Tworzenie i uruchamianie potoków uczenia maszynowego przy użyciu składników w usłudze Azure Machine Learning Studio
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
W tym artykule dowiesz się, jak tworzyć i uruchamiać potoki uczenia maszynowego przy użyciu programu Azure Machine Learning Studio i składników. Potoki można tworzyć bez używania składników, ale składniki zapewniają większą elastyczność i ponowne użycie. Potoki usługi Azure Machine Learning można definiować w języku YAML i uruchamiać z interfejsu wiersza polecenia, utworzonego w języku Python lub komponowanego w projektancie usługi Azure Machine Learning Studio za pomocą interfejsu użytkownika przeciągania i upuszczania. Ten dokument koncentruje się na interfejsie użytkownika projektanta usługi Azure Machine Learning Studio.
Wymagania wstępne
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Obszar roboczy usługi Azure Machine Learning Tworzenie zasobów obszaru roboczego.
Sklonuj repozytorium przykładów:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Uwaga
Projektant obsługuje dwa typy składników, klasyczne wstępnie utworzone składniki (wersja 1) i składniki niestandardowe (wersja 2). Te dwa typy składników nie są zgodne.
Klasyczne wstępnie utworzone składniki zapewniają wstępnie utworzone składniki na potrzeby przetwarzania danych i tradycyjnych zadań uczenia maszynowego, takich jak regresja i klasyfikacja. Klasyczne wstępnie utworzone składniki nadal są obsługiwane, ale nie będą mieć dodanych nowych składników. Ponadto wdrożenie klasycznych wstępnie utworzonych składników (v1) nie obsługuje zarządzanych punktów końcowych online (wersja 2).
Składniki niestandardowe umożliwiają opakowywanie własnego kodu jako składnika. Obsługuje udostępnianie składników między obszarami roboczymi i bezproblemowe tworzenie między interfejsami studio, interfejsem wiersza polecenia w wersji 2 i zestawem SDK w wersji 2.
W przypadku nowych projektów zdecydowanie zalecamy użycie składnika niestandardowego, który jest zgodny z językiem AzureML w wersji 2 i będzie nadal otrzymywać nowe aktualizacje.
Ten artykuł dotyczy składników niestandardowych.
Rejestrowanie składnika w obszarze roboczym
Aby skompilować potok przy użyciu składników w interfejsie użytkownika, musisz najpierw zarejestrować składniki w obszarze roboczym. Możesz użyć interfejsu użytkownika, interfejsu wiersza polecenia lub zestawu SDK, aby zarejestrować składniki w obszarze roboczym, aby umożliwić udostępnianie i ponowne używanie składnika w obszarze roboczym. Zarejestrowane składniki obsługują automatyczne przechowywanie wersji, dzięki czemu można zaktualizować składnik, ale zapewnić, że potoki wymagające starszej wersji będą nadal działać.
W poniższym przykładzie użyto interfejsu użytkownika do rejestrowania składników, a pliki źródłowe składnikówazureml-examples znajdują się w cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components katalogu repozytorium. Najpierw sklonuj repozytorium do lokalnego.
- W obszarze roboczym usługi Azure Machine Learning przejdź do strony Składniki i wybierz pozycję Nowy składnik (zostanie wyświetlona jedna z dwóch stron stylu).


W tym przykładzie użyto train.yml w katalogu . Plik YAML definiuje nazwę, typ, interfejs, w tym dane wejściowe i wyjściowe, kod, środowisko i polecenie tego składnika. Kod tego składnika train.py znajduje się w ./train_src folderze, który opisuje logikę wykonywania tego składnika. Aby dowiedzieć się więcej na temat schematu składnika, zobacz dokumentację schematu YAML składnika polecenia.
Uwaga
Podczas rejestrowania składników w interfejsie użytkownika zdefiniowany w pliku YAML składnika może wskazywać tylko bieżący folder, code w którym znajduje się plik YAML lub podfoldery, co oznacza, że nie można określić ../ jako code interfejs użytkownika nie może rozpoznać katalogu nadrzędnego.
additional_includes może wskazywać tylko bieżący lub podrzędny folder.
Obecnie interfejs użytkownika obsługuje tylko rejestrowanie składników z command typem.
- Wybierz pozycję Przekaż z folderu i wybierz
1b_e2e_registered_componentsfolder do przekazania. Wybierztrain.ymlz listy rozwijanej.

Wybierz pozycję Dalej w dolnej części strony i możesz potwierdzić szczegóły tego składnika. Po potwierdzeniu wybierz pozycję Utwórz , aby zakończyć proces rejestracji.
Powtórz poprzednie kroki, aby zarejestrować składnik Score i Eval przy użyciu
score.ymlpolecenia ieval.yml.Po pomyślnym zarejestrowaniu trzech składników można zobaczyć składniki w interfejsie użytkownika programu Studio.

Tworzenie potoku przy użyciu zarejestrowanego składnika
Utwórz nowy potok w projektancie. Pamiętaj, aby wybrać opcję Niestandardowe .
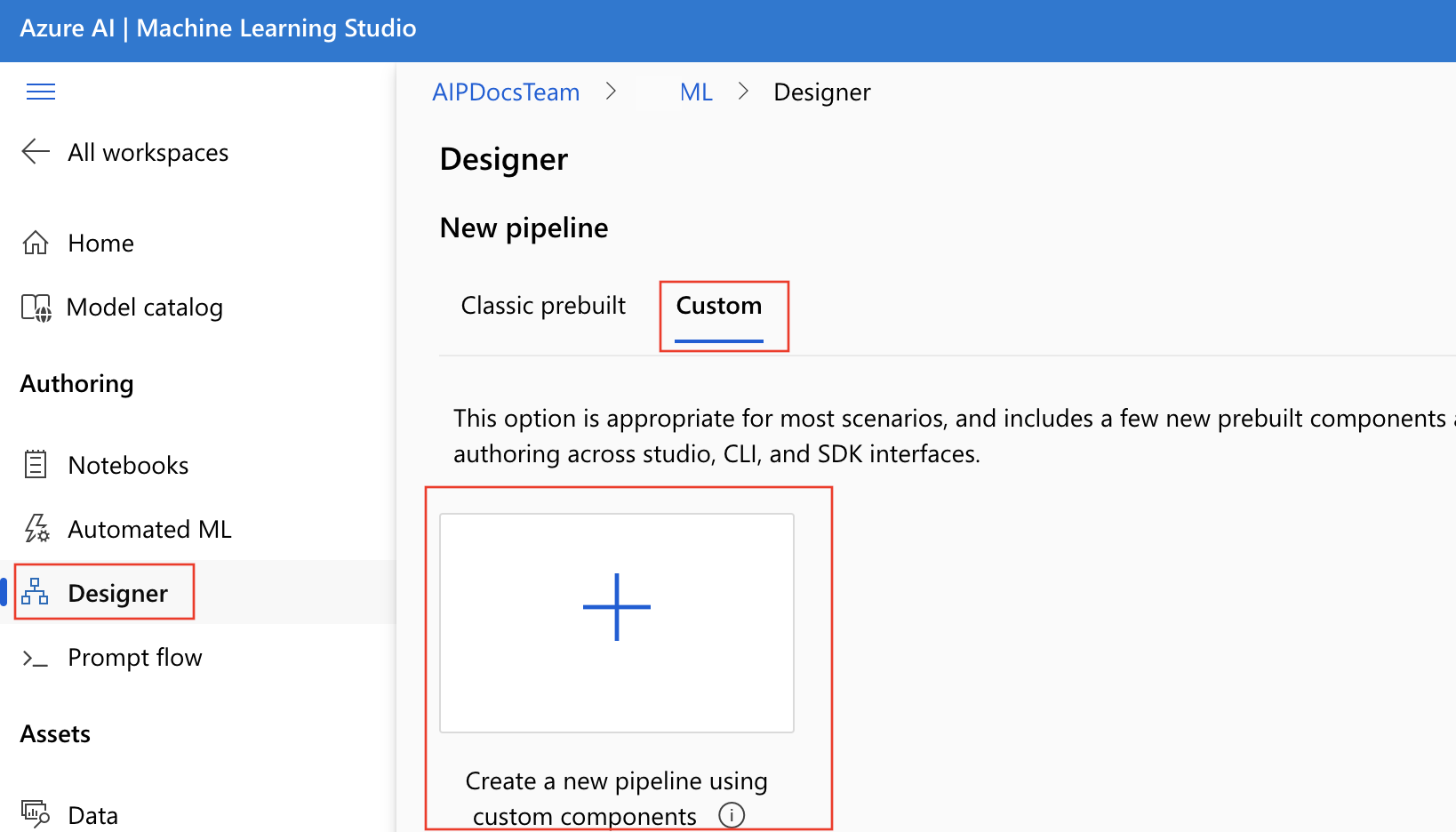
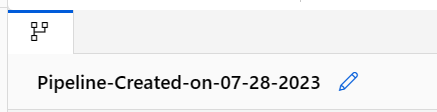
Nadaj potokowi znaczącą nazwę, wybierając ikonę ołówka oprócz nazwy wygenerowanej automatycznie.
W bibliotece zasobów projektanta można wyświetlić karty Dane, Model i Składniki . Przejdź do karty Składniki , aby wyświetlić składniki zarejestrowane w poprzedniej sekcji. Jeśli istnieje zbyt wiele składników, możesz wyszukać nazwę składnika.
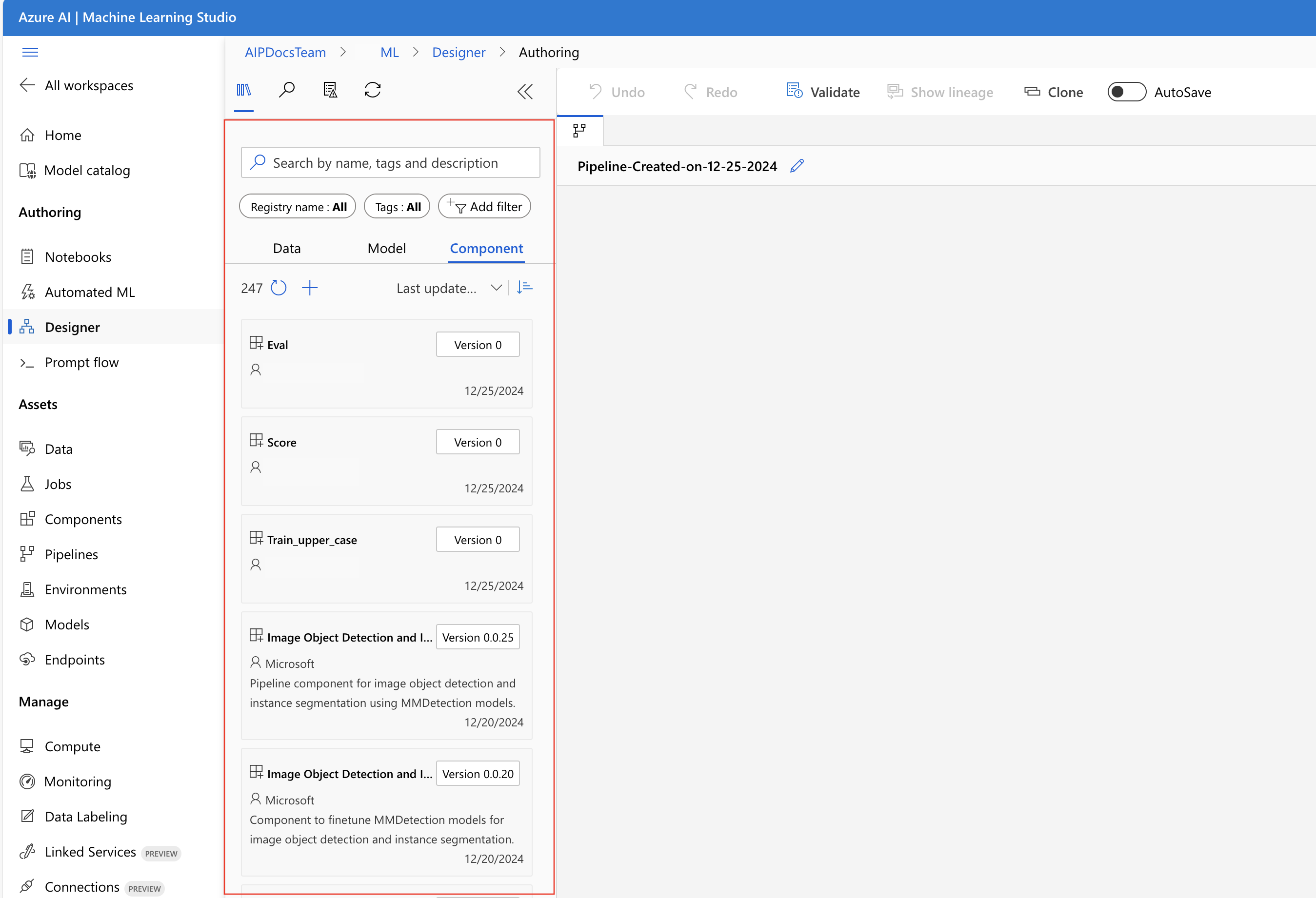
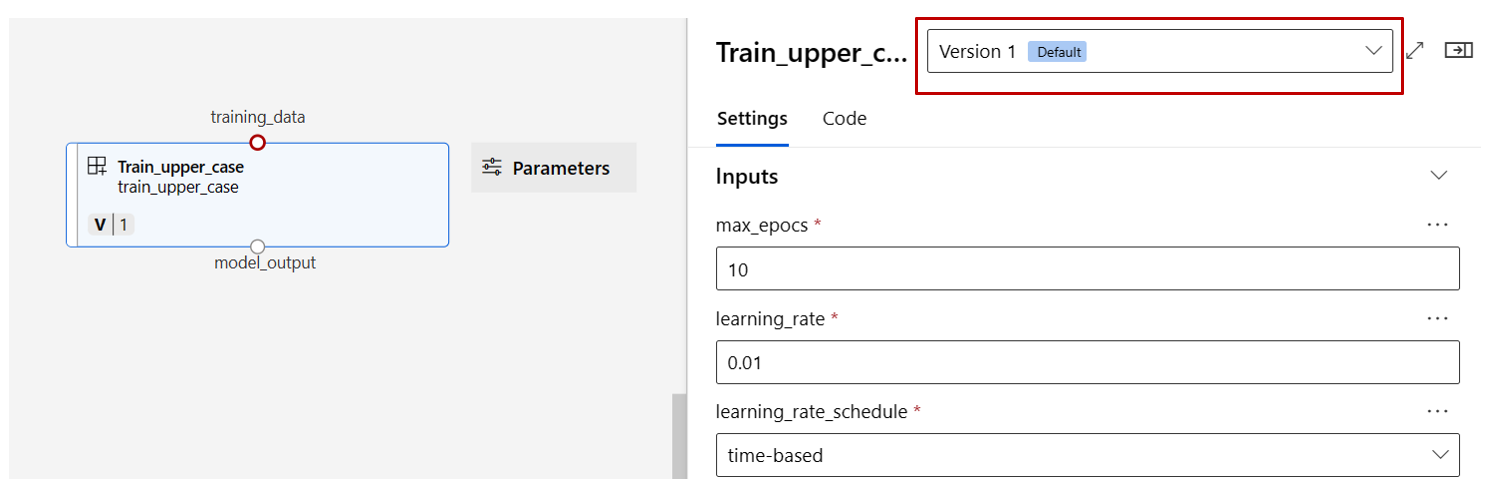
Znajdź składniki pociągu, oceny i oceny zarejestrowane w poprzedniej sekcji, a następnie przeciągnij je i upuść na kanwie. Domyślnie używa on domyślnej wersji składnika i można zmienić ją na określoną wersję w okienku po prawej stronie składnika. Okienko po prawej stronie składnika jest wywoływane przez dwukrotne kliknięcie składnika.
W tym przykładzie użyjemy przykładowych danych w tej ścieżce. Zarejestruj dane w obszarze roboczym, wybierając ikonę dodawania w bibliotece zasobów projektanta —> kartę dane, ustaw pozycję Typ = Folder(uri_folder), a następnie postępuj zgodnie z instrukcjami kreatora, aby zarejestrować dane. Typ danych musi być uri_folder, aby dopasować go do definicji składnika trenowania.

Następnie przeciągnij i upuść dane na kanwę. Wygląd potoku powinien wyglądać podobnie do poniższego zrzutu ekranu.
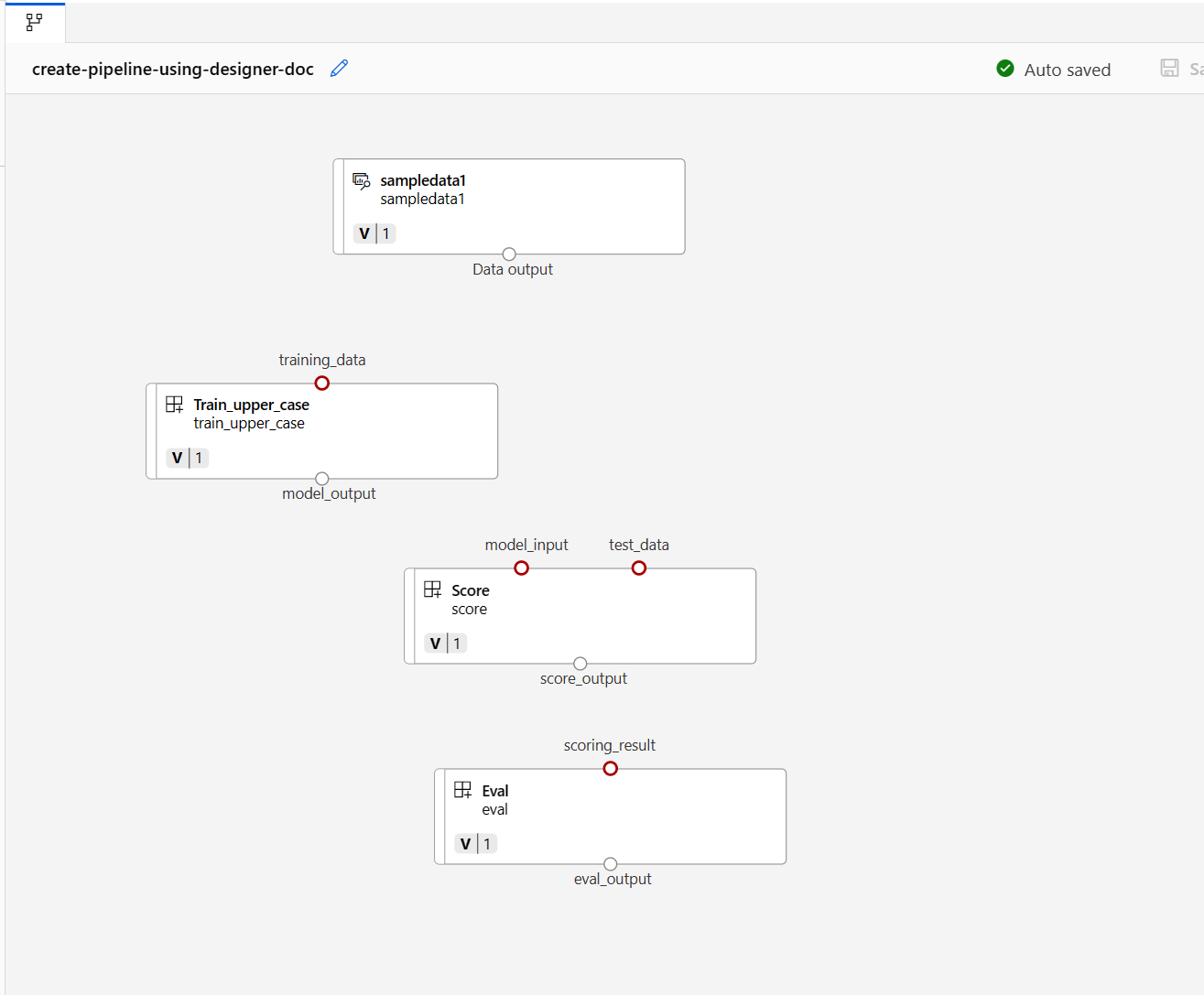
Połącz dane i składniki, przeciągając połączenia na kanwie.
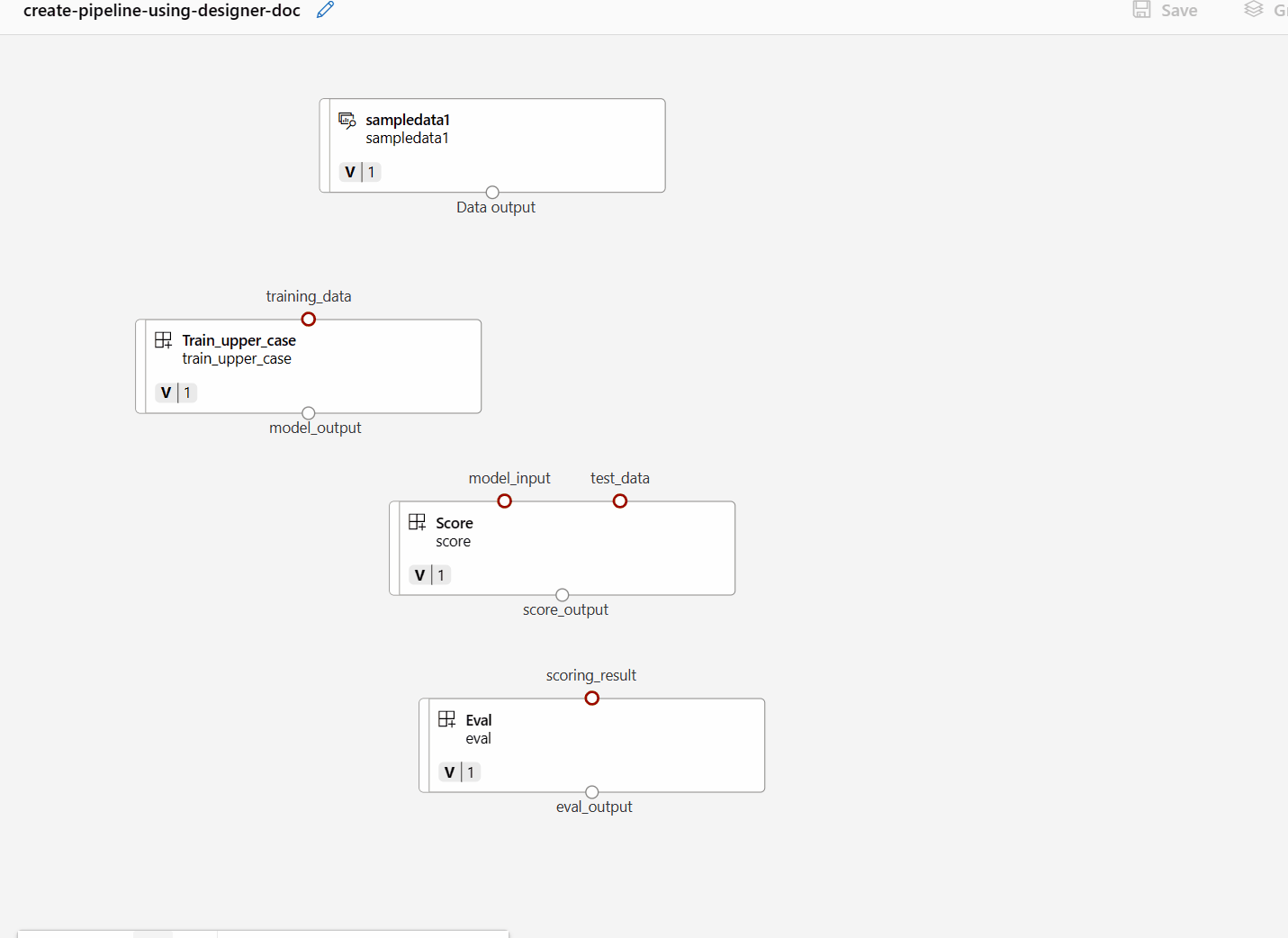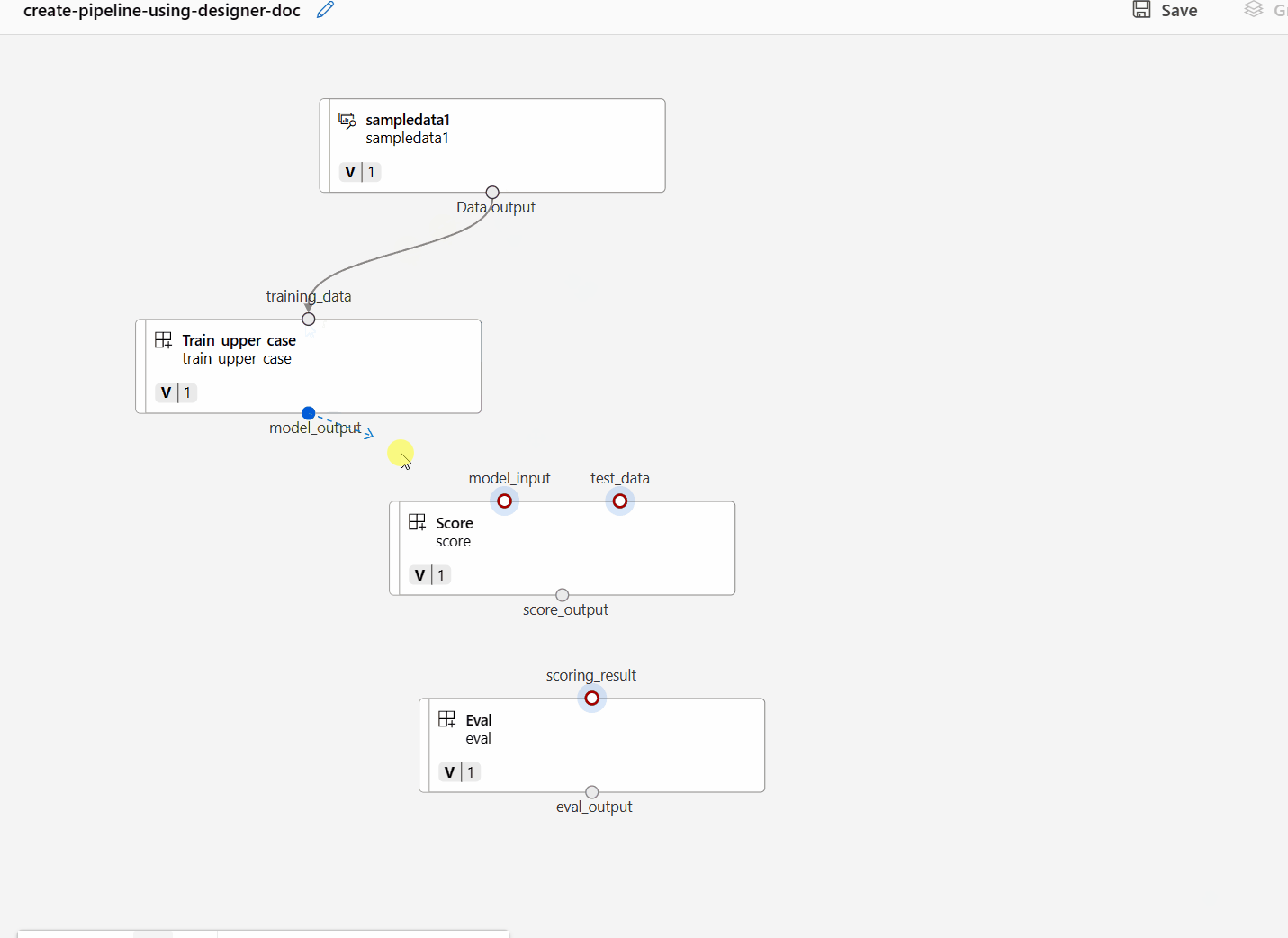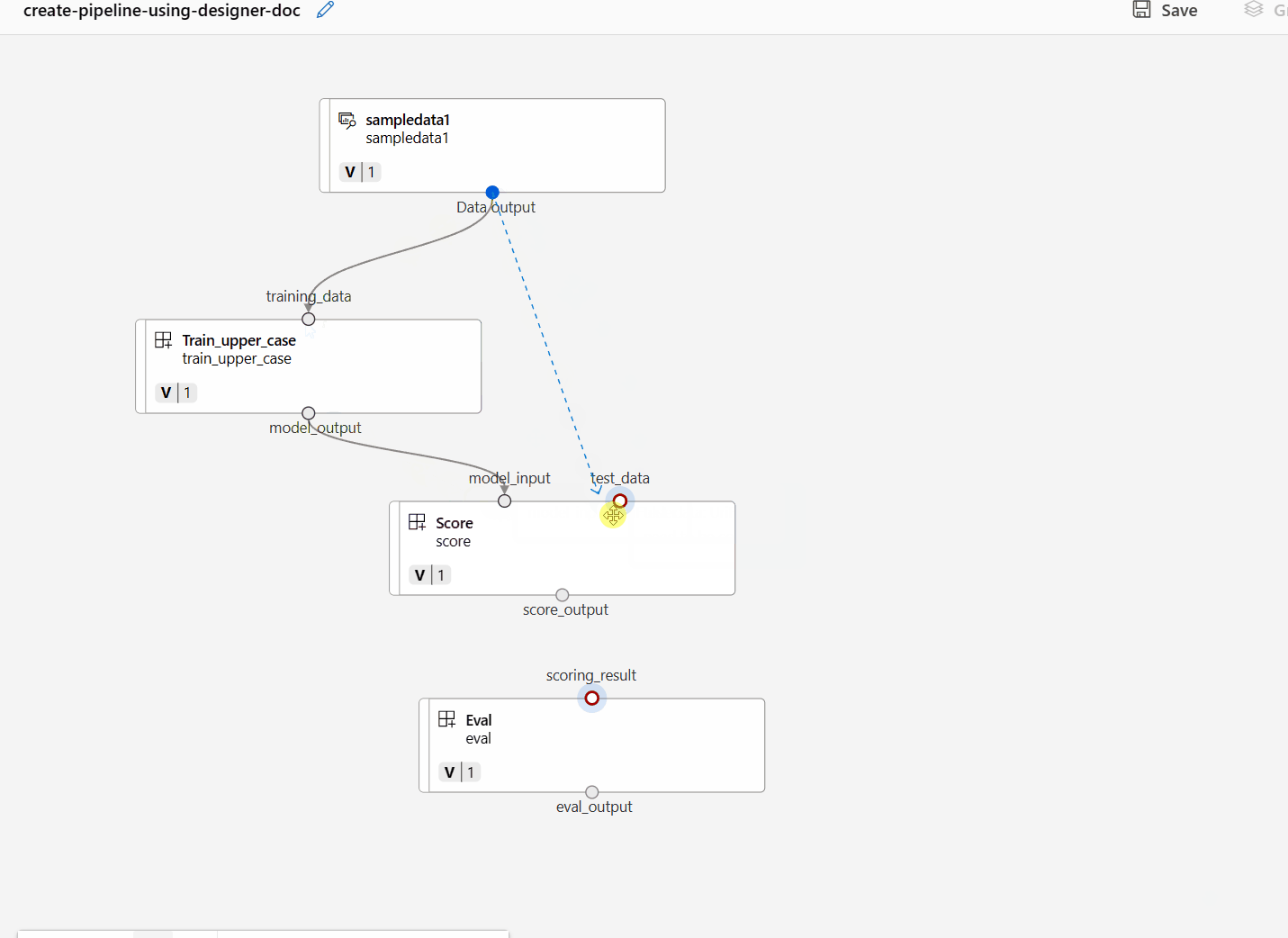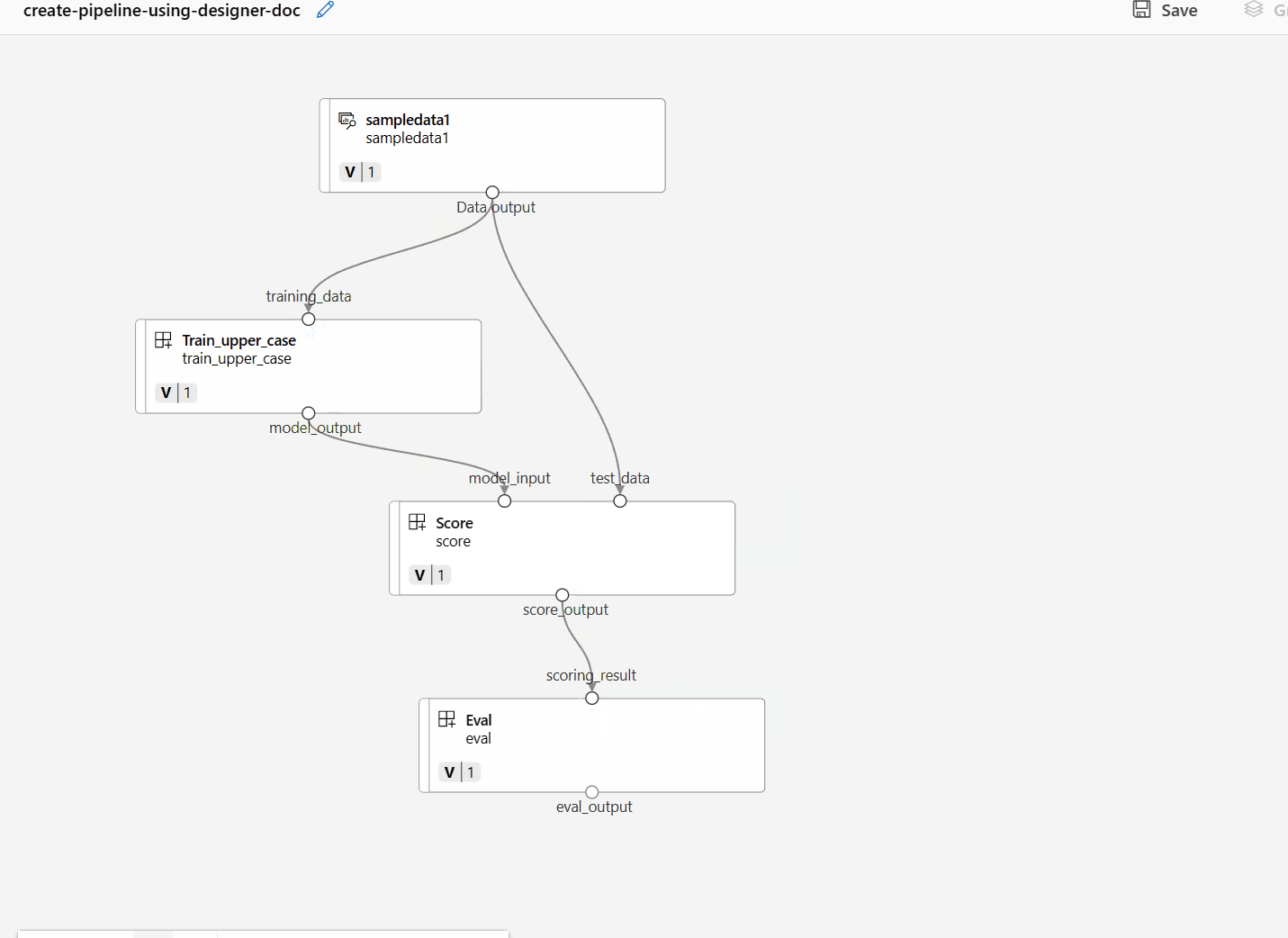
Kliknij dwukrotnie jeden składnik. Zostanie wyświetlone okienko po prawej stronie, w którym można skonfigurować składnik.
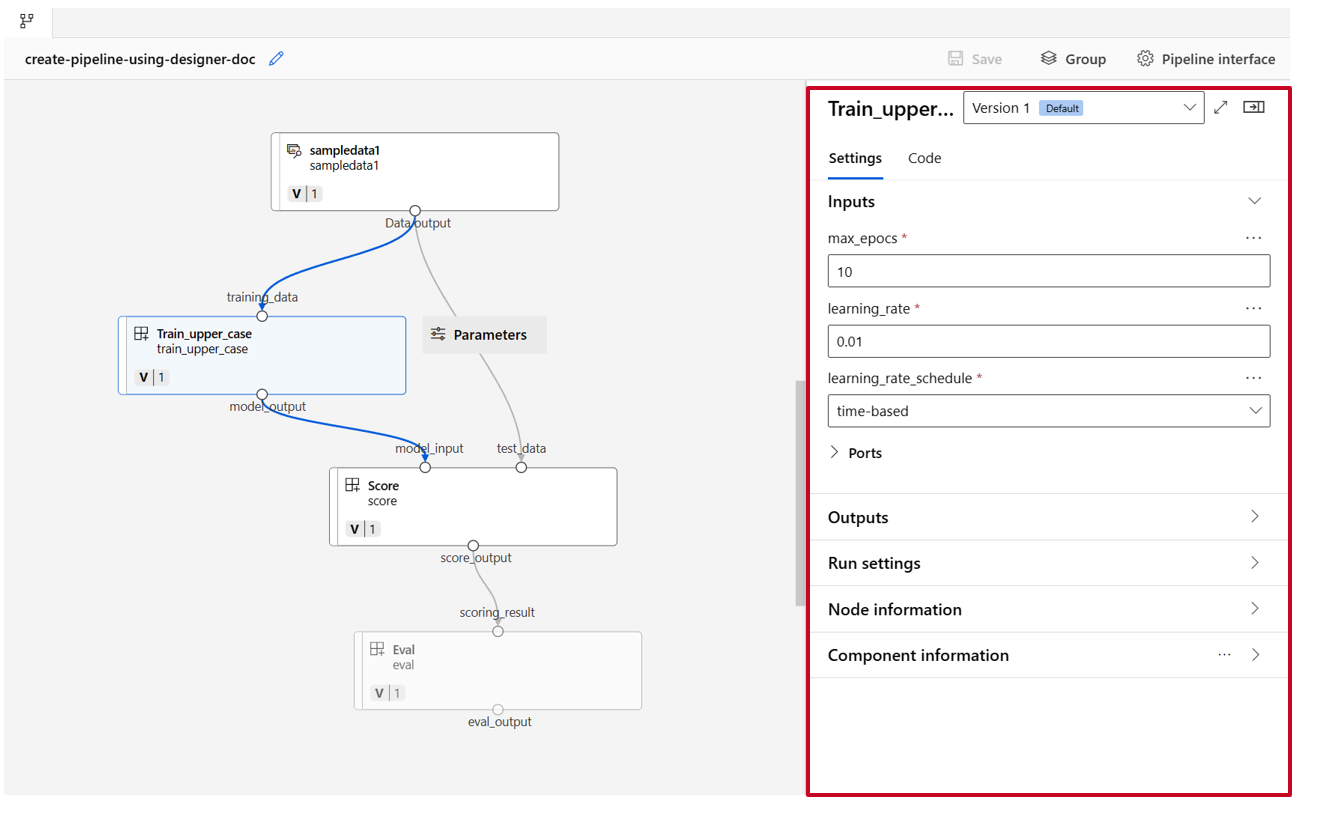
W przypadku składników z danymi wejściowymi typu pierwotnego, takimi jak liczba, liczba całkowita, ciąg i wartość logiczna, można zmienić wartości takich danych wejściowych w okienku szczegółowym składnika w sekcji Dane wejściowe .
Możesz również zmienić ustawienia danych wyjściowych (gdzie przechowywać dane wyjściowe składnika) i ustawienia uruchamiania (docelowy obiekt obliczeniowy, aby uruchomić ten składnik) w okienku po prawej stronie.
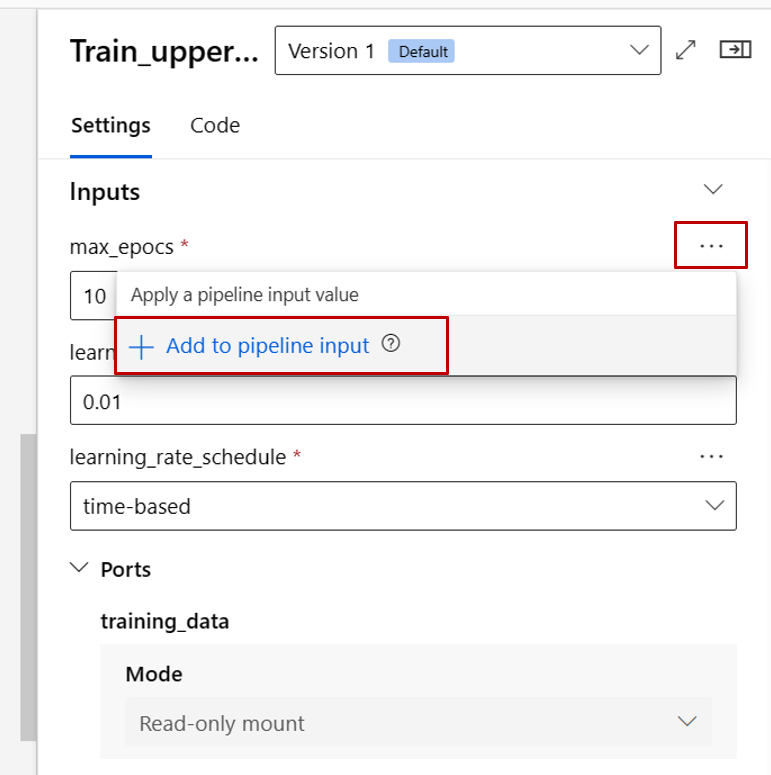
Teraz podwyższamy poziom max_epocs danych wejściowych składnika trenowania do danych wejściowych na poziomie potoku. Dzięki temu można przypisać inną wartość do tych danych wejściowych za każdym razem przed przesłaniem potoku.









Uwaga
Składników niestandardowych i klasycznych wstępnie utworzonych składników projektanta nie można używać razem.
Przesyłanie potoku
Wybierz pozycję Konfiguruj i prześlij w prawym górnym rogu, aby przesłać potok.

Następnie zobaczysz kreatora krok po kroku, postępuj zgodnie z instrukcjami kreatora, aby przesłać zadanie potoku.

W kroku Podstawy można skonfigurować eksperyment, nazwę wyświetlaną zadania, opis zadania itp.
W kroku Dane wejściowe i wyjściowe można skonfigurować dane wejściowe/wyjściowe , które są promowane do poziomu potoku. W poprzednim kroku promowaliśmy max_epocs składnika pociągu do danych wejściowych potoku, więc powinno być możliwe wyświetlenie i przypisanie wartości do max_epocs tutaj.
W obszarze Ustawienia środowiska uruchomieniowego można skonfigurować domyślny magazyn danych i domyślne obliczenia potoku. Jest to domyślny magazyn danych/obliczenia dla wszystkich składników potoku. Należy jednak pamiętać, że w przypadku jawnego ustawienia innego zasobu obliczeniowego lub magazynu danych dla składnika system uwzględnia ustawienie poziomu składnika. W przeciwnym razie używa wartości domyślnej potoku.
Krok Przeglądanie i przesyłanie to ostatni krok umożliwiający przejrzenie wszystkich konfiguracji przed przesłaniem. Kreator zapamiętuje konfigurację ostatniego czasu, jeśli kiedykolwiek prześlesz potok.
Po przesłaniu zadania potoku w górnej części zostanie wyświetlony komunikat z linkiem do szczegółów zadania. Możesz wybrać ten link, aby przejrzeć szczegóły zadania.

Określanie tożsamości w zadaniu potoku
Podczas przesyłania zadania potoku można określić tożsamość, aby uzyskać dostęp do danych w obszarze Run settings. Tożsamość domyślna to AMLToken , która w międzyczasie nie korzystała z żadnej tożsamości, obsługujemy elementy i UserIdentity Managed. W przypadku UserIdentityprogramu tożsamość przesyłająca zadanie jest używana do uzyskiwania dostępu do danych wejściowych i zapisywania wyniku w folderze wyjściowym. Jeśli określisz Managedwartość , system użyje tożsamości zarządzanej, aby uzyskać dostęp do danych wejściowych i zapisać wynik w folderze wyjściowym.

Następne kroki
- Użyj tych notesów Jupyter w usłudze GitHub , aby dokładniej eksplorować potoki uczenia maszynowego
- Dowiedz się , jak używać interfejsu wiersza polecenia w wersji 2 do tworzenia potoku przy użyciu składników.
- Dowiedz się , jak używać zestawu SDK w wersji 2 do tworzenia potoku przy użyciu składników