Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Python SDK azure-ai-ml w wersji 2 (bieżąca)
Python SDK azure-ai-ml w wersji 2 (bieżąca)
Dowiedz się, jak skonfigurować środowisko deweloperskie języka Python dla usługi Azure Machine Learning.
W poniższej tabeli przedstawiono każde środowisko programistyczne opisane w tym artykule wraz z zaletami i wadami.
| Środowisko | Plusy | Minusy |
|---|---|---|
| Środowisko lokalne | Pełna kontrola nad środowiskiem projektistycznym i zależnościami. Uruchom przy użyciu dowolnego narzędzia kompilacji, środowiska lub IDE. | Rozpoczynanie pracy trwa dłużej. Należy zainstalować wymagane pakiety SDK, a także środowisko, jeśli jeszcze go nie masz. |
| Wystąpienie obliczeniowe usługi Azure Machine Learning | Najłatwiejszy sposób, aby zacząć. Zestaw SDK jest już zainstalowany na maszynie wirtualnej Twojego obszaru roboczego, a samouczki Jupyter Notebook są wstępnie sklonowane i gotowe do uruchomienia. | Brak kontroli nad środowiskiem projektistycznym i zależnościami. Koszt jest naliczany dla maszyny wirtualnej z systemem Linux (maszyna wirtualna może zostać zatrzymana, gdy nie jest używana w celu uniknięcia opłat). Zobacz szczegółowe informacje o cenach. |
| Maszyna wirtualna Nauka o danych (DSVM) | Podobnie jak w przypadku instancji obliczeniowej opartej na chmurze, gdzie wstępnie zainstalowano język Python, ale z innymi popularnymi narzędziami do nauki o danych i uczenia maszynowego które są wstępnie zainstalowane. Łatwe skalowanie i łączenie z innymi niestandardowymi narzędziami i przepływami pracy. | Wolniejsze środowisko pracy w porównaniu z wystąpieniem obliczeniowym opartym na chmurze. |
Ten artykuł zawiera również inne porady dotyczące użycia dla następujących narzędzi:
Notesy Jupyter Notebook: jeśli już używasz notesów Jupyter Notebook, zestaw SDK zawiera pewne dodatki, które należy zainstalować.
Visual Studio Code: jeśli używasz programu Visual Studio Code, rozszerzenie Usługi Azure Machine Learning obejmuje obsługę języka Python oraz funkcje, które ułatwiają pracę z usługą Azure Machine Learning znacznie wygodniejsze i wydajne.
Wymagania wstępne
- Obszar roboczy usługi Azure Machine Learning. Jeśli go nie masz, możesz utworzyć obszar roboczy usługi Azure Machine Learning za pomocą witryny Azure Portal, interfejsu wiersza polecenia platformy Azure i szablonów usługi Azure Resource Manager.
Utwórz plik konfiguracji obszaru roboczego: tylko lokalne i DSVM
Plik konfiguracji obszaru roboczego to plik JSON, który informuje zestaw SDK, jak komunikować się z obszarem roboczym usługi Azure Machine Learning. Plik ma nazwę config.json i ma następujący format:
{
"subscription_id": "<subscription-id>",
"resource_group": "<resource-group>",
"workspace_name": "<workspace-name>"
}
Ten plik JSON musi znajdować się w strukturze katalogów zawierającej skrypty języka Python lub notesy Jupyter Notebook. Może on znajdować się w tym samym katalogu, podkatalogu o nazwie.azureml*lub w katalogu nadrzędnym.
Aby użyć tego pliku z kodu, zastosuj metodę MLClient.from_config. Ten kod ładuje informacje z pliku i nawiązuje połączenie z obszarem roboczym.
Utwórz plik konfiguracji obszaru roboczego w jednej z następujących metod:
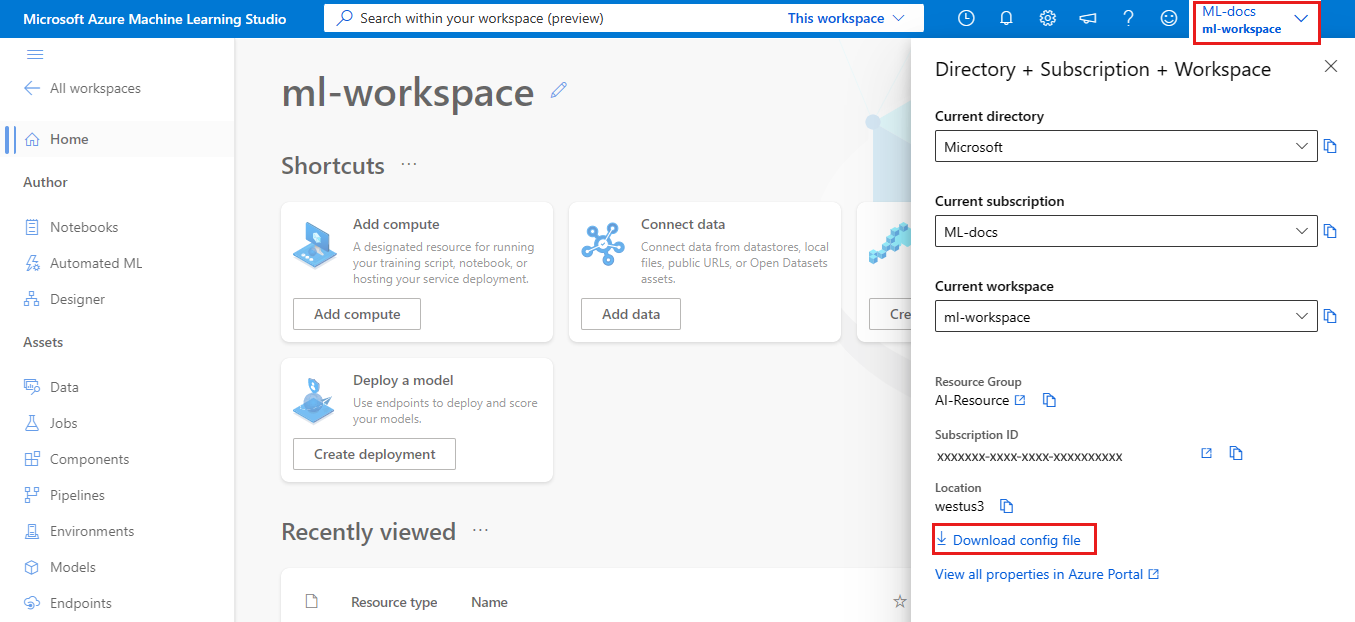
Azure Machine Learning Studio
Pobierz plik:
- Zaloguj się do usługi Azure Machine Learning Studio
- Na pasku narzędzi usługi Azure Machine Learning Studio w prawym górnym rogu wybierz nazwę obszaru roboczego.
- Wybierz link Pobierz plik konfiguracji.
Zestaw SDK języka Python usługi Azure Machine Learning
Utwórz skrypt umożliwiający nawiązanie połączenia z obszarem roboczym usługi Azure Machine Learning. Pamiętaj, aby zastąpić
subscription_id,resource_groupiworkspace_namewłasnymi elementami.DOTYCZY:
Python SDK azure-ai-ml w wersji 2 (bieżąca)#import required libraries from azure.ai.ml import MLClient from azure.identity import DefaultAzureCredential #Enter details of your Azure Machine Learning workspace subscription_id = '<SUBSCRIPTION_ID>' resource_group = '<RESOURCE_GROUP>' workspace = '<AZUREML_WORKSPACE_NAME>' #connect to the workspace ml_client = MLClient(DefaultAzureCredential(), subscription_id, resource_group, workspace)

Komputer lokalny lub zdalne środowisko maszyny wirtualnej
Środowisko można skonfigurować na komputerze lokalnym lub zdalnej maszynie wirtualnej, takiej jak wystąpienie obliczeniowe usługi Azure Machine Learning lub Data Science VM.
Aby skonfigurować lokalne środowisko programistyczne lub zdalną maszynę wirtualną:
Tworzenie środowiska wirtualnego języka Python (virtualenv, conda).
Uwaga
Mimo że nie jest to wymagane, zalecamy używanie środowiska Anaconda lub Miniconda do zarządzania środowiskami wirtualnymi języka Python i instalowania pakietów.
Ważne
Jeśli korzystasz z systemu Linux lub macOS i używasz powłoki innej niż bash (na przykład zsh), podczas wykonywania niektórych poleceń mogą wystąpić błędy. Aby ominąć ten problem, użyj polecenia
bashdo uruchomienia nowej powłoki bash, a następnie wykonaj tam polecenia.Aktywuj nowo utworzone środowisko wirtualne języka Python.
Zainstaluj zestaw SDK języka Python usługi Azure Machine Learning.
Aby skonfigurować środowisko lokalne do korzystania z obszaru roboczego usługi Azure Machine Learning, utwórz plik konfiguracji obszaru roboczego lub użyj istniejącego.
Po skonfigurowaniu środowiska lokalnego możesz rozpocząć pracę z usługą Azure Machine Learning. Zobacz Samouczek: Azure Machine Learning w ciągu dnia, aby rozpocząć pracę.
Notebooki Jupyter
Podczas uruchamiania lokalnego serwera notesu Jupyter Notebook zalecamy utworzenie jądra IPython dla środowiska wirtualnego języka Python. Pomaga to zapewnić oczekiwane zachowanie jądra i importu pakietów.
Włączanie jądra IPython specyficznych dla środowiska
conda install notebook ipykernelUtwórz jądro dla środowiska wirtualnego języka Python. Pamiętaj, aby zastąpić
<myenv>nazwą środowiska wirtualnego Python.ipython kernel install --user --name <myenv> --display-name "Python (myenv)"Uruchamianie serwera Jupyter Notebook
Napiwek
Przykładowe notesy można znaleźć w repozytorium AzureML-Examples . Przykłady zestawu SDK znajdują się w katalogu /sdk/python. Na przykład przykład notesu konfiguracji .
Visual Studio Code
Aby użyć programu Visual Studio Code do programowania:
- Zainstalowanie programu Visual Studio Code.
- Zainstaluj rozszerzenie programu Visual Studio Code usługi Azure Machine Learning (wersja zapoznawcza).
Po zainstalowaniu rozszerzenia programu Visual Studio Code użyj go do:
- Zarządzanie zasobami usługi Azure Machine Learning
- Nawiąż połączenie z wystąpieniem obliczeniowym usługi Azure Machine Learning
- Lokalne debugowanie punktów końcowych online
- Wdrażanie wytrenowanych modeli.
Wystąpienie obliczeniowe usługi Azure Machine Learning
Wystąpienie obliczeniowe usługi Azure Machine Learning to bezpieczna, oparta na chmurze stacja robocza platformy Azure, która udostępnia analitykom danych serwer Jupyter Notebook, JupyterLab i w pełni zarządzane środowisko uczenia maszynowego.
Nie ma nic do zainstalowania ani skonfigurowania dla wystąpienia obliczeniowego.
Utwórz jeden w dowolnym momencie z poziomu obszaru roboczego usługi Azure Machine Learning. Podaj tylko nazwę i określ typ maszyny wirtualnej platformy Azure. Wypróbuj to teraz, klikając Utwórz zasoby, aby rozpocząć.
Aby dowiedzieć się więcej o wystąpieniach obliczeniowych, w tym o sposobie instalowania pakietów, zobacz Tworzenie wystąpienia obliczeniowego usługi Azure Machine Learning.
Napiwek
Aby zapobiec naliczaniu opłat za nieużywaną instancję obliczeniową, włącz wyłączanie w stanie bezczynności.
Oprócz serwera Jupyter Notebook i programu JupyterLab można używać wystąpień obliczeniowych w zintegrowanej funkcji notesu w usłudze Azure Machine Learning Studio.
Możesz również użyć rozszerzenia programu Visual Studio Code usługi Azure Machine Learning, aby nawiązać połączenie ze zdalnym wystąpieniem obliczeniowym przy użyciu programu VS Code.
Data Science Virtual Machine
Maszyna wirtualna do nauki o danych to spersonalizowany obraz maszyny wirtualnej, którego można użyć jako środowiska programistycznego. Jest przeznaczona do pracy związanej z nauką o danych, wyposażona w wstępnie skonfigurowane narzędzia i oprogramowanie takie jak:
- Pakiety, takie jak TensorFlow, PyTorch, Scikit-learn, XGBoost i Zestaw SDK usługi Azure Machine Learning
- Popularne narzędzia do nauki o danych, takie jak autonomiczna platforma Spark i przechodzenie do szczegółów
- Narzędzia Azure, takie jak Azure interfejs wiersza poleceń (CLI), AzCopy i Eksplorator przestrzeni dyskowej.
- Zintegrowane środowiska programistyczne (IDE), takie jak Visual Studio Code i PyCharm
- Serwer Notebooków Jupyter
Aby uzyskać bardziej kompleksową listę narzędzi, zobacz przewodnik po narzędziach wirtualnej maszyny do nauki o danych.
Ważne
Jeśli planujesz korzystać z maszyny wirtualnej Data Science jako celu obliczeniowego dla zadań trenowania lub wnioskowania, obsługiwana jest tylko Ubuntu.
Aby użyć maszyny wirtualnej Data Science jako środowisko programistyczne:
Utwórz maszynę wirtualną Data Science przy użyciu jednej z następujących metod:
Użyj witryny Azure Portal, aby utworzyć maszynę DSVM z systemem Ubuntu lub Windows .
Utwórz maszynę wirtualną do analizy danych przy użyciu szablonów ARM.
Użyj Azure CLI
Aby utworzyć maszynę wirtualną z systemem Ubuntu Nauka o danych, użyj następującego polecenia:
# create a Ubuntu Data Science VM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully # If you need to create a new resource group use: "az group create --name YOUR-RESOURCE-GROUP-NAME --location YOUR-REGION (For example: westus2)" az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:linux-data-science-vm-ubuntu:linuxdsvmubuntu:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --generate-ssh-keys --authentication-type passwordAby utworzyć maszynę DSVM z systemem Windows, użyj następującego polecenia:
# create a Windows Server 2016 DSVM in your resource group # note you need to be at least a contributor to the resource group in order to execute this command successfully az vm create --resource-group YOUR-RESOURCE-GROUP-NAME --name YOUR-VM-NAME --image microsoft-dsvm:dsvm-windows:server-2016:latest --admin-username YOUR-USERNAME --admin-password YOUR-PASSWORD --authentication-type password
Utwórz środowisko conda dla zestawu AZURE Machine Learning SDK:
conda create -n py310 python=310Po utworzeniu środowiska aktywuj go i zainstaluj zestaw SDK
conda activate py310 pip install azure-ai-ml azure-identityAby skonfigurować maszynę wirtualną Data Science do korzystania z obszaru roboczego usługi Azure Machine Learning, utwórz plik konfiguracji obszaru roboczego lub użyj istniejącego.
Napiwek
Podobnie jak w środowiskach lokalnych, można użyć programu Visual Studio Code i rozszerzenia programu Visual Studio Code usługi Azure Machine Learning do interakcji z usługą Azure Machine Learning.
Aby uzyskać więcej informacji, zobacz Wirtualne maszyny do nauki o danych.
Następne kroki
- Trenowanie i wdrażanie modelu w usłudze Azure Machine Learning przy użyciu zestawu danych MNIST.
- Zobacz dokumentację dotyczącą zestawu Azure Machine Learning SDK dla języka Python.