Śledzenie eksperymentów uczenia maszynowego w usłudze Azure Databricks za pomocą platformy MLflow i usługi Azure Machine Learning
MLflow to biblioteka typu open source do zarządzania cyklem życia eksperymentów uczenia maszynowego. Za pomocą platformy MLflow możesz zintegrować usługę Azure Databricks z usługą Azure Machine Learning, aby zapewnić najlepsze wyniki z obu produktów.
W tym artykule podano informacje o:
- Wymagane biblioteki potrzebne do korzystania z bibliotek MLflow z usługami Azure Databricks i Azure Machine Learning.
- Jak śledzić przebiegi usługi Azure Databricks za pomocą biblioteki MLflow w usłudze Azure Machine Learning.
- Jak rejestrować modele za pomocą biblioteki MLflow , aby je zarejestrować w usłudze Azure Machine Learning.
- Jak wdrażać i korzystać z modeli zarejestrowanych w usłudze Azure Machine Learning.
Wymagania wstępne
- Pakiet
azureml-mlflow, który obsługuje łączność z usługą Azure Machine Learning, w tym uwierzytelnianie. - Obszar roboczy i klaster usługi Azure Databricks.
- Obszar roboczy usługi Azure Machine Learning.
Sprawdź, które uprawnienia dostępu są potrzebne do wykonywania operacji platformy MLflow w obszarze roboczym.
Przykładowe notesy
Modele trenowania w usłudze Azure Databricks i ich wdrażanie w repozytorium usługi Azure Machine Learning pokazują, jak trenować modele w usłudze Azure Databricks i wdrażać je w usłudze Azure Machine Learning. W tym artykule opisano również sposób śledzenia eksperymentów i modeli za pomocą wystąpienia platformy MLflow w usłudze Azure Databricks. W tym artykule opisano sposób używania usługi Azure Machine Learning do wdrożenia.
Instalowanie bibliotek
Aby zainstalować biblioteki w klastrze:
Przejdź do karty Biblioteki i wybierz pozycję Zainstaluj nowy.
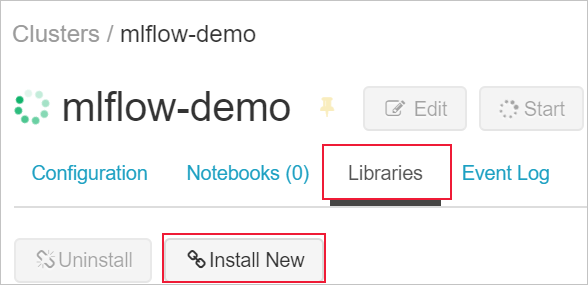
W polu Pakiet wpisz azureml-mlflow, a następnie wybierz pozycję Zainstaluj. Powtórz ten krok w razie potrzeby, aby zainstalować inne pakiety w klastrze na potrzeby eksperymentu.
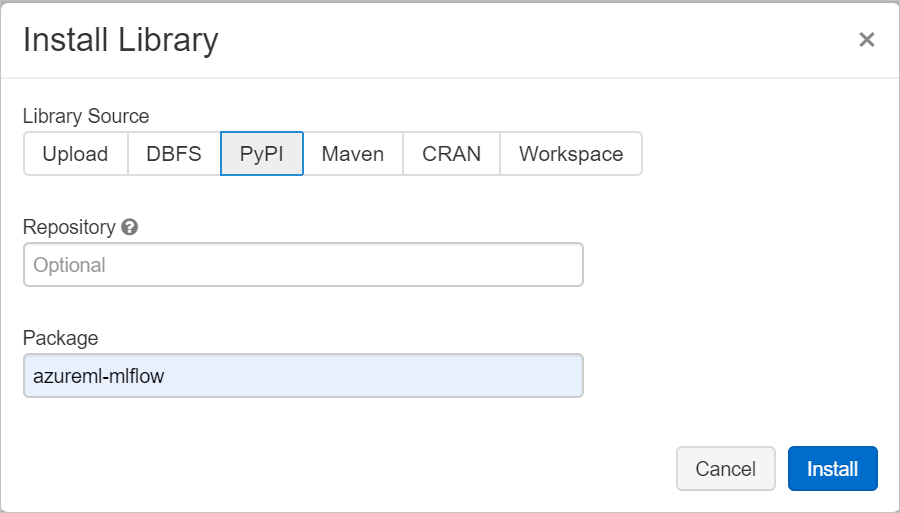
Śledzenie przebiegów usługi Azure Databricks za pomocą platformy MLflow
Usługę Azure Databricks można skonfigurować do śledzenia eksperymentów przy użyciu platformy MLflow na dwa sposoby:
- Śledzenie zarówno w obszarze roboczym usługi Azure Databricks, jak i w obszarze roboczym usługi Azure Machine Learning (śledzenie podwójne)
- Śledzenie wyłącznie w usłudze Azure Machine Learning
Domyślnie po połączeniu obszaru roboczego usługi Azure Databricks zostanie skonfigurowane podwójne śledzenie.
Podwójne śledzenie w usłudze Azure Databricks i usłudze Azure Machine Learning
Łączenie obszaru roboczego usługi Azure Databricks z obszarem roboczym usługi Azure Machine Learning umożliwia śledzenie danych eksperymentu w obszarze roboczym usługi Azure Machine Learning i obszarze roboczym usługi Azure Databricks w tym samym czasie. Ta konfiguracja jest nazywana śledzeniem podwójnym.
Podwójne śledzenie w obszarze roboczym usługi Azure Machine Learning z obsługą łącza prywatnego nie jest obecnie obsługiwane. Zamiast tego skonfiguruj śledzenie na wyłączność za pomocą obszaru roboczego usługi Azure Machine Learning.
Podwójne śledzenie nie jest obecnie obsługiwane na platformie Microsoft Azure obsługiwanej przez firmę 21Vianet. Zamiast tego skonfiguruj śledzenie na wyłączność za pomocą obszaru roboczego usługi Azure Machine Learning.
Aby połączyć obszar roboczy usługi Azure Databricks z nowym lub istniejącym obszarem roboczym usługi Azure Machine Learning:
Zaloguj się w witrynie Azure Portal.
Przejdź do strony Przegląd obszaru roboczego usługi Azure Databricks.
Wybierz pozycję Połącz obszar roboczy usługi Azure Machine Learning.
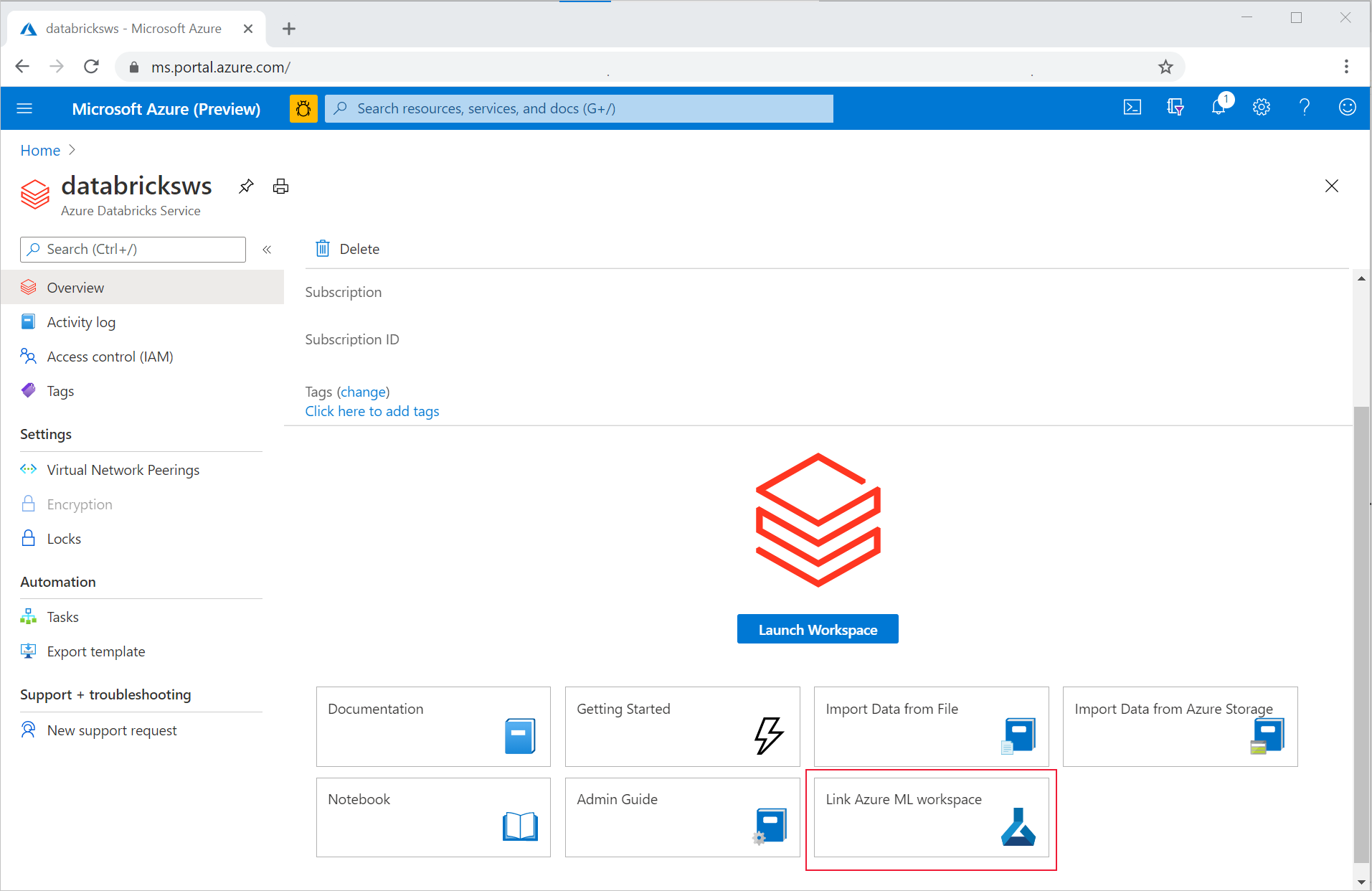

Po połączeniu obszaru roboczego usługi Azure Databricks z obszarem roboczym usługi Azure Machine Learning śledzenie platformy MLflow jest automatycznie śledzone w następujących miejscach:
- Połączony obszar roboczy usługi Azure Machine Learning.
- Oryginalny obszar roboczy usługi Azure Databricks.
Następnie możesz użyć biblioteki MLflow w usłudze Azure Databricks w taki sam sposób, jak wcześniej. W poniższym przykładzie nazwa eksperymentu jest ustawiana jak zwykle w usłudze Azure Databricks i rozpoczyna rejestrowanie niektórych parametrów.
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Uwaga
W przeciwieństwie do śledzenia rejestry modeli nie obsługują rejestrowania modeli w tym samym czasie zarówno w usłudze Azure Machine Learning, jak i w usłudze Azure Databricks. Aby uzyskać więcej informacji, zobacz Rejestrowanie modeli w rejestrze za pomocą biblioteki MLflow.
Śledzenie wyłącznie w obszarze roboczym usługi Azure Machine Learning
Jeśli wolisz zarządzać śledzonych eksperymentów w scentralizowanej lokalizacji, możesz ustawić śledzenie MLflow tak, aby śledzić tylko w obszarze roboczym usługi Azure Machine Learning. Ta konfiguracja ma zaletę włączania łatwiejszej ścieżki wdrażania przy użyciu opcji wdrażania usługi Azure Machine Learning.
Ostrzeżenie
W przypadku obszaru roboczego usługi Azure Machine Learning z obsługą łącza prywatnego należy wdrożyć usługę Azure Databricks we własnej sieci (iniekcja sieci wirtualnej), aby zapewnić odpowiednią łączność.
Skonfiguruj identyfikator URI śledzenia MLflow, aby wskazywał wyłącznie usługę Azure Machine Learning, jak pokazano w poniższym przykładzie:
Konfigurowanie identyfikatora URI śledzenia
Pobierz identyfikator URI śledzenia dla obszaru roboczego.
DOTYCZY:
 Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)Zaloguj się i skonfiguruj obszar roboczy.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Identyfikator URI śledzenia można uzyskać przy użyciu
az ml workspacepolecenia .az ml workspace show --query mlflow_tracking_uri
Skonfiguruj identyfikator URI śledzenia.
Metoda
set_tracking_uri()wskazuje identyfikator URI śledzenia MLflow na ten identyfikator URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
Napiwek
Podczas pracy ze środowiskami udostępnionymi, takimi jak klaster usługi Azure Databricks, klaster usługi Azure Synapse Analytics lub podobny, można ustawić zmienną środowiskową MLFLOW_TRACKING_URI na poziomie klastra. Takie podejście umożliwia automatyczne skonfigurowanie identyfikatora URI śledzenia MLflow w taki sposób, aby wskazywały usługę Azure Machine Learning dla wszystkich sesji uruchomionych w klastrze, a nie na potrzeby poszczególnych sesji.
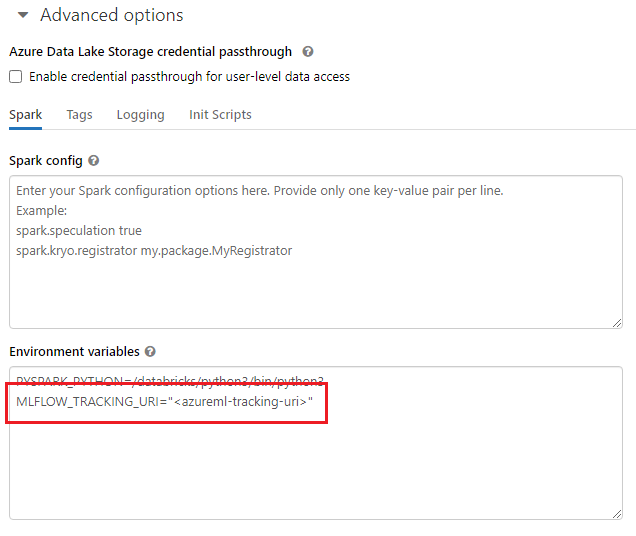
Po skonfigurowaniu zmiennej środowiskowej każdy eksperyment uruchomiony w takim klastrze jest śledzony w usłudze Azure Machine Learning.
Konfiguruj uwierzytelnianie
Po skonfigurowaniu śledzenia skonfiguruj sposób uwierzytelniania w skojarzonym obszarze roboczym. Domyślnie wtyczka usługi Azure Machine Learning dla platformy MLflow otwiera przeglądarkę, aby interaktywnie monitować o poświadczenia. Aby uzyskać inne sposoby konfigurowania uwierzytelniania dla platformy MLflow w obszarach roboczych usługi Azure Machine Learning, zobacz Konfigurowanie biblioteki MLflow dla usługi Azure Machine Learning: Konfigurowanie uwierzytelniania.
W przypadku zadań interaktywnych, w których istnieje użytkownik połączony z sesją, można polegać na uwierzytelnianiu interakcyjnym i dlatego nie jest wymagana żadna dalsza akcja.
Ostrzeżenie
Uwierzytelnianie interakcyjne przeglądarki blokuje wykonywanie kodu po wyświetleniu monitu o podanie poświadczeń. Takie podejście nie jest odpowiednie do uwierzytelniania w środowiskach nienadzorowanych, takich jak zadania szkoleniowe. Zalecamy skonfigurowanie innego trybu uwierzytelniania.
W przypadku tych scenariuszy, w których wymagane jest nienadzorowane wykonanie, należy skonfigurować jednostkę usługi do komunikowania się z usługą Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Napiwek
Podczas pracy nad środowiskami udostępnionymi zalecamy skonfigurowanie tych zmiennych środowiskowych w obliczeniach. Najlepszym rozwiązaniem jest zarządzanie nimi jako wpisami tajnymi w wystąpieniu usługi Azure Key Vault.
Na przykład w usłudze Azure Databricks można używać wpisów tajnych w zmiennych środowiskowych w następujący sposób w konfiguracji klastra: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Aby uzyskać więcej informacji na temat implementowania tego podejścia w usłudze Azure Databricks, zobacz Odwołanie do wpisu tajnego w zmiennej środowiskowej lub zapoznaj się z dokumentacją platformy.
Eksperyment nazw w usłudze Azure Machine Learning
Podczas konfigurowania platformy MLflow do wyłącznego śledzenia eksperymentów w obszarze roboczym usługi Azure Machine Learning konwencja nazewnictwa eksperymentów musi być stosowana zgodnie z konwencją nazewnictwa używaną przez usługę Azure Machine Learning. W usłudze Azure Databricks eksperymenty mają nazwę ze ścieżką do miejsca zapisania eksperymentu, na przykład /Users/alice@contoso.com/iris-classifier. Jednak w usłudze Azure Machine Learning należy podać nazwę eksperymentu bezpośrednio. Ten sam eksperyment zostanie nazwany iris-classifier bezpośrednio.
mlflow.set_experiment(experiment_name="experiment-name")
Śledzenie parametrów, metryk i artefaktów
Po tej konfiguracji możesz użyć biblioteki MLflow w usłudze Azure Databricks w taki sam sposób, jak w przypadku użycia. Aby uzyskać więcej informacji, zobacz Dzienniki i wyświetlanie metryk i plików dziennika.
Modele dzienników za pomocą biblioteki MLflow
Po wytrenowaniu modelu możesz zarejestrować go na serwerze śledzenia przy użyciu mlflow.<model_flavor>.log_model() metody . <model_flavor> odnosi się do struktury skojarzonej z modelem. Dowiedz się, jakie smaki modeli są obsługiwane.
W poniższym przykładzie jest rejestrowany model utworzony za pomocą biblioteki Spark MLLib.
mlflow.spark.log_model(model, artifact_path = "model")
Smak spark nie odpowiada faktowi, że trenujesz model w klastrze Spark. Zamiast tego wynika to z używanej platformy szkoleniowej. Model można wytrenować przy użyciu biblioteki TensorFlow z platformą Spark. Smak do użycia to tensorflow.
Modele są rejestrowane wewnątrz śledzonego przebiegu. Oznacza to, że modele są dostępne zarówno w usłudze Azure Databricks, jak i w usłudze Azure Machine Learning (wartość domyślna) lub wyłącznie w usłudze Azure Machine Learning, jeśli skonfigurowano identyfikator URI śledzenia w taki sposób, aby wskazywał.
Ważne
Nie określono parametru registered_model_name . Aby uzyskać więcej informacji na temat tego parametru i rejestru, zobacz Rejestrowanie modeli w rejestrze za pomocą biblioteki MLflow.
Rejestrowanie modeli w rejestrze za pomocą biblioteki MLflow
W przeciwieństwie do śledzenia rejestry modeli nie mogą działać w tym samym czasie w usługach Azure Databricks i Azure Machine Learning. Muszą używać jednego lub drugiego. Domyślnie rejestry modeli używają obszaru roboczego usługi Azure Databricks. Jeśli zdecydujesz się ustawić śledzenie MLflow na śledzenie tylko w obszarze roboczym usługi Azure Machine Learning, rejestr modeli jest obszarem roboczym usługi Azure Machine Learning.
Jeśli używasz konfiguracji domyślnej, poniższy kod rejestruje model wewnątrz odpowiednich przebiegów usług Azure Databricks i Azure Machine Learning, ale rejestruje go tylko w usłudze Azure Databricks.
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- Jeśli zarejestrowany model o nazwie nie istnieje, metoda rejestruje nowy model, tworzy wersję 1 i zwraca
ModelVersionobiekt MLflow. - Jeśli zarejestrowany model o nazwie już istnieje, metoda tworzy nową wersję modelu i zwraca obiekt wersji.
Korzystanie z rejestru usługi Azure Machine Learning z rozwiązaniem MLflow
Jeśli chcesz użyć usługi Azure Machine Learning Model Registry zamiast usługi Azure Databricks, zalecamy ustawienie śledzenia platformy MLflow tak, aby było śledzone tylko w obszarze roboczym usługi Azure Machine Learning. Takie podejście eliminuje niejednoznaczność miejsc, w których są rejestrowane modele i upraszcza konfigurację.
Jeśli chcesz nadal korzystać z funkcji podwójnego śledzenia, ale zarejestrować modele w usłudze Azure Machine Learning, możesz poinstruować platformę MLflow, aby korzystała z usługi Azure Machine Learning dla rejestrów modeli, konfigurując identyfikator URI rejestru modeli MLflow. Ten identyfikator URI ma ten sam format i wartość, która śledzi identyfikator URI.
mlflow.set_registry_uri(azureml_mlflow_uri)
Uwaga
Wartość azureml_mlflow_uri elementu została uzyskana w taki sam sposób, jak opisano w temacie Ustawianie śledzenia MLflow w celu śledzenia tylko w obszarze roboczym usługi Azure Machine Learning.
Pełny przykład tego scenariusza można znaleźć w temacie Training models in Azure Databricks (Trenowanie modeli w usłudze Azure Databricks) i wdrażanie ich w usłudze Azure Machine Learning.
Wdrażanie i używanie modeli zarejestrowanych w usłudze Azure Machine Learning
Modele zarejestrowane w usłudze Azure Machine Learning Service przy użyciu platformy MLflow mogą być używane jako:
- Punkt końcowy usługi Azure Machine Learning (w czasie rzeczywistym i partia). To wdrożenie umożliwia korzystanie z funkcji wdrażania usługi Azure Machine Learning na potrzeby wnioskowania w czasie rzeczywistym i wsadowego w usłudze Azure Container Instances, Azure Kubernetes lub zarządzanych punktów końcowych wnioskowania.
- Obiekty modelu MLFlow lub funkcje zdefiniowane przez użytkownika biblioteki Pandas (UDF), które mogą być używane w notesach usługi Azure Databricks w potokach przesyłania strumieniowego lub wsadowego.
Wdrażanie modeli w punktach końcowych usługi Azure Machine Learning
Wtyczka azureml-mlflow umożliwia wdrożenie modelu w obszarze roboczym usługi Azure Machine Learning. Aby uzyskać więcej informacji na temat wdrażania modeli w różnych miejscach docelowych Jak wdrożyć modele MLflow.
Ważne
Aby je wdrożyć, należy zarejestrować modele w rejestrze usługi Azure Machine Learning. Jeśli modele są zarejestrowane w wystąpieniu platformy MLflow w usłudze Azure Databricks, zarejestruj je ponownie w usłudze Azure Machine Learning. Aby uzyskać więcej informacji, zobacz Trenowanie modeli w usłudze Azure Databricks i wdrażanie ich w usłudze Azure Machine Learning
Wdrażanie modeli w usłudze Azure Databricks na potrzeby oceniania wsadowego przy użyciu funkcji zdefiniowanych przez użytkownika
Możesz wybrać klastry usługi Azure Databricks na potrzeby oceniania wsadowego. Za pomocą platformy Mlflow można rozpoznać dowolny model z rejestru, z którym masz połączenie. Zazwyczaj używasz jednej z następujących metod:
- Jeśli model został wytrenowany i skompilowany przy użyciu bibliotek platformy Spark, takich jak
MLLib, użyjmlflow.pyfunc.spark_udfpolecenia , aby załadować model i użyć go jako funkcji zdefiniowanej przez użytkownika platformy Spark Pandas w celu oceny nowych danych. - Jeśli model nie został wytrenowany lub skompilowany przy użyciu bibliotek platformy Spark, użyj
mlflow.pyfunc.load_modelmlflow.<flavor>.load_modellub załaduj model w sterowniku klastra. Należy zorganizować dowolną równoległą lub rozkład pracy, który ma nastąpić w klastrze. Platforma MLflow nie instaluje żadnej biblioteki wymaganej do uruchomienia modelu. Te biblioteki należy zainstalować w klastrze przed uruchomieniem.
W poniższym przykładzie pokazano, jak załadować model z rejestru o nazwie uci-heart-classifier i użyć go jako funkcji zdefiniowanej przez użytkownika platformy Spark Pandas w celu oceny nowych danych.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Aby uzyskać więcej sposobów odwoływania się do modeli z rejestru, zobacz Ładowanie modeli z rejestru.
Po załadowaniu modelu możesz użyć tego polecenia, aby ocenić nowe dane.
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Czyszczenie zasobów
Jeśli chcesz zachować obszar roboczy usługi Azure Databricks, ale nie potrzebujesz już obszaru roboczego usługi Azure Machine Learning, możesz usunąć obszar roboczy usługi Azure Machine Learning. Ta akcja powoduje odłączenie obszaru roboczego usługi Azure Databricks i obszaru roboczego usługi Azure Machine Learning.
Jeśli nie planujesz używania zarejestrowanych metryk i artefaktów w obszarze roboczym, usuń grupę zasobów zawierającą konto magazynu i obszar roboczy.
- W witrynie Azure Portal wyszukaj Grupy zasobów. W obszarze usługi wybierz pozycję Grupy zasobów.
- Na liście Grupy zasobów znajdź i wybierz utworzoną grupę zasobów, aby ją otworzyć.
- Na stronie Przegląd wybierz pozycję Usuń grupę zasobów.
- Aby zweryfikować usunięcie, wprowadź nazwę grupy zasobów.