Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak za pomocą biblioteki MLlib platformy Apache Spark utworzyć aplikację uczenia maszynowego. Aplikacja wykonuje analizę predykcyjną otwartego zestawu danych. Z wbudowanych bibliotek uczenia maszynowego platformy Spark w tym przykładzie użyto klasyfikacji za pośrednictwem regresji logistycznej.
Biblioteka MLlib to podstawowa biblioteka platformy Spark, która udostępnia wiele narzędzi przydatnych w przypadku zadań uczenia maszynowego, takich jak:
- Klasyfikacja
- Regresja
- Klastrowanie
- Modelowanie
- Dekompozycja wartości pojedynczej (SVD) i analiza głównych składników (PCA)
- Testowanie hipotez i obliczanie przykładowych statystyk
Omówienie klasyfikacji i regresji logistycznej
Klasyfikacja, popularne zadanie uczenia maszynowego, to proces sortowania danych wejściowych w kategorie. Jest to zadanie algorytmu klasyfikacji, aby dowiedzieć się, jak przypisać "etykiety" do danych wejściowych, które podajesz. Można na przykład myśleć o algorytmie uczenia maszynowego, który akceptuje informacje giełdowe jako dane wejściowe. Następnie dzieli akcje na dwie kategorie: akcje, które należy sprzedawać i akcje, które należy zachować.
Regresja logistyczna to algorytm używany do klasyfikacji. Interfejs API regresji logistycznej platformy Spark jest przydatny do klasyfikacji binarnej lub klasyfikowania danych wejściowych w jedną z dwóch grup. Aby uzyskać więcej informacji na temat regresji logistycznej, zobacz Wikipedia.
Podsumowując, proces regresji logistycznej generuje funkcję logistyczną. Użyj funkcji , aby przewidzieć prawdopodobieństwo, że wektor wejściowy należy do jednej grupy lub drugiej.
Przykład analizy predykcyjnej danych inspekcji żywności
W tym przykładzie użyjesz platformy Spark do przeprowadzenia analizy predykcyjnej na temat danych inspekcji żywności (Food_Inspections1.csv). Dane uzyskane za pośrednictwem portalu danych City of Chicago. Ten zestaw danych zawiera informacje o inspekcjach zakładów żywnościowych, które zostały przeprowadzone w Chicago. W tym informacje o każdym zakładzie, naruszenia znalezione (jeśli istnieją) oraz wyniki inspekcji. Plik danych CSV jest już dostępny na koncie magazynu skojarzonym z klastrem w lokalizacji /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv.
W poniższych krokach utworzysz model, aby zobaczyć, co trzeba zrobić, aby przejść lub zakończyć inspekcję żywności.
Tworzenie aplikacji uczenia maszynowego MLlib platformy Apache Spark
Utwórz notes Jupyter Przy użyciu jądra PySpark. Aby uzyskać instrukcje, zobacz Tworzenie pliku notesu Jupyter Notebook.
Zaimportuj typy wymagane dla tej aplikacji. Skopiuj i wklej następujący kod do pustej komórki, a następnie naciśnij klawisze SHIFT + ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Ze względu na jądro PySpark nie trzeba jawnie tworzyć żadnych kontekstów. Konteksty Spark i Hive są tworzone automatycznie podczas uruchamiania pierwszej komórki kodu.
Konstruowanie ramki danych wejściowych
Użyj kontekstu platformy Spark, aby ściągnąć nieprzetworzone dane CSV do pamięci jako tekst bez struktury. Następnie użyj biblioteki CSV języka Python, aby przeanalizować każdy wiersz danych.
Uruchom następujące wiersze, aby utworzyć odporny rozproszony zestaw danych (RDD) przez zaimportowanie i przeanalizowanie danych wejściowych.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Uruchom następujący kod, aby pobrać jeden wiersz z RDD, aby zapoznać się ze schematem danych:
inspections.take(1)Dane wyjściowe to:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]Dane wyjściowe zawierają informacje o schemacie pliku wejściowego. Zawiera nazwę każdego zakładu oraz typ zakładu. Ponadto adres, dane inspekcji i lokalizacja, między innymi.
Uruchom następujący kod, aby utworzyć ramkę danych (df) i tabelę tymczasową (CountResults) z kilkoma kolumnami przydatnymi do analizy predykcyjnej.
sqlContextsłuży do przekształcania danych strukturalnych.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Cztery interesujące kolumny ramki danych to identyfikator, nazwa, wyniki i naruszenia.
Uruchom następujący kod, aby uzyskać niewielką próbkę danych:
df.show(5)Dane wyjściowe to:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Omówienie danych
Zacznijmy zrozumieć, co zawiera zestaw danych.
Uruchom następujący kod, aby wyświetlić odrębne wartości w kolumnie wyników :
df.select('results').distinct().show()Dane wyjściowe to:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Uruchom następujący kod, aby zwizualizować rozkład tych wyników:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsNastępnie magia
%%sql-o countResultsdfgwarantuje, że dane wyjściowe zapytania są utrwalane lokalnie na serwerze Jupyter (zazwyczaj w węźle głównym klastra). Dane wyjściowe są utrwalane jako ramka danych biblioteki Pandas z określoną nazwą countResultsdf. Aby uzyskać więcej informacji na temat%%sqlmagii i innych magii dostępnych w jądrze PySpark, zobacz Jądra dostępne w notesach Jupyter Notebooks with Apache Spark HDInsight clusters (Jądra dostępne w notesach Jupyter Notebooks z klastrami apache Spark HDInsight).Dane wyjściowe to:
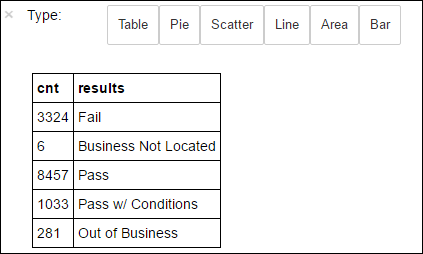
Do utworzenia wykresu można również użyć biblioteki Matplotlib, która służy do konstruowania wizualizacji danych. Ponieważ wykres musi zostać utworzony na podstawie lokalnie utrwalonej ramki danych countResultsdf , fragment kodu musi zaczynać się od
%%localmagii. Ta akcja gwarantuje, że kod jest uruchamiany lokalnie na serwerze Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Aby przewidzieć wynik inspekcji żywności, należy opracować model na podstawie naruszeń. Ponieważ regresja logistyczna jest metodą klasyfikacji binarnej, warto zgrupować dane wynikowe w dwie kategorie: Niepowodzenie i Przekazywanie:
Zdane
- Zdane
- Przejmij warunki
Niepowodzenie
- Niepowodzenie
Odrzuć
- Firma nie znajduje się
- Poza biznesem
Dane z innymi wynikami ("Firma nie znajduje się" lub "Poza firmą") nie są przydatne i mimo to tworzą niewielki procent wyników.
Uruchom następujący kod, aby przekonwertować istniejącą ramkę danych(
df) na nową ramkę danych, w której każda inspekcja jest reprezentowana jako para naruszeń etykiet. W takim przypadku etykieta0.0reprezentuje błąd, etykietę1.0reprezentującą sukces, a etykieta-1.0reprezentuje niektóre wyniki oprócz tych dwóch wyników.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Uruchom następujący kod, aby wyświetlić jeden wiersz oznaczonych danymi:
labeledData.take(1)Dane wyjściowe to:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Tworzenie modelu regresji logistycznej na podstawie ramki danych wejściowych
Ostatnim zadaniem jest przekonwertowanie oznaczonych danych. Przekonwertuj dane na format analizowany przez regresję logistyczną. Dane wejściowe algorytmu regresji logistycznej wymagają zestawu par wektorów etykiet. Gdzie "wektor funkcji" jest wektorem liczb reprezentujących punkt wejściowy. Dlatego należy przekonwertować kolumnę "naruszenia", która jest częściowo ustrukturyzowana i zawiera wiele komentarzy w wolnym tekście. Przekonwertuj kolumnę na tablicę liczb rzeczywistych, którą maszyna może łatwo zrozumieć.
Jedną ze standardowych metod uczenia maszynowego do przetwarzania języka naturalnego jest przypisanie każdego odrębnego słowa indeksu. Następnie przekaż wektor do algorytmu uczenia maszynowego. Tak, aby wartość każdego indeksu zawierała względną częstotliwość tego słowa w ciągu tekstowym.
Biblioteka MLlib umożliwia łatwe wykonywanie tej operacji. Najpierw "tokenizuj" każdy ciąg naruszenia, aby uzyskać poszczególne wyrazy w każdym ciągu. Następnie użyj elementu , HashingTF aby przekonwertować każdy zestaw tokenów na wektor funkcji, który następnie może zostać przekazany do algorytmu regresji logistycznej w celu skonstruowania modelu. Wszystkie te kroki należy wykonać w sekwencji przy użyciu potoku.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Ocena modelu przy użyciu innego zestawu danych
Możesz użyć utworzonego wcześniej modelu, aby przewidzieć wyniki nowych inspekcji. Przewidywania są oparte na zaobserwowanych naruszeniach. Ten model został wytrenowany na Food_Inspections1.csv zestawu danych. Możesz użyć drugiego zestawu danych, Food_Inspections2.csv, aby ocenić siłę tego modelu na nowych danych. Ten drugi zestaw danych (Food_Inspections2.csv) znajduje się w domyślnym kontenerze magazynu skojarzonym z klastrem.
Uruchom następujący kod, aby utworzyć nową ramkę danych predictionsDf zawierającą przewidywanie wygenerowane przez model. Fragment kodu tworzy również tymczasową tabelę o nazwie Predictions na podstawie ramki danych.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsPowinny zostać wyświetlone dane wyjściowe podobne do następującego tekstu:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Przyjrzyj się jednemu z przewidywań. Uruchom ten fragment kodu:
predictionsDf.take(1)Istnieje przewidywanie pierwszego wpisu w zestawie danych testowych.
Metoda
model.transform()stosuje tę samą transformację do wszelkich nowych danych z tym samym schematem i jest przewidywana sposób klasyfikowania danych. Możesz wykonać pewne statystyki, aby zrozumieć, jak były przewidywania:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")Dane wyjściowe wyglądają podobnie do następującego tekstu:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateUżycie regresji logistycznej na platformie Spark zapewnia model relacji między opisami naruszeń w języku angielskim. I czy dana firma przejdzie, czy nie inspekcji żywności.
Tworzenie wizualnej reprezentacji przewidywania
Teraz możesz utworzyć ostateczną wizualizację, aby ułatwić zapoznanie się z wynikami tego testu.
Zacznij od wyodrębnienia różnych przewidywań i wyników z tabeli tymczasowej Predictions utworzonej wcześniej. Następujące zapytania oddzielają dane wyjściowe jako dane wyjściowe true_positive, false_positive, true_negative i false_negative. W poniższych zapytaniach wyłączysz wizualizację przy użyciu polecenia
-q, a także zapiszesz dane wyjściowe (przy użyciu polecenia-o) jako ramki danych, które mogą być następnie używane z magią%%local.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Na koniec użyj poniższego fragmentu kodu, aby wygenerować wykres przy użyciu biblioteki Matplotlib.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Powinny zostać wyświetlone następujące dane wyjściowe:
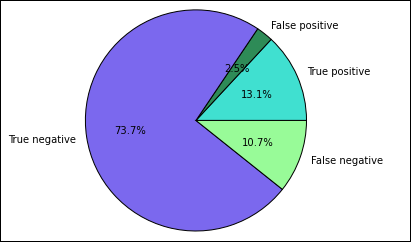
Na tym wykresie wynik "pozytywny" odnosi się do nieudanej inspekcji żywności, podczas gdy negatywny wynik odnosi się do uchwalonej kontroli.
Zamykanie notesu
Po uruchomieniu aplikacji należy zamknąć notes, aby zwolnić zasoby. W tym celu w menu File (Plik) w notesie wybierz pozycję Close and Halt (Zamknij i zatrzymaj). Ta akcja powoduje zatrzymanie i zamknięcie notesu.