Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Z tego artykułu dowiesz się, jak trenować modele przetwarzania obrazów na danych obrazów za pomocą zautomatyzowanego uczenia maszynowego. Modele można trenować przy użyciu rozszerzenia interfejsu wiersza polecenia usługi Azure Machine Learning w wersji 2 lub zestawu SDK języka Python usługi Azure Machine Learning w wersji 2.
Zautomatyzowane uczenie maszynowe obsługuje trenowanie modeli dla zadań przetwarzania obrazów, takich jak klasyfikowanie obrazów, wykrywanie obiektów i segmentacja wystąpień. Tworzenie modeli zautomatyzowanego uczenia maszynowego dla zadań przetwarzania obrazów jest obecnie obsługiwane za pośrednictwem zestawu Azure Machine Learning Python SDK. Wynikowe wersje próbne, modele i dane wyjściowe eksperymentów są dostępne z poziomu interfejsu użytkownika usługi Azure Machine Learning Studio. Dowiedz się więcej na temat zautomatyzowanego uczenia maszynowego na potrzeby zadań przetwarzania obrazów na danych obrazów.
Wymagania wstępne
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
- Obszar roboczy usługi Azure Machine Learning. Aby utworzyć obszar roboczy, zobacz Tworzenie zasobów obszaru roboczego.
- Zainstaluj i skonfiguruj interfejs wiersza polecenia (wersja 2) i upewnij się, że zainstalowano
mlrozszerzenie.
Wybierz typ zadania
Zautomatyzowane uczenie maszynowe dla obrazów obsługuje następujące typy zadań:
| Typ zadania | Składnia zadania rozwiązania AutoML |
|---|---|
| klasyfikacja obrazów | Interfejs wiersza polecenia w wersji 2: image_classification Zestaw SDK w wersji 2: image_classification() |
| klasyfikacja obrazów — wiele etykiet | Interfejs wiersza polecenia w wersji 2: image_classification_multilabel Zestaw SDK w wersji 2: image_classification_multilabel() |
| wykrywanie obiektu obrazu | Interfejs wiersza polecenia w wersji 2: image_object_detection Zestaw SDK w wersji 2: image_object_detection() |
| segmentacja wystąpienia obrazu | Interfejs wiersza polecenia w wersji 2: image_instance_segmentation Zestaw SDK w wersji 2: image_instance_segmentation() |
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Ten typ zadania jest wymaganym parametrem i można go ustawić przy użyciu task klucza.
Na przykład:
task: image_object_detection
Dane trenowania i walidacji
Aby wygenerować modele przetwarzania obrazów, należy wprowadzić dane obrazu oznaczone etykietą jako dane wejściowe na potrzeby trenowania modelu w postaci elementu MLTable. Dane szkoleniowe można utworzyć MLTable w formacie JSONL.
Jeśli dane szkoleniowe mają inny format (np. pascal VOC lub COCO), możesz zastosować skrypty pomocnika dołączone do przykładowych notesów, aby przekonwertować dane na format JSONL. Dowiedz się więcej na temat przygotowywania danych do zadań przetwarzania obrazów za pomocą zautomatyzowanego uczenia maszynowego.
Uwaga
Dane szkoleniowe muszą mieć co najmniej 10 obrazów, aby móc przesłać zadanie rozwiązania AutoML.
Ostrzeżenie
MLTable Tworzenie danych w formacie JSONL jest obsługiwane tylko przy użyciu zestawu SDK i interfejsu wiersza polecenia dla tej funkcji. Tworzenie za pośrednictwem interfejsu MLTable użytkownika nie jest obecnie obsługiwane.
Przykłady schematów JSONL
Struktura zestawu TabularDataset zależy od zadania. W przypadku typów zadań przetwarzania obrazów składa się z następujących pól:
| Pole | opis |
|---|---|
image_url |
Zawiera ścieżkę pliku jako obiekt StreamInfo |
image_details |
Informacje o metadanych obrazu składają się z wysokości, szerokości i formatu. To pole jest opcjonalne, dlatego może lub nie istnieje. |
label |
Reprezentacja json etykiety obrazu na podstawie typu zadania. |
Poniższy kod to przykładowy plik JSONL na potrzeby klasyfikacji obrazów:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Poniższy kod to przykładowy plik JSONL do wykrywania obiektów:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Korzystanie z danych
Gdy dane są w formacie JSONL, możesz utworzyć trenowanie i walidację MLTable , jak pokazano poniżej.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Zautomatyzowane uczenie maszynowe nie nakłada żadnych ograniczeń dotyczących rozmiaru danych trenowania ani sprawdzania poprawności na potrzeby zadań przetwarzania obrazów. Maksymalny rozmiar zestawu danych jest ograniczony tylko przez warstwę magazynu za zestawem danych (przykład: magazyn obiektów blob). Nie ma minimalnej liczby obrazów ani etykiet. Zalecamy jednak rozpoczęcie od co najmniej 10–15 próbek na etykietę, aby upewnić się, że model wyjściowy jest wystarczająco wytrenowany. Im większa łączna liczba etykiet/klas, tym więcej próbek potrzebujesz na etykietę.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Dane szkoleniowe są wymaganym parametrem i są przekazywane przy użyciu training_data klucza. Opcjonalnie możesz określić inną tabelę MLtable jako dane weryfikacji za pomocą validation_data klucza. Jeśli nie określono żadnych danych walidacji, domyślnie do walidacji jest używane 20% danych treningowych, chyba że argument zostanie przekazany validation_data_size z inną wartością.
Nazwa kolumny docelowej jest wymaganym parametrem i jest używana jako element docelowy dla nadzorowanego zadania uczenia maszynowego. Jest on przekazywany przy użyciu target_column_name klucza. Na przykład:
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Obliczenia w celu uruchomienia eksperymentu
Podaj docelowy obiekt obliczeniowy dla zautomatyzowanego uczenia maszynowego w celu przeprowadzenia trenowania modelu. Zautomatyzowane modele uczenia maszynowego na potrzeby zadań przetwarzania obrazów wymagają jednostek SKU procesora GPU oraz obsługi rodzin NC i ND. W celu szybszego trenowania zalecamy serię NCsv3 (z procesorami GPU w wersji 100). Docelowy obiekt obliczeniowy z procesorem SKU maszyny wirtualnej z wieloma procesorami GPU używa wielu procesorów GPU do przyspieszenia trenowania. Ponadto podczas konfigurowania docelowego obiektu obliczeniowego z wieloma węzłami można przeprowadzić szybsze trenowanie modelu za pomocą równoległości podczas dostrajania hiperparametrów dla modelu.
Uwaga
Jeśli używasz wystąpienia obliczeniowego jako celu obliczeniowego, upewnij się, że wiele zadań automatycznego uczenia maszynowego nie jest uruchamianych w tym samym czasie. Upewnij się również, że max_concurrent_trials ustawiono wartość 1 w limitach zadań.
Docelowy obiekt obliczeniowy jest przekazywany przy użyciu parametru compute . Na przykład:
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
compute: azureml:gpu-cluster
Konfigurowanie eksperymentów
W przypadku zadań przetwarzania obrazów można uruchamiać poszczególne wersje próbne, ręczne zamiatania lub automatyczne zamiatania. Zalecamy rozpoczęcie od automatycznego zamiatania, aby uzyskać pierwszy model odniesienia. Następnie możesz wypróbować poszczególne wersje próbne z niektórymi modelami i konfiguracjami hiperparametrów. Na koniec za pomocą ręcznych zamiatania można eksplorować wiele wartości hiperparametrów w pobliżu bardziej obiecujących modeli i konfiguracji hiperparametrów. Ten trzyetapowy przepływ pracy (automatyczne zamiatanie, indywidualne próby, ręczne zamiatania) pozwala uniknąć przeszukiwania całej przestrzeni hiperparametrów, która rośnie wykładniczo w liczbie hiperparametrów.
Automatyczne zamiatania mogą przynieść konkurencyjne wyniki dla wielu zestawów danych. Ponadto nie wymagają one zaawansowanej wiedzy na temat architektur modelu, uwzględniają korelacje hiperparametrów i działają bezproblemowo w różnych konfiguracjach sprzętu. Wszystkie te powody sprawiają, że są one silną opcją na wczesnym etapie procesu eksperymentowania.
Metryka podstawowa
Zadanie trenowania automatycznego uczenia maszynowego używa podstawowej metryki do optymalizacji modelu i dostrajania hiperparametrów. Metryka podstawowa zależy od typu zadania, jak pokazano poniżej; inne podstawowe wartości metryk nie są obecnie obsługiwane.
- Dokładność klasyfikacji obrazów
- Skrzyżowanie z unią w celu klasyfikacji obrazów wieloznakowego
- Średnia precyzja wykrywania obiektów obrazów
- Średnia precyzja dla segmentacji wystąpienia obrazu
Limity zadań
Zasoby wydane w zadaniu trenowania obrazów automatycznego uczenia maszynowego można kontrolować, określając timeout_minutesparametr i max_trialsmax_concurrent_trials dla zadania w ustawieniach limitu zgodnie z opisem w poniższym przykładzie.
| Parametr | Szczegół |
|---|---|
max_trials |
Parametr dla maksymalnej liczby prób do zamiatania. Musi być liczbą całkowitą z zakresu od 1 do 1000. Podczas eksplorowania tylko domyślnych hiperparametrów dla danej architektury modelu ustaw ten parametr na 1. Domyślna wartość wynosi 1. |
max_concurrent_trials |
Maksymalna liczba prób, które mogą być uruchamiane współbieżnie. W przypadku określenia musi być liczbą całkowitą z zakresu od 1 do 100. Domyślna wartość wynosi 1. UWAGA: max_concurrent_trials jest ograniczona max_trials wewnętrznie. Jeśli na przykład użytkownik ustawia max_concurrent_trials=4wartości , max_trials=2wartości zostaną wewnętrznie zaktualizowane jako max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
Czas w minutach przed zakończeniem eksperymentu. Jeśli żaden z nich nie zostanie określony, domyślny eksperyment timeout_minutes wynosi siedem dni (maksymalnie 60 dni) |
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Automatyczne zamiatanie hiperparametrów modelu (AutoMode)
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Trudno przewidzieć najlepszą architekturę modelu i hiperparametry dla zestawu danych. Ponadto w niektórych przypadkach czas ludzki przydzielony do dostrajania hiperparametrów może być ograniczony. W przypadku zadań przetwarzania obrazów można określić dowolną liczbę prób, a system automatycznie określa region przestrzeni hiperparametrów do zamiatania. Nie trzeba definiować przestrzeni wyszukiwania hiperparametrów, metody próbkowania ani zasad wczesnego zakończenia.
Wyzwalanie automodu
Automatyczne zamiatania można uruchamiać, ustawiając max_trials wartość większą niż 1 w limits i nie określając miejsca wyszukiwania, metody próbkowania i zasad zakończenia. Nazywamy to funkcją AutoMode; Zapoznaj się z poniższym przykładem.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
limits:
max_trials: 10
max_concurrent_trials: 2
Wiele prób z zakresu od 10 do 20 prawdopodobnie działa dobrze w wielu zestawach danych. Budżet czasu zadania automatycznego uczenia maszynowego może być nadal ustawiony, ale zalecamy wykonanie tej czynności tylko wtedy, gdy każda wersja próbna może zająć dużo czasu.
Ostrzeżenie
Uruchamianie automatycznych zamiatania za pośrednictwem interfejsu użytkownika nie jest obecnie obsługiwane.
Indywidualne wersje próbne
W poszczególnych próbach można bezpośrednio kontrolować architekturę modelu i hiperparametry. Architektura modelu jest przekazywana za pośrednictwem parametru model_name .
Obsługiwane architektury modeli
W poniższej tabeli przedstawiono podsumowanie obsługiwanych starszych modeli dla każdego zadania przetwarzania obrazów. Użycie tylko tych starszych modeli spowoduje wyzwolenie przebiegów przy użyciu starszego środowiska uruchomieniowego (w którym każde pojedyncze uruchomienie lub wersja próbna jest przesyłane jako zadanie polecenia). Poniżej przedstawiono obsługę funkcji HuggingFace i MMDetection.
| Zadanie | architektury modelu | Składnia literału ciągudefault_model* oznaczany za pomocą * |
|---|---|---|
| Klasyfikacja obrazów (wiele klas i wiele etykiet) |
MobileNet: lekkie modele dla aplikacji mobilnych ResNet: sieci resztkowe ResNeSt: Dzielenie sieci uwagi SE-ResNeXt50: Sieci wyciśnięcia i ekscytacji ViT: Sieci przekształcania obrazów |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (mały) vitb16r224* (podstawa) vitl16r224 (duży) |
| Wykrywanie obiektów |
YOLOv5: jeden model wykrywania obiektów etapu Szybsza funkcja RCNN ResNet FPN: dwa etapowe modele wykrywania obiektów RetinaNet ResNet FPN: rozwiązywanie dysproporcji klas z utratą ogniskową Uwaga: zapoznaj się z model_size hiperparametrem dla rozmiarów modeli YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentacja wystąpień | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Obsługiwane architektury modeli — HuggingFace i MMDetection
W przypadku nowego zaplecza uruchamianego w potokach usługi Azure Machine Learning można również użyć dowolnego modelu klasyfikacji obrazów z centrum HuggingFace, który jest częścią biblioteki przekształcania (takiej jak microsoft/beit-base-patch16-224), a także dowolnego modelu wykrywania obiektów lub segmentacji wystąpień z zoo modelu MMDetection w wersji 3.1.0 (na przykład atss_r50_fpn_1x_coco).
Oprócz obsługi dowolnego modelu z bibliotek HuggingFace Transfomers i MMDetection 3.1.0 oferujemy również listę wyselekcjonowanych modeli z tych bibliotek w rejestrze azureml. Te wyselekcjonowane modele zostały dokładnie przetestowane i używają domyślnych hiperparametrów wybranych z rozbudowanych testów porównawczych w celu zapewnienia skutecznego trenowania. Poniższa tabela zawiera podsumowanie tych wyselekcjonowanych modeli.
| Zadanie | architektury modelu | Składnia literału ciągu |
|---|---|---|
| Klasyfikacja obrazów (wiele klas i wiele etykiet) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Wykrywanie obiektów |
Rozrzedny R-CNN Deformowalne DETR Sieć wirtualna YOLOF |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Segmentacja wystąpień | Maskowanie sieci R-CNN | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Stale aktualizujemy listę wyselekcjonowanych modeli. Najbardziej aktualną listę wyselekcjonowanych modeli dla danego zadania można uzyskać przy użyciu zestawu SDK języka Python:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Wyjście:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Użycie dowolnego modelu HuggingFace lub MMDetection spowoduje wyzwolenie przebiegów przy użyciu składników potoku. Jeśli są używane zarówno starsze modele, jak i HuggingFace/MMdetection, wszystkie uruchomienia/wersje próbne zostaną wyzwolone przy użyciu składników.
Oprócz kontrolowania architektury modelu można również dostroić hiperparametry używane do trenowania modelu. Chociaż wiele hiperparametrów uwidocznionych jest niezależny od modelu, istnieją wystąpienia, w których hiperparametry są specyficzne dla zadań lub specyficzne dla modelu. Dowiedz się więcej na temat dostępnych hiperparametrów dla tych wystąpień.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Jeśli chcesz użyć domyślnych wartości hiperparametrów dla danej architektury (np. yolov5), możesz określić ją przy użyciu klucza model_name w sekcji training_parameters. Na przykład:
training_parameters:
model_name: yolov5
Ręczne zamiatanie hiperparametrów modelu
Podczas trenowania modeli przetwarzania obrazów wydajność modelu zależy w dużym stopniu od wybranych wartości hiperparametrów. Często warto dostosować hiperparametry, aby uzyskać optymalną wydajność. W przypadku zadań przetwarzania obrazów można zamiatać hiperparametry, aby znaleźć optymalne ustawienia dla modelu. Ta funkcja stosuje możliwości dostrajania hiperparametrów w usłudze Azure Machine Learning. Dowiedz się, jak dostroić hiperparametry.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Definiowanie przestrzeni wyszukiwania parametrów
Architektury modelu i hiperparametry można zdefiniować, aby zamiatać w przestrzeni parametrów. Można określić jedną architekturę modelu lub wiele z nich.
- Zobacz Poszczególne wersje próbne , aby uzyskać listę obsługiwanych architektur modelu dla każdego typu zadania.
- Zobacz Hiperparametry dla hiperparametrów zadań przetwarzania obrazów dla każdego typu zadania przetwarzania obrazów.
- Szczegółowe informacje na temat obsługiwanych dystrybucji dla dyskretnych i ciągłych hiperparametrów.
Metody próbkowania dla zamiatania
Podczas zamiatania hiperparametrów należy określić metodę próbkowania, która ma być używana do zamiatania przez zdefiniowaną przestrzeń parametrów. Obecnie następujące metody próbkowania są obsługiwane za pomocą parametru sampling_algorithm :
| Typ próbkowania | Składnia zadania rozwiązania AutoML |
|---|---|
| Losowe próbkowanie | random |
| Próbkowanie siatki | grid |
| Próbkowanie bayesowskie | bayesian |
Uwaga
Obecnie tylko próbkowanie losowe i siatki obsługuje tylko warunkowe przestrzenie hiperparametryczne.
Zasady wczesnego kończenia
Możesz automatycznie zakończyć słabe wersje próbne z zasadami wczesnego kończenia. Wczesne zakończenie poprawia wydajność obliczeniową, oszczędzając zasoby obliczeniowe, które w przeciwnym razie zostałyby wydane na mniej obiecujące wersje próbne. Zautomatyzowane uczenie maszynowe dla obrazów obsługuje następujące zasady wczesnego zakończenia przy użyciu parametru early_termination . Jeśli nie określono żadnych zasad zakończenia, wszystkie wersje próbne zostaną uruchomione do ukończenia.
| Zasady wczesnego kończenia | Składnia zadania rozwiązania AutoML |
|---|---|
| Zasady bandytu | Interfejs wiersza polecenia w wersji 2: bandit Zestaw SDK w wersji 2: BanditPolicy() |
| Mediana zatrzymywania zasad | Interfejs wiersza polecenia w wersji 2: median_stopping Zestaw SDK w wersji 2: MedianStoppingPolicy() |
| Zasady wyboru obcięcia | Interfejs wiersza polecenia w wersji 2: truncation_selection Zestaw SDK w wersji 2: TruncationSelectionPolicy() |
Dowiedz się więcej na temat konfigurowania zasad wczesnego zakończenia dla zamiatania hiperparametrów.
Uwaga
Aby zapoznać się z kompletnym przykładem konfiguracji zamiatania, zapoznaj się z tym samouczkiem.
Możesz skonfigurować wszystkie parametry powiązane z funkcjami zamiatania, jak pokazano w poniższym przykładzie.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Ustawienia stałe
Możesz przekazać stałe ustawienia lub parametry, które nie zmieniają się podczas zamiatania przestrzeni parametrów, jak pokazano w poniższym przykładzie.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Rozszerzanie danych
Ogólnie rzecz biorąc, wydajność modelu uczenia głębokiego może często poprawić się przy użyciu większej ilości danych. Rozszerzanie danych to praktyczna technika wzmacniania rozmiaru danych i zmienności zestawu danych, co pomaga zapobiec nadmiernemu dopasowaniu i ulepszeniu uogólniania modelu w przypadku niezaużytowanych danych. Zautomatyzowane uczenie maszynowe stosuje różne techniki rozszerzania danych na podstawie zadania przetwarzania obrazów przed przekazywaniem obrazów wejściowych do modelu. Obecnie nie ma uwidocznionych hiperparametrów do kontrolowania rozszerzeń danych.
| Zadanie | Zestaw danych, na który ma to wpływ | Zastosowane techniki rozszerzania danych |
|---|---|---|
| Klasyfikacja obrazów (wiele klas i wiele etykiet) | Szkolenie Walidacja i testowanie |
Losowy rozmiar i przycinanie, przerzucanie poziome, zakłócenia kolorów (jasność, kontrast, nasycenie i odcienie), normalizacja przy użyciu średniej i odchylenia standardowego sieci ImageNet opartej na kanale Zmienianie rozmiaru, wyśrodkowanie przycinania, normalizacja |
| Wykrywanie obiektów, segmentacja wystąpień | Szkolenie Walidacja i testowanie |
Losowe przycinanie wokół pól ograniczenia, rozwijanie, przerzucanie w poziomie, normalizacja, zmiana rozmiaru Normalizacja, zmiana rozmiaru |
| Wykrywanie obiektów przy użyciu narzędzia yolov5 | Szkolenie Walidacja i testowanie |
Mozaika, losowa szafka (obrót, tłumaczenie, skala, ścinanie), przerzucanie poziome Zmiana rozmiaru skrzynki pocztowej |
Obecnie rozszerzenia zdefiniowane powyżej są stosowane domyślnie dla zautomatyzowanego uczenia maszynowego dla zadania obrazu. Aby zapewnić kontrolę nad rozszerzeniami, zautomatyzowane uczenie maszynowe dla obrazów uwidacznia poniżej dwóch flag w celu wyłączenia niektórych rozszerzeń. Obecnie te flagi są obsługiwane tylko w przypadku zadań wykrywania obiektów i segmentacji wystąpień.
- apply_mosaic_for_yolo: ta flaga jest specyficzna tylko dla modelu Yolo. Ustawienie wartości False powoduje wyłączenie rozszerzenia danych mozaiki, które jest stosowane w czasie trenowania.
-
apply_automl_train_augmentations: ustawienie tej flagi na false powoduje wyłączenie rozszerzenia zastosowanego podczas trenowania modeli wykrywania obiektów i segmentacji wystąpień. Aby uzyskać rozszerzenia, zobacz szczegóły w powyższej tabeli.
- W przypadku modeli wykrywania obiektów innych niż yolo i modeli segmentacji wystąpień ta flaga wyłącza tylko pierwsze trzy rozszerzenia. Na przykład: Losowe przycinanie wokół pól ograniczenia, rozwijanie, przerzucanie w poziomie. Normalizacja i zmiana rozmiaru rozszerzeń są nadal stosowane niezależnie od tej flagi.
- W przypadku modelu Yolo ta flaga wyłącza losowe affine i poziome rozszerzenia przerzucania.
Te dwie flagi są obsługiwane za pośrednictwem advanced_settings w training_parameters i mogą być kontrolowane w następujący sposób.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Należy pamiętać, że te dwie flagi są niezależne od siebie i mogą być również używane w połączeniu przy użyciu następujących ustawień.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
W naszych eksperymentach okazało się, że te rozszerzenia pomagają modelowi lepiej uogólniać. W związku z tym po wyłączeniu tych rozszerzeń zalecamy użytkownikom łączenie ich z innymi rozszerzeniami offline w celu uzyskania lepszych wyników.
Trenowanie przyrostowe (opcjonalnie)
Po zakończeniu zadania trenowania możesz jeszcze bardziej trenować model, ładując wytrenowany punkt kontrolny modelu. Do trenowania przyrostowego można użyć tego samego zestawu danych lub innego zestawu danych. Jeśli model jest zadowalający, możesz zatrzymać trenowanie i użyć bieżącego modelu.
Przekazywanie punktu kontrolnego za pomocą identyfikatora zadania
Możesz przekazać identyfikator zadania, z którego chcesz załadować punkt kontrolny.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Przesyłanie zadania automatycznego uczenia maszynowego
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Aby przesłać zadanie rozwiązania AutoML, uruchom następujące polecenie interfejsu wiersza polecenia w wersji 2 ze ścieżką do pliku .yml, nazwy obszaru roboczego, grupy zasobów i identyfikatora subskrypcji.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Dane wyjściowe i metryki oceny
Zadania zautomatyzowanego trenowania uczenia maszynowego generują pliki modelu wyjściowego, metryki oceny, dzienniki i artefakty wdrożenia, takie jak plik oceniania i plik środowiska. Te pliki i metryki można wyświetlić na karcie danych wyjściowych i dzienników i metryk zadań podrzędnych.
Napiwek
Sprawdź, jak przejść do wyników zadania w sekcji Wyświetlanie wyników zadania.
Aby zapoznać się z definicjami i przykładami wykresów wydajności i metryk podanych dla każdego zadania, zobacz Ocena wyników eksperymentu zautomatyzowanego uczenia maszynowego.
Rejestrowanie i wdrażanie modelu
Po zakończeniu zadania można zarejestrować model, który został utworzony w najlepszej wersji próbnej (konfiguracja, która spowodowała najlepszą metryki podstawową). Model można zarejestrować po pobraniu lub określając ścieżkę azureml przy użyciu odpowiedniego identyfikatora jobid. Uwaga: Jeśli chcesz zmienić ustawienia wnioskowania opisane poniżej, musisz pobrać model i zmienić settings.json i zarejestrować się przy użyciu zaktualizowanego folderu modelu.
Uzyskiwanie najlepszej wersji próbnej
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
CLI example not available, please use Python SDK.
rejestrowanie modelu
Zarejestruj model przy użyciu ścieżki azureml lub ścieżki pobranej lokalnie.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Po zarejestrowaniu modelu, którego chcesz użyć, możesz wdrożyć go przy użyciu zarządzanego punktu końcowego online deploy-managed-online-endpoint
Konfigurowanie punktu końcowego online
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Tworzenie punktu końcowego
Przy użyciu utworzonego wcześniej punktu końcowego MLClient utworzymy punkt końcowy w obszarze roboczym. To polecenie uruchamia tworzenie punktu końcowego i zwraca odpowiedź potwierdzenia, gdy tworzenie punktu końcowego będzie kontynuowane.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Konfigurowanie wdrożenia online
Wdrożenie to zestaw zasobów wymaganych do hostowania modelu, który wykonuje rzeczywiste wnioskowanie. Utworzymy wdrożenie dla naszego punktu końcowego ManagedOnlineDeployment przy użyciu klasy . Możesz użyć jednostek SKU maszyn wirtualnych procesora GPU lub procesora CPU dla klastra wdrażania.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Tworzenie wdrożenia
Przy użyciu utworzonego MLClient wcześniej wdrożenia utworzymy teraz w obszarze roboczym. To polecenie spowoduje uruchomienie tworzenia wdrożenia i zwrócenie odpowiedzi potwierdzenia podczas tworzenia wdrożenia.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
aktualizowanie ruchu:
Domyślnie bieżące wdrożenie jest ustawione na odbieranie 0% ruchu. Można ustawić wartość procentową bieżącego wdrożenia ruchu. Suma wartości procentowych ruchu we wszystkich wdrożeniach z jednym punktem końcowym nie powinna przekraczać 100%.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
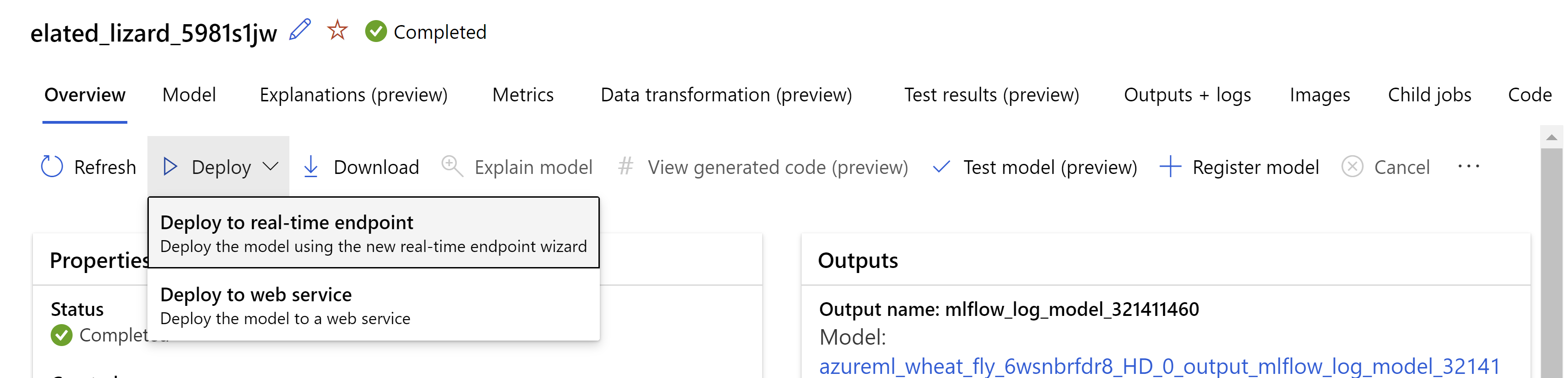
Alternatywnie możesz wdrożyć model z poziomu interfejsu użytkownika usługi Azure Machine Learning Studio. Przejdź do modelu, który chcesz wdrożyć na karcie Modele zadania zautomatyzowanego uczenia maszynowego, a następnie wybierz pozycję Wdróż i wybierz pozycję Wdróż do punktu końcowego w czasie rzeczywistym.
 .
.
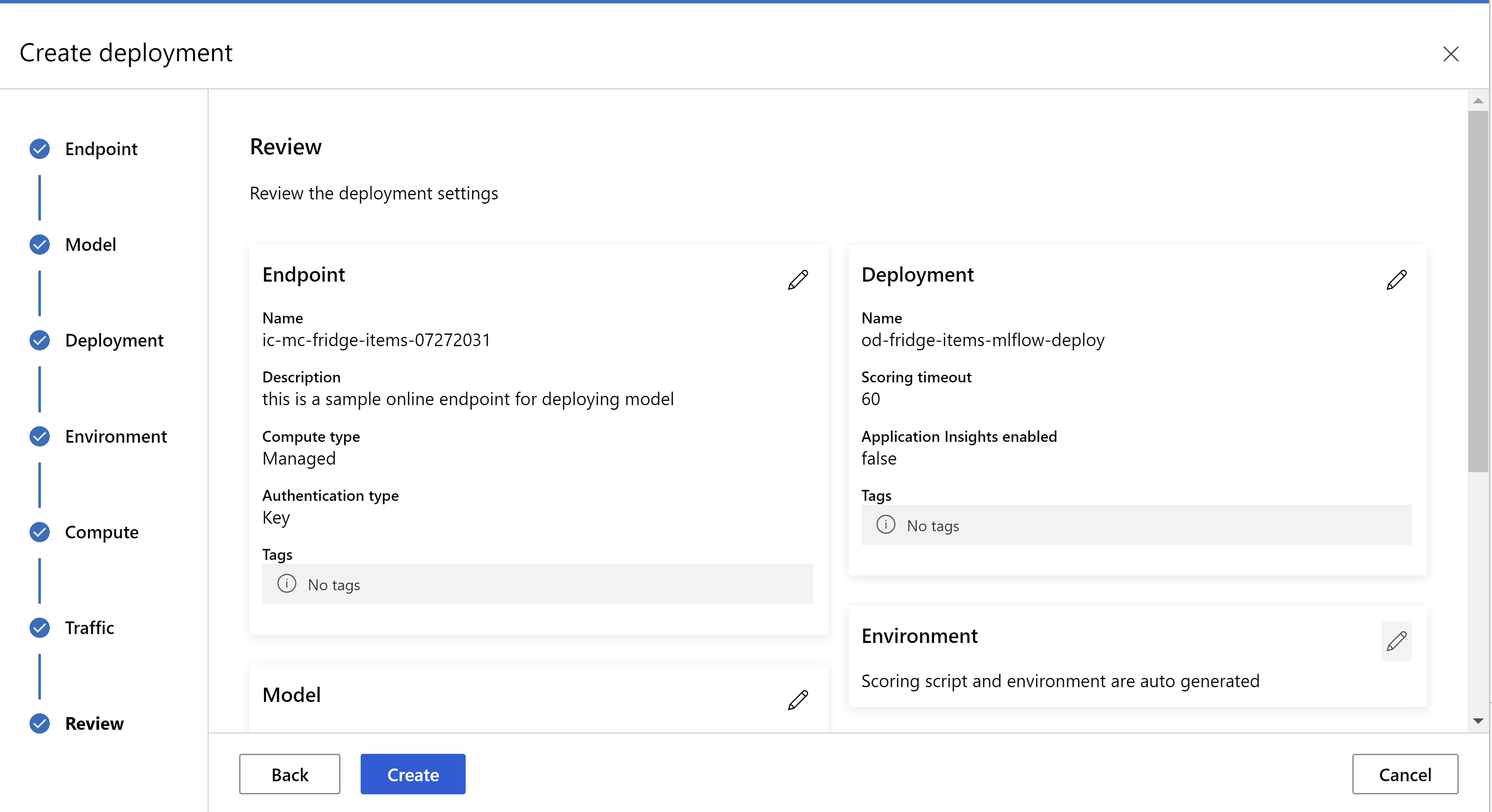
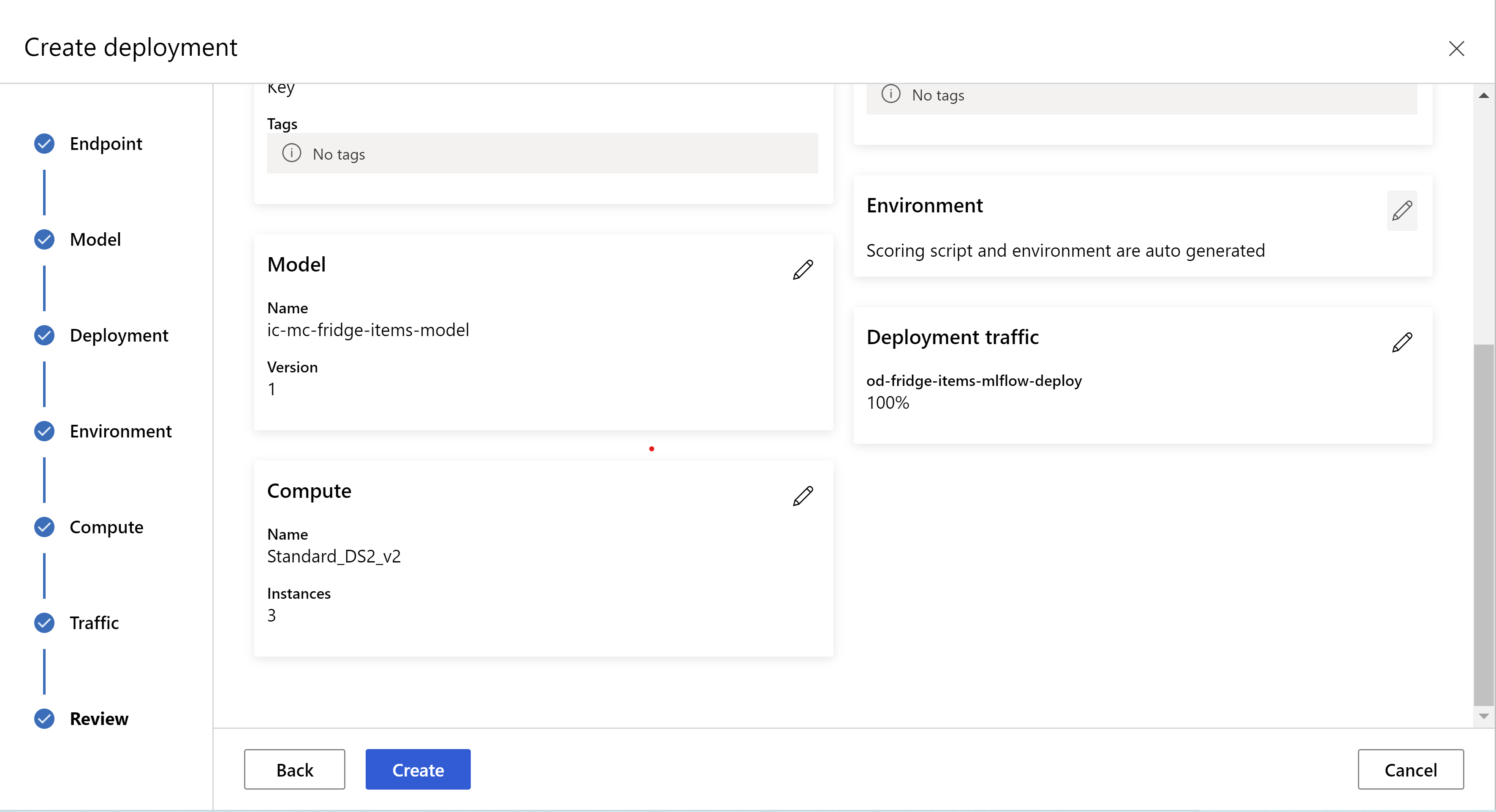
W ten sposób wygląda strona przeglądu. Możemy wybrać typ wystąpienia, liczbę wystąpień i ustawić procent ruchu dla bieżącego wdrożenia.
 .
.
 .
.
Aktualizowanie ustawień wnioskowania
W poprzednim kroku pobraliśmy plik mlflow-model/artifacts/settings.json z najlepszego modelu. które mogą służyć do aktualizowania ustawień wnioskowania przed zarejestrowaniem modelu. Chociaż zaleca się używanie tych samych parametrów co trenowanie w celu uzyskania najlepszej wydajności.
Każde z zadań (i niektórych modeli) ma zestaw parametrów. Domyślnie używamy tych samych wartości dla parametrów, które były używane podczas trenowania i walidacji. W zależności od zachowania, którego potrzebujemy podczas korzystania z modelu do wnioskowania, możemy zmienić te parametry. Poniżej znajduje się lista parametrów dla każdego typu zadania i modelu.
| Zadanie | Nazwa parametru | Wartość domyślna |
|---|---|---|
| Klasyfikacja obrazów (wiele klas i wiele etykiet) | valid_resize_sizevalid_crop_size |
256 224 |
| Wykrywanie obiektów | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0,5 100 |
Wykrywanie obiektów przy użyciu yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 Średni 0.1 0,5 |
| Segmentacja wystąpień | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0,5 100 0,5 100 Fałsz JPG |
Aby zapoznać się ze szczegółowym opisem hiperparametrów specyficznych dla zadań podrzędnych, zapoznaj się z hiperparametrami dotyczącymi zadań przetwarzania obrazów w zautomatyzowanym uczeniu maszynowym.
Jeśli chcesz użyć tilingu i chcesz kontrolować zachowanie tilingu, dostępne są następujące parametry: tile_grid_size, tile_overlap_ratio i tile_predictions_nms_thresh. Aby uzyskać więcej informacji na temat tych parametrów, zobacz Trenowanie małego modelu wykrywania obiektów przy użyciu rozwiązania AutoML.
Testowanie wdrożenia
Sprawdź tę sekcję Testowanie wdrożenia , aby przetestować wdrożenie i zwizualizować wykrycia z modelu.
Generowanie wyjaśnień dla przewidywań
Ważne
Te ustawienia są obecnie dostępne w publicznej wersji zapoznawczej. Są one dostarczane bez umowy dotyczącej poziomu usług. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Ostrzeżenie
Wyjaśnienie modelu jest obsługiwane tylko w przypadku klasyfikacji wieloklasowej i klasyfikacji wielu etykiet.
Niektóre zalety używania funkcji Wyjaśnij sztuczną inteligencję (XAI) z rozwiązaniem AutoML dla obrazów:
- Poprawia przejrzystość złożonych przewidywań modelu przetwarzania obrazów
- Pomaga użytkownikom zrozumieć ważne funkcje/piksele na obrazie wejściowym współtworzenia prognoz modelu
- Pomaga w rozwiązywaniu problemów z modelami
- Pomaga w odkrywaniu uprzedzeń
Wyjaśnienia
Wyjaśnienia to przypisania funkcji lub wagi podane dla każdego piksela na obrazie wejściowym na podstawie jego wkładu w przewidywanie modelu. Każda waga może być ujemna (negatywnie skorelowana z przewidywaniem) lub dodatnia (dodatnio skorelowana z przewidywaniem). Te przypisania są obliczane względem przewidywanej klasy. W przypadku klasyfikacji wieloklasowej jest generowana dokładnie jedna macierz rozmiaru [3, valid_crop_size, valid_crop_size] przypisania dla każdej próbki, natomiast w przypadku klasyfikacji wielokatatrowej macierz przypisywania rozmiaru [3, valid_crop_size, valid_crop_size] jest generowana dla każdej przewidywanej etykiety/klasy dla każdej próbki.
Korzystając z funkcji Wyjaśnij sztuczną inteligencję w rozwiązaniu AutoML dla obrazów we wdrożonym punkcie końcowym, użytkownicy mogą uzyskiwać wizualizacje wyjaśnień (przypisywanie autorstwa nakładane na obraz wejściowy) i/lub przypisania (tablica wielowymiarowa o rozmiarze [3, valid_crop_size, valid_crop_size]) dla każdego obrazu. Oprócz wizualizacji użytkownicy mogą również uzyskać macierze atrybucji, aby uzyskać większą kontrolę nad wyjaśnieniami (takimi jak generowanie wizualizacji niestandardowych przy użyciu przypisań lub analizowanie segmentów przypisań). Wszystkie algorytmy wyjaśnienia używają przyciętych obrazów kwadratowych o rozmiarze valid_crop_size do generowania przypisań.
Wyjaśnienia można wygenerować z punktu końcowego online lub punktu końcowego wsadowego. Po zakończeniu wdrażania można użyć tego punktu końcowego do wygenerowania wyjaśnień dotyczących przewidywań. We wdrożeniach online pamiętaj, aby przekazać request_settings = OnlineRequestSettings(request_timeout_ms=90000) parametr do ManagedOnlineDeployment parametru i ustawić request_timeout_ms wartość maksymalną, aby uniknąć problemów z przekroczeniem limitu czasu podczas generowania wyjaśnień (zapoznaj się z sekcją rejestrowanie i wdrażanie modelu). Niektóre metody objaśnienia (XAI), takie jak xrai zużywają więcej czasu (szczególnie w przypadku klasyfikacji wieloeznakowej, ponieważ musimy wygenerować przypisania i/lub wizualizacje względem każdej przewidywanej etykiety). Dlatego zalecamy wykonanie jakichkolwiek wystąpień procesora GPU w celu uzyskania szybszych wyjaśnień. Aby uzyskać więcej informacji na temat schematu danych wejściowych i wyjściowych na potrzeby generowania wyjaśnień, zobacz dokumentację schematu.
Obsługujemy następujące najnowocześniejsze algorytmy objaśnienia w rozwiązaniu AutoML dla obrazów:
- XRAI (xrai)
- Gradienty zintegrowane (integrated_gradients)
- Przewodnik GradCAM (guided_gradcam)
- BackPropagation z przewodnikiem (guided_backprop)
W poniższej tabeli opisano parametry dostrajania specyficzne dla algorytmu objaśnienia dla XRAI i zintegrowanych gradientów. Backpropagation z przewodnikiem i gradcam z przewodnikiem nie wymagają żadnych parametrów dostrajania.
| Algorytm XAI | Parametry specyficzne dla algorytmu | Wartości domyślne |
|---|---|---|
xrai |
1. : n_stepsliczba kroków używanych przez metodę przybliżenia. Większa liczba kroków prowadzi do lepszego przybliżenia przypisań (wyjaśnień). Zakres n_steps to [2, inf), ale wydajność przypisań zaczyna się zbieżność po 50 krokach. Optional, Int 2. : xrai_fastCzy używać szybszej wersji XRAI. jeśli True, czas obliczeń dla wyjaśnień jest szybszy, ale prowadzi do mniej dokładnych wyjaśnień (przypisań) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. : n_stepsliczba kroków używanych przez metodę przybliżenia. Większa liczba kroków prowadzi do lepszych przypisań (wyjaśnienia). Zakres n_steps to [2, inf), ale wydajność przypisań zaczyna się zbieżność po 50 krokach.Optional, Int 2. : approximation_methodMetoda przybliżania całkowitej. Dostępne metody przybliżenia to riemann_middle i gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Algorytm XRAI wewnętrznie używa zintegrowanych gradientów.
n_steps Dlatego parametr jest wymagany zarówno przez zintegrowane gradienty, jak i algorytmy XRAI. Większa liczba kroków zużywa więcej czasu na przybliżenie wyjaśnień i może spowodować problemy z przekroczeniem limitu czasu w punkcie końcowym online.
Zalecamy używanie algorytmów Z przewodnikiem XRAI > GradCAM Integrated Gradients > z przewodnikiem BackPropagation w celu uzyskania lepszych wyjaśnień, podczas gdy z przewodnikiem BackPropagation > z przewodnikiem GradCAM >> zintegrowane gradienty > XRAI są zalecane do szybszych wyjaśnień w określonej kolejności.
Przykładowe żądanie do punktu końcowego online wygląda następująco. To żądanie generuje wyjaśnienia, gdy model_explainability jest ustawiona wartość True. Następujące żądanie generuje wizualizacje i przypisania przy użyciu szybszej wersji algorytmu XRAI z 50 krokami.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Aby uzyskać więcej informacji na temat generowania wyjaśnień, zobacz Repozytorium notesów GitHub dla przykładów zautomatyzowanego uczenia maszynowego.
Interpretowanie wizualizacji
Wdrożony punkt końcowy zwraca ciąg obrazu zakodowany w formacie base64, jeśli oba model_explainability punkty i visualizations są ustawione na Truewartość . Zdekoduj ciąg base64 zgodnie z opisem w notesach lub użyj następującego kodu, aby zdekodować i zwizualizować ciągi obrazu base64 w przewidywaniu.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
Na poniższej ilustracji opisano wizualizację objaśnień przykładowego obrazu wejściowego.

Zdekodowana ilustracja base64 zawiera cztery sekcje obrazu w siatce 2 x 2.
- Obraz w lewym górnym rogu (0, 0) to przycięty obraz wejściowy
- Obraz w prawym górnym rogu (0, 1) to mapa cieplna przypisań w skali kolorów bgyw (niebieski żółty biały), gdzie wkład białych pikseli w przewidywanej klasie jest najwyższy, a niebieskie piksele są najniższe.
- Obraz w lewym dolnym rogu (1, 0) jest mieszaną mapą cieplną przypisań przyciętych obrazów wejściowych
- Obraz w prawym dolnym rogu (1, 1) jest przyciętym obrazem wejściowym z 30 procentami pikseli na podstawie wyników autorstwa.
Interpretowanie autorstwa
Wdrożony punkt końcowy zwraca atrybuty przypisania, jeśli parametr i model_explainabilityattributions jest ustawiony na Truewartość . Aby uzyskać więcej informacji, zapoznaj się z notesami klasyfikacji wieloklasowej i klasyfikacji wielu etykiet.
Te przypisania zapewniają większą kontrolę użytkownikom w celu generowania niestandardowych wizualizacji lub oceniania ocen na poziomie pikseli. Poniższy fragment kodu opisuje sposób generowania wizualizacji niestandardowych przy użyciu macierzy autorstwa. Aby uzyskać więcej informacji na temat schematu przypisywania autorstwa dla klasyfikacji wieloklasowej i klasyfikacji wielu etykiet, zobacz dokumentację schematu.
Użyj dokładnych valid_resize_size wartości i valid_crop_size wybranego modelu, aby wygenerować wyjaśnienia (wartości domyślne to odpowiednio 256 i 224). Poniższy kod używa funkcji wizualizacji Captum do generowania wizualizacji niestandardowych. Użytkownicy mogą używać dowolnej innej biblioteki do generowania wizualizacji. Aby uzyskać więcej informacji, zapoznaj się z narzędziami wizualizacji captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Duże zestawy danych
Jeśli używasz rozwiązania AutoML do trenowania na dużych zestawach danych, istnieją pewne ustawienia eksperymentalne, które mogą być przydatne.
Ważne
Te ustawienia są obecnie dostępne w publicznej wersji zapoznawczej. Są one dostarczane bez umowy dotyczącej poziomu usług. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Trenowanie z wieloma procesorami GPU i wieloma węzłami
Domyślnie każdy model trenuje na jednej maszynie wirtualnej. Jeśli trenowanie modelu zajmuje zbyt dużo czasu, użycie maszyn wirtualnych zawierających wiele procesorów GPU może pomóc. Czas trenowania modelu na dużych zestawach danych powinien zmniejszyć się w przybliżeniu liniową proporcję do liczby używanych procesorów GPU. (Na przykład model powinien trenować mniej więcej dwa razy szybciej na maszynie wirtualnej z dwoma procesorami GPU, jak na maszynie wirtualnej z jednym procesorem GPU). Jeśli czas trenowania modelu jest nadal wysoki na maszynie wirtualnej z wieloma procesorami GPU, możesz zwiększyć liczbę maszyn wirtualnych używanych do trenowania każdego modelu. Podobnie jak w przypadku trenowania wielu procesorów GPU, czas trenowania modelu na dużych zestawach danych powinien również zmniejszyć się w przybliżeniu liniową proporcję do liczby używanych maszyn wirtualnych. Podczas trenowania modelu na wielu maszynach wirtualnych należy użyć jednostki SKU obliczeniowej obsługującej rozwiązanie InfiniBand w celu uzyskania najlepszych wyników. Liczbę maszyn wirtualnych używanych do trenowania pojedynczego modelu można skonfigurować, ustawiając node_count_per_trial właściwość zadania automatycznego uczenia maszynowego.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
properties:
node_count_per_trial: "2"
Przesyłanie strumieniowe plików obrazów z magazynu
Domyślnie wszystkie pliki obrazów są pobierane na dysk przed rozpoczęciem trenowania modelu. Jeśli rozmiar plików obrazów jest większy niż dostępne miejsce na dysku, zadanie kończy się niepowodzeniem. Zamiast pobierać wszystkie obrazy na dysk, możesz wybrać opcję przesyłania strumieniowego plików obrazów z usługi Azure Storage, ponieważ są one potrzebne podczas trenowania. Pliki obrazów są przesyłane strumieniowo z usługi Azure Storage bezpośrednio do pamięci systemowej, pomijając dysk. Jednocześnie jak najwięcej plików z magazynu jest buforowanych na dysku, aby zminimalizować liczbę żądań do magazynu.
Uwaga
Jeśli przesyłanie strumieniowe jest włączone, upewnij się, że konto usługi Azure Storage znajduje się w tym samym regionie co zasoby obliczeniowe, aby zminimalizować koszty i opóźnienia.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Przykładowe notesy
Przejrzyj szczegółowe przykłady kodu i przypadki użycia w repozytorium notesów GitHub, aby zapoznać się z przykładami zautomatyzowanego uczenia maszynowego. Sprawdź foldery z prefiksem "automl-image-", aby uzyskać przykłady specyficzne dla tworzenia modeli przetwarzania obrazów.
Przykłady kodu
Zapoznaj się ze szczegółowymi przykładami kodu i przypadkami użycia w repozytorium azureml-examples na potrzeby przykładów zautomatyzowanego uczenia maszynowego.