Trenowanie modeli TensorFlow na dużą skalę za pomocą usługi Azure Machine Learning
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
W tym artykule dowiesz się, jak uruchamiać skrypty szkoleniowe TensorFlow na dużą skalę przy użyciu zestawu SDK języka Python usługi Azure Machine Learning w wersji 2.
Przykładowy kod w tym artykule szkoli model TensorFlow w celu klasyfikowania cyfr odręcznych przy użyciu głębokiej sieci neuronowej (DNN); zarejestruj model; i wdróż go w punkcie końcowym online.
Niezależnie od tego, czy tworzysz model TensorFlow od podstaw, czy wprowadzasz istniejący model do chmury, możesz użyć usługi Azure Machine Learning, aby skalować zadania szkoleniowe typu open source przy użyciu elastycznych zasobów obliczeniowych w chmurze. Za pomocą usługi Azure Machine Learning można tworzyć, wdrażać, wersję i monitorować modele klasy produkcyjnej.
Wymagania wstępne
Aby skorzystać z tego artykułu, musisz:
- Uzyskiwanie dostępu do subskrypcji platformy Azure. Jeśli jeszcze go nie masz, utwórz bezpłatne konto.
- Uruchom kod w tym artykule przy użyciu wystąpienia obliczeniowego usługi Azure Machine Learning lub własnego notesu Jupyter.
- Wystąpienie obliczeniowe usługi Azure Machine Learning — brak pobierania ani instalacji
- Ukończ samouczek Tworzenie zasobów, aby rozpocząć pracę, aby utworzyć wstępnie załadowany dedykowany serwer notesu za pomocą zestawu SDK i przykładowego repozytorium.
- W folderze przykładów uczenia głębokiego na serwerze notesów znajdź ukończony i rozszerzony notes, przechodząc do tego katalogu: zadania języka Python zestawu SDK > > > w wersji 2>— jeden krok > — szkolenie tensorflow > — hiperparametr- tune-deploy-with-tensorflow.
- Serwer notesu Jupyter
- Wystąpienie obliczeniowe usługi Azure Machine Learning — brak pobierania ani instalacji
- Pobierz następujące pliki:
- tf_mnist.py skryptu szkoleniowego
- skrypt oceniania score.py
- przykładowy plik żądania sample-request.json
Możesz również znaleźć ukończoną wersję notesu Jupyter Notebook na stronie przykładów usługi GitHub.
Przed uruchomieniem kodu w tym artykule w celu utworzenia klastra procesora GPU należy zażądać zwiększenia limitu przydziału dla obszaru roboczego.
Konfigurowanie zadania
Ta sekcja konfiguruje zadanie trenowania przez załadowanie wymaganych pakietów języka Python, nawiązanie połączenia z obszarem roboczym, utworzenie zasobu obliczeniowego w celu uruchomienia zadania polecenia i utworzenie środowiska do uruchomienia zadania.
Nawiązywanie połączenia z obszarem roboczym
Najpierw musisz nawiązać połączenie z obszarem roboczym usługi Azure Machine Learning. Obszar roboczy usługi Azure Machine Learning to zasób najwyższego poziomu dla usługi. Zapewnia scentralizowane miejsce do pracy ze wszystkimi artefaktami tworzonymi podczas korzystania z usługi Azure Machine Learning.
Używamy DefaultAzureCredential polecenia , aby uzyskać dostęp do obszaru roboczego. To poświadczenie powinno być w stanie obsługiwać większość scenariuszy uwierzytelniania zestawu Azure SDK.
Jeśli DefaultAzureCredential nie zadziała, zobacz azure-identity reference documentation lub Set up authentication w przypadku większej liczby dostępnych poświadczeń.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Jeśli wolisz używać przeglądarki do logowania się i uwierzytelniania, usuń komentarz z poniższego kodu i użyj go zamiast tego.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Następnie uzyskaj dojście do obszaru roboczego, podając identyfikator subskrypcji, nazwę grupy zasobów i nazwę obszaru roboczego. Aby znaleźć następujące parametry:
- Wyszukaj nazwę obszaru roboczego w prawym górnym rogu paska narzędzi usługi Azure Machine Learning Studio.
- Wybierz nazwę obszaru roboczego, aby wyświetlić identyfikator grupy zasobów i subskrypcji.
- Skopiuj wartości dla pola Grupa zasobów i Identyfikator subskrypcji do kodu.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Wynikiem uruchomienia tego skryptu jest uchwyt obszaru roboczego używany do zarządzania innymi zasobami i zadaniami.
Uwaga
- Tworzenie
MLClientnie spowoduje połączenia klienta z obszarem roboczym. Inicjowanie klienta jest leniwe i będzie czekać po raz pierwszy, aby wykonać wywołanie. W tym artykule będzie to miało miejsce podczas tworzenia zasobów obliczeniowych.
Tworzenie zasobu obliczeniowego
Usługa Azure Machine Learning wymaga zasobu obliczeniowego do uruchomienia zadania. Ten zasób może być maszynami z jednym lub wieloma węzłami z systemem operacyjnym Linux lub Windows albo określoną siecią szkieletową obliczeniową, taką jak Spark.
W poniższym przykładowym skry skrycie aprowizujemy system Linux compute cluster. Zostanie wyświetlona Azure Machine Learning pricing strona zawierająca pełną listę rozmiarów maszyn wirtualnych i cen. Ponieważ w tym przykładzie potrzebujemy klastra gpu, wybierzmy model STANDARD_NC6 i utwórzmy obliczenia usługi Azure Machine Learning.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Tworzenie środowiska zadań
Aby uruchomić zadanie usługi Azure Machine Learning, potrzebne jest środowisko. Środowisko usługi Azure Machine Learning hermetyzuje zależności (takie jak środowisko uruchomieniowe oprogramowania i biblioteki) wymagane do uruchomienia skryptu trenowania uczenia maszynowego na zasobie obliczeniowym. To środowisko jest podobne do środowiska języka Python na komputerze lokalnym.
Usługa Azure Machine Learning umożliwia korzystanie ze środowiska nadzorowanego (lub gotowego) — przydatnego w przypadku typowych scenariuszy trenowania i wnioskowania — lub tworzenia środowiska niestandardowego przy użyciu obrazu platformy Docker lub konfiguracji conda.
W tym artykule użyjesz ponownie wyselekcjonowanych środowisk AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpuusługi Azure Machine Learning. Używasz najnowszej wersji tego środowiska przy użyciu @latest dyrektywy .
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"Konfigurowanie i przesyłanie zadania szkoleniowego
W tej sekcji zaczniemy od wprowadzenia danych do trenowania. Następnie omówimy sposób uruchamiania zadania szkoleniowego przy użyciu udostępnionego przez nas skryptu szkoleniowego. Dowiesz się, jak skompilować zadanie trenowania, konfigurując polecenie do uruchamiania skryptu szkoleniowego. Następnie przesyłasz zadanie szkoleniowe do uruchomienia w usłudze Azure Machine Learning.
Uzyskiwanie danych treningowych
Użyjesz danych z bazy danych Zmodyfikowanego Narodowego Instytutu Standardów i Technologii (MNIST) cyfr odręcznych. Te dane pochodzą z witryny internetowej Yan LeCun i przechowywane na koncie usługi Azure Storage.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Aby uzyskać więcej informacji na temat zestawu danych MNIST, odwiedź witrynę internetową Yan LeCun.
Przygotowywanie skryptu szkoleniowego
W tym artykule udostępniliśmy skrypt szkoleniowy tf_mnist.py. W praktyce powinno być możliwe użycie dowolnego niestandardowego skryptu szkoleniowego w następujący sposób i uruchomienie go za pomocą usługi Azure Machine Learning bez konieczności modyfikowania kodu.
Podany skrypt szkoleniowy wykonuje następujące czynności:
- obsługuje przetwarzanie wstępne danych, dzielenie danych na dane testowe i trenowanie;
- trenuje model przy użyciu danych; i
- zwraca model wyjściowy.
Podczas uruchamiania potoku używasz biblioteki MLFlow do rejestrowania parametrów i metryk. Aby dowiedzieć się, jak włączyć śledzenie mlFlow, zobacz Track ML experiments and models with MLflow (Śledzenie eksperymentów i modeli uczenia maszynowego za pomocą biblioteki MLflow).
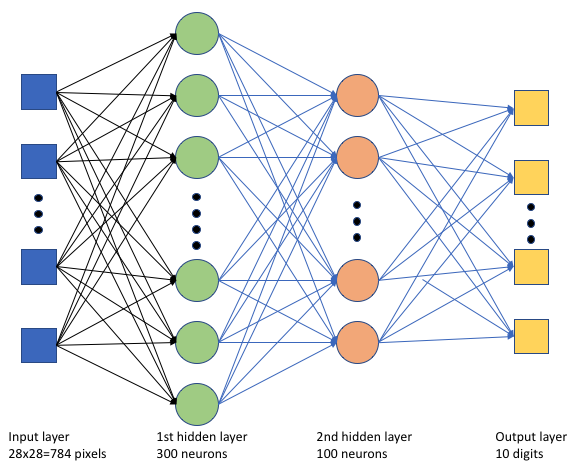
W skrypcie tf_mnist.pytrenowania utworzymy prostą głęboką sieć neuronową (DNN). Ta nazwa sieci rozproszonej ma:
- Warstwa wejściowa z 28 * 28 = 784 neurony. Każdy neuron reprezentuje piksel obrazu.
- Dwie ukryte warstwy. Pierwsza ukryta warstwa ma 300 neuronów, a druga ukryta warstwa ma 100 neuronów.
- Warstwa wyjściowa z 10 neuronami. Każdy neuron reprezentuje docelową etykietę z zakresu od 0 do 9.
Tworzenie zadania szkoleniowego
Teraz, gdy masz wszystkie zasoby wymagane do uruchomienia zadania, nadszedł czas, aby skompilować go przy użyciu zestawu SDK języka Python usługi Azure Machine Learning w wersji 2. W tym przykładzie tworzysz element command.
Usługa Azure Machine Learning command to zasób, który określa wszystkie szczegóły potrzebne do wykonania kodu szkoleniowego w chmurze. Te szczegóły obejmują dane wejściowe i wyjściowe, typ sprzętu do użycia, oprogramowanie do zainstalowania i sposób uruchamiania kodu. Zawiera command informacje umożliwiające wykonanie pojedynczego polecenia.
Konfigurowanie polecenia
Używasz ogólnego przeznaczenia command do uruchamiania skryptu szkoleniowego i wykonywania żądanych zadań. Utwórz obiekt, Command aby określić szczegóły konfiguracji zadania trenowania.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)Dane wejściowe dla tego polecenia obejmują lokalizację danych, rozmiar partii, liczbę neuronów w pierwszej i drugiej warstwie oraz szybkość nauki. Zwróć uwagę, że przekazaliśmy ścieżkę internetową bezpośrednio jako dane wejściowe.
Dla wartości parametrów:
- podaj klaster
gpu_compute_target = "gpu-cluster"obliczeniowy utworzony na potrzeby uruchamiania tego polecenia; - podaj zadeklarowane wcześniej środowisko
curated_env_namewyselekcjonowane; - skonfiguruj samą akcję wiersza polecenia — w tym przypadku polecenie to
python tf_mnist.py. Dostęp do danych wejściowych i wyjściowych można uzyskać w poleceniu${{ ... }}za pośrednictwem notacji; i - skonfiguruj metadane, takie jak nazwa wyświetlana i nazwa eksperymentu; gdzie eksperyment jest kontenerem dla wszystkich iteracji, które wykonuje w określonym projekcie. Wszystkie zadania przesłane pod tą samą nazwą eksperymentu zostaną wyświetlone obok siebie w usłudze Azure Machine Learning Studio.
- podaj klaster
W tym przykładzie
UserIdentityużyjesz polecenia , aby uruchomić polecenie . Użycie tożsamości użytkownika oznacza, że polecenie będzie używać tożsamości do uruchamiania zadania i uzyskiwania dostępu do danych z obiektu blob.
Przesyłanie zadania
Nadszedł czas na przesłanie zadania do uruchomienia w usłudze Azure Machine Learning. Tym razem użyjesz polecenia create_or_update w pliku ml_client.jobs.
ml_client.jobs.create_or_update(job)Po zakończeniu zadanie zarejestruje model w obszarze roboczym (w wyniku trenowania) i wyświetli link do wyświetlania zadania w usłudze Azure Machine Learning Studio.
Ostrzeżenie
Usługa Azure Machine Learning uruchamia skrypty szkoleniowe, kopiując cały katalog źródłowy. Jeśli masz poufne dane, które nie chcesz przekazywać, użyj pliku .ignore lub nie dołącz go do katalogu źródłowego.
Co się dzieje podczas wykonywania zadania
Po wykonaniu zadania przechodzi on przez następujące etapy:
Przygotowywanie: obraz platformy Docker jest tworzony zgodnie ze zdefiniowanym środowiskiem. Obraz jest przekazywany do rejestru kontenerów obszaru roboczego i buforowany w celu późniejszego uruchomienia. Dzienniki są również przesyłane strumieniowo do historii zadań i można je wyświetlić w celu monitorowania postępu. Jeśli zostanie określone wyselekcjonowane środowisko, zostanie użyty buforowany obraz obsługujący wyselekcjonowane środowisko.
Skalowanie: klaster próbuje skalować w górę, jeśli wymaga więcej węzłów do wykonania przebiegu, niż są obecnie dostępne.
Uruchomione: wszystkie skrypty w folderze skryptu src są przekazywane do docelowego obiektu obliczeniowego, magazyny danych są instalowane lub kopiowane, a skrypt jest wykonywany. Dane wyjściowe z pliku stdout i folderu ./logs są przesyłane strumieniowo do historii zadań i mogą służyć do monitorowania zadania.
Dostrajanie hiperparametrów modelu
Teraz, gdy już wiesz, jak wykonać przebieg trenowania TensorFlow przy użyciu zestawu SDK, zobaczmy, czy możesz jeszcze bardziej poprawić dokładność modelu. Hiperparametry modelu można dostroić i zoptymalizować przy użyciu możliwości usługi Azure Machine Learning sweep .
Aby dostroić hiperparametry modelu, zdefiniuj przestrzeń parametrów, w której mają być wyszukiwane podczas trenowania. W tym celu zastąpisz niektóre parametry (batch_size, first_layer_neurons, second_layer_neuronsi learning_rate) przekazane do zadania trenowania specjalnymi danymi wejściowymi z azure.ml.sweep pakietu.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Następnie skonfigurujesz zamiatanie zadania polecenia, używając niektórych parametrów specyficznych dla zamiatania, takich jak metryka podstawowa do obserwowania i algorytm próbkowania do użycia.
W poniższym kodzie użyjemy losowego próbkowania, aby wypróbować różne zestawy konfiguracji hiperparametrów w celu zmaksymalizowania podstawowej metryki . validation_acc
Definiujemy również zasady wczesnego zakończenia — BanditPolicy. Te zasady działają, sprawdzając zadanie co dwie iteracji. Jeśli podstawowa metryka , validation_accspadnie poza zakres 10 procent, usługa Azure Machine Learning zakończy zadanie. Dzięki temu model nie będzie nadal eksplorować hiperparametrów, które nie wykazują obietnicy uzyskania pomocy w osiągnięciu docelowej metryki.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Teraz możesz przesłać to zadanie tak jak wcześniej. Tym razem będziesz uruchamiać zadanie zamiatania, które zamiata nad zadaniem pociągu.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Zadanie można monitorować przy użyciu linku interfejsu użytkownika programu Studio, który jest prezentowany podczas uruchamiania zadania.
Znajdowanie i rejestrowanie najlepszego modelu
Po zakończeniu wszystkich przebiegów można znaleźć przebieg, który wygenerował model z najwyższą dokładnością.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Następnie możesz zarejestrować ten model.
registered_model = ml_client.models.create_or_update(model=model)Wdrażanie modelu jako punktu końcowego online
Po zarejestrowaniu modelu możesz wdrożyć go jako punkt końcowy online — czyli jako usługę internetową w chmurze platformy Azure.
Aby wdrożyć usługę uczenia maszynowego, zwykle potrzebne są następujące elementy:
- Zasoby modelu, które chcesz wdrożyć. Te zasoby obejmują plik i metadane modelu, które zostały już zarejestrowane w zadaniu trenowania.
- Niektóre kod do uruchomienia jako usługa. Kod wykonuje model na danym żądaniu wejściowym (skrypt wpisu). Ten skrypt wpisu odbiera dane przesyłane do wdrożonej usługi internetowej i przekazuje je do modelu. Po przetworzeniu danych przez model skrypt zwraca odpowiedź modelu na klienta. Skrypt jest specyficzny dla modelu i musi zrozumieć dane, których model oczekuje i zwraca. W przypadku korzystania z modelu MLFlow usługa Azure Machine Learning automatycznie tworzy ten skrypt.
Aby uzyskać więcej informacji na temat wdrażania, zobacz Deploy and score a machine learning model with managed online endpoint using Python SDK v2 (Wdrażanie i ocenianie modelu uczenia maszynowego za pomocą zarządzanego punktu końcowego online przy użyciu zestawu SDK języka Python w wersji 2).
Tworzenie nowego punktu końcowego online
Pierwszym krokiem do wdrożenia modelu jest utworzenie punktu końcowego online. Nazwa punktu końcowego musi być unikatowa w całym regionie świadczenia usługi Azure. W tym artykule utworzysz unikatową nazwę przy użyciu uniwersalnego unikatowego identyfikatora (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Po utworzeniu punktu końcowego można go pobrać w następujący sposób:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Wdrażanie modelu w punkcie końcowym
Po utworzeniu punktu końcowego możesz wdrożyć model za pomocą skryptu wejścia. Punkt końcowy może mieć wiele wdrożeń. Korzystając z reguł, punkt końcowy może następnie kierować ruch do tych wdrożeń.
W poniższym kodzie utworzysz pojedyncze wdrożenie, które obsługuje 100% ruchu przychodzącego. Do wdrożenia używamy dowolnej nazwy koloru (tff-blue). Możesz również użyć dowolnej innej nazwy, takiej jak tff-green lub tff-red dla wdrożenia. Kod wdrażania modelu w punkcie końcowym wykonuje następujące czynności:
- wdraża najlepszą wersję zarejestrowanego wcześniej modelu;
- ocenia model przy użyciu
score.pypliku i - do wnioskowania używa tego samego środowiska wyselekcjonowane (zadeklarowane wcześniej).
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Uwaga
Spodziewaj się, że ukończenie tego wdrożenia zajmie trochę czasu.
Testowanie wdrożenia przy użyciu przykładowego zapytania
Po wdrożeniu modelu w punkcie końcowym można przewidzieć dane wyjściowe wdrożonego modelu przy użyciu invoke metody w punkcie końcowym. Aby uruchomić wnioskowanie, użyj przykładowego pliku sample-request.json żądania z folderu żądania .
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)Następnie można wydrukować zwrócone przewidywania i wykreślić je wraz z obrazami wejściowymi. Użyj koloru czcionki czerwonej i odwróconego obrazu (białego na czarno), aby wyróżnić błędnie sklasyfikowane przykłady.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Uwaga
Ponieważ dokładność modelu jest wysoka, może być konieczne uruchomienie komórki kilka razy przed sprawdzeniem błędnie sklasyfikowanej próbki.
Czyszczenie zasobów
Jeśli nie będziesz używać punktu końcowego, usuń go, aby zatrzymać korzystanie z zasobu. Przed usunięciem punktu końcowego upewnij się, że żadne inne wdrożenia nie korzystają z niego.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Uwaga
Spodziewaj się, że wykonanie tego oczyszczania zajmie trochę czasu.
Następne kroki
W tym artykule wytrenujesz i zarejestrowano model TensorFlow. Model został również wdrożony w punkcie końcowym online. Zapoznaj się z innymi artykułami, aby dowiedzieć się więcej o usłudze Azure Machine Learning.