Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tej serii samouczków pokazano, jak funkcje bezproblemowo integrują wszystkie fazy cyklu życia uczenia maszynowego: tworzenie prototypów, trenowanie i operacjonalizacja.
Za pomocą usługi Azure Machine Learning magazyn zarządzanych funkcji można odnajdywać, tworzyć i operacjonalizować funkcje. Cykl życia uczenia maszynowego obejmuje fazę tworzenia prototypów, w której eksperymentujesz z różnymi funkcjami. Obejmuje to również fazę operacjonalizacji, w której są wdrażane modele i kroki wnioskowania wyszukują dane funkcji. Funkcje służą jako tkanka łącząca w cyklu życia uczenia maszynowego. Aby dowiedzieć się więcej na temat podstawowych pojęć dotyczących zarządzanego magazynu funkcji, odwiedź stronę Co to jest zarządzany magazyn funkcji? i Omówienie jednostek najwyższego poziomu w zarządzanym magazynie funkcji.
W tym samouczku opisano sposób tworzenia specyfikacji zestawu funkcji za pomocą przekształceń niestandardowych. Następnie używa tego zestawu funkcji do generowania danych treningowych, włączania materializacji danych i wykonywania operacji backfill. Materializacja oblicza wartości funkcji dla okna funkcji, a następnie przechowuje te wartości w magazynie materializacji. Zapytania dotyczące funkcji mogą następnie korzystać z tych wartości z magazynu danych.
Bez materializacji zapytanie zestawu funkcji stosuje przekształcenia do źródła na bieżąco, aby obliczyć funkcje przed zwróceniem wartości. Ten proces dobrze sprawdza się w fazie tworzenia prototypów. Jednak w przypadku operacji trenowania i wnioskowania w środowisku produkcyjnym zalecamy zmaterializowanie funkcji w celu zapewnienia większej niezawodności i dostępności.
Ten samouczek jest pierwszą częścią serii samouczków dotyczących zarządzanego magazynu funkcji. Tutaj dowiesz się, jak wykonywać następujące czynności:
- Utwórz nowy, minimalny zasób magazynu funkcji.
- Opracowywanie i lokalne testowanie zestawu funkcji przy użyciu możliwości przekształcania funkcji.
- Zarejestruj element repozytorium funkcji w repozytorium funkcji.
- Zarejestruj zestaw funkcji, który opracowałeś w repozytorium funkcji.
- Wygeneruj przykładową ramkę danych trenowania przy użyciu utworzonych funkcji.
- Włącz materializację w trybie offline w zestawach funkcji i uzupełnij dane funkcji.
Ta seria poradników ma dwie ścieżki:
- Ścieżka tylko z SDK używa wyłącznie SDK języka Python. Wybierz ten utwór dla czystego, opartego na języku Python programowania i wdrażania.
- Zestaw SDK i CLI używa zestawu SDK języka Python do rozwoju i testowania funkcji oraz korzysta z CLI w przypadku operacji CRUD (tworzenie, odczytywanie, aktualizowanie i usuwanie). Ta ścieżka jest przydatna w scenariuszach ciągłej integracji i ciągłego dostarczania (CI/CD) lub GitOps, gdzie preferowane są narzędzia interfejsu wiersza polecenia (CLI) lub YAML.
Wymagania wstępne
Przed kontynuowaniem pracy z tym samouczkiem należy uwzględnić następujące wymagania wstępne:
Obszar roboczy usługi Azure Machine Learning. Aby uzyskać więcej informacji na temat tworzenia obszaru roboczego, zobacz Szybki start: tworzenie zasobów obszaru roboczego.
Na koncie użytkownika potrzebna jest rola Właściciel dla grupy zasobów, w której jest tworzony magazyn funkcji.
Jeśli zdecydujesz się użyć nowej grupy zasobów na potrzeby tego samouczka, możesz łatwo usunąć wszystkie zasoby, usuwając grupę zasobów.
Przygotowywanie środowiska notesu
W tym samouczku do programowania jest używany notes platformy Spark usługi Azure Machine Learning.
W środowisku Azure Machine Learning studio wybierz Notatniki w okienku po lewej stronie, a następnie przejdź do karty Przykłady.
Przejdź do katalogu featurestore_sample (wybierz Samples>SDK v2>sdk>python>featurestore_sample), a następnie wybierz pozycję Clone.
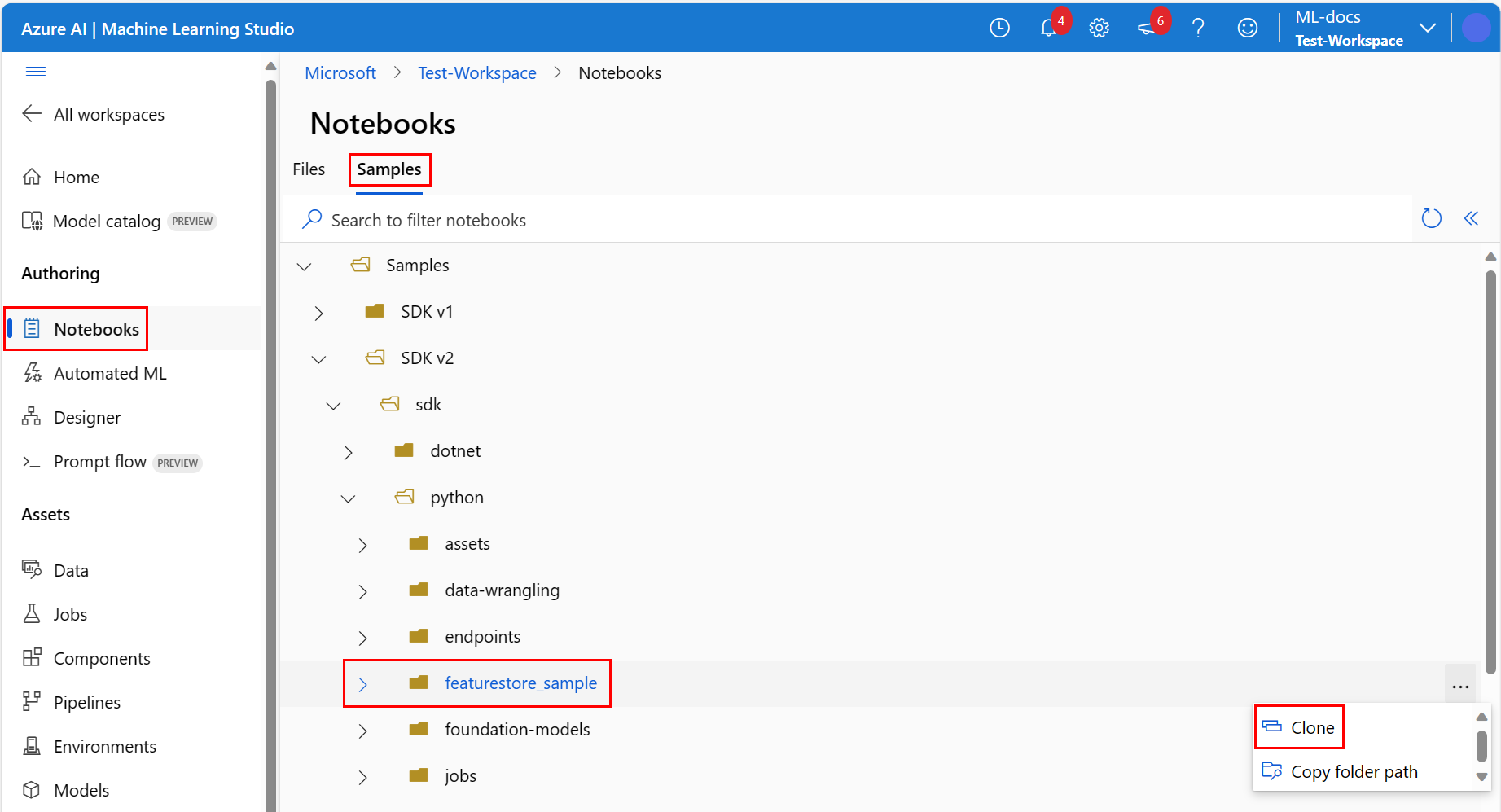
Zostanie otwarty panel Wybierz katalog docelowy. Wybierz katalog Użytkownicy, a następnie wybierz nazwę użytkownika, a na koniec wybierz pozycję Klonuj.
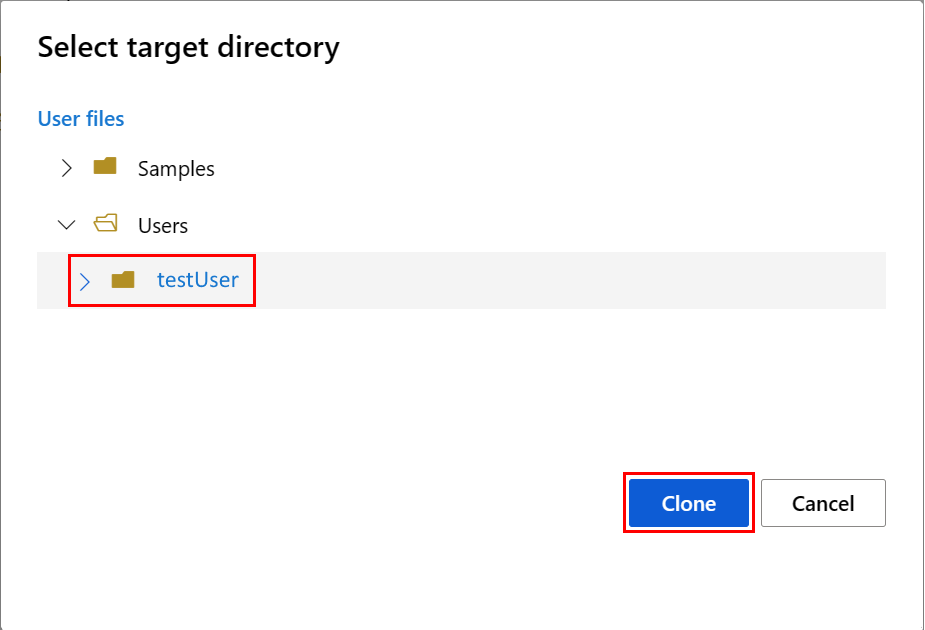
Aby skonfigurować środowisko notesu, należy przekazać plik conda.yml :
- Wybierz pozycję Notesy w okienku po lewej stronie, a następnie wybierz kartę Pliki .
- Przejdź do katalogu env (wybierz pozycję Użytkownicy>your_user_name>featurestore_sample>projekt>env), a następnie wybierz plik conda.yml.
- Wybierz Pobierz.
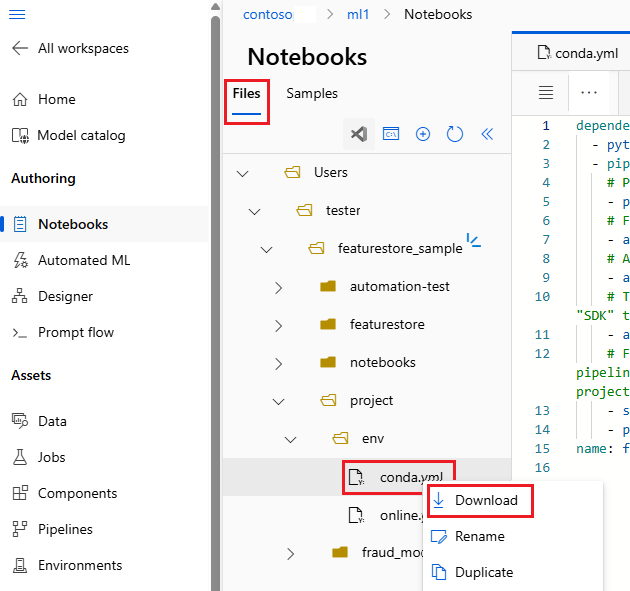
- Na górnym pasku nawigacyjnym wybierz z listy rozwijanej Obliczenia pozycję Bezserwerowe obliczenia Spark. Ta operacja może potrwać od jednej do dwóch minut. Poczekaj na pasek stanu u góry, aby wyświetlić pozycję Konfiguruj sesję.
- Wybierz pozycję Konfiguruj sesję na górnym pasku stanu.
- Wybierz Pakiety Pythona.
- Wybierz pozycję Przekaż pliki conda.
-
conda.ymlWybierz plik pobrany na urządzeniu lokalnym. - (Opcjonalnie) Zwiększ limit czasu sesji (czas bezczynności w minutach), aby skrócić czas uruchamiania klastra spark bezserwerowego.
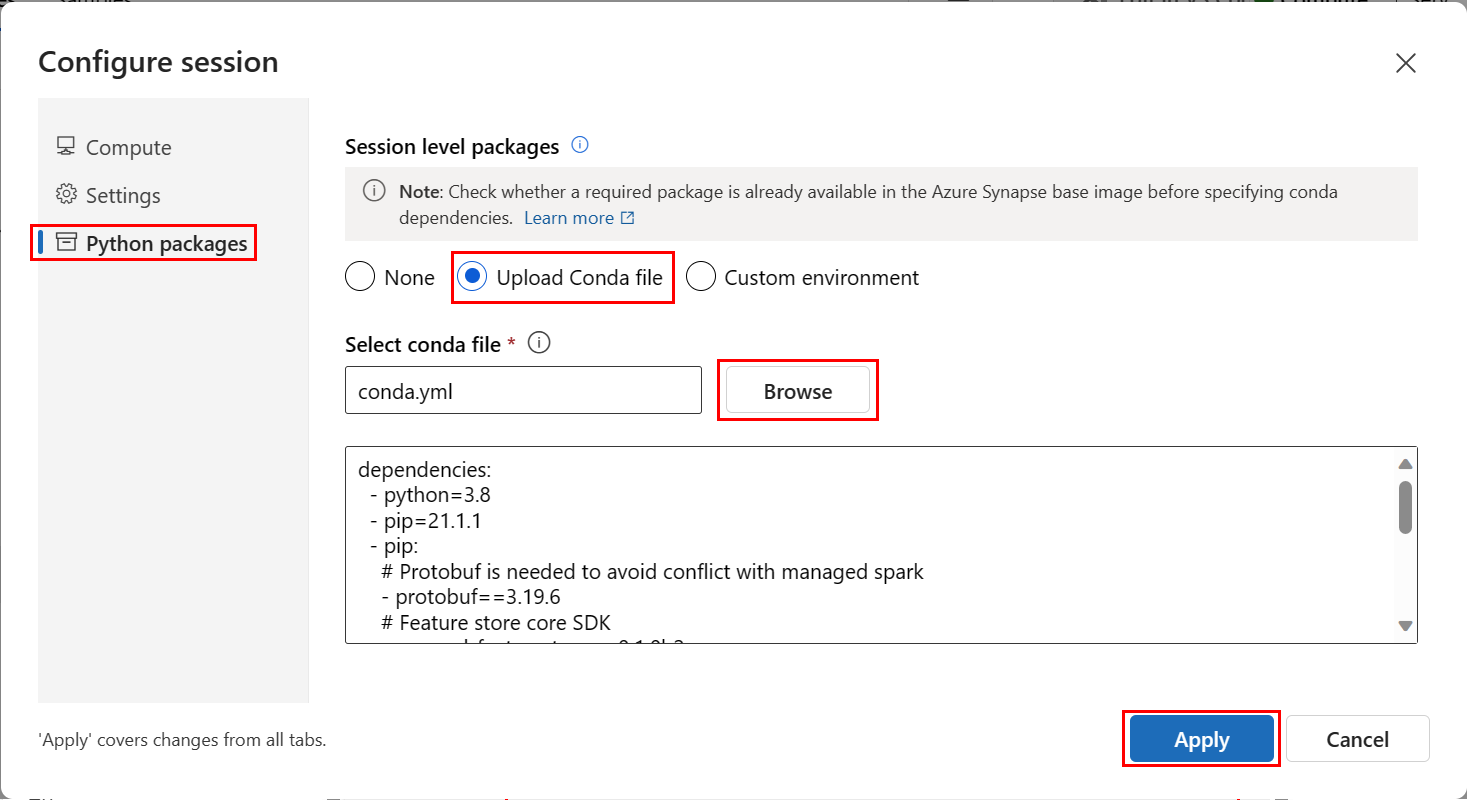
W środowisku usługi Azure Machine Learning otwórz notes, a następnie wybierz pozycję Konfiguruj sesję.
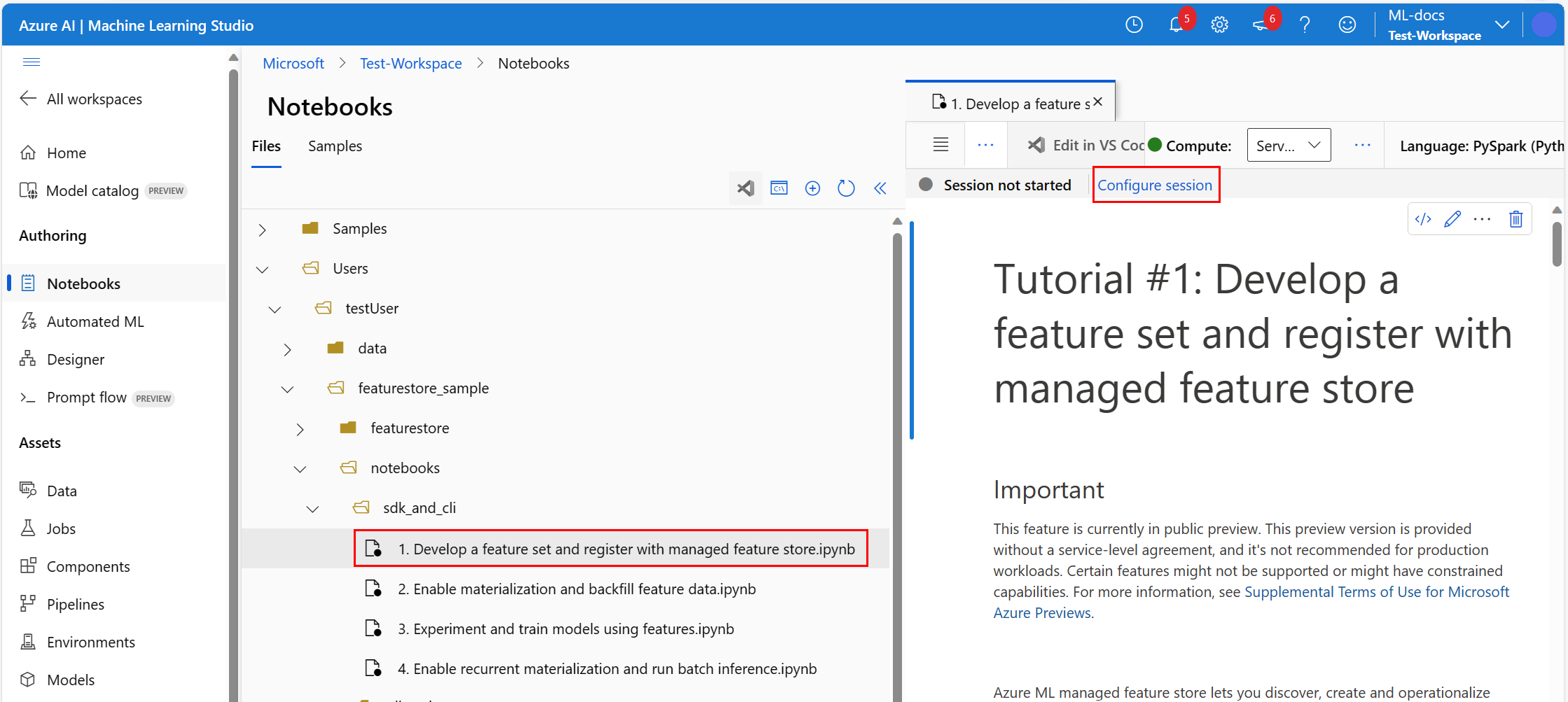
Na panelu Konfigurowanie sesji wybierz pozycję Pakiety języka Python.
Przekaż plik Conda:
- Na karcie Pakiety języka Python wybierz pozycję Przekaż plik Conda.
- Przejdź do katalogu, który hostuje plik Conda.
- Wybierz pozycję conda.yml, a następnie wybierz pozycję Otwórz.
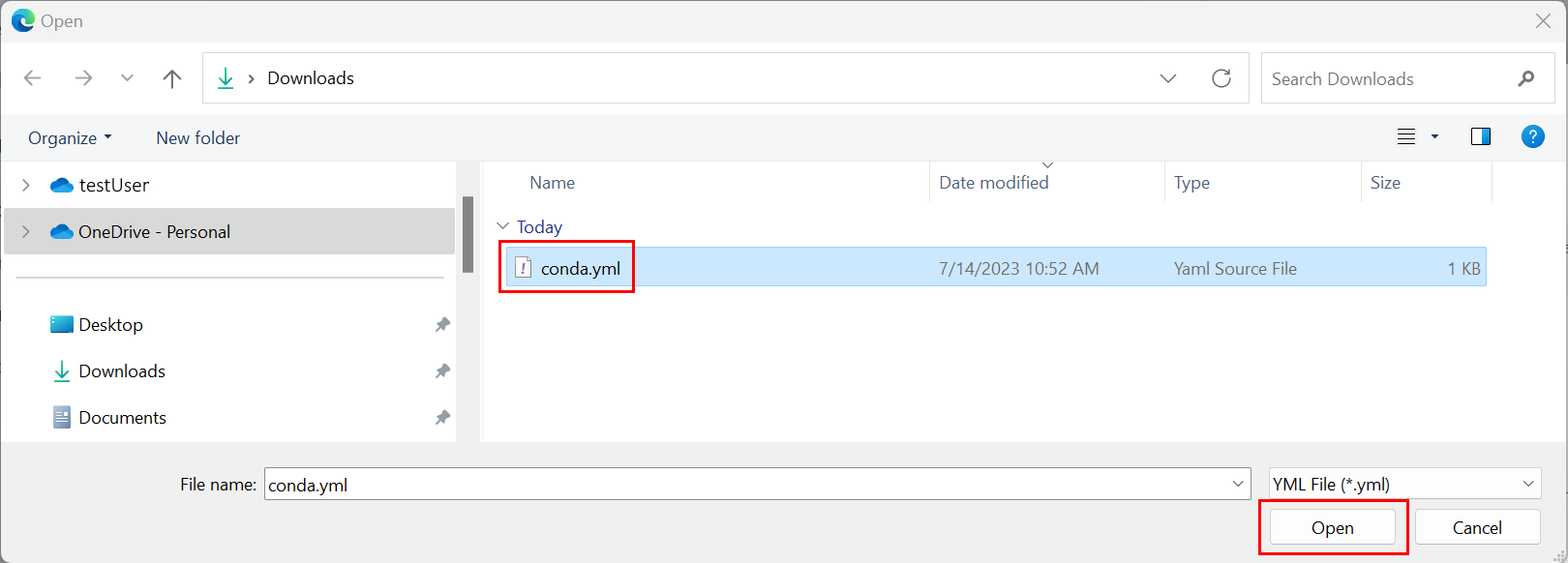
Wybierz Zastosuj.






Uruchamianie sesji platformy Spark
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")Konfigurowanie katalogu głównego dla przykładów
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")Konfigurowanie interfejsu wiersza polecenia
Uwaga
Magazyn funkcji służy do ponownego używania funkcji w projektach. Obszar roboczy projektu (obszar roboczy usługi Azure Machine Learning) służy do trenowania modeli wnioskowania, korzystając z funkcji z magazynów funkcji. Wiele obszarów roboczych projektu może współużytkować ten sam magazyn funkcji i używać go ponownie.
W tym samouczku są używane dwa zestawy SDK:
Zestaw SDK CRUD magazynu funkcji
Używasz tego samego
MLClientzestawu SDK (nazwyazure-ai-mlpakietu ), który jest używany z obszarem roboczym usługi Azure Machine Learning. Magazyn funkcji jest implementowany jako typ obszaru roboczego. W związku z tym ten SDK jest używany na potrzeby operacji CRUD dla repozytoriów funkcji, zestawów funkcji i jednostek repozytorium funkcji.Podstawowy zestaw SDK magazynu funkcji
Ten zestaw SDK (
azureml-featurestore) jest przeznaczony do rozwoju i użycia zestawu funkcji. W kolejnych krokach tego samouczka opisano następujące operacje:- Opracowywanie specyfikacji zestawu funkcji.
- Pobieranie danych funkcji.
- Wymień lub pobierz zarejestrowany zestaw funkcji.
- Tworzenie i rozwiązywanie specyfikacji pobierania funkcji.
- Generowanie danych szkoleniowych i danych do wnioskowania przy użyciu łączenia w danym punkcie czasowym.
Ten samouczek nie wymaga jawnej instalacji tych zestawów SDK, ponieważ wcześniejsze instrukcje conda.yml obejmują ten krok.
Tworzenie minimalnego magazynu funkcji
Ustaw parametry repozytorium funkcji, w tym nazwę, lokalizację i inne wartości.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Utwórz magazyn funkcji.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Inicjalizacja klienta podstawowego zestawu SDK sklepu funkcji dla Azure Machine Learning.
Jak wyjaśniono wcześniej w tym samouczku, podstawowy klient SDK magazynu funkcji służy do opracowywania i korzystania z funkcji.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Przyznaj rolę "Azure Machine Learning Data Scientist" w magazynie cech tożsamości użytkownika. Uzyskaj wartość identyfikatora obiektu Entra firmy Microsoft z witryny Azure Portal, zgodnie z opisem w artykule Znajdowanie identyfikatora obiektu użytkownika.
Przypisz rolę badacze dancyh usługi AzureML do tożsamości użytkownika, aby móc tworzyć zasoby w obszarze roboczym magazynu funkcji. Propagacja uprawnień może wymagać pewnego czasu.
Aby uzyskać więcej informacji na temat kontroli dostępu, odwiedź zasób Zarządzanie kontrolą dostępu do zarządzanego magazynu funkcji.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Tworzenie prototypów i tworzenie zestawu funkcji
W tych krokach utworzysz zestaw cech o nazwie transactions zawierający cechy agregowane na podstawie okien przesuwających się.
Eksploruj dane źródłowe
transactions.W tym notesie używane są przykładowe dane przechowywane w kontenerze blob dostępnym publicznie. Można go odczytywać tylko na platformie Spark za pośrednictwem
wasbssterownika. Tworząc zestawy funkcji z wykorzystaniem własnych danych źródłowych, przechowuj je w koncie usługi Azure Data Lake Storage Gen2 i użyj sterownikaabfssw ścieżce danych.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueLokalnie opracuj zestaw funkcji.
Specyfikacja zestawu funkcji to samodzielna definicja zestawu funkcji, którą można lokalnie opracowywać i testować. W tym miejscu utworzysz te funkcje agregacji okien kroczących:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
Przejrzyj plik kodu przekształcania funkcji: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Zwróć uwagę na agregację kroczącą zdefiniowaną dla funkcji. Jest to transformator spark.
Aby dowiedzieć się więcej na temat zestawu funkcji i przekształceń, odwiedź zasób Co to jest magazyn zarządzanych funkcji?
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Eksportuj jako specyfikację zestawu funkcji.
Aby zarejestrować specyfikację zestawu funkcji w magazynie funkcji, należy zapisać tę specyfikację w określonym formacie.
Przejrzyj wygenerowaną
transactionsspecyfikację zestawu funkcji. Otwórz ten plik z drzewa plików, aby wyświetlić specyfikację featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml .Specyfikacja zawiera następujące elementy:
-
source: odwołanie do zasobu magazynowego. W tym przypadku jest to plik parquet w zasobie magazynu danych blob. -
features: lista funkcji i ich typów danych. Jeśli podasz kod przekształcenia, kod musi zwrócić ramkę danych, która mapuje się na funkcje i typy danych. -
index_columns: klucze dołączenia wymagane do uzyskania dostępu do wartości z zestawu cech.
Aby dowiedzieć się więcej na temat specyfikacji, odwiedź zasoby Zrozumienie jednostek najwyższego poziomu w zarządzanym magazynie funkcji i schemat YAML zestawu funkcji interfejsu wiersza polecenia (CLI v2).
Utrwalanie specyfikacji zestawu funkcji zapewnia kolejną korzyść: specyfikacja zestawu funkcji obsługuje kontrolę źródła.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)-
Rejestrowanie jednostki magazynu funkcji
Dobre praktyki polegają na tym, że dzięki użyciu encji można wymusić stosowanie tej samej definicji klucza sprzężenia w zestawach funkcji korzystających z tych samych logicznych encji. Przykłady jednostek obejmują konta i klientów. Jednostki są zwykle tworzone raz, a następnie ponownie używane w zestawach funkcji. Aby dowiedzieć się więcej, odwiedź stronę Zrozumienie jednostek najwyższego poziomu w zarządzanym magazynie funkcji.
Zainicjuj klienta CRUD dla przechowywania cech.
Jak wyjaśniono wcześniej w tym samouczku,
MLClientsłuży do tworzenia, odczytywania, aktualizowania i usuwania zasobu magazynu funkcji. Pokazany tutaj przykładowy kod w komórce notesu wyszukuje repozytorium funkcji, które utworzyłeś we wcześniejszym kroku. W tym miejscu nie można ponownie użyć tej samejml_clientwartości, która została użyta wcześniej w tym samouczku, ponieważ ta wartość jest ograniczona na poziomie grupy zasobów. Odpowiednie określenie zakresu jest wymaganiem wstępnym dla tworzenia magazynu funkcji.W tym przykładzie kodu klient jest ograniczony na poziomie repozytorium funkcji.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Zarejestruj jednostkę w
accountmagazynie funkcji.Utwórz jednostkę
account, która ma kluczaccountIDsprzężenia typustring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
Rejestrowanie zestawu cech transakcji w przechowalni cech
Użyj tego kodu, aby zarejestrować zasób zestawu funkcji w magazynie funkcji. Następnie możesz ponownie użyć tego zasobu i łatwo go udostępnić. Rejestracja zasobu zestawu funkcji oferuje funkcje zarządzane, w tym przechowywanie wersji i materializacja. W kolejnych krokach tej serii samouczków omówiono możliwości zarządzane.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Eksplorowanie interfejsu użytkownika magazynu funkcji
Tworzenie i aktualizacje zasobów repozytorium funkcji mogą odbywać się tylko za pośrednictwem SDK i interfejsu wiersza polecenia. Interfejs użytkownika umożliwia wyszukiwanie lub przeglądanie magazynu funkcji:
- Otwórz globalną stronę docelową usługi Azure Machine Learning.
- Wybierz pozycję Repozytoria cech w okienku po lewej stronie.
- Z listy dostępnych magazynów funkcji wybierz magazyn funkcji utworzony wcześniej w tym samouczku.
Udziel roli Czytelnika Danych Obiektu Blob magazynu dostępu do twojego konta użytkownika w magazynie offline.
Rola Czytelnik danych obiektów blob Storage musi być przypisana do twojego konta użytkownika w magazynie offline. Dzięki temu konto użytkownika może odczytywać zmaterializowane dane funkcji z magazynu materializacji w trybie offline.
Uzyskaj wartość identyfikatora obiektu Entra firmy Microsoft z witryny Azure Portal, zgodnie z opisem w artykule Znajdowanie identyfikatora obiektu użytkownika.
Uzyskaj informacje o magazynie materializacji w trybie offline ze strony Przegląd w interfejsie użytkownika magazynu funkcji. Wartości identyfikatora subskrypcji konta magazynu, nazwy grupy zasobów konta magazynu i nazwy konta magazynu dla magazynu materializacji offline można znaleźć na karcie magazynu materializacji offline.
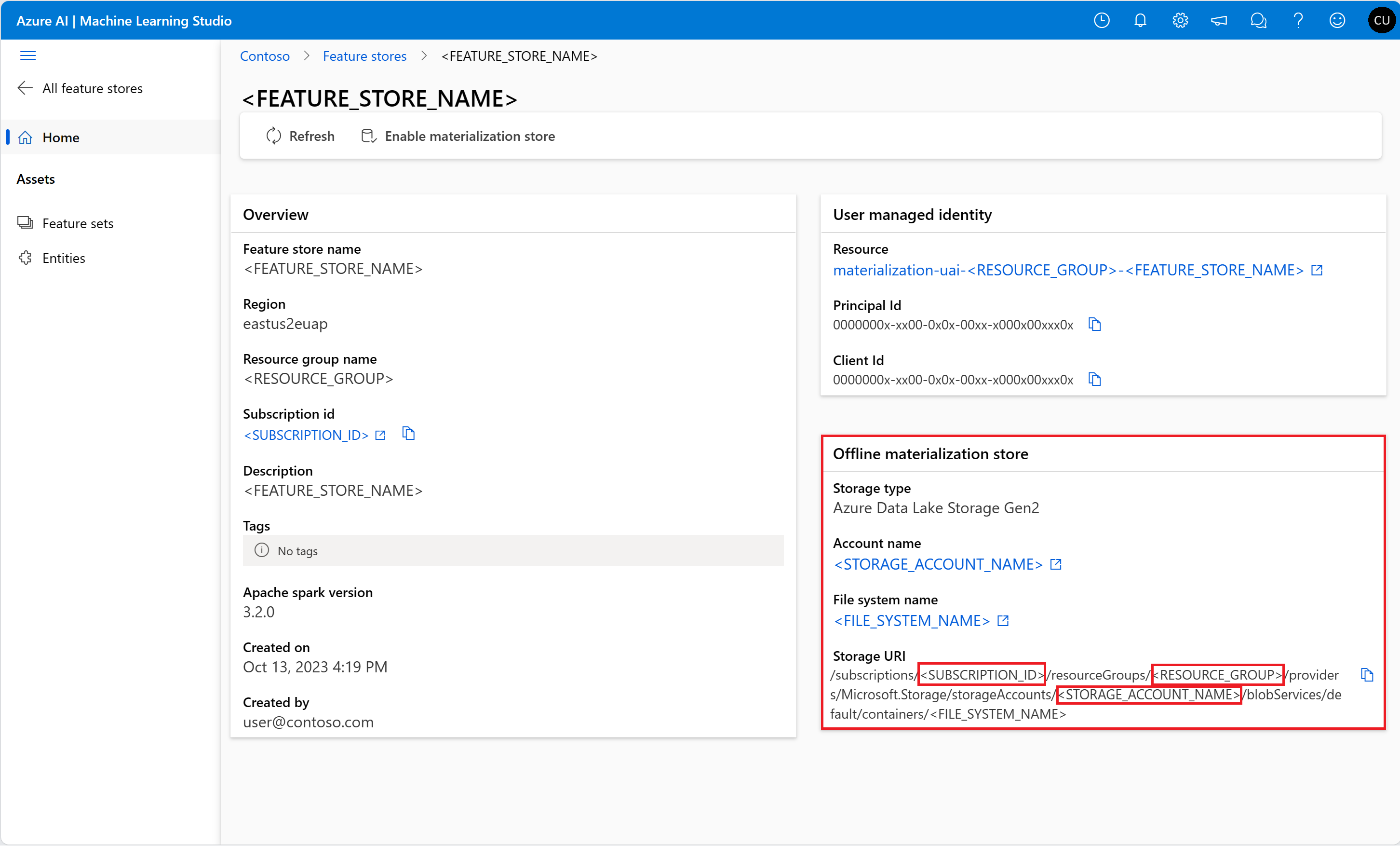
Aby uzyskać więcej informacji na temat kontroli dostępu, odwiedź stronę Zarządzanie kontrolą dostępu dla zasobu magazyn zarządzanych funkcji.
Wykonaj tę komórkę kodu na potrzeby przypisania roli. Propagacja uprawnień może wymagać pewnego czasu.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Generowanie ramki danych treningowych przy użyciu zarejestrowanego zestawu funkcji
Ładowanie danych obserwacji.
Dane obserwacji zwykle obejmują podstawowe dane używane do trenowania i wnioskowania. Te dane łączą się z danymi funkcji, aby utworzyć pełny zasób danych szkoleniowych.
Dane obserwacji to dane przechwycone podczas samego zdarzenia. W tym miejscu zawiera podstawowe dane transakcji, w tym identyfikator transakcji, identyfikator konta i wartości kwoty transakcji. Ponieważ używasz go do trenowania, ma dołączoną również zmienną docelową (is_fraud).
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valuePobierz zarejestrowany zestaw funkcji i wyświetl listę jego funkcji.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Wybierz funkcje, które stają się częścią danych treningowych. Następnie użyj zestawu SDK magazynu funkcji, aby wygenerować same dane szkoleniowe.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueŁączenie w punkcie czasowym dodaje cechy do danych treningowych.
Włącz materializację offline w transactions zestawie funkcji
Po włączeniu materializacji zestawu funkcji można wykonać uzupełnianie brakujących danych. Można również zaplanować powtarzające się zadania materializacji. Aby uzyskać więcej informacji, odwiedź trzeci samouczek w zasobie serii .
Ustaw plik spark.sql.shuffle.partitions w pliku yaml zgodnie z rozmiarem danych funkcji
Konfiguracja Spark spark.sql.shuffle.partitions jest opcjonalnym parametrem, który może mieć wpływ na liczbę plików parquet generowanych (dziennie), gdy zestaw funkcji zostanie zmaterializowany w magazynie offline. Wartość domyślna tego parametru to 200. Najlepiej jest unikać generowania wielu małych plików Parquet. Jeśli pobieranie funkcji offline stanie się powolne po materializacji zestawu funkcji, przejdź do odpowiedniego folderu w magazynie offline, aby sprawdzić, czy problem obejmuje zbyt wiele małych plików parquet (dziennie) i odpowiednio dostosować wartość tego parametru.
Uwaga
Przykładowe dane używane w tym notesie są małe. W związku z tym ten parametr jest ustawiony na wartość 1 w pliku featureset_asset_offline_enabled.yaml.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())Zasób zestawu funkcji można również zapisać jako zasób YAML.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Uzupełnianie danych dla zestawu funkcji transactions
Jak wyjaśniono wcześniej, materializacja oblicza wartości funkcji dla okna funkcji i przechowuje te obliczone wartości w magazynie materializacji. Materializacja funkcji zwiększa niezawodność i dostępność obliczonych wartości. Wszystkie zapytania dotyczące funkcji używają teraz wartości z magazynu materializacji. Ten krok wykonuje jednorazowe uzupełnienie danych dla 18-miesięcznego okna czasowego.
Uwaga
Może być konieczne określenie wartości okna danych wypełniania danych. Okno musi być zgodne z oknem danych treningowych. Aby na przykład użyć 18 miesięcy danych do trenowania, musisz pobrać funkcje przez 18 miesięcy. Oznacza to, że należy wypełnić dane zapasowe w 18-miesięcznym oknie.
Ta komórka kodu materializuje dane według bieżącego stanu Brak lub Niekompletne dla zdefiniowanego okna funkcji.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Napiwek
- Kolumna
timestamppowinna być zgodna z formatemyyyy-MM-ddTHH:mm:ss.fffZ. - Granularność
feature_window_start_timeifeature_window_end_timejest ograniczona do sekund. Wszystkie milisekundy podane wdatetimeobiekcie zostaną zignorowane. - Zadanie materializacji zostanie przesłane tylko wtedy, gdy dane w oknie funkcji będą zgodne z
data_status, który jest zdefiniowany podczas przesyłania zadania wypełniania.
Drukuj przykładowe dane z zestawu funkcji. Informacje wyjściowe pokazują, że dane zostały pobrane z magazynu materializacji. Metoda get_offline_features() pobrała dane z treningu i inferencji. Domyślnie używa również magazynu materializacji.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Dalsze eksplorowanie materializacji funkcji w trybie offline
Stan materializacji funkcji można eksplorować dla zestawu funkcji w interfejsie użytkownika zadań materializacji.
Otwórz globalną stronę docelową usługi Azure Machine Learning.
Wybierz pozycję Repozytoria cech w okienku po lewej stronie.
Z listy dostępnych magazynów funkcji wybierz magazyn funkcji, dla którego wykonano wypełnianie.
Wybierz kartę Zadania materializacji.
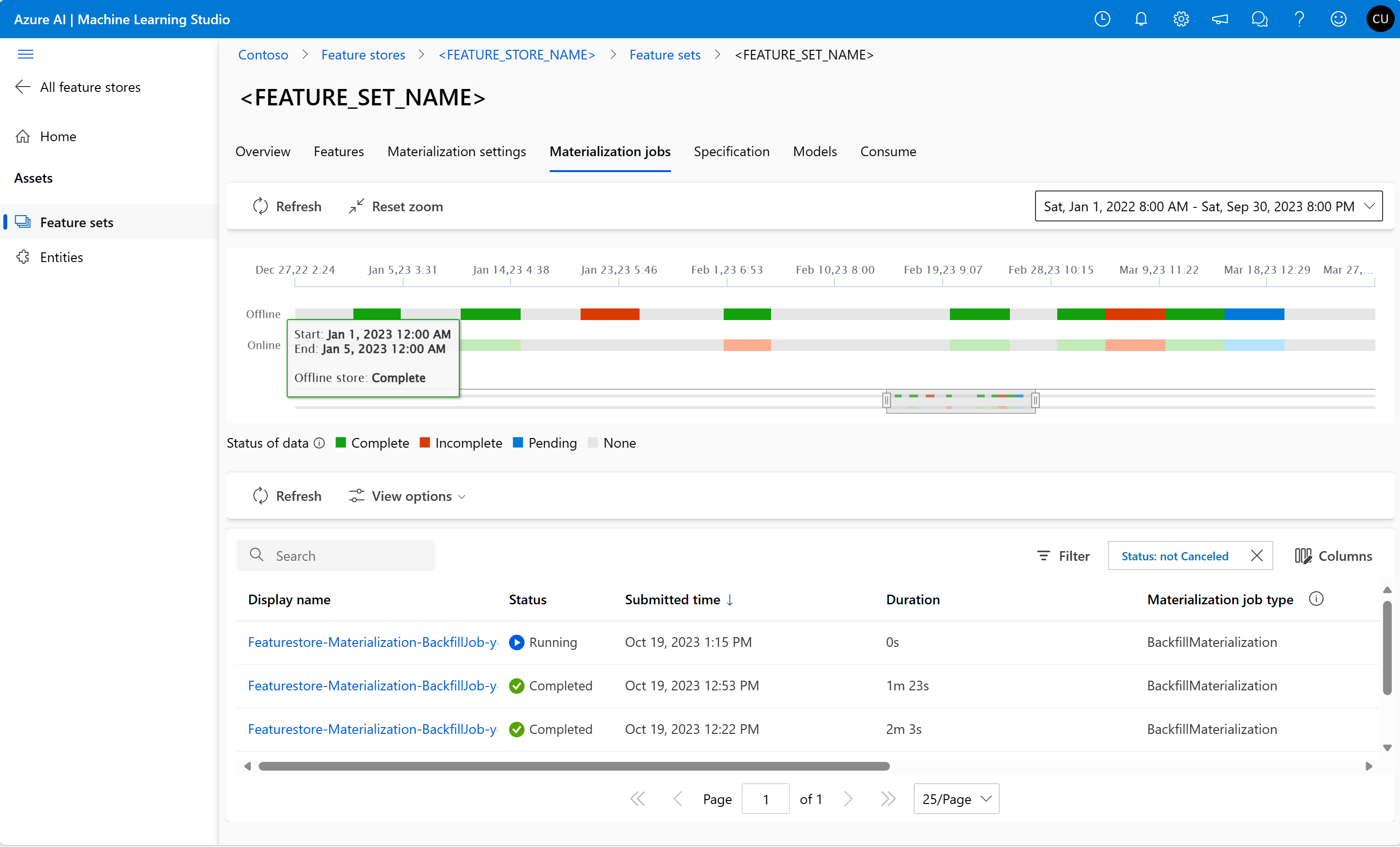

Stan materializacji danych może być
- Ukończ (zielony)
- Niekompletne (czerwone)
- Oczekiwanie (niebieski)
- Brak (szary)
Interwał danych reprezentuje ciągłą część danych z tym samym stanem materializacji danych. Na przykład wcześniejsza migawka ma 16 interwałów danych w magazynie materializacji offline.
Dane mogą mieć maksymalnie 2000 przedziałów danych. Jeśli dane zawierają ponad 2000 interwałów danych, utwórz nową wersję zestawu funkcji.
Możesz podać listę więcej niż jednego stanu danych (na przykład
["None", "Incomplete"]) w jednym zadaniu wypełniania.Podczas wypełniania kopii zapasowej jest przesyłane nowe zadanie materializacji dla każdego interwału danych należącego do zdefiniowanego okna funkcji.
Jeśli zadanie materializacji oczekuje lub zadanie jest przetwarzane dla przedziału danych, który nie został jeszcze wypełniony, nowe zadanie nie zostanie przesłane dla tego przedziału danych.
Możesz ponowić próbę nieudanego zadania materializacji.
Uwaga
Aby uzyskać identyfikator niepowodzenia zadania materializacji:
- Przejdź do interfejsu użytkownika zbioru funkcji zadań materializacji.
- Wybierz nazwę wyświetlaną określonego zadania ze stanem Niepowodzeniem.
- Znajdź identyfikator zadania we właściwości Name na stronie Przegląd zadania. Zaczyna się od
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Aktualizowanie magazynu materializacji w trybie offline
- Jeśli magazyn materializacji w trybie offline musi zostać zaktualizowany na poziomie magazynu funkcji, wszystkie zestawy funkcji w magazynie funkcji powinny mieć wyłączoną materializację w trybie offline.
- Jeśli w zestawie funkcji materializacja w trybie offline jest wyłączona, stan materializacji danych, które już zostały zmaterializowane w sklepie materializacji offline, zostanie zresetowany. Resetowanie renderuje dane, które są już zmaterializowane, bezużyteczne. Po włączeniu materializacji w trybie offline należy ponownie przesłać zadania materializacji.
W tym samouczku utworzono dane szkoleniowe z funkcjami z magazynu funkcji, włączono materializację do magazynu funkcji w trybie offline i wykonano wypełnianie. Następnie uruchomisz szkolenie modelu przy użyciu tych funkcji.
Czyszczenie
Piąty samouczek z serii opisuje sposób usuwania zasobów.
Następne kroki
- Zapoznaj się z następnym samouczkiem z serii: Eksperymentowanie i trenowanie modeli przy użyciu funkcji.
- Dowiedz się więcej o koncepcjach sklepu funkcji i jednostkach najwyższego poziomu w zarządzanym sklepie funkcji.
- Dowiedz się więcej na temat tożsamości i kontroli dostępu dla zarządzanego magazynu funkcji.
- Zapoznaj się z przewodnikiem rozwiązywania problemów z zarządzanym magazynem funkcji.
- Wyświetl referencję YAML.