Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Jednym z największych wyzwań związanych z bieżącymi praktykami debugowania modelu jest użycie zagregowanych metryk do oceniania modeli w zestawie danych porównawczych. Dokładność modelu może nie być jednolita w podgrupach danych i mogą występować kohorty wejściowe, dla których model częściej kończy się niepowodzeniem. Bezpośrednie konsekwencje tych niepowodzeń to brak niezawodności i bezpieczeństwa, pojawienie się problemów z sprawiedliwością i całkowite utratę zaufania do uczenia maszynowego.

Analiza błędów odchodzi od agregacji metryk dokładności. Uwidacznia dystrybucję błędów deweloperom w przejrzysty sposób i umożliwia im efektywne identyfikowanie i diagnozowanie błędów.
Składnik analizy błędów pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji zapewnia praktykom uczenia maszynowego dokładniejsze zrozumienie rozkładu błędów modelu i pomaga im szybko identyfikować błędne kohorty danych. Ten składnik identyfikuje kohorty danych z wyższym współczynnikiem błędów w porównaniu z ogólnym współczynnikiem błędów testu porównawczego. Przyczynia się on do etapu identyfikacji przepływu pracy cyklu życia modelu za pomocą następujących elementów:
- Drzewo decyzyjne, które ujawnia kohorty z wysokimi współczynnikami błędów.
- Mapa cieplna, która wizualizuje sposób, w jaki funkcje wejściowe wpływają na szybkość błędów w kohortach.
Rozbieżności w błędach mogą wystąpić, gdy system nie radzi sobie z określonymi grupami demograficznymi lub rzadko obserwowanymi kohortami wejściowymi w danych treningowych.
Możliwości tego składnika pochodzą z pakietu Analiza błędów, który generuje profile błędów modelu.
Użyj analizy błędów, jeśli musisz:
- Dowiedz się, jak awarie modelu są dystrybuowane w zestawie danych oraz w kilku wymiarach danych wejściowych i cech.
- Podziel zagregowane metryki wydajności, aby automatycznie odnaleźć błędną kohortę w celu poinformowania o ukierunkowanych krokach ograniczania ryzyka.
Drzewo błędów
Często wzorce błędów są złożone i obejmują więcej niż jedną lub dwie funkcje. Deweloperzy mogą mieć trudności z eksplorowanie wszystkich możliwych kombinacji funkcji w celu odnalezienia ukrytych kieszeni danych z krytycznymi awariami.
Aby złagodzić obciążenie, wizualizacja drzewa binarnego automatycznie partycjonuje dane porównawcze w podgrupy z możliwością interpretacji, które mają nieoczekiwanie wysokie lub niskie współczynniki błędów. Innymi słowy, drzewo używa funkcji wejściowych, aby maksymalnie oddzielić błąd modelu od powodzenia. Dla każdego węzła definiującego podgrupę danych użytkownicy mogą zbadać następujące informacje:
- Współczynnik błędów: część wystąpień w węźle, dla której model jest niepoprawny. Jest on pokazany przez intensywność koloru czerwonego.
- Pokrycie błędów: część wszystkich błędów, które należą do węzła. Jest on wyświetlany za pośrednictwem współczynnika wypełnienia węzła.
- Reprezentacja danych: liczba wystąpień w każdym węźle drzewa błędów. Jest on wyświetlany przez grubość krawędzi przychodzącej do węzła wraz z całkowitą liczbą wystąpień w węźle.

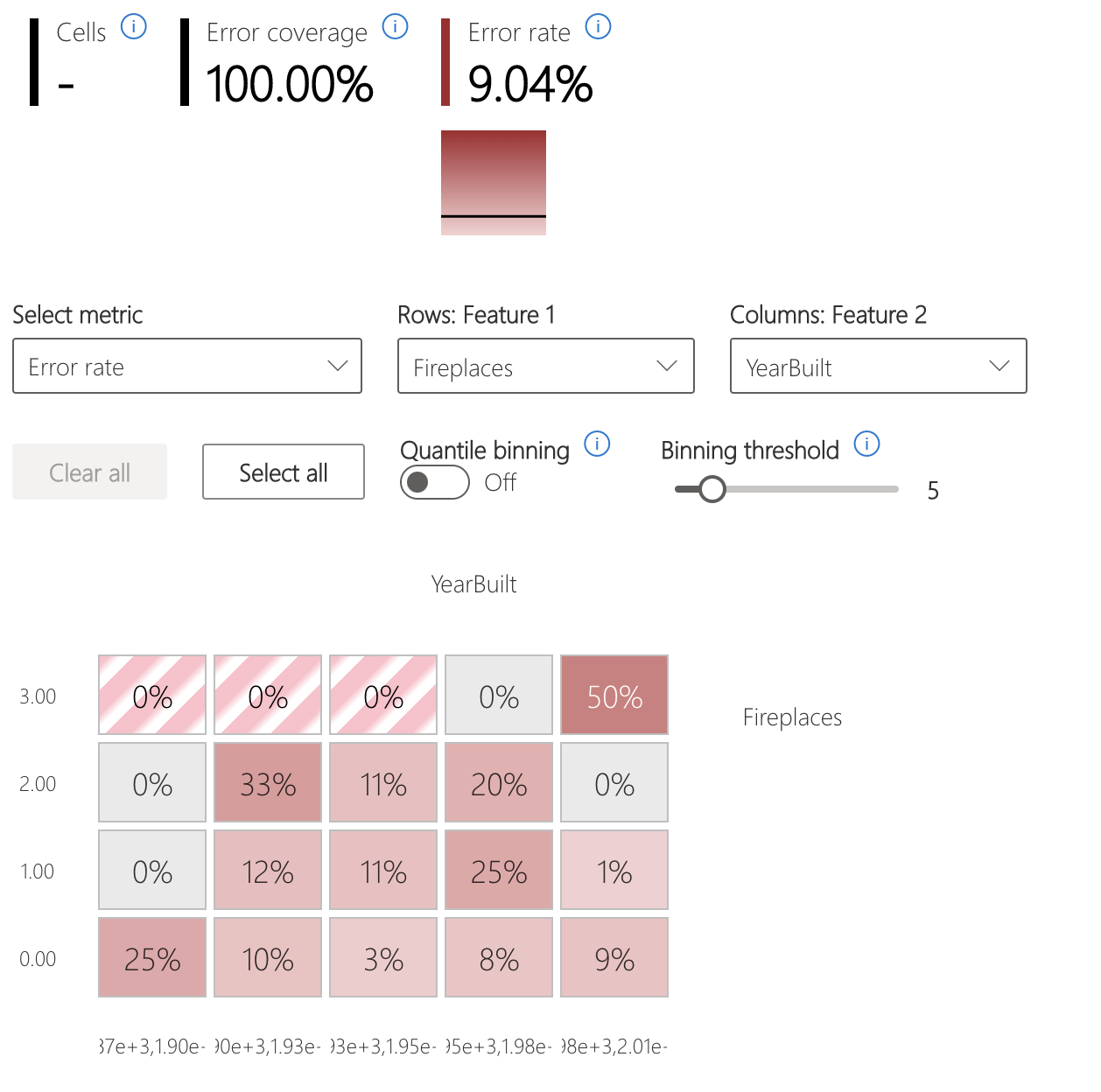
Mapa cieplna błędu
Widok fragmentuje dane na podstawie jednowymiarowej lub dwuwymiarowej siatki cech wejściowych. Użytkownicy mogą wybrać interesujące funkcje wejściowe do analizy.
Mapa cieplna wizualizuje komórki o wysokim błędzie przy użyciu ciemniejszego koloru czerwonego, aby zwrócić uwagę użytkownika na te regiony. Ta funkcja jest szczególnie przydatna, gdy motywy błędów różnią się między partycjami, co często występuje w praktyce. W tym widoku identyfikacji błędów analiza jest bardzo kierowana przez użytkowników i ich wiedzę lub hipotezy dotyczące tego, jakie funkcje mogą być najważniejsze w celu zrozumienia błędów.
Następne kroki
- Dowiedz się, jak wygenerować pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji za pomocą interfejsu wiersza polecenia i zestawu SDK lub interfejsu użytkownika usługi Azure Machine Learning Studio.
- Zapoznaj się z obsługiwanymi wizualizacjami analizy błędów.
- Dowiedz się, jak wygenerować kartę wyników odpowiedzialnej sztucznej inteligencji na podstawie szczegółowych informacji obserwowanych na pulpicie nawigacyjnym odpowiedzialnej sztucznej inteligencji.