Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
W tym artykule przedstawiono sposób wdrażania nowej wersji modelu uczenia maszynowego w środowisku produkcyjnym bez powodowania zakłóceń. W celu wprowadzenia nowej wersji usługi internetowej do środowiska produkcyjnego należy zastosować strategię wdrożenia niebiesko-zielonego, która jest również znana jako strategia bezpiecznego wdrażania. W przypadku korzystania z tej strategii możesz wdrożyć nową wersję usługi internetowej w małym podzestawie użytkowników lub żądań przed całkowitym wdrożeniem tej wersji.
W tym artykule założono, że używasz punktów końcowych online lub punktów końcowych używanych do wnioskowania online (w czasie rzeczywistym). Istnieją dwa typy punktów końcowych online: zarządzane punkty końcowe online i punkty końcowe online platformy Kubernetes. Aby uzyskać więcej informacji na temat punktów końcowych i różnic między typami punktów końcowych, zobacz Zarządzane punkty końcowe online a punkty końcowe online platformy Kubernetes.
W tym artykule do wdrożenia są używane zarządzane punkty końcowe online. Zawiera również uwagi, które wyjaśniają sposób używania punktów końcowych platformy Kubernetes zamiast zarządzanych punktów końcowych online.
W tym artykule przedstawiono, jak wykonać następujące działania:
- Zdefiniuj punkt końcowy online przy użyciu wdrożenia o nazwie
blue, aby obsłużyć pierwszą wersję modelu. - Skaluj wdrożenie
blue, aby mogło obsługiwać więcej żądań. - Wdróż drugą wersję modelu, która jest nazywana
greenwdrożeniem, do punktu końcowego, ale wyślij wdrożenie bez ruchu na żywo. - Przetestuj
greenwdrożenie w izolacji. - Przekieruj procent ruchu na żywo do wdrożenia
green, aby go zweryfikować. - Wyślij niewielki procent ruchu na żywo do wdrożenia
green. - Wyślij cały ruch w czasie rzeczywistym do
greenwdrożenia. - Usuń nieużywane
bluewdrożenie.
Wymagania wstępne
Interfejs wiersza polecenia platformy Azure i
mlrozszerzenie interfejsu wiersza polecenia platformy Azure, zainstalowane i skonfigurowane. Aby uzyskać więcej informacji, zobacz Instalowanie i konfigurowanie interfejsu wiersza polecenia (wersja 2).Powłoka Bash lub zgodna powłoka, taka jak powłoka w systemie Linux lub Podsystem Windows dla systemu Linux. Przykłady Azure CLI w tym artykule przyjmują, że używasz tego typu powłoki.
Obszar roboczy usługi Azure Machine Learning. Aby uzyskać instrukcje dotyczące tworzenia obszaru roboczego, zobacz Konfigurowanie.
Konto użytkownika, które ma co najmniej jedną z następujących ról kontroli dostępu na podstawie ról (RBAC) platformy Azure:
- Rola właściciela obszaru roboczego usługi Azure Machine Learning
- Rola Współautor dla obszaru roboczego usługi Azure Machine Learning
- Rola niestandardowa, która ma
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*uprawnienia
Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszarów roboczych usługi Azure Machine Learning.
Opcjonalnie silnik Docker, zainstalowany i działający lokalnie. To wymaganie wstępne jest zdecydowanie zalecane. Potrzebujesz tego do wdrożenia modelu lokalnie i jest to przydatne do debugowania.
Przygotowywanie systemu
Ustawianie zmiennych środowiskowych
Możesz skonfigurować wartości domyślne do użycia z interfejsem wiersza polecenia platformy Azure. Aby uniknąć wielokrotnego przekazywania wartości dla subskrypcji, obszaru roboczego i grupy zasobów, uruchom następujący kod:
az account set --subscription <subscription-ID>
az configure --defaults workspace=<Azure-Machine-Learning-workspace-name> group=<resource-group-name>
Klonowanie repozytorium przykładów
Aby skorzystać z tego artykułu, najpierw sklonuj repozytorium przykładów (azureml-examples). Następnie przejdź do katalogu repozytorium cli/ :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Napiwek
Użyj --depth 1 polecenia, aby sklonować tylko najnowszy commit do repozytorium, co skraca czas potrzebny na wykonanie operacji.
Polecenia w tym samouczku znajdują się w pliku deploy-safe-rollout-online-endpoints.sh w katalogu interfejsu wiersza polecenia, a pliki konfiguracji YAML znajdują się w podkatalogu endpoints/online/managed/sample/.
Uwaga
Pliki konfiguracji YAML dla punktów końcowych online platformy Kubernetes znajdują się w podkatalogu endpoints/online/kubernetes.
Definiowanie punktu końcowego i wdrożenia
Punkty końcowe online są używane do wnioskowania w trybie online (w czasie rzeczywistym). Punkty końcowe online zawierają wdrożenia, które są gotowe do odbierania danych od klientów i wysyłają odpowiedzi z powrotem w czasie rzeczywistym.
Definiowanie punktu końcowego
W poniższej tabeli wymieniono atrybuty klucza do określenia podczas definiowania punktu końcowego.
| Atrybut | Wymagane lub opcjonalne | Opis |
|---|---|---|
| Nazwa/nazwisko | Wymagane | Nazwa punktu końcowego. Musi być unikatowa w swoim regionie świadczenia usługi Azure. Aby uzyskać więcej informacji na temat reguł nazewnictwa, zobacz Punkty końcowe online usługi Azure Machine Learning i punkty końcowe wsadowe. |
| Tryb uwierzytelniania | Opcjonalnie | Metoda uwierzytelniania punktu końcowego. Możesz wybrać uwierzytelnianie oparte na kluczach oraz keyuwierzytelnianie oparte na tokenach usługi Azure Machine Learning. aml_token Klucz nie wygasa, ale token wygasa. Aby uzyskać więcej informacji na temat uwierzytelniania, zobacz Uwierzytelnianie klientów dla punktów końcowych online. |
| Opis | Opcjonalnie | Opis punktu końcowego. |
| Tagi | Opcjonalnie | Słownik tagów dla punktu końcowego. |
| Ruch | Opcjonalnie | Reguły dotyczące kierowania ruchu między wdrożeniami. Ruch jest reprezentowany jako słownik par klucz-wartość, gdzie klucz reprezentuje nazwę wdrożenia, a wartość reprezentuje procent ruchu do tego wdrożenia. Można ustawić ruch dopiero po utworzeniu wdrożeń w ramach punktu końcowego. Możesz również zaktualizować ruch dla internetowego punktu końcowego po utworzeniu wdrożeń. Aby uzyskać więcej informacji na temat korzystania z dublowanego ruchu, zobacz Przydziel niewielki procent ruchu na żywo do nowego wdrożenia. |
| Ruch dublowania | Opcjonalnie | Procent ruchu na żywo do odwzorowania w ramach wdrożenia. Aby uzyskać więcej informacji na temat korzystania z dublowanego ruchu, zobacz Testowanie wdrożenia przy użyciu ruchu dublowanego. |
Aby wyświetlić pełną listę atrybutów, które można określić podczas tworzenia punktu końcowego; zapoznaj się ze schematem YAML online punku końcowego w CLI (wersja 2). Aby uzyskać wersję 2 zestawu Azure Machine Learning SDK dla języka Python, zobacz ManagedOnlineEndpoint Class (Klasa ManagedOnlineEndpoint).
Definiowanie wdrożenia
Wdrożenie to zestaw zasobów wymaganych do hostowania modelu, który wykonuje rzeczywiste wnioskowanie. W poniższej tabeli opisano kluczowe atrybuty, które należy określić podczas definiowania wdrożenia.
| Atrybut | Wymagane lub opcjonalne | Opis |
|---|---|---|
| Nazwa/nazwisko | Wymagane | Nazwa wdrożenia. |
| Nazwa punktu końcowego | Wymagane | Nazwa punktu końcowego do utworzenia wdrożenia w obszarze. |
| Model | Opcjonalnie | Model do użycia na potrzeby wdrożenia. Ta wartość może być odwołaniem do istniejącego modelu w wersji w obszarze roboczym lub specyfikacji wbudowanego modelu. W przykładach podanych w tym artykule model scikit-learn wykonuje regresję. |
| Ścieżka kodu | Opcjonalnie | Ścieżka do folderu w lokalnym środowisku programistycznym zawierającym cały kod źródłowy języka Python do oceniania modelu. Można użyć katalogów i pakietów zagnieżdżonych. |
| Skrypt oceniania | Opcjonalnie | Kod języka Python, który wykonuje model na danym żądaniu wejściowym. Ta wartość może być ścieżką względną do pliku oceniania w folderze kodu źródłowego. Skrypt oceniania odbiera dane przesłane do wdrożonej usługi internetowej i przekazuje je do modelu. Następnie skrypt wykonuje model i zwraca jego odpowiedź na klienta. Skrypt oceniania jest specyficzny dla modelu i musi zrozumieć dane oczekiwane przez model jako dane wejściowe i zwracane jako dane wyjściowe. W przykładach tego artykułu jest używany plik score.py. Ten kod w języku Python musi mieć init funkcję i run funkcję. Funkcja init jest wywoływana po utworzeniu lub zaktualizowaniu modelu. Można jej użyć do buforowania modelu w pamięci, na przykład. Funkcja run jest wywoływana przy każdym wywołaniu punktu końcowego w celu wykonania rzeczywistego oceniania i przewidywania. |
| Środowisko | Wymagane | Środowisko do hostowania modelu i kodu. Ta wartość może być odwołaniem do istniejącego środowiska w wersji w obszarze roboczym lub specyfikacji środowiska wbudowanego. Środowisko może być obrazem platformy Docker z zależnościami Conda, plikiem Dockerfile lub zarejestrowanym środowiskiem. |
| Typ wystąpienia | Wymagane | Rozmiar maszyny wirtualnej do użycia na potrzeby wdrożenia. Aby uzyskać listę obsługiwanych rozmiarów, zobacz Lista jednostek SKU zarządzanych punktów końcowych online. |
| Liczba wystąpień | Wymagane | Liczba wystąpień do użycia na potrzeby wdrożenia. Wartość jest oparta na oczekiwanym obciążeniu. Aby zapewnić wysoką dostępność, zalecamy użycie co najmniej trzech instancji. Usługa Azure Machine Learning rezerwuje dodatkowe 20 procent na potrzeby przeprowadzania uaktualnień. Aby uzyskać więcej informacji, zapoznaj się z punktami końcowymi usługi Azure Machine Learning, zarówno online, jak i wsadowymi. |
Aby wyświetlić pełną listę atrybutów, które można określić podczas tworzenia wdrożenia, zobacz Schemat YAML zarządzanego wdrożenia online CLI (wersja 2). Aby uzyskać wersję 2 zestawu SDK języka Python, zobacz ManagedOnlineDeployment Class.
Tworzenie punktu końcowego online
Najpierw należy ustawić nazwę punktu końcowego, a następnie skonfigurować go. W tym artykule użyjesz pliku endpoints/online/managed/sample/endpoint.yml, aby skonfigurować punkt końcowy. Ten plik zawiera następujące wiersze:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
W poniższej tabeli opisano klucze używane przez format YAML punktu końcowego. Aby dowiedzieć się, jak określić te atrybuty, zobacz Schemat YAML punktu końcowego online CLI (wersja 2). Aby uzyskać informacje o limitach związanych z zarządzanymi punktami końcowymi online, zobacz Punkty końcowe online i punkty końcowe wsadowe usługi Azure Machine Learning.
| Klawisz | Opis |
|---|---|
$schema |
(Opcjonalnie) Schemat YAML. Aby wyświetlić wszystkie dostępne opcje w pliku YAML, możesz wyświetlić schemat w poprzednim bloku kodu w przeglądarce. |
name |
Nazwa punktu końcowego. |
auth_mode |
Tryb uwierzytelniania. Służy key do uwierzytelniania opartego na kluczach. Służy aml_token do uwierzytelniania opartego na tokenach usługi Azure Machine Learning. Aby uzyskać najnowszy token, użyj az ml online-endpoint get-credentials polecenia . |
Aby utworzyć punkt końcowy online:
Ustaw nazwę punktu końcowego, uruchamiając następujące polecenie systemu Unix. Zastąp ciąg
YOUR_ENDPOINT_NAMEunikatową nazwą.export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Ważne
Nazwy punktów końcowych muszą być unikatowe w regionie świadczenia usługi Azure. Na przykład w regionie świadczenia usługi Azure
westus2może istnieć tylko jeden punkt końcowy o nazwiemy-endpoint.Utwórz punkt końcowy w chmurze, uruchamiając następujący kod. Ten kod używa pliku endpoint.yml do skonfigurowania punktu końcowego:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Utwórz niebieskie wdrożenie
Możesz użyć pliku endpoints/online/managed/sample/blue-deployment.yml, aby skonfigurować kluczowe aspekty wdrożenia o nazwie blue. Ten plik zawiera następujące wiersze:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Aby użyć pliku blue-deployment.yml do utworzenia wdrożenia blue dla punktu końcowego, uruchom następujące polecenie.
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Ważne
Flaga --all-traffic w poleceniu az ml online-deployment create przydziela 100 procent ruchu punktu końcowego do nowo utworzonego blue wdrożenia.
W pliku blue-deployment.yaml wiersz path określa, skąd przesyłać pliki. Interfejs wiersza polecenia usługi Azure Machine Learning używa tych informacji do przekazywania plików i rejestrowania modelu i środowiska. Najlepszym rozwiązaniem w środowisku produkcyjnym jest zarejestrowanie modelu i środowiska oraz określenie zarejestrowanej nazwy i wersji oddzielnie w kodzie YAML. Użyj formatu model: azureml:<model-name>:<model-version> dla modelu, na przykład model: azureml:my-model:1. W środowisku użyj formatu environment: azureml:<environment-name>:<environment-version>, na przykład environment: azureml:my-env:1.
W celu rejestracji można wyodrębnić definicje YAML plików model YAML i environment do oddzielnych plików YAML oraz użyć poleceń az ml model create i az ml environment create. Aby dowiedzieć się więcej o tych poleceniach, uruchom az ml model create -h i az ml environment create -h.
Aby uzyskać więcej informacji na temat rejestrowania modelu jako zasobu, zobacz Rejestrowanie modelu przy użyciu interfejsu wiersza polecenia platformy Azure lub zestawu SDK języka Python. Aby uzyskać więcej informacji na temat tworzenia środowiska, zobacz Tworzenie środowiska niestandardowego.





Potwierdzanie istniejącego wdrożenia
Jednym ze sposobów potwierdzenia istniejącego wdrożenia jest wywołanie punktu końcowego, aby mógł ocenić model dla danego żądania wejściowego. Podczas wywoływania punktu końcowego za pośrednictwem interfejsu wiersza polecenia platformy Azure lub zestawu SDK języka Python możesz określić nazwę wdrożenia, aby odbierać ruch przychodzący.
Uwaga
W przeciwieństwie do interfejsu wiersza polecenia platformy Azure lub zestawu SDK języka Python program Azure Machine Learning Studio wymaga określenia wdrożenia podczas wywoływania punktu końcowego.
Wywołaj punkt końcowy z nazwą wdrożenia
Podczas wywoływania punktu końcowego można określić nazwę wdrożenia, które ma odbierać ruch. W takim przypadku usługa Azure Machine Learning kieruje ruch punktu końcowego bezpośrednio do określonego wdrożenia i zwraca dane wyjściowe. Możesz użyć --deployment-name opcji interfejsu wiersza polecenia usługi Azure Machine Learning w wersji 2 lub deployment_name opcji zestawu SDK języka Python w wersji 2, aby określić wdrożenie.
Wywoływanie punktu końcowego bez określania wdrożenia
Jeśli wywołasz punkt końcowy bez określenia wdrożenia, które ma odbierać ruch, usługa Azure Machine Learning kieruje przychodzący ruch punktu końcowego do wdrożeń w punkcie końcowym na podstawie ustawień kontroli ruchu.
Ustawienia kontroli ruchu przydzielają określone wartości procentowe ruchu przychodzącego do każdego wdrożenia w punkcie końcowym. Jeśli na przykład reguły ruchu określają, że określone wdrożenie w punkcie końcowym powinno odbierać ruch przychodzący 40 procent czasu, usługa Azure Machine Learning kieruje 40% ruchu punktu końcowego do tego wdrożenia.
Aby wyświetlić stan istniejącego punktu końcowego i wdrożenia, uruchom następujące polecenia:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
Wynik zawiera informacje o $ENDPOINT_NAME punkcie końcowym i blue wdrożeniu.
Testowanie punktu końcowego przy użyciu przykładowych danych
Punkt końcowy można wywołać przy użyciu invoke polecenia . Następujące polecenie używa pliku JSON sample-request.json do wysłania przykładowego żądania:
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json


Skalowanie istniejącego wdrożenia w celu obsługi większej liczby ruchu
We wdrożeniu opisanym w artykule Wdrażanie i ocenianie modelu uczenia maszynowego przy użyciu punktu końcowego online należy ustawić instance_count wartość na 1 w pliku YAML wdrożenia. Można zwiększyć skalowanie w poziomie przy użyciu polecenia update.
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Uwaga
W poprzednim poleceniu --set opcja zastępuje konfigurację wdrożenia. Alternatywnie możesz zaktualizować plik YAML i przekazać go jako dane wejściowe do update polecenia przy użyciu --file opcji .

Wdróż nowy model, ale nie kieruj do niego ruchu
Utwórz nowe wdrożenie o nazwie green:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Ponieważ nie przydzielasz jawnie żadnego ruchu do wdrożenia green, nie ma ono przypisanego żadnego ruchu. Możesz zweryfikować ten fakt, używając następującego polecenia:
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
Testowanie nowego wdrożenia
Mimo że green wdrożenie ma przydzielony do niego 0 procent ruchu, można wywołać go bezpośrednio za pomocą opcji --deployment.
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
Jeśli chcesz używać klienta REST do bezpośredniego wywoływania wdrożenia bez przechodzenia przez reguły ruchu, ustaw następujący nagłówek HTTP: azureml-model-deployment: <deployment-name>. Poniższy kod używa klienta dla adresu URL (cURL), aby wywołać wdrożenie bezpośrednio. Kod można uruchomić w środowisku Unix lub w Podsystemie Windows dla systemu Linux (WSL). Aby uzyskać instrukcje dotyczące pobierania $ENDPOINT_KEY wartości, zobacz Pobieranie klucza lub tokenu dla operacji płaszczyzny danych.
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json


Testowanie wdrożenia przy użyciu ruchu dublowanego
Po przetestowaniu green wdrożenia można zdublować procent ruchu na żywo do punktu końcowego, kopiując ten procent ruchu i wysyłając go do green wdrożenia. Dublowanie ruchu, nazywane również cieniowaniem, nie zmienia wyników zwracanych do klientów — 100 procent żądań nadal przepływa do blue wdrożenia. Zdublowany procent ruchu jest kopiowany, a także przesyłany do green wdrożenia, dzięki czemu można zbierać metryki i rejestrowanie bez wpływu na klientów.
Dublowanie jest przydatne, gdy chcesz zweryfikować nowe wdrożenie bez wpływu na klientów. Na przykład można użyć dublowania, aby sprawdzić, czy opóźnienie mieści się w dopuszczalnych granicach, czy nie ma żadnych błędów HTTP. Użycie dublowania ruchu lub cieniowania w celu przetestowania nowego wdrożenia jest również nazywane testowaniem w tle. Wdrożenie odbierające ruch lustrzany, w tym przypadku green wdrożenie, może być również nazywane wdrożeniem cieniowym.
Dublowanie ma następujące ograniczenia:
- Dublowanie jest obsługiwane w wersjach 2.4.0 i nowszych interfejsu wiersza polecenia usługi Azure Machine Learning oraz w wersjach 1.0.0 i nowszych zestawu SDK języka Python. Jeśli używasz starszej wersji Azure Machine Learning CLI lub Python SDK do zaktualizowania punktu końcowego, utracisz ustawienie ruchu lustrzanego.
- Dublowanie nie jest obecnie obsługiwane w przypadku punktów końcowych online platformy Kubernetes.
- Ruch można dublować tylko do jednego wdrożenia w punkcie końcowym.
- Maksymalny procent ruchu, który można dublować, wynosi 50 procent. Ten limit ogranicza wpływ na limit przydziału przepustowości punktu końcowego, który ma domyślną wartość 5 MB/s. Przepustowość punktu końcowego jest ograniczana w przypadku przekroczenia przydzielonego limitu przydziału. Aby uzyskać informacje na temat monitorowania ograniczania przepustowości, zobacz Ograniczanie przepustowości.
Zwróć również uwagę na następujące zachowanie:
- Wdrożenie można skonfigurować tak, aby odbierało tylko ruch na żywo lub ruch dublowany, a nie oba te elementy.
- Podczas wywoływania punktu końcowego można określić nazwę dowolnego z jego wdrożeń — nawet tajnego wdrożenia — w celu uzyskania prognozy.
- Po wywołaniu punktu końcowego i określeniu nazwy wdrożenia, które odbiera ruch przychodzący, usługa Azure Machine Learning nie odzwierciedla ruchu do wdrożenia w tle. Usługa Azure Machine Learning dubluje ruch do wdrożenia w tle z ruchu wysyłanego do punktu końcowego, gdy nie określisz wdrożenia.
Jeśli wdrożenie jest ustawione na otrzymywanie 10 procent dublowanego ruchu, klienci nadal otrzymują przewidywania wyłącznie z wdrożenia blue.
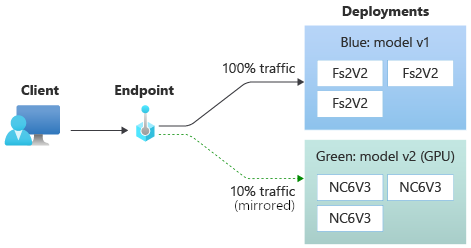
Użyj następującego polecenia, aby przechwycić 10 procent ruchu sieciowego i wysłać go do green wdrożenia.
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
Ruch odzwierciedlony można przetestować, wywołując punkt końcowy kilka razy bez określania wdrożenia, aby odbierać nadchodzący ruch.
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
Możesz potwierdzić, że określony procent ruchu jest wysyłany do green wdrożenia, sprawdzając dzienniki z wdrożenia:
az ml online-deployment get-logs --name green --endpoint $ENDPOINT_NAME
Po przetestowaniu można ustawić ruch dublowania na zero, aby wyłączyć dublowanie:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"



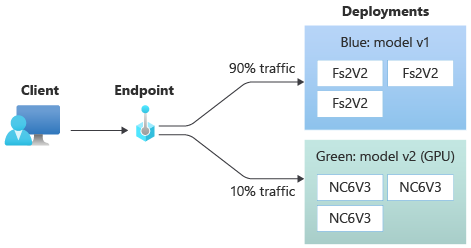
Przydzielanie niewielkiego procentu ruchu na żywo do nowego wdrożenia
Po przetestowaniu wdrożenia green, przydziel do niego niewielki procent ruchu.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
Napiwek
Całkowity procent ruchu musi wynosić 0 procent, aby wyłączyć ruch lub 100 procent, aby umożliwić ruch.
Twoje wdrożenie green teraz otrzymuje 10 procent całego ruchu w czasie rzeczywistym. Klienci otrzymują przewidywania zarówno z wdrożeń blue, jak i green.
Wysyłanie całego ruchu do nowego wdrożenia
Kiedy będziesz w pełni usatysfakcjonowany z wdrożenia green, przełącz cały ruch do niego.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
Usuwanie starego wdrożenia
Wykonaj poniższe kroki, aby usunąć pojedyncze wdrożenie z zarządzanego punktu końcowego online. Usunięcie pojedynczego wdrożenia nie ma wpływu na inne wdrożenia w zarządzanym punkcie końcowym online:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
Usuwanie punktu końcowego i wdrożenia
Jeśli nie zamierzasz używać punktu końcowego i wdrożenia, usuń je. Usunięcie punktu końcowego spowoduje również usunięcie wszystkich jego podstawowych wdrożeń.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait