Śledzenie eksperymentów i modeli uczenia maszynowego za pomocą biblioteki MLflow
Z tego artykułu dowiesz się, jak używać biblioteki MLflow do śledzenia eksperymentów i przebiegów w obszarach roboczych usługi Azure Machine Learning.
Śledzenie to proces zapisywania odpowiednich informacji o uruchamianych eksperymentach. Zapisane informacje (metadane) różnią się w zależności od projektu i mogą obejmować:
- Kod
- Szczegóły środowiska (takie jak wersja systemu operacyjnego, pakiety języka Python)
- Dane wejściowe
- Konfiguracje parametrów
- Modele
- Metryki oceny
- Wizualizacje ewaluacyjne (takie jak macierze pomyłek, wykresy ważności)
- Wyniki oceny (w tym niektóre przewidywania oceny)
Podczas pracy z zadaniami w usłudze Azure Machine Learning usługa Azure Machine Learning automatycznie śledzi niektóre informacje o eksperymentach, takie jak kod, środowisko i dane wejściowe i wyjściowe. Jednak w przypadku innych, takich jak modele, parametry i metryki, konstruktor modelu musi skonfigurować swoje śledzenie, ponieważ są one specyficzne dla konkretnego scenariusza.
Uwaga
Jeśli chcesz śledzić eksperymenty uruchomione w usłudze Azure Databricks, zobacz Track Azure Databricks ML experiments with MLflow and Azure Machine Learning (Śledzenie eksperymentów usługi Azure Databricks ML za pomocą platformy MLflow i usługi Azure Machine Learning). Aby dowiedzieć się więcej na temat śledzenia eksperymentów uruchomionych w usłudze Azure Synapse Analytics, zobacz Track Azure Synapse Analytics ML experiments with MLflow and Azure Machine Learning (Śledzenie eksperymentów usługi Azure Synapse Analytics ML za pomocą platformy MLflow i usługi Azure Machine Learning).
Zalety eksperymentów śledzenia
Zdecydowanie zalecamy śledzenie eksperymentów przez praktyków uczenia maszynowego niezależnie od tego, czy trenujesz zadania w usłudze Azure Machine Learning, czy też trenujesz interaktywnie w notesach. Śledzenie eksperymentów umożliwia:
- Organizuj wszystkie eksperymenty uczenia maszynowego w jednym miejscu. Następnie możesz wyszukiwać i filtrować eksperymenty oraz przechodzić do szczegółów, aby wyświetlić szczegółowe informacje o eksperymentach, które przeprowadzono wcześniej.
- Porównanie eksperymentów, analizowanie wyników i debugowanie trenowania modelu z niewielką ilością dodatkowych zadań.
- Odtwórz lub ponownie uruchom eksperymenty, aby zweryfikować wyniki.
- Zwiększ współpracę, ponieważ możesz zobaczyć, co robią inni koledzy z zespołu, udostępniać wyniki eksperymentów i uzyskiwać dostęp do danych eksperymentu programowo.
Dlaczego warto używać biblioteki MLflow do śledzenia eksperymentów?
Obszary robocze usługi Azure Machine Learning są zgodne z platformą MLflow, co oznacza, że możesz używać biblioteki MLflow do śledzenia przebiegów, metryk, parametrów i artefaktów w obszarach roboczych usługi Azure Machine Learning. Główną zaletą korzystania z biblioteki MLflow do śledzenia jest to, że nie trzeba zmieniać procedur szkoleniowych, aby pracować z usługą Azure Machine Learning ani wprowadzać żadnej składni specyficznej dla chmury.
Aby uzyskać więcej informacji na temat wszystkich obsługiwanych funkcji MLflow i Azure Machine Learning, zobacz MLflow i Azure Machine Learning.
Ograniczenia
Niektóre metody dostępne w interfejsie API platformy MLflow mogą nie być dostępne po nawiązaniu połączenia z usługą Azure Machine Learning. Aby uzyskać szczegółowe informacje na temat obsługiwanych i nieobsługiwanych operacji, zobacz Macierz obsługi dla przebiegów zapytań i eksperymentów.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Zainstaluj pakiet
mlflowzestawu MLflow SDK i wtyczkę usługi Azure Machine Learningazureml-mlflowdla biblioteki MLflow:pip install mlflow azureml-mlflowNapiwek
Możesz użyć
mlflow-skinnypakietu, który jest lekkim pakietem MLflow bez magazynu SQL, serwera, interfejsu użytkownika lub zależności nauki o danych.mlflow-skinnyjest zalecane dla użytkowników, którzy potrzebują głównie funkcji śledzenia i rejestrowania MLflow bez importowania pełnego zestawu funkcji, w tym wdrożeń.Obszar roboczy usługi Azure Machine Learning. Aby utworzyć obszar roboczy, zobacz samouczek Tworzenie zasobów uczenia maszynowego. Przejrzyj uprawnienia dostępu potrzebne do wykonywania operacji MLflow w obszarze roboczym.
Jeśli wykonujesz zdalne śledzenie (czyli śledzenie eksperymentów uruchomionych poza usługą Azure Machine Learning), skonfiguruj rozwiązanie MLflow, aby wskazywało identyfikator URI śledzenia obszaru roboczego usługi Azure Machine Learning. Aby uzyskać więcej informacji na temat łączenia platformy MLflow z obszarem roboczym, zobacz Konfigurowanie biblioteki MLflow dla usługi Azure Machine Learning.
Konfigurowanie eksperymentu
Platforma MLflow organizuje informacje w eksperymentach i przebiegach (uruchomienia są nazywane zadaniami w usłudze Azure Machine Learning). Domyślnie przebiegi są rejestrowane w eksperymencie o nazwie Default , który jest automatycznie tworzony. Możesz skonfigurować eksperyment, w którym odbywa się śledzenie.
W przypadku interaktywnego szkolenia, takiego jak w notesie Jupyter, użyj polecenia mlflow.set_experiment()MLflow . Na przykład poniższy fragment kodu konfiguruje eksperyment:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Konfigurowanie przebiegu
Usługa Azure Machine Learning śledzi dowolne zadanie szkoleniowe w tym, co MLflow wywołuje przebieg. Użyj przebiegów, aby przechwycić wszystkie wykonywane przez zadanie przetwarzanie.
Gdy pracujesz interaktywnie, platforma MLflow zacznie śledzić procedurę trenowania natychmiast po próbie zarejestrowania informacji wymagających aktywnego uruchomienia. Na przykład śledzenie MLflow rozpoczyna się po zarejestrowaniu metryki, parametru lub rozpoczęcia cyklu trenowania, a funkcja automatycznego rejestrowania usługi Mlflow jest włączona. Jednak zwykle pomocne jest jawne uruchomienie przebiegu, szczególnie jeśli chcesz przechwycić całkowity czas eksperymentu w polu Czas trwania . Aby jawnie uruchomić przebieg, użyj polecenia mlflow.start_run().
Bez względu na to, czy uruchamiasz przebieg ręcznie, czy nie, w końcu musisz zatrzymać przebieg, aby usługa MLflow wiedziała, że przebieg eksperymentu jest wykonywany i może oznaczać stan przebiegu jako Ukończono. Aby zatrzymać przebieg, użyj polecenia mlflow.end_run().
Zdecydowanie zalecamy ręczne uruchamianie przebiegów, aby nie zapominać o ich zakończeniu podczas pracy w notesach.
Aby uruchomić przebieg ręcznie i zakończyć go po zakończeniu pracy w notesie:
mlflow.start_run() # Your code mlflow.end_run()Zazwyczaj warto użyć paradygmatu menedżera kontekstu, aby ułatwić zapamiętanie zakończenia przebiegu:
with mlflow.start_run() as run: # Your codePo uruchomieniu nowego przebiegu
mlflow.start_run()za pomocą polecenia może być przydatne określenierun_nameparametru, który później przekłada się na nazwę przebiegu w interfejsie użytkownika usługi Azure Machine Learning i pomoże ci zidentyfikować przebieg szybciej:with mlflow.start_run(run_name="hello-world-example") as run: # Your code
Włączanie automatycznego rejestrowania MLflow
Metryki, parametry i pliki można rejestrować ręcznie za pomocą biblioteki MLflow . Można jednak również polegać na funkcji automatycznego rejestrowania MLflow. Każda platforma uczenia maszynowego obsługiwana przez platformę MLflow decyduje o tym, co ma być śledzone automatycznie.
Aby włączyć automatyczne rejestrowanie, wstaw następujący kod przed kodem treningowym:
mlflow.autolog()
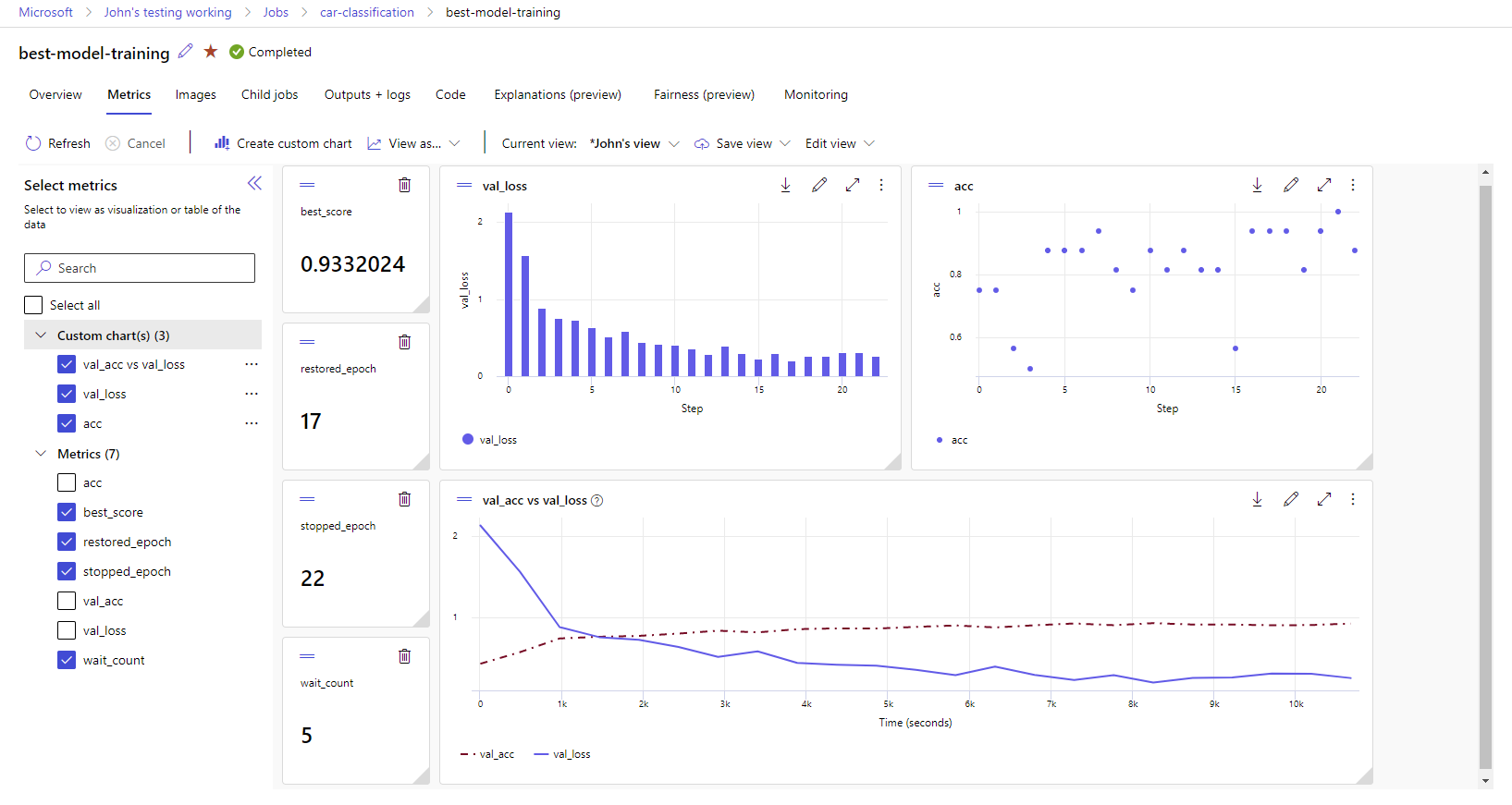
Wyświetlanie metryk i artefaktów w obszarze roboczym
Metryki i artefakty z rejestrowania MLflow są śledzone w obszarze roboczym. Możesz je wyświetlać i uzyskiwać do nich dostęp w studio w dowolnym momencie lub uzyskać do nich dostęp programowo za pośrednictwem zestawu MLflow SDK.
Aby wyświetlić metryki i artefakty w studio:
Przejdź do usługi Azure Machine Learning Studio.
Przejdź do obszaru roboczego.
Znajdź eksperyment według nazwy w obszarze roboczym.
Wybierz zarejestrowane metryki, aby renderować wykresy po prawej stronie. Wykresy można dostosować, stosując wygładzenie, zmianę koloru lub kreślenie wielu metryk na jednym grafie. Możesz również zmienić rozmiar i zmienić układ zgodnie z życzeniem.
Po utworzeniu żądanego widoku zapisz go do użytku w przyszłości i udostępnij go kolegom z zespołu, korzystając z linku bezpośredniego.

Aby uzyskać dostęp do metryk, parametrów i artefaktów lub wykonywać zapytania programowo za pomocą zestawu MLflow SDK, użyj mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Napiwek
W przypadku metryk poprzedni przykładowy kod zwróci tylko ostatnią wartość danej metryki. Jeśli chcesz pobrać wszystkie wartości danej metryki, użyj mlflow.get_metric_history metody . Aby uzyskać więcej informacji na temat pobierania wartości metryki, zobacz Pobieranie parametrów i metryk z przebiegu.
Aby pobrać zarejestrowane artefakty, takie jak pliki i modele, użyj mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Aby uzyskać więcej informacji na temat pobierania lub porównywania informacji z eksperymentów i przebiegów w usłudze Azure Machine Learning przy użyciu biblioteki MLflow, zobacz Zapytania i porównanie eksperymentów i przebiegów za pomocą platformy MLflow.