Śledzenie eksperymentów uczenia maszynowego w usłudze Azure Synapse Analytics za pomocą platformy MLflow i usługi Azure Machine Learning
Z tego artykułu dowiesz się, jak włączyć rozwiązanie MLflow w celu nawiązania połączenia z usługą Azure Machine Learning podczas pracy w obszarze roboczym usługi Azure Synapse Analytics. Tę konfigurację można wykorzystać do śledzenia, zarządzania modelami i wdrażania modelu.
MLflow to biblioteka typu open source do zarządzania cyklem życia eksperymentów uczenia maszynowego. MlFlow Tracking to składnik biblioteki MLflow, który rejestruje i śledzi metryki przebiegu trenowania i artefakty modelu. Dowiedz się więcej o platformie MLflow.
Jeśli masz projekt MLflow do trenowania za pomocą usługi Azure Machine Learning, zobacz Szkolenie modeli uczenia maszynowego przy użyciu projektów MLflow i usługi Azure Machine Learning (wersja zapoznawcza).
Wymagania wstępne
- Obszar roboczy i klaster usługi Azure Synapse Analytics.
- Obszar roboczy usługi Azure Machine Learning.
Instalowanie bibliotek
Aby zainstalować biblioteki w dedykowanym klastrze w usłudze Azure Synapse Analytics:
requirements.txtUtwórz plik z pakietami wymaganymi przez eksperymenty, ale upewnij się, że zawiera również następujące pakiety:requirements.txt
mlflow azureml-mlflow azure-ai-mlPrzejdź do portalu obszaru roboczego usługi Azure Analytics.
Przejdź do karty Zarządzanie i wybierz pozycję Pule platformy Apache Spark.
Kliknij trzy kropki obok nazwy klastra i wybierz pozycję Pakiety.
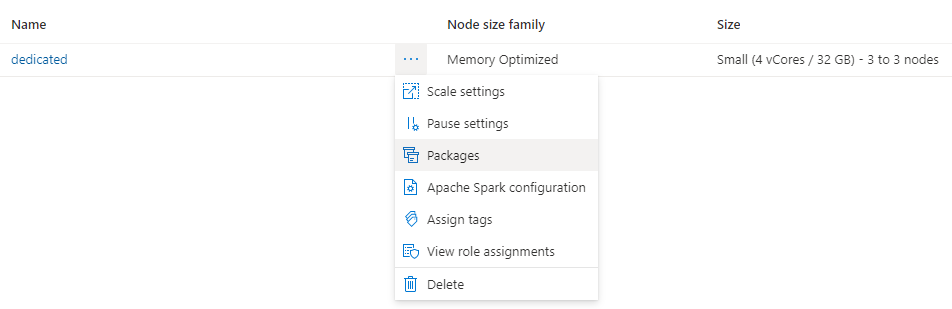
W sekcji Pliki wymagań kliknij pozycję Przekaż.
Przekaż plik
requirements.txt.Poczekaj na ponowne uruchomienie klastra.
Śledzenie eksperymentów za pomocą platformy MLflow
Usługę Azure Synapse Analytics można skonfigurować do śledzenia eksperymentów przy użyciu biblioteki MLflow do obszaru roboczego usługi Azure Machine Learning. Usługa Azure Machine Learning udostępnia scentralizowane repozytorium do zarządzania całym cyklem życia eksperymentów, modeli i wdrożeń. Zaletą jest również umożliwienie łatwiejszego wdrażania przy użyciu opcji wdrażania usługi Azure Machine Learning.
Konfigurowanie notesów do używania biblioteki MLflow połączonej z usługą Azure Machine Learning
Aby użyć usługi Azure Machine Learning jako scentralizowanego repozytorium dla eksperymentów, możesz skorzystać z biblioteki MLflow. W każdym notesie, nad którym pracujesz, musisz skonfigurować identyfikator URI śledzenia, aby wskazywał obszar roboczy, którego będziesz używać. W poniższym przykładzie pokazano, jak można to zrobić:
Konfigurowanie identyfikatora URI śledzenia
Pobierz identyfikator URI śledzenia dla obszaru roboczego:
DOTYCZY:
 Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure ml w wersji 2 (bieżąca)Zaloguj się i skonfiguruj obszar roboczy:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Identyfikator URI śledzenia można uzyskać za pomocą
az ml workspacepolecenia :az ml workspace show --query mlflow_tracking_uri
Konfigurowanie identyfikatora URI śledzenia:
Następnie metoda
set_tracking_uri()wskazuje identyfikator URI śledzenia MLflow na ten identyfikator URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)Napiwek
Podczas pracy w środowiskach udostępnionych, takich jak klaster usługi Azure Databricks, klaster usługi Azure Synapse Analytics lub podobny, warto ustawić zmienną środowiskową
MLFLOW_TRACKING_URIna poziomie klastra, aby automatycznie skonfigurować identyfikator URI śledzenia MLflow w taki sposób, aby wskazywał usługę Azure Machine Learning dla wszystkich sesji uruchomionych w klastrze, a nie w celu wykonania jej dla poszczególnych sesji.
Konfiguruj uwierzytelnianie
Po skonfigurowaniu śledzenia należy również skonfigurować sposób uwierzytelniania w skojarzonym obszarze roboczym. Domyślnie wtyczka usługi Azure Machine Learning dla platformy MLflow przeprowadzi uwierzytelnianie interakcyjne, otwierając domyślną przeglądarkę, aby wyświetlić monit o poświadczenia. Zobacz Konfigurowanie platformy MLflow dla usługi Azure Machine Learning: konfigurowanie uwierzytelniania na dodatkowe sposoby konfigurowania uwierzytelniania dla platformy MLflow w obszarach roboczych usługi Azure Machine Learning.
W przypadku zadań interaktywnych, w których istnieje użytkownik połączony z sesją, można polegać na uwierzytelnianiu interakcyjnym i dlatego nie jest wymagana żadna dalsza akcja.
Ostrzeżenie
Uwierzytelnianie interakcyjne przeglądarki zablokuje wykonywanie kodu podczas monitowania o poświadczenia. Nie jest to odpowiednia opcja uwierzytelniania w środowiskach nienadzorowanych, takich jak zadania szkoleniowe. Zalecamy skonfigurowanie innego trybu uwierzytelniania.
W przypadku tych scenariuszy, w których wymagane jest nienadzorowane wykonanie, należy skonfigurować jednostkę usługi do komunikowania się z usługą Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Napiwek
Podczas pracy w środowiskach udostępnionych zaleca się skonfigurowanie tych zmiennych środowiskowych w środowisku obliczeniowym. Najlepszym rozwiązaniem jest zarządzanie nimi jako wpisami tajnymi w wystąpieniu usługi Azure Key Vault zawsze, gdy jest to możliwe. Na przykład w usłudze Azure Databricks można używać wpisów tajnych w zmiennych środowiskowych w następujący sposób w konfiguracji klastra: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Zobacz Odwołanie do wpisu tajnego w zmiennej środowiskowej , aby dowiedzieć się, jak to zrobić w usłudze Azure Databricks lub zapoznaj się z podobną dokumentacją na platformie.
Nazwy eksperymentów w usłudze Azure Machine Learning
Domyślnie usługa Azure Machine Learning śledzi przebiegi w domyślnym eksperymencie o nazwie Default. Zazwyczaj dobrym pomysłem jest ustawienie eksperymentu, nad którym będziesz pracować. Użyj następującej składni, aby ustawić nazwę eksperymentu:
mlflow.set_experiment(experiment_name="experiment-name")
Śledzenie parametrów, metryk i artefaktów
Następnie możesz użyć biblioteki MLflow w usłudze Azure Synapse Analytics w taki sam sposób, jak wcześniej. Aby uzyskać szczegółowe informacje, zobacz Dzienniki i wyświetlanie metryk i plików dziennika.
Rejestrowanie modeli w rejestrze za pomocą biblioteki MLflow
Modele można zarejestrować w obszarze roboczym usługi Azure Machine Learning, który oferuje scentralizowane repozytorium do zarządzania ich cyklem życia. Poniższy przykład rejestruje model wytrenowany za pomocą biblioteki MLLib platformy Spark, a także rejestruje go w rejestrze.
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
Jeśli zarejestrowany model o nazwie nie istnieje, metoda rejestruje nowy model, tworzy wersję 1 i zwraca obiekt MLflow ModelVersion.
Jeśli zarejestrowany model o nazwie już istnieje, metoda tworzy nową wersję modelu i zwraca obiekt wersji.
Modele zarejestrowane w usłudze Azure Machine Learning można zarządzać przy użyciu platformy MLflow. Aby uzyskać więcej informacji, zobacz Zarządzanie rejestrami modeli w usłudze Azure Machine Learning przy użyciu biblioteki MLflow .
Wdrażanie i korzystanie z modeli zarejestrowanych w usłudze Azure Machine Learning
Modele zarejestrowane w usłudze Azure Machine Learning Service przy użyciu platformy MLflow mogą być używane jako:
Punkt końcowy usługi Azure Machine Learning (w czasie rzeczywistym i partia): to wdrożenie umożliwia korzystanie z funkcji wdrażania usługi Azure Machine Learning zarówno w czasie rzeczywistym, jak i wnioskowania wsadowego w usłudze Azure Container Instances (ACI), Azure Kubernetes (AKS) lub zarządzanych punktów końcowych.
Obiekty modelu MLFlow lub funkcje zdefiniowane przez użytkownika biblioteki Pandas, które mogą być używane w notesach usługi Azure Synapse Analytics w potokach przesyłania strumieniowego lub wsadowego.
Wdrażanie modeli w punktach końcowych usługi Azure Machine Learning
Wtyczkę azureml-mlflow można wykorzystać do wdrożenia modelu w obszarze roboczym usługi Azure Machine Learning. Zobacz stronę Jak wdrożyć modele MLflow, aby uzyskać pełny opis sposobu wdrażania modeli w różnych miejscach docelowych.
Ważne
Aby je wdrożyć, należy zarejestrować modele w rejestrze usługi Azure Machine Learning. Wdrażanie niezarejestrowanych modeli nie jest obsługiwane w usłudze Azure Machine Learning.
Wdrażanie modeli na potrzeby oceniania wsadowego przy użyciu funkcji zdefiniowanych przez użytkownika
Możesz wybrać klastry usługi Azure Synapse Analytics na potrzeby oceniania wsadowego. Model MLFlow jest ładowany i używany jako funkcja UDF platformy Spark pandas do oceniania nowych danych.
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Czyszczenie zasobów
Jeśli chcesz zachować obszar roboczy usługi Azure Synapse Analytics, ale nie potrzebujesz już obszaru roboczego usługi Azure Machine Learning, możesz usunąć obszar roboczy usługi Azure Machine Learning. Jeśli nie planujesz używania zarejestrowanych metryk i artefaktów w obszarze roboczym, możliwość ich usunięcia indywidualnie jest niedostępna w tej chwili. Zamiast tego usuń grupę zasobów zawierającą konto magazynu i obszar roboczy, aby nie ponosić żadnych opłat:
W witrynie Azure Portal na końcu z lewej strony wybierz pozycję Grupy zasobów.
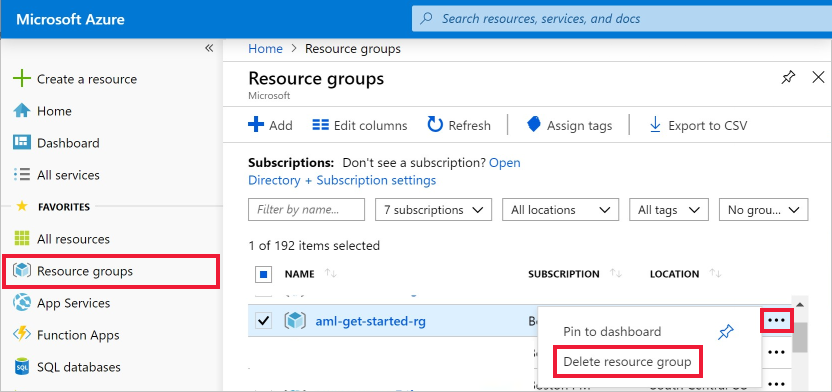
Wybierz utworzoną grupę zasobów z listy.
Wybierz pozycję Usuń grupę zasobów.
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.
Następne kroki
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla