Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
APPLIES TO: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
W usłudze Azure Machine Learning można użyć niestandardowego kontenera do wdrożenia modelu w punkcie końcowym online. Niestandardowe wdrożenia kontenerów mogą używać serwerów internetowych innych niż domyślny serwer platformy Python Flask używany przez usługę Azure Machine Learning.
W przypadku korzystania z wdrożenia niestandardowego można wykonywać następujące czynności:
- Użyj różnych narzędzi i technologii, takich jak TensorFlow Serving (TF Serving), TorchServe, Triton Inference Server, pakiet Plumber R i minimalny obraz wnioskowania usługi Azure Machine Learning.
- Nadal korzystaj z wbudowanego monitorowania, skalowania, alertów i uwierzytelniania, które oferuje usługa Azure Machine Learning.
W tym artykule pokazano, jak użyć obrazu TF Serving do obsługi modelu TensorFlow.
Prerequisites
Obszar roboczy usługi Azure Machine Learning. Aby uzyskać instrukcje dotyczące tworzenia przestrzeni roboczej, zobacz Create the workspace.
Azure CLI i rozszerzenie
mllub Azure Machine Learning Python SDK v2:Aby zainstalować Azure CLI oraz rozszerzenie
ml, zobacz Zainstaluj i skonfiguruj CLI (v2).Przykłady w tym artykule zakładają, że używasz powłoki Bash lub innej kompatybilnej powłoki. Na przykład możesz użyć powłoki w systemie Linux lub Windows Subsystem for Linux.
Grupa zasobów platformy Azure, zawierająca obszar roboczy, do której ty lub twój główny podmiot usługi macie dostęp jako współautorzy. Jeśli wykonasz kroki opisane w sekcji Tworzenie obszaru roboczego w celu skonfigurowania obszaru roboczego , spełniasz to wymaganie.
Docker Engine, installed and running locally. This prerequisite is highly recommended. Potrzebujesz tego, aby wdrożyć model lokalnie, oraz jest to pomocne do debugowania.
Deployment examples
The following table lists deployment examples that use custom containers and take advantage of various tools and technologies.
| Example | Skrypt Azure CLI | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Wdraża wiele modeli w jednym wdrożeniu, rozszerzając minimalny obraz wnioskowania usługi Azure Machine Learning. |
| minimal/single-model | deploy-custom-container-minimal-single-model | Wdraża pojedynczy model, rozszerzając minimalny obraz wnioskowania usługi Azure Machine Learning. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Wdraża dwa modele MLFlow z różnymi wymaganiami dotyczącymi języka Python do dwóch oddzielnych wdrożeń, obsługiwanych przez jeden wspólny punkt końcowy. Używa minimalnego obrazu wnioskowania usługi Azure Machine Learning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Wdraża trzy modele regresji w jednym punkcie końcowym. Używa pakietu Plumber R. |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Wdraża model Half Plus Two przy użyciu kontenera niestandardowego obsługującego serwer TF. Używa standardowego procesu rejestracji modelu. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Wdraża model Half Plus Two, korzystając z niestandardowego kontenera TF Serving z modelem zintegrowanym w obrazie. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Wdraża pojedynczy model przy użyciu niestandardowego kontenera TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Wdraża model Triton przy użyciu kontenera niestandardowego. |
W tym artykule pokazano, jak użyć przykładu tfserving/half-plus-two.
Warning
Zespoły wsparcia Microsoftu mogą nie być w stanie rozwiązać problemów spowodowanych przez obraz niestandardowy. Jeśli wystąpią problemy, może zostać wyświetlony monit o użycie obrazu domyślnego lub jednego z obrazów, które firma Microsoft udostępnia, aby sprawdzić, czy problem jest specyficzny dla twojego obrazu.
Pobieranie kodu źródłowego
The steps in this article use code samples from the azureml-examples repository. Użyj następujących poleceń, aby sklonować repozytorium:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Inicjowanie zmiennych środowiskowych
Aby użyć modelu TensorFlow, potrzebujesz kilku zmiennych środowiskowych. Uruchom następujące polecenia, aby zdefiniować te zmienne:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Pobieranie modelu TensorFlow
Pobierz i rozpakuj model, który dzieli wartość wejściową na dwa i dodaje dwa do wyniku:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Testuj obraz serwera TF lokalnie
Użyj platformy Docker, aby uruchomić obraz lokalnie na potrzeby testowania:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Wysyłaj żądania sprawdzania żywotności i oceny do obrazu
Wyślij żądanie aktualności, aby sprawdzić, czy proces wewnątrz kontenera jest uruchomiony. Powinien zostać wyświetlony kod stanu odpowiedzi 200 OK.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Wyślij żądanie oceniania, aby sprawdzić, czy można uzyskać przewidywania dotyczące danych bez etykiet:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Zatrzymywanie obrazu
Po zakończeniu testowania lokalnego zatrzymaj obraz:
docker stop tfserving-test
Wdrażanie punktu końcowego online na platformie Azure
Aby wdrożyć punkt końcowy online na platformie Azure, wykonaj kroki opisane w poniższych sekcjach.
Utwórz pliki YAML dla punktu końcowego i wdrożenia
Wdrożenie w chmurze można skonfigurować przy użyciu języka YAML. Na przykład w celu skonfigurowania punktu końcowego można utworzyć plik YAML o nazwie tfserving-endpoint.yml zawierający następujące wiersze:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
Aby skonfigurować wdrożenie, możesz utworzyć plik YAML o nazwie tfserving-deployment.yml zawierający następujące wiersze:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
W poniższych sekcjach omówiono ważne pojęcia dotyczące parametrów YAML i Python.
Base image
W sekcji environment w YAML lub w konstruktorze Environment w Pythonie określasz podstawowy obraz jako parametr. W tym przykładzie użyto docker.io/tensorflow/serving:latest jako wartości image.
Jeśli sprawdzisz kontener, zobaczysz, że ten serwer używa ENTRYPOINT poleceń do uruchomienia skryptu punktu wejścia. Ten skrypt przyjmuje zmienne środowiskowe, takie jak MODEL_BASE_PATH i MODEL_NAME, i uwidacznia porty, takie jak 8501. Wszystkie te szczegóły dotyczą tego serwera i można użyć tych informacji, aby określić sposób definiowania wdrożenia. Jeśli na przykład ustawisz MODEL_BASE_PATH zmienne środowiskowe i MODEL_NAME w definicji wdrożenia, funkcja TF Serving używa tych wartości do zainicjowania serwera. Podobnie, jeśli ustawisz port dla każdej trasy do 8501 w definicji wdrożenia, żądania użytkowników do tych tras są prawidłowo kierowane do serwera obsługującego tf.
Ten przykład jest oparty na przypadku obsługi serwera TF. Można jednak użyć dowolnego kontenera, który jest aktywny i odpowiada na żądania dotyczące tras sprawdzania aktywności, gotowości i oceniania. Aby dowiedzieć się, jak utworzyć Dockerfile w celu stworzenia kontenera, możesz zapoznać się z innymi przykładami. Niektóre serwery używają CMD instrukcji zamiast ENTRYPOINT instrukcji.
Parametr inference_config
environment jest parametrem w sekcji Environment lub w klasie inference_config. Określa port i ścieżkę dla trzech typów tras: trasy żywotności, gotowości i oceny. Parametr inference_config jest wymagany, jeśli chcesz uruchomić własny kontener z zarządzanym punktem końcowym online.
Trasy sprawności a trasy działania
Niektóre serwery interfejsu API umożliwiają sprawdzenie stanu serwera. Istnieją dwa typy tras, które można określić do sprawdzania stanu:
- Liveness routes: To check whether a server is running, you use a liveness route.
- Readiness routes: To check whether a server is ready to do work, you use a readiness route.
W kontekście wnioskowania uczenia maszynowego serwer może przed załadowaniem modelu odpowiedzieć na żądanie żywotności kodem stanu 200 OK. Serwer może odpowiedzieć kodem stanu 200 OK do żądania gotowości dopiero po załadowaniu modelu do pamięci.
Więcej informacji na temat sond działania i gotowości można znaleźć w sekcji Konfigurowanie sond działania, gotowości i uruchamiania (Configure Liveness, Readiness and Startup Probes).
Serwer interfejsu API, który wybierzesz, określa trasy aktywności i gotowości. Serwer można zidentyfikować we wcześniejszym kroku podczas lokalnego testowania kontenera. W tym artykule przykładowe wdrożenie używa tej samej ścieżki dla tras żywotności i przygotowania, ponieważ TF Serving definiuje tylko trasę żywotności. Inne sposoby definiowania tras można znaleźć w innych przykładach.
Scoring routes
Używany serwer interfejsu API umożliwia odbieranie ładunku do pracy. W kontekście wnioskowania uczenia maszynowego serwer odbiera dane wejściowe za pośrednictwem określonej trasy. Zidentyfikuj tę trasę dla serwera interfejsu API podczas lokalnego testowania kontenera we wcześniejszym kroku. Określ tę trasę jako trasę oceniającą, gdy określasz wdrożenie, które należy utworzyć.
Pomyślne utworzenie wdrożenia spowoduje również zaktualizowanie scoring_uri parametru punktu końcowego. Ten fakt można zweryfikować, uruchamiając następujące polecenie: az ml online-endpoint show -n <endpoint-name> --query scoring_uri.
Lokalizowanie zainstalowanego modelu
When you deploy a model as an online endpoint, Azure Machine Learning mounts your model to your endpoint. Po zainstalowaniu modelu można wdrożyć nowe wersje modelu bez konieczności tworzenia nowego obrazu platformy Docker. By default, a model registered with the name my-model and version 1 is located on the following path inside your deployed container: /var/azureml-app/azureml-models/my-model/1.
Rozważmy na przykład następującą konfigurację:
- Struktura folderów na komputerze lokalnym /azureml-examples/cli/endpoints/online/custom-container
- Nazwa modelu
half_plus_two
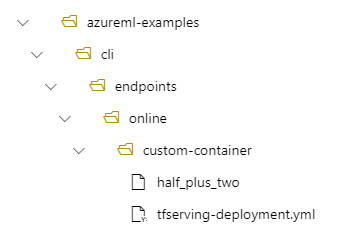
Załóżmy, że plik tfserving-deployment.yml zawiera następujące wiersze w sekcji model . W tej sekcji name wartość odnosi się do nazwy używanej do rejestrowania modelu w usłudze Azure Machine Learning.
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
W takim przypadku podczas tworzenia wdrożenia model znajduje się w następującym folderze: /var/azureml-app/azureml-models/tfserving-mounted/1.
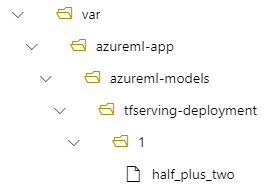
Możesz skonfigurować opcjonalnie wartość model_mount_path. Dostosowując to ustawienie, możesz zmienić ścieżkę, w której jest zainstalowany model.
Important
Wartość model_mount_path musi być prawidłową ścieżką bezwzględną w systemie Linux (w systemie operacyjnym gościa obrazu kontenera).
Important
model_mount_path jest używany tylko w scenariuszu BYOC (Bring your own container). W scenariuszu byOC środowisko używane przez wdrożenie online musi mieć inference_config skonfigurowany parametr . Przy użyciu interfejsu wiersza polecenia usługi Azure ML lub zestawu SDK języka Python można określić inference_config parametr podczas tworzenia środowiska. Interfejs użytkownika programu Studio obecnie nie obsługuje określania tego parametru.
Po zmianie wartości parametru model_mount_pathnależy również zaktualizować zmienną MODEL_BASE_PATH środowiskową. Aby uniknąć nieudanego wdrożenia z powodu błędu dotyczącego nieznalezienia ścieżki bazowej, ustaw MODEL_BASE_PATH na tę samą wartość co model_mount_path.
Możesz na przykład dodać model_mount_path parametr do pliku tfserving-deployment.yml. Możesz również zaktualizować wartość MODEL_BASE_PATH w tym pliku.
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
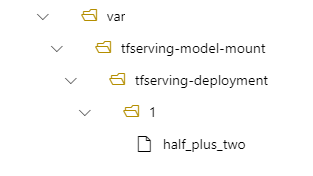
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
W ramach wdrożenia model znajduje się w lokalizacji /var/tfserving-model-mount/tfserving-mounted/1. Nie jest już w obszarze azureml-app/azureml-models, ale w określonej ścieżce instalacji:
Tworzenie punktu końcowego i wdrożenia
Po utworzeniu pliku YAML użyj następującego polecenia, aby utworzyć punkt końcowy:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
Użyj następującego polecenia, aby utworzyć wdrożenie. Ten krok może potrwać kilka minut.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
Wywoływanie punktu końcowego
Po zakończeniu wdrażania utwórz żądanie oceniania do wdrożonego punktu końcowego.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Usuwanie punktu końcowego
Jeśli punkt końcowy nie jest już potrzebny, uruchom następujące polecenie, aby go usunąć:
az ml online-endpoint delete --name tfserving-endpoint