Analizowanie danych w usłudze Data Lake Storage Gen1 przy użyciu klastra HDInsight Spark
W tym artykule użyjesz notesu Jupyter Notebook dostępnego w klastrach HDInsight Spark, aby uruchomić zadanie odczytujące dane z konta usługi Data Lake Storage.
Wymagania wstępne
Konto usługi Azure Data Lake Storage Gen1. Postępuj zgodnie z instrukcjami w artykule Rozpoczynanie pracy z usługą Azure Data Lake Storage Gen1 przy użyciu witryny Azure Portal.
Klaster Spark usługi Azure HDInsight z usługą Data Lake Storage Gen1 jako magazynem. Postępuj zgodnie z instrukcjami w przewodniku Szybki start: konfigurowanie klastrów w usłudze HDInsight.
Przygotowywanie danych
Uwaga
Nie musisz wykonywać tego kroku, jeśli utworzono klaster usługi HDInsight z usługą Data Lake Storage jako magazyn domyślny. Proces tworzenia klastra dodaje przykładowe dane na koncie usługi Data Lake Storage określonym podczas tworzenia klastra. Przejdź do sekcji Używanie klastra Spark usługi HDInsight z usługą Data Lake Storage.
Jeśli utworzono klaster usługi HDInsight z usługą Data Lake Storage jako dodatkowy magazyn i obiekt blob usługi Azure Storage jako magazyn domyślny, najpierw skopiuj przykładowe dane na konto usługi Data Lake Storage. Możesz użyć przykładowych danych z obiektu blob usługi Azure Storage skojarzonego z klastrem usługi HDInsight.
Otwórz wiersz polecenia i przejdź do katalogu, w którym zainstalowano narzędzie AdlCopy, zazwyczaj
%HOMEPATH%\Documents\adlcopy.Uruchom następujące polecenie, aby skopiować określony obiekt blob z kontenera źródłowego do usługi Data Lake Storage:
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>Skopiuj przykładowy plik danych HVAC.csv w lokalizacji /HdiSamples/HdiSamples/SensorSampleData/hvac/ na konto usługi Azure Data Lake Storage. Fragment kodu powinien wyglądać następująco:
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==Ostrzeżenie
Upewnij się, że nazwy plików i ścieżek używają odpowiednich liter.
Zostanie wyświetlony monit o wprowadzenie poświadczeń dla subskrypcji platformy Azure, w ramach której masz konto usługi Data Lake Storage. Zostaną wyświetlone dane wyjściowe podobne do następującego fragmentu kodu:
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.Plik danych (HVAC.csv) zostanie skopiowany w folderze /hvac na koncie usługi Data Lake Storage.
Używanie klastra SPARK usługi HDInsight z usługą Data Lake Storage Gen1
W witrynie Azure Portal na tablicy startowej kliknij kafelek klastra Apache Spark (jeśli przypięty został on do tablicy startowej). Możesz także przejść do klastra, wybierając polecenia Przeglądaj wszystko>Klastry usługi HDInsight.
W bloku klastra Spark kliknij pozycję Szybkie linki, a następnie w bloku Pulpit nawigacyjny klastra kliknij pozycję Jupyter Notebook. Jeśli zostanie wyświetlony monit, wprowadź poświadczenia administratora klastra.
Uwaga
Można również przejść do aplikacji Jupyter Notebook dla klastra, otwierając następujący adres URL w przeglądarce. Zastąp ciąg CLUSTERNAME nazwą klastra:
https://CLUSTERNAME.azurehdinsight.net/jupyterUtwórz nowy notes. Kliknij opcję New (Nowy), a następnie kliknij pozycję PySpark.
Ponieważ notes został utworzony z użyciem jądra PySpark, nie ma konieczności jawnego tworzenia kontekstów. Konteksty Spark i Hive zostaną automatycznie utworzone po uruchomieniu pierwszej komórki kodu. Możesz zacząć od importowania typów wymaganych w tym scenariuszu. W tym celu wklej poniższy fragment kodu w komórce i naciśnij klawisze SHIFT + ENTER.
from pyspark.sql.types import *Przy każdym uruchomieniu zadania w oprogramowaniu Jupyter w tytule okna przeglądarki sieci Web będzie wyświetlony stan (Busy) (Zajęty) wraz z tytułem notesu. Widoczne będzie także pełne kółko obok tekstu PySpark w prawym górnym rogu. Po zakończeniu zadania zmieni się ono w pusty okrąg.

Załaduj przykładowe dane do tabeli tymczasowej przy użyciu pliku HVAC.csv skopiowanego na konto usługi Data Lake Storage Gen1. Dostęp do danych na koncie usługi Data Lake Storage można uzyskać przy użyciu następującego wzorca adresu URL.
Jeśli masz magazyn usługi Data Lake Storage Gen1 jako domyślny, HVAC.csv będzie znajdować się w ścieżce podobnej do następującego adresu URL:
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvMożesz też użyć skróconego formatu, takiego jak:
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csvJeśli masz usługę Data Lake Storage jako dodatkowy magazyn, HVAC.csv będzie znajdować się w lokalizacji, w której zostały skopiowane, na przykład:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>W pustej komórce wklej poniższy przykładowy kod, zastąp ciąg MYDATALAKESTORE nazwą konta usługi Data Lake Storage, a następnie naciśnij klawisze SHIFT + ENTER. Ten przykład kodu rejestruje dane w tabeli tymczasowej o nazwie hvac.
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
Ponieważ używane jest jądro PySpark, można teraz bezpośrednio uruchomić zapytanie SQL w tabeli tymczasowej hvac utworzonej przed chwilą za pomocą polecenia magicznego
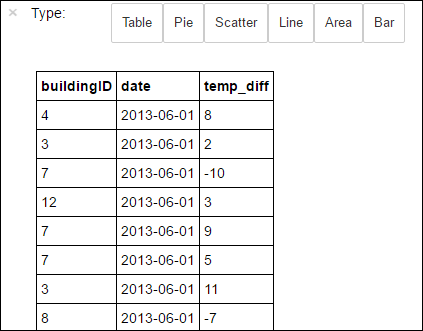
%%sql. Aby uzyskać więcej informacji na temat%%sqlmagii, a także innych magii dostępnych w jądrze PySpark, zobacz Jądra dostępne w notesach Jupyter Notebooks with Apache Spark HDInsight clusters (Jądra dostępne w notesach Jupyter Notebooks z klastrami apache Spark HDInsight).%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Po pomyślnym ukończeniu zadania domyślnie wyświetlane są następujące tabelaryczne dane wyjściowe.
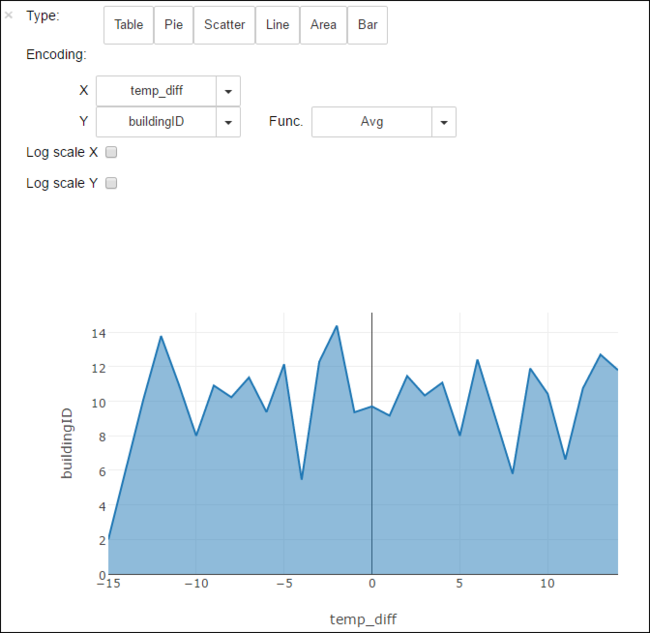
Wyniki można również przeglądać w postaci innych wizualizacji. Na przykład wykres warstwowy tych samych danych wyjściowych będzie wyglądać w następujący sposób.
Po zakończeniu działania aplikacji należy ją zamknąć, aby zwolnić zasoby. W tym celu w menu File (Plik) w notesie kliknij polecenie Close and Halt (Zamknij i zatrzymaj). Spowoduje to zakończenie pracy i zamknięcie notesu.
Następne kroki
- Tworzenie autonomicznej aplikacji Scala do uruchamiania w klastrze Apache Spark
- Tworzenie aplikacji Platformy Apache Spark dla klastra spark w usłudze HDInsight Spark w zestawie narzędzi Azure Toolkit for IntelliJ
- Tworzenie aplikacji Apache Spark dla klastra HDInsight Spark dla klastra hdInsight Spark w zestawie narzędzi Azure Toolkit for Eclipse
- Korzystanie z usługi Azure Data Lake Storage Gen2 w połączeniu z klastrami usługi Azure HDInsight
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla