Samouczek: tworzenie klastrów Apache Hadoop na żądanie w usłudze HDInsight przy użyciu usługi Azure Data Factory
Z tego samouczka dowiesz się, jak utworzyć klaster Apache Hadoop na żądanie w usłudze Azure HDInsight przy użyciu usługi Azure Data Factory. Następnie użyjesz potoków danych w usłudze Azure Data Factory, aby uruchomić zadania hive i usunąć klaster. Po ukończeniu tego samouczka dowiesz się, jak operationalize uruchomić zadanie danych big data, w którym tworzenie klastra, uruchamianie zadania i usuwanie klastra odbywa się zgodnie z harmonogramem.
Ten samouczek obejmuje następujące zadania:
- Tworzenie konta usługi Azure Storage
- Omówienie działania usługi Azure Data Factory
- Tworzenie fabryki danych przy użyciu witryny Azure Portal
- Tworzenie połączonych usług
- Tworzenie potoku
- Wyzwalanie potoku
- Monitorowanie potoku
- Sprawdzanie danych wyjściowych
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Zainstalowany moduł Az programu PowerShell.
Jednostka usługi Firmy Microsoft Entra. Po utworzeniu jednostki usługi pamiętaj, aby pobrać identyfikator aplikacji i klucz uwierzytelniania, korzystając z instrukcji w artykule połączonym. Te wartości będą potrzebne w dalszej części tego samouczka. Upewnij się również, że jednostka usługi jest członkiem roli Współautor subskrypcji lub grupy zasobów, w której jest tworzony klaster. Aby uzyskać instrukcje dotyczące pobierania wymaganych wartości i przypisywania odpowiednich ról, zobacz Tworzenie jednostki usługi Microsoft Entra.
Tworzenie wstępnych obiektów platformy Azure
W tej sekcji utworzysz różne obiekty, które będą używane dla klastra usługi HDInsight utworzonego na żądanie. Utworzone konto magazynu będzie zawierać przykładowy skrypt HiveQL, partitionweblogs.hqlktóry służy do symulowania przykładowego zadania apache Hive uruchomionego w klastrze.
W tej sekcji użyto skryptu programu Azure PowerShell do utworzenia konta magazynu i skopiowania wymaganych plików na koncie magazynu. Przykładowy skrypt programu Azure PowerShell w tej sekcji wykonuje następujące zadania:
- Zaloguje się do platformy Azure.
- Tworzy grupę zasobów platformy Azure.
- Tworzy konto usługi Azure Storage.
- Tworzy kontener obiektów blob na koncie magazynu
- Kopiuje przykładowy skrypt HiveQL (partitionweblogs.hql) kontenera obiektów blob. Przykładowy skrypt jest już dostępny w innym publicznym kontenerze obiektów blob. Poniższy skrypt programu PowerShell tworzy kopię tych plików na utworzone konto usługi Azure Storage.
Tworzenie konta magazynu i kopiowanie plików
Ważne
Określ nazwy grupy zasobów platformy Azure i konta usługi Azure Storage, które zostanie utworzone przez skrypt. Zapisz nazwę grupy zasobów, nazwę konta magazynu i klucz konta magazynu w danych wyjściowych skryptu. Będą one potrzebne w następnej sekcji.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Weryfikowanie konta magazynu
- Zaloguj się w witrynie Azure Portal.
- Po lewej stronie przejdź do pozycji Wszystkie usługi>Ogólne>grupy zasobów.
- Wybierz nazwę grupy zasobów utworzoną w skryscie programu PowerShell. Użyj filtru, jeśli masz zbyt wiele grup zasobów na liście.
- W widoku Przegląd zostanie wyświetlony jeden zasób, chyba że grupa zasobów zostanie udostępniona innym projektom. Ten zasób to konto magazynu o podanej wcześniej nazwie. Wybierz nazwę konta magazynu.
- Wybierz kafelek Kontenery.
- Wybierz kontener adfgetstarted. Zostanie wyświetlony folder o nazwie
hivescripts. - Otwórz folder i upewnij się, że zawiera przykładowy plik skryptu partitionweblogs.hql.
Omówienie działania usługi Azure Data Factory
Usługa Azure Data Factory organizuje i automatyzuje przenoszenie i przekształcanie danych. Usługa Azure Data Factory może utworzyć klaster just in time usługi HDInsight Hadoop, aby przetworzyć wycinek danych wejściowych i usunąć klaster po zakończeniu przetwarzania.
W usłudze Azure Data Factory fabryka danych może mieć co najmniej jeden potok danych. Potok danych ma co najmniej jedno działanie. Istnieją dwa typy działań:
- Działania przenoszenia danych. Działania przenoszenia danych służą do przenoszenia danych do przenoszenia danych ze źródłowego magazynu danych do docelowego magazynu danych.
- Działania przekształcania danych. Działania przekształcania danych służą do przekształcania/przetwarzania danych. Działanie hive usługi HDInsight to jedno z działań przekształcania obsługiwanych przez usługę Data Factory. W tym samouczku użyjesz działania przekształcania programu Hive.
W tym artykule skonfigurujesz działanie programu Hive w celu utworzenia klastra usługi HDInsight Hadoop na żądanie. Gdy działanie jest uruchamiane w celu przetwarzania danych, oto co się stanie:
Klaster Usługi Hadoop w usłudze HDInsight jest automatycznie tworzony w celu przetworzenia wycinka.
Dane wejściowe są przetwarzane przez uruchomienie skryptu HiveQL w klastrze. W tym samouczku skrypt HiveQL skojarzony z działaniem hive wykonuje następujące akcje:
- Używa istniejącej tabeli (hivesampletable) do utworzenia innej tabeli HiveSampleOut.
- Wypełnia tabelę HiveSampleOut tylko określonymi kolumnami z oryginalnego elementu hivesampletable.
Klaster hadoop usługi HDInsight jest usuwany po zakończeniu przetwarzania, a klaster jest bezczynny przez skonfigurowany czas (ustawienie timeToLive). Jeśli następny wycinek danych jest dostępny do przetworzenia w tym czasie Bezczynności Na żywo, ten sam klaster jest używany do przetwarzania wycinka.
Tworzenie fabryki danych
Zaloguj się w witrynie Azure Portal.
W menu po lewej stronie przejdź do
+ Create a resource>usługi Analytics>Data Factory.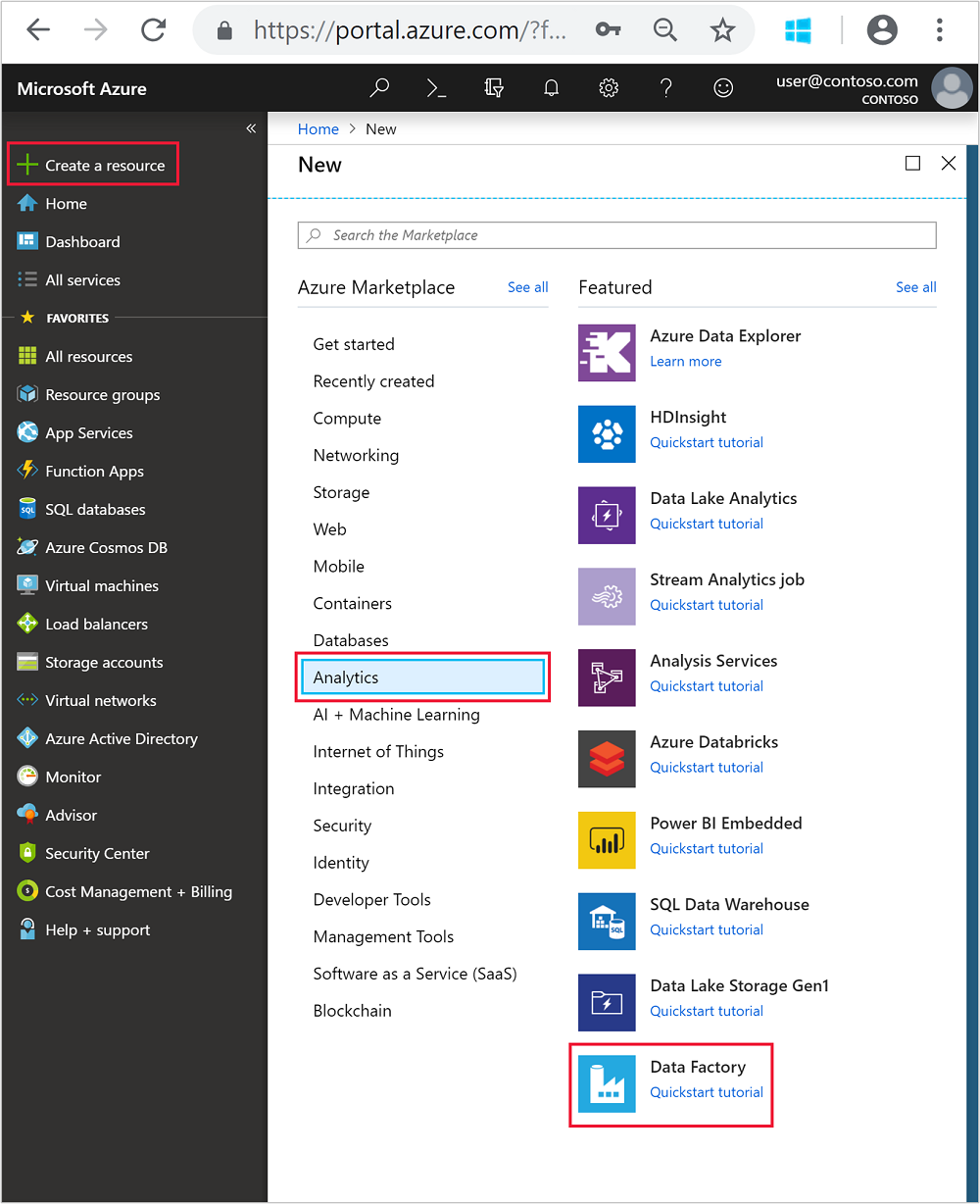
Wprowadź lub wybierz następujące wartości dla kafelka Nowa fabryka danych:
Właściwości Wartość Nazwisko Wprowadź nazwę fabryki danych. Ta nazwa musi być unikatowa w skali globalnej. Wersja Pozostaw wartość V2. Subskrypcja Wybierz subskrypcję platformy Azure. Resource group Wybierz grupę zasobów utworzoną przy użyciu skryptu programu PowerShell. Lokalizacja Lokalizacja jest automatycznie ustawiana na lokalizację określoną wcześniej podczas tworzenia grupy zasobów. Na potrzeby tego samouczka lokalizacja jest ustawiona na Wschodnie stany USA. Włączanie usługi GIT Usuń zaznaczenie tego pola. 
Wybierz pozycję Utwórz. Tworzenie fabryki danych może potrwać od 2 do 4 minut.
Po utworzeniu fabryki danych otrzymasz powiadomienie Wdrożenie zakończyło się pomyślnie z przyciskiem Przejdź do zasobu . Wybierz pozycję Przejdź do zasobu , aby otworzyć widok domyślny usługi Data Factory.
Wybierz pozycję Autor i monitor , aby uruchomić portal tworzenia i monitorowania usługi Azure Data Factory.
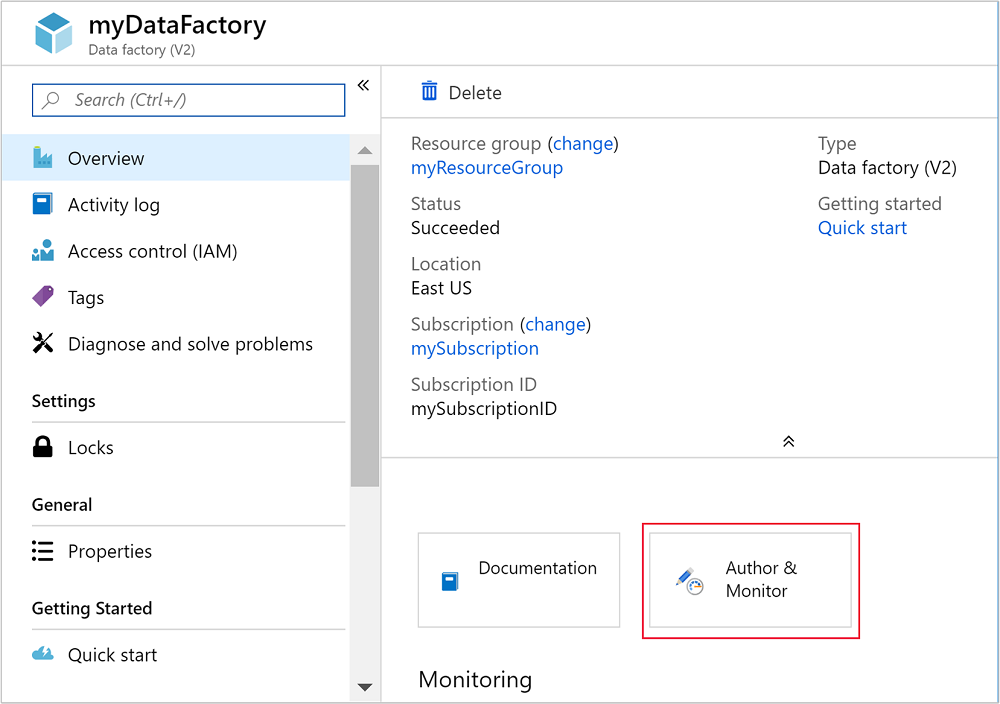
Tworzenie połączonych usług
W tej sekcji utworzysz dwie połączone usługi w fabryce danych.
- Połączoną usługę Azure Storage, która łączy konto usługi Azure Storage z fabryką danych. Ten magazyn jest używany przez klaster usługi HDInsight na żądanie. Zawiera również skrypt programu Hive uruchamiany w klastrze.
- Połączoną usługę HDInsight dostępną na żądanie. Usługa Azure Data Factory automatycznie tworzy klaster usługi HDInsight i uruchamia skrypt hive. Następnie usuwa klaster usługi HDInsight, gdy jest on bezczynny przez wstępnie skonfigurowany czas.
Tworzenie połączonej usługi Azure Storage
W lewym okienku strony Rozpocznij pracę wybierz ikonę Autor .

Wybierz pozycję Połączenie ions w lewym dolnym rogu okna, a następnie wybierz pozycję +Nowy.
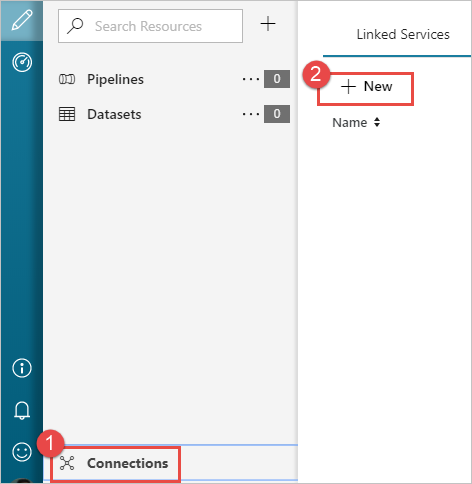
W oknie dialogowym Nowa połączona usługa wybierz pozycję Azure Blob Storage, a następnie wybierz pozycję Kontynuuj.
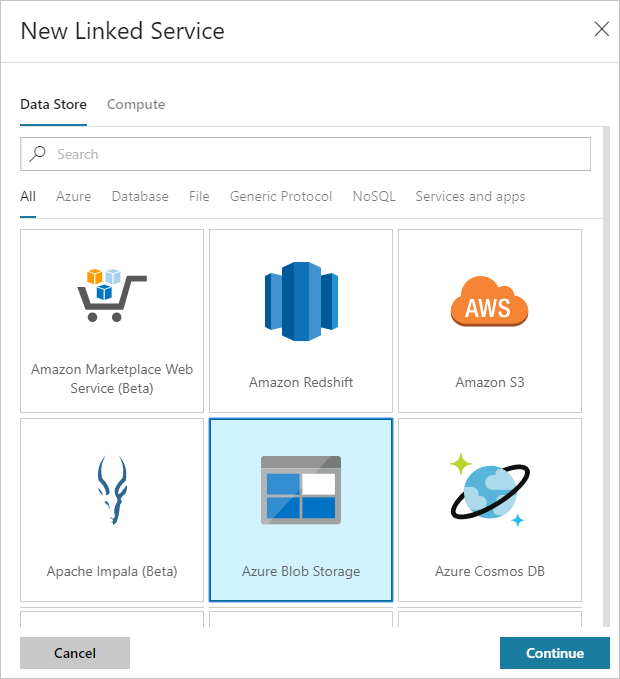
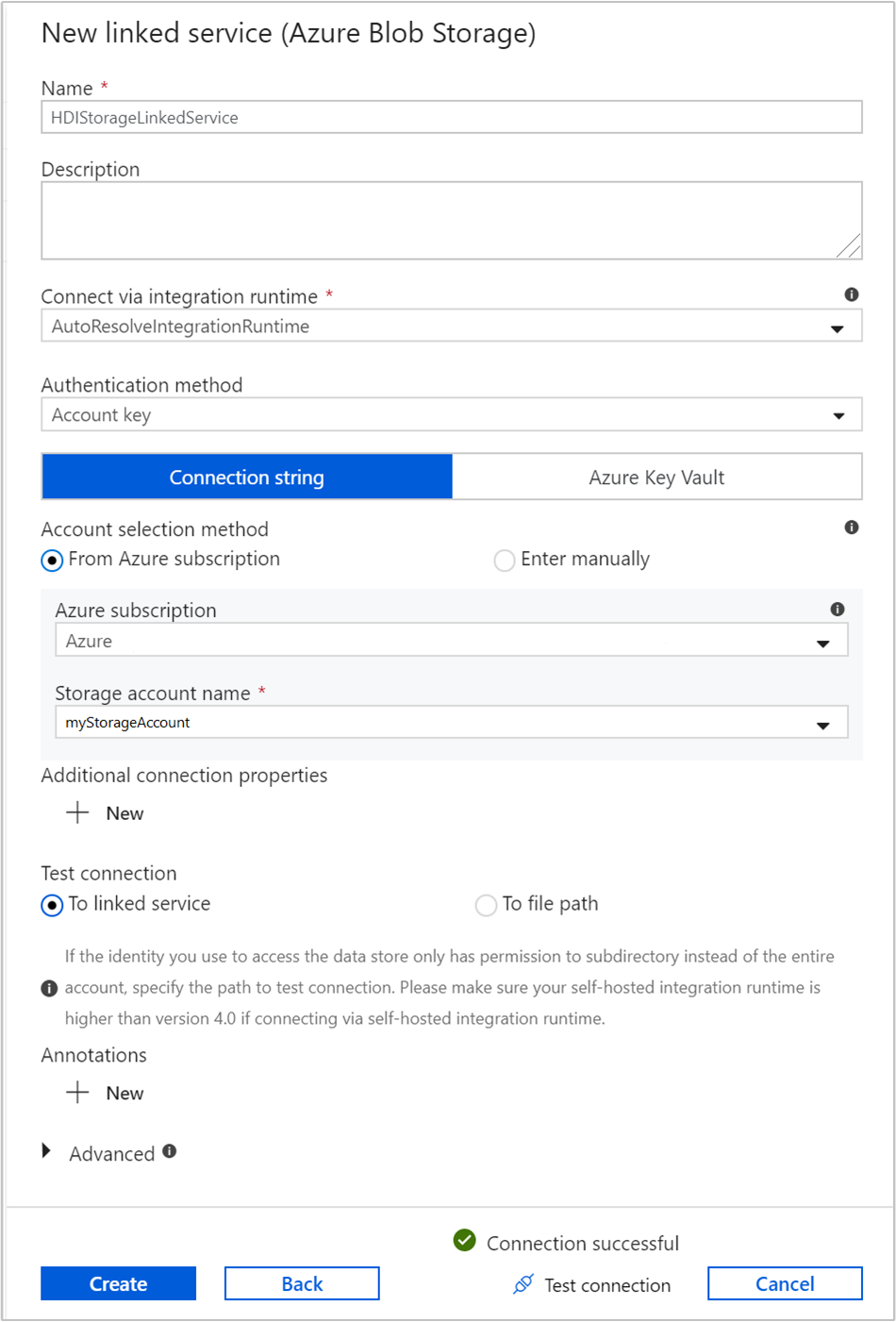
Podaj następujące wartości dla połączonej usługi magazynu:
Właściwości Wartość Nazwisko Wprowadź HDIStorageLinkedService.Subskrypcja platformy Azure Wybierz swoją subskrypcję z listy rozwijanej. Nazwa konta magazynu Wybierz konto usługi Azure Storage utworzone w ramach skryptu programu PowerShell. Wybierz pozycję Testuj połączenie i jeśli zakończy się pomyślnie, a następnie wybierz pozycję Utwórz.
Tworzenie połączonej usługi HDInsight na żądanie
Wybierz ponownie przycisk + Nowy, aby utworzyć kolejną połączoną usługę.
W oknie Nowa połączona usługa wybierz kartę Obliczenia.
Wybierz pozycję Azure HDInsight, a następnie wybierz pozycję Kontynuuj.
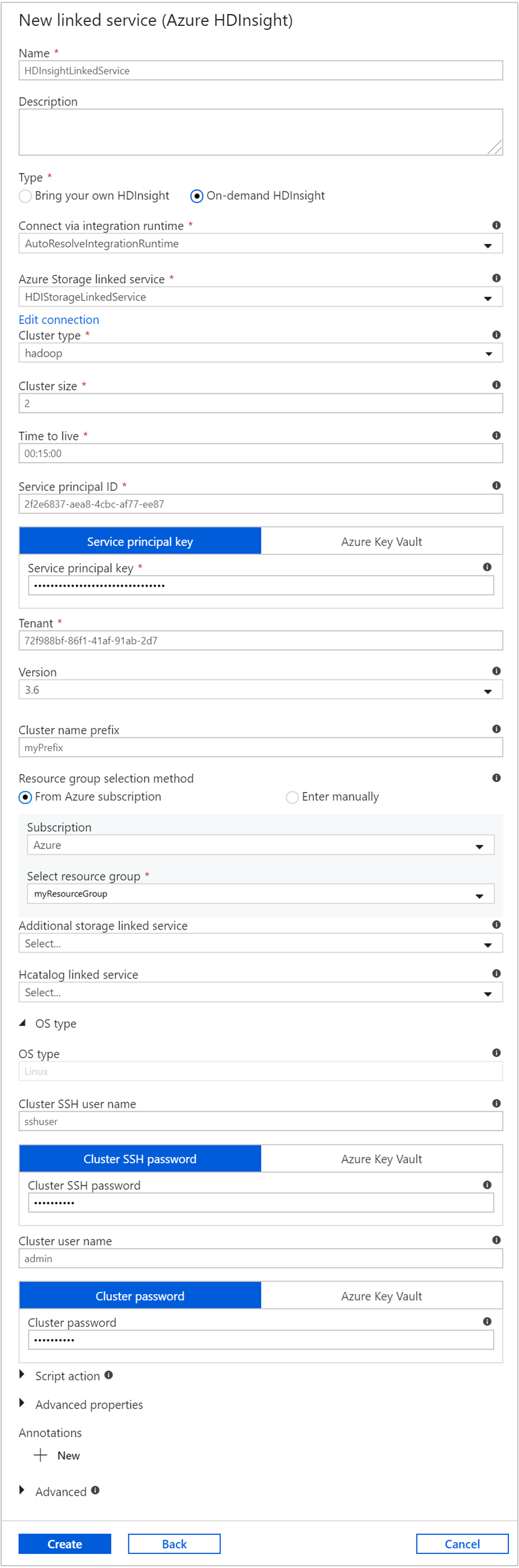
W oknie Nowa połączona usługa wprowadź następujące wartości i pozostaw resztę jako domyślną:
Właściwości Wartość Nazwisko Wprowadź HDInsightLinkedService.Typ Wybierz pozycję Na żądanie w usłudze HDInsight. Połączona usługa Azure Storage Wybierz opcję HDIStorageLinkedService.Typ klastra Wybieranie usługi hadoop Time to live (Czas wygaśnięcia) Podaj czas trwania, przez który klaster usługi HDInsight ma być dostępny przed automatycznym usunięciem. Identyfikator jednostki usługi Podaj identyfikator aplikacji jednostki usługi Microsoft Entra utworzonej w ramach wymagań wstępnych. Klucz jednostki usługi Podaj klucz uwierzytelniania dla jednostki usługi Microsoft Entra. Prefiks nazwy klastra Podaj wartość, która zostanie poprzedzona wszystkimi typami klastrów utworzonymi przez fabrykę danych. Subskrypcja Wybierz swoją subskrypcję z listy rozwijanej. Wybierz grupę zasobów Wybierz grupę zasobów utworzoną wcześniej jako część użytego wcześniej skryptu programu PowerShell. Typ systemu operacyjnego/Nazwa użytkownika SSH klastra Wprowadź nazwę użytkownika SSH, często sshuser.Typ systemu operacyjnego/hasło SSH klastra Podaj hasło dla użytkownika SSH Typ systemu operacyjnego/nazwa użytkownika klastra Wprowadź nazwę użytkownika klastra, często admin.Typ systemu operacyjnego/hasło klastra Podaj hasło dla użytkownika klastra. Następnie wybierz Utwórz.
Tworzenie potoku
Wybierz przycisk + (znak plus), a następnie wybierz pozycję Potok.
W przyborniku Działania rozwiń węzeł HDInsight i przeciągnij działanie Hive na powierzchnię projektanta potoku. Na karcie Ogólne podaj nazwę działania.
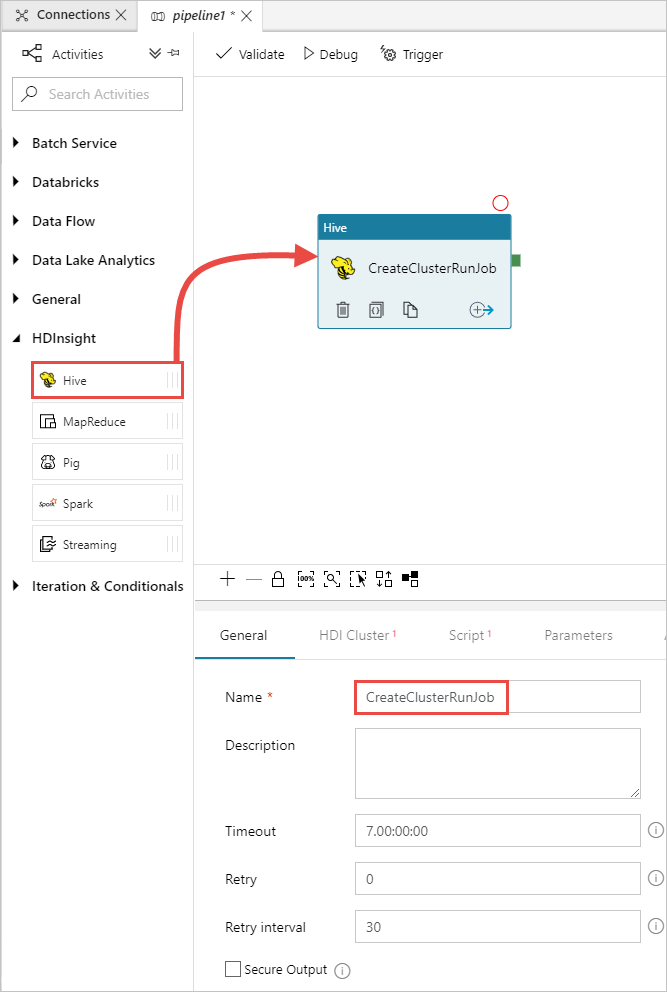
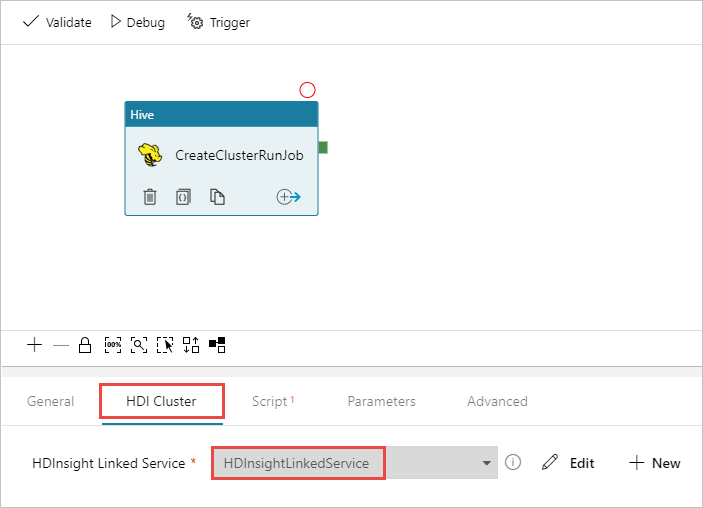
Upewnij się, że wybrano działanie Programu Hive, wybierz kartę Klaster usługi HDI. Z listy rozwijanej Połączona usługa HDInsight wybierz utworzoną wcześniej połączoną usługę HDInsightLinkedService dla usługi HDInsight.
Wybierz kartę Skrypt i wykonaj następujące kroki:
W polu Połączona usługa skryptu wybierz pozycję HDIStorageLinkedService z listy rozwijanej. Ta wartość to utworzona wcześniej połączona usługa magazynu.
W polu Ścieżka pliku wybierz pozycję Przeglądaj magazyn i przejdź do lokalizacji, w której jest dostępny przykładowy skrypt Hive. Jeśli wcześniej uruchomiono skrypt programu PowerShell, ta lokalizacja powinna mieć wartość
adfgetstarted/hivescripts/partitionweblogs.hql.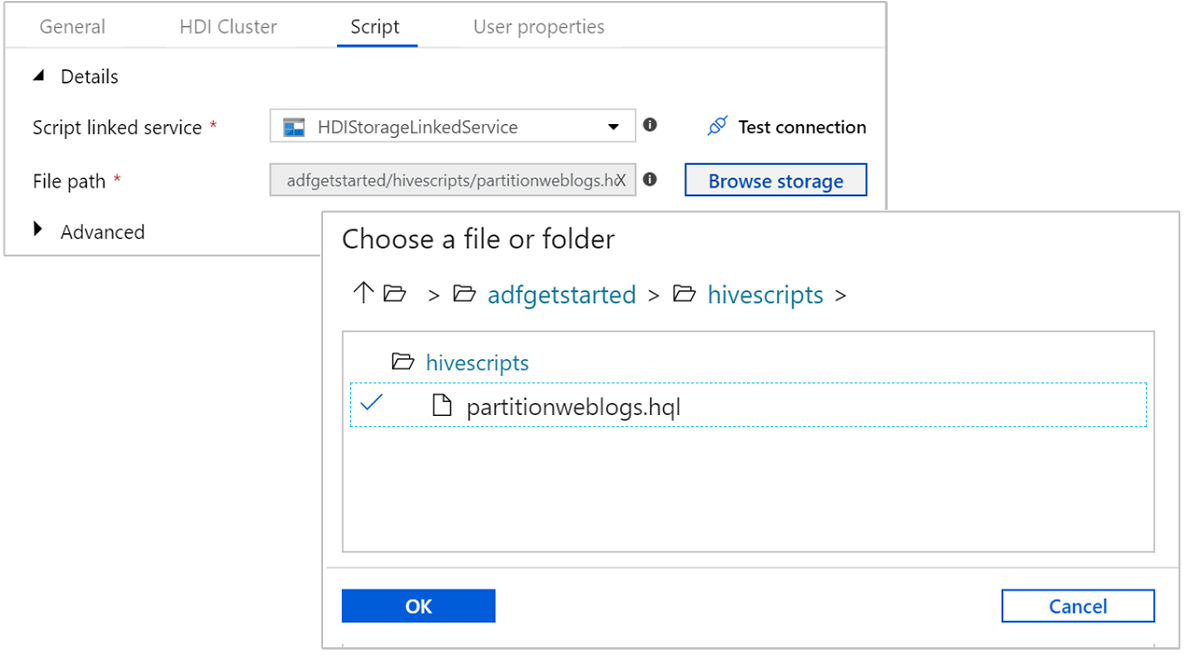
W obszarze Parametry zaawansowane>wybierz pozycję .
Auto-fill from scriptTa opcja wyszukuje wszystkie parametry w skryscie Programu Hive, które wymagają wartości w czasie wykonywania.W polu tekstowym wartości dodaj istniejący folder w formacie
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. W ścieżce jest rozróżniana wielkość liter. Ta ścieżka to miejsce, w którym będą przechowywane dane wyjściowe skryptu. Schematwasbsjest niezbędny, ponieważ konta magazynu mają teraz domyślnie włączony bezpieczny transfer.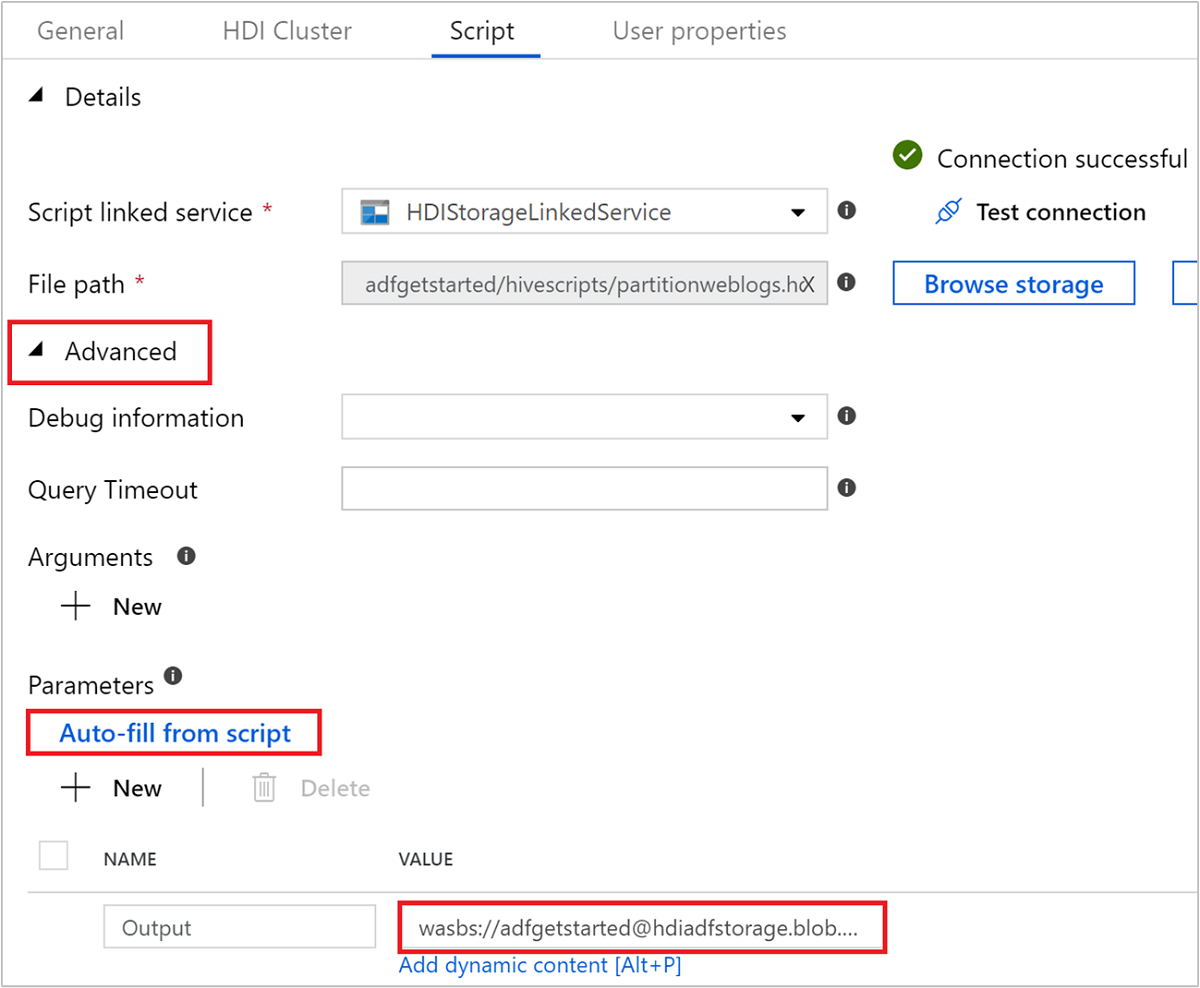
Wybierz pozycję Weryfikuj , aby zweryfikować potok. Wybierz przycisk >> (strzałka w prawo), aby zamknąć okno weryfikacji.
Na koniec wybierz pozycję Publikuj wszystko , aby opublikować artefakty w usłudze Azure Data Factory.
Wyzwalanie potoku
Na pasku narzędzi na powierzchni projektanta wybierz pozycję Dodaj wyzwalacz Wyzwalacz>teraz.
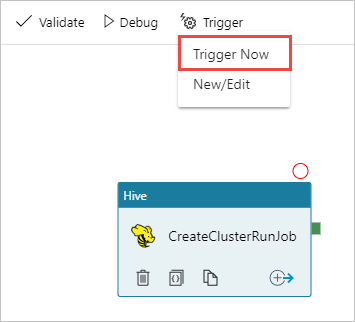
Wybierz przycisk OK na pasku podręcznym po stronie.
Monitorowanie potoku
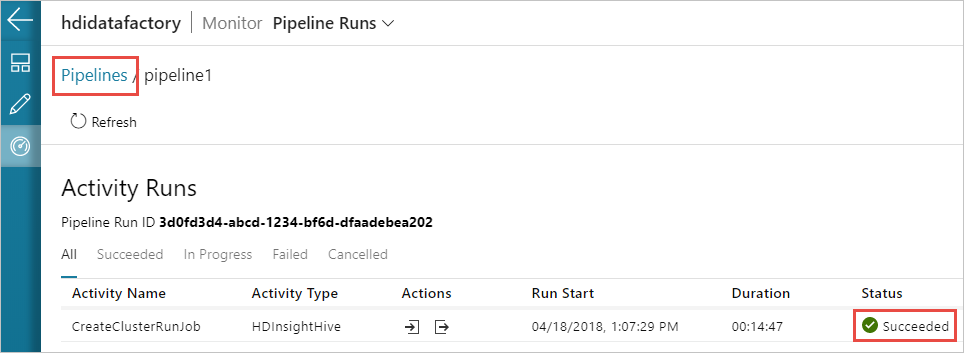
Przejdź do karty Monitorowanie po lewej stronie. Uruchomienie potoku zostanie wyświetlone na liście Uruchomienia potoku. Zwróć uwagę na stan przebiegu w kolumnie Stan .
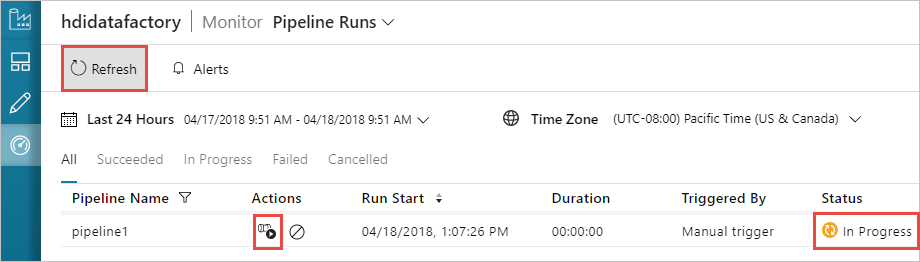
Wybierz pozycję Odśwież, aby odświeżyć stan.
Możesz również wybrać ikonę Wyświetl uruchomienia działań, aby wyświetlić uruchomienie działania skojarzone z potokiem. Na poniższym zrzucie ekranu widać tylko jedno uruchomienie działania, ponieważ w utworzonym potoku znajduje się tylko jedno działanie. Aby wrócić do poprzedniego widoku, wybierz pozycję Potoki w górnej części strony.
Sprawdzanie danych wyjściowych
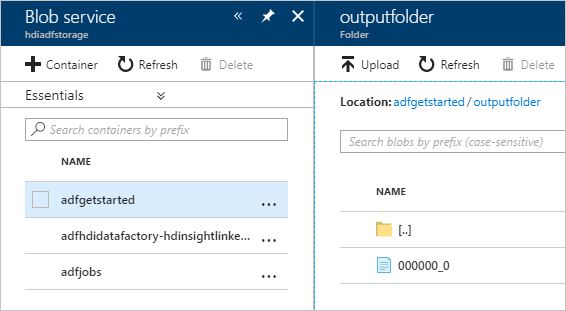
Aby zweryfikować dane wyjściowe, w witrynie Azure Portal przejdź do konta magazynu użytego na potrzeby tego samouczka. Powinny zostać wyświetlone następujące foldery lub kontenery:
Zostanie wyświetlony folder adfgerstarted/outputfolder zawierający dane wyjściowe skryptu Programu Hive, który został uruchomiony w ramach potoku.
Zostanie wyświetlony kontener adfhdidatafactory-linked-service-name-timestamp><<>. Ten kontener jest domyślną lokalizacją magazynu klastra usługi HDInsight, który został utworzony w ramach uruchomienia potoku.
Zostanie wyświetlony kontener adfjobs z dziennikami zadań usługi Azure Data Factory.
Czyszczenie zasobów
Po utworzeniu klastra usługi HDInsight na żądanie nie trzeba jawnie usuwać klastra usługi HDInsight. Klaster jest usuwany na podstawie konfiguracji podanej podczas tworzenia potoku. Nawet po usunięciu klastra konta magazynu skojarzone z klastrem nadal istnieją. Takie zachowanie jest zgodnie z projektem, dzięki czemu można przechowywać dane bez zmian. Jeśli jednak nie chcesz utrwalać danych, możesz usunąć utworzone konto magazynu.
Możesz też usunąć całą grupę zasobów utworzoną na potrzeby tego samouczka. Ten proces usuwa konto magazynu i utworzoną usługę Azure Data Factory.
Usuwanie grupy zasobów
Zaloguj się w witrynie Azure Portal.
Wybierz pozycję Grupy zasobów w okienku po lewej stronie.
Wybierz nazwę grupy zasobów utworzoną w skryscie programu PowerShell. Użyj filtru, jeśli masz zbyt wiele grup zasobów na liście. Spowoduje to otwarcie grupy zasobów.
Na kafelku Zasoby będziesz mieć domyślne konto magazynu i fabrykę danych wymienioną, chyba że grupa zasobów zostanie udostępniona innym projektom.
Wybierz pozycję Usuń grupę zasobów. Spowoduje to usunięcie konta magazynu i danych przechowywanych na koncie magazynu.
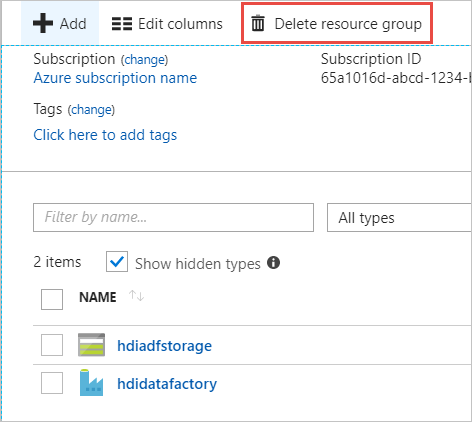
Wprowadź nazwę grupy zasobów, aby potwierdzić usunięcie, a następnie wybierz pozycję Usuń.
Następne kroki
W tym artykule przedstawiono sposób użycia usługi Azure Data Factory do tworzenia klastra usługi HDInsight na żądanie i uruchamiania zadań apache Hive. Przejdź do następnego artykułu, aby dowiedzieć się, jak tworzyć klastry usługi HDInsight przy użyciu konfiguracji niestandardowej.