy danych pobierz wartość nazwy serwera ze strony przeglądu. Umieść kursor myszy nad wartością pola Nazwa serwera i wybierz ikonę kopiowania wyświetlaną obok wartości. Zapisz tę wartość do użycia później (ustawimy zmienną o nazwie MSSQLSERVER_HOST na tę wartość).
Uwaga
Aby utrzymać niskie koszty pieniężne, przewodnik Szybki start przekierowuje czytelnika do wybrania bezserwerowej warstwy obliczeniowej. Ten poziom jest skalowany do zera, gdy nie ma żadnej aktywności. W takim przypadku baza danych nie reaguje natychmiast. Jeśli w jakimkolwiek momencie wykonywania kroków opisanych w tym artykule zaobserwowano problemy z bazą danych, rozważ wyłączenie automatycznego wstrzymywania. Aby dowiedzieć się, jak wyszukiwać automatyczne wstrzymywanie w usłudze Azure SQL Database bezserwerowe. Podczas pisania tego artykułu następujące polecenie interfejsu wiersza polecenia platformy Azure wyłącza automatyczne wstrzymywanie bazy danych skonfigurowanej w tym artykule: az sql db update --resource-group $RESOURCEGROUP --server <Server name, without the .database.windows.net part> --name todos_db --auto-pause-delay -1
Wykonaj następne kroki, aby skompilować i uruchomić aplikację lokalnie.
Skompiluj rozruchowy plik JAR. Ponieważ używamy bazy
eap-datasources-galleon-packdanych MS SQL Server, musimy określić wersję sterownika bazy danych, której chcemy użyć z tą konkretną zmienną środowiskową. Aby uzyskać więcej informacji na temat programueap-datasources-galleon-packi programu MS SQL Server, zobacz dokumentację oprogramowania Red Hatexport MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 mvn clean packageUruchom rozruchowy plik JAR przy użyciu następujących poleceń.
Należy się upewnić, że baza danych Azure SQL Database zezwala na ruch sieciowy z hosta, na którym jest uruchomiony ten serwer. Ponieważ podczas wykonywania kroków opisanych w przewodniku Szybki start wybrano pozycję Dodaj bieżący adres IP klienta: Tworzenie pojedynczej bazy danych usługi Azure SQL Database, jeśli host, na którym jest uruchomiony serwer, jest tym samym hostem, z którego przeglądarka łączy się z witryną Azure Portal, ruch sieciowy powinien być dozwolony. Jeśli host, na którym działa serwer, jest innym hostem, zapoznaj się z artykułem Zarządzanie regułami zapory adresów IP na poziomie serwera za pomocą witryny Azure Portal.
Podczas uruchamiania aplikacji musimy przekazać wymagane zmienne środowiskowe, aby skonfigurować źródło danych:
export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:runUwaga
Firma Microsoft zaleca korzystanie z najbezpieczniejszego dostępnego przepływu uwierzytelniania. Przepływ uwierzytelniania opisany w tej procedurze, taki jak bazy danych, pamięci podręczne, komunikaty lub usługi sztucznej inteligencji, wymaga bardzo wysokiego stopnia zaufania w aplikacji i niesie ze sobą ryzyko, które nie występują w innych przepływach. Użyj tego przepływu tylko wtedy, gdy bardziej bezpieczne opcje, takie jak tożsamości zarządzane dla połączeń bez hasła lub bez kluczy, nie są opłacalne. W przypadku operacji maszyny lokalnej preferuj tożsamości użytkowników dla połączeń bez hasła lub bez klucza.
Jeśli chcesz dowiedzieć się więcej na temat bazowego środowiska uruchomieniowego używanego w tym pokazie, pakiet Funkcji Galleon do integrowania dokumentacji źródeł danych zawiera pełną listę dostępnych zmiennych środowiskowych. Aby uzyskać szczegółowe informacje na temat koncepcji pakietu feature-pack, zobacz dokumentację platformy WildFly.
Jeśli wystąpi błąd z tekstem podobnym do następującego przykładu:
Cannot open server '<your prefix>mysqlserver' requested by the login. Client with IP address 'XXX.XXX.XXX.XXX' is not allowed to access the server.Ten komunikat wskazuje, że kroki umożliwiające upewnienie się, że ruch sieciowy jest dozwolony, nie zadziałał. Upewnij się, że adres IP z komunikatu o błędzie jest uwzględniony w regułach zapory.
Jeśli zostanie wyświetlony komunikat z tekstem podobnym do następującego przykładu:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: There is already an object named 'TODOS' in the database.Ten komunikat wskazuje, że przykładowe dane są już w bazie danych. Ten komunikat można zignorować.
(Opcjonalnie) Jeśli chcesz zweryfikować możliwości klastrowania, możesz również uruchomić więcej wystąpień tej samej aplikacji, przekazując argument Bootable JAR
jboss.node.nameargument i, aby uniknąć konfliktów z numerami portów, przesuwając numery portów przy użyciu poleceniajboss.socket.binding.port-offset. Aby na przykład uruchomić drugie wystąpienie reprezentujące nowy zasobnik w usłudze OpenShift, możesz wykonać następujące polecenie w nowym oknie terminalu:export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:run -Dwildfly.bootable.arguments="-Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000"Uwaga
Firma Microsoft zaleca korzystanie z najbezpieczniejszego dostępnego przepływu uwierzytelniania. Przepływ uwierzytelniania opisany w tej procedurze, taki jak bazy danych, pamięci podręczne, komunikaty lub usługi sztucznej inteligencji, wymaga bardzo wysokiego stopnia zaufania w aplikacji i niesie ze sobą ryzyko, które nie występują w innych przepływach. Użyj tego przepływu tylko wtedy, gdy bardziej bezpieczne opcje, takie jak tożsamości zarządzane dla połączeń bez hasła lub bez kluczy, nie są opłacalne. W przypadku operacji maszyny lokalnej preferuj tożsamości użytkowników dla połączeń bez hasła lub bez klucza.
Jeśli klaster działa, możesz zobaczyć w konsoli serwera ślad podobny do następującego:
INFO [org.infinispan.CLUSTER] (thread-6,ejb,node) ISPN000094: Received new cluster view for channel ejbUwaga
Domyślnie rozruchowy plik JAR konfiguruje podsystem JGroups do korzystania z protokołu UDP i wysyła komunikaty w celu odnalezienia innych elementów członkowskich klastra na adres multiemisji 230.0.0.4. Aby prawidłowo sprawdzić możliwości klastrowania na komputerze lokalnym, system operacyjny powinien mieć możliwość wysyłania i odbierania multiemisji datagramów oraz kierowania ich do adresu IP 230.0.0.4 za pośrednictwem interfejsu ethernet. Jeśli widzisz ostrzeżenia związane z klastrem w dziennikach serwera, sprawdź konfigurację sieci i sprawdź, czy obsługuje multiemisji na tym adresie.
Otwórz http://localhost:8080/ w przeglądarce, aby odwiedzić stronę główną aplikacji. Jeśli utworzono więcej wystąpień, możesz uzyskać do nich dostęp, przenosząc numer portu, na przykład http://localhost:9080/. Aplikacja powinna wyglądać podobnie do poniższej ilustracji:
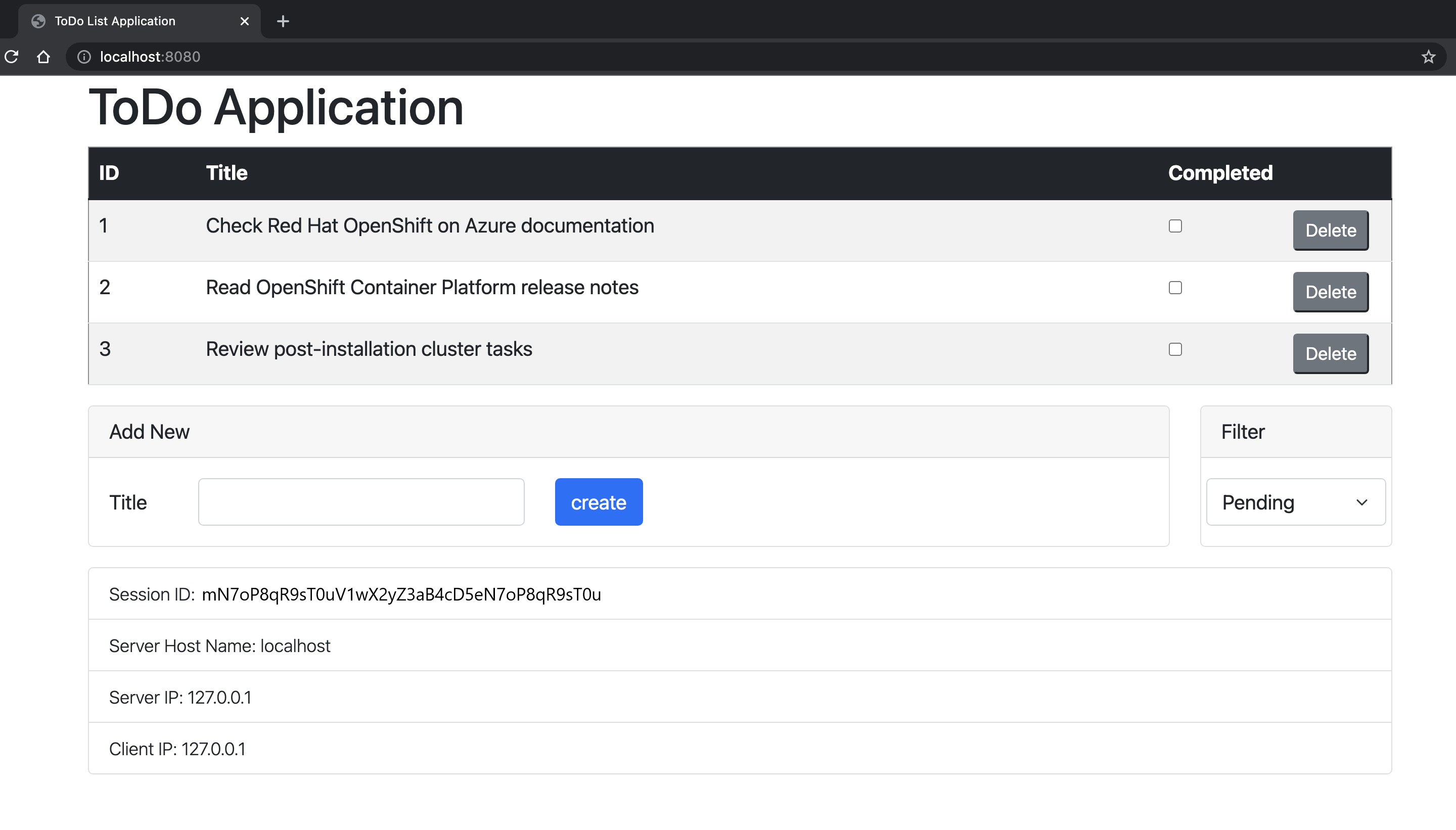
Sprawdź sondy dostępności i gotowości dla aplikacji. Usługa OpenShift używa tych punktów końcowych do sprawdzania, kiedy zasobnik jest na żywo i jest gotowy do odbierania żądań użytkowników.
Aby sprawdzić stan aktualności, uruchom polecenie:
curl http://localhost:9990/health/livePowinny być widoczne następujące dane wyjściowe:
{"status":"UP","checks":[{"name":"SuccessfulCheck","status":"UP"}]}Aby sprawdzić stan gotowości, uruchom polecenie:
curl http://localhost:9990/health/readyPowinny być widoczne następujące dane wyjściowe:
{"status":"UP","checks":[{"name":"deployments-status","status":"UP","data":{"todo-list.war":"OK"}},{"name":"server-state","status":"UP","data":{"value":"running"}},{"name":"boot-errors","status":"UP"},{"name":"DBConnectionHealthCheck","status":"UP"}]}Naciśnij Ctrl+C, aby zatrzymać aplikację.
Wdrażanie w usłudze OpenShift
Aby wdrożyć aplikację, użyjemy wykresów JBoss EAP Helm dostępnych już w usłudze Azure Red Hat OpenShift. Musimy również podać żądaną konfigurację, na przykład użytkownik bazy danych, hasło bazy danych, wersję sterownika, której chcemy użyć, oraz informacje o połączeniu używane przez źródło danych. W poniższych krokach założono, że usługa Azure SQL jest uruchomiona i dostępna z klastra OpenShift, a nazwa użytkownika bazy danych, hasło, nazwa hosta, port i nazwa bazy danych w obiekcie OpenShift OpenShift
Przejdź do lokalnego repozytorium aplikacji demonstracyjnej i zmień bieżącą gałąź na bootable-jar-openshift:
git checkout bootable-jar-openshift
Przyjrzyjmy się temu, co zmieniliśmy w tej gałęzi:
- Dodaliśmy nowy profil narzędzia Maven o nazwie
bootable-jar-openshift, który przygotowuje rozruchowy plik JAR z określoną konfiguracją do uruchamiania serwera w chmurze. Na przykład umożliwia podsystemowi JGroups używanie żądań sieciowych do odnajdywania innych zasobników przy użyciu protokołu KUBE_PING. - Dodaliśmy zestaw plików konfiguracji w katalogu jboss-on-aro-jakartaee/deployment . W tym katalogu można znaleźć pliki konfiguracji do wdrożenia aplikacji.
Wdrażanie aplikacji w usłudze OpenShift
W następnych krokach wyjaśniono, jak można wdrożyć aplikację przy użyciu wykresu Helm przy użyciu konsoli internetowej OpenShift. Unikaj twardego kodowania poufnych wartości na wykresie Helm przy użyciu funkcji o nazwie "wpisy tajne". Sekret to po prostu zbiór par nazwa-wartość, w którym wartości są określone w pewnym znanym miejscu, zanim będą potrzebne. W naszym przypadku wykres Helm używa dwóch sekretów, z następującymi parami nazwa-wartość z każdej z tajemnic.
mssqlserver-secret-
db-hostprzekazuje wartośćMSSQLSERVER_HOST. -
db-nameprzekazuje wartośćMSSQLSERVER_DATABASE -
db-passwordprzekazuje wartośćMSSQLSERVER_PASSWORD -
db-portprzekazuje wartośćMSSQLSERVER_PORT. -
db-userprzekazuje wartośćMSSQLSERVER_USER.
-
todo-list-secret-
app-cluster-passwordprzekazuje dowolne hasło określone przez użytkownika, aby węzły klastra mogły tworzyć bezpieczniej. -
app-driver-versionprzekazuje wartośćMSSQLSERVER_DRIVER_VERSION. -
app-ds-jndiprzekazuje wartośćMSSQLSERVER_JNDI.
-
Utwórz plik
mssqlserver-secret.oc create secret generic mssqlserver-secret \ --from-literal db-host=${MSSQLSERVER_HOST} \ --from-literal db-name=${MSSQLSERVER_DATABASE} \ --from-literal db-password=${MSSQLSERVER_PASSWORD} \ --from-literal db-port=${MSSQLSERVER_PORT} \ --from-literal db-user=${MSSQLSERVER_USER}Utwórz plik
todo-list-secret.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 oc create secret generic todo-list-secret \ --from-literal app-cluster-password=mut2UTG6gDwNDcVW \ --from-literal app-driver-version=${MSSQLSERVER_DRIVER_VERSION} \ --from-literal app-ds-jndi=${MSSQLSERVER_JNDI}Uwaga
Firma Microsoft zaleca korzystanie z najbezpieczniejszego dostępnego przepływu uwierzytelniania. Przepływ uwierzytelniania opisany w tej procedurze, taki jak bazy danych, pamięci podręczne, komunikaty lub usługi sztucznej inteligencji, wymaga bardzo wysokiego stopnia zaufania w aplikacji i niesie ze sobą ryzyko, które nie występują w innych przepływach. Użyj tego przepływu tylko wtedy, gdy bardziej bezpieczne opcje, takie jak tożsamości zarządzane dla połączeń bez hasła lub bez kluczy, nie są opłacalne. W przypadku operacji maszyny lokalnej preferuj tożsamości użytkowników dla połączeń bez hasła lub bez klucza.
Otwórz konsolę OpenShift i przejdź do widoku dewelopera. Adres URL konsoli klastra OpenShift można odnaleźć, uruchamiając to polecenie. Zaloguj się przy użyciu identyfikatora użytkownika
kubeadmini hasła uzyskanego z poprzedniego kroku.az aro show \ --name $CLUSTER \ --resource-group $RESOURCEGROUP \ --query "consoleProfile.url" \ --output tsvWybierz perspektywę </> Developer z menu rozwijanego w górnej części okienka nawigacji.
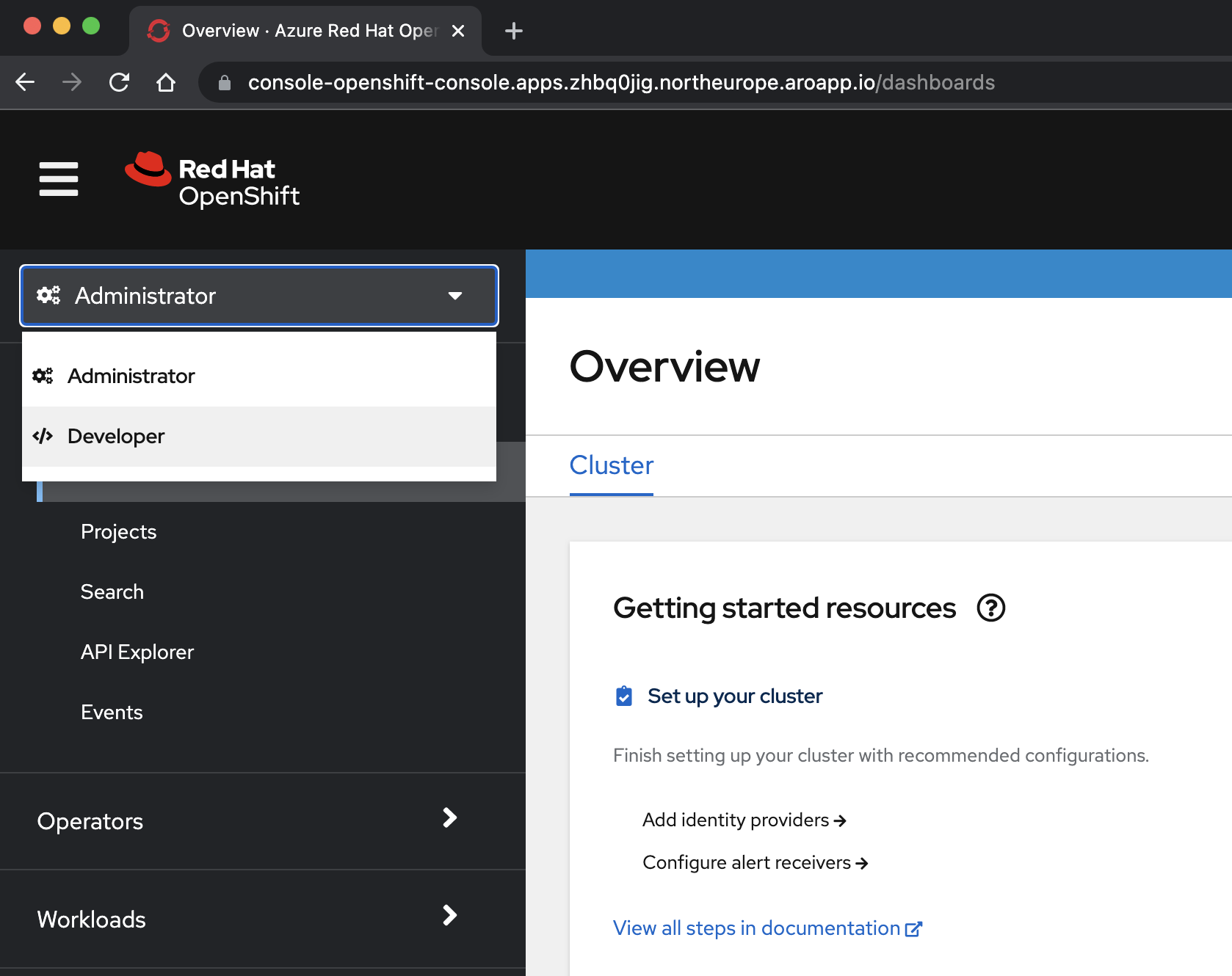
<W perspektywie />Developer wybierz projekt eap-demo z menu rozwijanego Projekt.
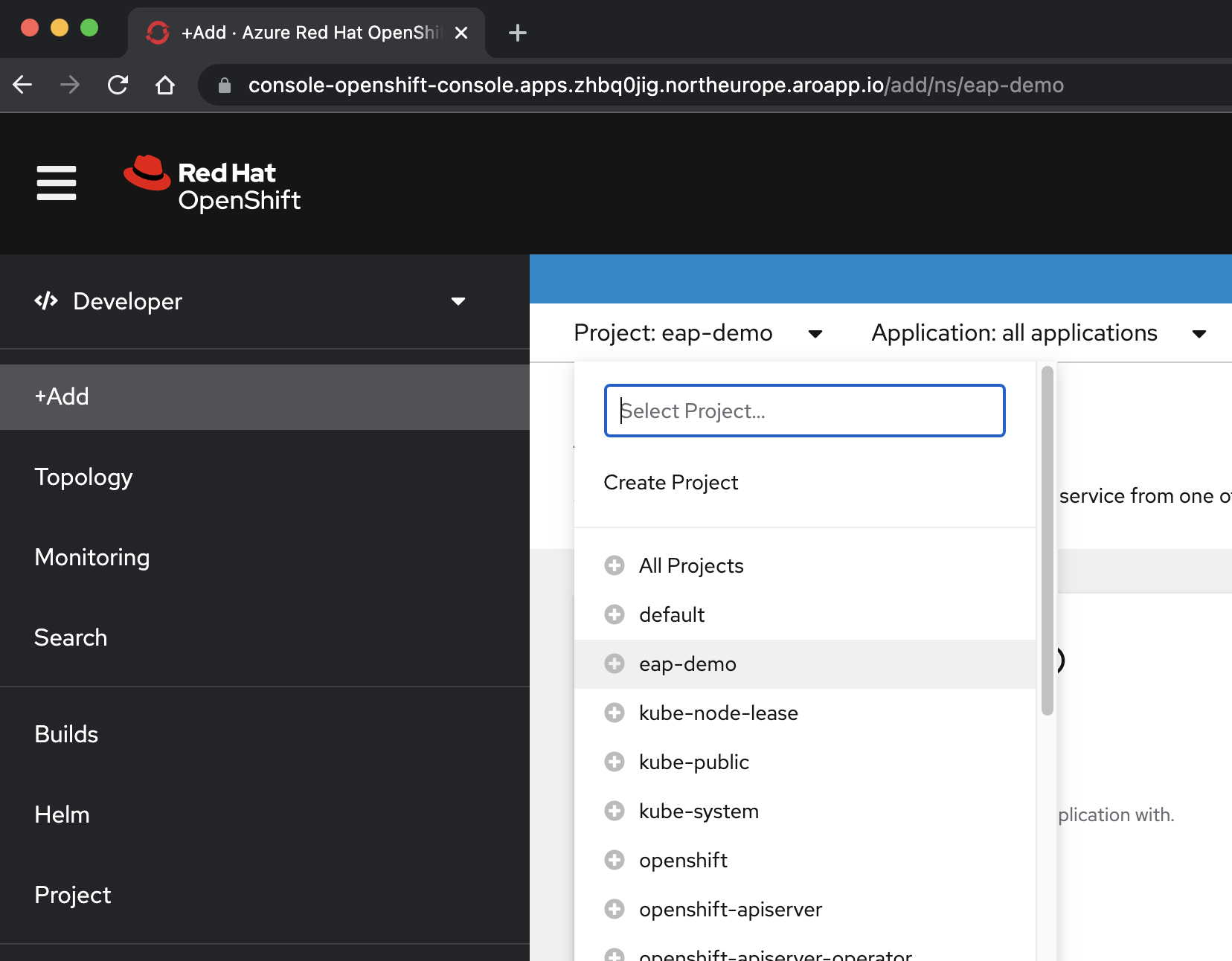
Wybierz pozycję +Dodaj. W sekcji Katalog deweloperów wybierz pozycję Helm Chart. Zostanie wyświetlony wykaz pakietów Helm dostępny w klastrze usługi Azure Red Hat OpenShift. W polu Filtruj według słowa kluczowego wpisz eap. Powinna zostać wyświetlona kilka opcji, jak pokazano poniżej:
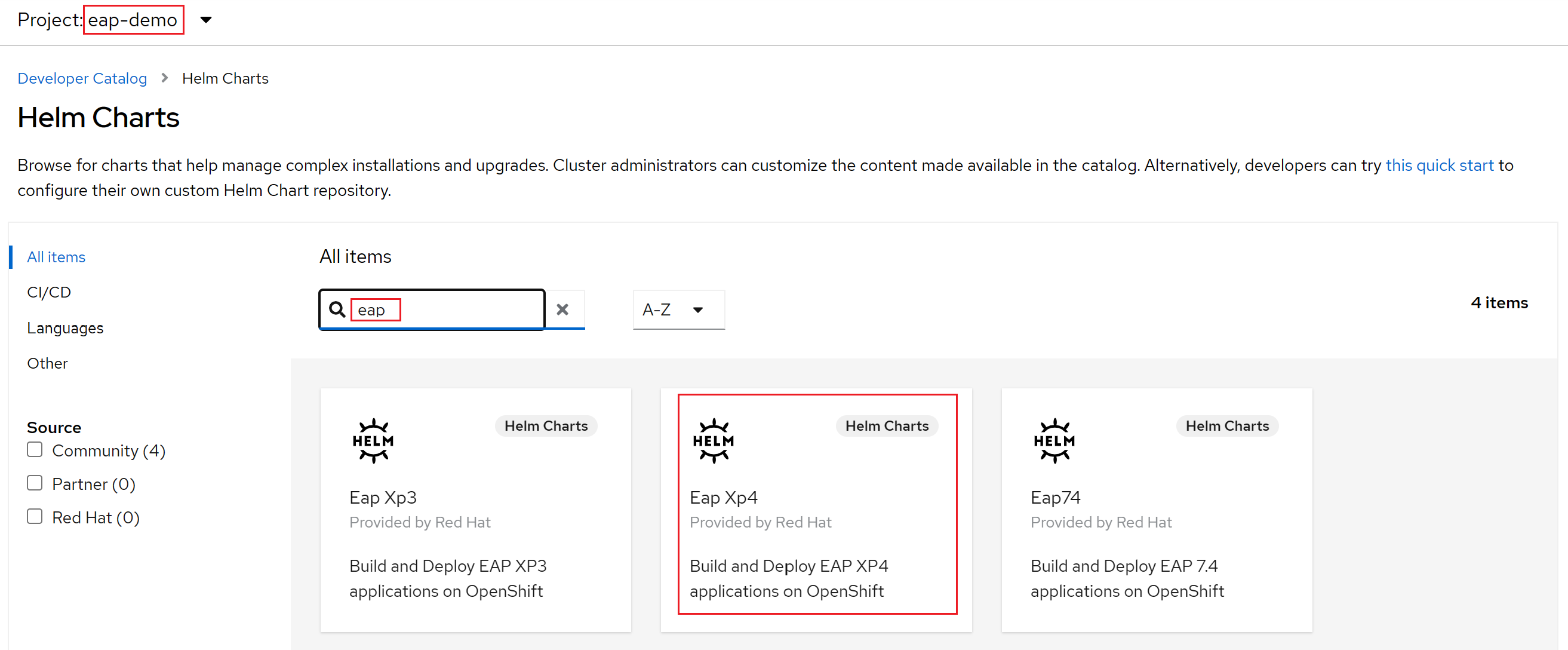
Ponieważ nasza aplikacja korzysta z funkcji MicroProfile, wybieramy wykres Helm dla protokołu EAP Xp. "Xp" oznacza Pakiet rozszerzeń. Dzięki pakietowi rozszerzeń JBoss Enterprise Application Platform deweloperzy mogą tworzyć i wdrażać aplikacje oparte na mikrousługach za pomocą interfejsów programowania aplikacji (API) środowiska Eclipse MicroProfile.
Wybierz wykres Helm JBoss EAP XP 4 , a następnie wybierz pozycję Zainstaluj pakiet Helm.
Na tym etapie musimy skonfigurować wykres w celu skompilowania i wdrożenia aplikacji:
Zmień nazwę wydania na eap-todo-list-demo.
Możemy skonfigurować pakiet Helm przy użyciu widoku formularza lub widoku YAML. W sekcji z etykietą Konfiguruj za pomocą wybierz pozycję Widok YAML.
Zmień zawartość YAML, aby skonfigurować pakiet Helm Chart, kopiując i wklejając zawartość pliku chart programu Helm dostępnego na stronie deployment/application/todo-list-helm-chart.yaml zamiast istniejącej zawartości:
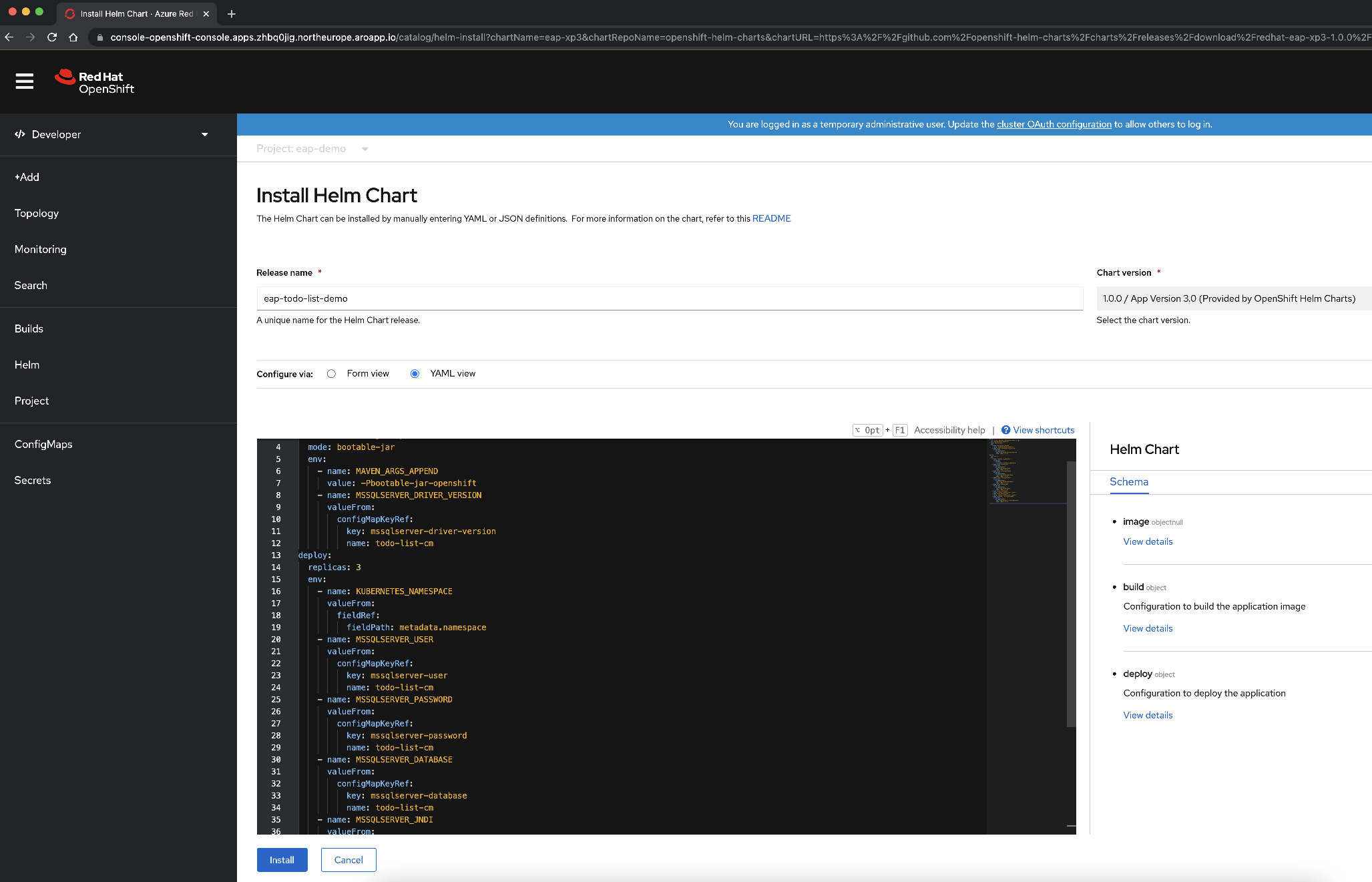
Ta zawartość odwołuje się do ustawionych wcześniej wpisów tajnych.
Na koniec wybierz pozycję Zainstaluj , aby rozpocząć wdrażanie aplikacji. Ta akcja powoduje otwarcie widoku Topologia z graficzną reprezentacją wydania programu Helm (o nazwie eap-todo-list-demo) i skojarzonymi z nimi zasobami.
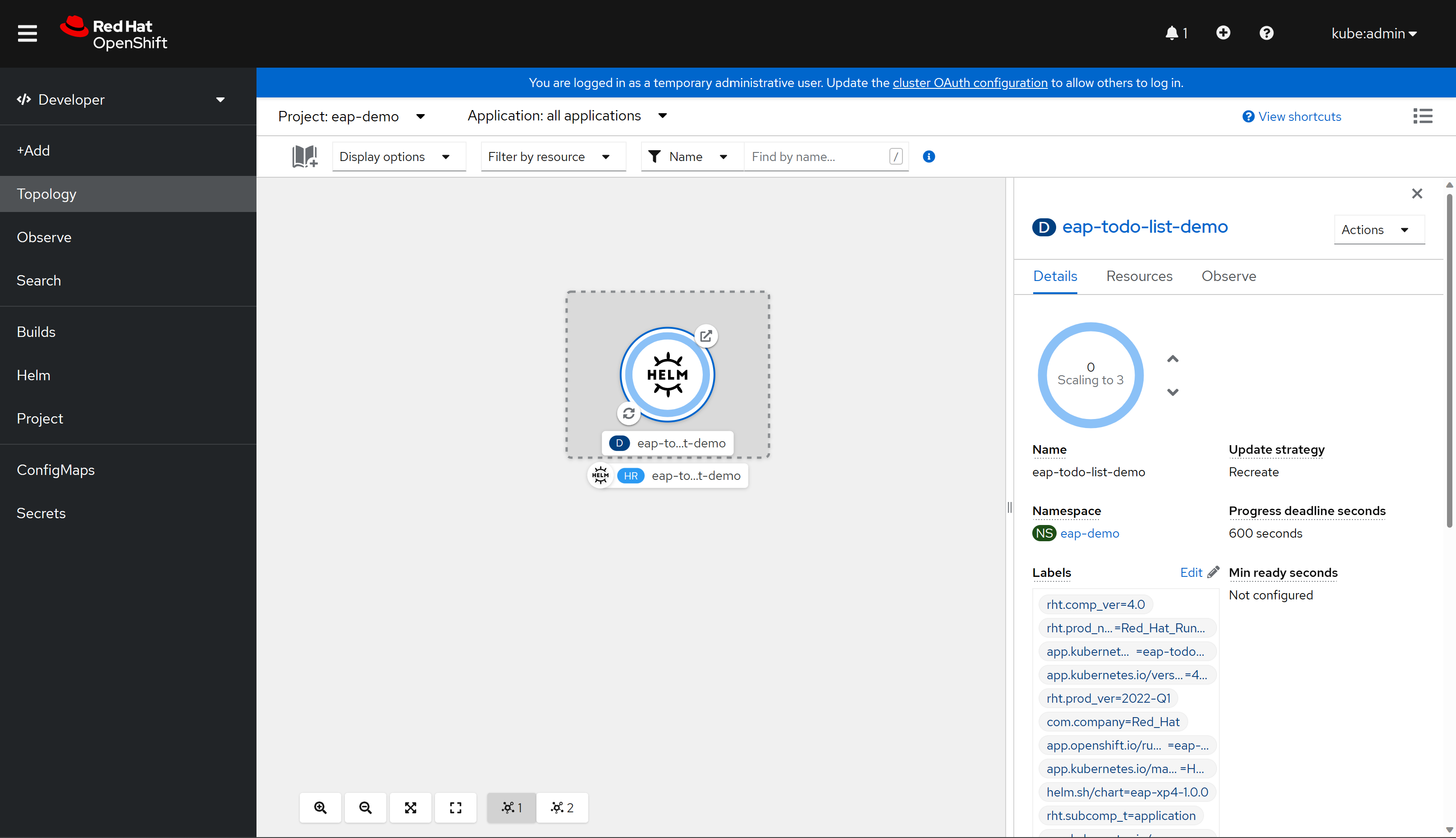
Wydanie programu Helm (skrócone hr) nosi nazwę eap-todo-list-demo. Zawiera on zasób wdrożenia (skrócony D) o nazwie eap-todo-list-demo.
Jeśli wybierzesz ikonę z dwiema strzałkami w okręgu w lewym dolnym rogu pola D , zostaniesz przeniesiony do okienka Dzienniki . W tym miejscu możesz obserwować postęp kompilacji. Aby powrócić do widoku topologii, wybierz pozycję Topologia w okienku nawigacji po lewej stronie.
Po zakończeniu kompilacji ikona w lewym dolnym rogu wyświetla zielony znaczek.
Po zakończeniu wdrażania kontur okręgu jest ciemnoniebieski. Jeśli umieścisz wskaźnik myszy na ciemnoniebieskim, powinien zostać wyświetlony komunikat z informacją podobną do
3 Running. Gdy zobaczysz ten komunikat, możesz przejść do aplikacji adres URL (przy użyciu ikony w prawym górnym rogu) z trasy skojarzonej z wdrożeniem.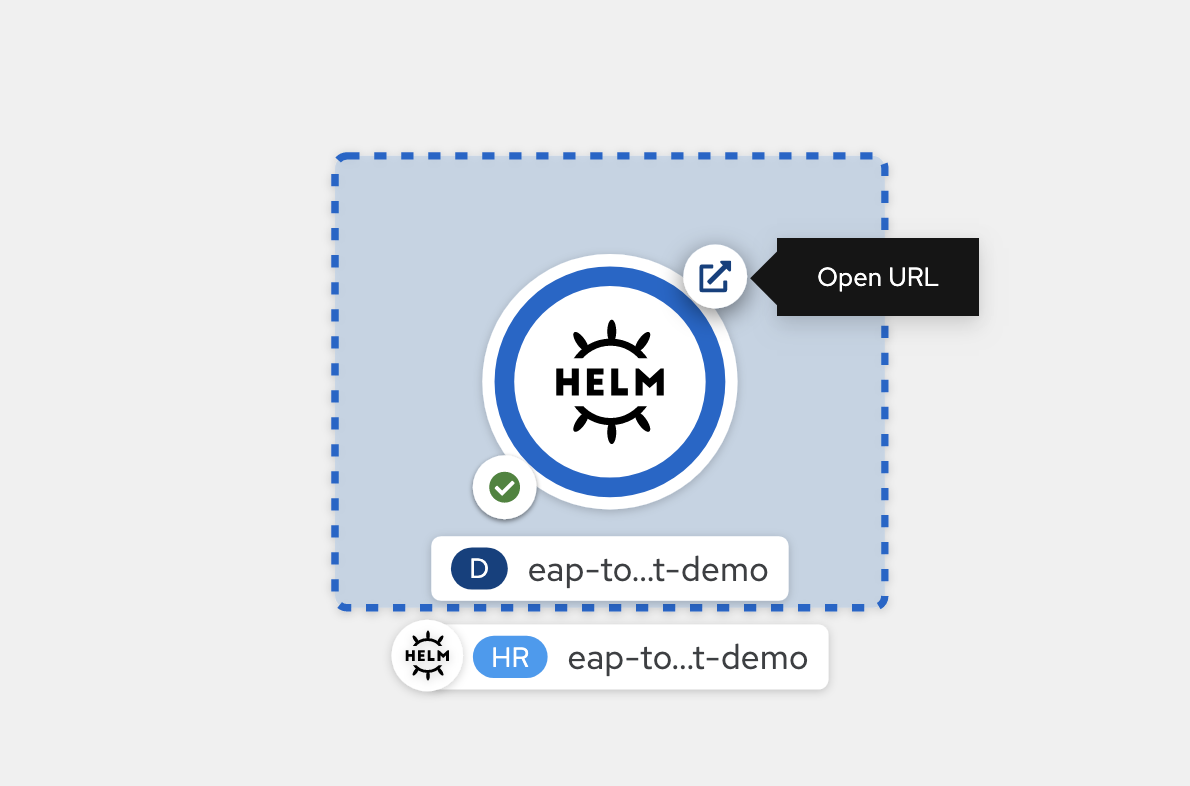
Aplikacja jest otwierana w przeglądarce, podobnie jak na poniższej ilustracji gotowej do użycia:
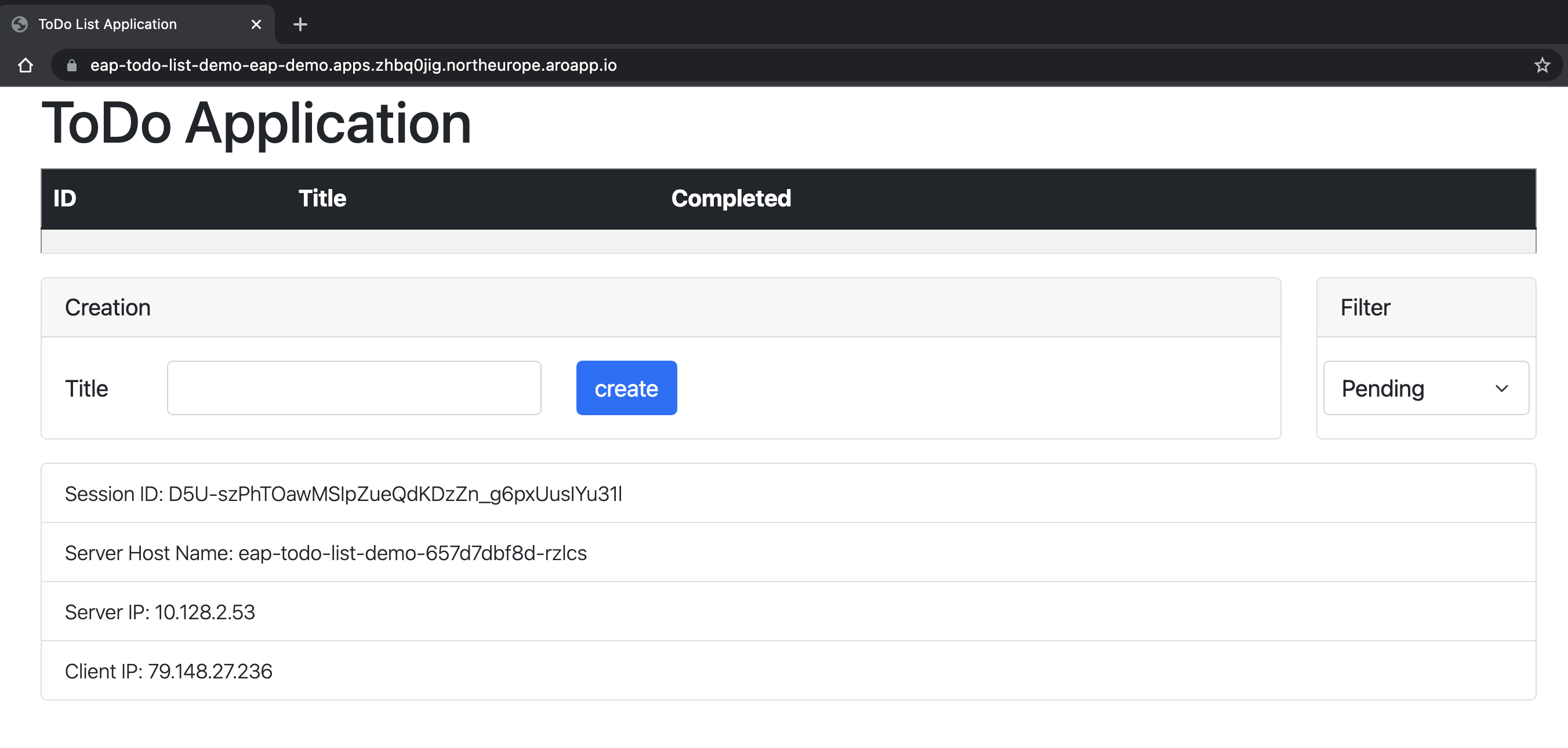
Aplikacja wyświetla nazwę zasobnika, który służy do obsługi informacji. Aby sprawdzić możliwości klastrowania, możesz dodać kilka elementów Todo. Następnie usuń zasobnik o nazwie wskazanej w polu Nazwa hosta serwera wyświetlanym w aplikacji przy użyciu polecenia
oc delete pod <pod-name>. Po usunięciu zasobnika utwórz nowe czynności do wykonania w tym samym oknie aplikacji. Widać, że nowy Todo jest dodawany za pośrednictwem żądania AJAX, a pole Nazwa hosta serwera teraz zawiera inną nazwę. W tle moduł równoważenia obciążenia OpenShift wysłał nowe żądanie i dostarczył go do dostępnego zasobnika. Widok Dżakarta Twarze jest przywracany z kopii sesji HTTP przechowywanej w zasobniku, który przetwarza żądanie. W rzeczywistości widać, że pole Identyfikator sesji nie uległo zmianie. Jeśli sesja nie jest replikowana w zasobnikach, otrzymujesz twarzeViewExpiredExceptionDżakarta, a aplikacja nie działa zgodnie z oczekiwaniami.

Czyszczenie zasobów
Usuwanie aplikacji
Jeśli chcesz usunąć tylko aplikację, możesz otworzyć konsolę OpenShift i w widoku dewelopera przejść do opcji menu Helm . W tym menu można wyświetlić wszystkie wersje pakietu Helm Chart zainstalowane w klastrze.

Znajdź eap-todo-list-demo Helm Chart. Na końcu wiersza wybierz pionowe kropki drzewa, aby otworzyć wpis menu kontekstowego akcji.
Wybierz pozycję Odinstaluj wydanie narzędzia Helm, aby usunąć aplikację. Zwróć uwagę, że obiekt tajny używany do dostarczania konfiguracji aplikacji nie jest częścią wykresu. Musisz usunąć go oddzielnie, jeśli nie jest już potrzebny.
Wykonaj następujące polecenie, jeśli chcesz usunąć wpis tajny, który przechowuje konfigurację aplikacji:
$ oc delete secrets/todo-list-secret
# secret "todo-list-secret" deleted
Usuwanie projektu OpenShift
Możesz również usunąć całą konfigurację utworzoną na potrzeby tego pokazu eap-demo , usuwając projekt. W tym celu wykonaj następujące polecenie:
$ oc delete project eap-demo
# project.project.openshift.io "eap-demo" deleted
Usuwanie klastra Usługi Azure Red Hat OpenShift
Usuń klaster Usługi Azure Red Hat OpenShift, wykonując kroki opisane w artykule Samouczek: usuwanie klastra usługi Azure Red Hat OpenShift 4.
Usuwanie grupy zasobów
Jeśli chcesz usunąć wszystkie zasoby utworzone w poprzednich krokach, usuń grupę zasobów utworzoną dla klastra Usługi Azure Red Hat OpenShift.
Następne kroki
Więcej informacji można dowiedzieć się z odwołań używanych w tym przewodniku:
- Red Hat JBoss Enterprise Application Platform
- Korzystanie z protokołu JBoss EAP na platformie kontenera OpenShift
- Azure Red Hat OpenShift
- JBoss EAP Helm Charts
- JBoss EAP Bootable JAR
Kontynuuj eksplorowanie opcji uruchamiania protokołu EAP JBoss na platformie Azure.