Replikowanie tematów platformy Apache Kafka przy użyciu platformy Kafka w usłudze HDInsight za pomocą narzędzia MirrorMaker
Dowiedz się, jak używać funkcji dublowania platformy Apache Kafka do replikowania tematów do klastra pomocniczego. Dublowanie można uruchamiać jako proces ciągły lub sporadycznie migrować dane z jednego klastra do innego.
W tym artykule użyjesz dublowania, aby replikować tematy między dwoma klastrami usługi HDInsight. Te klastry znajdują się w różnych sieciach wirtualnych w różnych centrach danych.
Ostrzeżenie
Nie używaj dublowania jako środka w celu osiągnięcia odporności na uszkodzenia. Przesunięcie elementów w temacie różni się między klastrami podstawowymi i pomocniczymi, więc klienci nie mogą używać tych dwóch zamiennie. Jeśli interesuje Cię odporność na uszkodzenia, należy ustawić replikację tematów w klastrze. Aby uzyskać więcej informacji, zobacz Wprowadzenie do platformy Apache Kafka w usłudze HDInsight.
Jak działa dublowanie platformy Apache Kafka
Dublowanie działa przy użyciu narzędzia MirrorMaker , które jest częścią platformy Apache Kafka. Narzędzie MirrorMaker używa rekordów z tematów w klastrze podstawowym, a następnie tworzy lokalną kopię w klastrze pomocniczym. Narzędzie MirrorMaker używa co najmniej jednego użytkownika odczytującego z klastra podstawowego i producenta , który zapisuje w klastrze lokalnym (pomocniczym).
Najbardziej przydatna konfiguracja dublowania na potrzeby odzyskiwania po awarii korzysta z klastrów platformy Kafka w różnych regionach świadczenia usługi Azure. Aby to osiągnąć, sieci wirtualne, w których znajdują się klastry, są połączone za pomocą komunikacji równorzędnej.
Na poniższym diagramie przedstawiono proces dublowania i sposób przepływu komunikacji między klastrami:
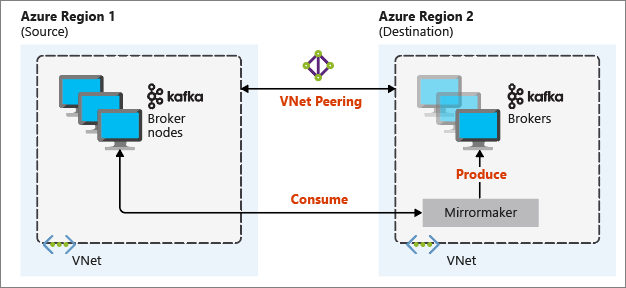
Klastry podstawowe i pomocnicze mogą być różne w liczbie węzłów i partycji, a przesunięcia w tych tematach również różnią się. Dublowanie utrzymuje wartość klucza używaną do partycjonowania, więc kolejność rekordów jest zachowywana na podstawie klucza.
Dublowanie między granicami sieci
Jeśli musisz dublować między klastrami platformy Kafka w różnych sieciach, należy wziąć pod uwagę następujące dodatkowe zagadnienia:
Bramy: sieci muszą być w stanie komunikować się na poziomie TCP/IP.
Adresowanie serwera: możesz wybrać adresowanie węzłów klastra przy użyciu ich adresów IP lub w pełni kwalifikowanych nazw domen.
Adresy IP: jeśli skonfigurujesz klastry platformy Kafka do korzystania z reklam adresów IP, możesz kontynuować konfigurację dublowania przy użyciu adresów IP węzłów brokera i węzłów usługi ZooKeeper.
Nazwy domen: jeśli nie skonfigurujesz klastrów platformy Kafka na potrzeby reklamy adresów IP, klastry muszą mieć możliwość łączenia się ze sobą przy użyciu w pełni kwalifikowanych nazw domen (FQDN). Wymaga to serwera systemu nazw domen (DNS) w każdej sieci skonfigurowanej do przekazywania żądań do innych sieci. Podczas tworzenia sieci wirtualnej platformy Azure zamiast używania automatycznego systemu DNS dostarczonego z siecią należy określić niestandardowy serwer DNS i adres IP serwera. Po utworzeniu sieci wirtualnej należy utworzyć maszynę wirtualną platformy Azure korzystającą z tego adresu IP. Następnie zainstalujesz i skonfigurujesz na nim oprogramowanie DNS.
Ważne
Utwórz i skonfiguruj niestandardowy serwer DNS przed zainstalowaniem usługi HDInsight w sieci wirtualnej. Nie ma dodatkowej konfiguracji wymaganej dla usługi HDInsight do korzystania z serwera DNS skonfigurowanego dla sieci wirtualnej.
Aby uzyskać więcej informacji na temat łączenia dwóch sieci wirtualnych platformy Azure, zobacz Konfigurowanie połączenia.
Architektura dublowania
Ta architektura obejmuje dwa klastry w różnych grupach zasobów i sieciach wirtualnych: podstawowym i pomocniczym.
Kroki tworzenia
Utwórz dwie nowe grupy zasobów:
Grupa zasobów Lokalizacja kafka-primary-rg Central US kafka-secondary-rg Północno-środkowe stany USA Utwórz nową sieć wirtualną kafka-primary-vnet na platformie kafka-primary-rg. Pozostaw ustawienia domyślne.
Utwórz nową sieć wirtualną kafka-secondary-vnet na platformie kafka-secondary-rg, również z ustawieniami domyślnymi.
Utwórz dwa nowe klastry platformy Kafka:
Nazwa klastra Grupa zasobów Sieć wirtualna Konto magazynu kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Tworzenie komunikacji równorzędnej sieci wirtualnych. W tym kroku zostaną utworzone dwie komunikacje równorzędne: jedna z platformy kafka-primary-vnet do sieci wirtualnej kafka-secondary-vnet i jedna z powrotem z sieci kafka-secondary-vnet do sieci kafka-primary-vnet.
Wybierz sieć wirtualną kafka-primary-vnet .
W obszarze Ustawienia wybierz pozycję Komunikacja równorzędna.
Wybierz pozycję Dodaj.
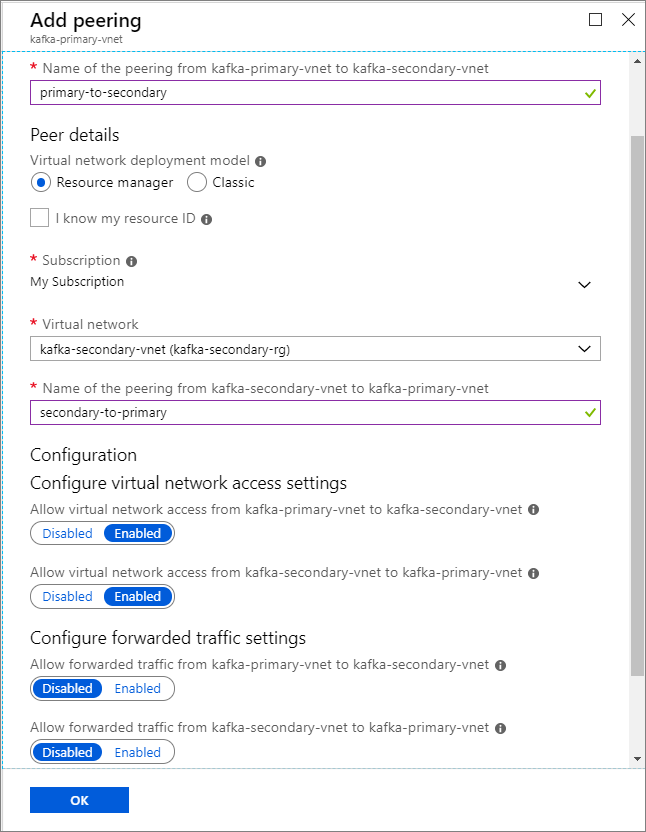
Na ekranie Dodawanie komunikacji równorzędnej wprowadź szczegóły, jak pokazano na poniższym zrzucie ekranu.
Konfigurowanie reklam IP
Skonfiguruj reklamy IP, aby umożliwić klientowi nawiązywanie połączenia przy użyciu adresów IP brokera zamiast nazw domen.
Przejdź do pulpitu nawigacyjnego systemu Ambari dla klastra podstawowego:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Wybierz pozycję Usługi>Kafka. Wybierz kartę Configs (Konfiguracje ).
Dodaj następujące wiersze konfiguracji do dolnej sekcji szablonu kafka-env . Wybierz pozycję Zapisz.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesWprowadź notatkę na ekranie Zapisz konfigurację , a następnie wybierz pozycję Zapisz.
Jeśli zostanie wyświetlone ostrzeżenie o konfiguracji, wybierz pozycję Kontynuuj mimo to.
W obszarze Zapisz zmiany konfiguracji wybierz przycisk OK.
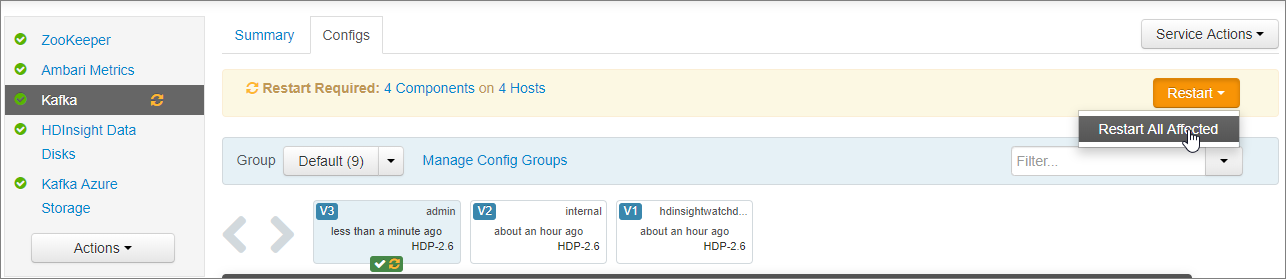
W powiadomieniu Wymagane ponowne uruchomienie wybierz pozycję Uruchom ponownie ponownie>wszystkie, których dotyczy problem. Następnie wybierz pozycję Potwierdź ponownie uruchom wszystko.
Konfigurowanie platformy Kafka do nasłuchiwania we wszystkich interfejsach sieciowych
- Na karcie Configs (Konfiguracje ) w obszarze Services Kafka ( Usługi>Kafka). W sekcji Broker platformy Kafka ustaw właściwość odbiorników na
PLAINTEXT://0.0.0.0:9092. - Wybierz pozycję Zapisz.
- Wybierz pozycję Uruchom ponownie, potwierdź ponowne uruchomienie> wszystkich.
Rejestrowanie adresów IP brokera i adresów ZooKeeper dla klastra podstawowego
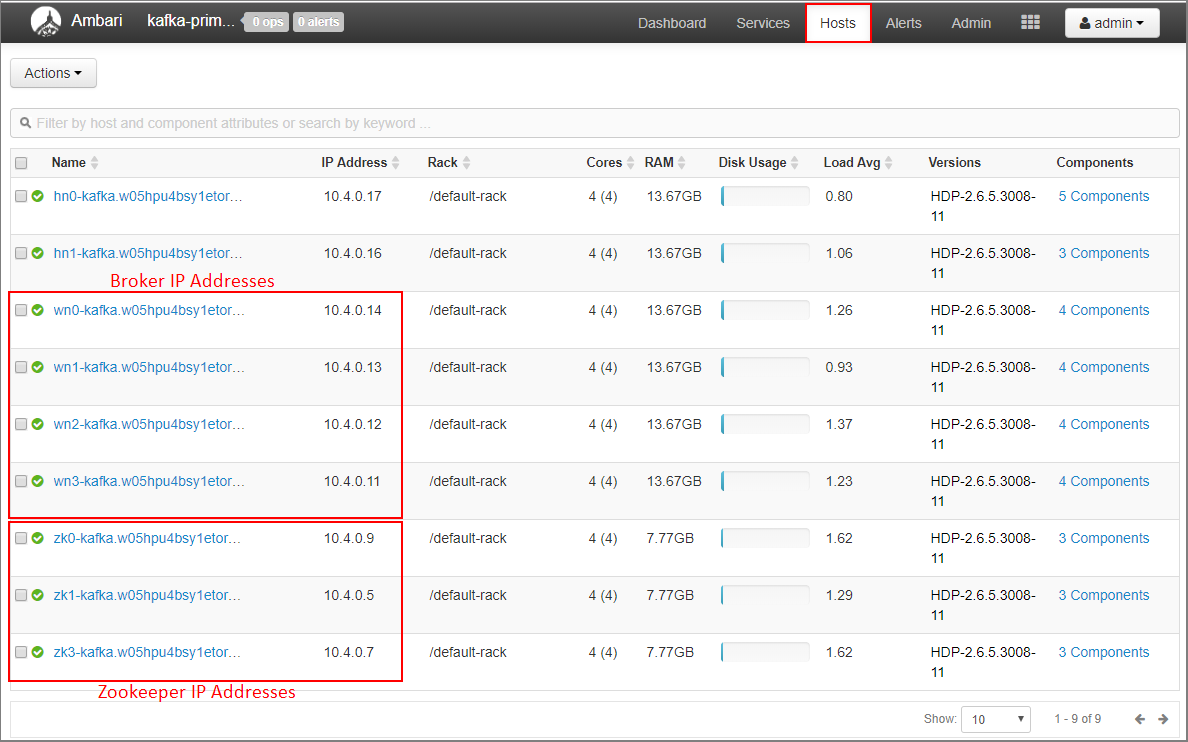
Wybierz pozycję Hosty na pulpicie nawigacyjnym systemu Ambari.
Zanotuj adresy IP brokerów i zooKeepers. Węzły brokera mają wn jako pierwsze dwie litery nazwy hosta, a węzły ZooKeeper mają zk jako pierwsze dwie litery nazwy hosta.
Powtórz poprzednie trzy kroki dla drugiego klastra, kafka-secondary-cluster: konfigurowanie reklamy IP, ustawianie odbiorników i zanotuj adresy IP brokera i zooKeeper.
Tworzenie tematów
Połącz się z klastrem podstawowym przy użyciu protokołu SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netZastąp ciąg
sshusernazwą użytkownika SSH użytą podczas tworzenia klastra. ZastąpPRIMARYCLUSTERciąg nazwą podstawową użytą podczas tworzenia klastra.Aby uzyskać więcej informacji, zobacz Używanie protokołu SSH w usłudze HDInsight.
Użyj następującego polecenia, aby utworzyć dwie zmienne środowiskowe z hostami usługi Apache ZooKeeper i hostami brokera dla klastra podstawowego. Zastąp ciągi takie jak
ZOOKEEPER_IP_ADDRESS1rzeczywistymi zarejestrowanymi wcześniej adresami IP, takimi jak10.23.0.11i10.23.0.7. To samo dotyczyBROKER_IP_ADDRESS1. Jeśli używasz rozpoznawania nazw FQDN z niestandardowym serwerem DNS, wykonaj następujące kroki , aby uzyskać nazwy brokera i usługi ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Aby utworzyć temat o nazwie
testtopic, użyj następującego polecenia:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSUżyj następującego polecenia, aby sprawdzić, czy temat został utworzony:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSOdpowiedź zawiera .
testtopicUżyj następujących informacji, aby wyświetlić informacje o hoście brokera dla tego klastra (podstawowego):
echo $PRIMARY_BROKERHOSTSZwraca to informacje podobne do następującego tekstu:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Zapisz te informacje. Jest on używany w następnej sekcji.
Konfigurowanie dublowania
Połącz się z klastrem pomocniczym przy użyciu innej sesji SSH:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netZastąp ciąg
sshusernazwą użytkownika SSH użytą podczas tworzenia klastra. ZastąpSECONDARYCLUSTERciąg nazwą użytą podczas tworzenia klastra.Aby uzyskać więcej informacji, zobacz Używanie protokołu SSH w usłudze HDInsight.
Użyj pliku, aby skonfigurować komunikację
consumer.propertiesz klastrem podstawowym. Aby utworzyć plik, użyj następującego polecenia:nano consumer.propertiesUżyj następującego tekstu jako zawartości
consumer.propertiespliku:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupZastąp ciąg
PRIMARY_BROKERHOSTSadresami IP hosta brokera z klastra podstawowego.W tym pliku opisano informacje o użytkowniku używane podczas odczytywania z podstawowego klastra platformy Kafka. Aby uzyskać więcej informacji, zobacz Konfiguracje konsumentów pod adresem
kafka.apache.org.Aby zapisać plik, naciśnij klawisze Ctrl+X, naciśnij klawisz Y, a następnie naciśnij klawisz Enter.
Przed skonfigurowaniem producenta komunikującego się z klastrem pomocniczym skonfiguruj zmienną dla adresów IP brokera klastra pomocniczego. Użyj następujących poleceń, aby utworzyć tę zmienną:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Polecenie
echo $SECONDARY_BROKERHOSTSpowinno zwrócić informacje podobne do następującego tekstu:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092producer.propertiesUżyj pliku do komunikowania się z klastrem pomocniczym. Aby utworzyć plik, użyj następującego polecenia:nano producer.propertiesUżyj następującego tekstu jako zawartości
producer.propertiespliku:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneZastąp ciąg
SECONDARY_BROKERHOSTSadresami IP brokera używanymi w poprzednim kroku.Aby uzyskać więcej informacji, zobacz Konfiguracja producenta pod adresem
kafka.apache.org.Użyj następujących poleceń, aby utworzyć zmienną środowiskową z adresami IP hostów zooKeeper dla klastra pomocniczego:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'Domyślna konfiguracja platformy Kafka w usłudze HDInsight nie zezwala na automatyczne tworzenie tematów. Przed rozpoczęciem procesu dublowania należy użyć jednej z następujących opcji:
Utwórz tematy w klastrze pomocniczym: ta opcja umożliwia również ustawienie liczby partycji i współczynnika replikacji.
Tematy można tworzyć z wyprzedzeniem przy użyciu następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSZastąp
testtopicciąg nazwą tematu do utworzenia.Skonfiguruj klaster na potrzeby automatycznego tworzenia tematu: ta opcja umożliwia narzędzie MirrorMaker automatyczne tworzenie tematów. Należy pamiętać, że może utworzyć je z inną liczbą partycji lub innym czynnikiem replikacji niż temat podstawowy.
Aby skonfigurować klaster pomocniczy do automatycznego tworzenia tematów, wykonaj następujące kroki:
- Przejdź do pulpitu nawigacyjnego systemu Ambari dla klastra pomocniczego:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Wybierz pozycję Usługi>Kafka. Następnie wybierz kartę Configs (Konfiguracje ).
- W polu Filtr wprowadź wartość .
auto.createSpowoduje to filtrowanie listy właściwości i wyświetlanieauto.create.topics.enableustawienia. - Zmień wartość na
auto.create.topics.enabletrue, a następnie wybierz pozycję Zapisz. Dodaj notatkę, a następnie ponownie wybierz pozycję Zapisz . - Wybierz usługę Kafka , wybierz pozycję Uruchom ponownie, a następnie wybierz pozycję Uruchom ponownie wszystkie, których dotyczy problem. Po wyświetleniu monitu wybierz pozycję Potwierdź ponowne uruchomienie wszystkich.
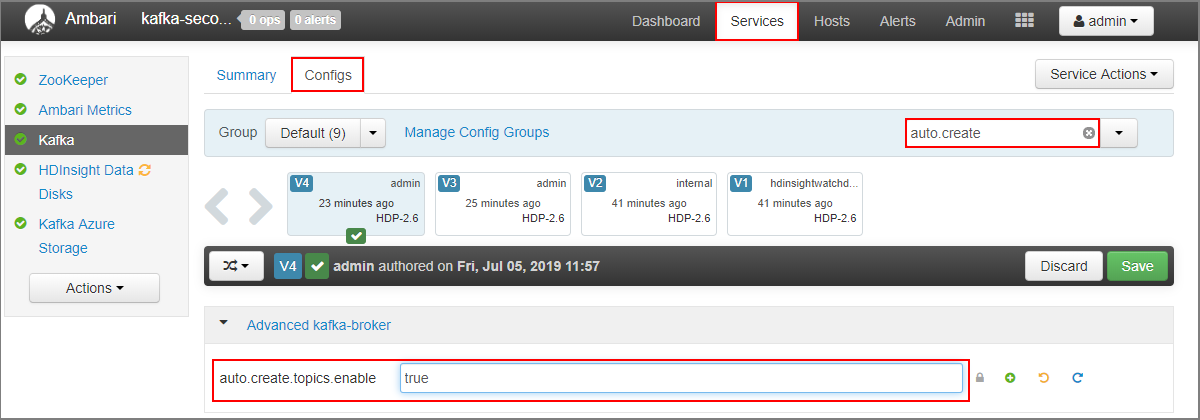
- Przejdź do pulpitu nawigacyjnego systemu Ambari dla klastra pomocniczego:
Uruchom narzędzie MirrorMaker
Uwaga
Ten artykuł zawiera odwołania do terminu, którego firma Microsoft już nie używa. Po usunięciu terminu z oprogramowania usuniemy go z tego artykułu.
Z połączenia SSH z klastrem pomocniczym użyj następującego polecenia, aby uruchomić proces MirrorMaker:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4Parametry używane w tym przykładzie to:
Parametr Opis --consumer.configOkreśla plik zawierający właściwości konsumenta. Te właściwości służą do tworzenia konsumenta, który odczytuje z podstawowego klastra platformy Kafka. --producer.configOkreśla plik zawierający właściwości producenta. Te właściwości służą do tworzenia producenta, który zapisuje w pomocniczym klastrze platformy Kafka. --whitelistLista tematów replikowanych z klastra podstawowego do pomocniczego programu MirrorMaker. --num.streamsLiczba wątków konsumenta do utworzenia. Użytkownik w węźle pomocniczym oczekuje teraz na odbieranie komunikatów.
Z poziomu połączenia SSH z klastrem podstawowym użyj następującego polecenia, aby uruchomić producenta i wysłać komunikaty do tematu:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicPo nadejściu pustego wiersza z kursorem wpisz kilka wiadomości tekstowych. Komunikaty są wysyłane do tematu w klastrze podstawowym. Po zakończeniu naciśnij klawisze Ctrl+C, aby zakończyć proces producenta.
Z połączenia SSH z klastrem pomocniczym naciśnij klawisze Ctrl+C, aby zakończyć proces MirrorMaker. Zakończenie procesu może potrwać kilka sekund. Aby sprawdzić, czy komunikaty zostały zreplikowane do pomocniczej, użyj następującego polecenia:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningLista tematów zawiera
testtopicteraz element , który jest tworzony podczas dublowania tematu z klastra podstawowego do pomocniczego. Komunikaty pobrane z tematu są takie same jak komunikaty wprowadzone w klastrze podstawowym.
Usuwanie klastra
Ostrzeżenie
Rozliczenia dla klastrów usługi HDInsight są naliczane proporcjonalnie na minutę, niezależnie od tego, czy są używane. Pamiętaj, aby usunąć klaster po zakończeniu korzystania z niego. Zobacz , jak usunąć klaster usługi HDInsight.
Kroki opisane w tym artykule zostały utworzone klastry w różnych grupach zasobów platformy Azure. Aby usunąć wszystkie utworzone zasoby, możesz usunąć dwie utworzone grupy zasobów: kafka-primary-rg i kafka-secondary-rg. Usunięcie grup zasobów powoduje usunięcie wszystkich zasobów utworzonych w tym artykule, w tym klastrów, sieci wirtualnych i kont magazynu.
Następne kroki
W tym artykule przedstawiono sposób tworzenia repliki klastra Apache Kafka przy użyciu narzędzia MirrorMaker. Skorzystaj z poniższych linków, aby odnaleźć inne sposoby pracy z platformą Kafka:
- Dokumentacja narzędzia Apache Kafka MirrorMaker w cwiki.apache.org.
- Najlepsze rozwiązania dotyczące usługi Kafka Mirror Maker
- Wprowadzenie do platformy Apache Kafka w usłudze HDInsight
- Korzystanie z platformy Apache Spark z platformą Apache Kafka w usłudze HDInsight
- Nawiązywanie połączenia z platformą Apache Kafka za pośrednictwem sieci wirtualnej platformy Azure
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla