Debugowanie zadań platformy Apache Spark uruchomionych w usłudze Azure HDInsight
Z tego artykułu dowiesz się, jak śledzić i debugować zadania platformy Apache Spark uruchomione w klastrach usługi HDInsight. Debuguj przy użyciu interfejsu użytkownika usługi Apache Hadoop YARN, interfejsu użytkownika platformy Spark i serwera historii platformy Spark. Uruchamiasz zadanie platformy Spark przy użyciu notesu dostępnego w klastrze Spark, Uczenie maszynowe: analiza predykcyjna danych inspekcji żywności przy użyciu biblioteki MLLib. Wykonaj poniższe kroki, aby śledzić aplikację przesłaną przy użyciu dowolnego innego podejścia, na przykład spark-submit.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight.
Należy uruchomić notes Machine Learning: Analiza predykcyjna danych inspekcji żywności przy użyciu biblioteki MLLib. Aby uzyskać instrukcje dotyczące uruchamiania tego notesu, postępuj zgodnie z linkiem.
Śledzenie aplikacji w interfejsie użytkownika usługi YARN
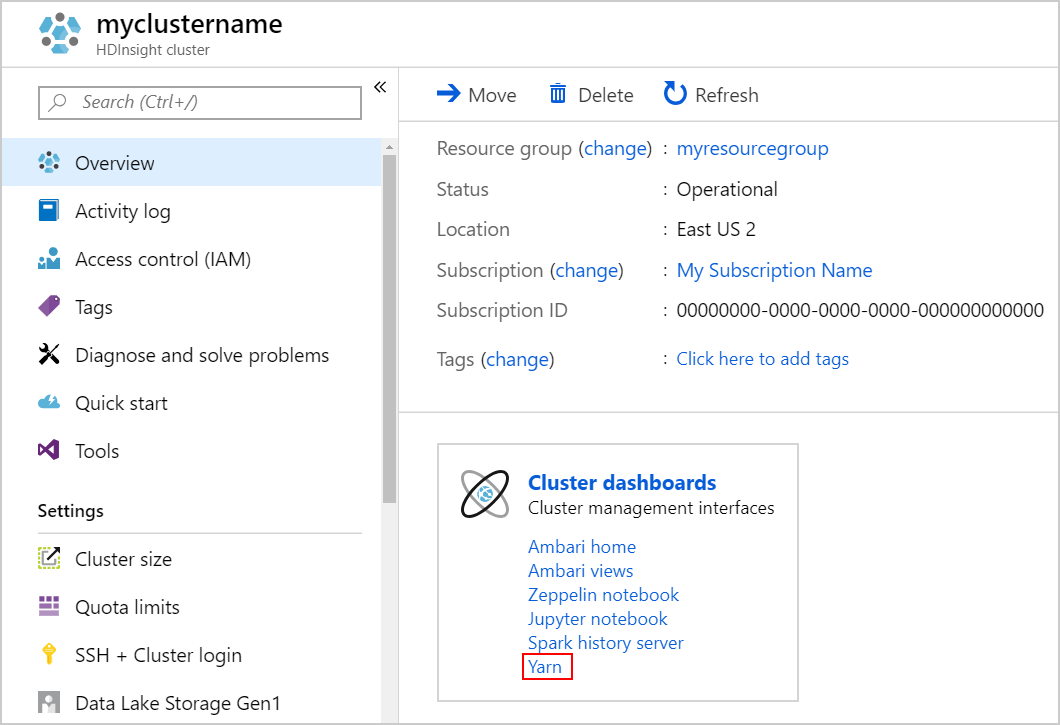
Uruchom interfejs użytkownika usługi YARN. Wybierz pozycję Yarn w obszarze Pulpity nawigacyjne klastra.
Napiwek
Alternatywnie możesz również uruchomić interfejs użytkownika usługi YARN z poziomu interfejsu użytkownika systemu Ambari. Aby uruchomić interfejs użytkownika systemu Ambari, wybierz pozycję Ambari home w obszarze Pulpity nawigacyjne klastra. W interfejsie użytkownika systemu Ambari przejdź do pozycji Szybkie linki> do> aktywnego interfejsu użytkownika usługi Resource Manager usługi Resource Manager.>
Ponieważ uruchomiono zadanie spark przy użyciu notesów Jupyter Notebooks, aplikacja ma nazwę remotesparkmagics (nazwa wszystkich aplikacji uruchomionych z notesów). Wybierz identyfikator aplikacji względem nazwy aplikacji, aby uzyskać więcej informacji o zadaniu. Ta akcja powoduje uruchomienie widoku aplikacji.
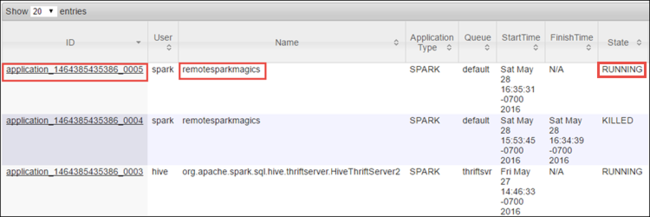
W przypadku takich aplikacji, które są uruchamiane z notesów Jupyter Notebook, stan jest zawsze uruchomiony do momentu zamknięcia notesu.
W widoku aplikacji możesz przejść do szczegółów, aby dowiedzieć się więcej o kontenerach skojarzonych z aplikacją i dziennikach (stdout/stderr). Możesz również uruchomić interfejs użytkownika platformy Spark, klikając link odpowiadający adresowi URL śledzenia, jak pokazano poniżej.
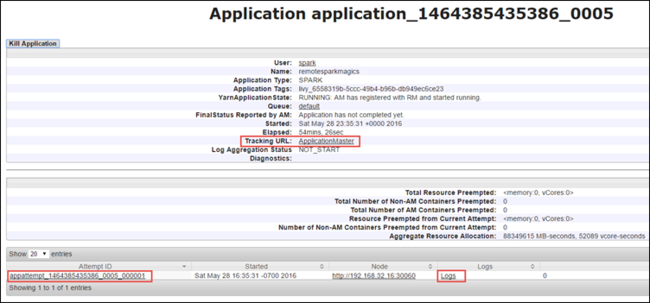
Śledzenie aplikacji w interfejsie użytkownika platformy Spark
W interfejsie użytkownika platformy Spark możesz przejść do szczegółów zadań platformy Spark, które zostały zduplikowane przez uruchomioną wcześniej aplikację.
Aby uruchomić interfejs użytkownika platformy Spark, w widoku aplikacji wybierz link względem adresu URL śledzenia, jak pokazano w powyższym przechwytywaniu ekranu. Wszystkie zadania platformy Spark, które są uruchamiane przez aplikację uruchomioną w notesie Jupyter Notebook.
Wybierz kartę Funkcje wykonawcze, aby wyświetlić informacje o przetwarzaniu i przechowywaniu dla każdego wykonawcy. Możesz również pobrać stos wywołań, wybierając link Zrzut wątku.
Wybierz kartę Etapy , aby wyświetlić etapy skojarzone z aplikacją.
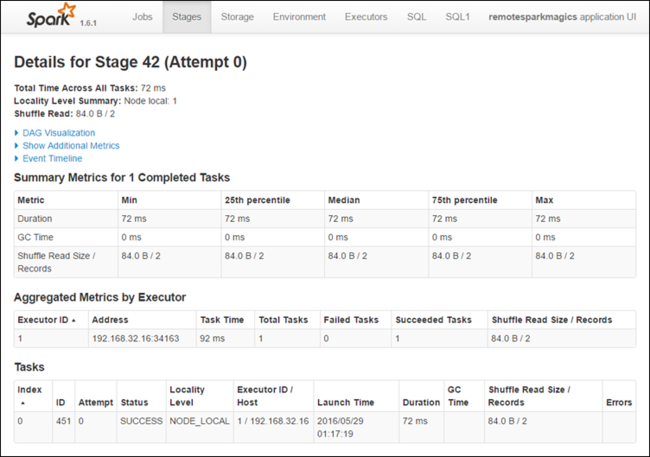
Każdy etap może mieć wiele zadań, dla których można wyświetlić statystyki wykonywania, jak pokazano poniżej.
Na stronie szczegółów etapu możesz uruchomić wizualizację JĘZYKA DAG. Rozwiń link Wizualizacja języka DAG w górnej części strony, jak pokazano poniżej.
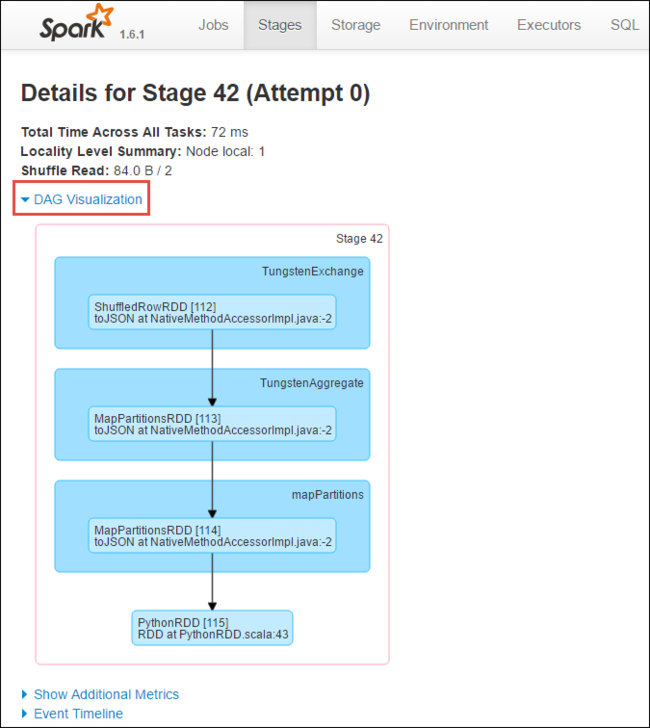
DaG lub Direct Aclyic Graph reprezentuje różne etapy w aplikacji. Każde niebieskie pole na grafie reprezentuje operację platformy Spark wywołaną z aplikacji.
Na stronie szczegółów etapu można również uruchomić widok osi czasu aplikacji. Rozwiń link Oś czasu zdarzenia w górnej części strony, jak pokazano poniżej.
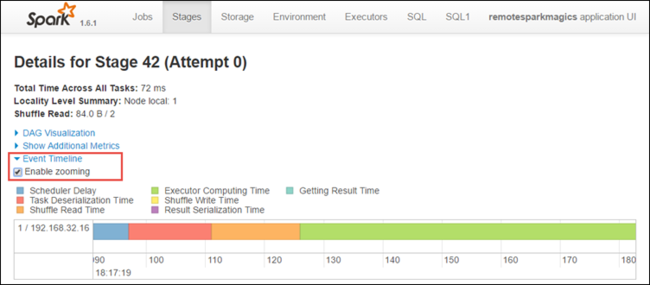
Ten obraz przedstawia zdarzenia platformy Spark w postaci osi czasu. Widok osi czasu jest dostępny na trzech poziomach, między zadaniami, w ramach zadania i na etapie. Powyższy obraz przechwytuje widok osi czasu dla danego etapu.
Napiwek
Jeśli zaznaczysz pole wyboru Włącz powiększanie , możesz przewinąć w lewo i w prawo w widoku osi czasu.
Inne karty w interfejsie użytkownika platformy Spark zawierają również przydatne informacje o wystąpieniu platformy Spark.
- Karta Magazyn — jeśli aplikacja tworzy RDD, możesz znaleźć informacje na karcie Magazyn.
- Karta Środowisko — ta karta zawiera przydatne informacje o wystąpieniu platformy Spark, takie jak:
- Wersja języka Scala
- Katalog dziennika zdarzeń skojarzony z klastrem
- Liczba rdzeni funkcji wykonawczej dla aplikacji
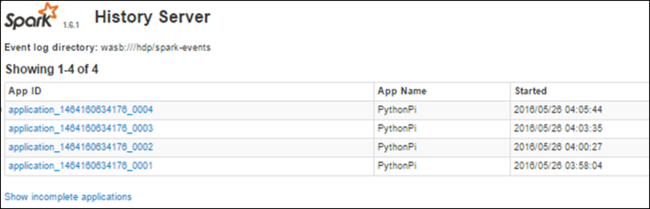
Znajdowanie informacji o ukończonych zadaniach przy użyciu serwera historii platformy Spark
Po zakończeniu zadania informacje o zadaniu są utrwalane na serwerze historii platformy Spark.
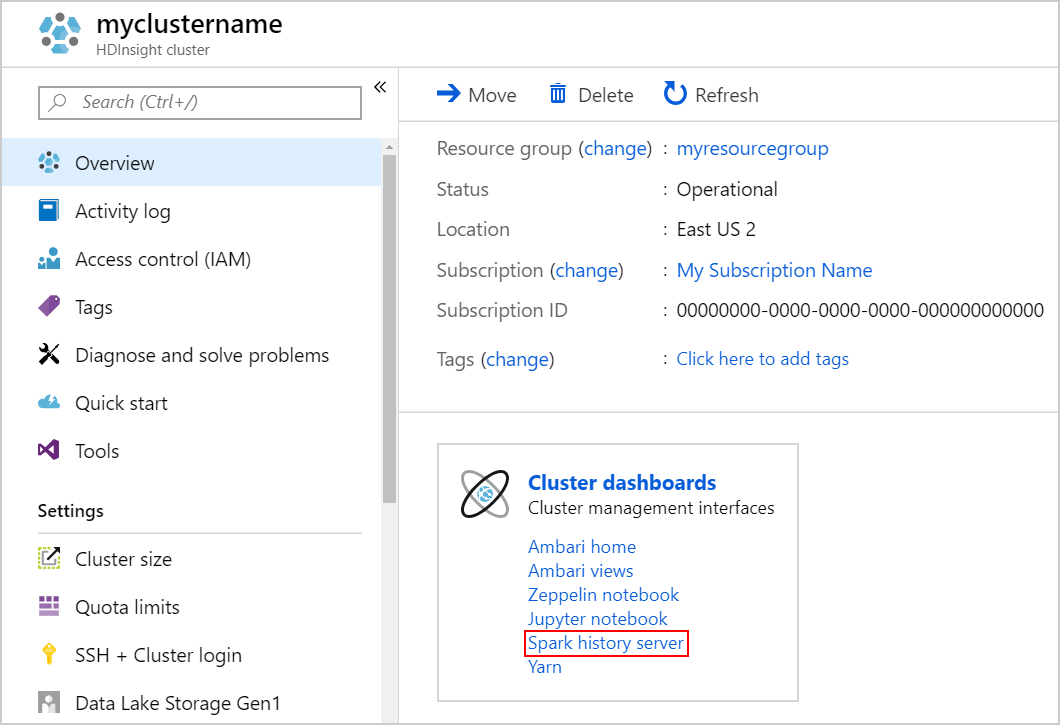
Aby uruchomić serwer historii platformy Spark, na stronie Przegląd wybierz pozycję Serwer historii platformy Spark w obszarze Pulpity nawigacyjne klastra.
Napiwek
Alternatywnie możesz również uruchomić interfejs użytkownika serwera historii platformy Spark z poziomu interfejsu użytkownika systemu Ambari. Aby uruchomić interfejs użytkownika systemu Ambari, w bloku Przegląd wybierz pozycję Ambari home w obszarze Pulpity nawigacyjne klastra. W interfejsie użytkownika systemu Ambari przejdź do interfejsu użytkownika serwera historii Spark2 Szybki link>Spark2.>
Zostaną wyświetlone wszystkie ukończone aplikacje. Wybierz identyfikator aplikacji, aby przejść do szczegółów aplikacji, aby uzyskać więcej informacji.