Wyzwalanie potoków uczenia maszynowego
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
W tym artykule dowiesz się, jak programowo zaplanować uruchamianie potoku na platformie Azure. Harmonogram można utworzyć w oparciu o czas, który upłynął lub zmiany systemu plików. Harmonogramy oparte na czasie mogą służyć do dbania o rutynowe zadania, takie jak monitorowanie dryfu danych. Harmonogramy oparte na zmianach mogą służyć do reagowania na nieregularne lub nieprzewidywalne zmiany, takie jak przekazywanie nowych danych lub edytowanie starych danych. Po zapoznaniu się z tworzeniem harmonogramów dowiesz się, jak je pobierać i dezaktywować. Na koniec dowiesz się, jak uruchamiać potoki przy użyciu innych usług platformy Azure, aplikacji logiki platformy Azure i usługi Azure Data Factory. Aplikacja logiki platformy Azure umożliwia bardziej złożone wyzwalanie logiki lub zachowania. Potoki usługi Azure Data Factory umożliwiają wywoływanie potoku uczenia maszynowego w ramach większego potoku aranżacji danych.
Wymagania wstępne
Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, utwórz bezpłatne konto.
Środowisko języka Python, w którym jest zainstalowany zestaw AZURE Machine Learning SDK dla języka Python. Aby uzyskać więcej informacji, zobacz Tworzenie środowisk wielokrotnego użytku i zarządzanie nimi na potrzeby trenowania i wdrażania za pomocą usługi Azure Machine Learning.
Obszar roboczy usługi Machine Learning z opublikowanym potokiem. Możesz użyć tego wbudowanego potoku tworzenia i uruchamiania potoków uczenia maszynowego za pomocą zestawu Azure Machine Learning SDK.
Wyzwalanie potoków za pomocą zestawu SDK usługi Azure Machine Learning dla języka Python
Aby zaplanować potok, musisz mieć odwołanie do obszaru roboczego, identyfikator opublikowanego potoku oraz nazwę eksperymentu, w którym chcesz utworzyć harmonogram. Te wartości można uzyskać za pomocą następującego kodu:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Tworzenie harmonogramu
Aby cyklicznie uruchamiać potok, utworzysz harmonogram. Element Schedule kojarzy potok, eksperyment i wyzwalacz. Wyzwalacz może być wyzwalaczem opisującyScheduleRecurrence oczekiwanie między zadaniami lub ścieżką magazynu danych określającą katalog do obserwowanego zmian. W obu przypadkach potrzebny będzie identyfikator potoku i nazwa eksperymentu, w którym ma zostać utworzony harmonogram.
W górnej części pliku języka Python zaimportuj Schedule klasy i ScheduleRecurrence :
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Tworzenie harmonogramu opartego na czasie
Konstruktor ScheduleRecurrence ma wymagany frequency argument, który musi być jednym z następujących ciągów: "Minute", "Hour", "Day", "Week" lub "Month". Wymaga to również argumentu całkowitego interval określającego, frequency ile jednostek powinno upłynąć między rozpoczęciem harmonogramu. Opcjonalne argumenty umożliwiają bardziej szczegółowe informacje na temat czasów rozpoczęcia, zgodnie z opisem w dokumentacji zestawu SDK ScheduleRecurrence.
Utwórz obiekt, który Schedule rozpoczyna zadanie co 15 minut:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Tworzenie harmonogramu opartego na zmianach
Potoki wyzwalane przez zmiany plików mogą być bardziej wydajne niż harmonogramy oparte na czasie. Jeśli chcesz zrobić coś przed zmianą pliku lub gdy nowy plik zostanie dodany do katalogu danych, możesz wstępnie przetworzyć ten plik. Możesz monitorować wszelkie zmiany w magazynie danych lub zmiany w określonym katalogu w magazynie danych. Jeśli monitorujesz określony katalog, zmiany w podkatalogach tego katalogu nie będą wyzwalać zadania.
Uwaga
Harmonogramy oparte na zmianach obsługują tylko monitorowanie usługi Azure Blob Storage.
Aby utworzyć plik reaktywny Schedule, należy ustawić datastore parametr w wywołaniu metody Schedule.create. Aby monitorować folder, ustaw path_on_datastore argument .
Argument polling_interval umożliwia określenie w minutach częstotliwości, z jaką magazyn danych jest sprawdzany pod kątem zmian.
Jeśli potok został skonstruowany za pomocą parametru DataPath PipelineParameter, możesz ustawić tę zmienną na nazwę zmienionego pliku, ustawiając data_path_parameter_name argument.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Opcjonalne argumenty podczas tworzenia harmonogramu
Oprócz omówionych wcześniej argumentów można ustawić argument na status wartość , aby "Disabled" utworzyć nieaktywny harmonogram. continue_on_step_failure Na koniec element umożliwia przekazanie wartości logicznej, która zastąpi domyślne zachowanie potoku.
Wyświetlanie zaplanowanych potoków
W przeglądarce internetowej przejdź do usługi Azure Machine Learning. W sekcji Punkty końcowe panelu nawigacji wybierz pozycję Punkty końcowe potoku. Spowoduje to przejście do listy potoków opublikowanych w obszarze roboczym.
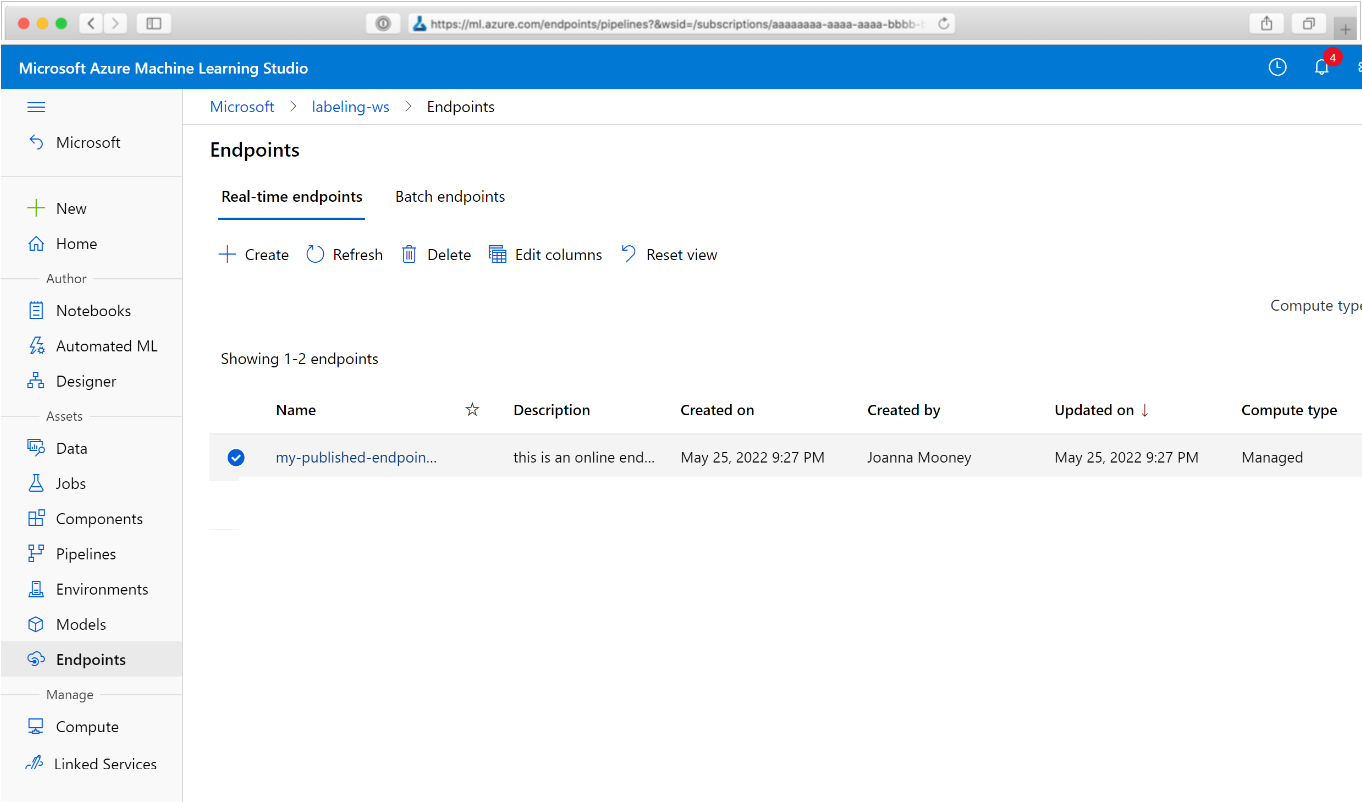
Na tej stronie można wyświetlić podsumowanie informacji o wszystkich potokach w obszarze roboczym: nazwy, opisy, stan itd. Przejdź do szczegółów, klikając potok. Na wyświetlonej stronie znajdują się więcej szczegółów na temat potoku i możesz przejść do szczegółów poszczególnych zadań.
Dezaktywowanie potoku
Jeśli masz opublikowaną Pipeline , ale nie zaplanowaną, możesz ją wyłączyć za pomocą następujących elementów:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Jeśli potok jest zaplanowany, musisz najpierw anulować harmonogram. Pobierz identyfikator harmonogramu z portalu lub uruchamiając polecenie:
ss = Schedule.list(ws)
for s in ss:
print(s)
Po wyłączeniu schedule_id uruchom polecenie:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Po ponownym uruchomieniu Schedule.list(ws) powinna zostać wyświetlona pusta lista.
Używanie usługi Azure Logic Apps do obsługi złożonych wyzwalaczy
Bardziej złożone reguły wyzwalacza lub zachowanie można utworzyć przy użyciu aplikacji logiki platformy Azure.
Aby użyć aplikacji logiki platformy Azure do wyzwolenia potoku usługi Machine Learning, potrzebny będzie punkt końcowy REST dla opublikowanego potoku usługi Machine Learning. Tworzenie i publikowanie potoku. Następnie znajdź punkt końcowy REST elementu PublishedPipeline przy użyciu identyfikatora potoku:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Tworzenie aplikacji logiki na platformie Azure
Teraz utwórz wystąpienie aplikacji logiki platformy Azure. Po aprowizacji aplikacji logiki wykonaj następujące kroki, aby skonfigurować wyzwalacz dla potoku:
Utwórz tożsamość zarządzaną przypisaną przez system, aby przyznać aplikacji dostęp do obszaru roboczego usługi Azure Machine Learning.
Przejdź do widoku Projektant aplikacji logiki i wybierz szablon Pusta aplikacja logiki.
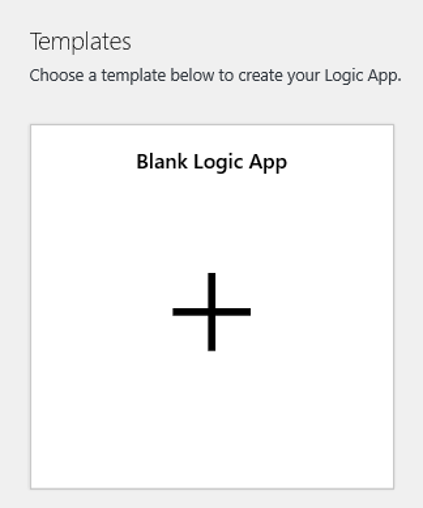
W projektancie wyszukaj obiekt blob. Wybierz wyzwalacz Po dodaniu lub zmodyfikowaniu obiektu blob (tylko właściwości) i dodaj ten wyzwalacz do aplikacji logiki.
Podaj informacje o połączeniu dla konta usługi Blob Storage, które chcesz monitorować pod kątem dodawania lub modyfikacji obiektów blob. Wybierz kontener do monitorowania.
Wybierz interwał i częstotliwość sondowania pod kątem aktualizacji, które działają dla Ciebie.
Uwaga
Ten wyzwalacz będzie monitorować wybrany kontener, ale nie będzie monitorować podfolderów.
Dodaj akcję HTTP, która zostanie uruchomiona po wykryciu nowego lub zmodyfikowanego obiektu blob. Wybierz pozycję + Nowy krok, a następnie wyszukaj i wybierz akcję HTTP.
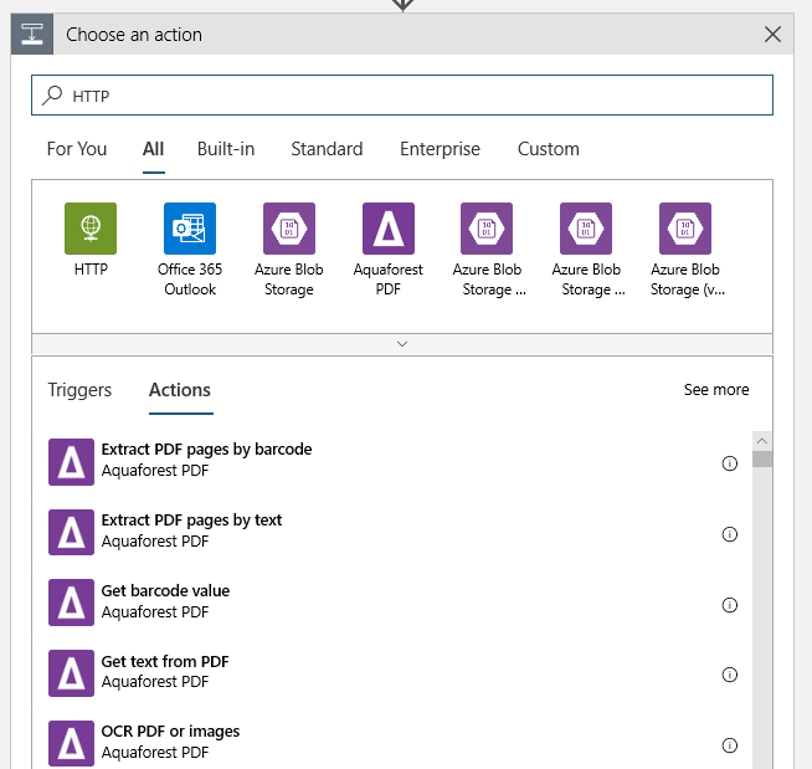
Aby skonfigurować akcję, użyj następujących ustawień:
| Ustawienie | Wartość |
|---|---|
| Akcja HTTP | POST |
| Identyfikator URI | punkt końcowy opublikowanego potoku, który został znaleziony jako warunek wstępny |
| Tryb uwierzytelniania | Tożsamość zarządzana |
Skonfiguruj harmonogram, aby ustawić wartość dowolnego parametru potoku ścieżki danych, które mogą być następujące:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Użyj elementu dodanego
DataStoreNamedo obszaru roboczego jako wymagania wstępne.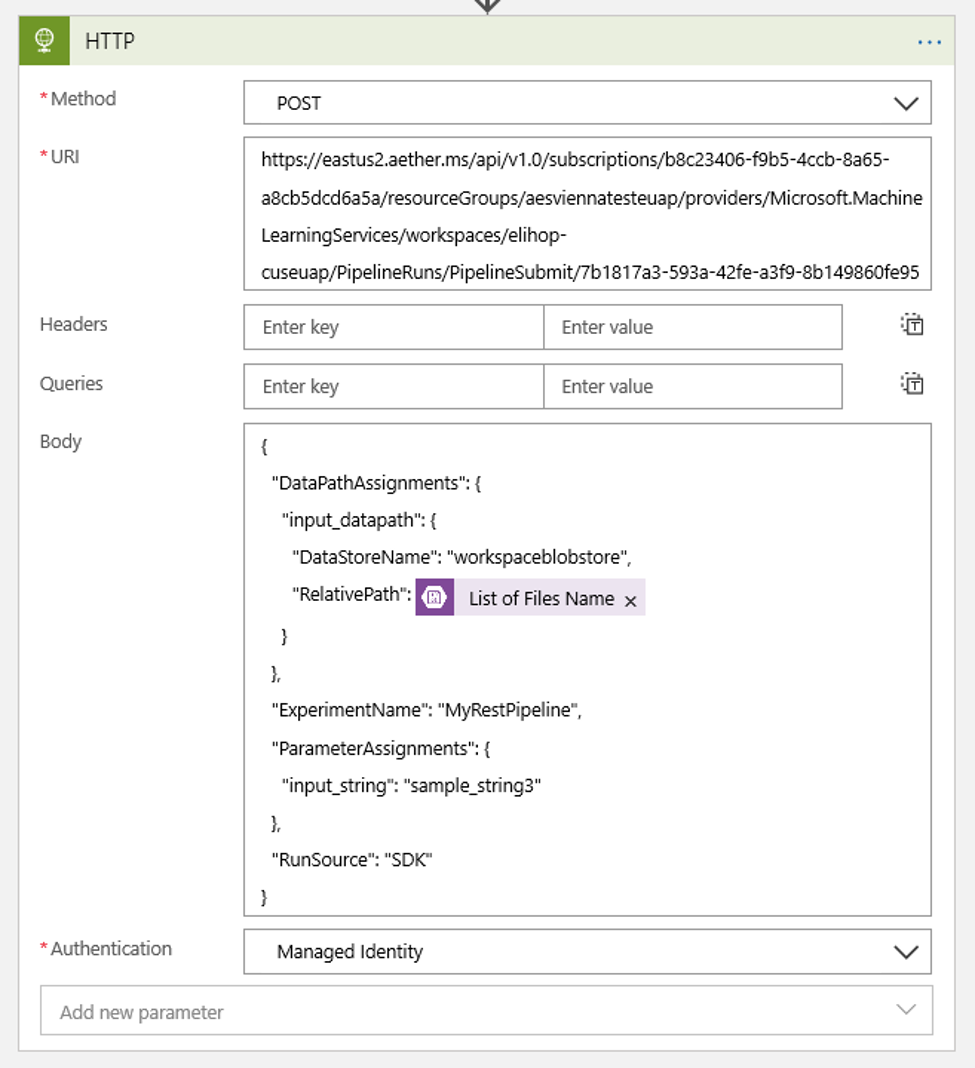
Wybierz pozycję Zapisz , a harmonogram jest teraz gotowy.
Ważne
Jeśli używasz kontroli dostępu opartej na rolach (RBAC) platformy Azure do zarządzania dostępem do potoku, ustaw uprawnienia dla scenariusza potoku (trenowanie lub ocenianie).
Wywoływanie potoków uczenia maszynowego z poziomu potoków usługi Azure Data Factory
W potoku usługi Azure Data Factory działanie Wykonywanie potoku usługi Machine Learning uruchamia potok usługi Azure Machine Learning. To działanie można znaleźć na stronie tworzenia usługi Data Factory w kategorii Machine Learning :
Następne kroki
W tym artykule użyto zestawu SDK usługi Azure Machine Learning dla języka Python do zaplanowana potoku na dwa różne sposoby. Jeden harmonogram jest powtarzany na podstawie czasu zegara, który upłynął. Inne zadania harmonogramu, jeśli plik jest modyfikowany w określonym Datastore lub w katalogu w tym magazynie. Pokazano, jak używać portalu do badania potoku i poszczególnych zadań. Wiesz już, jak wyłączyć harmonogram, aby potok przestał działać. Na koniec utworzono aplikację logiki platformy Azure w celu wyzwolenia potoku.
Aby uzyskać więcej informacji, zobacz:
- Dowiedz się więcej o potokach
- Dowiedz się więcej o eksplorowaniu usługi Azure Machine Learning za pomocą programu Jupyter
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla