Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Klaster usługi HDInsight tworzy różne pliki dziennika. Na przykład platforma Apache Hadoop i powiązane usługi, takie jak Apache Spark, generują szczegółowe dzienniki wykonywania zadań. Zarządzanie plikami dzienników jest częścią utrzymania klastra usługi HDInsight w dobrej kondycji. Mogą również istnieć wymagania prawne dotyczące archiwizowania dzienników. Ze względu na liczbę i rozmiar plików dziennika optymalizowanie magazynu dzienników i archiwizowanie pomaga w zarządzaniu kosztami usług.
Zarządzanie dziennikami klastra usługi HDInsight obejmuje przechowywanie informacji o wszystkich aspektach środowiska klastra. Te informacje obejmują wszystkie skojarzone dzienniki usługi platformy Azure, konfigurację klastra, informacje o wykonaniu zadania, wszystkie stany błędów i inne dane zgodnie z potrzebami.
Typowe kroki zarządzania dziennikami usługi HDInsight to:
- Krok 1. Określanie zasad przechowywania dzienników
- Krok 2. Zarządzanie dziennikami konfiguracji wersji usługi klastra
- Krok 3. Zarządzanie plikami dziennika wykonywania zadań klastra
- Krok 4. Prognozowanie rozmiarów i kosztów magazynu woluminów dziennika
- Krok 5. Określanie zasad i procesów archiwum dziennika
Krok 1. Określanie zasad przechowywania dzienników
Pierwszym krokiem tworzenia strategii zarządzania dziennikami klastra usługi HDInsight jest zebranie informacji o scenariuszach biznesowych i wymaganiach dotyczących magazynu historii wykonywania zadań.
Szczegóły klastra
Poniższe szczegóły klastra ułatwiają zbieranie informacji w strategii zarządzania dziennikami. Zbierz te informacje ze wszystkich klastrów usługi HDInsight utworzonych na określonym koncie platformy Azure.
- Nazwa klastra
- Region klastra i strefa dostępności platformy Azure
- Stan klastra, w tym szczegóły ostatniej zmiany stanu
- Typ i liczba wystąpień usługi HDInsight określonych dla węzłów głównych, podstawowych i zadań
Większość tych informacji najwyższego poziomu można uzyskać w witrynie Azure Portal. Alternatywnie możesz użyć interfejsu wiersza polecenia platformy Azure, aby uzyskać informacje o klastrach usługi HDInsight:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Możesz również użyć programu PowerShell, aby wyświetlić te informacje. Aby uzyskać więcej informacji, zobacz Apache Manage Hadoop clusters in HDInsight by using Azure PowerShell (Zarządzanie klastrami Hadoop w usłudze HDInsight przy użyciu programu Azure PowerShell).
Omówienie obciążeń uruchomionych w klastrach
Ważne jest, aby zrozumieć typy obciążeń uruchomione w klastrach usługi HDInsight, aby zaprojektować odpowiednie strategie rejestrowania dla każdego typu.
- Czy obciążenia eksperymentalne (takie jak programowanie lub testowanie) czy jakość produkcji?
- Jak często działają obciążenia jakości produkcyjnej?
- Czy którekolwiek z obciążeń intensywnie korzystających z zasobów i/lub długotrwałych?
- Czy którekolwiek z obciążeń korzysta ze złożonego zestawu usług Hadoop, dla których są tworzone wiele typów dzienników?
- Czy którekolwiek z obciążeń ma skojarzone wymagania dotyczące pochodzenia danych z przepisami?
Przykładowe wzorce i rozwiązania dotyczące przechowywania dzienników
Rozważ utrzymanie śledzenia pochodzenia danych przez dodanie identyfikatora do każdego wpisu dziennika lub za pomocą innych technik. Dzięki temu można śledzić oryginalne źródło danych i operację oraz śledzić dane na każdym etapie, aby zrozumieć jego spójność i ważność.
Zastanów się, jak można zbierać dzienniki z klastra lub z więcej niż jednego klastra i sortować je do celów, takich jak inspekcja, monitorowanie, planowanie i alerty. Możesz użyć niestandardowego rozwiązania do regularnego uzyskiwania dostępu do plików dziennika i pobierania ich oraz łączenia i analizowania w celu zapewnienia wyświetlania pulpitu nawigacyjnego. Możesz również dodać inne możliwości alertów dotyczących zabezpieczeń lub wykrywania błędów. Te narzędzia można tworzyć przy użyciu programu PowerShell, zestawów SDK usługi HDInsight lub kodu, który uzyskuje dostęp do klasycznego modelu wdrażania platformy Azure.
Zastanów się, czy rozwiązanie do monitorowania czy usługa byłaby przydatną korzyścią. Program Microsoft System Center udostępnia pakiet administracyjny usługi HDInsight. Możesz również używać narzędzi innych firm, takich jak Apache Chukwa i Ganglia, do zbierania i scentralizowania dzienników. Wiele firm oferuje usługi monitorowania rozwiązań do obsługi danych big data opartych na usłudze Hadoop, na przykład:
Centerity, Compuware APM, Sematext SPM i Zettaset Orchestrator.
Krok 2. Zarządzanie wersjami usługi klastra i wyświetlanie dzienników
Typowy klaster usługi HDInsight używa kilku usług i pakietów oprogramowania typu open source (takich jak Apache HBase, Apache Spark itd.). W przypadku niektórych obciążeń, takich jak bioinformatyka, może być konieczne zachowanie historii dziennika konfiguracji usługi oprócz dzienników wykonywania zadań.
Wyświetlanie ustawień konfiguracji klastra za pomocą interfejsu użytkownika systemu Ambari
Apache Ambari upraszcza zarządzanie, konfigurację i monitorowanie klastra usługi HDInsight, zapewniając internetowy interfejs użytkownika i interfejs API REST. System Ambari jest dołączony do klastrów usługi HDInsight opartych na systemie Linux. Wybierz okienko Pulpit nawigacyjny klastra na stronie usługi HDInsight w witrynie Azure Portal, aby otworzyć stronę linku Pulpity nawigacyjne klastra. Następnie wybierz okienko pulpitu nawigacyjnego klastra usługi HDInsight, aby otworzyć interfejs użytkownika systemu Ambari. Zostanie wyświetlony monit o podanie poświadczeń logowania klastra.
Aby otworzyć listę widoków usług, wybierz okienko Widoki systemu Ambari na stronie witryny Azure Portal dla usługi HDInsight. Ta lista różni się w zależności od zainstalowanych bibliotek. Na przykład mogą zostać wyświetlone pozycje Menedżer kolejek usługi YARN, Widok Hive i Tez View. Wybierz dowolny link usługi, aby wyświetlić informacje o konfiguracji i usłudze. Strona Stos i wersja interfejsu użytkownika systemu Ambari zawiera informacje o konfiguracji i historii wersji usług klastra. Aby przejść do tej sekcji interfejsu użytkownika systemu Ambari, wybierz menu Administratora, a następnie pozycję Stosy i wersje. Wybierz kartę Wersje , aby wyświetlić informacje o wersji usługi.
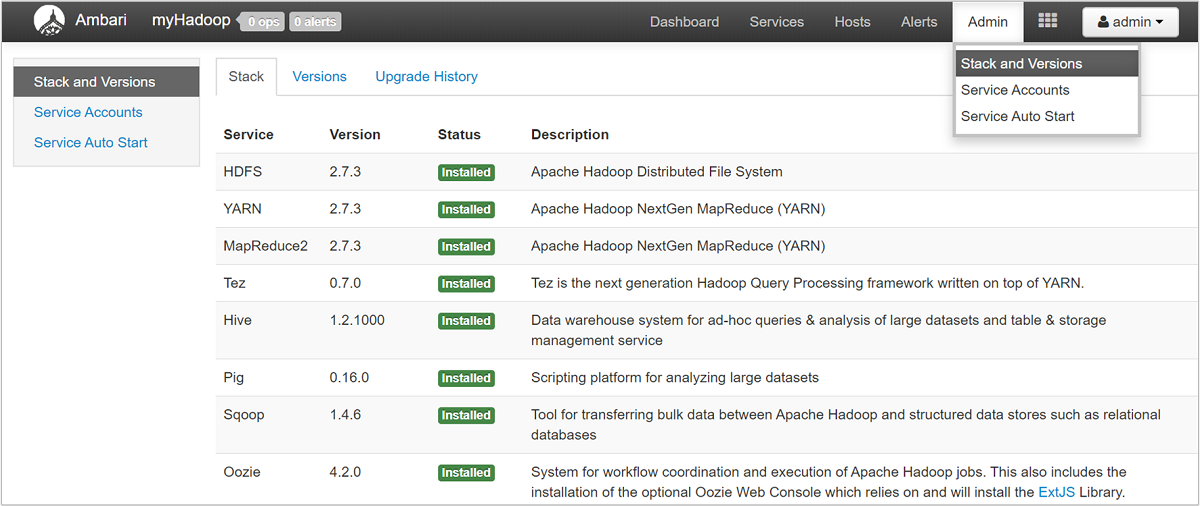
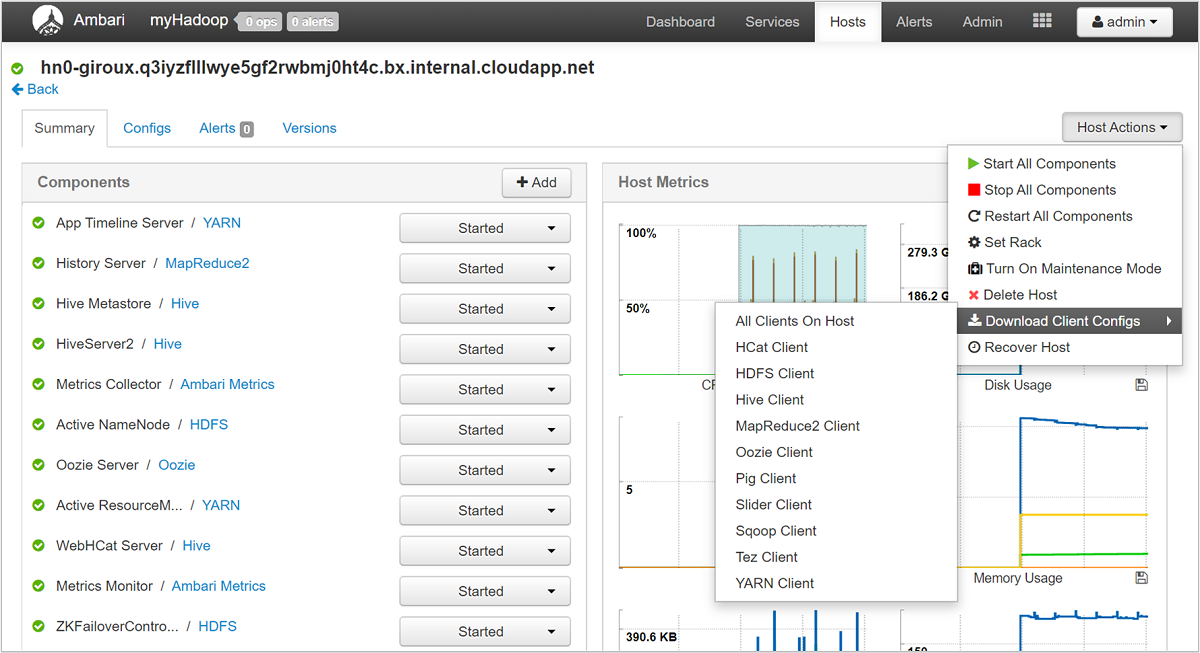
Za pomocą interfejsu użytkownika systemu Ambari możesz pobrać konfigurację dla dowolnych (lub wszystkich) usług uruchomionych na określonym hoście (lub węźle) w klastrze. Wybierz menu Hosty, a następnie link dla hosta zainteresowania. Na stronie tego hosta wybierz przycisk Akcje hosta, a następnie pozycję Pobierz konfiguracje klienta.
Wyświetlanie dzienników akcji skryptu
Akcje skryptów usługi HDInsight uruchamiają skrypty w klastrze ręcznie lub po określeniu. Na przykład akcje skryptu mogą służyć do instalowania innego oprogramowania w klastrze lub zmiany ustawień konfiguracji z wartości domyślnych. Dzienniki akcji skryptu mogą zapewnić wgląd w błędy, które wystąpiły podczas instalacji klastra, a także zmiany ustawień konfiguracji, które mogą mieć wpływ na wydajność i dostępność klastra. Aby wyświetlić stan akcji skryptu, wybierz przycisk ops w interfejsie użytkownika systemu Ambari lub uzyskaj dostęp do dzienników stanu na domyślnym koncie magazynu. Dzienniki magazynu są dostępne pod adresem /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Wyświetlanie dzienników stanu alertów systemu Ambari
System Apache Ambari zapisuje zmiany stanu alertu na ambari-alerts.log. Pełna ścieżka to /var/log/ambari-server/ambari-alerts.log. Aby włączyć debugowanie dziennika, zmień właściwość w /etc/ambari-server/conf/log4j.properties. obszarze Zmień, a następnie wpis poniżej:# Log alert state changes
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Krok 3. Zarządzanie plikami dziennika wykonywania zadań klastra
Następnym krokiem jest przejrzenie plików dziennika wykonywania zadania dla różnych usług. Usługi mogą obejmować platformy Apache HBase, Apache Spark i wiele innych. Klaster Hadoop generuje dużą liczbę pełnych dzienników, więc określenie, które dzienniki są przydatne (i które nie) mogą być czasochłonne. Zrozumienie systemu rejestrowania jest ważne w przypadku docelowego zarządzania plikami dziennika. Na poniższej ilustracji przedstawiono przykładowy plik dziennika.
Uzyskiwanie dostępu do plików dziennika usługi Hadoop
Usługa HDInsight przechowuje pliki dziennika zarówno w systemie plików klastra, jak i w usłudze Azure Storage. Pliki dziennika w klastrze można sprawdzić, otwierając połączenie SSH z klastrem i przeglądając system plików, lub korzystając z portalu stanu usługi Hadoop YARN na zdalnym serwerze węzła głównego. Pliki dziennika w usłudze Azure Storage można sprawdzić przy użyciu dowolnego narzędzia, które mogą uzyskiwać dostęp do danych i pobierać je z usługi Azure Storage. Przykłady to AzCopy, CloudXplorer i Eksplorator serwera programu Visual Studio. Do uzyskiwania dostępu do danych w usłudze Azure Blob Storage można również użyć programu PowerShell i bibliotek klienckich usługi Azure Storage lub zestawów SDK platformy Azure .NET.
Usługa Hadoop uruchamia pracę zadań jako próby zadania w różnych węzłach w klastrze. Usługa HDInsight może inicjować spekulacyjne próby zadań, przerywając wszelkie inne próby wykonania zadania, które nie są najpierw ukończone. Spowoduje to wygenerowanie znaczącej aktywności zarejestrowanej w plikach dziennika kontrolera, stderr i dziennika syslog na bieżąco. Ponadto wiele prób zadań jest uruchamianych jednocześnie, ale plik dziennika może wyświetlać wyniki tylko liniowo.
Dzienniki usługi HDInsight zapisywane w usłudze Azure Blob Storage
Klastry usługi HDInsight są skonfigurowane do zapisywania dzienników zadań na koncie usługi Azure Blob Storage dla dowolnego zadania przesłanego przy użyciu poleceń cmdlet programu Azure PowerShell lub interfejsów API przesyłania zadań platformy .NET. Jeśli przesyłasz zadania za pośrednictwem protokołu SSH do klastra, informacje rejestrowania wykonywania są przechowywane w tabelach platformy Azure zgodnie z opisem w poprzedniej sekcji.
Oprócz podstawowych plików dziennika generowanych przez usługę HDInsight zainstalowane usługi, takie jak YARN, generują również pliki dziennika wykonywania zadań. Liczba i typ plików dziennika zależą od zainstalowanych usług. Typowe usługi to Apache HBase, Apache Spark itd. Zbadaj pliki wykonywania dziennika zadań dla każdej usługi, aby poznać ogólne pliki rejestrowania dostępne w klastrze. Każda usługa ma własne unikatowe metody rejestrowania i lokalizacji do przechowywania plików dziennika. Na przykład szczegółowe informacje dotyczące uzyskiwania dostępu do najczęściej używanych plików dziennika usługi (z usługi YARN) zostały omówione w poniższej sekcji.
Dzienniki usługi HDInsight generowane przez usługę YARN
Usługa YARN agreguje dzienniki we wszystkich kontenerach w węźle procesu roboczego i przechowuje te dzienniki jako jeden zagregowany plik dziennika na węzeł roboczy. Ten dziennik jest przechowywany w domyślnym systemie plików po zakończeniu działania aplikacji. Aplikacja może używać setek lub tysięcy kontenerów, ale dzienniki dla wszystkich kontenerów uruchamianych w jednym węźle roboczym są zawsze agregowane do jednego pliku. Istnieje tylko jeden dziennik na węzeł roboczy używany przez aplikację. Agregacja dzienników jest domyślnie włączona w klastrach usługi HDInsight w wersji 3.0 lub nowszej. Zagregowane dzienniki znajdują się w domyślnym magazynie klastra.
/app-logs/<user>/logs/<applicationId>
Zagregowane dzienniki nie są bezpośrednio czytelne, ponieważ są zapisywane w formacie binarnym TFile indeksowanym przez kontener. Użyj dzienników usługi YARN ResourceManager lub narzędzi interfejsu wiersza polecenia, aby wyświetlić te dzienniki jako zwykły tekst dla interesujących aplikacji lub kontenerów.
Narzędzia interfejsu wiersza polecenia usługi YARN
Aby użyć narzędzi interfejsu wiersza polecenia usługi YARN, należy najpierw nawiązać połączenie z klastrem usługi HDInsight przy użyciu protokołu SSH.
<applicationId>Określ informacje , <user-who-started-the-application>, <containerId>i <worker-node-address> podczas uruchamiania tych poleceń. Dzienniki można wyświetlić jako zwykły tekst za pomocą jednego z następujących poleceń:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
Interfejs użytkownika usługi Resource Manager usługi YARN
Interfejs użytkownika usługi Resource Manager usługi YARN działa w węźle głównym klastra i jest dostępny za pośrednictwem internetowego interfejsu użytkownika systemu Ambari. Aby wyświetlić dzienniki usługi YARN, wykonaj następujące czynności:
- W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.netadresu . Zastąp CLUSTERNAME nazwą klastra usługi HDInsight: - Z listy usług po lewej stronie wybierz pozycję YARN.
- Z listy rozwijanej Szybkie linki wybierz jeden z węzłów głównych klastra, a następnie wybierz pozycję Dzienniki usługi Resource Manager. Zostanie wyświetlona lista linków do dzienników usługi YARN.
Krok 4. Prognozowanie rozmiarów i kosztów magazynu woluminów dziennika
Po wykonaniu poprzednich kroków masz wiedzę na temat typów i woluminów plików dziennika, które są tworzone przez klastry usługi HDInsight.
Następnie przeanalizuj ilość danych dziennika w lokalizacjach przechowywania dzienników kluczy w danym okresie. Na przykład można analizować wielkość i wzrost w ciągu 30-60-90 dni. Zapisz te informacje w arkuszu kalkulacyjnym lub użyj innych narzędzi, takich jak Visual Studio, Eksplorator usługi Azure Storage lub Power Query dla programu Excel. ```
Masz teraz wystarczającą ilość informacji, aby utworzyć strategię zarządzania dziennikami dla kluczowych dzienników. Użyj arkusza kalkulacyjnego (lub wybranego narzędzia), aby prognozować zarówno wzrost rozmiaru dziennika, jak i koszty usług platformy Azure magazynu dzienników w przyszłości. Należy również rozważyć wszelkie wymagania dotyczące przechowywania dzienników dla zestawu sprawdzanych dzienników. Teraz możesz reforecast przyszłych kosztów magazynu dzienników, po ustaleniu, które pliki dziennika można usunąć (jeśli istnieją) i które dzienniki powinny być przechowywane i archiwizowane w tańszej usłudze Azure Storage.
Krok 5. Określanie zasad i procesów archiwum dziennika
Po ustaleniu, które pliki dziennika można usunąć, można dostosować parametry rejestrowania w wielu usługach Hadoop, aby automatycznie usuwać pliki dziennika po określonym przedziale czasu.
W przypadku niektórych plików dziennika można użyć tańszego podejścia do archiwizowania plików dziennika. W przypadku dzienników aktywności usługi Azure Resource Manager możesz zapoznać się z tym podejściem przy użyciu witryny Azure Portal. Skonfiguruj archiwizowanie dzienników usługi Resource Manager, wybierając link Dziennik aktywności w witrynie Azure Portal dla wystąpienia usługi HDInsight. W górnej części strony przeszukiwania dziennika aktywności wybierz element menu Eksportuj, aby otworzyć okienko Eksportuj dziennik aktywności. Wypełnij subskrypcję, region, czy chcesz wyeksportować na konto magazynu, oraz liczbę dni przechowywania dzienników. W tym samym okienku można również wskazać, czy ma być eksportowany do centrum zdarzeń.
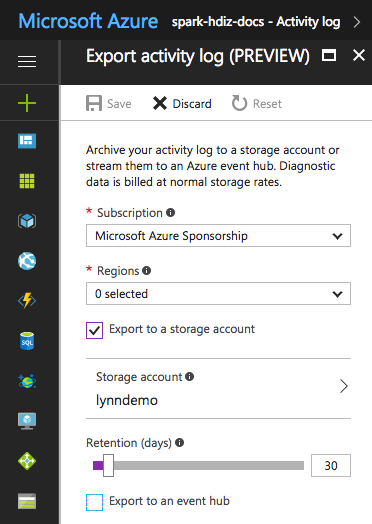
Alternatywnie możesz wykonać archiwizowanie dzienników skryptów za pomocą programu PowerShell.
Uzyskiwanie dostępu do metryk usługi Azure Storage
Usługę Azure Storage można skonfigurować do rejestrowania operacji magazynu i dostępu. Możesz użyć tych szczegółowych dzienników do monitorowania i planowania pojemności oraz inspekcji żądań do magazynu. Zarejestrowane informacje zawierają szczegółowe informacje o opóźnieniach, które umożliwiają monitorowanie i dostosowywanie wydajności rozwiązań. Zestaw SDK platformy .NET dla platformy Hadoop umożliwia sprawdzenie plików dziennika wygenerowanych dla usługi Azure Storage, która przechowuje dane dla klastra usługi HDInsight.
Kontrolowanie rozmiaru i liczby indeksów kopii zapasowych dla starych plików dziennika
Aby kontrolować rozmiar i liczbę zachowanych plików dziennika, ustaw następujące właściwości :RollingFileAppender
-
maxFileSizejest krytycznym rozmiarem pliku, który jest rzutowany. Wartość domyślna to 10 MB. -
maxBackupIndexokreśla liczbę plików kopii zapasowej do utworzenia, wartość domyślna 1.
Inne techniki zarządzania dziennikami
Aby uniknąć wyczerpania miejsca na dysku, możesz użyć niektórych narzędzi systemu operacyjnego, takich jak logrotate , aby zarządzać do obsługi plików dziennika. Można skonfigurować logrotate uruchamianie codziennie, kompresowanie plików dziennika i usuwanie starych. Twoje podejście zależy od wymagań, takich jak czas przechowywania plików dziennika w węzłach lokalnych.
Możesz również sprawdzić, czy rejestrowanie debugowania jest włączone dla co najmniej jednej usługi, co znacznie zwiększa rozmiar dziennika wyjściowego.
Aby zebrać dzienniki ze wszystkich węzłów do jednej centralnej lokalizacji, możesz utworzyć przepływ danych, taki jak pozyskiwanie wszystkich wpisów dziennika do rozwiązania Solr.