Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Rozwiązania do obsługi danych big data w czasie rzeczywistym działają na danych, które są w ruchu. Zazwyczaj te dane są najcenniejsze w momencie ich przybycia. Jeśli przychodzący strumień danych stanie się większy niż można obsłużyć w tej chwili, może być konieczne ograniczenie zasobów. Alternatywnie klaster usługi HDInsight może zwiększać skalę, aby spełnić wymagania rozwiązania do przesyłania strumieniowego, dodając węzły na żądanie.
W aplikacji przesyłania strumieniowego co najmniej jedno źródło danych generuje zdarzenia (czasami w milionach sekund), które muszą być pozyskiwane szybko bez porzucania żadnych przydatnych informacji. Zdarzenia przychodzące są obsługiwane z buforowaniem strumienia, nazywanym również kolejkowaniem zdarzeń, przez usługę, taką jak Apache Kafka lub Event Hubs. Po zebraniu zdarzeń można następnie analizować dane przy użyciu systemu analizy w czasie rzeczywistym w warstwie przetwarzania strumieniowego. Przetworzone dane mogą być przechowywane w długoterminowych systemach magazynowania, takich jak Usługa Azure Data Lake Storage, i wyświetlane w czasie rzeczywistym na pulpicie nawigacyjnym analizy biznesowej, takim jak Power BI, Tableau lub niestandardowa strona internetowa.
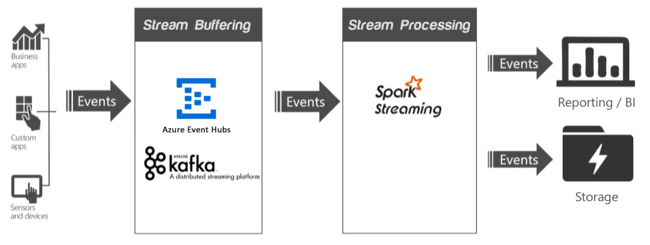
Apache Kafka
Platforma Apache Kafka udostępnia usługę kolejkowania komunikatów o wysokiej przepływności o małych opóźnieniach i jest teraz częścią pakietu Apache oprogramowania typu open source (OSS). Platforma Kafka używa modelu publikowania i subskrybowania komunikatów oraz przechowuje strumienie partycjonowanych danych w rozproszonym, replikowanym klastrze. Platforma Kafka skaluje się liniowo wraz ze wzrostem przepustowości.
Aby uzyskać więcej informacji, zobacz Wprowadzenie do platformy Apache Kafka w usłudze HDInsight.
Spark Streaming
Spark Streaming to rozszerzenie platformy Spark, które umożliwia wykorzystanie tego samego kodu, który jest używany do przetwarzania wsadowego. Zapytania wsadowe i interakcyjne można łączyć w tej samej aplikacji. W przeciwieństwie do Spark, przetwarzanie strumieniowe zapewnia semantykę przetwarzania stanowego z dokładnością do jednego razu. W przypadku użycia w połączeniu z interfejsem API Direct platformy Kafka, który gwarantuje, że wszystkie dane Kafka odbierane w Spark Streaming są przetwarzane dokładnie raz, możliwe jest osiągnięcie kompleksowych gwarancji przetwarzania dokładnie raz. Jedną z zalet przesyłania strumieniowego platformy Spark jest możliwość odporności na błędy, szybko odzyskując uszkodzone węzły, gdy w klastrze jest używanych wiele węzłów.
Aby uzyskać więcej informacji, zobacz Co to jest przesyłanie strumieniowe Apache Spark?.
Skalowanie klastra
Chociaż podczas tworzenia można określić liczbę węzłów w klastrze, możesz zwiększyć lub zmniejszyć klaster, aby był zgodny z obciążeniem. Wszystkie klastry usługi HDInsight umożliwiają zmianę liczby węzłów w klastrze. Klastry Spark można usuwać bez utraty danych, ponieważ wszystkie dane są przechowywane w usłudze Azure Storage lub Data Lake Storage.
Istnieją zalety oddzielenia technologii. Na przykład platforma Kafka jest technologią buforowania zdarzeń, więc jest bardzo intensywnie obciążana operacjami we/wy i nie wymaga dużej mocy obliczeniowej. W porównaniu, procesory strumieniowe, takie jak Spark Streaming, są obciążone obliczeniowo, co wymaga użycia bardziej zaawansowanych maszyn wirtualnych. Dzięki rozdzieleniu tych technologii na różne klastry można je skalować niezależnie, korzystając z maszyn wirtualnych.
Skalowanie warstwy buforowania strumienia
Technologie buforowania strumieniowego, takie jak Event Hubs i Kafka, używają partycji, a czytelnicy odczytują dane z tych partycji. Skalowanie przepływności wejściowej wymaga skalowania w górę liczby partycji, a dodawanie partycji zapewnia zwiększenie równoległości. W usłudze Event Hubs nie można zmienić liczby partycji po wdrożeniu, dlatego należy zacząć od skali docelowej. Za pomocą platformy Kafka można dodawać partycje, nawet jeśli platforma Kafka przetwarza dane. Platforma Kafka udostępnia narzędzie do ponownego przypisania partycji, kafka-reassign-partitions.sh. Usługa HDInsight udostępnia narzędzie do ponownego równoważenia repliki partycji, rebalance_rackaware.py. To narzędzie ponownego równoważenia wywołuje narzędzie kafka-reassign-partitions.sh w taki sposób, że każda replika znajduje się w oddzielnej domenie błędów i aktualizacji, dzięki czemu Kafka jest świadoma lokalizacji stelaży i zwiększa odporność na błędy.
Skalowanie warstwy przetwarzania strumienia
Przesyłanie strumieniowe platformy Apache Spark obsługuje dodawanie węzłów roboczych do klastrów, nawet jeśli dane są przetwarzane.
Platforma Apache Spark używa trzech kluczowych parametrów do konfigurowania środowiska w zależności od wymagań aplikacji: spark.executor.instances, spark.executor.coresi spark.executor.memory.
Funkcja wykonawcza to proces uruchamiany dla aplikacji Spark. Funkcja wykonawcza jest uruchamiana w węźle roboczym i jest odpowiedzialna za wykonywanie zadań aplikacji. Domyślna liczba executorów i rozmiary executorów dla każdego klastra są obliczane na podstawie liczby węzłów roboczych i rozmiaru węzła roboczego. Te liczby są przechowywane w spark-defaults.confpliku w każdym węźle głównym klastra.
Te trzy parametry można skonfigurować na poziomie klastra dla wszystkich aplikacji uruchamianych w klastrze i można również określić dla każdej aplikacji. Aby uzyskać więcej informacji, zobacz Zarządzanie zasobami dla klastrów Platformy Apache Spark.