Tworzenie i uruchamianie potoków uczenia maszynowego za pomocą zestawu Azure Machine Learning SDK
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Z tego artykułu dowiesz się, jak tworzyć i uruchamiać potoki uczenia maszynowego przy użyciu zestawu SDK usługi Azure Machine Learning. Użyj potoków uczenia maszynowego, aby utworzyć przepływ pracy, który łączy różne fazy uczenia maszynowego. Następnie opublikuj ten potok na potrzeby późniejszego dostępu lub udostępniania innym osobom. Śledź potoki uczenia maszynowego, aby zobaczyć, jak działa model w świecie rzeczywistym i wykrywać dryf danych. Potoki uczenia maszynowego są idealne w przypadku scenariuszy oceniania wsadowego, przy użyciu różnych obliczeń, ponownego użycia kroków zamiast ponownego uruchamiania i udostępniania przepływów pracy uczenia maszynowego innym osobom.
Ten artykuł nie jest samouczkiem. Aby uzyskać wskazówki dotyczące tworzenia pierwszego potoku, zobacz Samouczek: tworzenie potoku usługi Azure Machine Learning na potrzeby oceniania wsadowego lub Używanie zautomatyzowanego uczenia maszynowego w potoku usługi Azure Machine Learning w języku Python.
Chociaż można użyć innego rodzaju potoku o nazwie Azure Pipeline na potrzeby automatyzacji ciągłej integracji/ciągłego wdrażania zadań uczenia maszynowego, ten typ potoku nie jest przechowywany w obszarze roboczym. Porównaj te różne potoki.
Utworzone potoki uczenia maszynowego są widoczne dla członków obszaru roboczego usługi Azure Machine Learning.
Potoki uczenia maszynowego są wykonywane na docelowych obiektach obliczeniowych (zobacz Co to są cele obliczeniowe w usłudze Azure Machine Learning). Potoki mogą odczytywać i zapisywać dane do i z obsługiwanych lokalizacji usługi Azure Storage .
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Wymagania wstępne
Obszar roboczy usługi Azure Machine Learning. Tworzenie zasobów obszaru roboczego.
Skonfiguruj środowisko programistyczne, aby zainstalować zestaw SDK usługi Azure Machine Learning lub użyć wystąpienia obliczeniowego usługi Azure Machine Learning z już zainstalowanym zestawem SDK.
Zacznij od dołączenia obszaru roboczego:
import azureml.core
from azureml.core import Workspace, Datastore
ws = Workspace.from_config()
Konfigurowanie zasobów uczenia maszynowego
Utwórz zasoby wymagane do uruchomienia potoku uczenia maszynowego:
Skonfiguruj magazyn danych używany do uzyskiwania dostępu do danych wymaganych w krokach potoku.
DatasetSkonfiguruj obiekt tak, aby wskazywał trwałe dane, które mieszkają w magazynie danych lub są dostępne w magazynie danych.OutputFileDatasetConfigSkonfiguruj obiekt dla danych tymczasowych przekazywanych między krokami potoku.Skonfiguruj docelowe obiekty obliczeniowe, na których zostaną uruchomione kroki potoku.
Konfigurowanie magazynu danych
Magazyn danych przechowuje dane dla potoku w celu uzyskania dostępu. Każdy obszar roboczy ma domyślny magazyn danych. Możesz zarejestrować więcej magazynów danych.
Podczas tworzenia obszaru roboczego usługi Azure Files i Azure Blob Storage są dołączane do obszaru roboczego. Domyślny magazyn danych jest zarejestrowany w celu nawiązania połączenia z usługą Azure Blob Storage. Aby dowiedzieć się więcej, zobacz Wybieranie, kiedy używać usługi Azure Files, obiektów blob platformy Azure lub dysków platformy Azure.
# Default datastore
def_data_store = ws.get_default_datastore()
# Get the blob storage associated with the workspace
def_blob_store = Datastore(ws, "workspaceblobstore")
# Get file storage associated with the workspace
def_file_store = Datastore(ws, "workspacefilestore")
Kroki zwykle wykorzystują dane i generują dane wyjściowe. Krok może tworzyć dane, takie jak model, katalog z plikami modelowymi i zależnymi lub danymi tymczasowymi. Te dane są następnie dostępne dla innych kroków w dalszej części potoku. Aby dowiedzieć się więcej na temat łączenia potoku z danymi, zobacz artykuły Jak uzyskać dostęp do danych i Jak rejestrować zestawy danych.
Konfigurowanie danych za pomocą Dataset obiektów i OutputFileDatasetConfig
Preferowanym sposobem dostarczania danych do potoku jest obiekt Zestawu danych . Obiekt Dataset wskazuje dane, które mieszkają w magazynie danych lub są dostępne z magazynu danych lub pod adresem URL sieci Web. Klasa Dataset jest abstrakcyjna, więc utworzysz wystąpienie FileDataset elementu (odwołującego się do jednego lub większej liczby plików) lub utworzonego TabularDataset przez jeden lub więcej plików z rozdzielanymi kolumnami danych.
Dataset Tworzysz przy użyciu metod, takich jak from_files lub from_delimited_files.
from azureml.core import Dataset
my_dataset = Dataset.File.from_files([(def_blob_store, 'train-images/')])
Dane pośrednie (lub dane wyjściowe kroku) są reprezentowane przez obiekt OutputFileDatasetConfig . output_data1 jest generowany jako dane wyjściowe kroku. Opcjonalnie te dane można zarejestrować jako zestaw danych, wywołując metodę register_on_complete. Jeśli utworzysz element OutputFileDatasetConfig w jednym kroku i użyjesz go jako danych wejściowych do innego kroku, zależność danych między krokami tworzy niejawną kolejność wykonywania w potoku.
OutputFileDatasetConfig obiekty zwracają katalog i domyślnie zapisuje dane wyjściowe do domyślnego magazynu danych obszaru roboczego.
from azureml.data import OutputFileDatasetConfig
output_data1 = OutputFileDatasetConfig(destination = (datastore, 'outputdataset/{run-id}'))
output_data_dataset = output_data1.register_on_complete(name = 'prepared_output_data')
Ważne
Dane pośrednie przechowywane przy użyciu OutputFileDatasetConfig nie są automatycznie usuwane przez platformę Azure.
Należy programowo usunąć dane pośrednie na końcu uruchomienia potoku, użyć magazynu danych z krótkimi zasadami przechowywania danych lub regularnie ręcznie wyczyścić.
Napiwek
Przekazuj tylko te pliki, które są istotne dla danego zadania. Wszelkie zmiany w plikach w katalogu danych będą traktowane jako powód, aby ponownie uruchomić krok przy następnym uruchomieniu potoku, nawet jeśli zostanie określone ponowne użycie.
Konfigurowanie docelowego obiektu obliczeniowego
W usłudze Azure Machine Learning termin obliczenia (lub docelowy obiekt obliczeniowy) odnosi się do maszyn lub klastrów, które wykonują kroki obliczeniowe w potoku uczenia maszynowego. Zobacz Cele obliczeniowe na potrzeby trenowania modelu, aby uzyskać pełną listę celów obliczeniowych i Utwórz cele obliczeniowe, aby dowiedzieć się, jak utworzyć i dołączyć je do obszaru roboczego. Proces tworzenia i dołączania docelowego obiektu obliczeniowego jest taki sam, niezależnie od tego, czy trenujesz model, czy uruchamiasz krok potoku. Po utworzeniu i dołączeniu docelowego obiektu obliczeniowego ComputeTarget użyj obiektu w kroku potoku.
Ważne
Wykonywanie operacji zarządzania na docelowych obiektach obliczeniowych nie jest obsługiwane z poziomu zadań zdalnych. Potoki uczenia maszynowego są przesyłane jako zadania zdalne, dlatego nie należy używać operacji zarządzania na docelowych obiektach obliczeniowych z wnętrza potoku.
Obliczenia w usłudze Azure Machine Learning
Aby wykonać kroki, możesz utworzyć środowisko obliczeniowe usługi Azure Machine Learning. Kod dla innych celów obliczeniowych jest podobny, z nieco różnymi parametrami, w zależności od typu.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "aml-compute"
vm_size = "STANDARD_NC6"
if compute_name in ws.compute_targets:
compute_target = ws.compute_targets[compute_name]
if compute_target and type(compute_target) is AmlCompute:
print('Found compute target: ' + compute_name)
else:
print('Creating a new compute target...')
provisioning_config = AmlCompute.provisioning_configuration(vm_size=vm_size, # STANDARD_NC6 is GPU-enabled
min_nodes=0,
max_nodes=4)
# create the compute target
compute_target = ComputeTarget.create(
ws, compute_name, provisioning_config)
# Can poll for a minimum number of nodes and for a specific timeout.
# If no min node count is provided it will use the scale settings for the cluster
compute_target.wait_for_completion(
show_output=True, min_node_count=None, timeout_in_minutes=20)
# For a more detailed view of current cluster status, use the 'status' property
print(compute_target.status.serialize())
Konfigurowanie środowiska przebiegu trenowania
Następnym krokiem jest upewnienie się, że przebieg szkolenia zdalnego ma wszystkie zależności wymagane przez kroki trenowania. Zależności i kontekst środowiska uruchomieniowego są ustawiane przez utworzenie i skonfigurowanie RunConfiguration obiektu.
from azureml.core.runconfig import RunConfiguration
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import Environment
aml_run_config = RunConfiguration()
# `compute_target` as defined in "Azure Machine Learning compute" section above
aml_run_config.target = compute_target
USE_CURATED_ENV = True
if USE_CURATED_ENV :
curated_environment = Environment.get(workspace=ws, name="AzureML-sklearn-0.24-ubuntu18.04-py37-cpu")
aml_run_config.environment = curated_environment
else:
aml_run_config.environment.python.user_managed_dependencies = False
# Add some packages relied on by data prep step
aml_run_config.environment.python.conda_dependencies = CondaDependencies.create(
conda_packages=['pandas','scikit-learn'],
pip_packages=['azureml-sdk', 'azureml-dataset-runtime[fuse,pandas]'],
pin_sdk_version=False)
Powyższy kod przedstawia dwie opcje obsługi zależności. Jak pokazano, w programie USE_CURATED_ENV = Truekonfiguracja jest oparta na wyselekcjonowanych środowiskach. Wyselekcjonowane środowiska są "wstępnie połączone" z typowymi bibliotekami zależnymi i mogą być szybsze w trybie online. Wyselekcjonowane środowiska mają wstępnie utworzone obrazy platformy Docker w usłudze Microsoft Container Registry. Aby uzyskać więcej informacji, zobacz Azure Machine Learning wyselekcjonowane środowiska.
Ścieżka wykonywana w przypadku zmiany USE_CURATED_ENV w celu pokazania False wzorca jawnego ustawiania zależności. W tym scenariuszu zostanie utworzony i zarejestrowany nowy niestandardowy obraz platformy Docker w usłudze Azure Container Registry w grupie zasobów (zobacz Wprowadzenie do prywatnych rejestrów kontenerów platformy Docker na platformie Azure). Tworzenie i rejestrowanie tego obrazu może potrwać sporo minut.
Konstruowanie kroków potoku
Po utworzeniu zasobu obliczeniowego i środowiska możesz zdefiniować kroki potoku. Istnieje wiele wbudowanych kroków dostępnych za pośrednictwem zestawu AZURE Machine Learning SDK, jak można znaleźć w dokumentacji referencyjnej azureml.pipeline.steps pakietu. Najbardziej elastyczna klasa to PythonScriptStep, który uruchamia skrypt języka Python.
from azureml.pipeline.steps import PythonScriptStep
dataprep_source_dir = "./dataprep_src"
entry_point = "prepare.py"
# `my_dataset` as defined above
ds_input = my_dataset.as_named_input('input1')
# `output_data1`, `compute_target`, `aml_run_config` as defined above
data_prep_step = PythonScriptStep(
script_name=entry_point,
source_directory=dataprep_source_dir,
arguments=["--input", ds_input.as_download(), "--output", output_data1],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Powyższy kod przedstawia typowy początkowy krok potoku. Kod przygotowywania danych znajduje się w podkatalogu (w tym przykładzie "prepare.py" w katalogu "./dataprep.src"). W ramach procesu tworzenia potoku ten katalog jest spakowany i przekazywany do compute_target elementu , a krok uruchamia skrypt określony jako wartość .script_name
Wartości arguments określają dane wejściowe i wyjściowe kroku. W powyższym przykładzie dane punktu odniesienia to my_dataset zestaw danych. Odpowiednie dane zostaną pobrane do zasobu obliczeniowego, ponieważ kod określa go jako as_download(). Skrypt prepare.py wykonuje dowolne zadania przekształcania danych, które są odpowiednie dla zadania podrzędnego, i generuje dane do output_data1typu , OutputFileDatasetConfigtypu . Aby uzyskać więcej informacji, zobacz Przenoszenie danych do i między krokami potoku uczenia maszynowego (Python).
Krok zostanie uruchomiony na maszynie zdefiniowanej przez compute_targetprogram przy użyciu konfiguracji aml_run_config.
Ponowne użycie poprzednich wyników (allow_reuse) jest kluczem podczas korzystania z potoków w środowisku współpracy, ponieważ wyeliminowanie niepotrzebnych ponownych uruchomień zapewnia elastyczność. Ponowne użycie jest zachowaniem domyślnym, gdy script_name, dane wejściowe i parametry kroku pozostają takie same. Gdy ponowne użycie jest dozwolone, wyniki z poprzedniego przebiegu są natychmiast wysyłane do następnego kroku. Jeśli allow_reuse jest ustawiona wartość False, nowy przebieg będzie zawsze generowany dla tego kroku podczas wykonywania potoku.
Istnieje możliwość utworzenia potoku z jednym krokiem, ale prawie zawsze zdecydujesz się podzielić ogólny proces na kilka kroków. Możesz na przykład wykonać kroki przygotowywania danych, trenowania, porównywania modeli i wdrażania. Można na przykład sobie wyobrazić, że po określeniu data_prep_step powyżej następnym krokiem może być trenowanie:
train_source_dir = "./train_src"
train_entry_point = "train.py"
training_results = OutputFileDatasetConfig(name = "training_results",
destination = def_blob_store)
train_step = PythonScriptStep(
script_name=train_entry_point,
source_directory=train_source_dir,
arguments=["--prepped_data", output_data1.as_input(), "--training_results", training_results],
compute_target=compute_target,
runconfig=aml_run_config,
allow_reuse=True
)
Powyższy kod jest podobny do kodu w kroku przygotowywania danych. Kod szkoleniowy znajduje się w katalogu oddzielnym od kodu przygotowywania danych. Dane OutputFileDatasetConfig wyjściowe kroku output_data1 przygotowywania danych są używane jako dane wejściowe do kroku trenowania. Zostanie utworzony nowy OutputFileDatasetConfig obiekt w training_results celu przechowywania wyników dla późniejszego porównania lub kroku wdrożenia.
Aby zapoznać się z innymi przykładami kodu, zobacz, jak utworzyć dwuetapowy potok uczenia maszynowego i jak zapisywać dane z powrotem do magazynów danych po zakończeniu wykonywania.
Po zdefiniowaniu kroków należy skompilować potok przy użyciu niektórych lub wszystkich tych kroków.
Uwaga
Podczas definiowania kroków lub tworzenia potoku nie są przekazywane żadne pliki lub dane do usługi Azure Machine Learning. Pliki są przekazywane po wywołaniu metody Experiment.submit().
# list of steps to run (`compare_step` definition not shown)
compare_models = [data_prep_step, train_step, compare_step]
from azureml.pipeline.core import Pipeline
# Build the pipeline
pipeline1 = Pipeline(workspace=ws, steps=[compare_models])
Korzystanie z zestawu danych
Zestawy danych utworzone na podstawie usługi Azure Blob Storage, Azure Files, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure SQL Database i Azure Database for PostgreSQL mogą służyć jako dane wejściowe do dowolnego kroku potoku. Dane wyjściowe można zapisywać w obiekcie DataTransferStep, DatabricksStep lub jeśli chcesz zapisać dane w określonym magazynie danych, użyj parametru OutputFileDatasetConfig.
Ważne
Zapisywanie danych wyjściowych z powrotem do magazynu danych za pomocą obiektu OutputFileDatasetConfig jest obsługiwane tylko w przypadku magazynów danych obiektów blob platformy Azure, udziału plików platformy Azure oraz magazynów danych usługi ADLS Gen 1 i Gen 2.
dataset_consuming_step = PythonScriptStep(
script_name="iris_train.py",
inputs=[iris_tabular_dataset.as_named_input("iris_data")],
compute_target=compute_target,
source_directory=project_folder
)
Następnie pobierz zestaw danych w potoku przy użyciu słownika Run.input_datasets .
# iris_train.py
from azureml.core import Run, Dataset
run_context = Run.get_context()
iris_dataset = run_context.input_datasets['iris_data']
dataframe = iris_dataset.to_pandas_dataframe()
Linia Run.get_context() jest warta wyróżnienia. Ta funkcja pobiera Run bieżący przebieg eksperymentalny. W powyższym przykładzie używamy go do pobierania zarejestrowanego zestawu danych. Innym typowym zastosowaniem obiektu jest pobranie zarówno samego eksperymentu Run , jak i obszaru roboczego, w którym znajduje się eksperyment:
# Within a PythonScriptStep
ws = Run.get_context().experiment.workspace
Aby uzyskać więcej szczegółów, w tym alternatywne sposoby przekazywania danych i uzyskiwania do nich dostępu, zobacz Przenoszenie danych do i między krokami potoku uczenia maszynowego (Python).
Buforowanie i ponowne używanie
Aby zoptymalizować i dostosować zachowanie potoków, możesz wykonać kilka czynności związanych z buforowaniem i ponownym użyciem. Możesz na przykład:
- Wyłącz domyślne ponowne użycie danych wyjściowych przebiegu kroku, ustawiając ustawienie
allow_reuse=Falsepodczas definicji kroku. Ponowne użycie jest kluczem podczas korzystania z potoków w środowisku współpracy, ponieważ wyeliminowanie niepotrzebnych przebiegów zapewnia elastyczność. Można jednak zrezygnować z ponownego użycia. - Wymuś ponowne generowanie danych wyjściowych dla wszystkich kroków w przebiegu za pomocą polecenia
pipeline_run = exp.submit(pipeline, regenerate_outputs=True)
Domyślnie allow_reuse dla kroków jest włączona, a source_directory parametr określony w definicji kroku jest skrótem. Dlatego jeśli skrypt dla danego kroku pozostanie taki sam (script_name, dane wejściowe i parametry), a nic innego w source_directory elemecie uległo zmianie, dane wyjściowe poprzedniego uruchomienia kroku zostaną ponownie użyte, zadanie nie zostanie przesłane do obliczeń, a wyniki z poprzedniego uruchomienia są natychmiast dostępne do następnego kroku.
step = PythonScriptStep(name="Hello World",
script_name="hello_world.py",
compute_target=aml_compute,
source_directory=source_directory,
allow_reuse=False,
hash_paths=['hello_world.ipynb'])
Uwaga
Jeśli nazwy danych wejściowych zmienią się, krok zostanie ponownie uruchomiony, nawet jeśli dane bazowe nie zmienią się. Należy jawnie ustawić name pole danych wejściowych (data.as_input(name=...)). Jeśli ta wartość nie zostanie jawnie ustawiona, name pole zostanie ustawione na losowy identyfikator GUID, a wyniki kroku nie zostaną ponownie użyte.
Przesyłanie potoku
Po przesłaniu potoku usługa Azure Machine Learning sprawdza zależności dla każdego kroku i przekazuje migawkę określonego katalogu źródłowego. Jeśli nie określono żadnego katalogu źródłowego, bieżący katalog lokalny zostanie przekazany. Migawka jest również przechowywana w ramach eksperymentu w obszarze roboczym.
Ważne
Aby zapobiec dołączaniu niepotrzebnych plików do migawki, utwórz plik ignoruj (.gitignore lub .amlignore) w katalogu. Dodaj do tego pliku katalogi i pliki do wykluczenia. Aby uzyskać więcej informacji na temat składni używanej w tym pliku, zobacz składnię i wzorce dla programu .gitignore. Plik .amlignore używa tej samej składni. Jeśli oba pliki istnieją, .amlignore zostanie użyty plik, a .gitignore plik jest nieużywany.
Aby uzyskać więcej informacji, zobacz Migawki.
from azureml.core import Experiment
# Submit the pipeline to be run
pipeline_run1 = Experiment(ws, 'Compare_Models_Exp').submit(pipeline1)
pipeline_run1.wait_for_completion()
Po pierwszym uruchomieniu potoku usługa Azure Machine Learning:
Pobiera migawkę projektu do docelowego obiektu obliczeniowego z magazynu obiektów blob skojarzonych z obszarem roboczym.
Tworzy obraz platformy Docker odpowiadający każdemu krokowi w potoku.
Pobiera obraz platformy Docker dla każdego kroku do docelowego obiektu obliczeniowego z rejestru kontenerów.
Konfiguruje dostęp do
Datasetobiektów i .OutputFileDatasetConfigWas_mount()przypadku trybu dostępu program FUSE jest używany do zapewnienia dostępu wirtualnego. Jeśli instalacja nie jest obsługiwana lub jeśli użytkownik określił dostęp jakoas_upload(), dane są zamiast tego kopiowane do docelowego obiektu obliczeniowego.Uruchamia krok w docelowym obiekcie obliczeniowym określonym w definicji kroku.
Tworzy artefakty, takie jak dzienniki, stdout i stderr, metryki i dane wyjściowe określone przez krok. Te artefakty są następnie przekazywane i przechowywane w domyślnym magazynie danych użytkownika.
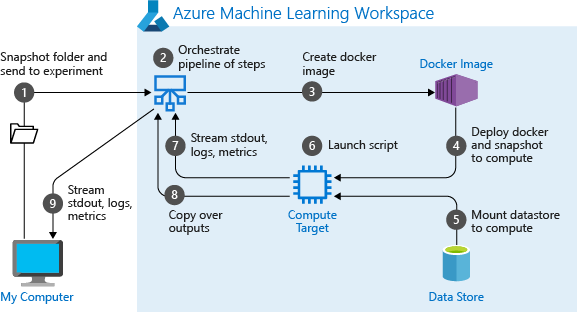
Aby uzyskać więcej informacji, zobacz dokumentację klasy Experiment.
Użyj parametrów potoku dla argumentów, które zmieniają się w czasie wnioskowania
Czasami argumenty poszczególnych kroków w potoku odnoszą się do okresu programowania i trenowania: takie rzeczy jak współczynniki trenowania i tempo, lub ścieżki do danych lub plików konfiguracji. Po wdrożeniu modelu należy jednak dynamicznie przekazać argumenty, na których jest wnioskowanie (czyli zapytanie utworzone w celu udzielenia odpowiedzi!). Należy ustawić te typy parametrów potoku argumentów. Aby to zrobić w języku Python, użyj azureml.pipeline.core.PipelineParameter klasy , jak pokazano w poniższym fragmencie kodu:
from azureml.pipeline.core import PipelineParameter
pipeline_param = PipelineParameter(name="pipeline_arg", default_value="default_val")
train_step = PythonScriptStep(script_name="train.py",
arguments=["--param1", pipeline_param],
target=compute_target,
source_directory=project_folder)
Jak środowiska języka Python działają z parametrami potoku
Jak opisano wcześniej w temacie Konfigurowanie środowiska przebiegu trenowania, stanu środowiska i zależności biblioteki języka Python są określane przy użyciu Environment obiektu. Ogólnie rzecz biorąc, można określić istniejącą, Environment odwołując się do jej nazwy i opcjonalnie, wersję:
aml_run_config = RunConfiguration()
aml_run_config.environment.name = 'MyEnvironment'
aml_run_config.environment.version = '1.0'
Jeśli jednak zdecydujesz się używać PipelineParameter obiektów do dynamicznego ustawiania zmiennych w czasie wykonywania kroków potoku, nie można użyć tej techniki odwoływania się do istniejącego Environmentelementu . Zamiast tego, jeśli chcesz używać PipelineParameter obiektów, musisz ustawić environment pole obiektu RunConfiguration na Environment obiekt. Twoim zadaniem jest upewnienie się, że takie Environment jednostki mają odpowiednie zależności od zewnętrznych pakietów języka Python.
Wyświetlanie wyników potoku
Zapoznaj się z listą wszystkich potoków i ich szczegółów uruchamiania w programie Studio:
Zaloguj się do usługi Azure Machine Learning Studio.
Po lewej stronie wybierz pozycję Potoki , aby wyświetlić wszystkie uruchomienia potoku.
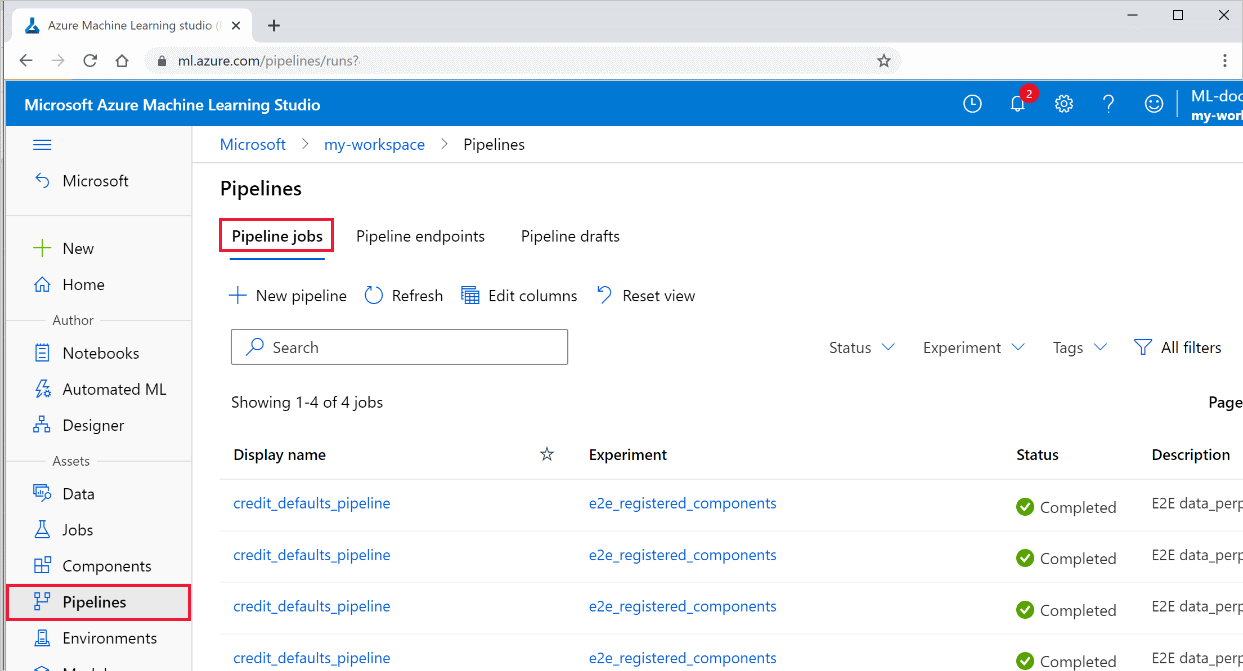
Wybierz określony potok, aby wyświetlić wyniki przebiegu.
Śledzenie i integracja z usługą Git
Po uruchomieniu przebiegu trenowania, w którym katalog źródłowy jest lokalnym repozytorium Git, informacje o repozytorium są przechowywane w historii uruchamiania. Aby uzyskać więcej informacji, zobacz Integracja z usługą Git dla usługi Azure Machine Learning.
Następne kroki
- Aby udostępnić potok współpracownikom lub klientom, zobacz Publikowanie potoków uczenia maszynowego
- Użyj tych notesów Jupyter w usłudze GitHub , aby dokładniej eksplorować potoki uczenia maszynowego
- Zobacz pomoc dotyczącą zestawu SDK dla pakietu azureml-pipelines-core i pakietu azureml-pipelines-steps
- Zapoznaj się z instrukcjami, aby uzyskać porady dotyczące debugowania i rozwiązywania problemów z potokami=
- Instrukcję uruchamiania notesów znajdziesz w artykule Use Jupyter notebooks to explore this service (Eksplorowanie tej usługi za pomocą notesów Jupyter).