Punkty końcowe wnioskowania w środowisku produkcyjnym
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Po przeszkoleniu modeli uczenia maszynowego lub potoków lub znalezieniu modeli z katalogu modeli, które odpowiadają Twoim potrzebom, należy wdrożyć je w środowisku produkcyjnym, aby inne osoby mogły ich używać do wnioskowania. Wnioskowanie to proces stosowania nowych danych wejściowych do modelu uczenia maszynowego lub potoku w celu wygenerowania danych wyjściowych. Chociaż te dane wyjściowe są zwykle określane jako "przewidywania", wnioskowanie może służyć do generowania danych wyjściowych dla innych zadań uczenia maszynowego, takich jak klasyfikacja i klastrowanie. W usłudze Azure Machine Learning wnioskowanie jest wykonywane przy użyciu punktów końcowych.
Punkty końcowe i wdrożenia
Punkt końcowy to stabilny i trwały adres URL, którego można użyć do żądania lub wywołania modelu. Należy podać wymagane dane wejściowe do punktu końcowego i odzyskać dane wyjściowe. Usługa Azure Machine Learning umożliwia implementowanie bezserwerowych punktów końcowych interfejsu API, punktów końcowych online i punktów końcowych wsadowych. Punkt końcowy zapewnia:
- stabilny i trwały adres URL (na przykład endpoint-name.region.inference.ml.azure.com),
- mechanizm uwierzytelniania i
- mechanizm autoryzacji.
Wdrożenie to zestaw zasobów i obliczeń wymaganych do hostowania modelu lub składnika, który wykonuje rzeczywiste wnioskowanie. Punkt końcowy zawiera wdrożenie, a w przypadku punktów końcowych online i wsadowych jeden punkt końcowy może zawierać kilka wdrożeń. Wdrożenia mogą hostować niezależne zasoby i zużywać różne zasoby na podstawie potrzeb zasobów. Ponadto punkt końcowy ma mechanizm routingu, który może kierować żądania do dowolnego z jego wdrożeń.
Z jednej strony niektóre typy punktów końcowych w usłudze Azure Machine Learning zużywają dedykowane zasoby we wdrożeniach. Aby te punkty końcowe były uruchamiane, musisz mieć limit przydziału zasobów obliczeniowych w ramach subskrypcji platformy Azure. Z drugiej strony niektóre modele obsługują wdrożenie bezserwerowe — dzięki czemu nie będą korzystać z limitu przydziału z subskrypcji. W przypadku wdrożenia bezserwerowego opłaty są naliczane na podstawie użycia.
Intuicja
Załóżmy, że pracujesz nad aplikacją, która przewiduje typ i kolor samochodu, biorąc pod uwagę jego zdjęcie. W przypadku tej aplikacji użytkownik z pewnymi poświadczeniami wysyła żądanie HTTP do adresu URL i udostępnia obraz samochodu w ramach żądania. W zamian użytkownik otrzymuje odpowiedź zawierającą typ i kolor samochodu jako wartości ciągu. W tym scenariuszu adres URL służy jako punkt końcowy.
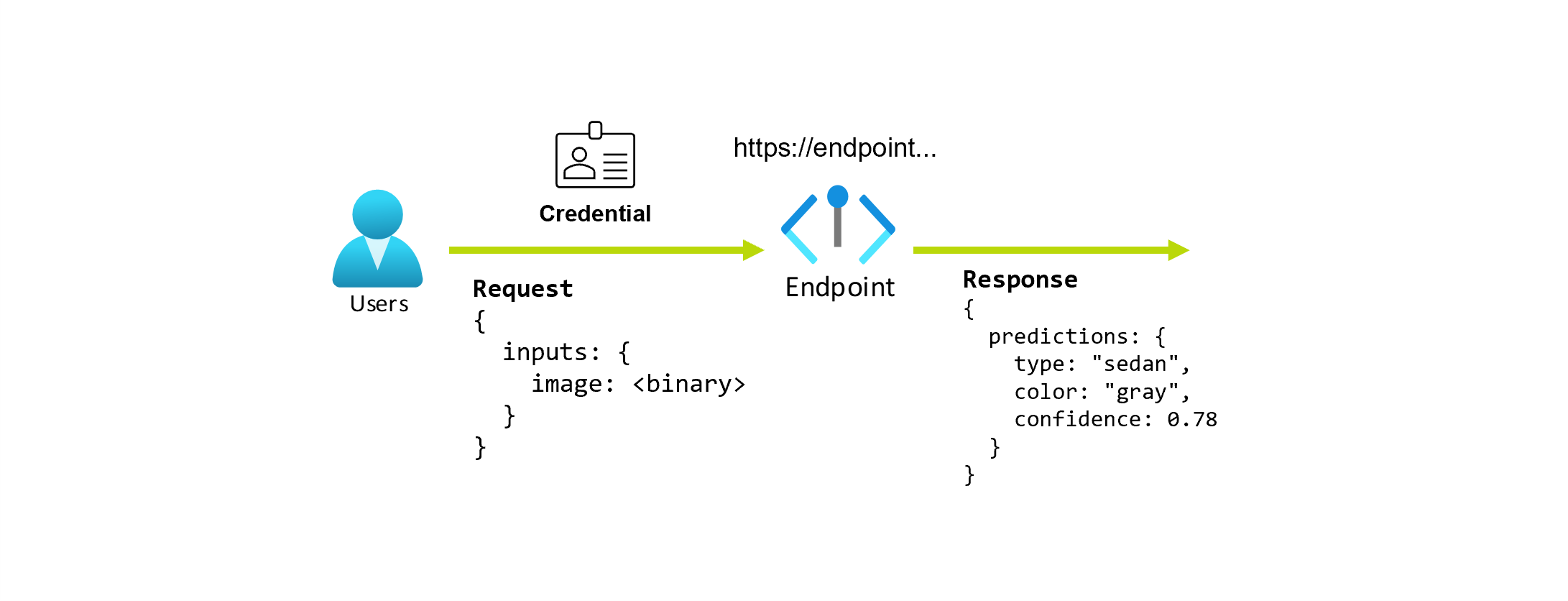
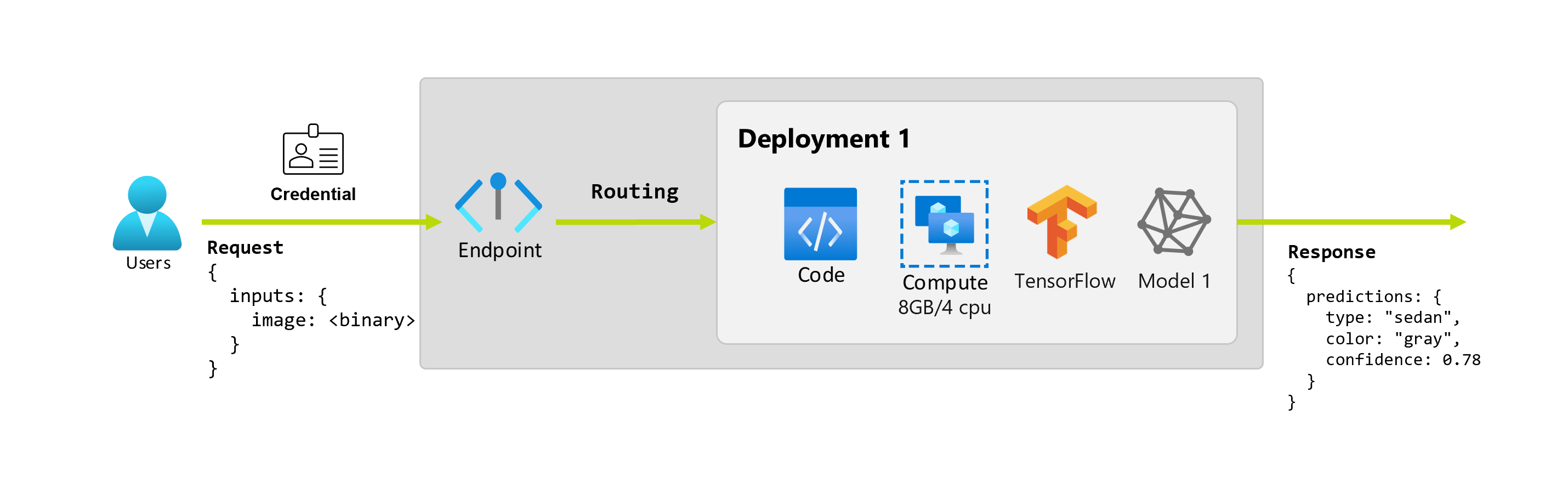
Ponadto załóżmy, że analityk danych Alice pracuje nad implementacją aplikacji. Alice wie wiele o tensorFlow i decyduje się wdrożyć model przy użyciu klasyfikatora sekwencyjnego Keras z architekturą RestNet z usługi TensorFlow Hub. Po przetestowaniu modelu Alice jest zadowolona z wyników i decyduje się na użycie modelu do rozwiązania problemu z przewidywaniem samochodu. Model jest duży i wymaga 8 GB pamięci z 4 rdzeniami do uruchomienia. W tym scenariuszu model i zasoby Alice, takie jak kod i obliczenia, które są wymagane do uruchomienia modelu tworzą wdrożenie w punkcie końcowym.
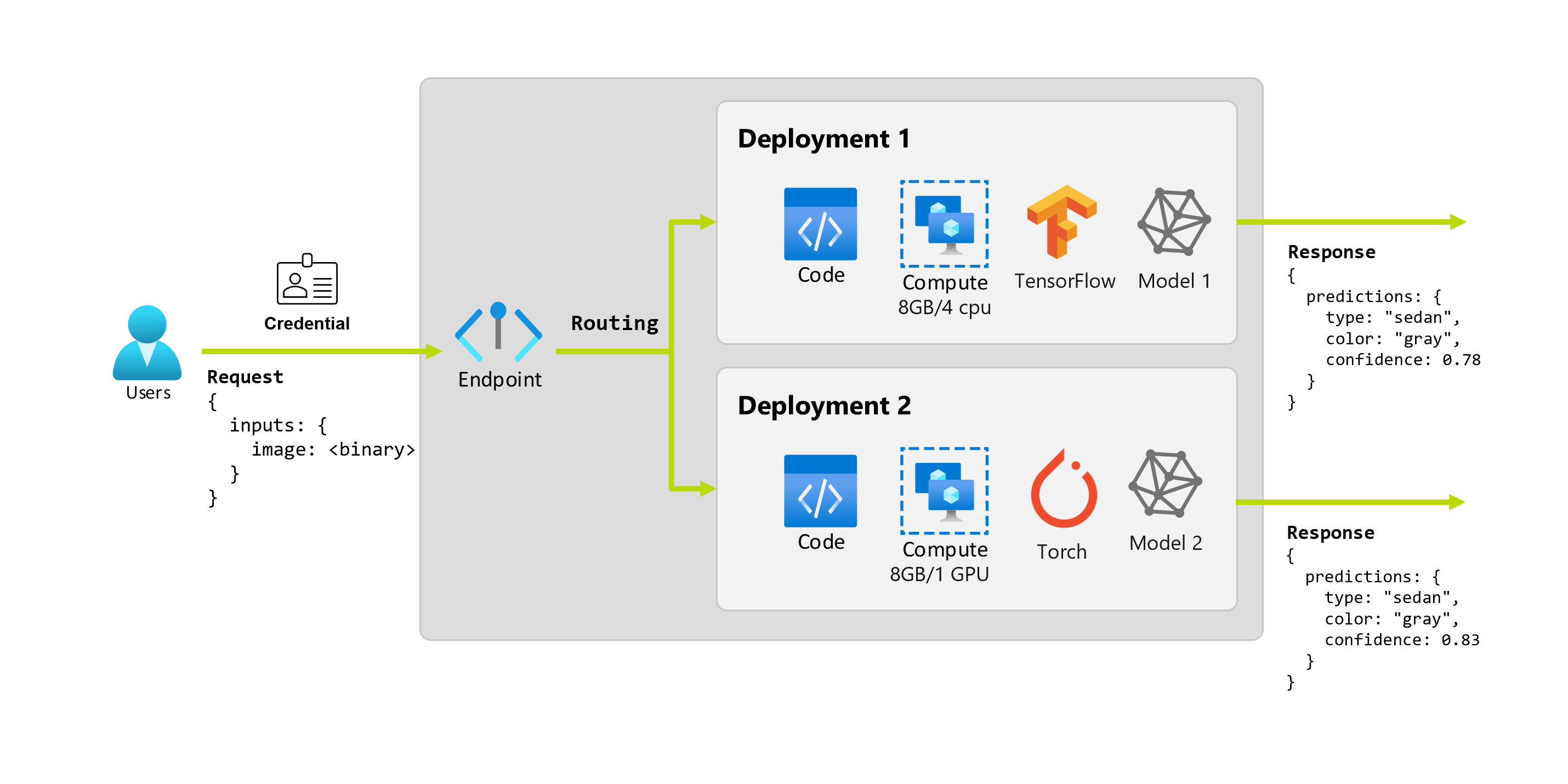
Wyobraźmy sobie, że po kilku miesiącach organizacja odkrywa, że aplikacja działa słabo na obrazach z mniej niż idealnymi warunkami oświetlenia. Bob, inny analityk danych, zna wiele technik rozszerzania danych, które pomagają modelowi w tworzeniu niezawodności tego czynnika. Jednak Bob czuje się bardziej komfortowo za pomocą Torch do zaimplementowania modelu i trenuje nowy model z Torch. Bob chce stopniowo wypróbować ten model w środowisku produkcyjnym, dopóki organizacja nie będzie gotowa do wycofania starego modelu. Nowy model pokazuje również lepszą wydajność podczas wdrażania w procesorze GPU, więc wdrożenie musi zawierać procesor GPU. W tym scenariuszu model Boba i zasoby, takie jak kod i obliczenia, które są wymagane do uruchomienia modelu tworzą kolejne wdrożenie w ramach tego samego punktu końcowego.
Punkty końcowe: bezserwerowy interfejs API, online i batch
Usługa Azure Machine Learning umożliwia implementowanie bezserwerowych punktów końcowych interfejsu API, punktów końcowych online i punktów końcowych wsadowych.
Bezserwerowe punkty końcowe interfejsu API i punkty końcowe online są przeznaczone do wnioskowania w czasie rzeczywistym. Za każdym razem, gdy wywołujesz punkt końcowy, wyniki są zwracane w odpowiedzi punktu końcowego. Punkty końcowe bezserwerowego interfejsu API nie korzystają z limitu przydziału z subskrypcji; zamiast tego są one rozliczane z rozliczeniami płatności zgodnie z rzeczywistym użyciem.
Punkty końcowe usługi Batch są przeznaczone do długotrwałego wnioskowania wsadowego. Za każdym razem, gdy wywołujesz punkt końcowy partii, wygenerujesz zadanie wsadowe, które wykonuje rzeczywistą pracę.
Kiedy należy używać bezserwerowego interfejsu API, punktów końcowych online i wsadowych
Punkty końcowe bezserwerowego interfejsu API:
Użyj bezserwerowych punktów końcowych interfejsu API, aby korzystać z dużych podstawowych modeli na potrzeby wnioskowania w czasie rzeczywistym poza półką lub dostrajania takich modeli. Nie wszystkie modele są dostępne do wdrożenia w punktach końcowych bezserwerowego interfejsu API. Zalecamy używanie tego trybu wdrażania w przypadku:
- Model jest podstawowym modelem lub dostosowaną wersją podstawowego modelu, który jest dostępny dla bezserwerowych wdrożeń interfejsu API.
- Możesz skorzystać z wdrożenia bez limitu przydziału.
- Nie musisz dostosowywać stosu wnioskowania używanego do uruchamiania modelu.
Punkty końcowe online:
Użyj punktów końcowych online, aby operacjonalizować modele na potrzeby wnioskowania w czasie rzeczywistym w synchronicznych żądaniach o małych opóźnieniach. Zalecamy ich używanie w przypadku:
- Model jest podstawowym modelem lub dostosowaną wersją podstawowego modelu, ale nie jest obsługiwany w punktach końcowych bezserwerowego interfejsu API.
- Wymagania dotyczące małych opóźnień.
- Model może odpowiedzieć na żądanie w stosunkowo krótkim czasie.
- Dane wejściowe modelu mieszczą się w ładunku HTTP żądania.
- Musisz skalować w górę pod względem liczby żądań.
Punkty końcowe usługi Batch:
Użyj punktów końcowych wsadowych , aby operacjonalizować modele lub potoki na potrzeby długotrwałego wnioskowania asynchronicznego. Zalecamy ich używanie w przypadku:
- Masz kosztowne modele lub potoki, które wymagają dłuższego czasu do uruchomienia.
- Chcesz operacjonalizować potoki uczenia maszynowego i ponownie używać składników.
- Należy przeprowadzić wnioskowanie na dużych ilościach danych, które są dystrybuowane w wielu plikach.
- Nie masz wymagań dotyczących małych opóźnień.
- Dane wejściowe modelu są przechowywane na koncie magazynu lub w zasobie danych usługi Azure Machine Learning.
- Możesz skorzystać z równoległości.
Porównanie bezserwerowego interfejsu API, punktów końcowych online i wsadowych
Wszystkie bezserwerowe interfejsy API, punkty końcowe w trybie online i wsadowe są oparte na idei punktów końcowych, dlatego można łatwo przejść z jednego do drugiego. Punkty końcowe online i wsadowe mogą również zarządzać wieloma wdrożeniami dla tego samego punktu końcowego.
Punkty końcowe
W poniższej tabeli przedstawiono podsumowanie różnych funkcji dostępnych dla bezserwerowego interfejsu API, punktów końcowych online i wsadowych na poziomie punktu końcowego.
| Funkcja | Punkty końcowe bezserwerowego interfejsu API | Punkty końcowe online | Punkty końcowe usługi Batch |
|---|---|---|---|
| Stabilny adres URL wywołania | Tak | Tak | Tak |
| Obsługa wielu wdrożeń | Nie. | Tak | Tak |
| Routing wdrożenia | Brak | Podział ruchu | Przełącz do domyślnego |
| Dublowanie ruchu w celu bezpiecznego wprowadzania | Nie. | Tak | Nie. |
| Obsługa struktury Swagger | Tak | Tak | Nie. |
| Uwierzytelnianie | Klucz | Klucz i identyfikator entra firmy Microsoft (wersja zapoznawcza) | Microsoft Entra ID |
| Obsługa sieci prywatnej (starsza wersja) | Nie. | Tak | Tak |
| Izolacja sieci zarządzanej | Tak | Tak | Tak (zobacz wymaganą dodatkową konfigurację) |
| Klucze zarządzane przez klienta | Nie dotyczy | Yes | Tak |
| Podstawa kosztów | Na punkt końcowy, na minutę1 | Brak | Brak |
1Niewielka część jest naliczana za punkty końcowe bezserwerowe interfejsu API na minutę. Zobacz sekcję wdrożenia , aby uzyskać opłaty związane z użyciem, które są rozliczane za token.
Wdrożenia
W poniższej tabeli przedstawiono podsumowanie różnych funkcji dostępnych dla bezserwerowych interfejsów API, punktów końcowych online i wsadowych na poziomie wdrożenia. Te pojęcia dotyczą każdego wdrożenia w punkcie końcowym (w przypadku punktów końcowych online i wsadowych) i mają zastosowanie do punktów końcowych bezserwerowego interfejsu API (gdzie koncepcja wdrożenia jest wbudowana w punkt końcowy).
| Funkcja | Punkty końcowe bezserwerowego interfejsu API | Punkty końcowe online | Punkty końcowe usługi Batch |
|---|---|---|---|
| Typy wdrożeń | Modele | Modele | Modele i składniki potoku |
| Wdrażanie modelu MLflow | Nie, tylko określone modele w wykazie | Tak | Tak |
| Wdrażanie modelu niestandardowego | Nie, tylko określone modele w wykazie | Tak, ze skryptem oceniania | Tak, ze skryptem oceniania |
| Wdrożenie pakietu modelu 2 | Wbudowana | Tak (wersja zapoznawcza) | Nie. |
| Serwer wnioskowania 3 | Interfejs API wnioskowania modelu Azure AI | — Serwer wnioskowania usługi Azure Machine Learning -Tryton - Niestandardowe (przy użyciu byOC) |
Wnioskowanie wsadowe |
| Wykorzystany zasób obliczeniowy | Brak (bezserwerowy) | Wystąpienia lub szczegółowe zasoby | Wystąpienia klastra |
| Typ środowiska obliczeniowego | Brak (bezserwerowy) | Zarządzane obliczenia i platforma Kubernetes | Zarządzane obliczenia i platforma Kubernetes |
| Obliczenia o niskim priorytcie | NA | Nie. | Tak |
| Skalowanie obliczeń do zera | Wbudowana | Nie. | Tak |
| Skalowanie automatyczne obliczeniowe4 | Wbudowana | Tak, na podstawie użycia zasobów | Tak, na podstawie liczby zadań |
| Zarządzanie nadwyżkami zdolności produkcyjnych | Ograniczanie przepływności | Ograniczanie przepływności | Kolejkowanie |
| Podstawa kosztu5 | Na token | Na wdrożenie: uruchomione wystąpienia obliczeniowe | Na zadanie: wystąpienie obliczeniowe używane w zadaniu (ograniczone do maksymalnej liczby wystąpień klastra) |
| Lokalne testowanie wdrożeń | Nie. | Tak | Nie. |
2 Wdrażanie modeli MLflow w punktach końcowych bez wychodzącej łączności internetowej lub sieci prywatnych wymaga najpierw spakowania modelu .
3 Serwer wnioskowania odnosi się do technologii obsługującej, która pobiera żądania, przetwarza je i tworzy odpowiedzi. Serwer wnioskowania określa również format danych wejściowych i oczekiwanych danych wyjściowych.
4 Autoskalowanie to możliwość dynamicznego skalowania w górę lub w dół przydzielonych zasobów wdrożenia na podstawie obciążenia. Wdrożenia online i wsadowe używają różnych strategii skalowania automatycznego. Wdrożenia online są skalowane w górę i w dół na podstawie wykorzystania zasobów (na przykład procesora CPU, pamięci, żądań itp.), punkty końcowe wsadowe są skalowane w górę lub w dół na podstawie liczby utworzonych zadań.
5 Opłaty za wdrożenia online i wsadowe są naliczane przez zużyte zasoby. We wdrożeniach online zasoby są aprowizowane w czasie wdrażania. W przypadku wdrażania wsadowego zasoby nie są używane w czasie wdrażania, ale w momencie uruchomienia zadania. W związku z tym nie ma żadnych kosztów związanych z samym wdrożeniem wsadowym. Podobnie zadania w kolejce nie zużywają zasobów.
Interfejsy deweloperskie
Punkty końcowe zostały zaprojektowane w celu ułatwienia organizacjom operacjonalizacji obciążeń na poziomie produkcyjnym w usłudze Azure Machine Learning. Punkty końcowe są niezawodnymi i skalowalnymi zasobami i zapewniają najlepsze możliwości implementowania przepływów pracy metodyki MLOps.
Punkty końcowe wsadowe i online można tworzyć i zarządzać nimi za pomocą kilku narzędzi programistycznych:
- Interfejs wiersza polecenia platformy Azure i zestaw PYTHON SDK
- Azure Resource Manager/interfejs API REST
- Portal internetowy usługi Azure Machine Learning Studio
- Witryna Azure Portal (IT/administrator)
- Obsługa potoków ciągłej integracji/ciągłego wdrażania metodyki MLOps przy użyciu interfejsu wiersza polecenia platformy Azure i interfejsów REST/ARM