Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Uwaga
Aby zapoznać się z samouczkiem korzystającym z SDK w wersji 1 do kompilowania potoku, zobacz Samouczek: tworzenie potoku usługi Azure Machine Learning na potrzeby klasyfikacji obrazów.
Potok uczenia maszynowego dzieli pełne zadanie uczenia maszynowego na wieloetapowy przepływ pracy. Każdy krok to zarządzany składnik, który można opracowywać, optymalizować, konfigurować i automatyzować osobno. Dobrze zdefiniowane interfejsy łączą kroki. Usługa potoków Azure Machine Learning koordynuje wszystkie zależności między krokami potoku.
Korzyści wynikające z używania pipeline'u to ustandaryzowana praktyka MLOps, skalowalna współpraca zespołowa, efektywność szkolenia i obniżenie kosztów. Aby dowiedzieć się więcej o zaletach potoków, zobacz Co to są potoki usługi Azure Machine Learning.
W tym samouczku użyjesz usługi Azure Machine Learning do utworzenia projektu uczenia maszynowego gotowego do produkcji przy użyciu zestawu SDK języka Python usługi Azure Machine Learning w wersji 2. Po wykonaniu tego samouczka możesz użyć zestawu SDK języka Python usługi Azure Machine Learning do:
- Uzyskiwanie dojścia do obszaru roboczego usługi Azure Machine Learning
- Tworzenie zasobów danych usługi Azure Machine Learning
- Tworzenie składników usługi Azure Machine Learning wielokrotnego użytku
- Tworzenie, weryfikowanie i uruchamianie potoków usługi Azure Machine Learning
W tym samouczku utworzysz potok usługi Azure Machine Learning, aby wytrenować model na potrzeby przewidywania domyślnego środków. Potok obsługuje dwa kroki:
- Przygotowywanie danych
- Trenowanie i rejestrowanie wytrenowanego modelu
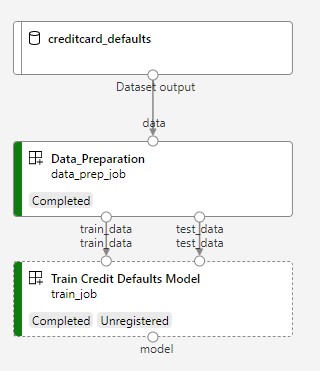
Następny obraz przedstawia prosty potok widoczny w Azure Studio po jego przesłaniu.
Te dwa kroki to przygotowanie danych i szkolenie.
W tym filmie wideo pokazano, jak rozpocząć pracę w usłudze Azure Machine Learning Studio, aby można było wykonać kroki opisane w samouczku. W filmie wideo pokazano, jak utworzyć notes, utworzyć wystąpienie obliczeniowe i sklonować notes. W poniższych sekcjach opisano również te kroki.
Wymagania wstępne
-
Aby korzystać z usługi Azure Machine Learning, potrzebny jest obszar roboczy. Jeśli go nie masz, ukończ tworzenie zasobów, aby rozpocząć tworzenie obszaru roboczego i dowiedz się więcej na temat korzystania z niego.
Ważne
Jeśli obszar roboczy usługi Azure Machine Learning jest skonfigurowany z zarządzaną siecią wirtualną, może być konieczne dodanie reguł ruchu wychodzącego w celu umożliwienia dostępu do publicznych repozytoriów pakietów języka Python. Aby uzyskać więcej informacji, zobacz Scenariusz: Uzyskiwanie dostępu do publicznych pakietów uczenia maszynowego.
-
Zaloguj się do programu Studio i wybierz swój obszar roboczy, jeśli jeszcze nie jest otwarty.
Ukończ samouczek Przekazywanie, uzyskiwanie dostępu do danych i eksplorowanie ich w celu utworzenia zasobu danych potrzebnego w tym samouczku. Upewnij się, że uruchomiono cały kod, aby utworzyć początkowy zasób danych. Możesz eksplorować dane i poprawiać je, jeśli chcesz, ale potrzebujesz tylko początkowych danych na potrzeby tego samouczka.
-
Otwórz lub utwórz notes w obszarze roboczym:
- Jeśli chcesz skopiować i wkleić kod do komórek, utwórz nowy notes.
- Możesz też otworzyć plik tutorials/get-started-notebooks/pipeline.ipynb z sekcji Przykłady programu Studio. Następnie wybierz pozycję Klonuj, aby dodać notes do plików. Aby znaleźć przykładowe notesy, zobacz Learn from sample notebooks (Informacje na podstawie przykładowych notesów).
Ustawianie jądra i otwieranie go w programie Visual Studio Code (VS Code)
Na górnym pasku powyżej otwartego notesu utwórz wystąpienie obliczeniowe, jeśli jeszcze go nie masz.

Jeśli wystąpienie obliczeniowe zostanie zatrzymane, wybierz pozycję Uruchom obliczenia i zaczekaj na jego uruchomienie.

Poczekaj na uruchomienie wystąpienia obliczeniowego. Następnie upewnij się, że jądro znajdujące się w prawym górnym rogu ma wartość
Python 3.10 - SDK v2. Jeśli nie, użyj listy rozwijanej, aby wybrać to jądro.
Jeśli to jądro nie jest widoczne, sprawdź, czy wystąpienie obliczeniowe jest uruchomione. Jeśli tak jest, wybierz przycisk Odśwież w prawym górnym rogu notesu.
Jeśli zostanie wyświetlony baner z informacją o konieczności uwierzytelnienia, wybierz pozycję Uwierzytelnij.
Możesz uruchomić notes tutaj lub otworzyć go w programie VS Code w celu uzyskania pełnego zintegrowanego środowiska projektowego (IDE) z możliwościami zasobów usługi Azure Machine Learning. Wybierz pozycję Otwórz w programie VS Code, a następnie wybierz opcję internetową lub klasyczną. Po uruchomieniu w ten sposób program VS Code jest dołączony do wystąpienia obliczeniowego, jądra i systemu plików obszaru roboczego.





Ważne
W pozostałej części tego samouczka znajdują się komórki notesu samouczka. Skopiuj je i wklej do nowego notesu lub przejdź do notesu teraz, jeśli go sklonujesz.
Konfigurowanie zasobów potoku
Platformę Azure Machine Learning można używać z poziomu interfejsu wiersza polecenia platformy Azure, zestawu SDK języka Python lub interfejsu studio. W tym przykładzie użyjesz zestawu SDK języka Python usługi Azure Machine Learning w wersji 2 do utworzenia potoku.
Przed utworzeniem potoku potrzebne są następujące zasoby:
- Zasób danych na potrzeby trenowania
- Środowisko oprogramowania do uruchamiania potoku
- Zasób obliczeniowy, w którym jest uruchamiane zadanie
Tworzenie dojścia do obszaru roboczego
Przed użyciem kodu potrzebny jest sposób odwołowania się do obszaru roboczego. Utwórz ml_client jako dojście do obszaru roboczego. Następnie używasz ml_client do zarządzania zasobami i zadaniami.
W następnej komórce wprowadź identyfikator subskrypcji, nazwę grupy zasobów i nazwę obszaru roboczego. Aby znaleźć następujące wartości:
- Na pasku narzędzi usługi Azure Machine Learning Studio w prawym górnym rogu wybierz nazwę obszaru roboczego.
- Skopiuj wartość obszaru roboczego, grupy zasobów i identyfikatora subskrypcji do kodu. Musisz skopiować jedną wartość, zamknąć obszar i wkleić, a następnie powrócić do następnej wartości.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Dokumentacja zestawu SDK:
Uwaga
Tworzenie klasy MLClient nie łączy się z obszarem roboczym. Inicjowanie klienta jest leniwe. Czeka, aż będzie musiał wykonać połączenie po raz pierwszy. Inicjowanie odbywa się w następnej komórce kodu.
Zweryfikuj połączenie, wykonując wywołanie metody ml_client. Ponieważ to jest pierwszy raz, kiedy wykonujesz wywołanie do obszaru roboczego, może pojawić się prośba o uwierzytelnienie.
# Verify that the handle works correctly.
# If you get an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Dokumentacja zestawu SDK:
Uzyskiwanie dostępu do zarejestrowanego zasobu danych
Zacznij od pobrania wcześniej zarejestrowanych danych w artykule Samouczek: przekazywanie, uzyskiwanie dostępu do danych i eksplorowanie ich w usłudze Azure Machine Learning.
Uwaga
Usługa Azure Machine Learning używa Data obiektu do rejestrowania definicji danych wielokrotnego użytku i korzystania z danych w potoku.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Dokumentacja zestawu SDK:
Tworzenie środowiska zadań dla kroków potoku
Do tej pory utworzono środowisko programistyczne na wystąpieniu obliczeniowym, czyli maszynie programistycznej. Potrzebne jest również środowisko do użycia dla każdego kroku potoku. Każdy krok może mieć własne środowisko lub można użyć niektórych typowych środowisk na potrzeby wielu kroków.
W tym przykładzie utworzysz środowisko conda dla zadań przy użyciu pliku yaml conda. Najpierw utwórz katalog do przechowywania pliku.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Teraz utwórz plik w katalogu dependencies.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.10
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
Specyfikacja zawiera niektóre zwykłe pakiety używane w potoku (numpy, pip), a także pakiety specyficzne dla Azure Machine Learning (azureml-mlflow).
Pakiety usługi Azure Machine Learning nie są wymagane do uruchamiania zadań usługi Azure Machine Learning. Dodając te pakiety, możesz wchodzić w interakcje z usługą Azure Machine Learning w celu rejestrowania metryk i rejestrowania modeli — wszystko to w zadaniu usługi Azure Machine Learning. Będą one używane w skrygcie szkoleniowym w dalszej części tego samouczka.
Użyj pliku yaml, aby utworzyć i zarejestrować to środowisko niestandardowe w obszarze roboczym:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Dokumentacja zestawu SDK:
Tworzenie potoku trenowania
Teraz, gdy masz wszystkie zasoby wymagane do uruchomienia potoku, nadszedł czas na zbudowanie samego potoku.
Potoki usługi Azure Machine Learning to przepływy pracy uczenia maszynowego wielokrotnego użytku, które zwykle składają się z kilku składników. Typowy cykl życia składnika to:
- Zapisz specyfikację YAML składnika lub utwórz go programowo przy użyciu polecenia
ComponentMethod. - Opcjonalnie zarejestruj składnik pod nazwą i wersją w obszarze roboczym, aby można było go ponownie używać i udostępniać.
- Załaduj ten składnik z kodu potoku.
- Zaimplementuj pipeline korzystając z danych wejściowych, wyjściowych i parametrów komponentu.
- Prześlij potok.
Składnik można utworzyć na dwa sposoby: definicję programową i definicję YAML. W kolejnych dwóch sekcjach opisano tworzenie składnika na oba sposoby. Możesz utworzyć dwa składniki, próbując użyć obu opcji lub wybrać preferowaną metodę.
Uwaga
W tym samouczku dla uproszczenia użyjesz tego samego obliczenia dla wszystkich składników. Można jednak ustawić różne obliczenia dla każdego składnika. Możesz na przykład dodać wiersz, taki jak train_step.compute = "cpu-cluster". Aby wyświetlić przykład tworzenia potoku z różnymi obliczeniami dla każdego składnika, zobacz sekcję Podstawowe zadanie potoku w samouczku dotyczącym potoku cifar-10.
Tworzenie składnika 1: przygotowywanie danych (przy użyciu definicji programowej)
Zacznij od utworzenia pierwszego składnika. Ten składnik obsługuje wstępne przetwarzanie danych. Zadanie przetwarzania wstępnego jest wykonywane w pliku data_prep.py Python.
Najpierw utwórz folder źródłowy dla składnika data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Ten skrypt wykonuje proste zadanie dzielenia danych na zestawy danych trenowania i testowania. Usługa Azure Machine Learning instaluje zestawy danych jako foldery do obliczeń. Utworzono funkcję pomocniczą select_first_file w celu uzyskania dostępu do pliku danych w zainstalowanym folderze wejściowym.
Usługa MLFlow służy do rejestrowania parametrów i metryk podczas uruchamiania potoku.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Teraz, gdy masz skrypt, który może wykonać żądane zadanie, utwórz na jego podstawie składnik usługi Azure Machine Learning.
Użyj ogólnego przeznaczenia CommandComponent , które mogą uruchamiać akcje wiersza polecenia. Ta akcja wiersza polecenia może bezpośrednio wywoływać polecenia systemowe lub uruchamiać skrypt. Dane wejściowe i wyjściowe są określane w wierszu polecenia przy użyciu ${{ ... }} notacji.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Dokumentacja zestawu SDK:
Opcjonalnie zarejestruj składnik w obszarze roboczym, aby ponownie użyć go w przyszłości.
# Now register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create and register the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Dokumentacja zestawu SDK:
Tworzenie składnika 2: trenowanie (przy użyciu definicji yaml)
Drugi utworzony składnik korzysta z danych treningowych i testowych, trenuje model oparty na drzewie i zwraca model wyjściowy. Korzystanie z funkcji rejestrowania usługi Azure Machine Learning w celu rejestrowania i wizualizowania postępu nauki.
Użyto klasy do utworzenia CommandComponent pierwszego składnika. Tym razem użyjesz definicji yaml do zdefiniowania drugiego składnika. Każda metoda ma własne zalety. Definicję yaml można zaewidencjonować wraz z kodem i uzyskać czytelne śledzenie historii. Metoda programowa przy użyciu metody CommandComponent może być łatwiejsza dzięki wbudowanej dokumentacji klasy i uzupełnianiu kodu.
Utwórz katalog dla tego składnika:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Utwórz skrypt szkoleniowy w katalogu:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Jak widać w tym skrypcie treningowym, po wytrenowaniu modelu plik modelu jest zapisywany i rejestrowany w obszarze roboczym. Teraz możesz użyć zarejestrowanego modelu w punktach końcowych wnioskowania.
W środowisku tego kroku należy użyć jednego z wbudowanych (wyselekcjonowanych) środowisk usługi Azure Machine Learning. Tag azureml informuje system o poszukiwaniu nazwy w środowiskach wyselekcjonowanych.
Najpierw utwórz plik yaml opisujący składnik:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Teraz utwórz i zarejestruj składnik. Zarejestrowanie go umożliwia jego ponowne użycie w innych potokach. Każda inna osoba mająca dostęp do obszaru roboczego może również używać zarejestrowanego składnika.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create and register the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Dokumentacja zestawu SDK:
Tworzenie potoku na podstawie składników
Po zdefiniowaniu i zarejestrowaniu składników rozpocznij implementację potoku.
Funkcje języka Python, które load_component() zwracają, działają jak każda zwykła funkcja języka Python. Użyj ich w potoku, aby wywołać każdy krok.
Aby zakodować potok, użyj określonego @dsl.pipeline dekoratora identyfikującego potoki usługi Azure Machine Learning. W dekoratorze określ opis potoku oraz domyślne zasoby, takie jak moc obliczeniowa i przechowywanie danych. Podobnie jak funkcja języka Python, potoki mogą mieć dane wejściowe. Można utworzyć wiele wystąpień pojedynczego potoku z różnymi danymi wejściowymi.
W poniższym przykładzie użyj danych wejściowych, współczynnika podziału i zarejestrowanej nazwy modelu jako zmiennych wejściowych. Następnie wywołaj składniki i połącz je przy użyciu identyfikatorów danych wejściowych i wyjściowych. Uzyskaj dostęp do danych wyjściowych każdego kroku przy użyciu .outputs właściwości .
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Dokumentacja zestawu SDK:
Teraz użyj definicji potoku, aby utworzyć wystąpienie potoku z zestawem danych, wybraną wartością podziału i nazwą, którą wybrałeś dla swojego modelu.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Dokumentacja zestawu SDK:
Przesyłanie zadania
Teraz prześlij zadanie do uruchomienia w usłudze Azure Machine Learning. Tym razem użyj polecenia create_or_update w pliku ml_client.jobs.
Przekaż nazwę eksperymentu. Eksperyment jest kontenerem dla wszystkich iteracji, które wykonuje w określonym projekcie. Wszystkie zadania przesłane pod tą samą nazwą eksperymentu są wyświetlane obok siebie w usłudze Azure Machine Learning Studio.
Po zakończeniu potok przetwarzania rejestruje model w obszarze roboczym jako rezultat treningu.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Dokumentacja zestawu SDK:
Postęp rozwiązania można śledzić, korzystając z linku wygenerowanego w poprzedniej komórce. Po pierwszym wybraniu tego linku możesz zauważyć, że pipeline jest nadal uruchomiony. Po zakończeniu możesz sprawdzić wyniki poszczególnych składników.
Kliknij dwukrotnie składnik Train Credit Defaults Model (Trenowanie domyślnego modelu środków).
Dwa ważne wyniki, które chcesz zobaczyć na temat trenowania:
Wyświetl dzienniki:
- Wybierz kartę Dane wyjściowe+dzienniki .
- Otwórz foldery w tej sekcji, aby wyświetlić
user_logs>std_log.txtskrypt uruchamiania stdout.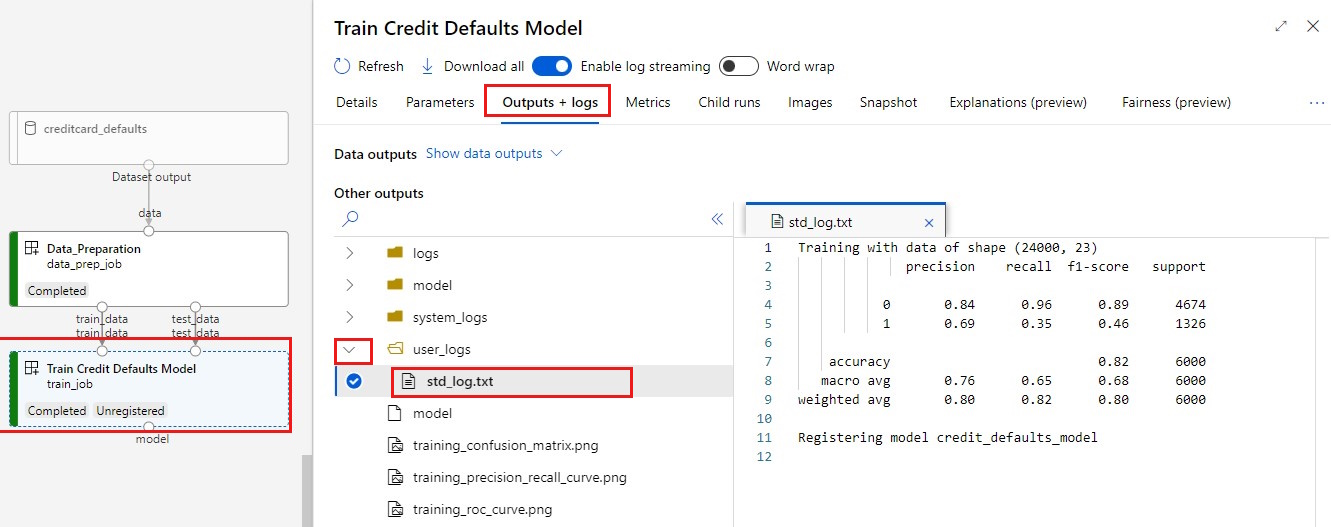
Wyświetl metryki: wybierz kartę Metryki . W tej sekcji przedstawiono różne zarejestrowane metryki. W tym przykładzie mlflow
autologgingautomatycznie rejestruje metryki trenowania.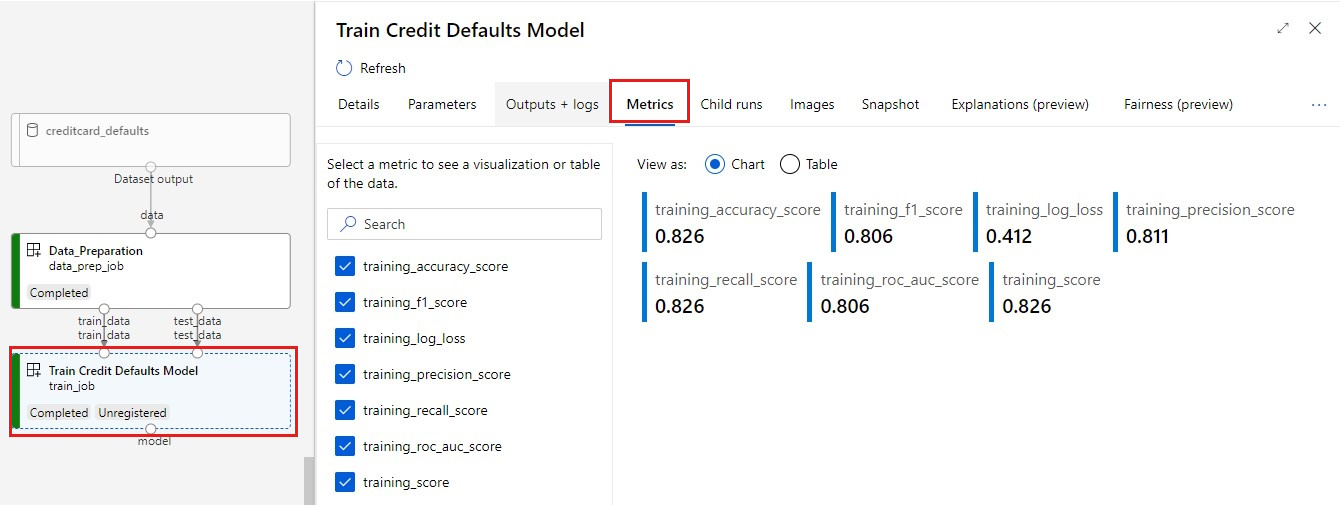


Wdrażanie modelu jako punktu końcowego online
Aby uzyskać więcej informacji na temat wdrażania modelu w punkcie końcowym online, zobacz Samouczek Wdrażanie modelu jako punktu końcowego online.
Czyszczenie zasobów
Jeśli planujesz kontynuować korzystanie z innych samouczków, przejdź do sekcji Następny krok.
Zatrzymywanie wystąpienia obliczeniowego
Jeśli nie zamierzasz teraz używać wystąpienia obliczeniowego, zatrzymaj je:
- W Studio w okienku po lewej stronie wybierz pozycję Komputer.
- Na pierwszych kartach wybierz pozycję Wystąpienia obliczeniowe.
- Wybierz wystąpienie obliczeniowe na liście.
- Na górnym pasku narzędzi wybierz pozycję Zatrzymaj.
Usuwanie wszystkich zasobów
Ważne
Utworzone zasoby mogą być używane jako wymagania wstępne w innych samouczkach usługi Azure Machine Learning i artykułach z instrukcjami.
Jeśli nie planujesz korzystać z żadnych utworzonych zasobów, usuń je, aby nie ponosić żadnych opłat:
W witrynie Azure Portal w polu wyszukiwania wprowadź ciąg Grupy zasobów i wybierz je z wyników.
Z listy wybierz utworzoną grupę zasobów.
Na stronie Przegląd wybierz pozycję Usuń grupę zasobów.
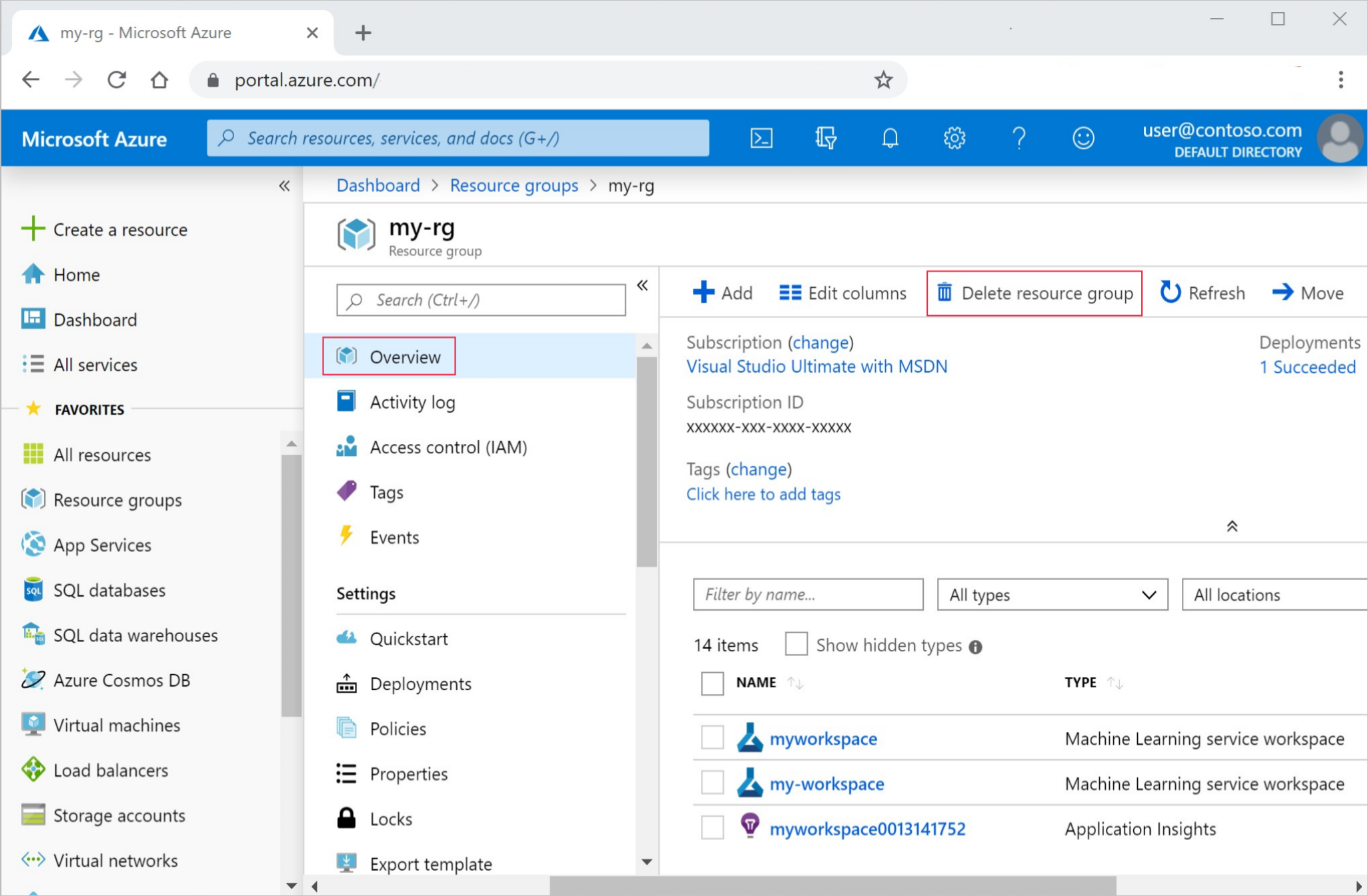
Wpisz nazwę grupy zasobów. Następnie wybierz Usuń.