Przykład przesyłania strumieniowego platformy Apache Spark (DStream) z platformą Apache Kafka w usłudze HDInsight
Dowiedz się, jak używać platformy Apache Spark do strumieniowego przesyłania danych do platformy Apache Kafka lub z niego w usłudze HDInsight przy użyciu platformy D Strumienie. W tym przykładzie użyto notesu Jupyter Notebook działającego w klastrze Spark.
Uwaga
Kroki przedstawione w tym dokumencie obejmują tworzenie grupy zasobów platformy Azure, która zawiera zarówno platformę Spark w usłudze HDInsight, jak i platformę Kafka w klastrze usługi HDInsight. Oba klastry znajdują się w usłudze Azure Virtual Network, dzięki czemu klaster Spark może komunikować się bezpośrednio z klastrem Kafka.
Po zakończeniu pracy z tym dokumentem pamiętaj o usunięciu tych klastrów, aby uniknąć naliczania opłat.
Ważne
W tym przykładzie użyto platformy D Strumienie, która jest starszą technologią przesyłania strumieniowego Spark. Aby zapoznać się z przykładem korzystającym z nowszych funkcji przesyłania strumieniowego platformy Spark, zobacz dokument Spark Structured Streaming with Apache Kafka (Przesyłanie strumieniowe ze strukturą platformy Spark przy użyciu platformy Apache Kafka ).
Tworzenie klastrów
Platforma Apache Kafka w usłudze HDInsight nie zapewnia dostępu do brokerów platformy Kafka za pośrednictwem publicznego Internetu. Wszystkie elementy, które rozmawiają z platformą Kafka, muszą znajdować się w tej samej sieci wirtualnej platformy Azure co węzły w klastrze platformy Kafka. W tym przykładzie zarówno klastry Kafka, jak i Spark znajdują się w sieci wirtualnej platformy Azure. Na poniższym diagramie przedstawiono przepływ komunikacji między klastrami:
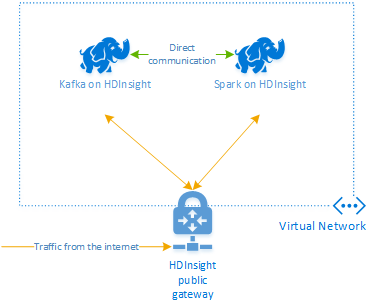
Uwaga
Chociaż sama platforma Kafka jest ograniczona do komunikacji w sieci wirtualnej, dostęp do innych usług w klastrze, takich jak SSH i Ambari, można uzyskać dostęp za pośrednictwem Internetu. Aby uzyskać więcej informacji o publicznych portach dostępnych z usługą HDInsight, zobacz Ports and URIs used by HDInsight (Porty i identyfikatory URI używane przez usługę HDInsight).
Chociaż można ręcznie utworzyć sieć wirtualną platformy Azure, platformę Kafka i klastry Spark, łatwiej jest użyć szablonu usługi Azure Resource Manager. Wykonaj poniższe kroki, aby wdrożyć sieć wirtualną platformy Azure, platformę Kafka i klastry Spark w ramach subskrypcji platformy Azure.
Kliknij poniższy przycisk, aby zalogować się do platformy Azure i otworzyć szablon w witrynie Azure Portal.

Ostrzeżenie
Aby zagwarantować dostępność platformy Kafka w usłudze HDInsight, klaster musi zawierać co najmniej cztery węzły robocze. Ten szablon tworzy klaster platformy Kafka zawierający cztery węzły robocze.
Ten szablon tworzy klaster usługi HDInsight 4.0 dla platformy Kafka i platformy Spark.
Użyj poniższych informacji, aby wypełnić wpisy w sekcji Wdrażanie niestandardowe:
Właściwości Wartość Grupa zasobów Utwórz grupę lub wybierz istniejącą. Lokalizacja Wybierz lokalizację geograficznie znajdującą się blisko Ciebie. Nazwa klastra podstawowego Ta wartość jest używana jako nazwa podstawowa dla klastrów Spark i Kafka. Na przykład wprowadzenie hdistreaming tworzy klaster Spark o nazwie spark-hdistreaming i klaster Kafka o nazwie kafka-hdistreaming. Nazwa użytkownika logowania klastra Nazwa użytkownika administratora dla klastrów Spark i Kafka. Hasło logowania klastra Hasło użytkownika administratora dla klastrów Spark i Kafka. Nazwa użytkownika SSH Użytkownik SSH do utworzenia dla klastrów Spark i Kafka. Hasło SSH Hasło użytkownika SSH dla klastrów Spark i Kafka. 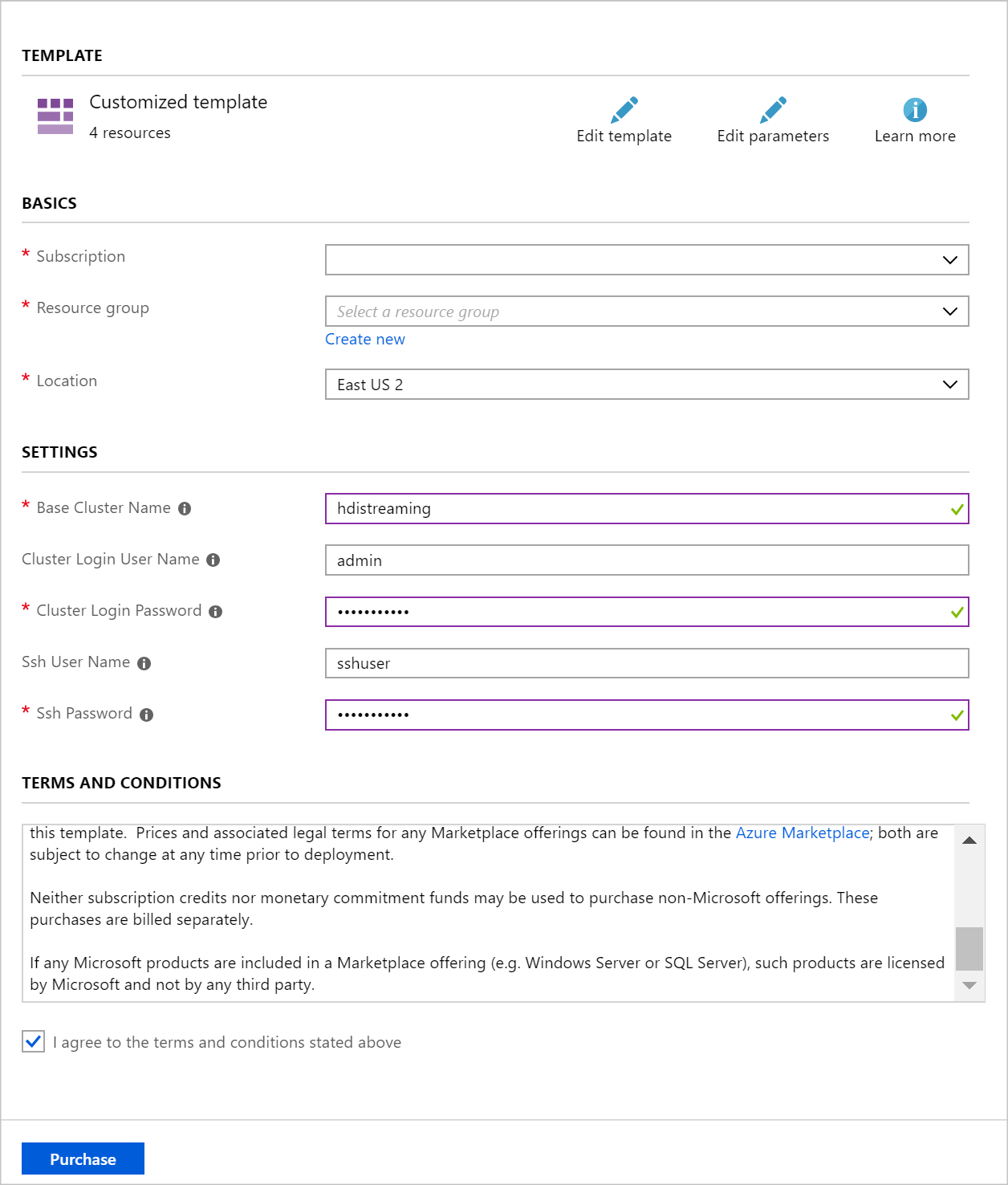
Przeczytaj Warunki i postanowienia, a następnie wybierz pozycję Wyrażam zgodę na powyższe warunki i postanowienia.
Na koniec wybierz pozycję Kup. Utworzenie klastrów trwa około 20 minut.
Po utworzeniu zasobów zostanie wyświetlona strona podsumowania.
Ważne
Zwróć uwagę, że nazwy klastrów usługi HDInsight to spark-BASENAME i kafka-BASENAME, gdzie BASENAME jest nazwą podaną w szablonie. Te nazwy są używane w kolejnych krokach podczas nawiązywania połączenia z klastrami.
Korzystanie z notesów
Kod przykładu opisanego w tym dokumencie jest dostępny na stronie https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Usuwanie klastra
Ostrzeżenie
Rozliczenia dla klastrów usługi HDInsight są naliczane proporcjonalnie na minutę, niezależnie od tego, czy są używane. Pamiętaj, aby usunąć klaster po zakończeniu korzystania z niego. Zobacz , jak usunąć klaster usługi HDInsight.
Ponieważ kroki opisane w tym dokumencie tworzą oba klastry w tej samej grupie zasobów platformy Azure, możesz usunąć grupę zasobów w witrynie Azure Portal. Usunięcie grupy spowoduje usunięcie wszystkich zasobów utworzonych zgodnie z tym dokumentem, siecią wirtualną platformy Azure i kontem magazynu używanym przez klastry.
Następne kroki
W tym przykładzie pokazano, jak używać platformy Spark do odczytywania i zapisywania na platformie Kafka. Skorzystaj z poniższych linków, aby odnaleźć inne sposoby pracy z platformą Kafka:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla