Generowanie szczegółowych informacji o odpowiedzialnej sztucznej inteligencji w interfejsie użytkownika programu Studio
W tym artykule utworzysz pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji i kartę wyników (wersja zapoznawcza) bez kodu w interfejsie użytkownika usługi Azure Machine Edukacja Studio.
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Aby uzyskać dostęp do kreatora generowania pulpitu nawigacyjnego i wygenerować pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji, wykonaj następujące czynności:
Zarejestruj model w usłudze Azure Machine Edukacja, aby uzyskać dostęp do środowiska bez kodu.
W lewym okienku usługi Azure Machine Edukacja Studio wybierz kartę Modele.
Wybierz zarejestrowany model, dla którego chcesz utworzyć szczegółowe informacje o odpowiedzialnej sztucznej inteligencji, a następnie wybierz kartę Szczegóły .
Wybierz pozycję Utwórz pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji (wersja zapoznawcza).
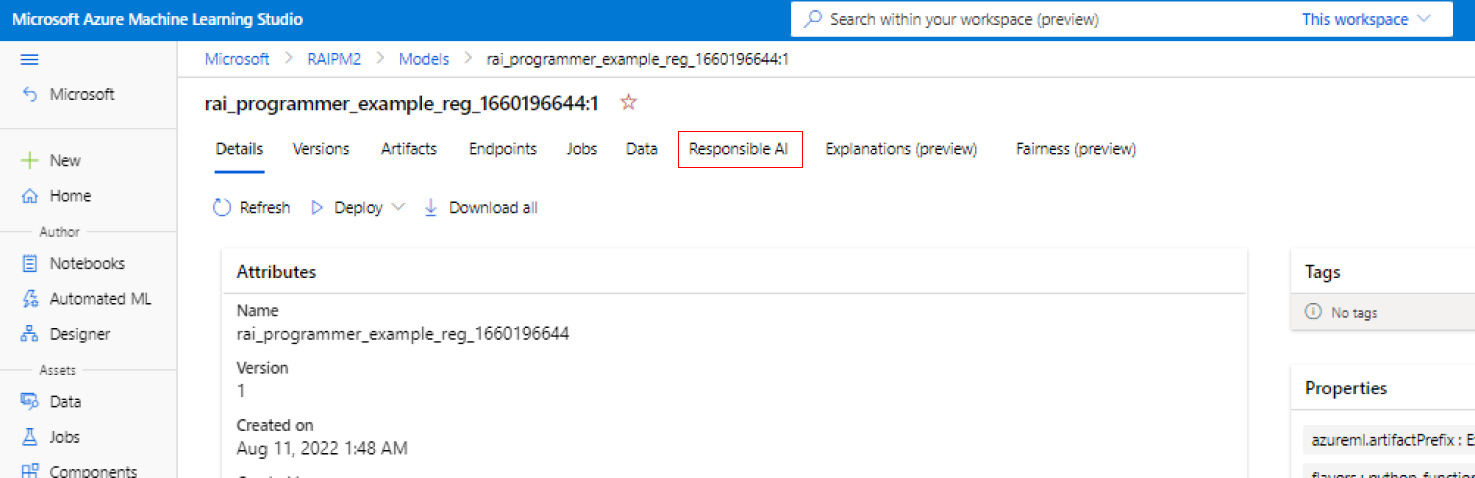

Aby dowiedzieć się więcej o obsługiwanych typach modeli i ograniczeniach na pulpicie nawigacyjnym Odpowiedzialne używanie sztucznej inteligencji, zobacz obsługiwane scenariusze i ograniczenia.
Kreator udostępnia interfejs umożliwiający wprowadzenie wszystkich niezbędnych parametrów do utworzenia pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji bez konieczności dotykania kodu. Środowisko odbywa się całkowicie w interfejsie użytkownika usługi Azure Machine Edukacja Studio. Studio przedstawia przepływ z przewodnikiem i tekst instruktażowy, aby ułatwić kontekst różnych wyborów dotyczących składników odpowiedzialnej sztucznej inteligencji, z którymi chcesz wypełnić pulpit nawigacyjny.
Kreator jest podzielony na pięć sekcji:
- Trenowanie zestawów danych
- Testowy zestaw danych
- Zadanie modelowania
- Składniki pulpitu nawigacyjnego
- Parametry składników
- Konfiguracja eksperymentu
Wybieranie zestawów danych
W dwóch pierwszych sekcjach wybierasz zestawy danych trenowania i testowania używane podczas trenowania modelu w celu generowania szczegółowych informacji debugowania modelu. W przypadku składników, takich jak analiza przyczynowa, która nie wymaga modelu, należy użyć trenowania zestawu danych, aby wytrenować model przyczynowy w celu wygenerowania szczegółowych informacji przyczynowych.
Uwaga
Obsługiwane są tylko formaty tabelarycznych zestawów danych w tabeli ML.
Wybierz zestaw danych do trenowania: na liście zarejestrowanych zestawów danych w obszarze roboczym usługi Azure Machine Edukacja wybierz zestaw danych, którego chcesz użyć do generowania szczegółowych informacji o odpowiedzialnej sztucznej inteligencji dla składników, takich jak wyjaśnienia modelu i analiza błędów.
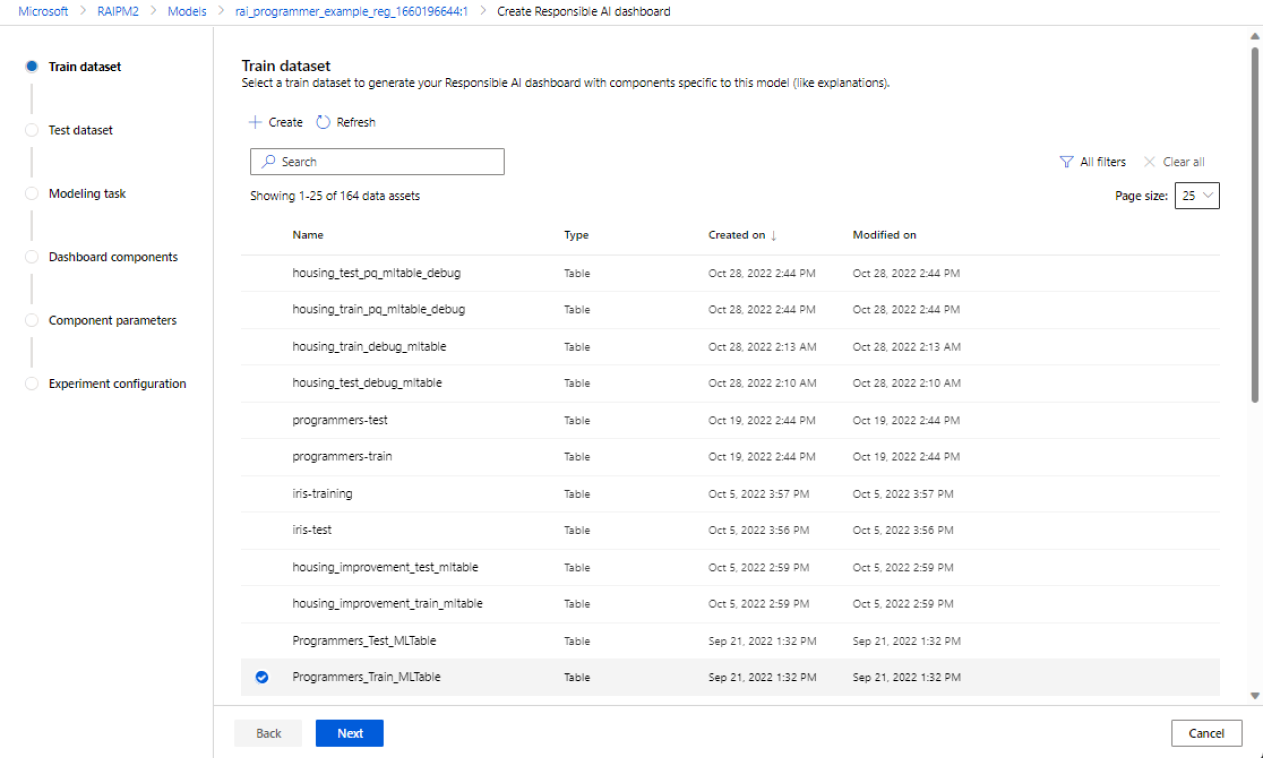
Wybierz zestaw danych do testowania: na liście zarejestrowanych zestawów danych wybierz zestaw danych, którego chcesz użyć do wypełnienia wizualizacji pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji.
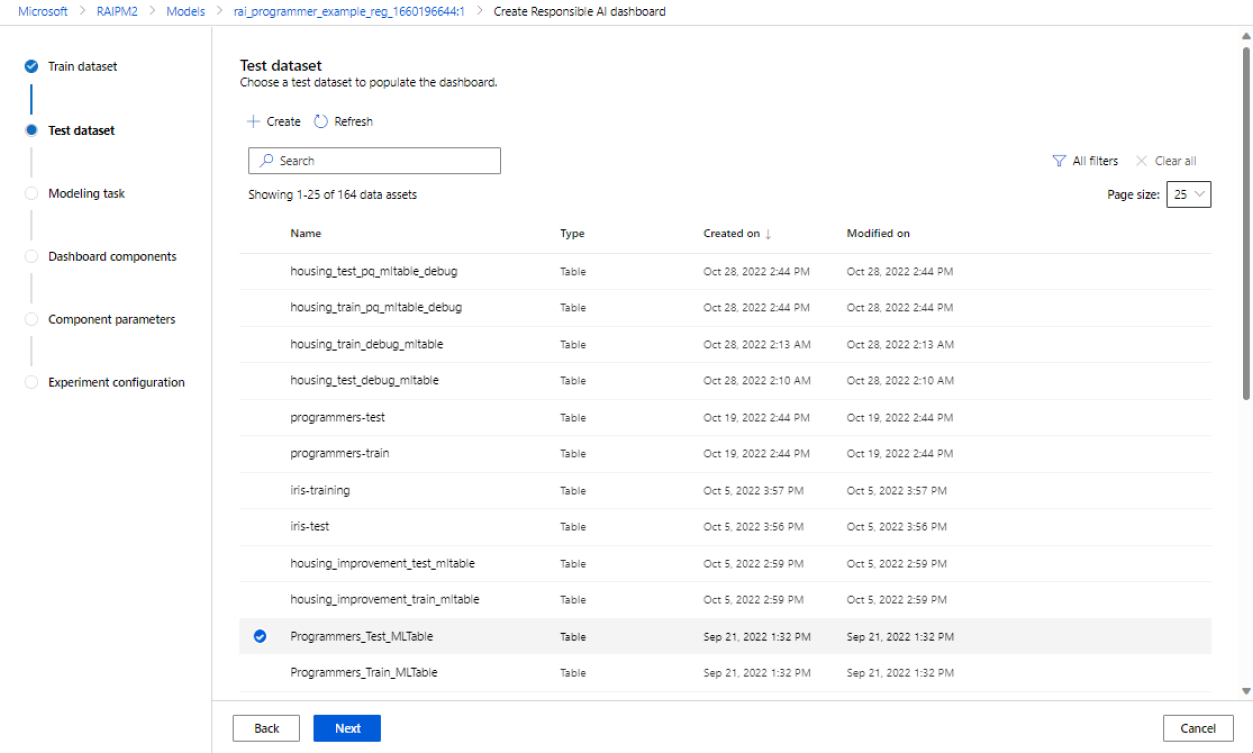
Jeśli zestaw danych trenowania lub testowania, którego chcesz użyć, nie znajduje się na liście, wybierz pozycję Utwórz , aby go przekazać.


Wybieranie zadania modelowania
Po wybraniu zestawów danych wybierz typ zadania modelowania, jak pokazano na poniższej ilustracji:

Wybieranie składników pulpitu nawigacyjnego
Pulpit nawigacyjny Odpowiedzialne używanie sztucznej inteligencji oferuje dwa profile dla zalecanych zestawów narzędzi, które można wygenerować:
Debugowanie modelu: Omówienie i debugowanie błędnej kohorty danych w modelu uczenia maszynowego przy użyciu analizy błędów, kontraktualnych przykładów analizy co-jeżeli i objaśnienia modelu.
Interwencje w czasie rzeczywistym: Zrozumienie i debugowanie błędnej kohorty danych w modelu uczenia maszynowego przy użyciu analizy przyczynowej.
Uwaga
Klasyfikacja wieloklasowa nie obsługuje profilu analizy interwencji rzeczywistych.

- Wybierz profil, którego chcesz użyć.
- Wybierz Dalej.
Konfigurowanie parametrów dla składników pulpitu nawigacyjnego
Po wybraniu profilu zostanie wyświetlone okienko Konfiguracja składnika debugowania modelu dla odpowiednich składników.

Parametry składnika do debugowania modelu:
Funkcja docelowa (wymagana): określ funkcję, którą model został wytrenowany do przewidywania.
Funkcje kategorii: wskazuje, które funkcje są podzielone na kategorie, aby prawidłowo renderować je jako wartości podzielone na kategorie w interfejsie użytkownika pulpitu nawigacyjnego. To pole jest wstępnie załadowane na podstawie metadanych zestawu danych.
Generowanie drzewa błędów i mapy cieplnej: włącz i wyłącz, aby wygenerować składnik analizy błędów dla pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji.
Funkcje mapy cieplnej błędów: wybierz maksymalnie dwie funkcje, dla których chcesz wstępnie wygenerować mapę cieplną błędów.
Konfiguracja zaawansowana: określ dodatkowe parametry, takie jak Maksymalna głębokość drzewa błędów, Liczba liści w drzewie błędów i Minimalna liczba próbek w każdym węźle liścia.
Wygeneruj alternatywne przykłady analizy co-jeżeli: włącz i wyłącz, aby wygenerować składnik analizy warunkowej dla pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji i wygeneruj go.
Liczba kontractuals (wymagane): określ liczbę przykładów counterfactual, które chcesz wygenerować dla punktu danych. Należy wygenerować co najmniej 10, aby umożliwić wyświetlanie wykresu słupkowego funkcji, które były najbardziej perturbed, średnio, w celu osiągnięcia żądanego przewidywania.
Zakres przewidywań wartości (wymagane): określ dla scenariuszy regresji zakres, w którym mają być podane wartości przewidywania. W przypadku scenariuszy klasyfikacji binarnej zakres zostanie automatycznie ustawiony w celu wygenerowania kontraktów dla przeciwnej klasy każdego punktu danych. W przypadku scenariuszy obejmujących wiele klasyfikacji użyj listy rozwijanej, aby określić, która klasa ma być przewidywana dla każdego punktu danych.
Określ, które funkcje mają zostać perturbowane: domyślnie wszystkie funkcje zostaną zakłócone. Jeśli jednak chcesz, aby tylko określone funkcje mają być wypaczone, wybierz pozycję Określ, które funkcje mają zostać zakłócone w celu wygenerowania objaśnień counterfactual, aby wyświetlić okienko z listą funkcji do wybrania.
Po wybraniu pozycji Określ, które funkcje mają zostać wypaczane, możesz określić zakres, w którym chcesz zezwolić na zakłócenia. Na przykład: w przypadku funkcji YOE (lat doświadczenia) określ, że liczniki powinny mieć wartości cech od tylko 10 do 21 zamiast wartości domyślnych od 5 do 21.
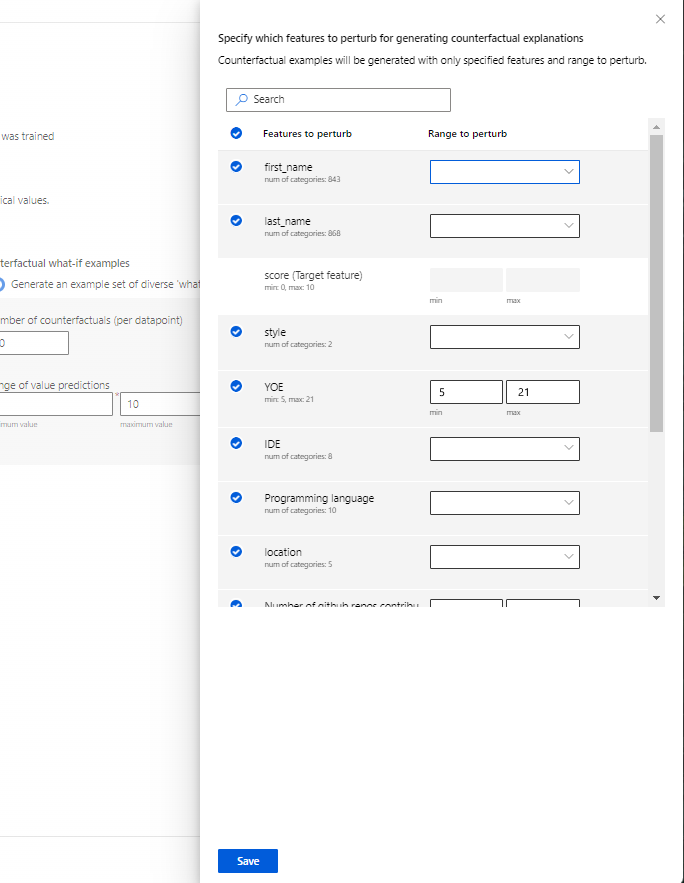
Generowanie wyjaśnień: włącz i wyłącz, aby wygenerować składnik wyjaśnienia modelu dla pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji. Nie jest wymagana żadna konfiguracja, ponieważ domyślny nieprzezroczystym objaśniaczem będzie używany do generowania ważności funkcji.

Alternatywnie, jeśli wybierzesz profil interwencji rzeczywistych , zostanie wyświetlony poniższy ekran wygeneruj analizę przyczynową. Pomoże to zrozumieć przyczynowe skutki funkcji, które chcesz "traktować" na określony wynik, który chcesz zoptymalizować.

Parametry składowe dla rzeczywistych interwencji korzystają z analizy przyczynowej. Należy wykonać następujące czynności:
- Funkcja docelowa (wymagana): wybierz wynik, dla którego mają zostać obliczone skutki przyczynowe.
- Funkcje leczenia (wymagane): wybierz co najmniej jedną funkcję, którą chcesz zmienić ("leczenie"), aby zoptymalizować wynik docelowy.
- Funkcje kategorii: wskazuje, które funkcje są podzielone na kategorie, aby prawidłowo renderować je jako wartości podzielone na kategorie w interfejsie użytkownika pulpitu nawigacyjnego. To pole jest wstępnie załadowane na podstawie metadanych zestawu danych.
- Ustawienia zaawansowane: określ dodatkowe parametry analizy przyczynowej, takie jak funkcje heterogeniczne (czyli dodatkowe funkcje umożliwiające zrozumienie segmentacji przyczynowej w analizie, oprócz funkcji leczenia) i model przyczynowy, który chcesz użyć.
Konfigurowanie eksperymentu
Na koniec skonfiguruj eksperyment, aby rozpocząć zadanie generowania pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji.

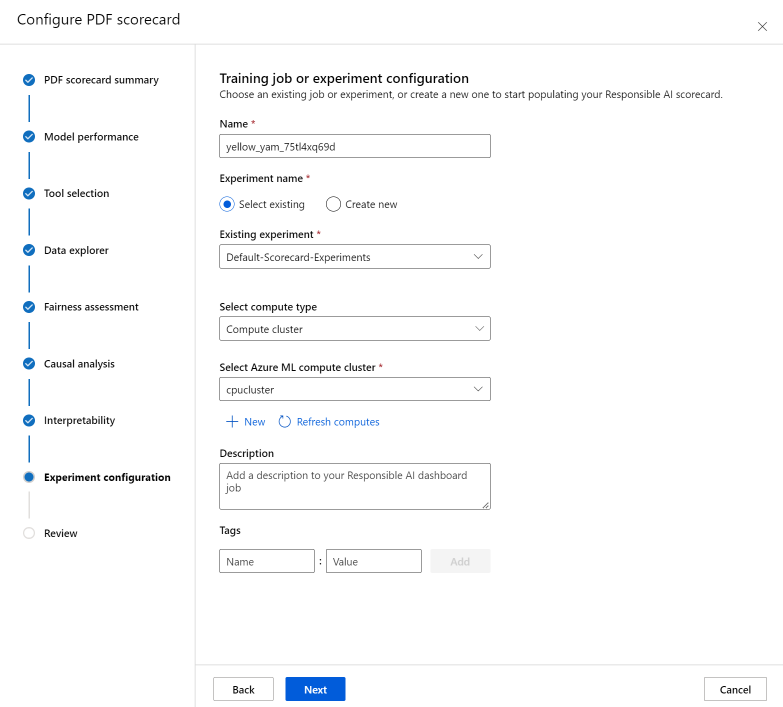
W okienku Zadanie trenowania lub Konfiguracja eksperymentu wykonaj następujące czynności:
- Nazwa: nadaj pulpitowi nawigacyjnemu unikatową nazwę, aby można było ją rozróżnić podczas wyświetlania listy pulpitów nawigacyjnych dla danego modelu.
- Nazwa eksperymentu: wybierz istniejący eksperyment, aby uruchomić zadanie, lub utwórz nowy eksperyment.
- Istniejący eksperyment: na liście rozwijanej wybierz istniejący eksperyment.
- Wybierz typ obliczeniowy: określ typ obliczeniowy, którego chcesz użyć do wykonania zadania.
- Wybierz pozycję Obliczenia: z listy rozwijanej wybierz zasoby obliczeniowe, których chcesz użyć. Jeśli nie ma istniejących zasobów obliczeniowych, wybierz znak plus (+), utwórz nowy zasób obliczeniowy, a następnie odśwież listę.
- Opis: Dodaj dłuższy opis pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji.
- Tagi: dodaj tagi do tego pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji.
Po zakończeniu konfigurowania eksperymentu wybierz pozycję Utwórz , aby rozpocząć generowanie pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji. Nastąpi przekierowanie do strony eksperymentu w celu śledzenia postępu zadania za pomocą linku do wynikowego pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji ze strony zadania po jej zakończeniu.
Aby dowiedzieć się, jak wyświetlać pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji i korzystać z niego, zobacz Korzystanie z pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji w usłudze Azure Machine Edukacja Studio.
Jak wygenerować kartę wyników odpowiedzialnej sztucznej inteligencji (wersja zapoznawcza)
Po utworzeniu pulpitu nawigacyjnego możesz użyć interfejsu użytkownika bez kodu w usłudze Azure Machine Edukacja Studio, aby dostosować i wygenerować kartę wyników odpowiedzialnej sztucznej inteligencji. Umożliwia to udostępnianie kluczowych szczegółowych informacji dotyczących odpowiedzialnego wdrażania modelu, takich jak sprawiedliwość i znaczenie funkcji, z zainteresowanymi stronami nietechnicznymi i technicznymi. Podobnie jak w przypadku tworzenia pulpitu nawigacyjnego, możesz użyć następujących kroków, aby uzyskać dostęp do kreatora generowania kart wyników:
- Przejdź do karty Modele na pasku nawigacyjnym po lewej stronie w usłudze Azure Machine Edukacja Studio.
- Wybierz zarejestrowany model, dla którego chcesz utworzyć kartę wyników, a następnie wybierz kartę Odpowiedzialne użycie sztucznej inteligencji .
- W górnym panelu wybierz pozycję Utwórz szczegółowe informacje o odpowiedzialnej sztucznej inteligencji (wersja zapoznawcza), a następnie pozycję Generuj nową kartę wyników PDF.
Kreator umożliwia dostosowanie karty wyników PDF bez konieczności dotykania kodu. Środowisko odbywa się w całości w usłudze Azure Machine Edukacja Studio, aby ułatwić kontekstowanie różnych opcji interfejsu użytkownika za pomocą przepływu z przewodnikiem i tekstu instrukcji ułatwiającego wybór składników, za pomocą których chcesz wypełnić kartę wyników. Kreator jest podzielony na siedem kroków z ósmym krokiem (ocena sprawiedliwości), który będzie wyświetlany tylko dla modeli z funkcjami kategorii:
- Podsumowanie karty wyników PDF
- Wydajność modelu
- Wybór narzędzia
- Analiza danych (wcześniej nazywana eksploratorem danych)
- Analiza przyczynowa
- Możliwość interpretowania
- Konfiguracja eksperymentu
- Ocena sprawiedliwości (tylko wtedy, gdy istnieją cechy kategorii)
Konfigurowanie karty wyników
Najpierw wprowadź opisowy tytuł karty wyników. Możesz również wprowadzić opcjonalny opis funkcjonalności modelu, dane, które zostały wytrenowane i ocenione, typ architektury i nie tylko.
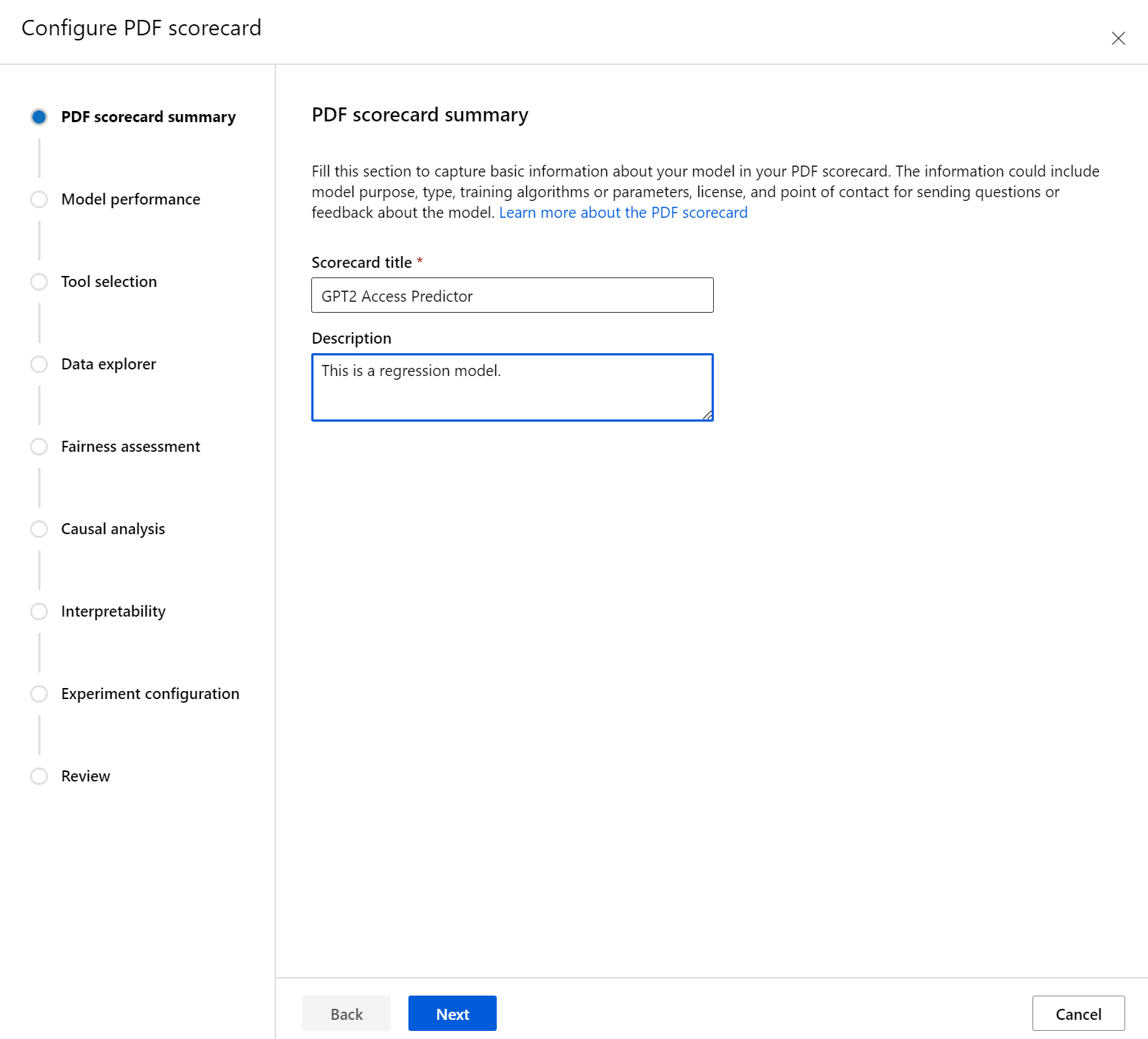
Sekcja Wydajność modelu umożliwia uwzględnienie w metrykach oceny modelu standardowej karty wyników, umożliwiając jednocześnie ustawianie żądanych wartości docelowych dla wybranych metryk. Wybierz żądane metryki wydajności (maksymalnie trzy) i wartości docelowe przy użyciu list rozwijanych.
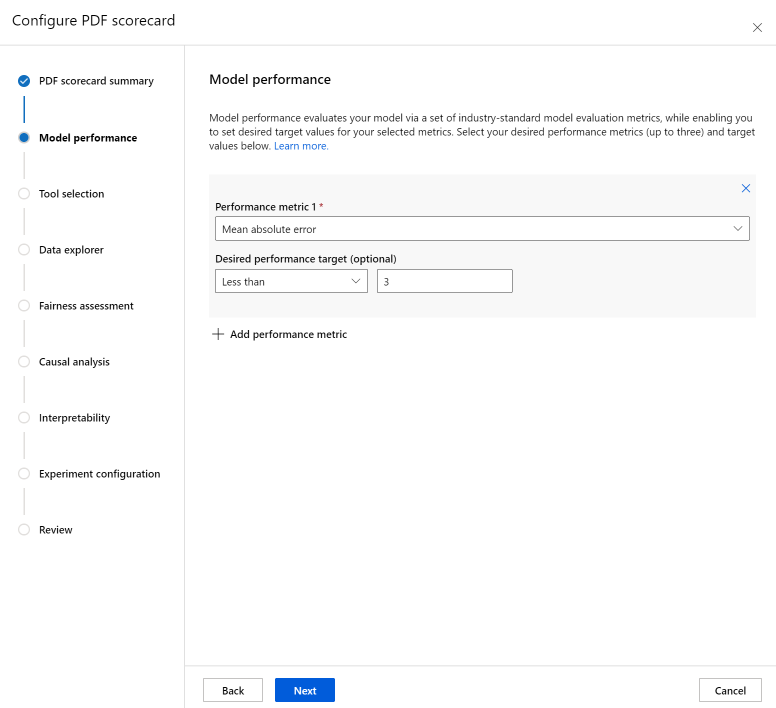
Krok Wyboru narzędzia umożliwia wybranie kolejnych składników, które mają być uwzględnione w karcie wyników. Synchronizacja clude na karcie wyników, aby uwzględnić wszystkie składniki lub sprawdzić/usunąć zaznaczenie każdego składnika indywidualnie. Wybierz ikonę informacji ("i" w okręgu) obok składników, aby dowiedzieć się więcej o nich.
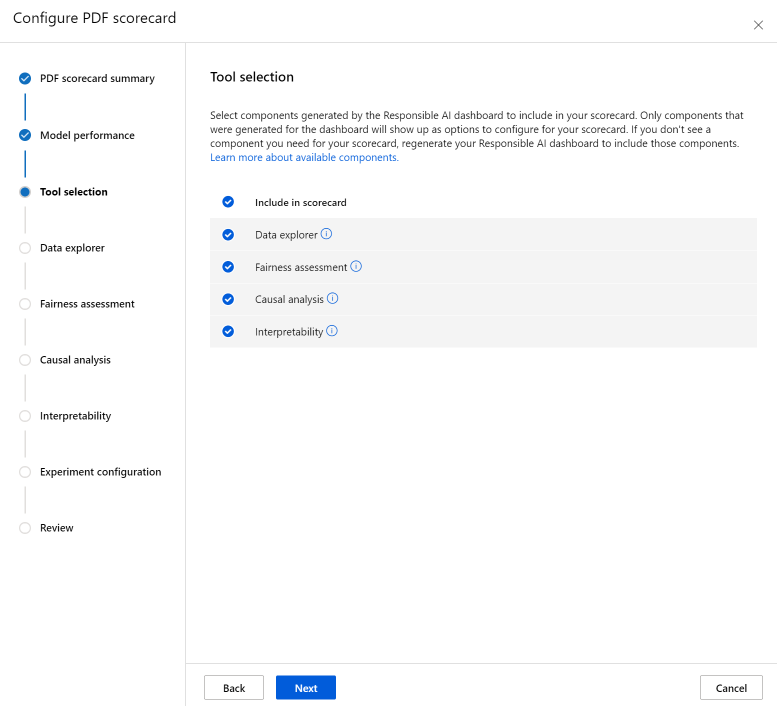
Sekcja Analiza danych (wcześniej nazywana eksploratorem danych) umożliwia analizę kohorty. W tym miejscu możesz zidentyfikować problemy związane z nadmierną reprezentacją i niedostateczną reprezentacją, aby dowiedzieć się, jak dane są klastrowane w zestawie danych oraz jak przewidywania modelu wpływają na określoną kohortę danych. Użyj pól wyboru na liście rozwijanej, aby wybrać swoje interesujące funkcje poniżej, aby zidentyfikować wydajność modelu na ich podstawowej kohortach.
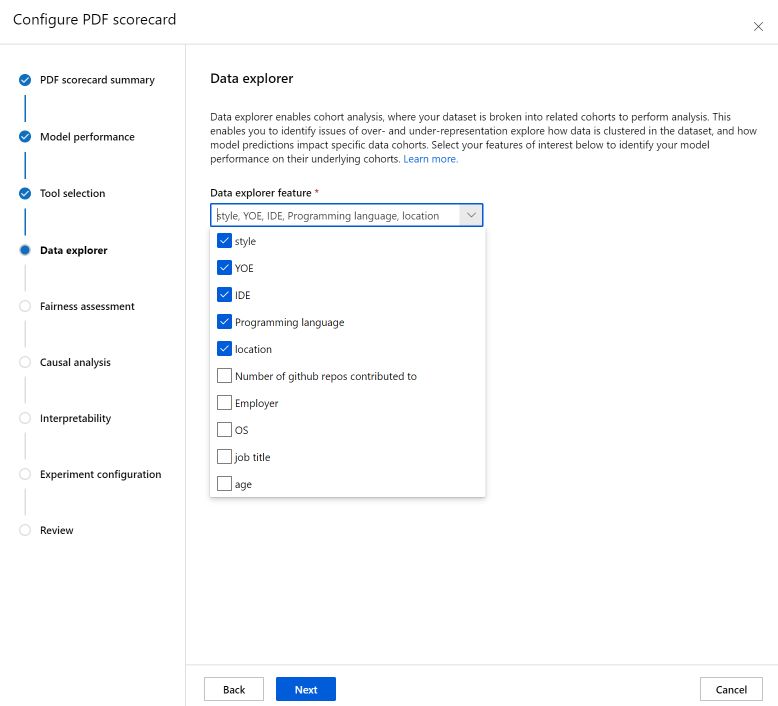
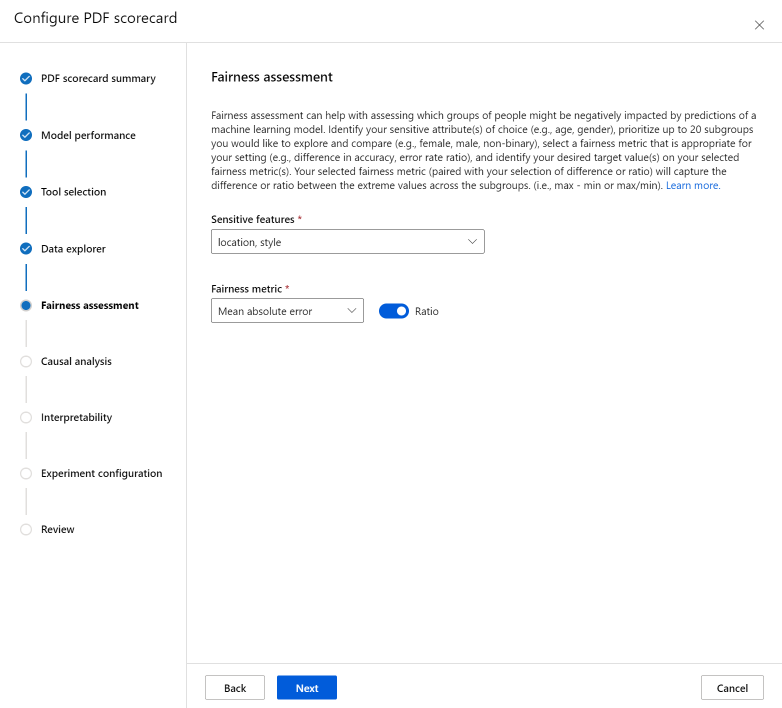
Sekcja Ocena sprawiedliwości może pomóc w ocenie, które grupy osób mogą mieć negatywny wpływ na przewidywania modelu uczenia maszynowego. W tej sekcji znajdują się dwa pola.
Funkcje poufne: zidentyfikuj wybrane atrybuty poufne (na przykład wiek, płeć), priorytetując maksymalnie 20 podgrup, które chcesz eksplorować i porównywać.
Metryka Sprawiedliwości: wybierz metrykę sprawiedliwości odpowiednią dla ustawienia (na przykład różnicę w dokładności, współczynnika błędów) i zidentyfikuj żądane wartości docelowe dla wybranych metryk sprawiedliwości. Wybrana metryka sprawiedliwości (w połączeniu z wyborem różnicy lub współczynnika za pośrednictwem przełącznika) przechwytuje różnicę lub stosunek między skrajnymi wartościami w podgrupach. (max - min lub max/min).
Uwaga
Ocena sprawiedliwości jest obecnie dostępna tylko dla atrybutów poufnych kategorii, takich jak płeć.
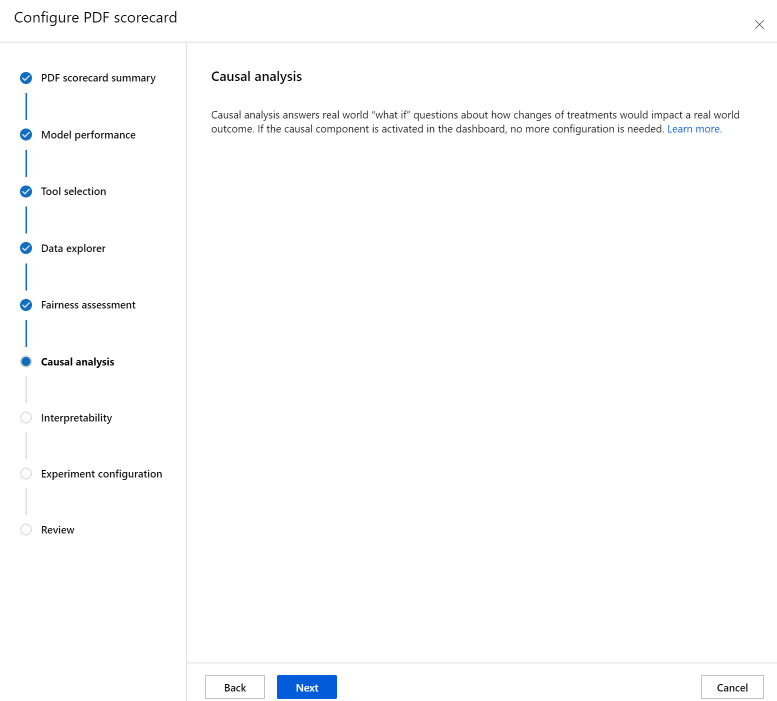
Sekcja Analiza przyczynowa odpowiada na rzeczywiste pytania "co jeśli" dotyczące wpływu zmian leczenia na rzeczywisty wynik. Jeśli składnik przyczynowy jest aktywowany na pulpicie nawigacyjnym odpowiedzialnej sztucznej inteligencji, dla którego generujesz kartę wyników, nie jest potrzebna żadna konfiguracja.
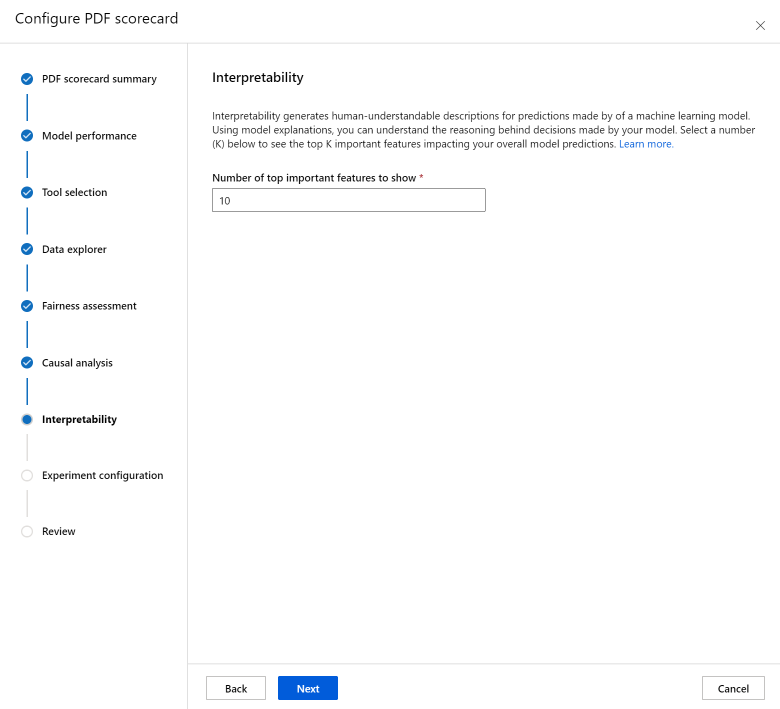
Sekcja Interpretacja generuje zrozumiałe dla człowieka opisy przewidywań wykonanych przez model uczenia maszynowego. Korzystając z wyjaśnień modelu, możesz zrozumieć przyczyny podejmowania decyzji przez model. Wybierz liczbę (K) poniżej, aby wyświetlić najważniejsze ważne funkcje K wpływające na ogólne przewidywania modelu. Wartość domyślna K to 10.
Na koniec skonfiguruj eksperyment, aby rozpocząć zadanie w celu wygenerowania karty wyników. Te konfiguracje są takie same jak te dla pulpitu nawigacyjnego Odpowiedzialne używanie sztucznej inteligencji.
Na koniec przejrzyj konfiguracje i wybierz pozycję Utwórz , aby rozpocząć zadanie!
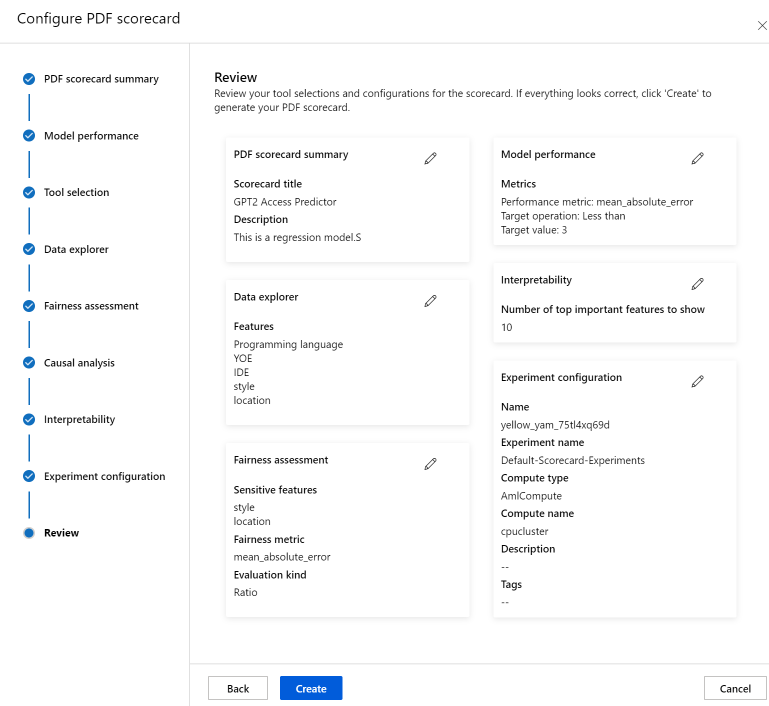
Nastąpi przekierowanie do strony eksperymentu w celu śledzenia postępu zadania po jego uruchomieniu. Aby dowiedzieć się, jak wyświetlać kartę wyników odpowiedzialnej sztucznej inteligencji i korzystać z nich, zobacz Korzystanie z karty wyników odpowiedzialnej sztucznej inteligencji (wersja zapoznawcza).









Następne kroki
- Po wygenerowaniu pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji wyświetl sposób uzyskiwania dostępu do niego i używania go w usłudze Azure Machine Edukacja Studio.
- Dowiedz się więcej o pojęciach i technikach związanych z pulpitem nawigacyjnym odpowiedzialnej sztucznej inteligencji.
- Dowiedz się więcej na temat odpowiedzialnego zbierania danych.
- Dowiedz się więcej o sposobie używania pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji i karty wyników do debugowania danych i modeli oraz informowania o lepszym podejmowaniu decyzji w tym wpisie w blogu społeczności technicznej.
- Dowiedz się, jak pulpit nawigacyjny i karta wyników odpowiedzialnej sztucznej inteligencji były używane przez brytyjski narodowy Usługa kondycji (NHS) w prawdziwej historii klienta.
- Zapoznaj się z funkcjami pulpitu nawigacyjnego odpowiedzialnej sztucznej inteligencji za pośrednictwem tego interaktywnego pokazu internetowego laboratorium sztucznej inteligencji.