Trenowanie modelu regresji przy użyciu zautomatyzowanego uczenia maszynowego i języka Python (zestaw SDK w wersji 1)
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Z tego artykułu dowiesz się, jak wytrenować model regresji przy użyciu zestawu SDK języka Python usługi Azure Machine Learning przy użyciu zautomatyzowanego uczenia maszynowego platformy Azure. Model regresji przewiduje opłaty za taksówki działające w Nowym Jorku (NYC). Napiszesz kod przy użyciu zestawu SDK języka Python, aby skonfigurować obszar roboczy z przygotowanymi danymi, wytrenować model lokalnie przy użyciu parametrów niestandardowych i eksplorować wyniki.
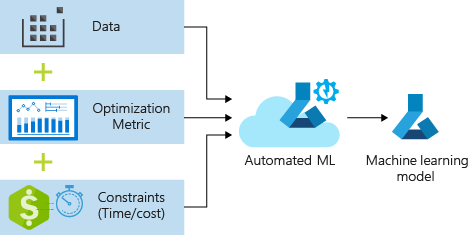
Proces akceptuje dane szkoleniowe i ustawienia konfiguracji. Automatycznie wykonuje iterację za pomocą kombinacji różnych metod normalizacji/standaryzacji funkcji, modeli i ustawień hiperparametrów, aby uzyskać najlepszy model. Na poniższym diagramie przedstawiono przepływ procesu trenowania modelu regresji:
Wymagania wstępne
Subskrypcja platformy Azure. Możesz utworzyć bezpłatne lub płatne konto usługi Azure Machine Learning.
Obszar roboczy usługi Azure Machine Learning lub wystąpienie obliczeniowe. Aby przygotować te zasoby, zobacz Szybki start: rozpoczynanie pracy z usługą Azure Machine Learning.
Przygotuj przykładowe dane na potrzeby ćwiczeń samouczka, ładując notes do obszaru roboczego:
Przejdź do obszaru roboczego w usłudze Azure Machine Learning Studio, wybierz pozycję Notesy, a następnie wybierz kartę Przykłady .
Na liście notesów rozwiń węzeł Samples SDK v1 tutorials>regression-automl-nyc-taxi-data node (Przykłady>zestawu SDK w wersji 1).>
Wybierz notes regression-automated-ml.ipynb.
Aby uruchomić każdą komórkę notesu w ramach tego samouczka, wybierz pozycję Sklonuj ten plik.
Alternatywne podejście: Jeśli wolisz, możesz uruchomić ćwiczenia samouczka w środowisku lokalnym. Samouczek jest dostępny w repozytorium notesów usługi Azure Machine Learning w witrynie GitHub. W przypadku tego podejścia wykonaj następujące kroki, aby uzyskać wymagane pakiety:
Uruchom polecenie
pip install azureml-opendatasets azureml-widgetsna komputerze lokalnym, aby pobrać wymagane pakiety.
Pobieranie i przygotowywanie danych
Pakiet Open Datasets zawiera klasę reprezentującą każde źródło danych (takie jak NycTlcGreen) w celu łatwego filtrowania parametrów daty przed pobraniem.
Poniższy kod importuje niezbędne pakiety:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Pierwszym krokiem jest utworzenie ramki danych taksówek. W przypadku pracy w środowisku innych niż Spark pakiet Open Datasets umożliwia pobieranie tylko jednego miesiąca danych w danym momencie z określonymi klasami. Takie podejście pomaga uniknąć problemu MemoryError , który może wystąpić w przypadku dużych zestawów danych.
Aby pobrać dane taksówek, iteracyjne pobieranie jednego miesiąca naraz. Przed dołączeniem następnego zestawu danych do green_taxi_df ramki danych losowe próbki 2000 rekordów z każdego miesiąca, a następnie wyświetlenie podglądu danych. Takie podejście pomaga uniknąć wzdęcia ramki danych.
Poniższy kod tworzy ramkę danych, pobiera dane i ładuje je do ramki danych:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
W poniższej tabeli przedstawiono wiele kolumn wartości w przykładowych danych taksówek:
| identyfikator dostawcy | lpepPickupDatetime | lpepDropoffDatetime | pasażerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | Dodatkowych | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1,88 | Brak | Brak | -73.996155 | 40.690903 | -73.964287 | ... | 1 | 15.0 | 1.0 | 0.5 | 0.3 | 4,00 | 0,0 | Brak | 20.80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | Brak | Brak | -73.978508 | 40.687984 | -73.955116 | ... | 1 | 11.5 | 0.5 | 0.5 | 0.3 | 2.55 | 0,0 | Brak | 15.35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3,54 | Brak | Brak | -73.957787 | 40.721779 | -73.963005 | ... | 1 | 13,5 | 0.5 | 0.5 | 0.3 | 2,80 | 0,0 | Brak | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1.00 | Brak | Brak | -73.919914 | 40.826023 | -73.904839 | ... | 2 | 6.5 | 0,0 | 0.5 | 0.3 | 0,00 | 0,0 | Brak | 7.30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | Brak | Brak | -73.943710 | 40.825439 | -73.982964 | ... | 1 | 18.5 | 0,0 | 0.5 | 0.3 | 3.85 | 0,0 | Brak | 23.15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | Brak | Brak | -73.940918 | 40.839714 | -73.994339 | ... | 1 | 24,0 | 0,0 | 0.5 | 0.3 | 4.80 | 0,0 | Brak | 29.60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1,03 | Brak | Brak | -73.985718 | 40.685646 | -73.996773 | ... | 1 | 6.5 | 0,0 | 0.5 | 0.3 | 1,30 | 0,0 | Brak | 8.60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | Brak | Brak | -73.939865 | 40.789822 | -73.952957 | ... | 2 | 12.5 | 0,0 | 0.5 | 0.3 | 0,00 | 0,0 | Brak | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3.00 | Brak | Brak | -73.957939 | 40.721928 | -73.926247 | ... | 1 | 14,0 | 0.5 | 0.5 | 0.3 | 2.00 | 0,0 | Brak | 17.30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | Brak | Brak | -73.943825 | 40.810257 | -73.943062 | ... | 1 | 10,0 | 0,0 | 0.5 | 0.3 | 2.00 | 0,0 | Brak | 12,80 | 1.0 |
Warto usunąć niektóre kolumny, których nie potrzebujesz do trenowania ani innego budynku funkcji. Możesz na przykład usunąć kolumnę lpepPickupDatetime , ponieważ zautomatyzowane uczenie maszynowe automatycznie obsługuje funkcje oparte na czasie.
Poniższy kod usuwa 14 kolumn z przykładowych danych:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Oczyszczanie danych
Następnym krokiem jest oczyszczenie danych.
Poniższy kod uruchamia describe() funkcję w nowej ramce danych w celu utworzenia statystyk podsumowania dla każdego pola:
green_taxi_df.describe()
W poniższej tabeli przedstawiono podsumowanie statystyk dla pozostałych pól w przykładowych danych:
| identyfikator dostawcy | pasażerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 | 24000.00 |
| znaczyć | 1.777625 | 1.373625 | 2.893981 | -73.827403 | 40.689730 | -73.819670 | 40.684436 | 14.892744 |
| Std | 0.415850 | 1.046180 | 3.072343 | 2.821767 | 1.556082 | 2.901199 | 1.599776 | 12.339749 |
| Min | 1,00 | 0,00 | 0,00 | -74.357101 | 0,00 | -74.342766 | 0,00 | -120.80 |
| 25% | 2.00 | 1.00 | 1.05 | -73.959175 | 40.699127 | -73.966476 | 40.699459 | 8.00 |
| 50% | 2.00 | 1.00 | 1.93 | -73.945049 | 40.746754 | -73.944221 | 40.747536 | 11.30 |
| 75% | 2.00 | 1.00 | 3.70 | -73.917089 | 40.803060 | -73.909061 | 40.791526 | 17.80 |
| Max | 2.00 | 8.00 | 154.28 | 0,00 | 41.109089 | 0,00 | 40.982826 | 425.00 |
Statystyki podsumowania pokazują kilka pól, które są wartościami odstające, które zmniejszają dokładność modelu. Aby rozwiązać ten problem, przefiltruj pola szerokości/długości geograficznej (lat/long), aby wartości mieściły się w granicach obszaru Manhattan. Takie podejście filtruje dłuższe przejazdy taksówek lub wycieczki, które są odstające w odniesieniu do ich relacji z innymi funkcjami.
Następnie przefiltruj pole pod kątem tripDistance wartości, które są większe niż zero, ale mniejsze niż 31 mil (odległość między dwiema parami lat/długimi). Ta technika eliminuje długie wyjazdy odstające, które mają niespójne koszty podróży.
Na koniec totalAmount pole ma ujemne wartości taryf taksówek, które nie mają sensu w kontekście modelu. Pole passengerCount zawiera również nieprawidłowe dane, w których minimalna wartość to zero.
Poniższy kod filtruje te anomalie wartości przy użyciu funkcji zapytań. Następnie kod usuwa kilka ostatnich kolumn, które nie są niezbędne do trenowania:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Ostatnim krokiem w tej sekwencji jest ponowne wywołanie describe() funkcji na danych w celu zapewnienia, że czyszczenie działa zgodnie z oczekiwaniami. Masz teraz przygotowany i oczyszczony zestaw danych taksówek, wakacji i pogody do użycia na potrzeby trenowania modelu uczenia maszynowego:
final_df.describe()
Konfigurowanie obszaru roboczego
Utwórz obiekt obszaru roboczego na podstawie istniejącego obszaru roboczego. Obszar roboczy to klasa, która akceptuje informacje o subskrypcji i zasobach platformy Azure. Tworzy ona również zasób w chmurze służący do monitorowania i śledzenia przebiegów modelu.
Poniższy kod wywołuje Workspace.from_config() funkcję w celu odczytania pliku config.json i załadowania szczegółów uwierzytelniania do obiektu o nazwie ws.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Obiekt ws jest używany w pozostałej części kodu w tym samouczku.
Podział danych na zestawy treningowe i testowe
Podziel dane na zestawy szkoleniowe i testowe przy użyciu train_test_split funkcji w bibliotece scikit-learn . Ta funkcja rozdziela dane do zestawu danych x (funkcje) na potrzeby trenowania modelu i zestawu danych y (wartości do przewidywania) na potrzeby testowania.
Parametr test_size określa procent danych przydzielanych do testowania. Parametr random_state ustawia inicjator do generatora losowego, aby podziały testów trenowania są deterministyczne.
Poniższy kod wywołuje funkcję w train_test_split celu załadowania zestawów danych x i y:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Celem tego kroku jest przygotowanie punktów danych do przetestowania gotowego modelu, który nie jest używany do trenowania modelu. Te punkty służą do mierzenia dokładności rzeczywistej. Dobrze wytrenowany model to taki, który może wykonywać dokładne przewidywania na podstawie niezaużyczonych danych. Masz teraz dane przygotowane do automatycznego trenowania modelu uczenia maszynowego.
Automatyczne trenowanie modelu
Aby przeprowadzić automatyczne trenowanie modelu, wykonaj następujące czynności:
Zdefiniuj ustawienia przebiegu eksperymentu. Dołącz do konfiguracji dane treningowe i zmodyfikuj ustawienia, które sterują procesem treningu.
Prześlij eksperyment do strojenia modelu. Po przesłaniu eksperymentu proces wykonuje iterację za pomocą różnych algorytmów uczenia maszynowego i ustawień hiperparametrów, przestrzegając zdefiniowanych ograniczeń. Na podstawie zoptymalizowanej metryki dokładności jest wybierany model o najlepszym dopasowaniu.
Definiowanie ustawień trenowania
Zdefiniuj parametr eksperymentu i ustawienia modelu na potrzeby trenowania. Wyświetl pełną listę ustawień. Przesyłanie eksperymentu z tymi ustawieniami domyślnymi trwa około 5–20 minut. Aby skrócić czas wykonywania, zmniejsz experiment_timeout_hours parametr .
| Właściwości | Wartość w ramach tego samouczka | opis |
|---|---|---|
iteration_timeout_minutes |
10 | Limit czasu w minutach dla każdej iteracji. Zwiększ tę wartość dla większych zestawów danych, które potrzebują więcej czasu dla każdej iteracji. |
experiment_timeout_hours |
0.3 | Maksymalny czas w godzinach, przez które wszystkie iteracji połączone mogą potrwać przed zakończeniem eksperymentu. |
enable_early_stopping |
Prawda | Flaga umożliwiająca wcześniejsze zakończenie, jeśli wynik nie poprawia się w krótkim okresie. |
primary_metric |
spearman_correlation | Metryka, który ma być optymalizowana. Najlepiej dopasowany model jest wybierany na podstawie tej metryki. |
featurization |
auto | Wartość automatyczna umożliwia eksperymentowi wstępne przetwarzanie danych wejściowych, w tym obsługę brakujących danych, konwertowanie tekstu na liczbowe itd. |
verbosity |
logging.INFO | Steruje poziomem rejestrowania. |
n_cross_validations |
5 | Liczba podziałów krzyżowej weryfikacji, które mają być wykonywane, gdy nie określono danych walidacji. |
Poniższy kod przesyła eksperyment:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Poniższy kod umożliwia użycie zdefiniowanych ustawień trenowania jako **kwargs parametru AutoMLConfig do obiektu. Ponadto należy określić dane treningowe i typ modelu, który jest regression w tym przypadku.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Uwaga
Zautomatyzowane kroki przetwarzania wstępnego uczenia maszynowego (normalizacja funkcji, obsługa brakujących danych, konwertowanie tekstu na liczbowe itd.) stają się częścią podstawowego modelu. Jeśli używasz modelu do przewidywania, te same kroki przetwarzania wstępnego stosowane podczas trenowania są stosowane automatycznie do danych wejściowych.
Trenowanie modelu regresji automatycznej
Utwórz obiekt eksperymentu w obszarze roboczym. Eksperyment działa jako kontener dla poszczególnych zadań. Przekaż zdefiniowany automl_config obiekt do eksperymentu i ustaw dla danych wyjściowych wartość True , aby wyświetlić postęp podczas zadania.
Po rozpoczęciu eksperymentu wyświetlane dane wyjściowe będą aktualizowane na żywo w miarę uruchamiania eksperymentu. Dla każdej iteracji zobaczysz typ modelu, czas trwania przebiegu i dokładność trenowania. Pole BEST śledzi najlepszy wynik trenowania na podstawie typu metryki:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
Dane wyjściowe są następujące:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Eksplorowanie wyników
Zapoznaj się z wynikami automatycznego trenowania za pomocą widżetu Jupyter. Widżet umożliwia wyświetlenie wykresu i tabeli wszystkich iteracji poszczególnych zadań wraz z metrykami dokładności trenowania i metadanymi. Ponadto można filtrować różne metryki dokładności niż podstawowa metryka za pomocą selektora listy rozwijanej.
Poniższy kod tworzy graf do eksplorowania wyników:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Szczegóły przebiegu widżetu Jupyter:

Wykres wykresu dla widżetu Jupyter:

Pobieranie najlepszego modelu
Poniższy kod umożliwia wybranie najlepszego modelu z iteracji. Funkcja get_output zwraca najlepszy przebieg i dopasowany model dla ostatniego wywołania dopasowania. Za pomocą przeciążeń get_output funkcji można pobrać najlepszy przebieg i dopasowany model dla dowolnej zarejestrowanej metryki lub określonej iteracji.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Testowanie najlepszej dokładności modelu
Użyj najlepszego modelu do uruchamiania przewidywań na zestawie danych testowych w celu przewidywania opłat za taksówkę. Funkcja predict używa najlepszego modelu i przewiduje wartości y, koszt podróży z x_test zestawu danych.
Poniższy kod wyświetla pierwsze 10 przewidywanych wartości kosztów z y_predict zestawu danych:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Oblicz wartość root mean squared error dla wyników. Przekonwertuj y_test ramkę danych na listę i porównaj z przewidywanymi wartościami. Funkcja mean_squared_error przyjmuje dwie tablice wartości i oblicza średni błąd kwadratowy między nimi. Wyciągnięcie pierwiastka kwadratowego z wyniku powoduje błąd w tych samych jednostkach co zmienna y koszt. Wskazuje mniej więcej, jak daleko przewidywania taryf taksówek pochodzą z rzeczywistych taryf.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Uruchom następujący kod, aby obliczyć średni bezwzględny błąd procentu (MAPE) przy użyciu pełnych y_actual zestawów danych.y_predict Ta metryka oblicza wartości bezwzględne różnic między poszczególnymi wartościami przewidywanymi i rzeczywistymi oraz sumuje wszystkie różnice. Następnie wyraża tę sumę jako procent sumy wartości rzeczywistych.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
Dane wyjściowe są następujące:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Z dwóch metryk dokładności przewidywania widać, że model jest dość dobry w przewidywaniu opłat za taksówkę z funkcji zestawu danych, zazwyczaj w zakresie +- 4,00 USD i około 15% błędów.
Tradycyjny proces tworzenia modelu uczenia maszynowego jest bardzo intensywnie obciążany zasobami. Wymaga to znacznej wiedzy i czasu inwestycji w domenę, aby uruchomić i porównać wyniki kilkudziesięciu modeli. Użycie automatycznego uczenia maszynowego jest doskonałym sposobem na szybkie przetestowanie wielu różnych modeli w danym scenariuszu.
Czyszczenie zasobów
Jeśli nie planujesz pracować z innymi samouczkami usługi Azure Machine Learning, wykonaj następujące kroki, aby usunąć zasoby, których już nie potrzebujesz.
Zatrzymywanie obliczeń
Jeśli używasz obliczeń, możesz zatrzymać maszynę wirtualną, gdy jej nie używasz, i zmniejszyć koszty:
Przejdź do obszaru roboczego w usłudze Azure Machine Learning Studio i wybierz pozycję Obliczenia.
Na liście wybierz zasoby obliczeniowe, które chcesz zatrzymać, a następnie wybierz pozycję Zatrzymaj.
Gdy wszystko będzie gotowe do ponownego użycia obliczeń, możesz ponownie uruchomić maszynę wirtualną.
Usuwanie innych zasobów
Jeśli nie planujesz korzystać z zasobów utworzonych w tym samouczku, możesz je usunąć i uniknąć naliczania dodatkowych opłat.
Wykonaj następujące kroki, aby usunąć grupę zasobów i wszystkie zasoby:
W witrynie Azure Portal przejdź do strony Grupy zasobów.
Na liście wybierz grupę zasobów utworzoną w tym samouczku, a następnie wybierz pozycję Usuń grupę zasobów.
Po wyświetleniu monitu o potwierdzenie wprowadź nazwę grupy zasobów, a następnie wybierz pozycję Usuń.
Jeśli chcesz zachować grupę zasobów i usunąć tylko jeden obszar roboczy, wykonaj następujące kroki:
W witrynie Azure Portal przejdź do grupy zasobów zawierającej obszar roboczy, który chcesz usunąć.
Wybierz obszar roboczy, wybierz pozycję Właściwości, a następnie wybierz pozycję Usuń.